
融合L2范数最小化和压缩Haar-like特征匹配的快速目标跟踪
2016-10-13 13:45吴正平崔晓梦张庆年
电子与信息学报 2016年11期
吴正平 杨 杰 崔晓梦 张庆年
融合L2范数最小化和压缩Haar-like特征匹配的快速目标跟踪
吴正平①②杨 杰*①崔晓梦①张庆年①
①(武汉理工大学光纤传感技术与信息处理教育部重点实验室 武汉 430070)②(三峡大学计算机与信息工程学院 宜昌 443002)
在贝叶斯推理框架下,基于PCA子空间和L2范数最小化的目标跟踪算法能较好地处理视频场景中多种复杂的外观变化,但在目标出现旋转或姿态变化时易发生跟踪漂移现象。针对这一问题,该文提出一种融合L2范数最小化和压缩Haar-like特征匹配的快速视觉跟踪方法。该方法通过去除规模庞大的方块模板集和简化观测似然度函数降低计算的复杂度;而压缩Haar-like特征匹配技术则增强了算法对目标姿态变化及旋转的鲁棒性。实验结果表明:与目前流行的跟踪方法相比,该方法对严重遮挡、光照突变、快速运动、姿态变化和旋转等干扰均具有较强的鲁棒性,且在多个测试视频上可以达到29帧/s的速度,能满足快速视频跟踪要求。
目标跟踪;PCA子空间;L2范数最小化;压缩Haar-like特征;观测似然度
1 引言
自动目标跟踪一直是计算机视觉领域一个核心问题,目前在智能视频监控、船舶航迹跟踪、机器人导航等方面有着广泛的应用。经典的目标跟踪方法包括均值漂移算法和粒子滤波算法。一般认为前者实时性好,但在遮挡等情况下容易陷入局部极值而导致跟踪的鲁棒性变差;后者具有较强的抗遮挡和背景干扰能力,但计算量大,难于满足实时跟踪要求。近二十年来,大量学者对视频跟踪问题进行深入研究,并提出了多种类型的跟踪算法。基于外观模型的跟踪算法一般可分为两大类:生成式算法和判别式算法。
生成式跟踪算法首先要通过学习得到表示目标的外观模型,然后搜寻具有最小重建误差的候选目标作为跟踪结果。文献[3]提出的IVT(Incremental learning for robust Visual Tracking)算法利用在线学习到的PCA(Principal Component Analysis)子空间对目标进行线性表示,并利用增量学习的方式对子空间进行更新。2011年,文献[4]将稀疏表示理论应用到目标跟踪中,提出了著名的L1-track (visual tracking usingminimization)算法,用一组目标模板和琐碎模板对目标进行L1范数最小化稀疏表示,较好地解决了部分遮挡问题。但L1-track在每一帧中都必须求解数百次的L1范数最小化,极大地限制了该算法在实时跟踪中的应用。通过引入最小误差界限(minimal error bounding)策略,文献[5]大幅提高了L1-track的处理速度,但依然不能满足实时处理要求。2012年,文献[6]提出一种关于L1范数最小化问题的快速数值解法,进一步提高了L1-track的时效性(称之为APG-L1算法)。近年来一些学者采用L2范数最小化来进行人脸识别研究,取得了和基于稀疏表示理论的算法一样甚至更高的识别度,更重要的是,L2范数最小化问题可用岭回归分析求解,其时间消耗远低于L1范数最小化。2012年,文献[8,9]将L2范数引入到视频跟踪(称之为L2算法),并使用PCA子空间基向量(PCA subspace vectors)和方块模板(square templates)替换L1-track中的目标模板和琐碎模板,在大量数据集上均取得了很高的跟踪精度,是目前非常优秀的跟踪算法之一。2013年,文献[10]完全去除L2算法中的方块模板,使得目标表示系数的求解变得更加简单和迅速,得到了一种真正意义上的实时目标跟踪算法(称之为PCAL2算法)。然而这两种算法都未能解决当目标出现旋转或姿态变化时易发生跟踪漂移的问题。
判别式跟踪算法则将视频跟踪问题转化为一个二分类问题,即找寻一个将目标和背景区别开来的最佳判别界限。2012年,文献[15]提出的实时压缩跟踪算法(real-time Compressive Tracking,称之为CT算法)是该类算法最典型代表之一。CT算法通过一个可离线计算得到随机测量矩阵来压缩Haar-like特征,极大地减少了提取目标外观特征所花费的时间,使得CT算法的跟踪速度远快于之前提到APG-L1, L2以及PCAL2算法。文献[16]提出了基于核相关滤波器的快速目标跟踪算法(high-speed tracking with Kernelized Correlation Filters, 称之为KCF算法),其中分类器中的样本通过快速傅里叶变换转换到频域进行运算,极大地提高了算法的时效性,是目前实时性最好的跟踪算法之一。但上述两种算法均缺乏有效的抗遮挡机制,对于严重遮挡和光照突变比较敏感。
针对当前视频跟踪算法中存在的挑战,本文提出了一种融合L2范数和压缩Haar-like特征的快速视频目标跟踪算法。首先利用增量学习的PCA子空间对目标进行线性表示,建立基于L2范数最小化的目标表示模型,并完全舍弃规模相对庞大的方块模板,使得目标表示系数的求解更加简单;但不同于L2和PCAL2,本文所建立的观测似然度模型仅利用残差向量的L1范数,可更快地对候选目标进行估计;最后,考虑PCAL2算法对旋转或姿态变化较为敏感的问题,本文引入压缩Haar-like特征匹配技术,并通过最小误差界限准则去除大多数非重要的粒子,以极小的时间代价增强了算法在复杂环境下的鲁棒性。
2 基于L2范数最小化的目标表示
2.1基于PCA子空间目标线性表示
主成分分析法(PCA)将灰度图像数据映射到低维子空间以获取目标外观的潜在特征,因而滤除了一些噪声,对于视点变化、尺度变化、光照变化等具有良好的适用性。假定目标存在于子空间中,那么观测向量可以由中的基向量进行线性表示,即

2.2 L2范数最小化求解编码系数


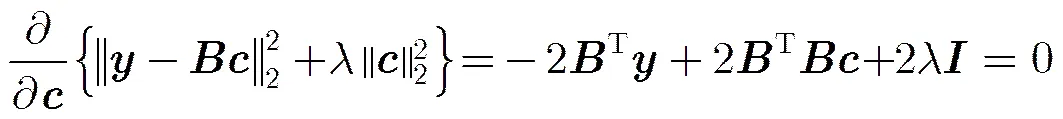
可得

3 目标跟踪算法框架
3.1贝叶斯MAP估计
本文把目标跟踪问题看成隐马尔科夫模型中隐藏状态变量的贝叶斯MAP估计问题。给定一组目标在第帧时的观测向量,那么可通过式(5)递推估计隐藏变量:
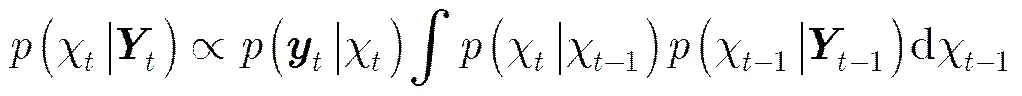
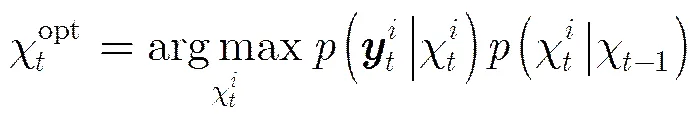
3.2状态转移模型
本文选取仿射变换的6个参数来对目标的运动变化进行描述,即目标状态变量定义为
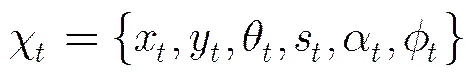

3.3目标观测模型

再根据式(1)可计算其重建误差(也称残差),即
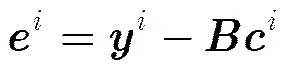

但文献[9]的作者通过实验观察发现,在观测似然度函数中引入残差的L1范数将有益于提高跟踪算法的鲁棒性和跟踪精度,受此启发,本文定义的观测似然度函数如式(12)


图1 两种观测似然度函数下跟踪精度对比
从图1可以看出,两种观测似然度函数下得到的中心误差曲线几乎是重合的。而从中心误差平均值和标准差两个指标来看,采用L1范数取得了更佳的跟踪精度,可见本文将观测似然函数设计为残差L1范数的指数函数是合理的。从计算代价来看,式(11)的时间复杂度为;而式(12)无乘法运算,其时间消耗可以忽略不计,因此用式(12)代替式(11)在一定程度上提高了算法的实时性。最后,第帧目标的最佳状态值可以通过选取似然度最大的候选目标来获得。

3.4 PCA子空间更新
本文采取与文献[9,10]类似的基于遮挡率(occlusion-ratio-based)的更新机制来对PCA子空间的基向量进行更新。在得到当前帧的最佳状态值后,利用式(10)可求出其对应的残差向量,那么反映目标被遮挡程度的遮挡率定义为

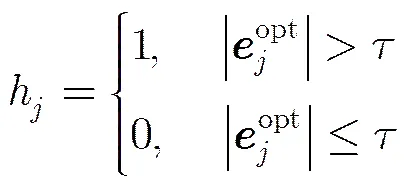
3.5 融合压缩Haar-like特征匹配
为提高跟踪算法对目标姿态变化及旋转的鲁棒性,引入压缩Haar-like特征匹配技术。该技术主要由不等式融合条件、压缩Haar-like特征提取及匹配和去除非重要性粒子3部分组成。
3.5.1不等式融合条件 首先通过式(14)获得当前帧和前一帧的遮挡率和。如果它们满足下面不等式约束:
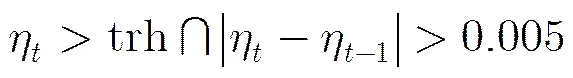
那么启用Haar-like特征匹配算法重新计算目标的最佳状态值。
3.5.2压缩Haar-like特征提取 在CT算法中,任一样本图像块(分别表示跟踪矩形框的长和宽,且在跟踪过程中保持不变)的压缩Haar-like特征生成过程如下:首先将与一组矩形滤波器进行卷积,得到一个高维图像Haar-like特征向量;然后在一满足有限等距性质(RIP)的随机测量矩阵协助下,实现将高维特征映射为低维特征,即



进一步利用最小误差界准则来去除大多数非重要粒子,以提高算法的实时性。重要粒子需满足式(20):
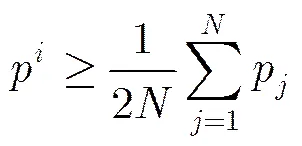

3.6 算法流程
综上所述,本文算法流程如表1所示。
表1本文算法流程

输入:第帧图像数据;第帧时的目标状态、压缩Haar-like特征向量和遮挡率;跟踪矩形框长W和宽H;粒子数量N。(1)利用状态转移模型,即式(8)生成N个粒子,获取每个候选目标中心位置对应的图像块,并对其进行归一化拉伸为向量,接着利用计算投影矩阵;(2)对所有观测向量按式(9)和式(10)分别计算表示系数和残差;(3)按式(12)计算观测似然度,按式(13)和式(14)分别获得目标最佳状态和目标被遮挡程度;(4)如果满足式(16),则顺序执行,否则转向步骤(7);(5)按式(20)筛选出重要性粒子,获取这些粒子对应图像块并计算其对应的压缩Haar-like特征向量集;(6)按式(19)计算特征相似度,按式(21)重新计算目标最佳状态;(7)执行赋值;(8)按式(17)计算并保存图像块对应的压缩Haar-like特征向量,记为;输出:第帧时的目标状态、压缩Haar-like特征向量和遮挡率。
4 实验结果与分析
4.1实验平台及实验参数设定

表2 实验中的测试视频
4.2对比实验结果的定性评估
在视频测试序列“FaceOcc1”,“Caviar2”,“Car4”和“Deer”中存在严重遮挡、尺度变化、剧烈的光线变化和快速运动等干扰因素(如图2第1~4行所示)。从图2所示的实验结果可以看出,本文算法、L2及PCAL2的跟踪性能要优于其他4种算法。IVT算法由于其采用的模板更新机制较为简单,在“Car4”和“Deer”视频序列最终跟踪失败。CT算法因其缺乏有效的抗遮挡机制,当目标被深度遮挡(如“FaceOcc1”中第534帧和“Caviar2”中第197帧)或发生光线突变(如“Car4”中第233帧)后,跟踪出现漂移并逐渐丢失目标。KCF算法因同样的原因导致其不能很好地应对严重遮挡和光线突变等干扰,在“FaceOcc1”和“Caviar2”两个视频序列中最终丢失目标(如“FaceOcc1”中第838帧和“Caviar2”中第429帧);在“Car4”视频序列中虽然没有丢失目标,但随着其跟踪窗口中引入的背景干扰信息逐渐积累,最终也出现了一定程度的跟踪漂移(如第630帧)。APG-L1算法虽然在整个“FaceOcc1”视频序列中成功跟踪目标,但它的稳定较差,在“Caviar2”,“Car4”和“Deer”视频序列上最终丢失目标。本文算法、L2及PCAL2在出现严重遮挡、尺度变化、剧烈光线变化和快速运动等异常情况下表现出良好的鲁棒性,主要归因于以下两点:一是PCA子空间对于尺度变化和光照变化等具有良好的适用性;二是基于遮挡率的更新机制大大增强了跟踪算法的抗遮挡性能。
在视频测试序列“David”,“Dudek”和“Sylvester2008b”中主要存在姿态变化和旋转两种干扰(如图2第5~7行所示)。在“David”视频跟踪实验中,当“David”转动其头部时(如第475帧),L2和PCAL2均丢失目标。尽管PCAL2之后成功跟踪上目标(如第564帧),但它的性能并不稳定,在第659, 705帧再次丢失目标。在“Dudek”和“Sylvester2008b”视频序列中的测试结果同样表明它们对于姿态变化和旋转较为敏感,在“Dudek”中第476, 550帧及“Sylvester2008b”中第187, 274, 360帧均丢失目标。CT和KCF均利用大量目标周围的样本数据在线训练和更新朴素贝叶斯分类器或RLS分类器,能很好地应对姿态变化和旋转等干扰因素,在整个视频中都能持续稳定地跟踪目标。本文算法则采用压缩Haar-like特征来区分背景和目标,也取得了良好的跟踪效果,这说明本文算法在处理姿态变化和旋转等干扰时较L2和PCAL2算法具有更强的鲁棒性。
在视频序列“Lemming”中,存在严重遮挡、尺度变化、旋转、快速运动与运动模糊等多种干扰因素(如图2最后一行所示)。在这个极具挑战性的视频中,只有本文算法能够完成整个视频的跟踪,这主要是因为本文算法结合了基于L2范数最小化的跟踪算法和Haar-like特征匹配技术的优点,能很好地应对各种复杂的外观变化。
4.3对比实验结果的定量评估
为对各种算法进行全面客观的评价,除采用中心位置误差这个经典度量标准外,还利用重叠率来定量评价跟踪算法的性能,其中是算法在某帧的跟踪矩形框所覆盖的区域,则是该帧目标所在的真实区域。表3和表4给出了所有跟踪算法在全部视频序列上的平均中心误差和平均重叠率。
从表3和表4可以看出,本文算法由于综合了PCAL2算法和Haar-like特征匹配技术的优点,在全部测试视频上均取得了最佳或次佳的结果。对于存在较大姿态变化和旋转的“David”,“Dudek”,“Sylvester2008b”和“Lemming”4个视频序列,本文算法的跟踪精度则明显优于IVT, L1-APG, L2和PCAL2算法;而对于另外的4个视频序列,本文算法的跟踪精度则明显优于CT和KCF两种算法。

图2 本文算法与其他6种跟踪算法在8个测试视频的部分跟踪结果
(从上到下分别对应“FaceOcc1”, “Caviar2”, “Car4”, “Deer”, “David”, “Dudek”, “Sylvester2008b”和“Lemming”)
4.4对比不同跟踪算法平均处理速度
为了检验融入特征匹配技术对跟踪算法处理速度的影响,统计了本文算法及与其相近的IVT, L2和PCAL2在对“FaceOcc1”,“Caviar2”,“Car4”,“David”和“Lemming”等5个视频序列进行跟踪实验时的平均处理速度,详见表5。从表5可以看出,本文跟踪方法的平均处理速度达29 帧/s,明显快于IVT和L2算法,能满足快速视频跟踪要求。尽管压缩Haar-like特征提取模块增加了本文算法的耗时,但由于以下3个方面的原因:(1)单个图像块的压缩Haar-like特征提取耗时极少(在本文的实验平台上约为s);(2)去除了大多数非重要性粒子;(3) 观测似然度函数中仅使用残差的L1范数,本文算法取得了和PCAL2相当的处理速度。
表3平均中心误差(像素)

跟踪算法FaceOcc1Caviar2Car4DeerDavidDudekSylvester2008bLemming平均值 IVT37.83.298.1271.1113.4 78.6196.8188.1123.4 CT41.566.190.6 38.8 15.7 55.0 15.1 91.2 51.8 APG-L119.566.092.7176.7 22.9119.7 77.0181.5 94.5 L2 6.4 2.8 3.0 9.7133.6 95.4118.3 69.2 54.8 PCAL2 6.6 6.0 3.6 8.9 59.5 65.7 79.7 74.6 38.1 KCF51.033.611.4 23.5 13.3 10.2 4.0107.3 31.8 本文算法 6.5 2.6 3.4 8.6 13.2 13.4 6.1 9.8 8.0
注:粗体字代表最佳结果,斜体字代表次佳结果
表4平均重叠率

跟踪算法FaceOcc1Caviar2Car4DeerDavidDudekSylvester2008bLemming平均值 IVT0.560.800.270.030.090.450.010.050.28 CT0.520.170.250.390.530.410.490.270.38 APG-L10.710.320.250.050.430.180.060.140.27 L20.870.750.890.700.110.530.200.380.55 PCAL20.870.730.870.730.330.540.340.380.60 KCF0.570.280.750.630.570.820.850.230.59 本文算法0.870.770.880.730.570.770.750.500.73
注:粗体字代表最佳结果,斜体字代表次佳结果
表5不同算法的平均处理速度(帧/s)

跟踪算法FaceOcc1Caviar2Car4DavidLemming平均值 IVT22.622.722.123.8 9.520.1 L221.419.620.623.917.920.7 PCAL227.029.230.331.324.528.5 本文算法28.531.133.927.923.529.0
5 结论
本文针对基于L2范数最小化的视觉跟踪算法在目标出现旋转或姿态变化时易发生跟踪漂移的不足,提出了一种融合L2范数最小化和压缩Haar-like特征匹配技术的快速视觉跟踪算法。一方面,该方法完全去除L2算法中的方块模板集,并将观测似然度函数简化为残差L1范数的指数函数,加快了目标跟踪的速度,在多个测试视频上可以达到29帧/s的速度;另一方面,该方法通过融入压缩Haar-like特征匹配技术来适应目标外观的变化,提高了跟踪算法对目标姿态变化及旋转的鲁棒性。最后利用多个具有挑战性的视频对提出的跟踪方法进行实验验证,并与多个目前流行的跟踪方法进行了定性和定量比较,实验结果表明:本文提出的跟踪方法对严重遮挡、光线突变、快速运动、姿态变化及旋转均具有较强的鲁棒性,且处理速度可满足快速视频跟踪要求。
[1] COMANICIU D, RAMESH V, and MEER P. Real-time tracking of non-rigid objects using mean shift[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Hilton Head, SC, USA, 2000: 142-149.
[2] KATJA N, ESTHER K M, and LUC V G. An adaptive color-based filter[J]., 2003, 21(1): 99-110.
[3] ROSS D, LIM J, LIN R S,. Incremental learning for robust visual tracking[J]., 2008, 77(1-3): 125-141. doi: 10.1007/s11263- 007-0075-7.
[4] MEI Xue and LING Haibin. Robust visual tracking usingminimization[C]. Proceedings of IEEE International Conference on Computer Vision, Kyoto, Japan, 2009: 1436-1443.
[5] MEI Xue, LING Haibin, WU Yi,. Minimum error bounded efficienttracker with occlusion detection[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Colorado, USA, 2011: 1257-1264.
[6] BAO Chenglong, WU Yi, LING Haibin,. Real time robust1tracker using accelerated proximal gradient approach[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Rhode Island, USA, 2012: 1830-1837.
[7] SHI Qinfeng, ERIKSSON A, VAN DEN HENGEL A,. Is face recognition really a compressive sensing problem?[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Colorado, USA, 2011: 553-560.
[8] XIAO Ziyang, LU Huchuan, and WANG Dong. Object tracking with L2_RLS[C]. Proceedings of 21st International Conference on Pattern Recognition, Tsukuba, Japan, 2012: 681-684.
[9] XIAO Ziyang, LU Huchuan, and WANG Dong. L2-RLS based object tracking[J].,2014, 24(8): 1301-1309. doi: 10.11834/jig.20140105.
QI Meibin, YANG Xun, YANG Yanfang,. Real-time object tracking based on L-norm minimization[J]., 2014, 19(1): 36-44. doi: 10.11834/jig. 20140105.
YUAN Guanglin and XUE Mogen. Robust coding via L-norm regularization for visual tracking[J].&, 2014, 36(8): 1838-1843. doi: 10.3724/SP.J.1146.2013.01416.
[12] WU Zhengping, YANG Jie, LIU Haibo,. A real-time object tracking via L2-RLS and compressed Haar-like features matching[J]., 2016: 1-17. doi: 10.1007/s11042-016-3356-8.
[13] HONG S and HAN B. Visual tracking by sampling tree-structured graphical models[C]. Proceedings of European Conference on Computer Vision, Zurich, Switzerland, 2014: 1-16.
[14] ZHUANG Bohan, LU Huchuan, XIAO Ziyang,. Visual tracking via discriminative sparse similarity map[J]., 2014, 23(4): 1872-1881. doi: 10.1109/TIP.2014.2308414.
[15] ZHANG Kaihua, ZHANG Lei, and YANG Minghsuan. Real-time compressive tracking[C]. Proceedings of European Conference on Computer Vision, Florence, Italy, 2012: 864-877.
[16] HENRIQUES J, CASEIRO R, MARTINS P,. High-speed tracking with kernelized correlation filters[J]., 2015, 37(3): 583-596. doi: 10.1109/TPAMI. 2014.2345390.
[17] LI Hanxin, LI Yi, and FATIH P. Deep track: learning discriminative feature representations by convolutional neural networks for visual tracking[C]. Proceedings of the British Machine Vision Conference, Nottingham, United Kingdom, 2014: 110-119.
[18] WU Zhengping, YANG Jie, LIU Haibo,. Robust compressive tracking under occlusion[C]. Proceedings of International Conference on Consumer Electronics, Berlin, Germany, 2015: 298-302.
[19] WU Yi, LIM J, and YANG Minghsuan. Online object tracking: a benchmark[C]. Proceedings of IEEE Conference on Computer Vision and Pattern Recognition, Portland, ORegon, USA, 2013: 2411-2418.
Fast Object Tracking Based on L2-norm Minimization and Compressed Haar-like Features Matching
WU Zhengping①②YANG Jie①CUI Xiaomeng①ZHANG Qingnian①
①(,,,430070,)②(,,443002,)
Under the framework of the Bayesian inference,tracking methods based on PCA subspace and L2-norm minimization can deal with some complex appearance changes in the video scene successfully. However, they are prone to drifting or failure when the target object undergoes pose variation or rotation. To deal with this problem, a fast visual tracking method is proposed based on L2-norm minimization and compressed Haar-like features matching. The proposed method not only removes square templates, but also presents a simple but effective observation likelihood, and its robustness to pose variation and rotation is strengthened by Haar-like features matching. Compared with other popular method, the proposed method has stronger robustness to abnormal changes (e.g. heavy occlusion, drastic illumination change, abrupt motion, pose variation and rotation, etc). Furthermore, it runs fast with a speed of about 29 frames/s.
Object tracking; PCA subspace; L2-norm minimization; Compressed Haar-like feature; Observation likelihood
TP391
A
1009-5896(2016)11-2803-08
10.11999/JEIT160122
2016-01-26;改回日期:2016-06-08;
2016-09-08
杨杰 jieyang509@163.com
国家自然科学基金(51479159)
The National Natural Science Foundation of China (51479159)
吴正平: 男,1978年生,博士生,研究方向为数字图像处理、计算机视觉等.
杨 杰: 女,1961年生,博士,教授,博士生导师,主要研究方向为模式识别、机器学习、人工智能等.
崔晓梦: 女,1983年生,博士生,研究方向为大数据处理、模式识别等.
张庆年: 男,1957年生,博士,教授,博士生导师,主要研究方向为交通运输安全管理、交通运输系统优化与决策、物流系统优化与设计等.
猜你喜欢
安阳工学院学报(2020年4期)2020-09-11
学生天地(2020年3期)2020-08-25
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
中国校外教育(下旬)(2017年8期)2017-10-30
自动化学报(2016年3期)2016-08-23
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
