
维吾尔族儿童词汇解码策略的发展特点
2016-09-13 08:03:12买合甫来提坎吉
双语教育研究 2016年1期
买合甫来提·坎吉
(新疆师范大学 教育科学学院,新疆 乌鲁木齐 830054)
维吾尔族儿童词汇解码策略的发展特点
买合甫来提·坎吉
(新疆师范大学 教育科学学院,新疆 乌鲁木齐 830054)
文章以维吾尔语为例,采用朗读真/假单词的任务,通过分析二年级和五年级不同阅读水平的维吾尔族儿童在朗读过程中出现的读音错误类型,考察透明的拼音文字阅读中不同解码策略的发展特点。研究发现,在真/假词的朗读中,不论是读真词还是假词,假词错误显然多于真词错误;读真词时的错误类型受到了阅读水平和年级的影响,表现为二年级和低水平的被试“真-假”错误显著多,五年级被试“真-真”错误显著多;假词朗读的错误类型不受阅读水平和年级的影响。从中可以得出以下结论,透明文字——维吾尔文单词识别中,亚词汇水平的语音解码策略是阅读中最基本的策略,而随着阅读水平的提高会发展出词汇水平的正字法加工策略,即不同水平之间的差异主要表现在不同解码策略的使用上。文章据此提出了关于维吾尔文读写学习的几点建议。
错误类型;真/假词;维吾尔语;透明文字;解码策略
一、问题的提出
阅读能力是儿童必须习得的一种基本能力。如果儿童不能有效掌握阅读,随后很可能导致行为、社会、学业和心理上的困难。[1]我们用文字记录语言,世界上不同文字之间的差异比语言之间的差异还要大。不同文字与其所记录的语音的关系不同,学习者的阅读过程也不同。
有效的词汇是识别阅读最好的基础。词汇通达的双通道模型认为单词识别有两条途径,一是直接的词典通路(lexical route),即词的视觉输入直接激活心理词典中的字形表征,字形表征的激活传输到语音表征,也可以通过词形表征到达语义表征系统再激活语音表征。由于这条通路要经过心理词典中与单词相关的各个表征系统,因此被称为词典通路;另一条是非词典通路(nonlexical route),即通过词典外的形-音转换规则(grapheme-to-phoneme correspondence,简称GPC),从亚词汇建构语音,这一通路不需要借助心理词典的信息,因此被称为非词典通路。[2]正字法深度理论[3]中提出,阅读者如何使用两个主要的词汇识别通路,即词汇和亚词汇是由所学习的文字正字法的深度决定的。根据正字法深度不同,可将文字分为透明文字,即浅层正字法文字;不透明文字,即深层正字法文字。①在透明文字中,字母和读音之间具有直接而明确的匹配关系、具有由形知音的特点,阅读者会更多依靠语音或非词汇通路,亦称之为语音解码策略。在不透明文字中,字母和读音之间明确的匹配关系很弱时,对语音通路的依赖相对少,而更多的依靠词汇或正字法的通路,亦称之为正字法加工策略。而最近,逐渐趋同一致的观点[4]认为,所有的语言中,词典通路中同时使用正字法和语音信息的加工,两者在单词识别过程中会发生交互作用,而涉及这两个通道加工过程的程度以及它们之间的交互作用会受不同正字法深度的影响。
词汇识别相关的联结主义模型,即并行分布加工的神经网络模型 (parallel distributed processing model,简称PDP),假设单词的正字法、语音和语义等信息采用代码的形式分布表征,而没有词汇与亚词汇信息的等级结构的区分。不同代码表征之间是以隐单元为中介相互作用的,词汇的有效识别由各种代码联结的权重决定的。[5]根据联结主义模型,字形表征和语音表征有很强的联结,才能够实现迅速有效的将视觉输入语音表征的匹配,才能成功地进行词汇的有效识别。佩尔费蒂(Perfetti)提出,发展自动而有效的视觉词汇识别的核心是增加正字法和语音之间联结的精确性和冗余性。其中精确性是指正字法和语音表征之间的正确匹配,冗余性是指正字法和语音形式之间在词汇和亚词汇水平上联接的程度。[6]
其实以上两种理论模型并不矛盾。研究者提出正字法和语音表征之间的联结包括不同水平的联结,如音素:字母-音位联结;可视词:整词读音和词义联结;单词家族:字符串和音节/韵律联结,所以在阅读中会存在不同的解码策略。有效的联结越多,词汇识别越好。[7]由此可知,由于阅读者不同表征之间的联结牢固程度不同,在阅读中具体使用的解码策略也不同。
儿童阅读发展阶段理论[8][9]一般认为儿童的阅读最初处于表意符阶段(logographic phase),儿童依赖字母和单词的视觉特征与语音进行机械的联结;儿童学习了字母和字母-发音(lettersound)的知识后,阅读开始向语音阶段(phonological phase)过度,儿童利用字素-音位对应知识来解码遇到新的单词,这个阶段儿童的阅读能力得到了极大的促进;最后儿童的阅读过渡到正字法阶段(orthographical phase),单词的正字法模式在心理词典中已经形成,儿童从正字法可以直接激活语音和意义,不再需要语音译码(recoding)的过程。
由此可见,儿童的阅读,不仅与其阅读的文字特点有关,也与其阅读能力发展水平有关。中国少数民族文字之一的维吾尔文字是一种字母文字,书写方向从右到左,而且在正字法深度上是一种完全规则化的透明文字,[10]既不同于英语等其它拼音文字,又不同于汉字,其透明性与国外塞尔维亚-克罗西亚语等透明文字有一定的相似之处,但又有其独特的特点。可见,维吾尔文字的这种独特性为探讨人类语言文字加工心理机制的跨文字一致性和特异性特点提供了非常好的研究空间。尤其是,其正字法的透明性特点,为正字法深度对阅读策略影响的研究提供了非常好的机会。
目前,在心理语言学研究领域,有关文字阅读中的词汇识别方面的研究通常采用的方法为问卷法和实验法,通过这两种方法可以间接地推测儿童词汇识别过程,但是这种研究有时可能与实际阅读有一些差别,研究的外在效度会有一定的局限性。在自然朗读过程中,儿童会犯各种错误,阅读水平低的儿童更是如此。而且儿童在朗读过程中出现的错误不是随机的,会有一定的规律性,因此,可以从这些规律反映出儿童词汇识别的机制和心理词典的特点,同时,也反映出其朗读过程中采用的词汇识别策略及所遇到的困难等。在以往研究[11]中发现,在不同正字法中不仅阅读正确率不同,其错误类型也不同。鉴于此,本研究认为,试图采取作业分析的定量和定性研究方法,通过分析维吾尔语小学儿童朗读单词中的读音错误类型,探讨他们在读音过程中所采用的策略,从而进一步揭示词汇解码过程中的认知特点。
二、研究方法
(一)被试
抽取乌鲁木齐市某小学二年级学生28名和五年级学生35名,共计63名维吾尔族学生,要求语文教师根据研究者所提供的关于阅读速度和正确性两个方面的标准,将每个学生阅读发展水平评定为高、中、低三个等级。为了使评估更为客观,教师的评估和每个班上最近一次的语文期末考试成绩相结合,最后再确定每一个学生阅读水平的等级(见表1)。
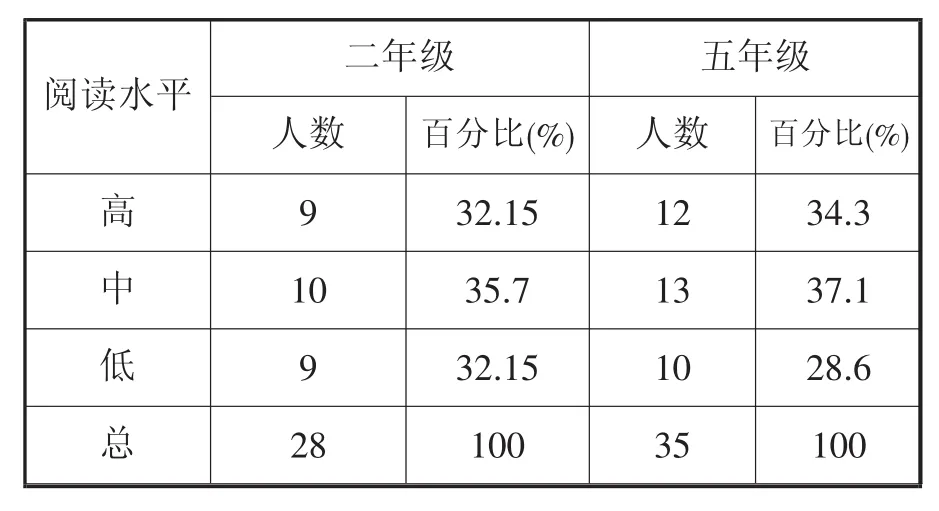
表1 不同阅读水平的被试分布
(二)测试材料
所用的材料是选自小学维吾尔文教材的72个维吾尔语单词,称之为真词和24个用维吾尔文字母制造的,符合维吾尔文字拼写规则,但是在维吾尔语中并不存在的词,称之为假词,共计96个单词。为了保证材料的代表性,真词包括不同频率、不同长度、不同类型,即实词或虚词等。其中高频词频率高于0.04,即每24 000词中出现次数超过1 000次,低频词频率低于0.0004,即每24 000词中出现次数少于10次;②短词为1-2个音节的词,长词为4-7个音节的词。将这些单词分为8组,每组为12个单词,分别印在8张卡片上。
(三)测试程序
个别进行单词朗读测试,主试每次随机抽取一张卡片呈现给儿童,要求读出上面的12个单词,主试将被试的读音和是否正确记录在记录卡片上,之后再出示第二张卡片,直至出示完8张卡片为止。
三、结果与分析
当错误为真词,即读音为原词的口语化发音或和原词不同的另一真词,我们称之为真词错误;当错误为假词,即读音不正确,而且读成维吾尔语中不存在即没有任何意义的词,称之为假词错误。这种错误分类在某种程度上能反映单词识别中语音解码策略和正字法加工策略的使用情况。因此,我们对真词和假词朗读中曾出现的错误类型按照以上分类进行了编码,其中读音为真词错误有两种:真词的读音为其它真词的错误编码为“真-真”错误和假词读音为真词错误为“假-真”错误;读音为假词错误也有两种:真词读音为假词错误为“真-假”错误和假词读音为假词错误为“假-假”错误。不同年级、不同水平的被试,分别在朗读真词和假词时,真词错误和假词错误的平均发生率如下所示(见表2、图1)。

表2 不同年级、不同水平的被试不同类型错误的平均发生率
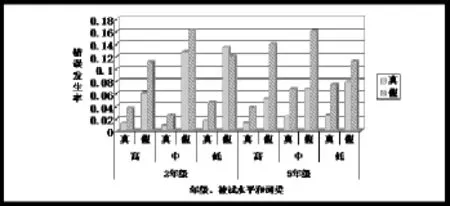
图1 不同年级、不同水平的被试不同类型的错误平均发生率
分别对真词朗读和假词朗读中的真词错误和假词错误的发生比率进行了错误类型为被试内因素,阅读水平和年级为被试间因素的混合设计方差分析,结果如下:
真词朗读中假词错误显著多于真词错误,即F(1,56)=83.059,p<0.001,而这两种错误类型和阅读水平的交互作用边缘显著,即F(2,56)= 3.002,p=.058,错误类型和年级的交互作用显著,即F(2,56)=10.405,p<0.01。简单效应分析表明,在各个水平上“真-假”错误都显著多于“真-真”错误,但“真-真”错误率上不同水平之间没有显著差异,即F(2,59)=1.05,p>0.1,而“真-假”错误上差异边缘显著,即F(2,59)= 2.90,p=.063,即低水平的被试“真-假”错误更多。在这两个年级中“真-假”错误发生率都显著高于“真-真”错误,其中二年级:F(1,60)=66.04,p<0.001;五年级:F(1,60)=17.71,p<0.001,而且年级之间的差异在“真-真”错误中边缘显著,即F(1,60)=3.58,p=.063,在“真-假”错误中显著,即F(1,60)=6.26,p<0.05。
假词朗读中,同样假词错误显著多于真词错误,即F(1,55)=31.654,p<0.001,而且错误类型和阅读水平,即F(1,55)=.935,p>0.1以及错误类型和年级交互作用,即F(1,55)=.125,p>0.1都不显著。
四、综合讨论
真/假词错误类型分析结果显示:总体上不仅读假词时假词错误多,而且读真词时假词错误也多,说明大部分错误发生在亚词汇水平的语音解码过程中,即表明了维吾尔语单词朗读过程中亚词汇水平的语音解码策略占主导地位,这和以往其它透明文字研究结果一致。如斯潘塞(Spencer)和汉利(Hanley)[12]对儿童在正字法深度不同的威尔士语和英语中,阅读真/假词时的错误类型进行比较发现,不仅在这两种语言的阅读正确率上而且阅读策略上也存在差异:英语中以其它真词替代的错误显著多,威尔士语中语音,即假词错误更多。塞尔维亚-克罗西亚语也是一个字音与字形之间的匹配关系,即一一对应的透明文字。对此文字的研究结果表明,无论阅读者是儿童还是成人,语音解码策略在阅读中起十分重要的作用。[13]
本研究进一步分析语音解码策略在不同阅读水平和年级发展中的表现,读假词时,“假-真”和“假-假”错误的发生不受阅读水平和年级的影响,说明不论阅读者处于何种阅读水平与年级,儿童阅读假词时均使用同样的策略,这是因为在假词阅读中,由于词典中不存在相应的正字法表征,只能使用亚词汇水平的语音解码策略,即GPC规则;读真词时,“真-真”和“真-假”这两种错误的发生受阅读水平和年级影响:不同阅读水平之间只有“真-假”错误上出现了差异。其中低水平被试的“真-假”错误显著多于高水平的被试,说明水平低的被试读真词时,比高水平的被试更多的依赖语音解码策略;五年级的“真-真”错误显著多于二年级,二年级的真-假错误非常显著的多于五年级,这又进一步支持了在低年级儿童主要依赖亚词汇水平的语音解码策略,到了高年级逐渐发展出词汇水平的正字法加工策略。
目前,虽然研究者一致承认使用字素-音素转换规则的语音解码技能是拼音文字阅读能力发展的基础,但阅读获得并不只局限于这种策略。儿童最初学习阅读时,更多的使用这种语音解码策略,但是就像内申(Nation)和斯诺(Snowling)[14]强调儿童为了成为流畅阅读者需要发展出词汇阅读,即通过心理词典的联结和整词的激活直接获取一组字符串的读音。巴贝多(Badian)[15]提出,儿童一旦掌握最基本的语音解码技能以后,语音意识在阅读中的作用会逐渐变小,而正字法的作用变得越来越重要。正字法系统可以表征语言的几个水平而字母只代表语言的音素-字素。有效的单词识别并不依赖于单独字母的识别。沙雷(Share)[16]也提出了阅读发展的自我教学(self-teaching)假设,认为儿童所具有的音位意识和字母声音的知识让他可以运用字素-音位对应的语音解码策略来拼出新单词的发音,这提供了一个自我教学机制。每一次成功的解码都为获得特定单词的正字法信息提供了一个机会。多次成功解码的项目,即高频词可以快速地在心理词典中建立起正字法表征,从而可以进行视觉识别即发展出正字法加工策略,即使是在阅读获得的最初阶段。对于不熟悉的项目儿童仍然没有建立起牢固的正字法表征,识别时将更加依赖语音译码。总之,本研究结果表明,我们认为维吾尔语阅读中亚词汇水平的语音译码策略始终非常重要,这也是维吾尔语作为透明文字,其词汇识别策略与英语和汉语等不透明文字的不同之处。但是,为了更快速、有效地阅读,儿童还是需要发展出词汇阅读策略,即儿童词汇识别策略的发展会表现出从语音加工向正字法加工发展的趋势,这又是与其他拼音文字相似之处。
五、对策与建议
经过以上分析,我们有理由认为,在具有完全透明正字法的维吾尔文字阅读中,词汇识别能力获得和发展中,亚词汇水平的语音解码策略是阅读中最基本的策略,而随着阅读水平的提高会发展出更有效的词汇水平的正字法加工策略。
由于不同年级、不同水平的儿童其阅读策略的发展特点不同,这就要求在实际教学中要根据儿童的年龄和阅读水平特点进行有针对性的教学。首先,维吾尔语初学者或低水平读写者,主要依赖于亚词汇水平上的语音解码,因此在教学中要注重语音意识的训练,具体操作的话,要引导初学者或低水平者对词形进行语音解剖,即分成若干首音-韵脚、音节、音位等亚词汇部分,并且通过其语音和相应的书写符号的匹配训练,以加强亚词汇水平的形-音联结。在此过程中同时注意强化字形中的弱刺激点,可用彩色笔标出或言语提醒。其次,随着阅读经验的增长,儿童通过对词汇的解码次数的增加而逐步建立和巩固词汇水平的形-音联结,即整词和读音之间的联系,由此逐渐过渡到正字法阶段,而且这又是快速、有效阅读的前提。因此,为了提高儿童的阅读能力,应鼓励和指导儿童进行大量阅读。最后,对于阅读困难的儿童,首先要分析其困难发生在哪一个水平上,即是亚词汇水平的语音解码有困难还是整词水平的正字法加工有困难,然后加强相应的能力训练。
注释:
①Frost,R.&Kartz,L.&Bentin,R.S.Strategies for visual word recognition and orthographical depth:A multilingual comparison[J].Journal of Experimental Psychology:Human Perception and Performance,1987,(1):104-114.
②根据玉素甫·艾白都拉等建立的维吾尔语语料库中的词频统计。此语料库的建立受国家自然科学基金(项目编号60163002,60463005)、新加坡《中文与东方语言信息处理学会》《国家教委留学基金》和《新疆维吾尔自治区科技厅少数民族特培人员启动资金》等项目的资助,尚未公开发表。
[1]Anthony,J.L.&Lonigan,C.J.The nature of phonological awareness:converging evidence form four studies of preschool and early grade school children[J].J ournal of Educational Psychology,2004,(1):43-55.
[2]Coltheart,et al.DRC.A dual route cascaded model of visual word recognition and reading aloud[J].Psychological Review,2001,(1):204-256.
[3]Frost,R.&Kartz,L.&Bentin,R.S.Strategies for visual word recognition and Orthographical depth:A multilingual comparison[J].Journal of Experimental Psychology:Human Perception and Performance,1987,(1):104-114.
[4]Seymour,P.H.K.&Aro,M.&Erskine,J.M.Foundation literacy acquisition in European orthographies[J].British Journal of Psychology,2003,(2):143-174.
[5]Seidenberg,M.S.&McClelland,J.L.A distributed,developmental model of word recognition and naming[J]. Psychological Review,1989,(1):523-568.
[6]Perfetti,C.A.&Bell,L.Phonemic activation during the first 40ms of word identification:Evidence from backward masking and priming[J].Journal of Memory and Language,1991,(4):473-485.
[7]Berninger,V.W.Multiple orthographic codes:Key to alternative instructional methodologies for developing the orthographical connections underlying word identification [M].School Psychology Review,1990,(4):518-533.
[8]Frith,U.Beneath the surface of developmental dyslexia [A].In:K.Patterson,J.Marshall&M.Coltheart(Eds.),Surface dyslexia[C].London:Erlbaum,1985:301-330.
[9]Ehri,L.C.Phases of development in learning to read words by sight[J].Journal of Research in Reading,1992,(2):116-125.
[10]买合甫来提·坎吉,刘翔平,张微.维吾尔语发展性阅读障碍儿童的高频词词典通达[J].心理科学,2011,(5):1124-1129.
[11]Cossu,G.&Gugliotta,M.&Marshall,J.C.Acquisition of reading and writing spelling in a transparent orthography:Two parallel processes?[J].Reading and Writing, 1995,(1):9-22.
[12]Spencer,H.L.&Hanley,R.Effects of orthographic transparency on reading and phoneme awareness in children learning to read in Wales[J].British Journal of Psychology,2003,(1):1-28.
[13]Coltheart V,Laxon V,Richard M,Elton C.Phonological recording in reading for meaning by adults and childen[J].Journal of Experimental Psychology:Learning,Memory and Cognition,1988,(3):387-397.
[14]Nation,K.&Snowling,M.J.Beyondphonological skills:broader language skills contribute to the development of reading[J].Journal of Research in Reading,2004,(4):342-356.
[15]Badian,N.A.Predicting reading ability over the long term:The changing role of letter-naming,phonological awareness and orthographic processing[J].Annals of Dysl-exia,1995,(1):79-96.
[16]Share,D.L.Phonological recoding and self-teaching:sine qua non of reading acquisition[J].Cognition,1995,(2):151-218.
[责任编辑]:张兴
A Study on the Development of Uyghur Children's Lexical Decoding Strategies
Mahpiret·Kanji
(College of Education Science,Xinjiang Normal University,Urumqi Xinjiang 830054)
By analyzing the error types of word and pseudoword reading among Uyghur pupils on different reading levels (Grade 2 and Grade 5),this paper studies the development characteristics of children's decoding strategies in reading transparent scripts.The results are as follows:there are much more errors in students'reading pseuodowords than in their reading real words;the error types in reading real words vary with children's reading levels or grades,i.e.,much more"truefalse"errors among students in Grade 2 or on lower reading levels,and much more"true-true"errors among those in Grade 5 or on higher reading levels;the error types in reading pseuodowords are irrelevant to children's reading levels or grades.It is concluded that,on the sub-lexical level,the phonological decoding strategyis the basic one in reading scripts of a transparent language like Uyghur,and the orthographical strategy is developed with the improvement of a child's reading skills.Based on the above results,the author puts forward some suggestions for the learning of Uyghur reading and writing.
Types of errors;Word/pseudoword;Uyghur language;Transparent script;Decoding strategies
H215
A
2095-6967(2016)01-020-06
2015-11-19
本文系国家社会科学基金一般项目“维吾尔语发展性阅读障碍认知机制及其干预研究”(08BYY024);新疆师范大学博士科研启动基金项目(XJNUBS1109)的阶段性成果。
买合甫来提·坎吉,新疆师范大学教育科学学院教授,博士生导师。
猜你喜欢
中国石油石化(2022年12期)2022-07-16 08:28:28
小天使·一年级语数英综合(2022年2期)2022-03-30 16:18:14
中国外汇(2019年19期)2019-11-26 00:57:32
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
小说界(2018年5期)2018-11-26 12:43:42
人生十六七(2015年29期)2015-02-28 13:09:01
