
基于HBase的飞参数据存储技术
2016-09-01 01:32:31张家叶子范纯龙丁国辉
沈阳航空航天大学学报 2016年3期
吕 游,管 林,张家叶子,范纯龙,丁国辉
(1. 沈阳航空航天大学 计算机学院,沈阳 110136; 2. 沈阳飞机设计研究所 网络信息中心,沈阳 110035;3. 92941部队 96分队,辽宁 葫芦岛 125000; 4. 91899部队 机务大队,辽宁 葫芦岛 125000)
基于HBase的飞参数据存储技术
吕游1,4,管林2,张家叶子3,范纯龙1,丁国辉1
(1. 沈阳航空航天大学 计算机学院,沈阳 110136; 2. 沈阳飞机设计研究所 网络信息中心,沈阳 110035;3. 92941部队 96分队,辽宁 葫芦岛 125000; 4. 91899部队 机务大队,辽宁 葫芦岛 125000)
随着数据记录技术的发展,飞参文件记录的信号数量和信号记录密度都在快速增长,飞参数据记录总量的快速增加促使故障分析等方面的飞参数据分析需求更加多元和迫切。传统的飞参数据处理方法以文件为单位,无法对跨文件的联合分析和特定信号集的分析提供有效的支持。针对飞参文件中数据存储和使用的局限,提出一个基于HBase数据库的分布式存储架构,将飞参文件中的数据依据飞行参数存储到HBase数据库中,实现了对飞行信号数据的列存储和对扩展检索需求的良好支持。实验结果表明,该种存储方法大大加快了面向飞行参数的数据访问效率,对飞参数据的综合利用提供了存储管理上的有益参考。
飞参文件;飞行信号;HBase;分布式存储
飞机每个架次的飞行都会由飞参数据记录系统对飞行过程中产生的各种数据进行记录,形成飞行数据记录文件,简称为飞参文件,其中的数据称为飞参数据。飞参数据在飞机研制、故障诊断及飞行品质评价等方面起到了重要作用[1]。随着数据记录技术的发展,飞参文件中记录的飞参数据信号数量超过1 000个,同时信号的记录密度也在增加,最大的单个飞参文件已经超过200 MB,并且还在快速增长中。传统的飞参数据处理方法以文件为单位,虽然不同的问题分析中关注的通常是少量的不同技术参数,但数据处理过程却需要对整个文件进行读取,而对多架次飞参数据的联合筛选和分析效率就更低了。
为了提高飞参数据的访问和处理效率,本文结合现有飞参数据的特点,设计了一种基于HBase的飞参数据存储结构,实现用HBase非关系型数据库存储飞参数据,将飞参数据按照参数重新组织,将飞参文件中一个参数的所有数据组织成HBase数据库中的一条行记录,实现了飞参数据的列存储模式,解决了传统飞参数据分析中面临的访问效率问题,并为大规模飞参数据的联合分析提供了技术支撑。列存储技术在很大程度上减少了参数数据分析时的读入数据量,使得系统的查询效率得到提高[2]。本文中采用部分飞参数据验证了设计的可行性。
1 背景介绍
1.1HBase的列存储架构
HBase是一个面向列的分布式数据库,作为非关系型数据库的一种,它不同于传统的关系型数据库[3-4]。HBase表由行和列组成,行列坐标交叉点是表的单元格,为一个有版本号的未解释的字节数组,版本号默认为单元格插入时的时间戳(Time Stamp)。HBase把表横切成不同的区域(region),每个区域包含表的一个行子集。行中的列被分组成若干列簇(column families),所有的簇成员都有相同的簇前缀,簇成员间通过标识符(qualifier)区分,因此,每列表示为column family:qualifier。
HBase中的数据存储在Hadoop文件系统HDFS中,HBase由HMaeter服务节点和HRegionServer存储节点组成,HMaster本身并不存储HBase中的数据,它主要负责管理所有的HRegionServer节点。HBase逻辑上的一个表被定义成为一个Region存储在某一台HRegionServer上,HRegionServer负责支持多个Region向客户端提供服务[5-6]。
HBase的基本模式结构是表,由RowKey、列族、Timestamp(时间版本)形成一个三维有序的结构,通过三个维度坐标准确定位数据。HBase与关系数据库(RDBMS)相比,更适合非结构化数据的存储和管理,在实际系统中,HBase也可以与关系数据库配合使用,兼顾二者的优点。HBase将所有数据都以字节串的形式存储,没有丰富的数据类型,数据存储按照RowKey的字典序排列,对Rowkey的设计提出了较高要求。HBase是基于列存储的,在物理存储中,不同的列族数据存储在不同的文件中,另外,HBase系统可以在节点内任意增加存储设备和节点,提高系统的灵活性和扩展性[10-12]。
1.2 飞参数据文件
记录技术、计算机技术及现代测控技术的发展,促使飞参数据记录系统能够记录的飞参数据量显著增加,这种数据量增加既包括记录参数数量的增加,也包括每个信号参数记录密度的增大。在四代机中,飞参数据里记录的参数数量接近1 000个,参数的记录密度最高的达到1 kHz,部分参数的记录密度与地面试验环境中的记录密度相当。这些都促使飞参数据的后期应用需求更加多元化,如故障分析、放飞审查、飞行品质评价和新机预研等。因此,利用飞参数据管理系统实现对飞参数据的有效管理,积累飞参数据资源,最大限度地发掘飞参中的有效信息,对飞机的研制和使用意义深远[7-9]。
飞参数据记录系统记录飞参生成的飞参文件一般包括文件头和数据区两部分,文件头主要由飞机及飞行相关的信息构成,包括机型、出厂编号、起始记录时间等属性描述信息;数据区是一个行记录集,每行记录代表特定时刻所有飞参参数的信号值。另外,每个飞行参数在数据类型、取值范围和精度等方面存在差别,因此行记录中信号值的排列由预定义的顺序决定。在新型飞机中,每个飞行小时产生的飞参文件规模增量约为100 MB。
传统飞参数据管理软件利用飞参文件检索数据的形势主要有两种:(1)将飞参文件作为访问单位,通过直接读取飞参文件来检索所需的目标数据,对于获取特定参数的所有数据值等操作经常需要遍历整个文件,并且无法快速满足对各参数值的灵活访问需求;(2)将飞参文件的内容存储到关系型数据库中,飞参文件数据区中的行记录转成关系数据库表中的行记录,实现对多个飞参文件中飞参数据的集中管理,对于获取特定参数的所有数据值等操作的处理形式简化了,但效率没有本质改善。
2 系统实现
2.1存储表结构设计
HBase分布式数据库中的持久化数据是以HFile文件形式存储在HDFS文件系统中的,在HFile文件中数据按RowKey有序排列。因此,HBase的表结构设计中RowKey设计是非常重要的,需要根据预期的访问和检索模式来为RowKey建模。
飞参文件在使用中,以对一个或多个飞行参数的值序列进行分析为主要需求,本文设计了一个基于HBase的飞参数据的列存储结构,利用HBase数据库将飞参文件中的行记录存储方式转换为面向参数值序列的列存储方式,从而提高飞参数据的检索效率。
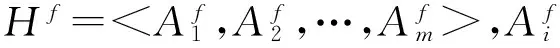
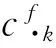
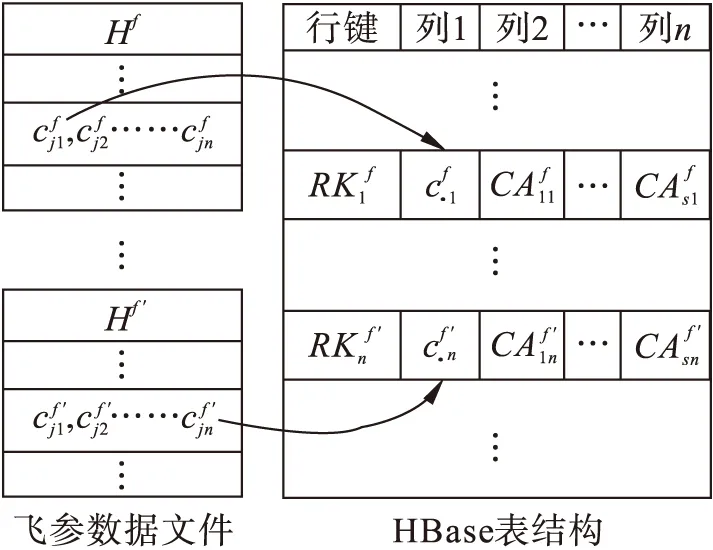
图1 HBase表结构设计
设HBase中飞参表的行结构模式为公式:
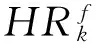
2.2飞参数据写入过程
本文先将飞参数据文件集上传到分布式文件系统HDFS中,然后对飞参文件进行预处理,将文件头和数据行记录分离,文件头部分按图1选择信息组成行键RowKey,行记录数据按参数分离,并调用函数处理各参数数据生成各参数的关联属性,与数据值共同组成表中各列数据——Value。通过Map过程将上述处理过的数据导入到分布式数据库HBase,导入时HBase会自动判断行键唯一性,如有重复行键则更新原有数据。在HBase中所谓更新就是新增数据版本,并不删除原有数据,这种保留历史数据的方法有利于分析过往飞参数据,其入库流程如图2所示。
3 实验环境及实验结果
3.1试验参数信息
实验环境:两台台式主机(CPU:inteli-5 3470,4GB内存)构成集群,虚拟机使用VirtualBox4.3.6,系统采用Ubuntu11.04。一台主机运行虚拟机master(单核,2GB内存),另一台主机运行两个虚拟机slave节点(单核,1GB内存)。Hadoop版本2.4.0,Hbase版本0.98.1,Zookeeper版本3.4.6,JDK版本1.7.0,网络属局域网,带宽100Mb/s。
实验数据使用飞机GPS传感器传回的连续时序数据,共60 600 209条记录;数据以ASCII文本表示,以逗号为分隔符,以回车换行符(0x0D0x0A)结尾。
3.2实验结果
为验证HBase分布式数据库的存储和查询效率以及可扩展性,本文使用共60 600 209条数据,分别存储在3 000个文件中,比较了通过C语言程序直接读取文件、MySQL关系型数据库和HBase集群三种解决方案的写入和读取效率。
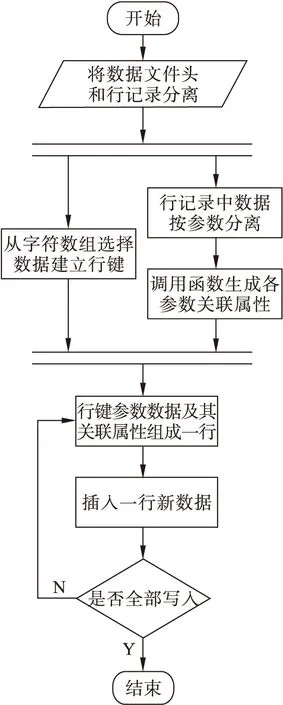
图2 数据入库流程图
图3对比了直接读取文件方式、MySQL数据库和HBase集群与数据规模的写入时间。从图3中可以看出,由于直接读取文件方法其入库时间只记为文件拷贝时间,所以时间比较固定,HBase集群写入时间明显低于MySQL关系型数据库,并且随文件量增大写入时间差距也随之变大。
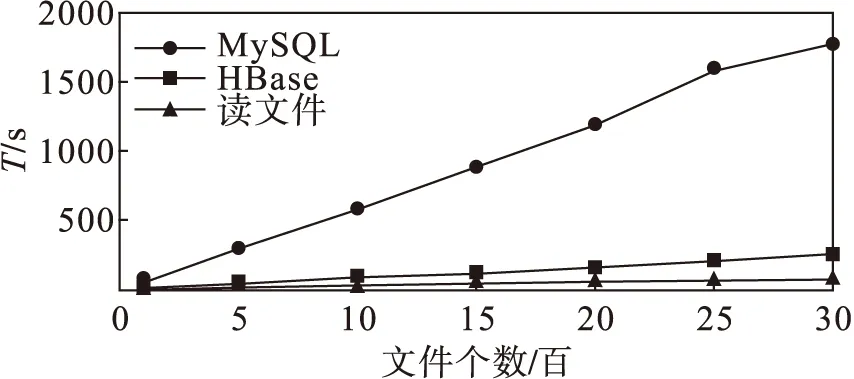
图3 数据量与写入时间关系对比
图4比较了直接读取文件方式、MySQL数据库和HBase集群在获取指定参数所有架次全部数据的效率对比。通过实验对比,3种方法查询时间均与数据规模呈正比关系,直接读取文件方式需要遍历所有目标文件,并且进行全文件扫描,获取飞参数据文件中指定参数的行记录。MySQL关系型数据库通过使用Select语句进行查询,仍要遍历整个数据表。由于本文的HBase存储结构设计将参数写入行键,所以可以通过行键直接筛选参数避免了全表扫描。在数据列获取过程中,利用HBase的列过滤器,可以避免读入不需要的列数据以提高效率。综上得出结论:HBase集群读取效率明显高于传统方法,具有高效的读写性能。
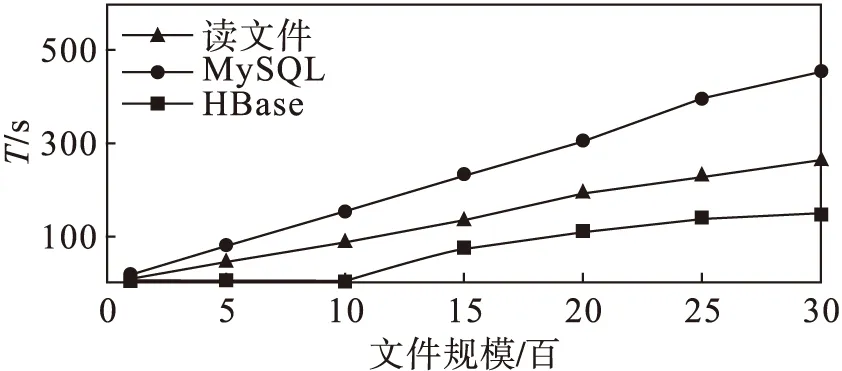
图4 数据量与读取时间关系对比
4 结论
本文针对目前飞参数据分析软件在分析飞参数据文件面临的访问效率低,管理不便的问题,提出了一种基于HBase数据库的面向飞行参数值序列的飞参数据列存储方案。根据HBase数据库的特点设计并实现了适合飞参数据使用的存储模型,解决了传统处理方法无法高效分离数据属性的问题,提高了存储效率和检索速度。实验验证了该方案的可行性,在入库和查询方面都能够提供更加高效的处理结果,该方案对大规模试验数据处理尤其是快速增长的飞参数据处理需求具有重要的理论价值和实用价值。对于HBase数据库与关系数据库联合使用,对飞参数据处理中的架次、飞行参数基本属性和索引等可结构化数据利用关系数据库管理,对飞行参数值序列及其不确定的衍生属性用HBase进行管理,从而更好的实现对飞参数据的管理和分析工作,将是下一步研究的工作。
[1]曲建岭,唐昌盛,李万泉.飞参数据的应用研究现状及发展趋势[J].计测技术,2007,27(6):1-4.
[2]IDREOS S,KERSTEN M L,MANEGOLDS.Self-organizing Tuple Reconstruction in Column-Stores[C].ACM SIGMOD International Conference on Management of Data.ACM,2009.
[3]STONEBRAKER M.SQL databases v.NoSQL databases[J].Communications of the ACM,2010,53(4):10-11.
[4]GHEMAWAT S,GOBIOFF H,LEUNG S T.The Google File System[C].In Proceedings of the 19th ACM Symposium on Operating System Principles,2003.
[5]Lars George.HBase权威指南[M].代志远,刘佳,蒋杰,译.北京:人民邮电出版社,2013:303-304.
[6]The Apache Software Foundation.Apache ZooKeeper[EB/OL].2010.http://zookeeper.apache.org/.
[7]丁建新,樊江滨,郭强,等.全周期试验数据管理系统研究[J].车辆与动力技术,2010(3):4-9.
[8]唐宗凯,曲建岭,高峰.飞参判据及其应用[J].计算机工程,2011(5):281-283.
[9]李洪奇.试验数据管理系统的应用[J].软件工程师,2010,26(4):43-44.
[10]DUTTA H,KAMIL A,POOLERY M,et al.Distributed storage of large-scale multidimensional electroencephalogram data using Hadoop and HBase [M] Grid and Cloud Database Management.Berlin:Springer,2011.
[11]The Apache Software Foundation.Apache HBase[EB/OL].2015.http://hbase.apache.org/.
[12]The Apache Software Foundation.Apache Hadoop[EB/OL].2015.http://hadoop.apache.org/.
[13]BAI J W,WANG J Z,HUANG J L.Spatial query processing on distributed databases[M].Advances in Intelligent Systems and Applicantions-Volume 1,Springer Berlin He idelberg,2013.
[14]Vamshi Krishna Konishetty,K Arun Kumar,Kaladhar Voruganti,and GV Rao.Implementation and evaluation of scalable data structure over hbase[C].International Conference on Advances in Computing,Communications and Informatics,2012.
[15]陈庆奎,周利珍.基于HBase的大规模无线传感网络数据存储系统[J].计算机应用,2012,32(7):1920-1923.
(责任编辑:吴萍英文审校:赵亮)
Flight data storage technology based on HBase
LV You1,4,GUAN Lin2,ZHANGJIA Ye-zi3,FAN Chun-long1,DING Guo-hui1
(1.College of Computer Science,Shenyang Aerospace University,Shenyang 110136,China;2.Network Information Center,Shenyang Aircraft Design and Research Institute,Shenyang 110035,China;3.96 Unit,92941 Troops,Huludao 125000,China;4.Locomotive Brigade,91899 Troops,Huludao 125000,China)
With the development of data recording technology,the number of signals and the signal recording density of flight data files are growing rapidly.The rapid increase of the total amount of the flight file data prompts the requirement of flight data analysis,such as failure analysis,more diverse and urgent.Since the traditional method of processing flight file data is based on file units,it could not provide effective support for the conjoint analysis across file and the specific signals set analysis.In this paper,a distributed storage architecture based HBase database was proposed.The parameters based flight file data were stored into the HBase database,where a good support for the flight signal data columns-storage and retrieval extension was achieved.Experimental results prove that this kind of storage method accelerates the data access efficiency for the parameters of flight data file,and provides a useful reference for flight data on the utilization of storage management.
flight data file;flight signal;HBase;distributed storage
2095-1248(2016)03-0079-05
2015-10-28
国家自然科学基金青年基金(项目编号:61303016)
吕游(1988-),男,黑龙江嫩江人,硕士研究生,主要研究方向:网络信息安全,E-mail:lv_you@foxmail.com;管林(1962-),男,辽宁沈阳人,高级工程师,主要研究方向:工程数据管理,E-mail:415628038@qq.com。
TP391.7
A
10.3969/j.issn.2095-1248.2016.03.013
猜你喜欢
甘肃教育(2020年14期)2020-09-11 07:57:42
中学生数理化(高中版.高考数学)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
财经(2017年15期)2017-07-03 22:40:49
财经(2017年2期)2017-03-10 14:35:35
财经(2016年15期)2016-06-03 07:38:02
财经(2016年3期)2016-03-07 07:44:46
财经(2016年6期)2016-02-24 07:41:51
时代英语·高二(2015年1期)2015-03-16 00:08:11
中国卫生(2014年11期)2014-11-12 13:11:32
