
基于用户反馈的统计机器翻译短语表优化方法
2016-09-01 01:32:26尹瑞程蔡东风
沈阳航空航天大学学报 2016年3期
尹瑞程,叶 娜,蔡东风
(沈阳航空航天大学 人机智能研究中心,沈阳 110136)
基于用户反馈的统计机器翻译短语表优化方法
尹瑞程,叶娜,蔡东风
(沈阳航空航天大学 人机智能研究中心,沈阳 110136)
近年来,统计机器翻译技术取得了长足进展,然而在译文质量要求较高的领域,机器翻译系统产生的译文仍不够理想。随着计算机辅助翻译和交互式机器翻译技术的出现,研究人员开始利用用户反馈,从中学习翻译知识,对翻译系统的各项参数进行优化。由于不同用户的翻译经验不同,所以他们反馈翻译知识的置信度也不同。通过分析影响用户置信度的特征,得到用户置信度评价模型,并利用该模型将不同用户反馈的翻译知识进行区分,实时调整更新短语表的参数。修改的参数包括正向短语翻译概率、正向词汇化翻译概率、逆向短语翻译概率、逆向词汇化翻译概率。实验结果表明,对不同用户反馈的翻译知识进行区分,改进短语表的参数,得到的译文质量比不区分用户得到的译文质量更好。
统计机器翻译;用户反馈;用户置信度;短语表;参数优化
目前,统计机器翻译技术取得了长足进展,然而在译文质量要求较高的领域(例如技术出版物或专利翻译等),翻译系统产生的译文仍不够理想。在这样的应用背景下,大部分的机器翻译系统仍然采用译后编辑获得高质量的译文。在统计机器翻译方面的研究领域,利用用户反馈的学习方法,对用户进行译后编辑得到的译文进行验证和校改并反馈给系统一直是国内外研究热点。系统对用户反馈的翻译知识充分利用,能有效地修改对数线性模型的各项参数,不断完善翻译系统内的翻译知识体系,提高翻译性能[1]。
由于不同翻译人员的翻译经验不同,擅长的翻译领域不同,导致他们翻译的译文质量也会不同。因此利用用户反馈的翻译知识改进翻译系统的性能时,对不同用户进行区分具有重要意义。
本文通过分析影响用户置信度的因素,引入用户的基本特征和用户的翻译状态特征。用户的基本特征包括用户从事翻译领域的工作时间和在翻译公司的职位等。用户的翻译状态特征包括对一个句子的用户翻译平均时间、用户翻错单词平均数、用户译文校验的平均次数等。根据不同用户的相似度分析,我们设计出用户置信度评价函数。并利用该函数,得到用户置信度评价模型,将不同用户反馈的翻译知识区别对待,重新修改短语表的各项参数,包括正向短语翻译概率、正向词汇化翻译概率、逆向短语翻译概率、逆向词汇化翻译概率等。
为了验证本文提出方法的有效性,在英汉航空技术出版物的语料上进行实验,利用20 000句带有校验人员标注信息的语料,统计出不同用户的翻译状态特征,用以构建用户置信度评价模型。用10万句平行语料,训练出了对应的短语表,每次加入5 000句不同用户反馈的译文,进行优化。实验结果表明,构建用户置信度评价模型,对不同用户反馈的翻译知识区别对待,能够有效提高翻译系统的优化效果。
1 相关工作
目前国内外利用用户反馈改进翻译系统的研究主要集中在两方面:一种是基于规则的方法,另一种是基于机器学习的方法。
基于规则的方法是一种将用户译后编辑的修改作为反馈,以模板或者规则的形式表示翻译知识,修改译文的方法。Guzman[2]等人利用用户译后编辑的信息,人工制定一些规则用以修改译文。Groves[3]等人利用机器翻译生成的译文和译后编辑的结果,记录达到正确译文时需要修改最小编辑距离,从中自动提取规则。该方法能够提高用户译后编辑的工作效率。由于受到规则形式的限制,所以对翻译系统的优化程度有限。
利用机器学习方法改进翻译系统的研究上,Simard[4]等人将译后编辑结果作为目标语言,翻译系统生成的译文为源语言,训练出一个自动译后编辑系统。利用该系统对得到的译文进行再翻译,而该方法对译文的调序错误作用不太明显。Llitjos[5]等人通过实时查找译文中错误的位置,对原机器翻译系统中的规则库和词典进行修改并优化翻译引擎。Martinez[6]等人提出,利用在线学习的技术,对译后编辑的译文进行处理,实时调整和更新统计机器翻译模型的各项参数,如语言模型中的历史计数N1+(*ω)等。通过用户数据的不断加入,实现翻译系统内各项参数的优化。
然而,研究人员利用用户反馈的翻译知识改进翻译系统时,忽略了用户的差异性。不同用户的翻译状态和翻译水平都会有所不同。因此,建立用户置信度评价模型,对不同用户进行区分,可以更好地融合多名用户的翻译知识,提高翻译系统的优化效果。
2 构建用户置信度评价模型
本文挖掘出多个特征用以构建用户置信度评价模型,并将这些特征分成两大类:基础特征和翻译特征。其中基础特征是指用户自身具备的属性,如用户从事翻译工作的时间等。而翻译状态特征是校验人员对不同用户后编辑的结果进行标注的语料中记录的信息,从中统计能够影响用户翻译状态的变量,如翻译一个句子的平均时间等。在本文中我们对这些特征进行分析处理,利用用户置信度的评价函数得到用户置信度评价模型。
2.1特征
(1)用户基础特征
针对用户固有的属性,挖掘出用户的基础特征,包括用户从事翻译工作的时间,用户在翻译公司的职位,可以从翻译公司记录下来的翻译人员的信息获得。
(2)用户的翻译特征
(a)用户翻译平均时间如式(1)所示:
(1)
通过译后编辑语料中记录的信息,得到用户翻译每个句子的起始时间和结束时间,这里Si代表用户翻译当前句子的起始时间,Ei表示翻译该句子的结束时间,n表示该用户翻译句子的总数。
(b)用户翻错单词平均数如式(2)所示:
(2)
通过译后编辑语料中校验人员的批注,统计出用户翻译当前句子中错误单词的个数Ri,以及该用户翻译句子的数目n,最终得到对应某个用户每个句子翻错单词的平均个数。
(c)用户译文校验的平均次数如式(3)所示:
(3)
通过在译后编辑语料中得到某个用户翻译句子时批注人修改的次数Ci,以及该用户翻译句子的数目n,可以得到用户翻译修改次数的平均数。
(d)用户翻译每句错误率的方差如式(4)所示:
(4)
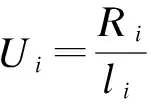
(e)用户的翻译总量
选取标注有用户姓名的大批量语料,该语料记录的是不同用户翻译一个月的总量,得到每个用户翻译句子的总数。利用不同特征向量描述用户翻译状态,对特征向量进行归一化,其中计算公式如式(5)所示:
(5)
在这里,T代表某个用户的某项翻译特征,Min代表所有用户在该对应特征下的最小值,Max代表所有用户在该对应特征下的最大值。此处用于构建用户置信评价模型的用户特征向量如公式(6)所示:
(6)
2.2用户置信度的评价函数
人工选取最好的用户,认为该用户的置信度最高,通过计算该用户与其他用户特征向量的相似度,设置不同用户的置信区间,最终得到用户置信度评价模型,其中用户相似度如式(7)所示:
C(PUseri,PUserj)=cosθ=
(7)
利用该公式得到不同用户的特征向量与人工选定用户的特征向量相似度的计算结果。由于进行译后编辑工作的用户多数都是专业翻译人员,他们反馈的译文质量差别并不是很大,因此我们根据相似度水平,把用户分成三类:相似度在(0.7,1.0]的用户我们设定为A档,是置信度高的用户群体;相似度在(0.3,0.7]的用户设定为B档,是置信度较高的用户群体;而相似度在(0,0.3]的用户为C档,是置信度一般的用户群体。
3 短语表的优化方法
通过用户置信度评价模型得到分类的结果,对不同用户设置不同的权重,优化翻译系统中短语表的各项参数,提高译文质量。
3.1用户权重的设定
通过计算,我们依据置信度将用户分为A、B、C三个用户群体,下一步还需为不同用户群体赋予不同的权重,以表示用户反馈的翻译知识的重要程度。由于用户都是专业翻译人员,总体上反馈的翻译知识都有一定的参考价值,所以将用户权重范围设定在(1,2]之间。通过在开发集上的反复实验,最后将A、B、C三个用户群体的权重系数分别设定为1.8、1.6、1.2。
3.2短语表参数的优化
短语表的质量是影响机器翻译系统性能的重要因素,短语表的获取大多都是建立在双语句对词对齐关系上的,按照一定的规则抽取出短语对。短语表的结构形式如表1所示:

表1 短语表的结构形式
下面将介绍短语表的四个翻译概率的计算及优化方法。
(1)正向短语翻译概率如式(8)所示:
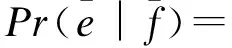
(8)
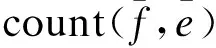
(2)正向词汇化翻译概率如式(9)所示:
(9)
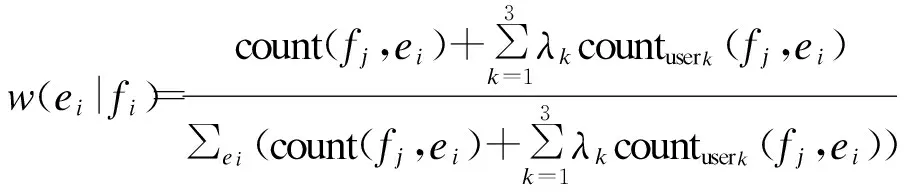
(10)
即源语言到目标语言词汇化加权概率,将源语言和目标语言的短语对拆分成词汇,通过词汇化概率公式的计算,得出短语对中词汇化的匹配程度。
公式(9)是一个二重循环问题:在外层循环中,从目标语言端第一个词汇遍历至最后一个词汇,将概率值进行连乘;在内层循环中,当前目标语言端词汇为ei,计算不同fj翻译为ei的概率和的均值。在这里a表示的是双语平行语料中对应的词对齐关系。从公式(10)中看出词汇化概率中count(fj,ei)表示短语对中源语言与目标语言(fj,ei)词汇化对在大规模平行语料中出现的次数,∑eicount(fj,ei)表示以fj为源语言端词汇化在大规模平行语料中出现的次数。与前面介绍的计算方式类似,这里countuserk(fj,ei)表示不同的用户群体翻译的平行句对中词对(fj,ei)出现的次数。∑eicountuserk(fj,ei)表示以fj为源语言端在用户翻译的平行句对出现的次数。对应的权重系数与之前介绍的相同。
(3)逆向短语翻译概率如式(11)所示:

(11)
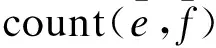
(4)逆向词汇化翻译概率如式(12)所示:
(13)
即目标语言到源语言词汇化加权概率,将短语拆分成词汇,通过双语词对齐结果统计出词汇化的概率,此处具体计算方式的解释与前面的正向词汇化翻译概率类似,在此不再赘述。
由于短语翻译概率系统大多都是基于对数线性模型进行建模,因此将以上四个翻译概率作为特征加入到对数线性模型中。
4 实验结果与分析
4.1实验数据
构建用户置信度评价模型时,我们采集翻译公司内翻译人员的基本个人信息作为基础特征向量。我们得到20 000句标注有校验人员修改信息的语料,这部分语料记录了用户在翻译过程的各种信息,语料的结构形式如表2所示:

表2 语料的结构形式
在这里原文的语言是中文,译文的语言是英语,作者是该译文翻译人员的姓名,翻译时间记录翻译当前句子的时间,形式如“201307020812”,意思是2013年7月2日8点12分开始翻译该句子。批注人是修改人员的姓名,批注的形式如<螺杆,翻译成threaded rod,应改为 screw rod>,最终译文是经过修改后的标准译文。在这里批注人有多个,而对应的批注为当前批注人修改的信息,同样该批注也会有多个。
本文评价优化算法的语料来源于航空技术出版物,该语料中的主要信息如表3所示。利用该语料得到对应的词对齐模型、翻译概率模型、语言模型、调序模型等。在这里词汇数为双语平行句对中不同单词的数目。
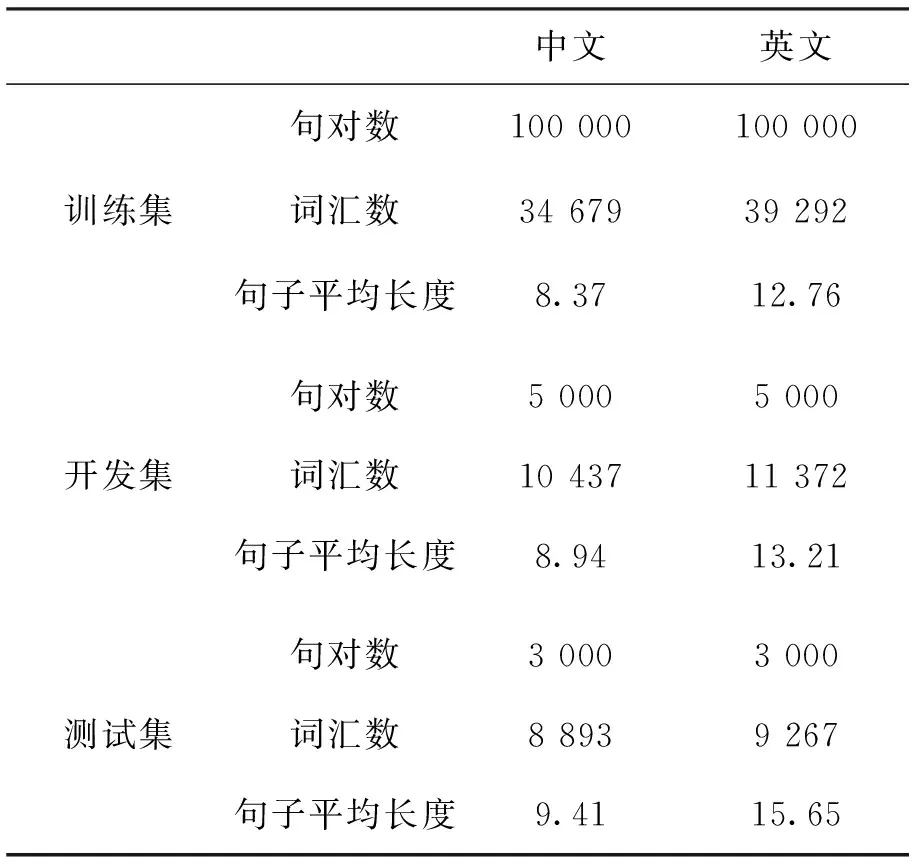
表3 评价语料的统计
另外再抽取6万对平行句对用于优化短语表,该语料记录翻译人员的姓名,用以区分不同的翻译人员;分词工具采用的是中科院的ICTCLAS;词对齐工具采用GIZA++[8];翻译概率模型的生成来自于东北大学研发的NiuTrans工具包[9]。
4.2实验结果及分析
为了验证提出方法的有效性,本文做了两组实验,分别为翻译概率模型直接优化实验(基线方法)和加入用户权重的翻译概率模型优化实验(本文方法)。
图1为加入用户权重和直接改进翻译概率模型时得到的两组BLEU值[10]的变化情况。图2为对应的NIST值[11]的变化情况。通过观察实验数据可以看到,利用60 000对中英文平行句对,改进翻译概率模型时,加入用户权重对应的 BLEU值提升9.56%,NIST值提升1.87%。而直接利用用户反馈的翻译知识改进翻译概率模型时,对应的BLEU值提升8.24%,NIST值提升0.92%。
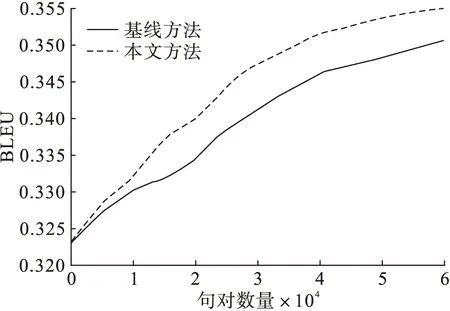
图1 加入不同用户权重和不加用户权重时BLEU值的变化情况
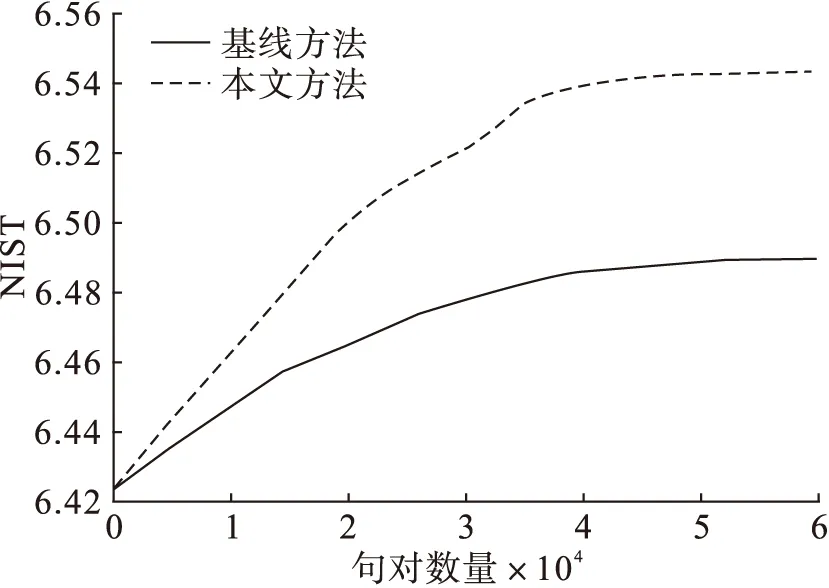
图2 加入不同用户权重和不加用户权重时NIST值的变化情况
从图1和图2的实验结果可以看出,利用用户反馈的翻译知识改进翻译系统时,译文质量得到了提高,原因是该语料的翻译人员都是专业的,对应的译文质量都比较高,反馈的翻译知识都是正向有价值的。无论有没有用户权重,翻译系统的引擎都得到优化。而加入用户权重,译文质量得到更大的提升,原因是不同用户的翻译经验不同,而A、B、C三档用户翻译的译文确实有所差别,A档用户翻译的译文要更准确一些。对不同用户进行分类,能够更加有效地利用用户反馈的翻译知识来改进翻译系统。随着用户反馈数据量的增加,译文质量的提升速度变慢了,这是因为系统性能的提升受到了其他因素的制约。本文提出的方法侧重于短语表的优化,而调序模型、语言模型等模型参数的优化问题还无法得到有效的解决。
5 总结和展望
当前统计机器翻译的译文质量仍然不够理想,人们开始关注如何利用用户反馈的翻译知识改进翻译系统。不同用户的翻译经验不同,本文通过深入分析影响用户翻译状态的因素,挖掘不同用户的特征,得到用户置信度评价模型,实现对不同用户分类,并利用分类结果修改翻译系统内短语表的参数。实验结果表明,对用户进行区分,改进翻译概率模型比直接改进翻译概率模型得到的译文质量要高。
未来的工作将进一步深入探讨用户置信度模型及用户权重的优化方法,也将寻找更多能够描述用户翻译状态的特征,实现对用户的更精确描述。
[1]A ARUN,P KOEHN.Online learning methods for discriminative training of phrase based statistical machine translation[J].Machine Translation,2007,XI:15-20.
[2]RGUZMAN.Automating MT Post-editing using Regular Expressions[J].Multilingual Computing,2007,18(6):49-52.
[3]D GROVES,D SCHMIDTKE.Identification and Analysis of Post-Editing Patterns for MT[C].Proceedings of MT Summit XII,2009,Ottawa,Canada.
[4]MSIMARD,CGOUTTE,PISABELLE.Statistical Phrase-based Post-Editing[C].Proceedings of NAACL,2007,2007:508-515,Rochester,USA.
[5]AFLLITJOS,JGCARBONELL.Automating Post-Editing to Improve MT Systems[C].Proceedings of the AMTA Automated Post-Editing Technique and Applications Workshop,2006,Cambridge,USA.
[6]DORTIZ-MARTINEZ,IGARCIA-VAREA,FCASACUBERTA.Online Learning for Interactive Statistical Machine Translation[C].Proceedings of NAACL,2010,2010:546-554,Los Angeles,USA.
[7]P KOEHN,FJ OCH,D MARCU.Statistical Phrase-Based Translation[C].Proceedings of HLT/NAACL,2003,2003:127-133,Edmonton,Canada.
[8]FJ OCH,H Ney.A systematic comparison of various statistical alignment models[J].Computational Linguistics,29(1):19-51.
[9]T XIAO,J ZHU,H ZHANG,QLI.Niutrans:An open source toolkit for phrase-based and syntax-based machine translation[C].Proceedings of ACL,2012,2012:19-24,Jeju,Korea.
[10]KPAPINENI,S ROUKOS,T WARD.BLEU:a method for automatic evaluation of machine translation[C].Proceedings of ACL,2002,2002:311-318,Philadelphia,USA.
[11]G DODDINGTON.Automatic Evaluation of Machine Translation Quality Using N-gram Co-Occurrence Statistics[C].Proceedings of HLT,2002,2002:138-145,San Diego,USA.
(责任编辑:刘划英文审校:赵亮)
Optimization method for statistical machine translation of phrase table based on user feedback
YIN Rui-cheng,YE Na,CAI Dong-feng
(Human-computer Intelligence Research Center,Shenyang Aerospace University,Shenyang 110136,China)
In recent years,a substantial progress is achieved in the study of statistical machine translation.However,in the domains with high translationquality requirements,the machine translation output still cannotbe satisfied.With the advent of computer-assisted translation and interactive machine translation technology,researchers begin to learn translation from users′ feedback to optimize the parameters of the machine translation systems.Since users′ translation experiences are different,the confidences of the translation knowledge learned from users are different.This paper analyzed the factors that influence the user′s confidence and proposed a model to evaluate it.This model can be used to distinguish the translation knowledge from different users,and update the parameters of phrase table in real time.The modified parameters included the probabilityof forward phrase translation,forward lexical translation,reverse phrase translation and reverse lexical translation.Experimental results show that by distinguishing the translation knowledge from different users′ feedback,an optimized performance is achieved compared to non-distinguishing users.
statistical machine translation;user feedback;user confidence;phrase table;parameter optimization
2095-1248(2016)03-0073-06
2016-01-25
国家自然科学基金(项目编号:61402299)
尹瑞程(1988-),男,河南洛阳人,硕士研究生,主要研究方向:机器翻译,E-mail:925910322@qq.com;叶娜(1981-),女,辽宁沈阳人,讲师,主要研究方向:机器翻译,E-mail:yena_1@126.com;蔡东风(1958-),男,辽宁沈阳人,教授,主要研究方向:人工智能、自然语言处理,E-mail:caidf@vip.163.com。
TP391.7
A
10.3969/j.issn.2095-1248.2016.03.012
猜你喜欢
核科学与工程(2021年4期)2022-01-12 06:30:22
计算机应用(2018年5期)2018-07-25 07:41:26
海外华文教育(2016年1期)2017-01-20 08:21:58
当代教育理论与实践(2015年9期)2015-12-16 16:26:05
轴承(2015年2期)2015-07-25 03:51:04
民族古籍研究(2014年0期)2014-10-27 08:24:34
外语教学理论与实践(2014年2期)2014-06-21 08:34:20
电讯技术(2011年11期)2011-04-02 14:00:37
