
微博事件感知与脉络呈现系统
2016-08-01 09:52欧阳逸於志文周兴社
浙江大学学报(工学版) 2016年6期
关键词:微博
欧阳逸, 郭 斌, 何 萌, 於志文, 周兴社
(西北工业大学 计算机学院,陕西 西安 710129)
微博事件感知与脉络呈现系统
欧阳逸, 郭斌, 何萌, 於志文, 周兴社
(西北工业大学 计算机学院,陕西 西安 710129)
摘要:为了研究微博的事件感知与脉络呈现方法,以Twitter为研究对象,对现实生活中发生的事件进行提取并呈现事件发展的过程.对微博的处理分为事件感知阶段和事件脉络呈现阶段.在事件感知阶段对原始微博进行过滤分析,去除冗余信息,并得到与事件相关的微博集.在事件脉络呈现阶段采用基于图结构的方法,将微博之间的关系转换成图中结点之间的关系,寻找图中的关键结点作为关键微博,并连接关键结点,最终得到在时间和内容上连贯的事件脉络.实验结果表明:所提出的方法能呈现事件的发展过程,也能体现事件发展的多样化.
关键词:微博;事件感知;事件脉络;图挖掘
近年来,随着互联网技术的发展和日益成熟,社交媒体网站(如:Facebook、Twitter、新浪微博等)如雨后春笋般出现在人们的视野中.作为一种新的社交媒体,微博已经得到了迅速的发展,人们可以通过它共享新闻和信息,也可以及时地了解现实生活中发生的事情[1-4].现在,越来越多的用户喜欢在微博上查询正在发生的事件[5],用户不仅能获得事件的最新动态,而且还能了解其他用户对事件的情感与主张[6-10].然而,对于某一事件,与之相关的微博量非常庞大,这些微博一方面带来了及时、丰富而多维度的信息,另一方面也因其包含零碎的信息而对了解事件全貌和发展演化带来挑战[11].
对微博中大量数据的挖掘已经成为了目前的研究热点.郑斐然等[12-17]的研究关注Twitter上的话题和事件的检测,局限性很大,无法展现事件全貌.Nichols等[18-21]统计了微博数量随时间的变化,通过检测微博数量的峰值来发现子事件,并按照时间顺序连接子事件得到事件发展脉络,这种方法会漏掉事件发展的关键信息.Lin等[22-23]采用图的方法来呈现事件脉络,把微博作为图中的结点,微博之间的关系用图中的边表示,这样不仅能清晰地展现事件发展的过程,而且非常直观,容易理解.
以马航失联为例,以下为马航失联5h内的事件发展过程.2014年3月8日8:45,一架由吉隆坡飞往北京的航班失去联系.8:52,飞机上有160名中国人.9:06,该机一直未进入我国空管情报区.9:50,飞机航油估计已经耗尽.10:47,飞机上中国人数字更新为154名.13:34,越南海军确认飞机坠落.如何能从微博上涌现的数以万计的相关帖子中获取以上事件脉络,是本文研究内容.
本研究存在如下挑战:1)关于某一事件的微博量十分庞大,其中会包含很多与事件无关的微博,从中提取出与事件相关的微博比较困难.2)呈现事件脉络是另一大挑战.在事件脉络呈现阶段,搜集事件在各个发展阶段的关键信息,即选取关键微博比较困难,这对呈现整个事件脉络造成了极大的挑战.
基于以上挑战,本文提出基于图结构来寻找关键微博和连接关键微博的方法.通过建图将微博之间的关系转换成图中结点之间的关系,寻找图中的关键结点作为关键微博,并在图中连接关键结点,得到最终的事件脉络.本文基于Twitter数据集进行实验,实验结果表明本文提出的方法能呈现事件的发展过程,同时也能体现事件的多样化特点.
1系统框架
本文的系统框架如图1所示,包括3个模块:微博数据库模块、事件感知模块、事件脉络呈现模块.微博数据库模块为整个系统提供了数据输入,事件感知模块以微博数据库的微博作为输入,输出与事件相关的微博集.事件脉络呈现模块以事件的微博集作为输入,呈现事件脉络.
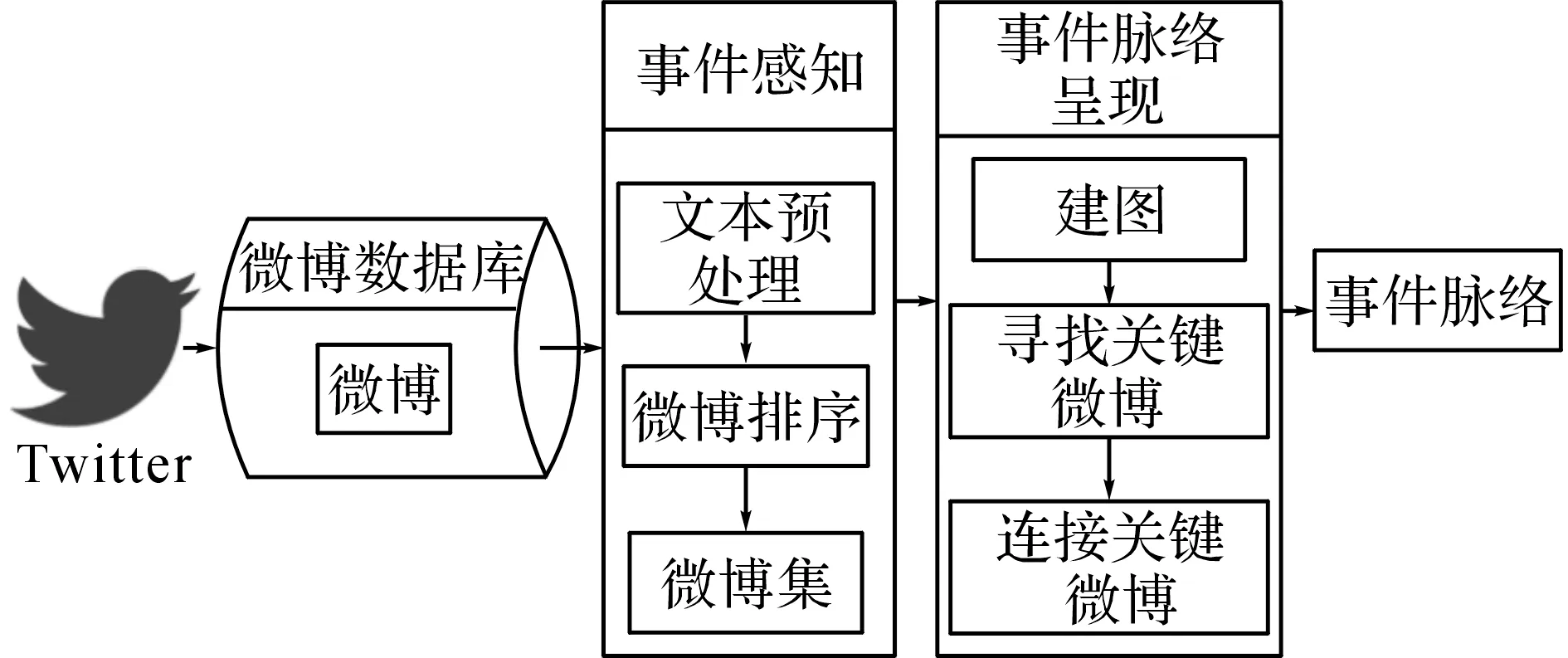
图1 事件感知与脉络呈现系统框架Fig.1 Frame of event sensing and vein presentation system
微博数据库是根据事件关键词查询出来的微博,其中包含与事件相关的微博,也包含大量无关的微博.事件感知模块对微博数据库中的原始微博进行分析处理,过滤大量无关的微博,保留与事件相关性高的微博.事件脉络呈现模块处理事件感知阶段得到的微博集合,从中挑选出关键微博,这些关键微博能够包含其他微博的内容,并将这些关键微博按照发布的时间顺序连接起来,形成事件脉络.
1.1事件感知
事件感知模块主要对微博进行过滤分析,降低冗余.对于微博数据库中的每一条微博,首先,根据事件关键词查询微博数据库,筛选出包含关键词的微博;然后,对这些微博进行预处理,过滤掉其中的冗余信息;接着,计算每一条微博的TF-IDF得分(词频与逆向文件频率的乘积,用于计算微博文本的重要性),并根据TF-IDF得分的高低将微博降序排列,选取排名靠前的微博,剔除排名靠后的微博;最后,输出排名靠前的微博集合,作为事件脉络呈现模块的输入.事件感知模块如图2所示.

图2 事件感知模块工作流程图Fig.2 Workflow of event sensing module
1.1.1文本预处理文本处理有多种不同的算法和工具.本文采用NLTK(自然语言工具包)对微博文本进行预处理,NLTK是英文文本处理中经常使用的一个工具,提供了丰富的语料库和词汇资源,在文本处理方面有较高的效率与准确率.
预处理分为如下步骤:1)将微博文本中的大写字母全部转换成小写字母;2)将文本中的单词分离,NLTK提供了分词工具;3)去除文本中的链接;4)去除文本中的停用词,NLTK提供了一份英文停用词数据,如:“I”,“me”,“my”等;5)去除文本中的标点符号.最终得到处理之后的微博集合,此时微博文本中的冗余信息已经被剔除.
1.1.2微博排序对于预处理得到的微博集合,计算每一条微博中出现的每个关键词的TF-IDF得分,并以所有关键词的TF-IDF得分之和作为这条微博的TF-IDF得分.
TF-IDF表示词语的逆向文档频率,可以通过计算文档中词语相对重要性的归一化得分来查询语料库.从数学的角度来说,TF-IDF表示词频和逆向文档频率的乘积:
Ttf_idf=Ttf·Tidf.
(1)
式中:Ttf为一个词语在某个具体文档中的重要性;Tidf为一个词语在整个语料库中的重要性.
因此,对于任意一条微博,其TF-IDF得分为
S(Ti)=∑q∈QTtf_idf(q).
(2)
式中:Q为事件关键词的集合;q为集合Q中的一个关键词;Ttf_idf(q)为关键词q的TF-IDF得分.
计算出每一条微博的TF-IDF得分之后,根据TF-IDF得分的高低将微博降序排列,选取排名靠前的微博,剔除排名靠后的微博.最后,输出排名靠前的微博集合,此时微博集合中的微博与事件的相关度很高,同时也包含了事件发展的各个过程.
1.2事件脉络呈现
事件脉络呈现模块主要分析微博之间的关系,呈现事件脉络.事件脉络呈现模块又分为3个子模块:建图、寻找关键微博、连接关键微博.该模块以事件感知模块输出的微博集作为输入,依次通过3个子模块的处理,最终呈现事件脉络.事件脉络呈现模块如图3所示.

图3 事件脉络呈现模块工作流程图Fig.3 Workflow of event vein presentation module
1.2.1创建图结构为了更加直观地呈现事件的脉络,考虑将微博之间的关系转化成图结构,采用图结构来展现事件的变化过程[22].
经过事件感知模块的处理,过滤掉了很多冗余信息,得到了与事件相关度较高的微博集,其中包含了事件发展的过程,但同时也存在许多重复和转发的微博,还有一些微博表达的主要信息都相同.因此这个微博集中还有一些微博是多余的,需要剔除,并且要找出关键微博来代替这些多余的微博,这样就能进一步地降低冗余.最后采用合适的方法将这些关键微博按照时间顺序连接起来,呈现完整的事件发展过程.
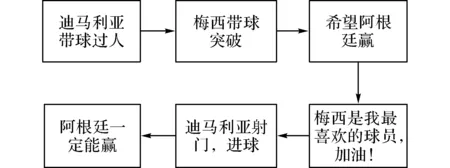
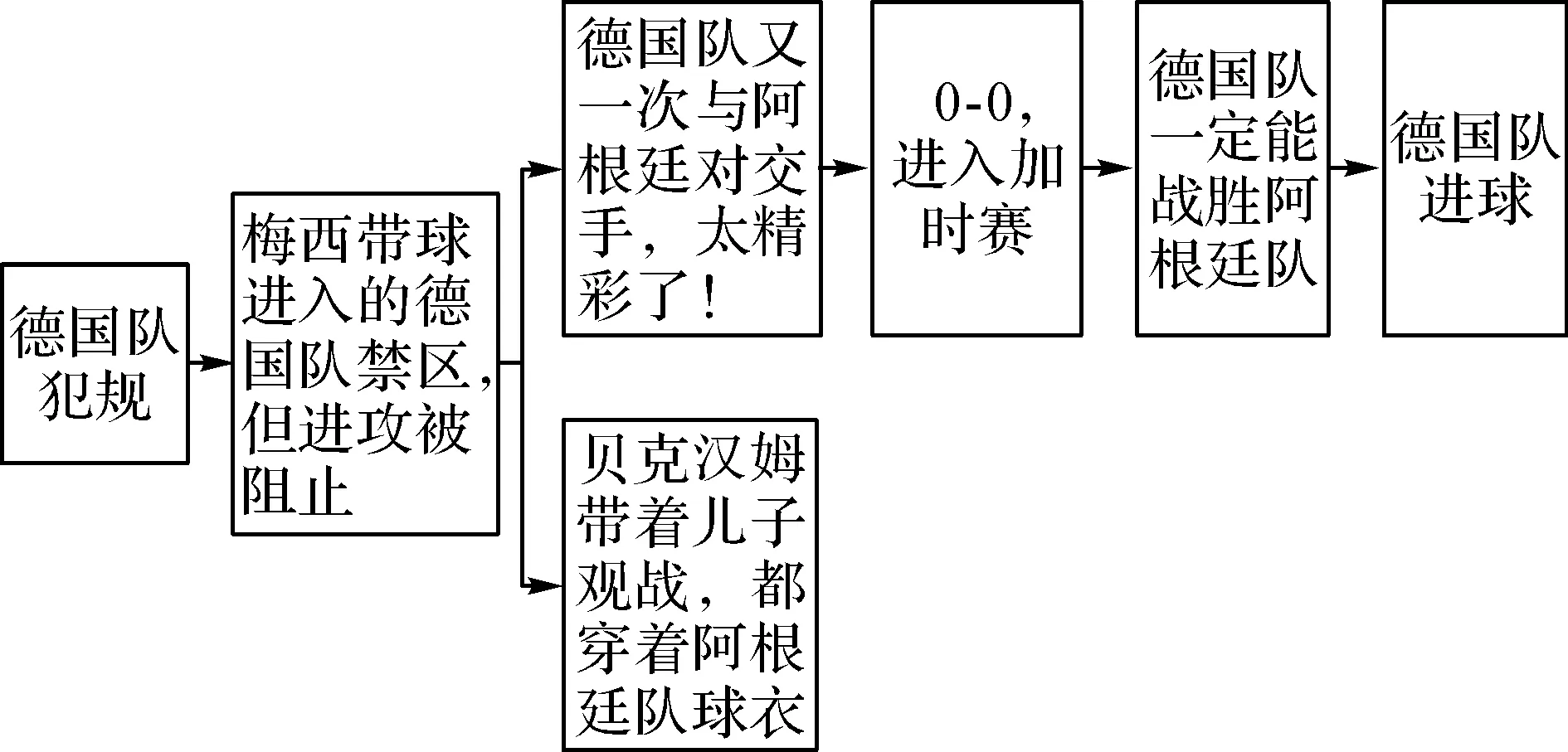
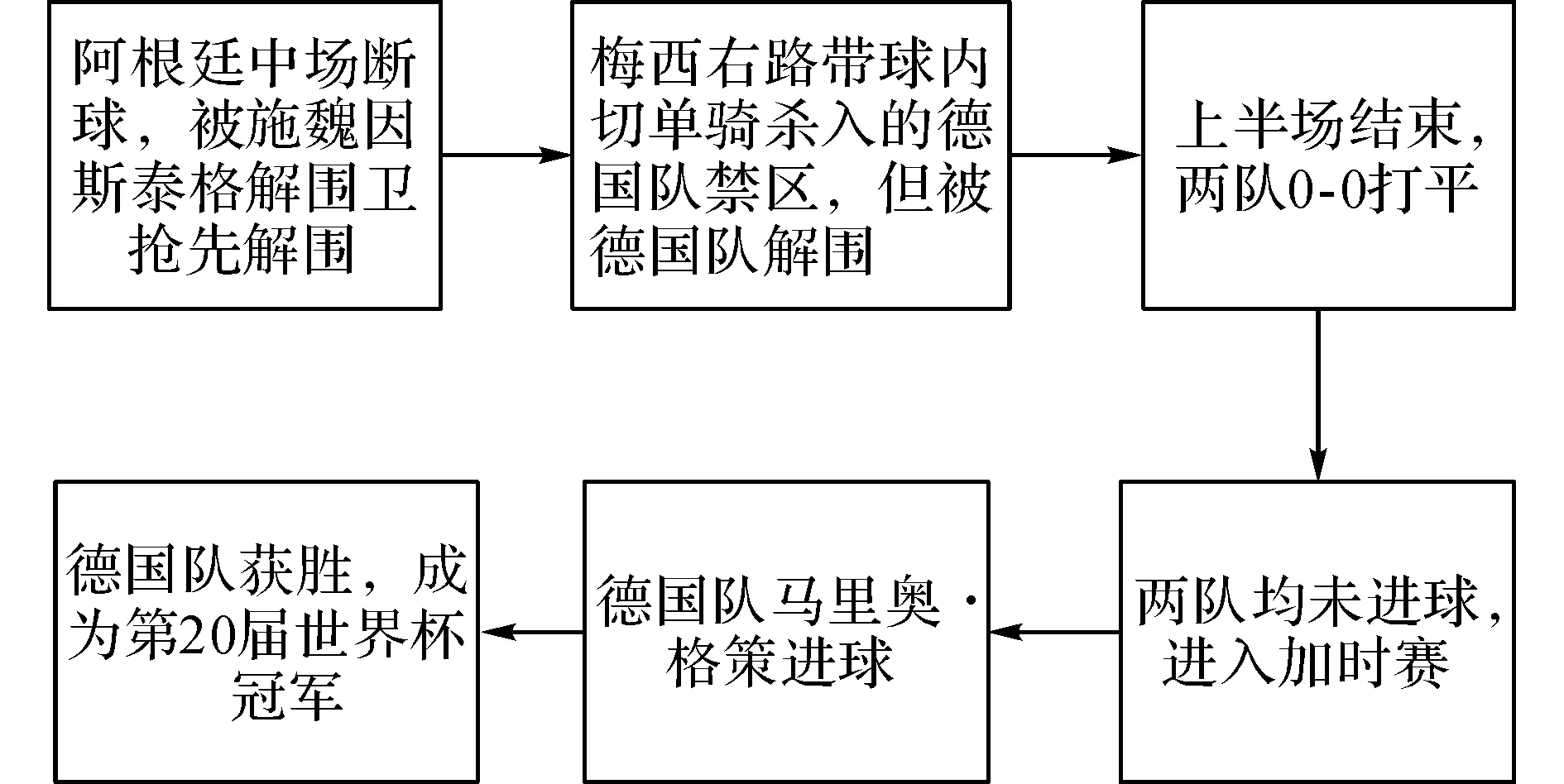
为了便于理解,创建2个图,一个无向图G(V,W,E)和一个有向图H(V,W,A).无向图用来表示微博之间的文本内容关系,有向图H用来表示微博之间的时间关系.无向图G和有向图H中每一个结点代表一条微博,且2个图中的结点及结点属性完全相同.V为结点集合;即微博集合;W为结点权值;E为无向边集合,表示微博文本之间的相似度关系.A为有向边集合,表示微博之间的时间关系.无向图G的创建由参数来控制;有向图H的创建由时间参数t1,t2来控制,且t1 采用如下方法计算每一个结点的权值: W(vi)=C(vi,Q) . (3) 式中:W(vi)为结点的vi权值;C(vi,Q)为结点vi对应微博与事件关键词集合Q的余弦相似度.C(vi,Q)越大,则说明该微博对应结点的权值越大,也表明与事件的相关度越高. 在计算集合时,当且仅当2条微博文本vi和vj之间的余弦相似度大于θ,即C(vi,Q)>θ时,就用一条无向边将对应的2个结点连接起来. 在计算集合A时,当且仅当t1≤tj-ti≤t2时,表明微博vi的发布时间ti比微博vj的发布时间tj早,就画一条从结点vi指向结点vj的有向边. 通过上述计算,就能构建完整地无向图G和有向图H,将微博之间的关系巧妙地转化为图中结点的关系,使处理过程更加直观,也便于理解. 在后续的处理过程中,希望能在无向图G中寻找到关键结点,即关键微博,并在有向图H中连接关键结点,最终得到事件脉络. 1.2.2选择关键微博原始微博经过事件感知阶段处理之后,得到的微博与事件的相关度已经很高了,在后续的处理中应当重点考虑微博与微博之间的关系,寻找关键微博来代表其他微博表达的内容.如何寻找关键微博就转化为如何寻找图中的关键结点的问题[22,24]. 采用计算加权相似度的方法来寻找无向图G中的关键结点.加权相似度的定义如下: (4) 选择关键结点v要既要考虑对应微博与事件的关联,又要考虑与邻结点对应微博的关联.W(vi)越大,表明邻结点vi对应微博与事件的相关度越高,也间接表明结点v对应微博与事件的相关度越高.C(v,vi)越大,表明结点v对应微博与邻结点vi对应微博的余弦相似度越大,也可以说明结点对应微博越具有代表性.当B(v)的值越大时,表示结点的加权相似度越高,即结点v对应微博越具有代表性,能够表示其邻结点对应微博的内容,则结点v为无向图G中的关键结点,对应微博为关键微博. 因此,寻找关键结点v*的模型可以表示如下: v*=argmaxv∈VB(v) . (5) 上述模型的原理就是,计算无向图G中所有结点的加权相似度,选取其中加权相似度最大的结点作为关键结点. 寻找关键微博的算法具体思想如下:在每一次迭代过程中,选择无向图G(V,W,E)中加权相似度B(v)达到最大的结点v作为关键结点,并添加到集合N中,同时将关键结点的所有邻结点全部添加到集合D中,并且在下一次迭代过程中不再处理这些结点.最终得到的集合D就是关键结点集合,集合N就是非关键结点集合. 这样不仅考虑了微博与事件的关联,而且着重考虑了微博与其他微博之间的关联,使得选取的关键微博与其他微博的相似度很高,能很好地表示其他微博的内容. 1.2.3连接关键微博在得到了关键结点集合D,即关键微博之后,需要在有向图H(V,W,A)中将这些关键结点按照微博发布的时间顺序连接起来,形成最终的事件. 在连接过程中,既要保证脉络的连贯性,即有向图H原始的连通性,又要保证时间的先后顺序.在连接时,如果2个关键结点本来就是邻结点,那直接连接即可;但也有可能2个关键结点不是邻结点,则需要通过过渡结点来连接这2个关键结点,过渡结点应该属于非关键结点集合,这时如何选择过渡结点,也就是选择连接2个关键结点的过渡路径就成为了主要问题[22,25]. 经过事件感知阶段的处理,得到的微博与事件的相关度已经很高,因此,不选择与事件关联度高的微博来作为过渡结点.得到的关键结点与其邻结点的加权相似度都已经很高,具有足够的代表性,因此,也不选择与关键结点相似度高的结点作为过渡结点.这样可以避免信息重复出现.考虑到事件的脉络已经初步生成,可以从事件多样化的角度来选择过渡结点,即选择加权相似度低的结点来作为过渡结点,这样不仅能呈现事件的脉络,还能体现事件的多样化. 寻找过渡结点的模型可以表示如下: (6) 式中:vi和vj为关键结点集合D中的任意2个关键结点;vk为vi到vj的一条路径中的过渡结点,且vk∈N;∑B(vk)为vi到vj的一条路径中所有过渡结点的加权相似度之和;p为关键结点vi和vj的连接方法,即过渡路径.上述模型的原理就是,选择加权相似度之和最小的过渡路径来连接2个关键结点. 连接关键微博的算法具体思想为,在有向图H中,如果对于任意2个关键结点vi和vj本来就是邻结点,则直接连接.如果不是邻结点,则需要添加有向图H中原来就存在的过渡结点vk,使得2个关键结点能够连通,并且还需要满足添加的过渡结点的加权相似度值之和达到最小.最后得到连接关键结点的边集合,即关键结点的连接结果.这样不仅将关键结点连接起来,而且还能体现事件的多样化.这样既保证了得到的事件在内容上连贯,又能体现事件的多样化,同时还保证了时间的先后顺序. 2实验结果及分析 2.1实验数据集 本文使用的数据集为2014年巴西世界杯的Twitter数据,采集了从2014年7月2日到2014年7月14日发布的Twitter数据. 本研究分别分析了2014年7月2日阿根廷队与瑞士队比赛的数据,以及2014年7月14日德国队与阿根廷队比赛的数据.2014年7月2日阿根廷队与瑞士队比赛的数据量相对较小,而2014年7月14日德国队与阿根廷队比赛为决赛,数据量非常庞大,处理起来比较困难,每场比赛持续时间大概为2h,因此分别分析了2014年7月2日0:00到2:00两个小时的数据,微博数量为38 230条,以及2014年7月14日3:00到5:00两个小时的数据,微博数量为62 161条. 2.2实验结果 对2014年7月2日举行的阿根廷与瑞士的比赛数据进行分析.数据处理流程如图4所示,圆形结点表示非关键结点,三角形结点表示关键结点.图4(a)为无向图,图4(b)为寻找到关键结点之后的图,图4(c)为有向图,图4(d)为连接关键结点之后的图.阿根廷与瑞士比赛的事件脉络如图5所示,对应图4(d).阿根廷与瑞士比赛的实际报道如图6所示. 对比上述事件脉络图5与实际报道图6可以看出,实际报道更加注重事件的整个过程,而脉络图更加关注事件发展的重要人物或重要阶段.同时,也展示了事件发展过程中用户的情感和观点,进一步体现了事件多样化的特点. 对2014年7月14日举行的德国与阿根廷的比赛数据进行分析.数据处理流程如图7所示.德国与阿根廷比赛的事件脉络如图8所示.德国与阿根廷比赛的实际报道如图9所示.对比上述事件脉络图8与实际报道图9可以看出,脉络图大致展示了事件发展的过程,并呈现了分支,增加了事件的趣味性,也进一步体现了事件多样化的特点. 图4 阿根廷与瑞士比赛的微博数据处理流程Fig.4 Microblog data processing of match between Argentina and Switzerland 图5 阿根廷与瑞士比赛的微博事件脉络图Fig.5 Microblog event vein of match between Argentina and Switzerland 图6 阿根廷与瑞士比赛的新闻报道图Fig.6 News report of match between Argentina and Switzerland 图7 德国与阿根廷比赛的微博数据处理流程Fig.7 Microblog data processing of match between Germany and Argentina 图8 德国与阿根廷比赛的微博事件脉络图Fig.8 Microblog event vein of match between Germany and Argentina 图9 德国与阿根廷比赛的新闻报道图Fig.9 News report of match between Germany and Argentina 2.3分析 通过对比分析,可以看出上述2组实验中的事件脉络图与实际报道图还是存在区别,实际报道更注重对客观事件的报道,而事件脉络图不仅呈现了事件发展的阶段,而且还呈现了用户对比赛以及球员的观点与态度,比实际报道会更有趣,也体现了事件的多样化. 分析实验结果与实际报道存在误差的原因如下: 1)在事件感知阶段,对微博的处理方法过于简单,仅仅靠计算微博与事件关键词的相关度高低来判断微博是否重要过于片面.由于事件感知模块输出的微博集存在误差,导致最终得到的事件与实际报道存在误差. 2)世界杯数据集中充斥着大量的用户情感,因为用户在观看比赛时,情感和态度都会比平时更加明确.用户情感一方面能使呈现的事件更加有趣,但另一方面会对呈现事件脉络造成干扰. 3结论 (1)检测微博中的事件变化过程能够提供更好的用户体验,并且也能更深入地了解事件的发展情况. (2)本文结合了微博挖掘、文本挖掘、图论等领域的方法,可以将其推广运用到社交媒体挖掘中,如:在海量的社交媒体中寻找信息扩散的源头,并预测信息扩散的未来趋势;实时更新获得社交媒体中的最新动态等. (3)本文提出的寻找关键微博和连接关键微博的方法着重考虑了微博之间的关联,将处理微博之间的关系转化为分析图中结点的关系,不仅直观,而且也便于理解. 本文也存在以下几个方面的不足. 1)在事件感知阶段,对微博的处理方法过于单一,仅仅靠微博中是否出现关键词来判断这条微博是否与事件相关过于片面.因为,还有一些微博可能与某一事件有潜在的相关性,但是不包含事件的关键词,这些微博在查询时就很可能会被遗漏,丢失一些有用的信息,对最后的事件呈现产生影响.由于事件感知模块输出的微博集存在误差,导致事件脉络呈现模块输出的事件与实际报道存在误差,相信改进微博过滤的方法,提高微博过滤的精确度,最后呈现的事件脉络会更好. 2)在事件脉络呈现阶段,连接关键结点的算法复杂度偏高,希望在后续的工作中改进算法,在保证结果准确的同时降低算法的复杂度.同时,在最后呈现的事件脉络中出现了用户情感,适当地呈现用户情感能体现事件的多样性与趣味性,但大量的用户情感也会导致结果与实际报道存在误差.因此,在后续工作中会考虑情感与事件的结合,呈现更加全面、多样化的事件脉络. 3)微博除了文本属性之外,还有其他属性,包括:评论、转发、微博博主的权威值等属性,这些属性也能体现事件的多样性,在后续的工作中会结合这些属性来呈现更加全面的事件脉络. 参考文献(References): [1]DORKM,GRUEND,WILLIAMSONC,etal.Avisualbackchannelforlarge-scaleevents[J].IEEETransactionsonVisualizationandComputerGraphics, 2010,6(16): 1129-1138. [2]MARCUSA,BERNSTEINMS,BADARO,etal.Twitinfo:aggregatingandvisualizingmicroblogsforeventexploration[C] ∥ProceedingsoftheSIGCHIConferenceonHumanFactorsinComputingSystems.Vancouver:ACM, 2011: 227-236. [3]ABELF,HAUFFC,HOUBENGJ,etal.Semantics+filtering+search=twitcident.exploringinformationinsocialwebstreams[C] ∥Proceedingsofthe23rdACMConferenceonHypertextandSocialMedia.Milwaukee:ACM, 2012: 285-294. [4]MCKELVEYK,MENCZERF.Designandprototypingofasocialmediaobservatory[C] ∥Proceedingsofthe22ndInternationalConferenceonWorldWideWebcompanion.RiodeJanerio:ACM, 2013: 1351-1358. [5]TEEVANJ,RAMAGED,MORRISMR.#TwitterSearch:acomparisonofmicroblogsearchandwebsearch[C] ∥Proceedingsofthe4thACMInternationalConferenceonWebsearchandDatamining.HongKong:ACM, 2011: 35-44. [6] 庞磊,李寿山,周国栋.基于情绪知识的中文微博情感分类方法[J].计算机工程,2012,38(13): 156-158. PANGLei,LIShou-shan,ZHOUGuo-dong.SentimentclassificationmethodofChinesemicro-blogbasedonemotionalknowledge[J].ComputerEngineering, 2012, 38(13): 156-158. [7] 张珊,于留宝,胡长军.基于表情图片与情感词的中文微博情感分析[J].计算机科学, 2012 (增3): 146-148. ZHANGShan,YULiu-bao,HUChang-jun.SentimentanalysisofChinesemicroblogsbasedonemoticonsandemotionalwords[J].ComputerScience, 2012 (Suppl. 3): 146-148. [8]BERMINGHAMA,SMEATONAF.Classifyingsentimentinmicroblogs:isbrevityanadvantage? [C] ∥Proceedingsofthe19thACMInternationalConferenceonInformationandKnowledgeManagement.Toronto:ACM, 2010: 1833-1836. [9]WANGR,HUANGW,CHENW,etal.ASEM:miningaspectsandsentimentofeventsfrommicroblog[C] ∥Proceedingsofthe24thACMInternationalonConferenceonInformationandKnowledgeManagement.Melbourne:ACM, 2015: 1923-1926. [10]WANGC,XIAOZ,LIUY,etal.SentiView:sentimentanalysisandvisualizationforinternetpopulartopics[J].IEEETransactionsonHuman-MachineSystems, 2013, 43(6): 620-630. [11]KOVACHB,ROSENSTIELT.Blur:Howtoknowwhat’strueintheageofinformationoverload[M].NewYork:BloomsburyPublishingUSA, 2011: 150-153. [12] 郑斐然,苗夺谦,张志飞,等.一种中文微博新闻话题检测的方法[J].计算机科学,2012,39(1): 138-141. ZHENGFei-ran,MIAODuo-qian,ZHANGZhi-fei,etal.NewstopicdetectionapproachonChinesemicroblog[J].ComputerScience, 2012, 39(1): 138-141. [13]MATHIOUDAKISM,KOUDASN.Twittermonitor:trenddetectionoverthetwitterstream[C] ∥Proceedingsofthe2010ACMSIGMODInternationalConferenceonManagementofData.Indianapolis:ACM, 2010: 1155-1158. [14]SAKAKIT,OKAZAKIM,MATSUOY.EarthquakeshakesTwitterusers:real-timeeventdetectionbysocialsensors[C] ∥Proceedingsofthe19thInternationalConferenceonWorldWideWeb.Raleigh:ACM, 2010: 851-860. [15]SHAMMADA,KENNEDYL,CHURCHILLEF.Peaksandpersistence:modelingtheshapeofmicroblogconversations[C] ∥ProceedingsoftheACM2011ConferenceonComputerSupportedCooperativeWork.Hangzhou:ACM, 2011: 355-358. [16] 张佳凡,郭斌,路新江,等.基于移动群智数据的城市热点事件感知方法[J].计算机科学,2015,42(6A): 5-9. ZHANGJia-fan,GUOBin,LUXin-jiang,etal.ApproachforurbanpopulareventdetectionusingmobileCrowdSourceddata[J].ComputerScience, 2015,42(6A): 5-9. [17] 郭跇秀,吕学强,李卓.基于突发词聚类的微博突发事件检测方法[J].计算机应用,2014,34(2): 486-490. GUOYi-xiu,LVXue-qiang,LIZhuo.BurstytopicsdetectionapproachonChinesemicroblogbasedonburstwordsclustering[J].JournalofComputerApplications, 2014, 34(2): 486-490. [18]NICHOLSJ,MAHMUDJ,DREWSC.Summarizingsportingeventsusingtwitter[C] ∥Proceedingsofthe2012ACMInternationalConferenceonIntelligentUserInterfaces.Lisbon:ACM, 2012: 189-198. [19]ALONSOO,SHIELLSK.Timelinesassummariesofpopularscheduledevents[C] ∥Proceedingsofthe22ndInternationalConferenceonWorldWideWebcompanion.RiodeJaneiro:ACM, 2013: 1037-1044. [20]SHOUL,WANGZ,CHENK,etal.Sumblr:continuoussummarizationofevolvingtweetstreams[C] ∥Proceedingsofthe36thinternationalACMSIGIRconferenceonResearchanddevelopmentinInformationRetrieval.Dublin:ACM, 2013: 533-542. [21]WANGZ,SHOUL,CHENK,etal.OnSummarizationandtimelinegenerationforevolutionarytweetstreams[J].IEEETransactionsonKnowledgeandDataEngineering, 2015, 27(5): 1301-1315. [22]LINC,LINC,LIJ,etal.Generatingeventstorylinesfrommicroblogs[C] ∥Proceedingsofthe21stACMInternationalConferenceonInformationandKnowledgeManagement.Maui:ACM, 2012: 175-184. [23]LEEP,LAKSHMANANLVS,MILIOSE.CAST:acontext-awarestory-tellerforstreamingsocialcontent[C] ∥Proceedingsofthe23rdACMInternationalConferenceonConferenceonInformationandKnowledgeManagement.Shanghai:ACM, 2014: 789-798. [24]SHENC,LIT.Multi-documentsummarizationviatheminimumdominatingset[C] ∥Proceedingsofthe23rdInternationalConferenceonComputationalLinguistics.Beijing:AssociationforComputationalLinguistics, 2010: 984-992. [25]WANGD,LIT,OGIHARAM.Generatingpictorialstorylinesviaminimum-weightconnecteddominatingsetapproximationinmulti-viewgraphs[C] ∥Proceedingsofthe26thAAAIConferenceonArtificialIntelligence.Toronto:AAAI, 2012: 683-689. 收稿日期:2016-01-22. 基金项目:国家“973”重点基础研究发展规划资助项目(2015CB352400);国家自然科学基金资助项目(61332005, 61373119,61222209). 作者简介:欧阳逸(1994—),男,博士生,从事普适计算研究. ORCID: 0000-0001-5987-451X. E-mail: ouyangyi@mail.nwpu.edu.cn 通信联系人:郭斌,男,教授. ORCID: 0000-0001-6097-2467. E-mail: guob@nwpu.edu.cn DOI:10.3785/j.issn.1008-973X.2016.06.023 中图分类号:TP 399 文献标志码:A 文章编号:1008-973X(2016)06-1176-07 Eventsensingandveinpresentationleveragingmicroblogging OU-YANGYi,GUOBin,HEMeng,YUZhi-wen,ZHOUXing-she (School of Computer Science, Northwestern Polytechnical University, Xi’an 710129, China) Abstract:The event sensing and vein presenting problem with the data from Twitter was investigated to extract real-life events and the development of the event and finally present a comprehensive event vein. Microblogging process was made up of two main modules, including event sensing and event presentation. The event sensing module processed raw microblogs, filtered redundant information and extracted the ones associated with the event. The event presentation module presented the event vein based on the relationship between microblogs. Next, an effective approach based on the graph structure was proposed to transform the relationship between microblogs to the relationship between nodes, each of which in the graph represented a microblog. Key nodes was identified in the graph, and then linked with edges. Finally, the event vein that ensured both temporal and content coherence was generated. Results of experiments over a real dataset collected from Twitter show that our approach to generate the event vein is effective and also can reflect the diversity of events. Key words:microblogging; event detection; storyline; graph mining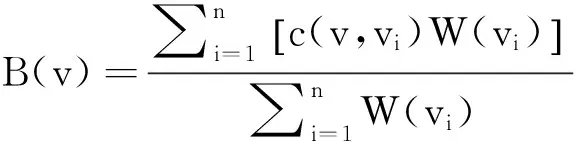




猜你喜欢
电脑知识与技术(2016年26期)2016-11-24
电脑知识与技术(2016年25期)2016-11-16
中国市场(2016年38期)2016-11-15
出版科学(2016年5期)2016-11-10
文艺生活·中旬刊(2016年9期)2016-11-07
人间(2016年26期)2016-11-03
中学课程辅导·教师教育(中)(2016年9期)2016-10-20
人民论坛(2016年27期)2016-10-14
意林(2013年15期)2013-05-14
