
兴趣模型的构建与Apriori数据挖掘算法优化研究*
2016-06-22 01:38:08方文和李国和吴卫江洪云峰周晓明
计算机与数字工程 2016年5期
方文和 李国和 吴卫江 洪云峰 周晓明
(1.中国石油大学(北京)地球物理与信息工程学院 北京 102249)(2.中国石油大学(北京)油气数据挖掘北京市重点实验室 北京 102249)(3.石大兆信数字身份管理与物联网技术研究院 北京 100029)
兴趣模型的构建与Apriori数据挖掘算法优化研究*
方文和1,2,3李国和1,2,3吴卫江1,2,3洪云峰3周晓明3
(1.中国石油大学(北京)地球物理与信息工程学院北京102249)(2.中国石油大学(北京)油气数据挖掘北京市重点实验室北京102249)(3.石大兆信数字身份管理与物联网技术研究院北京100029)
摘要分析关联规则算法实际过程中参数规律,改进重构Gray和Orlowska兴趣度模型,引入兴趣项、频数阈值、构建兴趣模型,从而能够减少不必要的挖掘扫描操作,提高挖掘的效率,使得挖掘更加有针对性。通过中国石油大学(北京)油气数据挖掘北京市重点实验室提供的标准仿真数据集合对比实验,证明改进后的算法效率更高,适合用于特定兴趣点的二次高效率挖掘。
关键词Apriori; 兴趣项; 关联规则; 兴趣模型; Gray和Orlowska
Class NumberTP3-05
1引言
事物数据库中关联规则的挖掘为数据挖掘领域研究重点。可概括成两个子问题[1],为寻求符合支撑条件高频项目集合以及由置信度筛选出关联规则。前者开销大,故研究多致力提升频繁项目集合寻求的效率。此外数值型、多层关联规则[2]的研究拓展了关联规则。
在很多领域,如油田数据挖掘中,研究人员往往希望能够高效地从历年来积累的大量的油田参数信息中挖掘出自己感兴趣并且有前经验模型参考的相关的参数之间的具体关联规则关系,如通过关键的参数与产量关联,可以得到产量与相关参数的实地油田关系数据。从而能够有针对性有效率地改进验证针对于具体油田的理论模型。并且可以发现新关系。推导出合理的公式,并指导实际油田工业生产。而油田数据参数纷杂,故有针对性地提高挖掘效率显得十分必要。
本文在分析Apriori算法基础上,通过对关联规则算法实际过程出现的规律,改进重构兴趣度模型,引入兴趣项和频数阈值,构建兴趣度,以减少对数据库的检索,提出改进方法,提高Apriori的效率。在中国石油大学(北京)油气数据挖掘北京市重点实验室提供的标准数据集合基础上进行效率对比实验。
2关联规则概述
令D的一个子集A满足A⊆D,则称事务包含项集A。关联规则A⟹B即A⊆D、B⊆D、A∩B=Φ[3]。
支持度与置信度是关联规则中最重要两个关键指标,它们分别为整个数据集合统计中的支持关键、关联的可信关键。
支持度=P(A∪B),置信度=P(A/B)。P(A∪B),P(A/B)大于一定关联方有关联规则一定的实际应用上价值,其值称为最低支持阈值minSup和最低置信阈值minConf,于规则关联符合minSup者即频繁项集;符合minSup及minConf两者规则即强规则[4]。高效的频繁项集、强规则即是目的。
3Apriori算法
Apriori算法过程:
1) 挖掘得频繁k-项集;
2) 其后由minSup筛选出频繁k-项集;
3) 合并所有的频繁k-项集,用minConf指标来筛选得到频繁关联规则。
该算法关键步骤为连接与剪枝。描述如下:
1) 连接步:可连接的Lk-1自连接,得候选k项集Ck;
2) 剪枝步:Lk的超集即是Ck。扫描数据库,将Ck每一个候选计数,标记的该计数值大于等于最小支持度的候选为频繁的,即属于Lk。
Ck若很大,则需大量计算量。为减少计算量,故压缩Ck,根据Apriori特性:一切不频繁(K-1)项集合皆非频繁K项集合子集。故一待选K项集合(K-1)项集不处于Lk,待选项亦非频繁的,可从Ck内删去[5]。改子集检测能采用在频繁项集建立的散列树方法迅速完成。
此外,传统Apriori算法过程中频繁扫描数据库;minSup和minConf挖掘过程中固定不可变,否则需重新挖掘。挖掘过程中没有排除并不感兴趣,浪费大量的时间。
4改进的Apriori算法
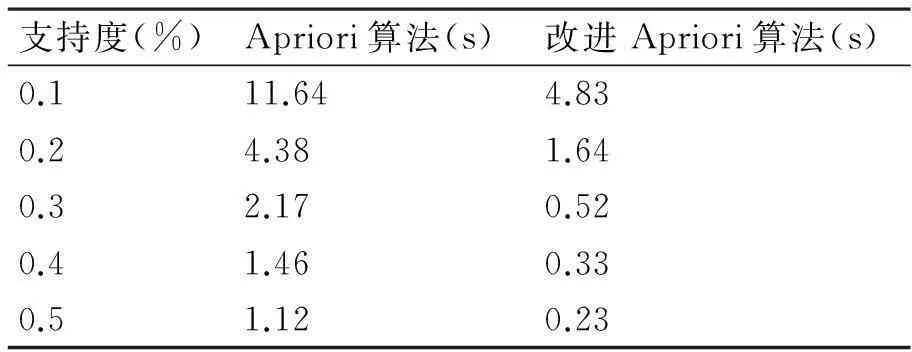
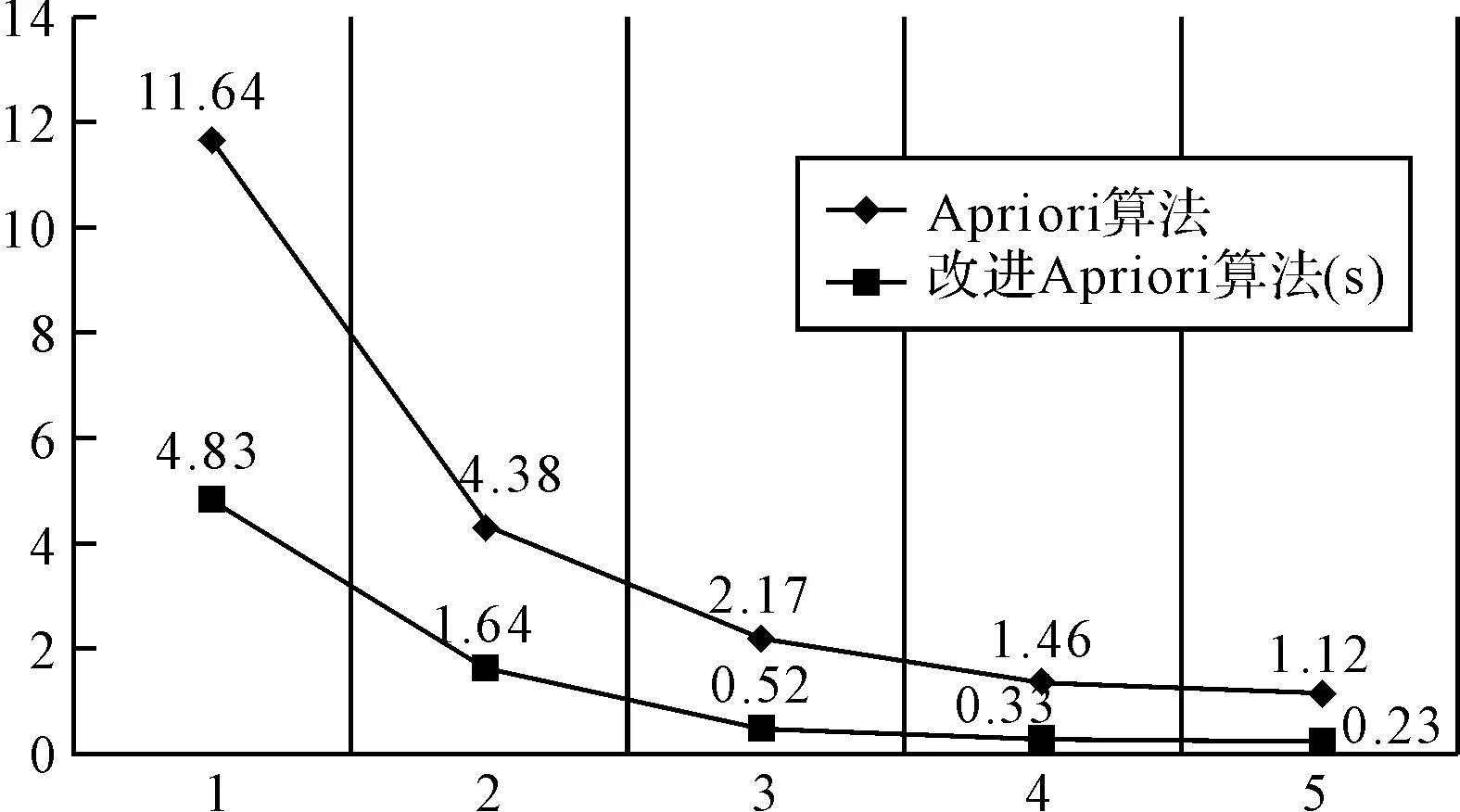
性质1:若A⟹B,则|AB|≥minCount。若|T| 性质2:若关联规则中有A⟹B,则A与B为频繁项集,而AB可能不为频繁项集。[7] 定义3:令挖掘的目标项集合为I,即兴趣项集合。记录I子集组成的项集在事务数据库中的频数为兴趣项频数。支持频数阈值minSupCount为minSupCount=|D|*minSup[8]。 令关联规则A⟹B中|A∪B|的最小值为minCount即频数阈值。其中: minCount=minSupCount*minConf 由于关联规则A⟹B成立,A、B为频繁项集,即|A|>minSupCount,|B|>minSupCount。A⟹B成立,故Conf(A⟹B)≥minConf。所以|A∪B|≥|A|*minConf≥|D|*minSup*minConf,即I子集里所有项集数不能小于minCount。 4.1建立兴趣度模型 兴趣度包括主观兴趣度与客观兴趣度两方面。目前对兴趣度的研究主要集中在客观兴趣度方面。[8] 根据Gray和Orlowska兴趣度模型[9]得: Interests(A⟹ *(p(A)p(B))m 由于关联规则算法实际过程出现如规律[10],要求改进重构Gray和Orlowska的兴趣度模型。 1) 规则A⟹B,A在事务数据库中出现的概率越大则推导出由其引出关联规则兴趣越高,即A出现的概率越大规则A⟹B的兴趣度应该越大[11]。 2)A和项B的耦合程度越高则其关联规则越希望被挖掘出来[12],Interests(A⟹B)应该越大[12]。 3)B在事务数据库中出现的概率越大表明引起项B的条件越多[13],则A⟹B概率就越小,故B与Interests(A⟹B)成一定反比关系[15]。 4)A⟹B出现的概率越大Interests(A⟹B)应该越大[16]。 综合上述改进兴趣度模型为 根据设定的兴趣度模型结合支持度与置信度评价标准得出新的强关联规则定义[14],即当Sup(A⟹B)≥minSup、Conf(A⟹B)≥minConf且Interests(A⟹B)≥minInterests时,称关联规则A⟹B为强关联规则[16]。 4.2算法实现步骤 Apriori算法的改进如下: 第一步:对兴趣项的各个子集合的项频数进行计算 1) 准备待挖掘的目标项集合为I(兴趣项)和待挖掘的数据库; 2) 扫描事务数据库; 第二步:找出关联关系 1) 输入minSup,minConf,Interests(A⟹B),把minSup转化为minSupCount。 2) 对保存的兴趣项子集进行扫描,挖掘频繁项集合,如果子集频数小于minCount进行删除。 3) 从计算获得的频繁项集合中,寻找置信度不小于minConf,兴趣度不小于Interests(A⟹B)的关联关系,并输出。 5算法性能分析 为验证改进后算法的效率,采用C#2008编译环境下,sql server2008数据库,在Intel(R)Pentium(R)双核3.00GHz,2.5GB内存250GB硬盘、Windows XP sp2操作系统环境。样本数据文件是中国石油大学(北京)油气数据挖掘北京市重点实验室提供的关联规则的标准仿真数据集,测试数据包含事务数为13457,每个事务包含156个属性。在相同的硬件配置条件下,对Apriori算法和改进后的Apriori算法的支持度从0.1,0.2,0.3,0.4,0.5的情况下,进行100次测试取平均值,统计结果如表1所示。 表1 算法实验测试结果 两种算法的软硬件测试环境相同,如图1比较Apriori算法和改进后的Apriori算法的计算时间,其中小圆点趋势线是标准Apriori算法的拟合线,方块点连线为改进后的Apriori算法的拟合线,可知改进后的Apriori算法的计算时间小于Apriori算法。 图1 算法效率对比 6结语 本文通过对关联规则算法实际过程参数相关关系进行分析研究,改进重构Gray和Orlowska兴趣度模型,使之更符合实际挖掘规律。具体挖掘引入兴趣项和频数阈值,构建兴趣度,以减少对数据库的检索,提出改进的算法,提高Apriori的效率。该算法能够有效减少不感兴趣的部分的数据库扫描操作,降低数据库的扫描频数。在中国石油大学(北京)油气数据挖掘北京市重点实验室提供的标准数据集合基础上经对比实验:改进后的关联规则挖掘时间效率较高,使得关联规则数据挖掘更加有针对性。 参 考 文 献 [1] Al-Betar M A, Doush I A, Khader A T, et al. Novel selectionshemes for harmony search[J] . Applied Mathematicsand Computation,2012,218(10):6095-6117. [2] Khmelev D, Tweedy F J. Using Markov chains for identification of Writers[J]. Literary and Linguistic Computing,2001,16(4):299-307. [3] 徐章艳,张师超,卢景丽.挖掘关联规则中的一种优化的Apriori算法[J].计算机工程,2003(19):83-87. XU Zhangyan, ZHANG Shichao, LU Jingli. An optimized Apriori algorithm for mining association rules[J]. Computer Engineering,2003(19):83-87. [4] 朱玉全,孙志挥.大型事务数据库中的一种快速的规则挖掘算法[J].计算机科学,2002(10):59-69. ZHU Yuquan, SUN Zhihui. A fast rule mining algorithm forlarge database[J]. Computer Science,2002(10):59-69. [5] Mao YX, Shi Bl. AFOPT-Tax: An efficient method for mining generalized requent itemsets[C]//Proc. of the 2nd Asian Conf. on Intelligent Information and Database Systems(Aciids),2010:82-92. [6] Agrawal R, Srikant R. Fast algorithms for mining association rules[C]//Proc. of the Int’t Conf. on Very Large Data Bases(VLDB). Santiago,1994:487-499. [7] Mahdavi M, Fesanghary M, Damangir E. An Improved Harmo-ny Search Algorithm for Solving Optimization Problems[J]. Applied Mathematics and Computation,2007,188(2):1567-1579. [8] 覃雄派,王会举.数据管理技术的新格局[J].软件学报,2013(2):175-197. QIN Xiong, WANG Huiju. New pattern of data management technology[J]. Software Journal,2013(2):175-197. [9] Yule G U. On sentence length as a statistical characteristic of stylein prose with application to two cases of disputed authorship[J]. Biometrika,1938,30:363-390. [10] 高宏宾,潘谷,黄义明.基于频繁项集特性的Apriori算法的改进[J].计算机工程与设计,2007(10):2273-2276. GAO Hongbin, PAN Gu, HUANG Yiming. Improvement of Apriori algorithm based on frequent item sets[J]. Computer Engineering and Design,2007(10):2273-2296. [11] Liu GM, Lu HJ, Lou WW, et al. Efficient mining of frequent patterns using ascending frequency ordered prefix-tree[J]. Data Mining and Knowledge Discovery(DMKD),2004,9(3):249-274. [12] 李金厚,周丽平,于晓青.基于用户操作行为的兴趣度的分析与计算[J].工业控制计算机,2011(7):64-67. LI Jinhou, ZHOU Liping, YU Xiaoqing. Analysis and calculation of interest based on user’s operation behavior[J]. Industrial Control Computer,2011(7):64-67. [13] Sriphaew K, Theeramunkong T. Fast algorithm for mining generalized frequent patterns of generalized association rules[J]. IEICE Trans. on Information and Systems(TOIS),2004,E87-D(3):761-770. [14] 尤磊,兰洋,熊炎.一种基于关系代数的Apriori优化方法[J].信阳师范学院学报(自然科学版),2010(1):156-160. YOU Lei, LAN Yang, XIONG Yan. Apriori optimization method based on relational algebra[J]. Journal of Xinyang Normal University(NATURAL SCIENCE EDITION),2010(1):156-160. [16] 王伟勤,郑燊海.Apriori算法的进一步改进[J].计算机与数字工程,2009(4):20-23. WANG Weiqin, ZANG Shenhai. Further improvement of Apriori algorithm[J]. Computer and Digital Engineering,2009(4):20-23. Optimization of Apriori Algorithm for Mining Interest Model FANG Wenhe1,2,3LI Guohe1,2,3WU Weijiang1,2,3HONG Yunfeng3ZHOU Xiaoming3 (1. College of Geophysics and Information Engineering, China University of Petroleum, Beijing102249)(2. Beijing Key Lab of Data Mining for Petroleum Data, China University of Petroleum, Beijing102249)(3. PanPass Institute of Digital Identification Management and Internet of Things, Beijing100029) AbstractParameters of association rules algorithm in the actual process are analyzed, the interest model of Gray and Orlowska reconstruction is improved, interest, frequency threshold are introduced, interest model is built, which can reduce unnecessary mining scanning operation, improve the efficiency of mining, the mining more targeted. The standard simulation data set of the Key Laboratory of China University of Petroleum(Beijing) is used to prove the efficiency of the improved algorithm is higher, which is suitable for the two time efficient mining of specific interest points. Key WordsApriori, interest, association rules, interest model, Gray and Orlowska * 收稿日期:2015年11月4日,修回日期:2015年12月25日 基金项目:国家高新技术研究发展计划(编号:2009AA062802);国家自然科学基金(编号:60473125);中国石油(CNPC)石油科技中青年创新基金(编号:05E7013);国家重大专项子课题(编号:G5800-08-ZS-WX)资助。 作者简介:方文和,男,硕士研究生,研究方向:知识发现,数据挖掘,信息安全。李国和,男,博士,教授,博士生导师,研究方向:人工智能,知识发现,信息安全。吴卫江,男,博士,副教授,研究方向:人工智能,知识发现。洪云峰,男,研究方向:ERP与数据管理。周晓明,男,高级工程师,研究方向:信息管理系统、决策支持。 中图分类号TP3-05 DOI:10.3969/j.issn.1672-9722.2016.05.001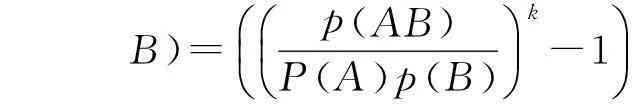
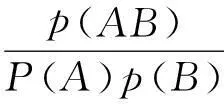
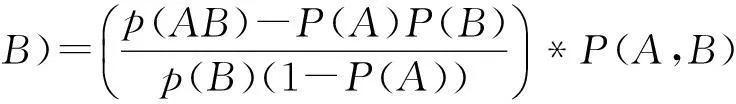
猜你喜欢
西南石油大学学报(社会科学版)(2022年4期)2022-07-06 08:01:16
西南石油大学学报(社会科学版)(2022年3期)2022-05-31 01:39:24
初中生世界·八年级(2017年3期)2017-03-24 15:36:23
中学生数理化·七年级数学人教版(2016年6期)2016-05-14 13:56:13
大庆社会科学(2015年1期)2015-11-28 05:48:29
初中生世界·八年级(2015年4期)2015-08-04 07:59:48
卷宗(2014年5期)2014-07-15 07:47:08
中医研究(2014年5期)2014-03-11 20:28:52
计算机工程(2014年6期)2014-02-28 01:26:12
中国石油大学学报(自然科学版)(2013年6期)2013-03-11 18:35:35
