
基于启发函数改进的SARSA(λ)算法*
2016-06-22 01:38:40马朋委潘地林
计算机与数字工程 2016年5期
关键词:强化学习
马朋委 潘地林
(安徽理工大学计算机科学与工程学院 淮南 232001)
基于启发函数改进的SARSA(λ)算法*
马朋委潘地林
(安徽理工大学计算机科学与工程学院淮南232001)
摘要强化学习是一种重要的机器学习方法,在机器人路径规划,智能控制等许多决策问题中取得了成功的应用,已经成为机器学习研究的一个重要分支。针对强化学习存在着的收敛慢,学习知识慢,探索与利用平衡等问题,论文对SARSA(λ)算法提出了一种改进,改进的方法借助经验知识从环境特征中提出一个用于策略择优和优化回报函数的启发函数,以此来加速算法的收敛速度。通过仿真对比,论文提出改进算法具有比SARSA(λ)更快的奖赏反馈,表明了该算法在知识学习方面的有效性。
关键词强化学习; SARSA(λ); 启发函数; 评估学习
Class NumberTP301.6
1引言
20世纪90年代强化学习通过与运筹学、控制理论的交叉结合,在控制理论和算法方面取得若干突破性的研究成果,奠定了强化学习的理论基础,并在智能控制、机器人系统规及分析预测等序贯决策中取得了成功的应用[1~2]。强化学习是一个试错学习的过程,目的是使Agent从环境中获得的累积奖赏值最大。Agent在环境中执行一个动作,到达下一个状态,同时给予Agent一个强化信号[3](奖励或惩罚),Agent借助环境给予的强化新号来对原有的策略进行改进,最终目的是最大化累积奖赏值。
强化学习大部分都是以马尔科夫决策过程(Markov Decision Process)为基础。马尔科夫决策过程借助四元组(S,A,P,r)来描述。S为环境状态空间,A为动作空间,P(s,a,s′)为状态转移概率,r为立即回报函数。在马尔科夫决策过程中,Agent是通过一个决策函数(即策略)来选择动作的,常用π表示策略。在定义了策略后对应状态-动作值函数为Qπ(s,a),Qπ(s,a)表示在状态s下根据策略π执行动作a的期望值如式(1):
(1)
最优动作值函数Q*(s,a)的定义为式(2):

Q*(s,a)=maxπQπ(s,a)
(2)
最优策略π*是使得Agent在每一个状态下均能获得最大值的策略如式(3):
(3)

一些强化学习算法已经在理论和应用方面取得了重大的成功Q_learning[4],TD(λ)[5],SARSA[6]。本文借助将人的经验和背景知识融入到强化学习中,基于SARSA(λ)提出一个改进的一个启发函数,提高Agent对环境知识的学习,加快算法的收敛。
2SARSA(λ)简介
SARSA算法是强化学习中的一种在策略(on-policy)的时序差分算法[7]。它由Rummery和Niranjan在1994年提出了一种基于模型的算法,最初称为改进的Q学习算法,后称为SARSA(STATE-ACTION-REWARD-STATE-ACTION)学习算法[8]。SARSA在更新时借助五元组(s,a,r,s′,a′)其中:s表示当前状态;a表示当前状态下选择的动作;r是选择动作a后获得的奖励;s′和a′则分别代表后续的状态和动作。SARSA算法中动作值函数的更新规则如式(4)所示:
δ=[r+γQ(s′,a′)-Q(s,a)]
Q(s,a)←Q(s,a)+αδ
(4)
γ为折扣因子;α是步长参数,0≤α≤1和0<γ≤1。
在Q_learning和SARSA算法中,当接收到一个奖赏值时只向后回溯一步,相当于做了一步备份,导致算法收敛缓慢,一个改进的方法是回溯任意步,称为SARSA(λ)算法,其动作值函数跟新规则如式(5):
δ=[r+γQ(s′,a′)-Q(s,a)]
Q(s,a)←Q(s,a)+αδe(s′,a′)
(5)
其中e(s,a)为状态的“资格迹”(eligibility trace)[9]。借助资格迹来体现每一步对结果负的责任大小。一个“状态-动作对”第一次被访问时,将它的资格迹设置为1。在随后的每个时间步里,它的资格迹应是不断减少的,当该状态再次被访问时,其资格迹加1。资格迹的定义如式(6):
(6)
其中表示状态s在t时刻的迹,SARSA(λ)使Agent对环境知识的学习有一定程度的进步,但对环境知识的学习依然是缓慢的,忽略了大量有用的信息和知识。由于缺乏有效的策略选择机制,常需在状态空间进行多次遍历才能收敛。针对SARSA(λ)存在的问题,本文引入启发(Heuristic)函数加速(Accelerate)算法对环境知识的学习,简称HASARSA(λ)算法。借助启发函数改进策略的选择,优化回报函数,相比SARSA(λ)对环境知识的学习有明显的提高。
3HASARSA(λ)设计
强化学习算法是通过不断地与环境交互,从当前一个状态s,选取一个动作a,到达下一个状态s′,获得该动作a的一个奖赏值,强化学习算法的关键问题在于动作选择函数和回报函数的设计,本文通过设计一个启发函数来改进动作的选择,优化回报函数,来加快算法的收敛。启发函数的定义主要来自两方面,一方面是借助先验领域知识,一方面是在学习的过程利用学习获得的信息。文献[10]提出了大多数启发函数的定义分为两个阶段,第一阶段是根据值函数V进行领域结构的提取,称作结构提取[10]。第二阶段是在结构提取后构造启发式函数,称为启发式构造。SARSA(λ)在引入启发式函数的强化学习模型如图1所示。

图1 启发式强化学习框架图
图1表明在原有的强化学习框架基础上引入了特征节点,并从特征中提取了附加回报和调和函数对原有的动作选择策略和回报函数进行优化。
3.1策略选择函数
Q_learning,SARSA算法在选择策略上通常选用ε-greedy算法。
ε-greedy选择策略定义如式(7):
(7)
其中π(st)表示策略选择函数,p为探索-利用平衡的参数,p越大,算法越倾向于利用已有的知识,arandom是当前动作集合中的一个随机动作。加入启发函数后改进的动作选择函数如式(8):
(8)
相比式(7)多了一个调和函数Ht(st,at),值可正可负。目的使Agent在执行选择策略过程中,通过调和函数来折中分析动作的好坏,不断强化好的动作,弱化差的动作,借此来指导动作的选择,减少都无用状态的探索,加速算法的收敛过程。
3.2回报函数
启发函数的回报函数分为两部分,原立即回报函数和附加回报函数如式(9):
R(st)=r+r′(st,at)
(9)
式中r为立即回报,是借助人的经验和背景知识,对环境的特征提取,设置的附加回报函数。
4实验结果仿真分析
4.1启发函数的设计
启发函数的设计依赖一定的环境问题背景,在这里选取一个20×20 Maze,state表示Agent的状态,坐标(x,y)。Agent开始状态随机生成,终点状态为state(20,20)。Agent可以执行的动作为上下左右,r表示执行一个动作后到达下一个状态获得的奖赏。如果是终点给予10的正奖励值,陷阱则给予负奖赏值-5,撞墙或遇到障碍物给予-1的奖赏值,其它情况给予0。
立即回报r可以表示如式(10):

(10)
为了定义启发函数,本文从环境中提取如下三个特征:
1) 本文借助Agent离终点的距离来表示该状态的重要性。用Wij表示state(i,j)的权重,Wij=(i+j)/40(i,j为该状态的坐标位置),离终点越近的位置权重越大,给予的附加奖赏就越大。启发后的回报函数可写成R=r+Wij*β,β取一个较小的正数,以免对已有的奖赏值产生较大的干扰。
2) 可以通过两个坐标的差值Δd=(x1-x2)+(y1-y2)来反映与终点的距离变化关系。Δd小于0反应越接近最终目标。
3) 越靠近正奖赏(也就是最终目标)的状态的Q值近似呈增大趋势,越靠近负奖赏(陷阱、障碍、墙壁)Q值呈近似减小趋势。Q值的正负也隐藏体现着与终点的距离。
从分析中可以看出,特征2),3)都从某种程度上反映了与终点距离的关系。因此动作选择函数中的协调函数可以表示如式(11):
(11)
其中θ取一个较小的数,e[s,a]表示资格迹,借助资格迹来减小调和函数H(st,at)累积效应所产生的误差。
4.2HASARSA(λ)算法
begin
初始化Q(s,a),e(s,a),从环境中提取特征,结合经验知识构造启发函数,观察目前的状态,利用基于改进的ε-greedy算法选取动作a
repeat forever
执行行为a
观察奖赏R和状态s′
R=r+r′
利用基于改进的ε-greedy算法选取动作a′
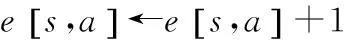
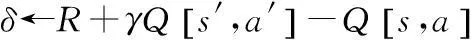
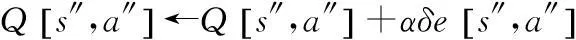

s←s′
a←a′
end repeat
end
4.3程序仿真图
建筑工程设计管理过程中,通过对BIM 模型的高效利用,有利于为建筑给排水、电气和暖通等专业的协调配合提供技术支持,满足建筑工程设计中管线整体剖析、碰撞查验、主要区域净空剖析、结构预留洞校验以及弱电专项剖析等方面的要求,并得到碰撞检查汇报、净空剖析汇报、结构预留洞优化图纸(预埋套管图)、综合管线审核汇报与优化图纸等,从而实现对工程设计管理要素的深入分析,建立与建筑工程密切相关的BIM模型并加以利用,促使实践中的建筑工程设计管理更加高效,进而有效避免工程设计管理问题的发生。
借助Matlab进行仿真,取ε为0.2,折扣率γ为0.9,步长α为0.1,得到仿真图如图2所示。
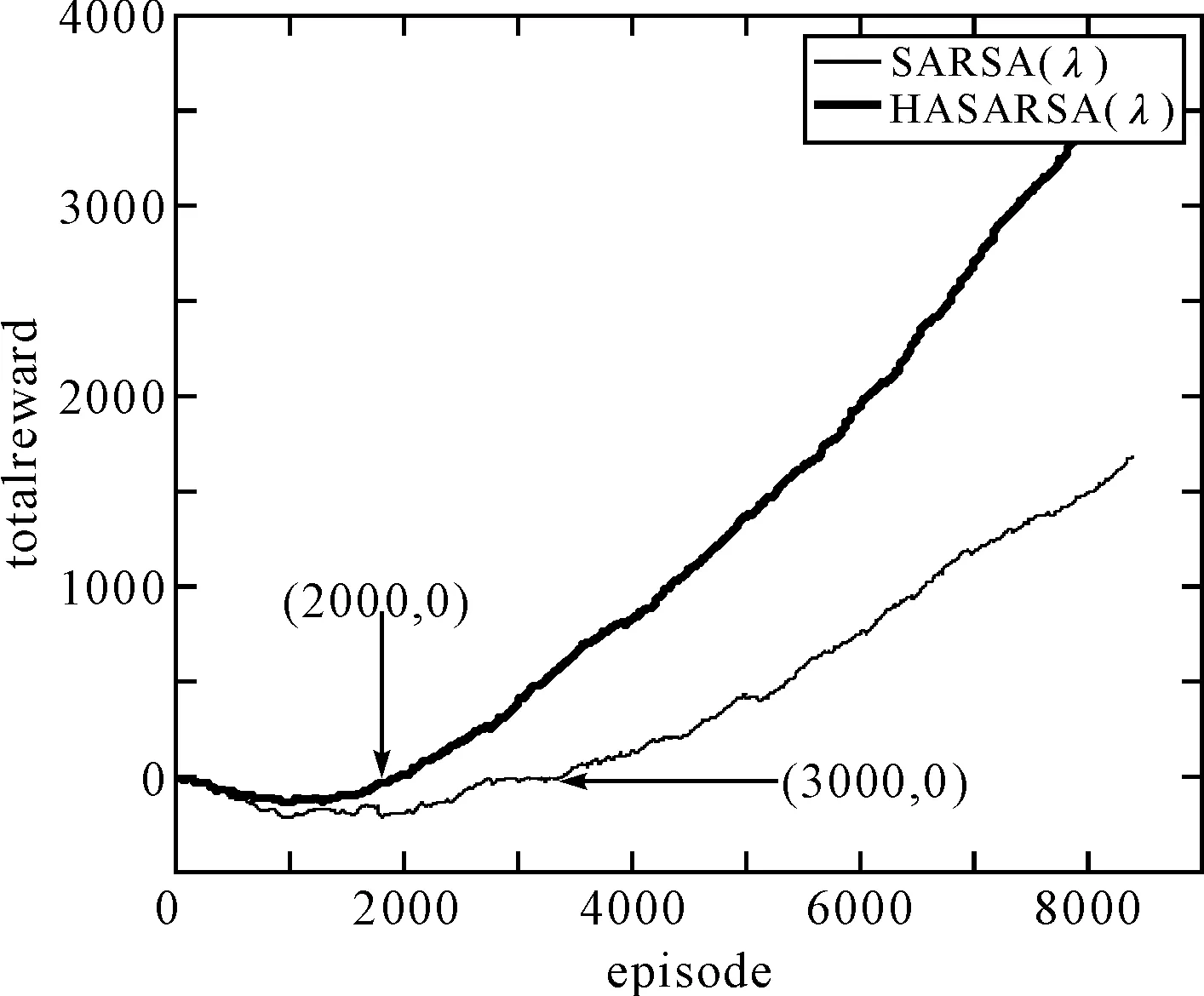
图2 两种算法的对比图
图2中横坐标episode为迭代次数,纵坐标totoalreward为总奖赏值。箭头所指位置对应两种算法总奖赏值为0的坐标。对比两个算法的结果:虽然SARSA(λ)和HASARSA(λ)算法刚开始获得了负奖赏,但HASARSA(λ)获得负奖赏明显比前者少,这表明HASARSA(λ)在执行中更多地避开了那些会获得负奖赏的状态。当算法进行2000次迭代,HASARSA(λ)总奖赏值已经开始为正值,并且接下来总奖赏值增长迅速,相比SARSA(λ)在3000次迭代后才为正值,而且增长速率比较平缓。这体现了HASARSA(λ)可以充分利用环境特征,使智能体的学习速度达到很大提升,体现了算法的可行性。
5结语
虽然HASARSA(λ)可以借助从环境特征提取启发函数,来使智能体学习知识的能力得到提升,但该算法也有一定的缺陷,定义启发函数需要依赖环境特征和知识背景,没有一个通用的标准。
参 考 文 献
[1] 史忠植.智能科学[M].北京:清华大学出版社,2006:31-35.
SHI Zhongzhi. Intelligent science[M]. Beijing: Tsinghua University Press,2006:31-35.
[2] MItchell T M.机器学习[M].曾华军,译.北京:机械工业出版社,2008:23-27.
[3] 金钊.加速强化学习方法研究[D].昆明:云南大学,2010:32-36.
JIN Zhao. Accelerate the reinforcement learning method research[D]. Kunming: Yunnan University,2010:32-36.
[4] L. P. Kael bling, M. L. Litt man, A. W. Moore. Reinforcement Learning: A Survey[R]. Arxiv preprint cs/9605103,1996:237-285.
[5] L. Tang, B. An, D. Cheng. An agent reinforcement learning model based on neural networks[C]//Bio-Inspired Computational Intelligence and Applications,2007:117-127.
[6] Jinsong, Leng, Lakhmi Jain, Colin Fyfe. Convergence Analysis on Approximate Reinforcement Learning[C]//Z.Zhang and Siekmann (Eds): KSEM 2007, LNAI 4798, pp.85-91.
[7] Rummery, G A, Niranjan, M. On-line Q_learning using connectionist system[D]. London: Cambridge University,1994.
[8] SUTTONRS, BARTO AG. Reinforcement learning: an introduction[M]. Cambridge: MIT,1998:150-185.
[9] Singh S P, Sutton R S. Reinforcement learning with replacing eligibility traces[J]. Machine Learning,1996,(22):123-158.
[10] Bianchi R A C, Ribeiro C H C, Costa A H R. Accelerating autonomous learning by using heuristic selection of actions[J]. Journal of Heuristics,2008,14(2):135-168.
SARSA (λ) Algorithm Based on Heuristic Function
MA PengweiPAN Dilin
(School of Computer Science and Engineering, Anhui University of Science and Technology, Huainan232001)
AbstractReinforcement learning is an important method of machine learning research. The success in robot path planning, intelligent control and many other successful application in decision making problems make it become an important component of machine learning. But it is also has the problem of slow convergence, slow learning, exploration and utilization of balance. In this paper, an improved algorithm is proposed based on SARSA (λ), which can extract features form the environment and get the heuristic function for strategy and reward function to accelerate the convergence speed. Through simulation comparison, this improved algorithm has faster reward feedback than SARSA(λ), it is showed that the effectiveness of the algorithm in the learning of knowledge.
Key Wordsreinforcement learning, SARSA(λ), heuristic function, assessment learning
* 收稿日期:2015年11月6日,修回日期:2015年12月26日
作者简介:马朋委,男,硕士,研究方向:机器学习。潘地林,男,教授,研究方向:机器学习。
中图分类号TP301.6
DOI:10.3969/j.issn.1672-9722.2016.05.011
猜你喜欢
中兴通讯技术(2018年2期)2018-09-21 11:11:14
中国科技博览(2018年24期)2018-06-01 10:14:38
电子技术与软件工程(2018年3期)2018-03-22 11:44:14
科学与财富(2017年30期)2018-01-01 11:54:45
软件导刊(2017年10期)2017-11-02 11:22:44
现代电子技术(2017年15期)2017-09-04 15:47:05
上海海事大学学报(2017年2期)2017-07-14 22:19:44
中学课程辅导·教学研究(2017年13期)2017-07-01 14:50:34
大经贸(2017年5期)2017-06-19 20:06:37
湖南大学学报·自然科学版(2016年10期)2016-11-30 19:02:13
