
使用关键词扩展的新闻文本自动摘要方法*
2016-06-13 00:17黄金柱李舟军杨伟铭
计算机与生活 2016年3期
李 峰,黄金柱,李舟军,杨伟铭
1.北京航空航天大学计算机学院,北京1001912.中国人民解放军后勤科学研究所,北京1001663.中国人民解放军外国语学院语言工程系,河南洛阳471003
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0372-09
使用关键词扩展的新闻文本自动摘要方法*
李峰1,2+,黄金柱3,李舟军1,杨伟铭2
1.北京航空航天大学计算机学院,北京100191
2.中国人民解放军后勤科学研究所,北京100166
3.中国人民解放军外国语学院语言工程系,河南洛阳471003
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0372-09
E-mail: fcst@vip.163.com
http://www.ceaj.org
Tel: +86-10-89056056
* The National Natural Science Foundation of China under Grant Nos. 61170189, 61370126, 61202239 (国家自然科学基金); the National High Technology Research and Development Program of China under Grant No. 2015AA016004 (国家高技术研究发展计划(863计划)); the Fund of the State Key Laboratory of Software Development Environment under Grant No. SKLSDE-2015ZX-16(软件开发环境国家重点实验室探索性自主研究课题基金).
Received 2015-08,Accepted 2015-10.
CNKI网络优先出版: 2015-10-30, http://www.cnki.net/kcms/detail/11.5602.TP.20151030.1605.002.html
Key words: keyword expansion; similar topic text; automatic summarization; graph algorithm; system implementation
摘要:提出了使用关键词扩展的新闻文本自动摘要方法。该方法从大规模的语料中提取与输入文档相近主题的文本组成背景语料,并基于背景语料进行关键词的扩展,强化关键词对文摘句的指示作用,从而提高新闻文本摘要抽取质量。研究和实验表明,该方法在Rouge-1、Rouge-2评测中取得了优于基于关键词、基于TextRank和基于Manifold Ranking方法的结果。在研究中组织制定了100篇新闻文本的4份中文新闻文本标准评价集,研制了基于关键词扩展的中文新闻文本自动摘要系统,开发了面向中文的基于ROUGE原理的新闻文本摘要结果自动评测系统,初步实现了从理论到实践的转化。
关键词:扩展;相近文本;自动摘要;图算法;系统实现
1 研究背景
自2001年美国国家标准技术研究所(National Institute of Standards and Technology,NIST)举办文档理解会议(Document Understanding Conference,DUC)以来,文本自动摘要研究得到了越来越多的关注。对于通用型自动文摘系统而言,Nenkova[1]研究发现,单文档摘要自动生成的难度往往与人们的直觉相反,要难于多文档摘要的自动生成。其根本原因是单文本自动摘要文档信息较少,可以利用的支撑信息不足,增加了单文本摘要句的判断难度[2-3]。
针对支撑信息不足的问题,近年来研究者们从两个方面进行了深入的研究:
一种是深入考察文本内部多种不同单元的相互关系,如词-句关系[4]、句-段关系[5]等,并通过图来表示这种关系,用迭代算法来确定文摘句,代表性的算法主要有TextRank[6]、LexRank[7]、Manifold Ranking[8]、GRASSHOPPER[9]等,这些算法根据PageRank[10]的思想,通过投票得分的多少来确定候选文摘句的重要程度。为取得更好的效果,也有学者尝试了基于多层图排序[4-5,11]的算法,并取得了相对较好的实验结果。
另一种是通过引入第三方资源,如领域语料[12-13]、维基百科[14]、超链接信息和网页点击日志[15-16]等来丰富文本信息,提高文摘句计算的准确度。如Louis[12]使用贝叶斯分类算法按照预先设定的领域语料,判断输入文档中词的新颖度,并据此进行更新式摘要文摘句的抽取;Delort[15]使用网页超链接数据信息来提高单个网页文本自动摘要的准确度;Sun等人[16]使用用户点击数据来进行网页文本的自动摘要生成。第三方资源的引入扩展了输入文档的可计算信息,单文本自动摘要的质量也随之得到了提升。
本文的研究属于引入第三方资源扩展的方法,不同的是本文提出的方法是从关键词指示作用入手,通过扩展并强化这种作用来提高文摘抽取的质量。在方法中,首先使用关键词抽取组件抽取输入文档的关键词,并与标题词合并生成关键词列表;其次依据抽取的关键词列表从大规模语料中抽取与输入文本主题相近的N篇语料组成一个临时的背景语料库,然后基于该背景语料库抽取与主题相关词;最后进行两级关键词的融合,再采用相关算法进行文摘句的抽取。本文方法的价值和创新主要有:
(1)设计了一套基于关键词扩展的中文新闻文本自动摘要抽取算法,通过基于Rouge的实验表明,本文算法在中文新闻文本自动摘要场景下能够取得较好的文摘质量。
(2)在中文文本自动摘要领域,尚没有一份公开的标准参考摘要,一定程度上延缓了面向中文的自动摘要研究。本文从多家媒体挑选了100篇覆盖多个主题的新闻文本,并制定了4份共400篇人工摘要,实验表明参考摘要具备较好的参考价值。
(3)实现了基于关键词、基于TextRank[6]和基于Manifold Ranking[8]的文摘抽取算法;实现了基于关键词扩展方法的中文新闻文本自动摘要系统,实现了面向评测集的人工摘要制定辅助工具;研制了基于Rouge评测原理的中文新闻文本自动摘要评价系统。
2 基于关键词扩展的中文新闻文本自动摘要相关算法
本文设计的新闻文本自动摘要方法可分解为两部分:一是利用大规模语料进行关键词扩展;二是利用扩展后的关键词来抽取文摘。总体流程如图1所示。
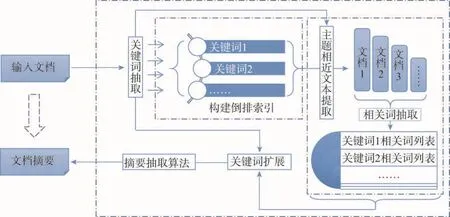
Fig.1 Flow-process diagram of method图1 方法流程图
主要步骤为:
(1)使用关键词抽取组件从输入文档中抽取关键词,得到一级关键词集={k1,k2,…,ki}。
2.1基于相近语料的关键词扩展算法
基于相近语料的关键词扩展算法包括两个部分:一是基于大规模语料的主题相近文本的提取;二是基于提取的文本进行关键词扩展。
2.1.1基于大规模语料的主题相近文本提取
一般而言,文本的关键词能够较大程度上承载文本的主题,两篇文本的关键词重叠度越高,则可以认为两者表述的主题可能就越相近。基于此,本文设计了一种从大规模语料提取主题相近文本的方法。该方法通过考察输入文档关键词在语料中的分布来获取相近文档,主要涉及关键词抽取以及基于关键词分布的主题相近文本获取。在关键词抽取部分,本文直接利用NLPIR2015(http://ictclas.nlpir.org/ downloads)关键词抽取组件抽取关键词,并使用关键词作为倒排索引项对大规模语料库进行倒排。在倒排索引构建完成后,对于输入的任意一篇文档,使用如下算法从大规模语料库中提取主题相近的文本:
算法1主题相近文本提取算法
输入:输入文档;要提取的主题相近文本个数n。
输出:n篇与输入文档主题最为相近的文档列表。


算法1中,mergedKeyWordsToDict函数用于合并正文关键词与标题关键词,在合并前先为标题关键词分配正文关键词的平均得分值,合并时选择正文关键词中没有的或者得分高于正文关键词的标题词加入列表,作为合并结果。由于每篇新闻的关键词集元素不重复,输入文档中的关键词集元素也保持了唯一性,在文档长度差异不大时,包含输入文档的关键词个数越多,即关键词交叠次数越多,则可认为其与输入文档主题越相近。为降低计算复杂度,在建立索引和处理输入文档时,算法进行了粗略处理,统一把内容关键词抽取个数限制为8个。
2.1.2基于主题相近文本的关键词扩展
文本中距离越相近的实词往往语义越相关,主题越相近的文本中相关词同现的可能性越高。例如“根据救灾需要不断增加救援队伍、医疗专家、机械装备、物资药品和应急资金等”这句话中,“医疗”、“专家”、“装备”、“物资”、“药品”这些词,因在同一个句子中共现而具有一定的相关性;在描述救灾主题的文本中这些词中的几个或全部也经常出现,即这些词对“救灾”亦有指示作用。根据这一思路,本文设计了一种基于主题相近文本的关键词扩展方法。该方法在同一相近主题文本集合中,通过考察输入关键词左右一定跨距内的实词相关程度来进行扩展,在测量实词与输入关键词的相关程度时,主要考查其出现的频数以及与关键词间的距离。基于相近文本的关键词扩展算法如下:
算法2基于相近文本的关键词扩展算法
输入:输入文档,关键词集topKeyWords,相近文本集similarDocuments,要提取的相关词个数为x,关键词相关词允许的最大跨距为p。
输出:带有相关度得分值的相关词表。


算法2中,computeKeyWords函数负责为关键词从相近文档中提取相关词,其通过统计关键词在相近文档中p个跨距范围内的实词作为候选相关词,在统计结束后,对于每个相关词而言,若其出现的频率为f,与ki的距离算术均值为g,则使用式(1)计算其与关键词的相关度得分s:得到当前关键词的相关词列表后,按得分值倒序排列,依次取x个词组成最终相关词列表并进行分值归一化处理后返回。在遍历完关键词集后,可以得到所有关键词的相关词集合。

因每个关键词在输入文档中的关键程度不同,则其相关词对输入文档摘要句的指示作用也应存在差异,在算法中使用关键词与相关词得分的乘积作为相关词的最终得分。
2.2基于关键词扩展的文摘句抽取
在获取输入文档的关键词集K及其相关词集T后,基于这些词对文摘句的指示作用来抽取文摘句,具体方法是:通过计算句子S包含关键词及扩展词的个数以及这些词的得分来确定文摘候选句权重的大小。句子S的权重值Sscore计算公式如下:

其中,lw为关键词或扩展词词长;ls为当前句长;vw为关键词或扩展词的得分值。
3 系统实现与实验分析
3.1中文新闻文本自动摘要系统的实现
基于前文描述的思路及相关算法,本文采用C# 4.0编程语言实现了一套中文新闻文本自动摘要系统,主界面如图2所示。
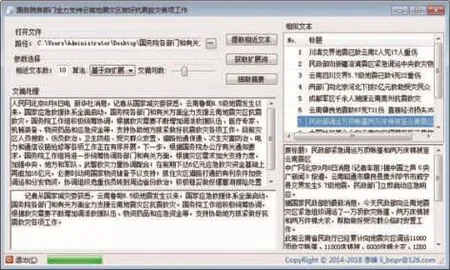
Fig.2 Automatic summarization system for Chinese news text图2 中文新闻文本自动摘要系统
3.2实验设计与结果分析
3.2.1参与评测的文摘抽取算法
为检验算法的有效性以及最终抽取的摘要结果质量,选取基于关键词的文摘抽取算法、TextRank算法和Manifold Ranking算法作为实验的Baseline。其中,基于关键词的算法根据句子包含关键词数目的多少来确定文摘句,是一种机械式方法;TextRank算法为无指导的图排序方法;Manifold Ranking算法为有指导的图排序方法。后两种算法具备较好的代表性,取得了相对较好的实验结果[6,8]。
3.2.2实验数据
实验以新浪2012年共150 366篇新闻语料作为语料支撑(http://news.sina.com.cn),采用NLPIR2015分词和抽取关键词。在评测过程中,为保证数据的科学性,从23家网络或报纸媒体采集了2014年10月27日至11月4日期间共341篇新闻文本作为候选参评语料,在剔除句子总数小于5个以及一些视频、访谈或花边娱乐新闻后,取100篇新闻参与文本摘要自动摘取测试,这100篇新闻涉及政治、法律、反恐、环境治理、自然灾害、官员贪腐、疾病防治等多个主题。在实验之前,对这100篇新闻进行了预处理,包括去除网络标记符、统一编码格式和人工辅助的文本校对与断句等。之后,组织了4位具有硕士以上学历的不同领域人员对上述100篇新闻抽取摘要。在摘要处理时,根据中文新闻撰写风格要求尽量保留新闻首句作为文摘句,且不允许对摘录的句子进行人工修改,经测试后确定摘要句抽取比例为原文句子数的30%,当句子数不是整数时,取其整数的上边界数为摘要句个数。最后得到了4份共400篇摘要结果作为参考摘要。
3.2.3评测方法及工具
文本自动摘要结果的评价,比较著名的是由Lin[17]提出的基于n-gram共现的ROUGE(recall oriented understudy for gisting evaluation)评测方法。该方法的评测结果与人工评测结果具有良好的相关性,并且更加客观,已成为文摘评价技术的通用标准之一[18]。目前基于ROUGE的文本自动摘要评价对象以及相应的参考摘要集多为基于英文的文本,还没有一个公开可用的中文新闻文本评价工具和评价集,也没有一个适用于中文文摘评价的ROUGE工具集。而如果使用人工打分的方式进行摘要结果的评测,不可避免地会带来较大的主观性。
本文在深入研究ROUGE评价原理及工具的基础上,开发了相应的中文新闻文本ROUGE评价工具,如图3所示。

Fig.3 ROUGE evaluation tool for Chinese news text automatic summarization图3 中文新闻文本自动摘要ROUGE评价工具
在评测过程中,使用Rouge-1、Rouge-2两种评价指标来考察每种算法抽取文摘的质量。在计算得分值时,实验以是否包含新闻首句,是否以实词(词性标注结果为动词、名词或形容词的词)为统计指标进行组合,从4个角度对比考察各种方法的实际效果。在基于TextRank和Manifold Ranking算法中,依据句子间重叠的实词个数来测量相似度大小[19],其中在TextRank算法中图节点间插入边的条件是句子相似度值大于0.05[4];在Manifold Ranking算法中,取新闻文本的首句作为流形排序的指导句。
3.2.4评测结果分析
在新闻文本中,首句往往是新闻的导语,涵盖相对较多的新闻要素,并对全文起着提纲挈领的作用;同时,在句子中实词相对而言更能表达文本的意义。在实验评测中,基于上述评测数据和方法,以是否包含首句,是否仅统计实词作为分类方法,将所有机器摘要与人工摘要的Rouge-1、Rouge-2得分情况数据进行汇总。其中,KW-Based、KWE-Based、TRBased和MFR-Based分别代表基于关键词、基于关键词扩展、基于TextRank和基于Manifold Ranking的方法,Refer-1、Refer-2、Refer-3、Refer-4分别代表4份人工制定的参考摘要。下文首先针对参考摘要进行评测,以确保参考摘要的质量;其次分析基于关键词扩展方法取得的摘要结果;最后分别就该方法与其他3种方法进行对比实验,并进行总结。
(1)对参考摘要的评测。文本的难度以及人们不同的认知背景会对参考摘要的质量带来较大的影响,为确保参考摘要集具备较好的稳定性和参考价值,分别选取4份参考摘要以全部参考摘要集为对象,进行Roug-1和Rouge-2的评测。从表1的数据可以看出,4份摘要在不同的测试条件和评测指标中,均保持了较好的稳定性,表明了本文人工制定的4份中文新闻文本摘要具备较好的参考价值。
(2)基于关键词扩展的方法。本文方法取得的文摘质量评测结果如表2所示。从结果来看,在摘要结果中包含首句,当不考虑词性时,两种评测指标均取得了较好的得分值,而当去除虚词时,得分出现较为明显的跌落。同时,在不同条件下采用不同的评测方式,最高得分与最低得分之间差距十分明显,高达约33.0个百分点,约占最高得分值的42.8%,并接近于最低得分值。
(3)与基于关键词的方法相比。基于关键词的方法是一种简单的未经扩展的文摘抽取方法,其各项评测分值如表3所示。可以看出,基于关键词的方法得分要低于表2中基于关键词扩展方法的各项得分,且当采用不同的条件及评测方式时,基于关键词的方法最高得分与最低得分值间的差异高达38.6个百分点,这种方式抽取的摘要在稳定性上表现较差,摘要结果与人工摘要结果差异较大。不难发现,基于关键词扩展的方法要明显优于仅基于关键词的方法。
(4)与基于TextRank的方法相比。基于TextRank的方法取得的结果如表4所示。与基于关键词扩展的方法相比,两者各项得分值相差不大,但基于关键词扩展的方法要略优。在不同的条件下采用不同的评测方式,TextRank方法最高值与最低值间的差异约为34.2个百分点,在稳定性上比基于关键词扩展的方法低1.2个百分点。
(5)与基于Manifold Ranking的方法相比。基于Manifold Ranking的方法取得的文摘评测结果如表5所示。在Rouge-1和Rouge-2评测中,该方法得分值均低于基于关键词扩展的方法。在不同的条件下采用不同的评测方式,Manifold Ranking方法最高值与最低值间的差异约为31.0个百分点,在整体稳定性上表现最佳。经仔细分析发现,在实验中基于Manifold Ranking的方法选择了新闻的首句作为指导句,而新闻首句往往对全文起着提纲挈领的作用,在Manifold Ranking迭代计算时无论是否要求在结果中包含首句,总会受到新闻首句的影响,这就保证了不会出现极差的文摘抽取结果,从而在稳定性上表现较好。

Table 1 ROUGE evaluation score of four reference summaries表1 4份参考摘要的ROUGE评测得分
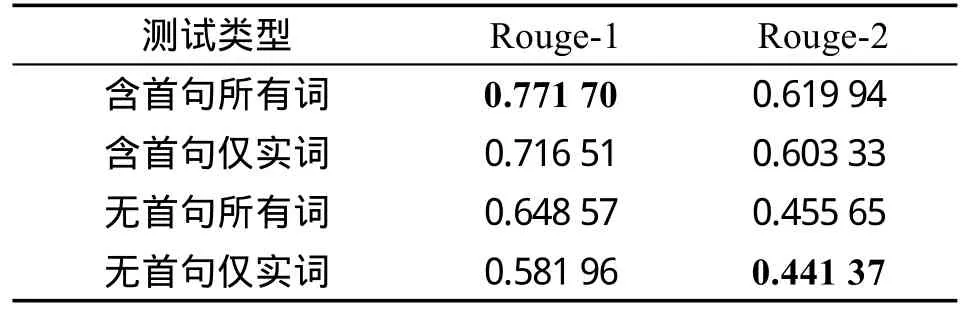
Table 2 Evaluation results of KWE-Based表2 基于关键词扩展方法的摘要评测结果
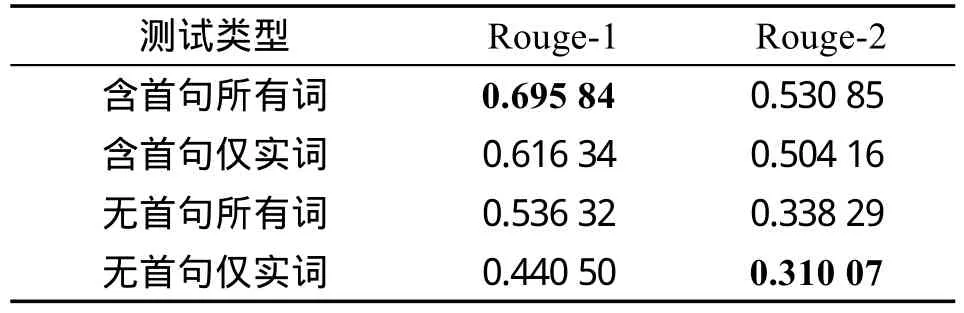
Table 3 Evaluation results of KW-Based表3 基于关键词方法的摘要结果评测
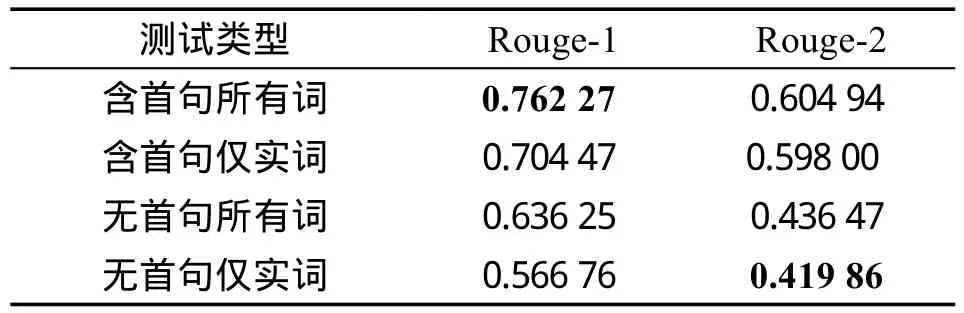
Table 4 Evaluation results of TR-Based表4 基于TextRank方法的摘要评测结果
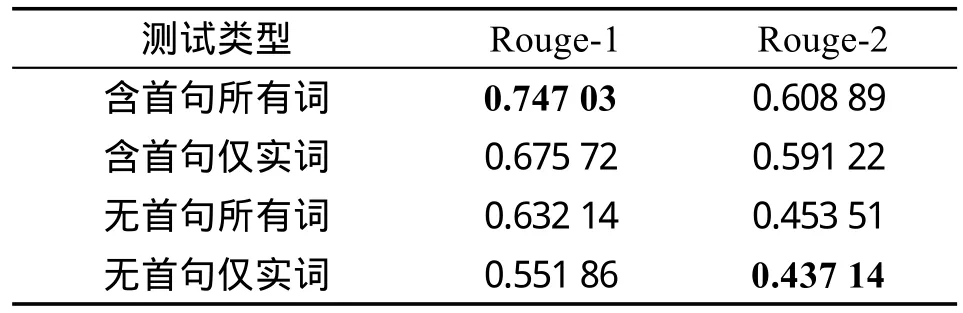
Table 5 Evaluation results of MFR-Based表5 基于Manifold Ranking方法的摘要评测结果
3.2.5结论
本文采用不同的方法作为对比参考,使用多个评测指标对基于关键词扩展的方法进行了全面的测试。从评测结果可以得到以下结论:
(1)基于关键词扩展的文本自动摘要方法在Rouge-1、Rouge2评测中,取得了优于基于关键词、TextRank和Manifold Ranking方法的结果;在稳定性上,得益于新闻首句的指导作用,Manifold Ranking方法略占优势,但本文方法与基于关键词和基于Text-Rank方法相比依然较好。
(2)首句对新闻文本的摘要质量影响较大,是否包含首句会为各种方法的文摘评测结果带来至少10个百分点的得分差异;在Rouge-1、Rouge-2评测中,是否仅考虑实词也会为评测结果带来5到10个百分点的得分差异。可以认为,新闻文本首句对文摘质量影响较大,同时是否考虑词性也会影响对文摘结果的评测。
(3)无论采用何种评测方式,机器摘要与人工摘要间的差距还是比较明显的,几种算法在抽取文摘结果质量的稳定性上还需要进一步加强。
4 结束语
本文设计了一种快速提取相近文本的方法,设计了基于背景语料的关键词扩展及融合方法,并基于关键词的扩展实现了一套中文新闻文本自动摘要系统;为评测方法抽取文摘的有效性,为100篇新闻制定了4份标准的人工摘要作为评测集,并设计开发了适用于中文新闻文本摘要的ROUGE评价工具,最后进行了文摘抽取实验,并对实验结果进行了对比分析。研究表明,通过从大规模语料中提取与输入文档主题相近的文本组成背景语料,并基于这些背景语料对输入文档的关键词进行扩展融合,能够进一步增强关键词对文摘句的指示作用,并取得相对较好的文摘结果。下一步,将在各种方法的融合上开展进一步的研究,并尝试在短文本摘要领域以及其他语种文本自动摘要领域进行新的探索。
References:
[1] Nenkova A. Automatic text summarization of newswire: lessons learned from the document understanding conference[C]//Proceedings of the 20th National Conference on Artificial Intelligence and the 17th Innovative Applications of Artificial Intelligence Conference, Pittsburgh, USA, Jul 9-13, 2005. Cambridge, USA: MIT Press, 2005: 1436-1441.
[2] Jones K S. Automatic summarizing: the state of the art[J]. Information Processing and Management, 2007, 43(6): 1449-1481.
[3] Elfayoumy S, Thoppil J. A survey of unstructured text summarization techniques[J]. International Journal of Advanced Computer Science and Applications, 2014, 5(4): 149-154.
[4] Wan Xiaojun, Yang Jianwu, Xiao Jianguo. Towards an iterative reinforcement approach for simultaneous document summarization and keyword extraction[C]//Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics, Prague, Czech Republic, Jun 23-30, 2007. Stroudsburg, USA:ACL, 2007: 552-559.
[5] Xie Hao, Sun Wei. Paragraph-sentence mutual reinforcement based automatic summarization algorithm[J]. Computer Science, 2013, 40(11A): 246-250.
[6] Mihalcea R, Tarau P. TextRank: bringing order into texts [C]//Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, Jul 25-26, 2004. Stroudsburg, USA:ACL, 2004: 404-411.
[7] Gunes E, Radev D R. LexRank: graph-based lexical centrality as salience in text summarization[J]. Journal of Artificial Intelligence Research, 2004, 22(1): 457-479.
[8] Wan Xiaojun, Yang Jianwu, Xiao Jianguo. Manifold-ranking based topic-focused multi-document summarization[C]// Proceedings of the 20th International Joint Conference on Artificial Intelligence, Hyderabad, India, Jan 6-12, 2007. Berlin, Heidelberg: Springer, 2007: 2903-2908.
[9] Zhu Xiaojin, Goldberg A, van Gael J, et al. Improving diversity in ranking using absorbing random walks[C]//Proceedings of the Human Language Technology Conference of the North American Chapter of the Association of Computational Linguistics, New York, USA, Apr 22-27, 2007. Stroudsburg, USA:ACL, 2007: 97-104.
[10] Liu Tongtong. The research and implementation of the Page-Rank algorithm with the correlation[D]. Haikou: Hainan University, 2009.
[11] Deng Hongbo, Lyu M R, King I.Ageneralized co-HITS algorithm and its application to bipartite graphs[C]//Proceedings of the 15th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Paris, France, Jun 28-Jul 1, 2009. New York, USA:ACM, 2009: 239-248.
[12] Louis A. A Bayesian method to incorporate background knowledge during automatic text summarization[C]//Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, USA, Jun 22-27, 2014. Stroudsburg, USA:ACL, 2014: 333-338.
[13] Reddy P V, Vardhan B V, Govardhan A A. Corpus based extractive document summarization for indic script[C]//Proceedings of the 2011 International Conference on Asian Lan-guage Processing, Penang, Malaysia, Nov 15- 17, 2011. Washington, USA: IEEE Computer Society, 2011: 154-157.
[14] Pourvali M. A new graph based text segmentation using Wikipedia for automatic text summarization[J]. International Journal of Advanced Computer Science and Applications, 2012, 3(1): 35-39.
[15] Delort J Y, Bouchon-Meunier B, Rifqi M. Enhanced Web document summarization using hyperlinks[C]//Proceedings of the 14th ACM Conference on Hypertext and Hypermedia, Nottingham, UK, Aug 26-30, 2003. New York, USA: ACM, 2003: 208-215.
[16] Sun Jiantao, Shen Dou, Zeng Huajun, et al. Web-page summarization using clickthrough data[C]//Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, Aug 15-19, 2005. New York, USA:ACM, 2005:194-201.
[17] Lin C Y. ROUGE: a package for automatic evaluation of summaries[C]//Proceedings of the 42nd Annual Meeting of the Association for Computational Linguistics, Barcelona, Spain, Jul 21-26, 2004. Stroudsburg, USA:ACL, 2004: 74-81.
[18] Ng J P, Bysani P, Lin Ziheng, et al. Exploiting categoryspecific information for multi-document summarization[C]// Proceedings of the 24th International Conference on Computational Linguistics, Mumbai, India, Dec 8-15, 2012: 2093-2108.
[19] Zhang Peiying. Model for sentence similarity computing based on multi-features combination[J]. Computer Engineering and Applications, 2010, 46(26): 136-137.
附中文参考文献:
[5]谢浩,孙伟.基于段落-句子互增强的自动文摘算法[J].计算机科学, 2013, 40(11A): 246-250.
[10]刘彤彤.融入了相关性的PageRank算法的研究与实现[D].海口:海南大学, 2009.
[19]张培颖.多特征融合的语句相似度计算模型[J].计算机工程与应用, 2010, 46(26): 136-137.

LI Feng was born in 1982. He received the Ph.D. degree in computational linguistics from PLA University of Foreign Languages in 2012. Now he is a postdoctoral fellow at School of Computer Science and Engineering, Beihang University. His research interests include natural language processing, big data analytics and corpus linguistics, etc.李峰(1982—),男,河南固始人,2012年于解放军外国语学院计算语言学专业获得博士学位,现为北京航空航天大学计算机学院博士后,主要研究领域为自然语言处理,大数据分析,语料库语言学等。

HUANG Jinzhu was born in 1980. He is a Ph.D. candidate at PLA University of Foreign Languages. His research interests include natural language processing and knowledge base construction, etc.黄金柱(1980—),男,新疆鄯善人,解放军外国语学院博士研究生,主要研究领域为自然语言处理,知识库建设等。

LI Zhoujun was born in 1963. He received the Ph.D. degree in computer science and technology from National University of Defense Technology in 1999. Now he is a professor and Ph.D. supervisor at Beihang University, and the member of CCF, EATCS, IEEE and ACM. His research interests include natural language processing, information security and big dada analysis, etc.李舟军(1963—),男,湖南湘乡人,1999年于国防科技大学计算机科学与技术专业获得博士学位,现为北京航空航天大学计算机学院教授、博士生导师,CCF高级会员、欧洲理论计算机科学学会(EATCS)会员、IEEE会员、ACM会员,主要研究领域为自然语言处理,信息安全,大数据分析等。

YANG Weiming was born in 1982. He received the M.S. degree in human geography from PLA Information Engineering University in 2006. His research interests include knowledge base construction and geospatial data mining, etc.杨伟铭(1982—),男,江西鹰潭人,2006年于解放军信息工程大学获得人文地理学硕士学位,主要研究领域为知识库建设,地理信息数据挖掘等。
Automatic Summarization Method of News Texts Using Keywords Expansionƽ
LI Feng1,2+, HUANG Jinzhu3, LI Zhoujun1, YANG Weiming2
1. School of Computer Science and Engineering, Beihang University, Beijing 100191, China
2. Logistics Science Research Institute of PLA, Beijing 100166, China
3. Department of Language Engineering, PLAUniversity of Foreign Languages, Luoyang, Henan 471003, China
+ Corresponding author: E-mail: li_bopr@126.com
LI Feng, HUANG Jinzhu, LI Zhoujun, et al. Automatic summarization method of news texts using keywords expansion. Journal of Frontiers of Computer Science and Technology, 2016, 10(3): 372-380.
Abstract:This paper proposes an automatic summarization method of news texts using keywords expansion. This method extracts texts with similar topics from large-scale data for input text to form background data, and based on background data this method makes keywords expansion so that keywords can play more important role in guiding summary sentences and consequently improves the quality of news text summarization. The study and experiments show that the results obtained in Rouge-1 and Rouge-2 evaluations are better than those of methods based on keyword, TextRank and Manifold Ranking. This paper constructs a Chinese evaluation set which covers 100 news texts divided into 4 groups, and also develops keyword-based Chinese news text automatic summarization system and Chinese news text automatic evaluation system based on ROUGE theory. Through these systems, the theory put forward in the paper is realized and tested successfully.
doi:10.3778/j.issn.1673-9418.1509085
文献标志码:A
中图分类号:TP391
猜你喜欢
家庭影院技术(2021年2期)2021-03-29
家庭影院技术(2021年1期)2021-03-19
环境影响评价(2020年2期)2020-12-02
中国自行车(2018年11期)2018-12-03
中国自行车(2017年1期)2017-04-16
宝藏(2017年2期)2017-03-20
海外华文教育(2016年1期)2017-01-20
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
