
基于卷积神经网络的纹理分类方法研究*
2016-06-13 00:17:11聂林红庞彦伟
计算机与生活 2016年3期
冀 中,刘 青,聂林红,庞彦伟
天津大学电子信息工程学院,天津300072
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0389-09
基于卷积神经网络的纹理分类方法研究*
冀中+,刘青,聂林红,庞彦伟
天津大学电子信息工程学院,天津300072
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0389-09
E-mail: fcst@vip.163.com
http://www.ceaj.org
Tel: +86-10-89056056
* The National Natural Science Foundation of China under Grant Nos. 61271325, 61472273 (国家自然科学基金); the Elite Scholar Program of Tianjin University under Grant No. 2015XRG-0014 (天津大学“北洋学者-青年骨干教师”项目).
Received 2015-05,Accepted 2015-07.
CNKI网络优先出版: 2015-07-14, http://www.cnki.net/kcms/detail/11.5602.TP.20150714.1558.001.html
摘要:深度卷积神经网络(convolutional neural network,CNN)在许多计算机视觉应用中都取得了突破性进展,但其在纹理分类应用中的性能还未得到深入研究。为此,就CNN模型在图像纹理分类中的应用进行了较book=390,ebook=94为系统的研究。具体而言,将CNN用于提取图像的初步特征,此特征经过PCA(principal component analysis)降维后可得到最终的纹理特征,将其输入到SVM(support vector machine)分类器中便可获得分类标签。在4个常用的纹理数据集上进行了性能测试与分析,结果表明CNN模型在大多纹理数据集上均能取得很好的性能,是一种优秀的纹理特征表示模型,但其对包含旋转和噪声的纹理图像数据集仍不能取得理想结果,需要进一步提升CNN的抗旋转能力和抗噪声能力。另外,有必要构建具有足够多样性的大规模纹理数据集来保证CNN性能的发挥。
关键词:纹理分类;卷积神经网络(CNN);计算机视觉
1 引言
纹理在自然界中广泛存在,几乎所有自然界事物的表面都是一种纹理,它包含了图像的表面信息与其周围环境的关系,兼顾了图像的宏观信息和微观结构,因此纹理分析在计算机视觉和多媒体分析领域占据重要地位。传统的纹理分类算法以局部二值模式(local binary pattern,LBP)[1]为代表,并以它为基础提出了一系列的改进算法,例如ELBP(extended LBP)[2]、CLBP(completed LBP)[3]、LFD(local frequency descriptors)[4]、BRINT(binary rotation invariant and noise tolerant)[5]等。
近年来,深度卷积神经网络(convolutional neural network,CNN)在图像分类任务中取得了突破性的进展[6-8],并吸引了许多学者和研究人员投身其中。CNN成功的原因之一是大数据为深度模型的训练提供了基础。其中,ILSVRC(ImageNet large-scale visual recognition challenge)[9]作为视觉识别系统性能的测试平台,在深度架构的发展中起到了至关重要的作用。一些优秀的CNN模型,例如ConvNet[6]、CaffeNet[10]、OverFeat[11]、GoogLeNet[12]等均以此为基础构建。近期,在研究CNN算法和结构的同时,一些学者还尝试将ImageNet上训练的CNN直接应用于场景分类[13]、目标检测[14]和图像检索[15]等其他视觉识别任务中,实验结果表明预训练的CNN可以作为通用的特征描述符使用。此外,文献[16]进一步提出应该将CNN作为计算机视觉领域中的首选模型。
虽然预训练的CNN在许多计算机视觉任务中都取得了良好的效果,但是其在纹理分类任务中的性能还未得到深入研究。为此,本文较为系统地研究了CNN模型在纹理分类中的性能,通过在4个常用的纹理数据集上的测试与分析,并与传统的纹理分类算法相比较,表明了其在纹理分类任务中的有效性。由于自然界中采集的纹理图像大都包含不同程度的旋转、噪声等变化,本文还针对CNN在纹理分类中的抗旋转和噪声的性能进行讨论,指出有必要提升CNN在纹理分类中的抗旋转能力和抗噪声能力,以及构建具有足够多样性的大规模纹理数据集。此外,本文还将预训练的CNN与直接训练的CNN模型进行对比,表明了预训练CNN模型的有效性。
2 算法描述
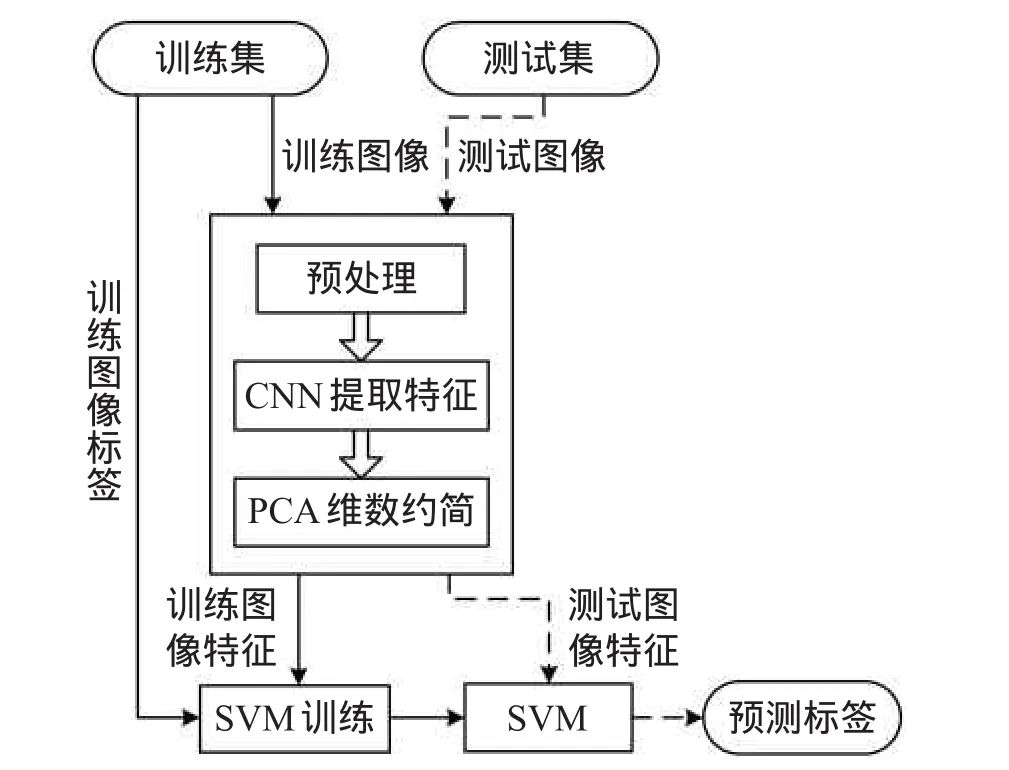
Fig.1 Process of texture classification with CNN图1 CNN用于纹理分类的具体流程
本文将在ImageNet数据集上训练得到的CNN模型应用于纹理分类任务,其具体过程如图1所示。在训练阶段,首先使用CNN提取预处理后的训练图像的特征;其次利用PCA(principal component analysis)技术对所提CNN特征进行维数约简得到最终的训练图像特征;最后结合训练图像的特征和标签,训练一个SVM(support vector machine)分类器。在测试阶段,测试图像经过与训练阶段相同的预处理、CNN特征提取以及PCA降维等过程得到测试图像的特征,并将所得特征作为已训练完成的SVM的输入,其输出即为测试图像的预测标签。下面介绍所提方法的具体细节。
2.1预处理
CNN作为一种神经网络结构,其超参数(hyperparameter)在训练时就已经确定。这些超参数包括神经网络的层数、每一层网络中的神经元个数等。因此,为了能够使用预训练的CNN提取纹理图像的特征,需要对纹理图像进行预处理。
预处理过程主要包括两个步骤:
(1)将纹理图像的尺寸统一调整为CNN在预训练时所设计的输入大小。针对本文所使用的CNN,纹理图像在输入网络之前均被调整为以下尺寸,即(227×227像素)×3通道。
(2)对调整后的纹理图像进行均值归一化操作。本文所使用的CNN是在ImageNet数据集上训练所得,因此在使用CNN提取特征前,需要将纹理图像减去ImageNet数据集的平均图像。
2.2 CNN特征提取
本文所使用的预训练模型为BVLC Reference CaffeNet(简称为CaffeNet),该模型是ConvNet模型的一个变体。CaffeNet包含5个卷积层(convolutional layer),3个最大池化层(max pooling layer)和3个全连接层(fully-connected layer),具体结构描述如表1所示。下面介绍CaffeNet中重要的组成部分。

Table 1 Structure and parameters of CaffeNet表1 CaffeNet网络结构与参数
2.2.1卷积层
卷积层是CNN的核心结构。卷积层中每个神经元的权值矩阵被称为卷积核(kernel)或者滤波器(filter),卷积核与输入之间是局部连接的,因而其网络参数与全连接方式相比减少很多。每个卷积核通过“滑动窗口”的方式提取出输入数据不同位置的特征,所得结果为一个二维特征集合,即特征图(feature map)。本层的特征图将作为下一层的输入继续传播。
通过训练,卷积核可以提取出某些有意义的特征,例如第一个卷积层的卷积核类似于Gabor滤波器[17],可以提取边缘、角等信息。CaffeNet包含5个卷积层(conv1~conv5),其卷积核大小(kernel size)分别为112、52、32、32、32像素,输出的特征图数目分别为96、256、384、384、256个,卷积的步长(Stride)分别为4、1、1、1、1像素。多层的结构可以对输入的图像进行逐层抽象,获得更高层次的分布式特征表达。
2.2.2池化层
池化(pooling)是计算机视觉与机器学习领域中的常见操作。所谓池化,就是将不同位置的特征进行聚合。常见的池化方式有平均池化(mean pooling)、最大池化(max pooling)和随机池化(stochastic pooling)等。CaffNet模型采用最大池化的方式,该模型中的conv1、conv2和conv5层后均连接了一个最大池化层,其池化尺寸均为32像素,池化步长均为2像素。通过池化,不仅可以降低特征的维数,还可以提高特征的鲁棒性。
2.2.3全连接层
相比于卷积层的局部连接方式,全连接层的全连接方式将会带来更多的网络参数。CaffeNet模型的最后3层为全连接层(full6~full8)。由于之前的卷积层及池化层已经将特征的维数降低至可接受的大小,因而使用全连接层并不会导致特别严重的计算负担。
在CaffeNet的3个全连接层中,full6和full7层均为包含4 096个神经元的隐藏层,而full8层为1 000路的softmax输出层。虽然这3个全连接层的输出都可作为通用的特征使用,但文献[18]中指出,将预训练的CNN应用于物体识别、图像检索等计算机视觉任务时,full6层输出的特征可以获得最好的效果,因此本文使用full6层的输出作为纹理图像的特征。
2.2.4 Rectified Linear Units
常见的激活函数主要包括sigmoid函数f(x)= (1+e-x)-1和双曲正切函数f(x)=tanh(x)。然而,就训练速度而言,使用这些饱和非线性激活函数要慢于使用非饱和非线性激活函数f(x)=max(0,x)[6],该函数被称为Rectified Linear Units(ReLU)[19]。
文献[20]指出,除了速度优势之外,ReLU还具有以下两个特点:
(1)相比于传统激活函数,ReLU的单边抑制更符合生物学观点;
(2)ReLU可以获得稀疏表达,其性能比传统激活函数的性能更好。
因此,CaffeNet模型使用ReLU作为激活函数。具体而言,CaffeNet的conv1~conv5以及full6~full7层后均使用ReLU获取激活值以继续前向传播。
2.2.5 Local Response Normalization
CaffeNet模型在conv1和conv2层后使用Local Response Normalization(LRN)方法来提升网络的泛化能力,如文献[6]所述,LRN具体实现如下:
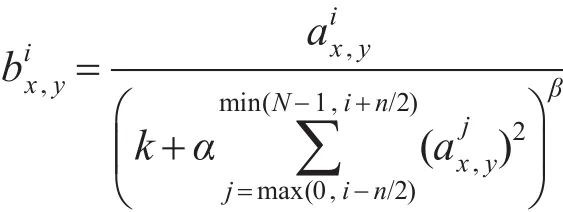
其中,aix,y表示把第i个卷积核作用于位置(x,y)并经过ReLU函数后的激活值;k、n、α和β为LRN的超参数,通常情况下取值为k=2,n=5,α=10-4,β=0.75。
2.3 PCA维数约简
本文使用CaffeNet中full6层的输出作为纹理图像的特征,该层包含4 096个神经元,相应的输出向量有4 096维,维数相对较高。因此,为降低特征维度,以减小计算负担,本文使用经典的PCA降维算法对所得特征进行维数约简,获得最终的纹理图像特征,其中所采用的降维原则是保留95%的能量。
2.4 SVM训练
训练图像特征提取完成后,结合训练图像的特征和标签可以训练得到一个SVM分类器。本文使用LIBLINEAR[21]工具包进行SVM的训练。LIBLINEAR是一个用于大规模线性分类的开源工具包,其中onevs-the-rest策略被用于多分类SVM的实现。
3 实验
目前主流的纹理数据集有CUReT[22]、KTH-TIPS[23]、KTH-TIPS_2b[23]和Outex_TC10[24]。本文分别对前3个数据集进行测试,验证CNN特征的有效性,并在下文讨论中,基于Outex_TC10数据集对CNN的抗旋转性能进行探讨。
实验选取的对比算法主要有:ELBP[2](IVC 2012)、CLBP[3](TIP2010)、VZ_MR8[22](IJCV 2005)、VZ_Joint[25](PAMI 2009)、LFD[4](PR 2013)和BRINT[5](TIP2014),这些对比算法既包括一些经典的算法,也包括目前在各个数据集上取得最好性能的算法,对比算法的实验性能均为相应文章所提供的数值。由于这些对比算法大多没有同时对这4个数据集进行实验验证,在接下来的实验对比分析中,这些对比算法并不是在每个数据集都有体现。如未加说明,实验中CNN即指利用ImageNet预训练好的CNN模型CaffeNet。下面分别介绍在这4个数据集上的实验结果及分析。
3.1 CUReT数据集
CUReT数据集包含61类在不同视角、光照和旋转角度条件下采集的纹理图像。在每一类图像中,92张采集角度小于60°的纹理图被选择出来用于实验,每张图像尺寸为200×200像素。在实验过程中,本文使用与文献[22]中相同的划分方式,即在每类纹理中,随机抽取N张图像作为训练样本,剩余的92-N张图像作为测试样本,数目N依次选取46、23、12和6。在固定数目N的情况下,随机实验重复进行10次,使用10次实验结果的均值作为算法的最终分类结果。
表2给出了CUReT数据集上不同算法性能的比较。由表中数据可以看出,与其他算法相比,在选取训练样本不同的情况下,CNN算法均达到了较好的分类性能,例如在N=46的情况下,CNN相比于ELBP、CLBP_S/M/C、VZ_MR8、VZ_Joint和LFD24,3等算法,其分类准确率分别提升了0.87%、1.79%、1.28%、1.46%和0.10%,性能仅次于BRINT。此外,还可以看出,随着训练样本个数的减小,CNN的性能提升明显增多,这些结果表明了CNN具有较强的表示能力。
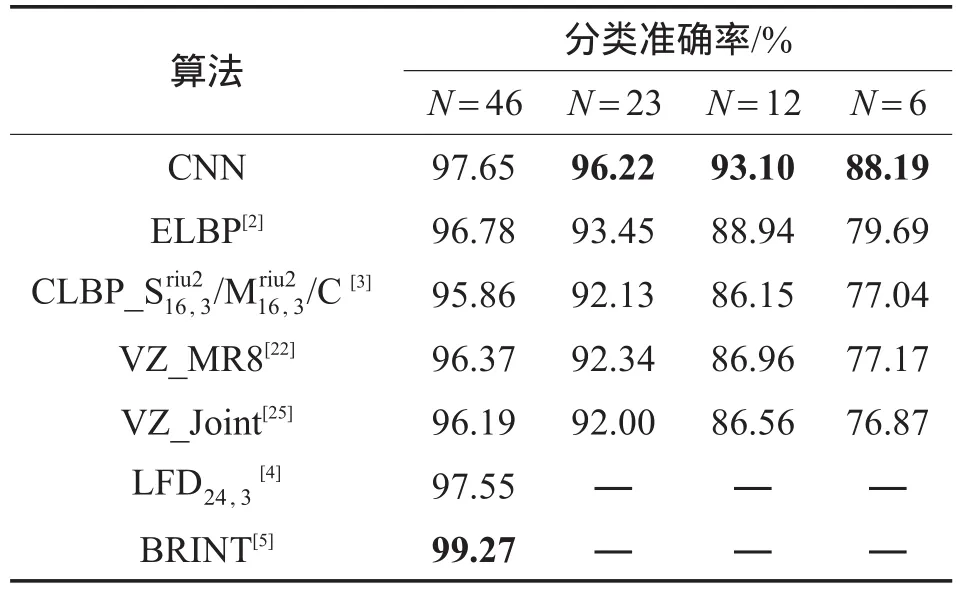
Table 2 Performance comparison on CUReT dataset表2 CUReT数据集上性能比较
3.2 KTH-TIPS数据集
KTH-TIPS数据集共包含10类在不同视角、光照和尺度条件下采集的纹理图像。在每一类图像中,前5种尺度的45张纹理图被选择出来用于实验,每张图像尺寸为200×200像素。在实验过程中,本文使用与文献[4]中相同的划分方式,即在每类纹理中,随机抽取23张图像作为训练样本,剩余的22张图像作为测试样本,随机实验重复进行50次,使用50次实验结果的均值作为算法的最终分类结果。各算法在KTH-TIPS数据集上的分类准确率如表3所示。

Table 3 Performance comparison on KTH-TIPS dataset表3 KTH-TIPS数据集上性能比较
C、VZ_MR8、VZ_Joint和LFD24,3等算法,分类准确率有了较大的提高,分别提升了4.77%、3.98%、12.78% 和1.65%。根据公开文献的调研结果,使用CNN模型的方法在KTH-TIPS数据集上取得了目前最好的性能,进一步表明了CNN在纹理分类任务中的有效性。
3.3 KTH-TIPS_2b数据集
KTH-TIPS_2b数据集是在KTH-TIPS数据集基础上经过扩展得到的更富挑战性的彩色纹理图像数据集。该数据集共包含11类在不同视角、光照和尺度条件下采集的纹理图像。每类图像包含4种不同的样本,分别为a、b、c、d,每种样本包含108张图像,每张图像尺寸为(200×200像素)×3通道。在实验过程中,随机选取3种不同样本进行训练,剩余的1种样本用于测试,实验重复进行4次,使用4次实验结果的均值作为算法的最终分类结果。
由于KTH-TIPS_2b是彩色数据集,为了检验颜色对性能的影响,本文在输入图像不同的情况下对CNN的性能进行测试,具体如下:(1)使用彩色原图作为CNN的输入;(2)先将彩色图像转为灰度图像,再使用灰度图像作为CNN的输入。分类结果如表4所示。
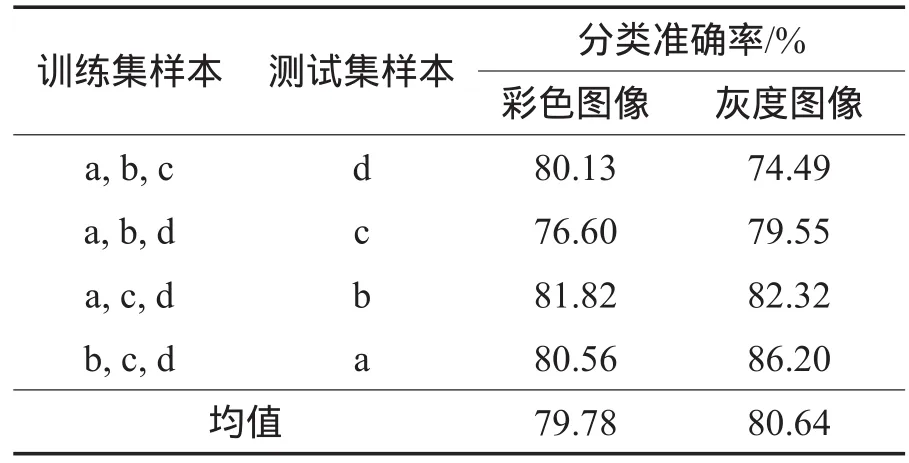
Table 4 Performance comparison between color and gray inputs on KTH-TIPS_2b dataset表4 KTH-TIPS_2b数据集上使用彩色图像和灰度图像作为输入的性能比较
由表4中数据可以看出,尽管在不同的训练集/测试集样本划分情况下,使用彩色图像和灰度图像的结果有所差异,但是整体而言,使用灰度图像的效果要更好。
表5给出了不同算法在KTH-TIPS_2b数据集上的分类性能比较。由于现有算法大多都不考虑颜色的影响,表中只列出了在使用灰度图像作为输入的情况下的分类性能比较。由于KTH-TIPS_2b中的图像相比于上述两个纹理集(CUReT以及KTHTIPS)中的图像更加复杂,因而更具挑战性。从表5中的数据可以看出,所有的算法在KTH-TIP_2b上的分类准确率均低于在CUReT和KTH-TIPS上的准确率。在这种情况下,相比于ELBP、CLBP、VZ_MR8、VZ_Joint和BRINT,CNN的分类准确率分别高出14.64%、15.34%、23.94%、19.94%和10.34%。由此可以说明,CNN具有强大的表示能力和鲁棒性,在复杂的纹理分类任务中也能获得很好的效果。
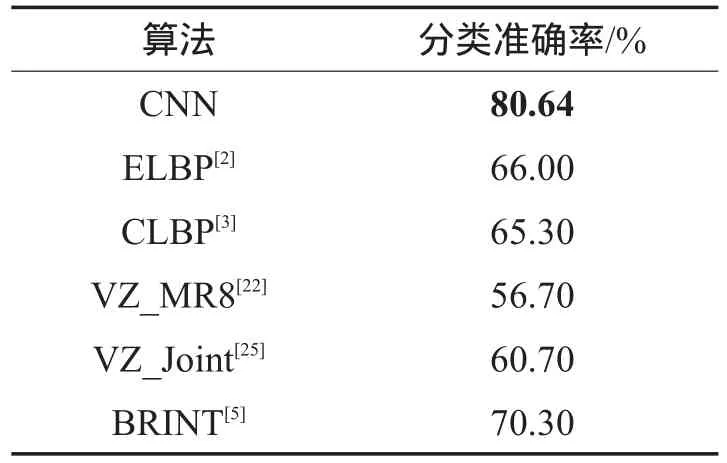
Table 5 Performance comparison on KTH-TIPS_2b dataset表5 KTH-TIPS_2b数据集上性能比较
4 讨论
下面围绕预训练的CNN在纹理分类任务中的应用展开讨论,具体包括:
(1)预训练的CNN与直接使用纹理图像训练的CNN的对比;
(2)预训练的CNN的抗旋转性能测试;
(3)预训练的CNN的抗噪声性能测试。
4.1预训练的CNN与直接训练的CNN的对比
为了论述方便,本节使用Direct-CNN表示直接使用纹理图像训练的CNN。
本文在CUReT数据集上进行Direct-CNN模型的训练,具体过程如下:首先,在每类纹理中,随机选取46张图像作为训练样本,并将剩余46张图像作为测试样本。其次,统一将训练样本的大小由200×200像素调整为128×128像素。最后,采用Data Augmentation方法增加训练样本个数,即选取每张训练图像中左上角、左下角、右上角、右下角以及中间的100×100像素图像块形成5个新图像,共14 030(61×46×5)张图像作为新的训练样本。测试时,需将测试图像的大小调整至与训练图像相同,即100×100像素,此时共有2 806(61×46)张测试图像。
由于数据集训练数据的限制,较难训练比较深度的模型,本文仅使用上述训练数据训练两个浅层的Direct-CNN用于测试对比,分别称为D1-CNN和D2-CNN,其中数字“1”和“2”分别表示CNN模型中卷积层的个数。D1-CNN与D2-CNN的参数如表6所示。
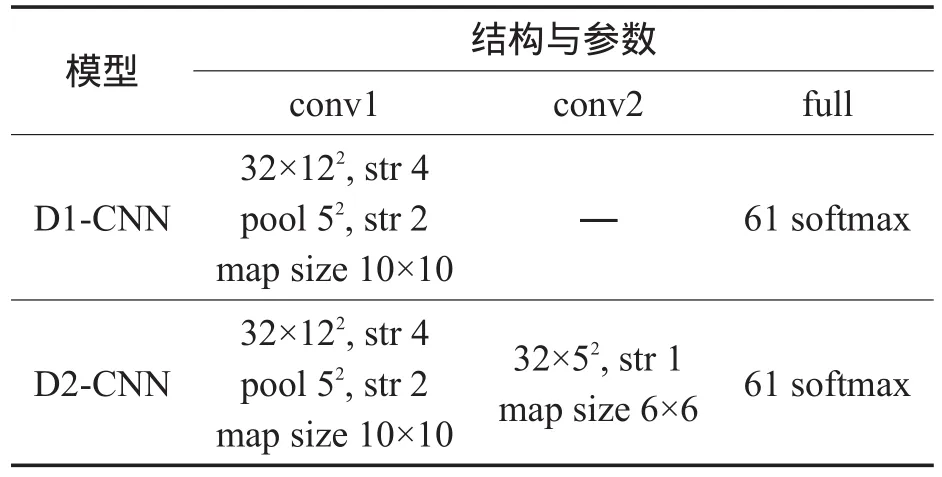
Table 6 Structures and parameters of D1-CNNand D2-CNN表6 D1-CNN与D2-CNN网络结构与参数
经过50次迭代训练后,D1-CNN和D2-CNN在测试集上的准确率分别为91.20%和89.27%,低于CNN 的97.64%。原因在于CUReT训练集中的图像较少,Direct-CNN难以得到充分的训练,所以其分类准确率较低;而CaffeNet是在大型数据集ImageNet上进行训练的,训练图像高达上百万张,可以学习到有效的特征,因此其分类准确率较高。在其他数据集上也取得了类似的结果。这些结果表明了预训练的CNN的有效性,同时也可知构建大型纹理数据集的必要性。
4.2抗旋转性能测试
CNN在CUReT、KTH-TIPS、KTH-TIPS_2b等数据集上能够取得良好的效果,一方面是由于CNN强大的学习能力和表示能力,另一方面也归功于训练样本的多样性。
为了测试CNN的抗旋转性能,使用Outex_TC10数据集进行实验。Outex_TC10数据集共包含24类在“inca”光照下采集的9种不同旋转角度(0°,5°,10°,15°,30°,45°,60°,75°,90°)的纹理图像,其中每张图像尺寸为128×128像素。在实验过程中,采用标准的训练方式,即选取旋转角度为0°的图像作为训练样本,其他旋转角度的图像作为测试样本。在训练时并未提供其他旋转角度的图像,因此可以很好地测试CNN特征自身的抗旋转能力。实验结果如表7所示。
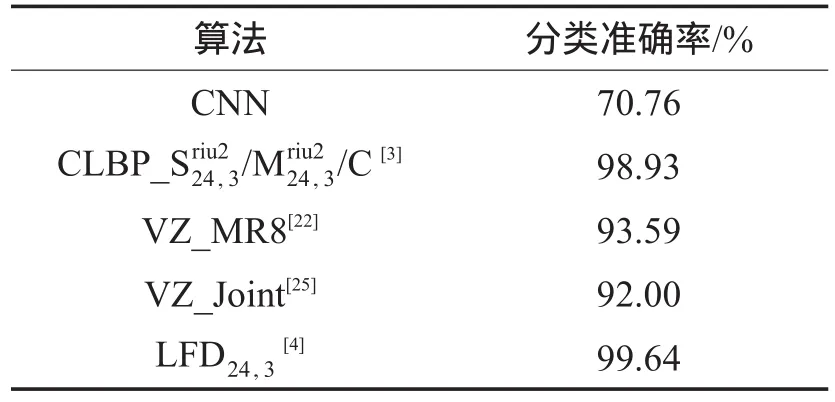
Table 7 Performance comparison on Outex_TC10 dataset表7 Outex_TC10数据集上性能比较
表7给出了不同算法在Outex_TC10数据集上的分类准确率的比较。由于传统的纹理分类方法在设计特征时均针对旋转变化进行了相应的改进,从而分类准确率较好;而在ImageNet上进行训练的CNN只具有一定的抗旋转能力,同时在提取特征时并未提供其他旋转角度的样本,因次分类准确率较差。
为了进一步证实上述分析,本文进行了以下补充实验:与标准方式仅选取旋转角度为0°的20张图像作为训练样本不同,补充实验在每类纹理中随机选取20张作为训练样本,剩余的160张作为测试样本,随机实验重复进行50次,使用50次实验结果的均值作为算法的最终分类结果。表8给出了Outex_ TC10数据集上使用标准和非标准训练方式的性能比较。由表中数据可以看出,使用随机方式选取训练图像的结果要远好于使用标准方式选取训练图像的结果。这说明虽然CNN自身的抗旋转能力有限,但是当训练数据包含足够的多样性时,CNN能够取得良好效果。该结果表明了有必要提升CNN在纹理分类中的抗旋转能力,以及构建具有足够多样性的纹理数据集。
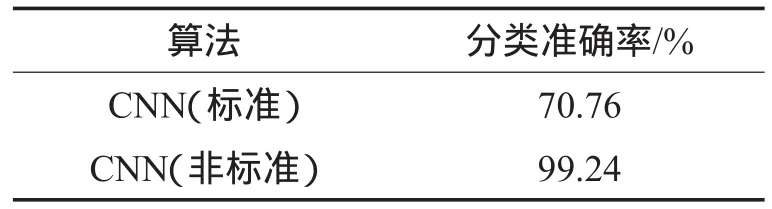
Table 8 Performance comparison between standard and non-standard training on Outex_TC10 dataset表8 Outex_TC10数据集上使用标准和非标准训练式的性能比较
4.3抗噪声性能测试
在自然条件下采集的纹理图像可能包含噪声,因此特征的抗噪声能力在纹理分类任务中比较重要。本节在CUReT数据集上添加高斯噪声以模拟自然条件下采集的带噪声的纹理图像。
在实验过程中,从每类纹理中随机抽取46张图像作为训练样本,剩余的46张图像作为测试样本,每张图像上添加高斯噪声后作为新的训练/测试样本。本文使用SNR(signal noise ratio)作为噪声强度的指标,依次选取SNR=30,15,10,5进行实验,并与现有文献中抗噪声性能最好的算法BRINT进行对比,实验结果如表9所示。可以看出,在不同的SNR情况下,CNN相比于目前最好的抗噪声算法BRINT性能降低15%以上,这说明CNN的抗噪声性能有待提高。
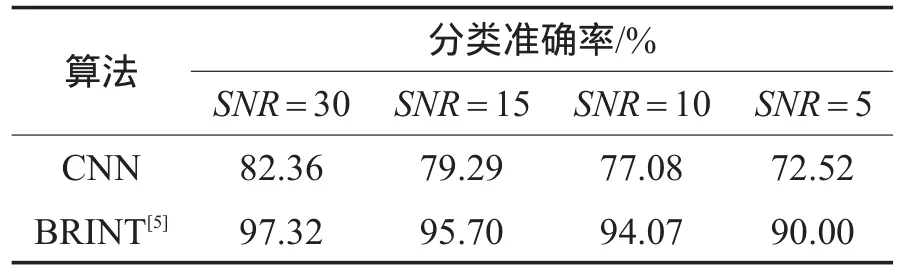
Table 9 Performance comparison with different SNR表9 不同SNR情况下的分类性能比较
5 结束语
本文将ImageNet数据集上预训练得到的CNN模型应用于纹理分类任务中。实验表明,预训练的CNN模型能够提取出有效的纹理特征,在常用的纹理数据集上均取得良好的效果。尤其在KTH-TIPS 和KTH-TIPS_2b数据集上,本文方法取得了目前为止最高的分类准确率。为了进一步探究预训练的CNN的性能,本文将预训练的CNN与直接训练的CNN进行对比,说明了构建大型纹理数据集的必要性。此外,本文还对CNN的抗旋转性能与抗噪声性能进行了测试,说明了提升CNN自身鲁棒性和构建多样性数据集的必要性。
References:
[1] Ojala T, Pietikainen M, Maenpaa T. Multiresolution gray-scaleand rotation invariant texture classification with local binary patterns[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987.
[2] Liu Li, Zhao Lingjun, Long Yunli, et al. Extended local binary patterns for texture classification[J]. Image and Vision Computing, 2012, 30(2): 86-99.
[3] Guo Zhenhua, Zhang Lei, Zhang D. A completed modeling of local binary pattern operator for texture classification[J]. IEEETransactionson Image Processing,2010,19(6):1657-1663.
[4] Maani R, Kalra S, Yang Y H. Noise robust rotation invariant features for texture classification[J]. Pattern Recognition, 2013, 46(8): 2103-2116.
[5] Liu Li, Long Yunli, Fieguth P W, et al. BRINT: binary rotation invariant and noise tolerant texture classification[J]. IEEETransactionson Image Processing,2014,23(7):3071-3084.
[6] Krizhevsky A, Sutskever I, Hinton G E. ImageNet classification with deep convolutional neural networks[C]//Advances in Neural Information Processing Systems 25: Proceedings of the 26th Annual Conference on Neural Information Processing Systems, Lake Tahoe, USA, Dec 3-6, 2012: 1097-1105.
[7] Zeiler M D, Fergus R. Visualizing and understanding convolutional networks[C]//LNCS 8689: Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, Sep 6-12, 2014. Berlin, Heidelberg: Springer, 2014: 818-833.
[8] Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[J/OL]. arXiv:1409.1556 (2014)[2015-03-30]. http://arxiv.org/pdf/1409.1556.pdf.
[9] Russakovsky O, Deng Jia, Su Hao, et al. ImageNet large scale visual recognition challenge[J/OL]. arXiv:1409.0575 (2014)[2015-03-30]. http://arxiv.org/pdf/1409.0575.pdf.
[10] Jia Yangqing, Shelhamer E, Donahue J, et al. Caffe: convolutional architecture for fast feature embedding[C]//Proceedings of the 2014 ACM Conference on Multimedia, Orlando, USA, Nov 3-7, 2014. New York, USA:ACM, 2014: 675-678.
[11] Sermanet P, Eigen D, Zhang Xiang, et al. OverFeat: integrated recognition, localization and detection using convolutional networks[J/OL]. arXiv:1312.6229 (2013)[2015-03-30]. http:// arxiv.org/abs/1312.6229.
[12] Szegedy C, Liu Wei, Jia Yangqing, et al. Going deeper with convolutions[J/OL].arXiv:1409.4842(2014)[2015-03-30].http:// arxiv.org/pdf/1409.4842v1.pdf.
[13] Yoo D, Park S, Lee J Y, et al. Fisher kernel for deep neural activations[J]. arXiv:1412.1628 (2014)[2015-03-30]. http://arxiv. org/pdf/1412.1628.pdf.
[14] He Kaiming, Zhang Xiangyu, Ren Shaoqing, et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J/OL]. arXiv:1406.4729 (2014)[2015-03-30]. http:// arxiv.org/pdf/1406.4729.pdf.
[15] Babenko A, Slesarev A, Chigorin A, et al. Neural codes for image retrieval[C]//LNCS 8689: Proceedings of the 13th European Conference on Computer Vision, Zurich, Switzerland, Sep 6-12, 2014. Berlin, Heidelberg: Springer, 2014: 584-599.
[16] Razavian A S, Azizpour H, Sullivan J, et al. CNN features off-the-shelf: an astounding baseline for recognition[J/OL]. arXiv:1403.6382 (2014)[2015-03-30]. http://arxiv.org/pdf/ 1403.6382.pdf.
[17] Yosinski J, Clune J, Bengio Y, et al. How transferable are features in deep neural networks?[C]//Advances in Neural Information Processing Systems 27: Proceedings of the 28th Annual Conference on Neural Information Processing Systems, Montreal, Canada, Dec 8-13, 2014: 3320-3328.
[18] Donahue J, Jia Yangqing, Vinyals O, et al. DeCAF: a deep convolutional activation feature for generic visual recognition[J/OL]. arXiv:1310.1531 (2014)[2015-03-30]. http://arxiv. org/abs/1310.1531.
[19] Nair V, Hinton G E. Rectified linear units improve restricted Boltzmann machines[C]//Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, Jun 21-25, 2010: 807-814.
[20] Glorot X, Bordes A, Bengio Y. Deep sparse rectifier neural networks[C]//Proceedings of the 14th International Conference on Artificial Intelligence and Statistics, Fort Lauderdale, USA, Apr 11-13, 2011. Brookline, USA: Microtome Publishing, 2011: 315-323.
[21] Fan Rongen, Chang Kaiwei, Hsieh C J, et al. LIBLINEAR: a library for large linear classification[J]. The Journal of Machine Learning Research, 2008, 9: 1871-1874.
[22] Varma M, Zisserman A. A statistical approach to texture classification from single images[J]. International Journal of Computer Vision, 2005, 62(1/2): 61-81.
[23] Mallikarjuna P, Fritz M, Targhi A T, et al. The kth-tips and kth-tips2 databases[DB/OL]. (2006)[2015-03-30]. http://www.nada.kth.se/cvap/databases/kth-tips/.
[24] Ojala T, Pietikainen M, Viertola J, et al. Outex-new framework for empirical evaluation of texture analysis algorithms[C]// Proceedings of the 16th International Conference on Pattern Recognition,Aug 11-15, 2002. Piscataway, USA: IEEE, 2002: 701-706.
[25] Varma M, Zisserman A. A statistical approach to material classification using image patches[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(11): 2032-2047.

JI Zhong was born in 1979. He received the Ph.D. degree in signal and information processing from Tianjin University in 2008. Now he is an associate professor and M.S. supervisor at Tianjin University. His research interests include multimedia content analysis and ranking, computer vision, feature learning and video summarization, etc. He has published more than 40 scientific papers.冀中(1979—),男,2008年于天津大学获得博士学位,现为天津大学副教授、硕士生导师,主要研究领域为多媒体内容分析和检索,计算机视觉,特征学习,视频摘要等。发表学术论文40多篇。

LIU Qing was born in 1990. He is an M.S. candidate at Tianjin University. His research interests include computer vision and deep learning, etc.刘青(1990—),男,天津大学硕士研究生,主要研究领域为计算机视觉,深度学习等。

NIE Linhong was born in 1991. She is an M.S. candidate at Tianjin University. Her research interests include computer vision and pattern recognition, etc.聂林红(1991—),女,天津大学硕士研究生,主要研究领域为计算机视觉,模式识别等。
Texture Classification with Convolutional Neural Networkƽ
JI Zhong+, LIU Qing, NIE Linhong, PANG Yanwei
School of Electronic Information Engineering, Tianjin University, Tianjin 300072, China
+ Corresponding author: E-mail: jizhong@tju.edu.cn
JI Zhong, LIU Qing, NIE Linhong, et al. Texture classification with convolutional neural network. Journal of Frontiers of Computer Science and Technology, 2016, 10(3):389-397.
Abstract:Deep convolutional neural network (CNN) has recently achieved great breakthroughs in many computer vision tasks. However, its application in texture classification has not been thoroughly researched. To this end, this paper carries out a systemic research on its application in image texture classification. Specifically, CNN is used to extract preliminary image feature, and subsequent PCA (principal component analysis) operation can reduce its dimensionality to obtain final texture feature which is fed into an SVM (support vector machine) classifier for prediction. This paper does comprehensive experiments and analysis on four benchmark datasets. The results show that CNN is a better texture feature representation and achieves quite good performance in most image texture datasets. However, CNN performs worse in datasets with image noise and rotation. Thus, this paper indicates the necessity to enhance the abilities of noise tolerance and rotation invariance of CNN, and it is necessary to construct a large diverse texture dataset to guarantee its best performance in image texture classification.
Key words:texture classification; convolutional neural network (CNN); computer vision
doi:10.3778/j.issn.1673-9418.1505073
文献标志码:A
中图分类号:TP183
猜你喜欢
计算机应用(2016年12期)2017-01-13 20:26:21
无线互联科技(2016年13期)2017-01-10 02:49:09
现代电子技术(2016年22期)2016-12-26 15:42:37
电子技术与软件工程(2016年19期)2016-12-19 19:21:36
中国科技纵横(2016年17期)2016-11-30 21:49:24
软件导刊(2016年9期)2016-11-07 22:20:49
软件工程(2016年8期)2016-10-25 15:47:34
电脑知识与技术(2016年10期)2016-06-16 21:27:26
