
利用关键因子过滤的正则表达式匹配算法*
2016-06-13 00:16杨晓春
计算机与生活 2016年3期
邱 涛,王 斌,杨晓春
东北大学信息科学与工程学院,沈阳110819
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0326-12
利用关键因子过滤的正则表达式匹配算法*
邱涛+,王斌,杨晓春
东北大学信息科学与工程学院,沈阳110819
ISSN 1673-9418 CODEN JKYTA8
Journal of Frontiers of Computer Science and Technology 1673-9418/2016/10(03)-0326-12
E-mail: fcst@vip.163.com
http://www.ceaj.org
Tel: +86-10-89056056
* The National Natural Science Foundation of China under Grant Nos. 61272178, 61322208 (国家自然科学基金); the National Natural Science Foundation of China on International Cooperation under Grant No. 61129002 (国家自然科学基金海外及港澳学者合作基金).
Received 2015-06,Accepted 2015-08.
CNKI网络优先出版: 2015-08-12, http://www.cnki.net/kcms/detail/11.5602.TP.20150812.0917.001.html
摘要:正则表达式(regular expression,RE)是一种能够提供复杂查询能力的技术,其通过特定的语法结构来
1 引言
随着信息社会的到来,数据量急速增长,人们也对信息查询有了更高的要求,简单的信息匹配已经不能满足用户的需求。正则表达式(regular expression, RE)不仅能处理传统的精确文本匹配,更加重要的是其具有强大的描述能力,能够描述文本深层次的特征,从而提供复杂的查询逻辑。正则表达式在各个领域都被广泛地应用,当前的一些文本编辑软件,如vim、eclipse,还有shell命令中的grep命令[1]被广泛地应用于文本查询中,其也是通过正则表达式查询来实现的。例如,可以通过shell命令“grep ^[0-9]+@[a-z]+.com emails.txt”在文件emails.txt中查询包含匹配结果的行,匹配结果是以数字开始,中间包含@,并且以.com结尾的邮箱号。此外,正则表达式的功能已经被集成到了一些语言的语法当中(如Perl、Ruby和AWK),或者通过标准库的形式被其他高级语言所支持,如JAVA、.NET等。
传统的实现正则表达式查询的方法是,对于查询Q构造其对应的自动机,然后对于字符串中的每一个位置,通过自动机来判断从该位置开始的子串是否可以被该自动机所接受。这种方法的主要限制在于需要重复这种验证过程很多次,并且验证代价往往是比较大的。有许多方法提出了改进措施来加速匹配过程[1-5],基本思路都是先确定字符串上的一些候选区间,然后一个接一个地验证这些区间(如图1所示)。这些方法从正则表达式中提取出一些子串(过滤因子)来确定候选区间出现的位置。每一个候选区间都将用一个或者多个自动机来验证。即使这些方法可以减少许多验证过程,但是当过滤后产生的候选区间较多时,这些方法的效率将变得非常低,尤其当文本非常长的时候更加明显。
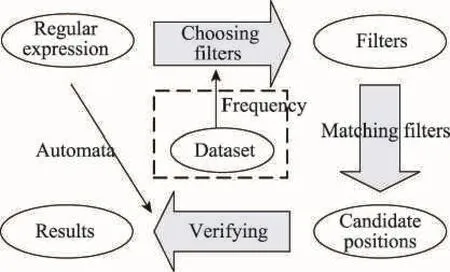
Fig.1 RE matching based on filtering strategy图1 基于过滤策略的匹配方法
现有方法采用的过滤因子包括前缀因子和必要因子。前缀因子和必要因子都是通过分析查询Q而得到子串集合,并没有考虑文本中字符不均匀分布对过滤能力的影响。实际情况中文本的字符不是均匀分布的,这将导致文本中子串出现的频率差别较大。例如,英文文档中子串like、they作为常用的单词,其出现的频率远大于klmn出现的频率。又如蛋白序列中,QLD和ELV等子串是很多蛋白结构的基本单元,因此其出现频率要高于其他子串的频率。
基于这个观察,在所有查询Q的匹配结果所包含的子串中,挑选一组在文本中出现频率低的作为过滤因子,将产生更好的过滤效果,因为这部分子串才是能否出现一个匹配结果的关键所在。本文将这样的频率少且用于过滤的子串称为关键因子。利用关键因子进行过滤将获得更好的过滤能力,从而提高整体的匹配性能。
本文的贡献主要有以下3个方面:描述一类文本的共同特征。正则表达式强大的表达能力和简洁的语法,使得其在各个领域都被广泛地应用。为了提高正则表达式的匹配效率,提出了一种利用关键因子进行过滤的匹配技术,关键因子指的是在文本中具有最小出现频率的有效过滤因子。由于实际文本中字符并不是均匀分布的,子串在文本中出现频率的差异将影响过滤因子的过滤能力。通过考虑有效过滤因子在文本中出现的频率,关键因子能获得更好的过滤能力。提出了利用正则表达式的划分来求取关键因子的算法,进而通过关键因子来过滤候选位置。通过在真实的蛋白序列和英文文本上进行实验,说明了基于关键因子过滤的匹配方法可以有效地提升正则表达式的匹配性能。关键词:正则表达式;过滤策略;算法性能;关键因子
(1)分析了基于过滤因子的正则表达式匹配方法,总结了可进行验证的有效过滤因子特点,提出了基于关键因子的过滤技术。
(2)为了构造给定正则表达式的关键因子,提出了一种高效的关键因子构造算法,即先求得正则表达式的所有划分,再通过划分发现所有有效过滤因子,从而得到关键因子。
(3)在真实数据上进行了全面的测试,结果表明了基于关键因子过滤的匹配方法可以有效地提升正则表达式的匹配性能。
2 相关工作
本文将从两个方面对正则表达式匹配的相关工作进行介绍,即经典的正则表达式匹配方法和基于过滤策略的匹配方法。
经典的正则表达式匹配方法的基本思路是先将正则表达式转换成自动机,然后直接利用自动机进行搜索。目前已经提出了很多基于该思路的方法[6-9]。文献[8]中Thompson在给出了NFA(non-deterministic finite automata)定义的同时,还在对该NFA直接模拟的基础上提出了一个复杂度为O(mn)的算法,称之为NFAThompson。它将当前活动状态的集合存储起来,对于每次读入的新字符,依次查看当前的每一个活动状态,以获得被激活的新状态。然后,将这些新状态加入一个新的活动状态集合。对这些新的活动状态,再跟随其所有的ε-转移获得其他所有可到达状态,并将其加入新活动状态集合中。通过这种方式,可以通过判断终止状态是否激活来判断是否找到RE的一个匹配[7]。DFAClassical算法[10]利用的是DFA (deterministic finite automata)来进行匹配,其可以保证具有O(n)的线性搜索时间。此外,基于Thompson NFA模拟,文献[5]提到了一种很有竞争力的算法BPThompson,它巧妙地运用了位并行的方法来模拟NFA的匹配。
上述经典的正则表达式匹配技术虽然提升了自动机匹配的效率,但由于经典的正则表达式匹配算法需要对文本逐个字符进行检验,这在很大程度上影响了匹配的效率。一种比较新颖的做法是利用过滤-验证模式来回答正则表达式查询。如图1所示,基于过滤策略的匹配方法的基本思路是,先通过多串匹配算法匹配出正则表达式在文本中的候选区域,然后再通过经典的正则表达式匹配算法对候选区域进行验证。由于过滤策略的应用,使得算法可以避免读入文本中的所有字符。下面介绍几种主要的基于过滤策略的匹配算法。
文献[3]介绍了一种MultiStringRE算法。该算法首先计算出可以匹配正则表达式中所有长度为lmin (lmin表示正则表达式的最短成功匹配长度)的前缀集合Pref(RE),然后利用一种类似Commentz-Water的算法,实现对Pref(RE)的多字符串匹配。因为正则表达式的每次成功匹配必须要以Pref(RE)中的字符串开始,所以只要从Pref(RE)在文本中的初始位置开始验证就可以。
RegularBNDM[11]是一种扩展的BNDM算法,其基本思想是通过对DFA自动机进行反转,使得自动机能够识别所有的反转正则表达式的前缀。算法在文本中滑动大小为lmin的窗口,并且自后向前读取窗口中的字符。窗口中的反向搜索会在两种情况下停止:一是DFA中没有活动状态,这时可以滑动窗口重新开始匹配过程;二是匹配位置到达了窗口的起始位置,这种情况说明算法识别出了RE的一个前缀,这时就可以使用正常的无自循环DFA自动机进行向前验证。
GNU Grep[1]使用的是基于必要因子的过滤方法,其基本思想也是先求得一个必要因子的集合,然后使用多串匹配计算搜索。对于文本中每一个必要因子出现的位置,它都需要分别向前和向后进行验证。例如,对于正则表达式(C|A)*GA(T|C),其中GA就是必要因子。必要因子的选取不仅仅是精确的子串,同时也可以是正则表达式的一个子表达式。必要因子必须是一个完整的子表达式(为了方便对候选区间进行前后验证),并且对于有些正则表达式并不存在必要因子。
前缀因子和必要因子实际是从找到匹配结果包含的子串的角度进行过滤,这种结果中包含的子串可以统称为正向因子。文献[12]介绍了一种基于反向因子的过滤技术,反向因子指的是匹配结果中一定不包含的子串。其通过同时利用正向因子和反向因子进行过滤,获得了更好的过滤能力。本文提出的关键因子属于一种正向因子,基于关键因子也可以利用反向因子实现过滤能力的进一步提升。
正如引言部分所描述的,前缀因子和关键因子主要问题在于忽略了文本中子串频率分布不均匀对于过滤能力的影响。本文对正则表达式的过滤因子进行了分析,提出了利用关键因子进行过滤的技术,通过考虑过滤因子在文本中出现的频率,构造出具有最少出现频率的有效过滤因子集合,即关键因子。因此关键因子总是能获得比前缀因子和必要因子更好的过滤能力,从而提升正则表达式匹配的效率。
3 正则表达式匹配定义
本文给出了正则表达式匹配的形式化定义,并在后面的章节中采用统一的标识符形式化表示这些概念。
定义1(正则表达式)一个正则表达式RE是有限字母表Σ与运算符集合{ε, | ,·,∗, ( ,)}中的元素组成的一个字符序列。它的递归定义如下:
(1)空字符ε是一个正则表达式,它表示一个空串。
(2)任意字符w∈Σ也是一个正则表达式,它表示的是字符串集合{w}。
(3)如果e1和e2都是正则表达式,那么(e1),(e1·e2),(e1| e2),(e1+)也都是正则表达式。
①(e1)表示的字符串集合与e1所表示集合相等。
②(e1·e2)表示一个字符串的集合x,并且x可以表示成x=yz,其中y可以被e1匹配,z可以被e2匹配。
③(e1| e2)表示的字符串集合x可以被e1匹配或者被e2匹配。
④(e1+)所表示的字符串集合x,可以被表示成x=x1, x2,…,xk,并且e1匹配每个字符串xi(1≤i≤k )。表达式(ε|e1+)表示的是柯林闭包e1*。本文接下来考虑的都是更为通用的e1*。
定义2(展开式集合)对于任意一个正则表达式查询Q,都存在一个字符串集合SQ来表示Q所描述的所有查询,本文称SQ为正则表达式Q的展开式集合。
正则表达式的展开式集合可能是一个无限大的集合,因为当其存在柯林闭包项时,柯林闭包项可以进行无限的扩展。如图5所示,对于正则表达式Q=(QL|EL ) V*D,它的展开式集合为SQ={QLD, ELD, QLVD, ELVD, QLVVD, ELVVD…},由于V*表示空或者任意多个V,因此对于该查询Q,其SQ是一个无限大的集合。SQ[i]表示集合中第i项( i≥0 ),SQ[0]为集合的第一项,它表示闭包项都为空时,Q所能匹配的字符串。正则表达式Q的展开式集合SQ中的字符串在文本T中的精确匹配即为Q在T上的匹配结果。
定义3(最小匹配长度)对于正则表达式Q,其在文本T上最短的匹配结果长度称为Q的最小匹配长度,本文用lmin进行表示。
由展开式集合的定义可以知道,对于一个正则表达式Q,其最小匹配长度lmin等于SQ中字符串长度最短的项的长度。例如,对于上述正则表达式Q,其lmin=3,因为SQ中最短串长度为3。
给定一个正则表达式,如果它的最短成功匹配长度为lmin,则任何跳跃方法都必须对每lmin个字符中的至少一个进行检验,以免错过匹配位置。因此,基于过滤因子的方法选取的过滤因子长度都不会超过lmin[13]。本文后面介绍关键因子长度也必须小于等于lmin。
对于文本T,T[i]表示文本中第i个字符(从0开始),T[i,j]表示T中从第i个字符到第j个字符的子串。阐述了正则表达式的定义以及相关概念后,下面给出本文研究内容的问题定义。
问题1(正则表达式匹配)给定文本T和正则表达式Q,T∈Σ*,正则表达式匹配即在文本T上匹配出所有满足Q的匹配结果。
例1给定正则表达式Q=(QL|EL)V*D,文本T如图2所示。

Fig.2 An example of protein sequences图2 蛋白序列文本例子
T[8,10]和T[25,27]即为Q在文本T中的匹配,正则表达式匹配需要返回所有满足Q的结果。
本文接下来介绍的基于关键因子的匹配技术是基于索引结构实现的,即可以通过索引快速得到子串在文本中的出现频率和位置。该技术也可以扩展到非索引的情况。在非索引的情况下,有多种技术可以用于估算子串在文本中的出现频率,例如采样技术和分阶段查询技术。
4 关键因子
本章将对关键因子的定义进行详细介绍。首先对基于过滤因子的正则表达式匹配技术进行分析,然后通过分析总结出可用于验证的有效过滤因子的特点,最后基于有效过滤因子进而定义关键因子。
定义4(等价查询)对于正则表达式Q1、Q2和Q,如果Q1·Q2与Q的匹配结果一致(即通过转换后具有相同的最小化确定自动机),那么称Q1·Q2与Q是等价的。
例如,对于Q=(QL|EL)V*D,存在Q1=(QL|EL), Q2=V*D,Q1·Q2与Q即为等价的正则表达式。
定义5(有效划分)对于正则表达式Q1,Q2和Q,如果Q1·Q2与Q是等价的,那么称Q1和Q2为Q的一组有效划分(简称划分),记为
对于一组过滤因子F,当SQ中的所有字符串的左子式通过或操作(|)所得到的正则表达式QL与右子式通过或操作(|)得到的正则表达式QR分别匹配与Q存在等价关系( QL∙QR=Q ),那么对于任意一个过滤因子f(f∈F)在文本中的出现位置π,都可以直接利用QL与QR直接进行前后验证。显然这种方式不需要单独处理每一个f,且对于任意f匹配得到的候选位置使用的都是同样的表达式进行验证。例如,对于Q= (QL|EL)V*D,存在一组过滤因子F3={LD, LVD, LVV},SQ中字符串关于F3中过滤因子的左子式可以表示为QL= (Q|E),右子式表示为QR= LV*D。
定义6(有效过滤因子)给定正则表达式Q,F为Q的一组过滤因子,Q通过F得到的用于前后验证的正则表达式分别为QL和QR,如果QL∙QR=Q (
可以发现,前缀因子和必要因子都属于有效过滤因子,因为它们用于验证的表达式与查询Q是等价的。对于前缀因子,其后向验证表达式为空。
定义7(发生频率)给定正则表达式Q和文本T, F为Q的一组有效过滤因子,F中元素个数为k。过滤因子fi(fi∈F)在文本中出现的次数为ci,那么对于F中所有过滤因子在文本中出现次数的总和称为F的发生频率,表示为
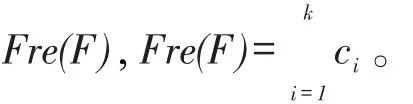
例如,对于过滤因子集合F1={QLD,ELD,QLV, ELV},其在图3所示文本T中的发生频率为Fre(F1)=3。
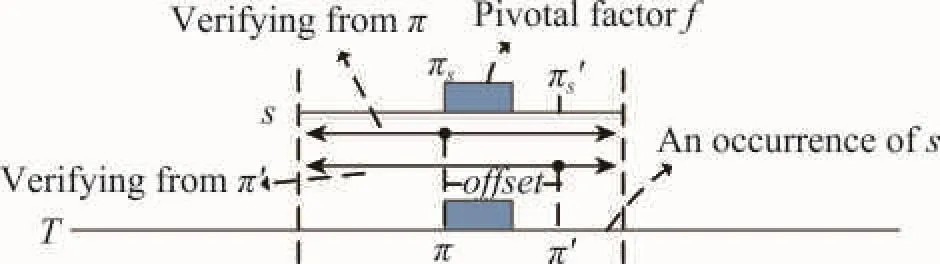
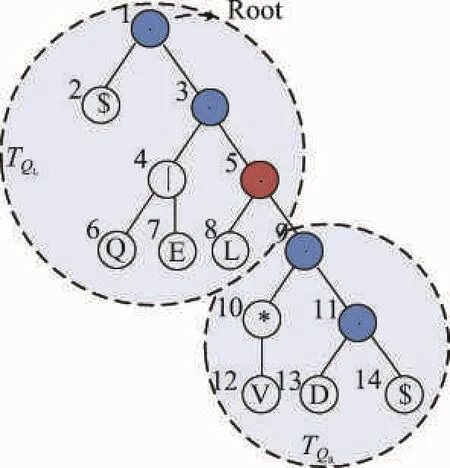
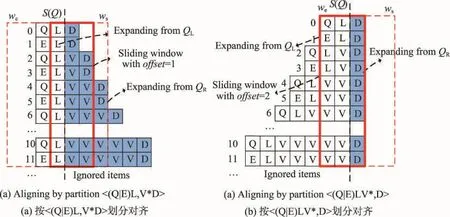
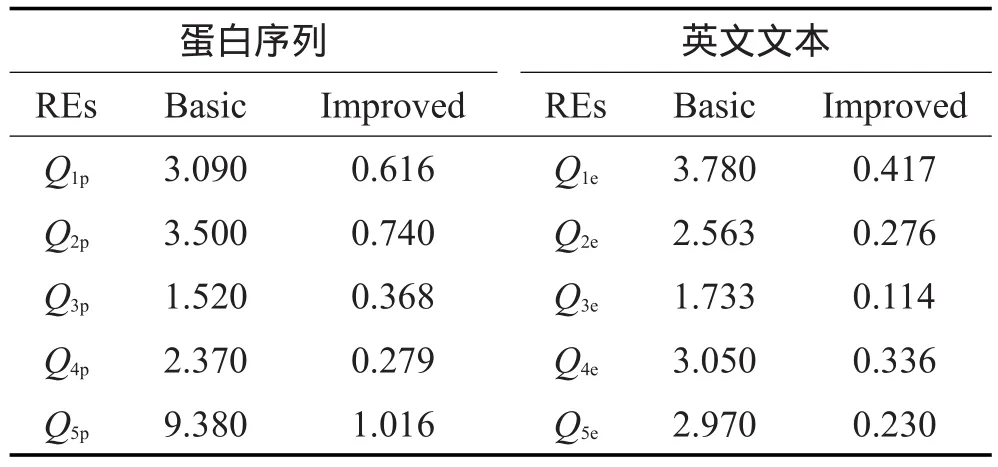
定义8(关键因子)给定正则表达式Q和文本T,Fall为Q的所有有效过滤因子的集合,对于一组有效过滤因子P(P∈Fall),如果Fall中不存在另外一组有效过滤因子P′,使得Fre(P′) 对于前面所述的有效过滤因子集合中,F3即为Q的关键因子集合,其在图3所示文本T中的发生频率为1,其余的有效过滤因子集合的发生频率都大于1。 由关键因子的定义可以知道,由于考虑了有效过滤因子在文本中出现的频率,相较于前缀因子和必要因子而言,关键因子总可以获得最好的过滤能力。 本章开始介绍关键因子的构造算法。关键因子实质是具有最小发生频率的有效过滤因子,只有满足有效过滤因子这个前提才能有效地对候选区间进行验证。一种最基本求取正则表达式Q的有效过滤因子的方法是先求取出所有的过滤因子,再对过滤因子进行有效性验证。通过对Q进行展开得到Q的展开集合SQ,然后通过SQ来枚举出Q的所有过滤因子集合。但是这种方法具有很高的代价,因为需要枚举出所有的过滤因子,再通过判断自动机是否等价来确定有效过滤因子。接下来,本文介绍一种高效的求取有效过滤因子的方法,它的基本思想是先找到查询Q的所有划分,通过Q的划分来找到满足条件的有效过滤因子集合,进而结合有效过滤因子的发生频率构造出关键因子。 5.1利用划分发现有效过滤因子 本节将介绍有效划分与有效过滤因子间的关系。通过前面的介绍可以发现,如果存在Q的一组有效过滤因子F,那么必然存在用于前后验证的划分 定理1给定正则表达式Q, 定理1所描述的验证方式称为基于偏移量offset的验证,offset=πs′-πs。图3可以用于说明基于偏移量的验证方式的原理。对于一个正则表达式Q,如果它在文本中存在一个匹配,那么这个匹配即是它展开式中的一个项,如图3所示,s∈SQ,过滤因子f得到了文本T中的一个起始位置为π的匹配。为了验证是否存在关于π的一个正则表达式匹配,可以选择基于位置π的前后验证,也可以选择基于位置π′的验证,很显然这两种方法得到的验证结果是一致的,只不过用于前后验证的划分不一样。但是因为有效过滤因子对于SQ中的任意一项都使用相同的验证方式,所以对于任意s( s∈SQ),s作为待验证字符串,其上的验证起始位置πs′与过滤因子出现的起始位置πs的差值应该等于offset。 Fig.3 Verification based on offset starting position图3 基于偏移量的验证方法 通过定理1可以知道,对于正则表达式Q,如果存在一组有效划分,那么可以求出基于该划分的具有不同偏移量offset的所有有效过滤因子集合。 5.2利用解析树计算有效划分 5.1节理论分析了通过有效划分可以找到基于该划分的所有有效过滤因子集合。为了求得所有有效过滤因子,接下来需要解决的一个问题就是如何求得正则表达式Q的所有有效划分。定义9(顶层操作符)对于正则表达式Q,Q中未被嵌套的操作符称为顶层操作符。正则表达式可以嵌套地包含子表达式,例如Q=(QL|EL ),其中QL|EL即嵌套于()操作符中的子表达式,Q中包含3个顶层项(QL|EL)、V*和D,其中V*的闭包操作为顶层闭包操作符。同时Q可以显式地表示为Q=ε∙(QL|EL)∙V*∙D∙ε,其中的4个连接操作即为Q的顶层连接操作符。定义10(最简化正则表达式)对于正则表达式Q,如果Q的所有等价的用于前后验证的划分 本节提出了一种基于解析树的划分计算方法。构造解析树是常用的正则表达式分析方式[13],该解析树亦可用于构造验证需要的自动机。为了快速得到所有顶层连接操作符,本文介绍了一种巧妙的方式来实现这一过程。通过在正则表达式的首尾添加一个非字符表Σ中的字符(本文以$符号为例),对于正则表达式Q=(Q|E)LV*D,将转换为表达式Q′=$(Q|E) LV*D$,通过Q′可以得到如图4所示的解析树。在之后通过解析树计算展开式集合和构造自动机的时候,将$解析成空即可,这样不会影响正则表达式的匹配。 通过图4可以发现当添加$符号后,顶层连接操作符(包括原正则表达式Q首尾的连接操作符)将连续出现在以根节点开始的所有右孩子节点上,直到遇到最后一个$符号结束,例如节点1、节点3、节点5、节点9、节点11都为顶层连接操作符。这是由解析树的构造过程决定的,解析树中所有的一元操作符仅存在一个子节点,例如节点10表示的是闭包操作。所有的二元操作符将存在左右孩子节点,如或操作(|)和连接操作(·)。 Fig.4 Parse tree of RE $(QL|EL)V*D$图4 正则表达式$(QL|EL)V*D$的解析树 5.3基于滑动窗口的关键因子构造算法 本节将介绍一种基于滑动窗口的关键因子构造算法。为了得到关键因子,需要先计算出有效过滤因子的集合。计算有效过滤因子集合的基本思路是利用定理1,找到所有与划分 Fig.5 Computing valid filtering factors based on sliding window图5 基于滑动窗口的有效过滤因子计算过程 当SQ中元素对齐之后,就可以利用长度为lmin的“滑动窗口”来取SQ的子串集合,这样可以保证滑动窗口所取的子串起始位置与分割位置都是等距的,因此滑动窗口中的子串集合即有效过滤因子集合(见定理1)。滑动窗口需要满足如下两方面的条件: 条件1滑动窗口中必须含有SQ中每一项的子串。如果有些项的子串没有包含在滑动窗口中那么就有可能导致匹配过程漏解。 条件2滑动窗口中子串必须是左对齐的。当且仅当滑动窗口中所有元素都左对齐时,其所有子串的文本中匹配的起始位置与验证起始位置才是等距的。 基于上述两个条件,可以选择从右向左移动滑动窗口,起始位置应为最右端的满足两个条件的位置,向左滑动直到任意一个条件不满足则停止。通过观察可以发现,起始窗口ws一定为仅包含SQ[0]中最右端字符的窗口,因为SQ[0]为展开式集合中最短的项,对于SQ[0],如果ws满足条件1,那么其余的项也会满足条件1,并且其余所有项在ws中的子串也都是左对齐的(满足条件2)。至于终止窗口we,其位置分为两种情况: (1)划分中用于后向验证的表达式QL的展开项的长度都是相等的,这种情况下we可以移动到窗口仅包含最左侧字符的位置。如图5(a)所示,后向验证表达式(Q|E)L所展开的字符串都是等长的,因此即使we仅包含最左侧字符时也会满足上述两个条件。 (2)后向验证的表达式QL的展开项的长度不等。此时we的起始位置应为SQ[0]的起始位置,因为SQ[0]为展开式集合中最短的项,再向左移动将不满足条件2,如图5(b)所示。 算法1描述了计算关键因子的过程。为了实现上述展开式的对齐操作,需要在通过解析树计算展开式集合SQ的过程中记录下每个划分在SQ中的分割位置集合StartPos。通过StartPos和当前的偏移量offest,就可以通过对SQ进行一次遍历来求得当前窗口中的所有子串(第9行所示)。对于每一个划分的每一个窗口位置,当求得其有效过滤因子集合F后,都会比较F与当前所求得的具有最小发生频率的有效过滤因子集合P的发生频率,如果F具有更小的发生频率,那么利用F来替换P,并且更新当前的最小频率值minFre。 为了快速得到过滤因子在文本T上的发生频率,一种最基本的方法是将T存储为后缀树的形式,在树的每个节点上存储从根节点到该节点所示子串在文本中的发生频率,但是当T很长时后缀树需要很大的存储空间。为了进一步减少空间开销,也可以利用BWT格式来存储文本T[15]。基于BWT索引,可以在常数时间O(|f|)内得到过滤因子f的发生频率。 算法1关键因子构造算法 输入:有效划分集合S( ) QL,QR,正则表达式解析树TQ。 输出:关键因子集合P,用于验证的划分 1.通过TQ计算基于扩展边界的集合SQ,并且返回S( ) QL,QR对应的QR在SQ中的起始位置集合Pos; 2. minFre←MAXVALUE; 3. For each 4.计算 5.获取当前QR在扩展集合SQ的起始位置集合StartPos←Pos[QR]; 6. w←ws; 7. For ws与we间的每一个窗口w do 8. offset←w的起始位置-QR起始位置; 9. F←FindFactorsWin(SQ,offset,StartPos); 10.计算F的发生频率Fre(F); 11. If Fre(F)< minFre then 12. minFre←Fre(P); P←F; 13. 14. Return P, 本章开始介绍基于关键因子的正则表达式匹配算法。5.1节介绍了基于偏移量的验证方式,本节将对其进行进一步的阐述。基于过滤-验证模式的正则表达式匹配技术分为两个阶段,过滤阶段和验证阶段。算法2描述了本文所介绍的基于关键因子的正则表达式匹配技术的执行过程。 算法2基于关键因子的正则表达式匹配算法 输入:正则表达式查询Q,文本T。 输出:匹配结果集合R。 1.利用算法1求得Q的关键因子P,相应的划分 2.通过QL′和QR′分别构造后向和前向验证自动机AL和AR; 3.获得P′中元素在T中出现的起始位置集合Sπ; 4. For each π in Sπdo 5.π′=π+offset; 6. resultB=VerifyB(T,π′-1, AL, startPos) ; 7. resultF=VerifyF(T,π′, AR, endPos); 8. If resultB and resultF are true then 9. R←< startPos, endPos>; 10. Return R; 在过滤阶段,不仅求出了查询表达式Q的关键因子集合P,而且需要返回对应的前后验证表达式 在验证阶段(见第4~9行),对于关键因子出现的每一个位置π,首先需要通过验证偏移量offset,确定出验证的起始位置π′,然后从π′-1位置开始利用后向验证自动机AL进行验证,验证成功将返回结束位置startPos(后向验证的匹配结果位置实际为Q匹配结果的起始位置)。前向验证将从π′开始,验证成功将返回匹配位置endPos。当前向与后向验证都匹配成功时将记录一个成功匹配结果。 例如,对于正则表达式Q=(QL|EL)V*D,其关键因子集合为{LD,LVD,LVV},其在图2所示文本T上的候选验证位置为9和26,该关键因子集合的划分为<ε,(Q|E)LV*D>,那么可以得到验证偏移量offset=-1。由于后向验证表达式为空,只需要进行前向验证。前向验证自动机AR将从8和25位置开始继续向前验证。 为了测试本文提出的基于关键因子的正则表达式匹配技术的有效性,本文在两个真实的数据集上进行了实验。 第一个数据集是蛋白序列(ftp://ftp.sanger.ac.uk/ pub/databases/Pfam/releases),实验所采用的蛋白数据库是Pfam 26.0,它包含了大量的蛋白质族,蛋白质都是由Pfam-A和Pfam-B组成的。蛋白质中字符全是由大写英文字母组成,除了字母“O”和字母“J”。数据集是从Pfam-B中随机抽取的长度范围在101和9 143之间的序列。 第二个数据集是英文文档(http://arnetminer.org/ DBLP_Citation),实验采用的是DBLP-Citation-network中的数据,其包括1 632 442个块,每个块都对应一篇论文的引用信息,例如标题、作者、摘要等。本文从每个块中抽取出摘要信息,字符集由52个英文字母和10个数字组成。 实验从蛋白序列和英文文本中连续抽取了大小为100 MB的数据集。因为不存在随机的正则表达式[16],所以实验在两个数据集上分别合成了5组正则表达式,每组包含10个正则表达式查询,这些正则表达式的长度为6到21,lmin大小为2到5。本文实验图中的查询(如Q1p)均表示一组查询,对应的值为该组查询的平均值。 所有算法均用C++实现,实验在Intel 3.10 GHz Quad Core CPU i5和8 GB内存的64位ubuntu系统上进行。 7.1匹配性能对比测试 首先实验比较的是本文提出的基于关键因子的正则表达式匹配方法PivotalRE与当今主流方法Agrep、GNU Grep还有NR-grep在不同数据集上的匹配性能和过滤能力。由于3个对比方法的设计初衷是用于匹配一组序列集合,当一个序列中存在多个匹配结果时,它们仅匹配第一个结果,并报告该序列存在一个结果匹配。为了公平地进行比较,本文修改了对比方法的源代码,使其可以找到序列中所有的匹配结果。此外PivotalRE利用了索引来快速获得关键因子的匹配位置,而对比方法都是利用多串匹配方法来获取过滤因子位置,因此本文也修改了其过滤因子匹配部分的代码,使其也可以利用索引快速匹配到过滤因子在文本中出现的位置。 图6所示为在100 MB的数据集上匹配性能的对比结果。无论在蛋白序列还是英文文本上,Pivotal-RE的匹配效率都要优于其余3种方法。例如,对于蛋白序列上的Q4p查询来说,PivotalRE花费时间为142 ms,而Agrep、GNU Grep、NR-grep花费时间分别为338 ms、343 ms和246 ms。PivotalRE在英文文档上的优势则更为明显,例如对于查询Q5e,PivotalRE需要128 ms完成查询,而Agrep、GNU Grep、NR-grep花费时间分别为349 ms、408 ms和262 ms。 从图6还可以发现,NR-grep算法的效率要优于GNU Grep,即使在NR-grep过滤能力要低于GNU Grep的情况下(图7所示),原因是NR-grep的验证效率要优于GNU Grep,其采用的是基于位并行的Regular-BNDM算法。 Fig.6 Comparison on query performance of different algorithms图6 不同算法的查询性能对比 7.2过滤能力对比测试 PivotalRE的匹配效率优于对比方法的主要原因在于PivotalRE可以获得最少的候选验证位置。本节通过实验比较了PivotalRE与对比方法的过滤能力。本文使用过滤因子匹配位置个数(候选验证位置个数)来衡量算法的过滤能力,算法过滤能力越好,其得到的过滤因子匹配位置个数就越少。Agrep直接使用了位并行的BPThompson算法进行匹配,相当于对每一个字符位置都需要进行验证,因此实验仅比较PivotalRE与GNU Grep、NR-grep的过滤能力。 过滤能力对比的实验结果如图7所示,PivotalRE过滤能力的优势在英文文本上更为明显。例如对于Q1e,GNU Grep与NR-grep需要验证的位置个数分别为733 729与1 507 066,而PivotalRE仅需要验证400 003,原因是英文文档比蛋白序列的子串频率分布更为不均匀,使得关键因子与前缀、必要因子在文本中的发生频率差别更大。 从图7还可以发现,对于Q1p与Q3e,GNU Grep与NR-grep的验证个数相差并不多,原因是对于这两组查询,GNU Grep对其中的多数查询进行过滤使用的是前缀因子作为其必要因子,因此对于这些查询GNU Grep得到的验证数目与NR-grep是一样的,从而导致了这两种方法在Q1p与Q3e这两组查询上的过滤能力差异不大。此外通过实验还发现,有些情况下由于选取的必要因子长度小于前缀因子长度,导致必要因子在文本中出现的频率反而更多。例如对于Q2p与Q4p,GNU Grep得到的候选验证位置个数分别为371 597和55 437,而NR-grep的验证位置个数仅为301 587和47 030。 Fig.7 Comparison on pruning power of different algorithms图7 不同算法的过滤能力对比 7.3关键因子的构造代价 当系统收到用户的正则表达式查询Q后,需要在线地对Q进行关键因子计算,关键因子构造的时间代价是正则表达式匹配代价的一部分。因此,关键因子的构造过程非常关键,如果关键因子的构造代价过大,那么过滤过程将起不到加速正则表达式匹配的效果。本节将对PivotalRE的关键因子构造代价进行测试。 实验结果如表1所示,Basic与Improved两种构造关键因子算法的区别在于,Improved方法采用了5.4节介绍的优化技术来避免对等价划分的计算。蛋白序列和英文文本上的测试结果都表明了Improved方法的构造代价要优于Basic方法的构造代价。在蛋白序列上的Q5p查询,Improved方法节省的构造时间最多,Basic方法需要花费9.380 ms,而Improved方法仅花费1.016 ms。英文文本上也得到了相似的测试结果,对于Improved方法来说,构造代价最大的查询Q1e也仅需要0.417 ms来构造关键因子。实验结果表明,PivotalRE可以有效地进行关键因子的构造。 本文研究了基于过滤策略的正则表达式匹配问题。通过考虑过滤因子在文本中出现的频率差异,提出了一种利用关键因子进行过滤的匹配技术。为了构造给定正则表达式的关键因子,本文提出了一种高效的关键因子构造算法,先求得正则表达式的所有划分,再通过划分发现所有有效过滤因子,从而得到关键因子。最后,提出了基于关键因子过滤的具有偏移量的验证方式。实验结果表明了基于关键因子过滤的匹配方法可以有效地提升正则表达式的匹配性能。 References: [1] GNU grep[EB/OL]. [2015-04-30]. ftp://reality.sgiweb.org/ freeware/relnotes/fw-5.3/fw_gnugrep/gnugrep.html. [2] Crochemore M, Czumaj A, Gasieniec L, et al. Speeding up two strings matching algorithms[J]. Algorithmica, 1994, 12 (4/5): 247-267. [3] Watson B W. A new regular grammar pattern matching algorithm[C]//LNCS 1136: Proceedings of the 4th Annual European Symposium, Barcelona, Spain, Sep 25-27, 1996. Berlin, Heidelberg: Springer, 1996: 364-377. [4] Mohri M. String matching with automata[J]. Nordic Journal of Computing, 1997: 217-231. [5] Navarro C, Raffinot M. Compact DFA representation for fast regular expression search[C]//LNCS 2141: Proceedings of the 5th International Workshop on Algorithm Engineering, Århus, Denmark, Aug 28-31, 2001. Berlin, Heidelberg: Springer, 2001: 1-13. [6] Myers E W. A four Russians algorithm for regular expression pattern matching[J]. Journal of the ACM, 1992, 39(2): 430-448. [7] Wu Sun, Manber U. Fast text searching allowing errors[J]. Communications of the ACM, 1992, 35(10): 83-91. [8] Thompson K. Programming techniques: regular expression search algorithm[J]. Communications of the ACM, 1968, 11 (6): 419-422. [9] Baeza-Yates R A, Gonnet G H. Fast text searching for regular expressions or automaton searching on tries[J]. Journal of the ACM, 1996, 43(6): 915-936. [10] Sethi R, Aho A V, Ullman J D. Compilers-principles, techniques and tools[M]. Singapore: Pearson Education, 1986. [11] Navarro G. NR-grep: a fast and flexible pattern matching tool[J]. Software Practice and Experience, 2001, 31(13): 1265-1312. [12] Yang Xiaochun, Wang Bin, Qiu Tao, et al. Improving regularexpression matching on strings using negative factors[C]// Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data, New York, USA, Jun 22-27, 2013. New York, USA:ACM, 2013: 361-372. [13] Navarro G, Raffinot M. Flexible pattern matching in strings: practical on-line search algorithms for texts and biological sequences[M]. Cambridge, UK: Cambridge UniversityPress, 2002. Table 1 Construction cost of pivotal factors表1 关键因子构造代价 ms [14] Hopcroft J E, Motwani R, Ullman J D. Automata theory, languages, and computation[M]. [S.l.]: Pearson, 2006. [15] Lam T W, Sung W K, Tam S L, et al. Compressed indexing and local alignment of DNA[J]. Bioinformatic, 2008, 24(6): 791-797. [16] Navarro C, Raffinot M. New techniques for regular expression searching[J].Algorithmica, 2004, 41(2): 89-116. QIU Tao was born in 1989. He is a Ph.D. candidate at Northeastern University. His research interests include approximate string query and bioinformatics, etc.邱涛(1989—),男,江西萍乡人,东北大学博士研究生,主要研究领域为字符串近似查询,生物信息学等。 WANG Bin was born in 1972. He is a lecturer at Northeastern University. His research interests include distributed database management and system structure, etc.王斌(1972—),男,辽宁沈阳人,东北大学讲师,主要研究领域为分布式数据管理,体系结构等。 YANG Xiaochun was born in 1973. She received the Ph.D. degree in computer software and theory from Northeastern University in 2001. Now she is a professor and Ph.D. supervisor at Northeastern University, and the senior member of CCF. Her research interests include theory and technology of database, data quality analysis and data privacy protection, etc.杨晓春(1973—),女,辽宁沈阳人,2001年于东北大学计算机软件与理论专业获得博士学位,现为东北大学教授、博士生导师,CCF高级会员,主要研究领域为数据库理论与技术,数据质量分析,数据隐私保护等。 Regular Expression Matching Algorithm Using Pivotal Factorsƽ QIU Tao+, WANG Bin, YANG Xiaochun QIU Tao, WANG Bin, YANG Xiaochun. Regular expression matching algorithm using pivotal factors. Journal of Frontiers of Computer Science and Technology, 2016, 10(3): 326-337. Abstract:Regular expression (RE) can describe complicated query, it depicts the common features of a set of text by the specific syntax. Since regular expression has the strong ability of expression and succinct syntax, it has been applied in many applications. In order to improve the matching performance of RE, this paper proposes a novel technique that pruning false negatives by utilizing pivotal factors, which are the valid filters with the least occurrences in text. Since the characters in text are not well-distributed, the difference of occurrences count of substrings will affect the pruning power of filters. Pivotal factors can achieve better pruning power by considering the occurrences count in text, which can also improve the matching performance of RE. This paper proposes the algorithm that computing pivotal factors by the partitions of RE, then further prunes the candidate positions by pivotal factors. Comprehensive experiments are conducted on real protein sequences and English text, the results show the significant performance improvement when utilizing the technique of pivotal factors. Key words:regular expression; filtering strategy; performance; pivotal factors doi:10.3778/j.issn.1673-9418.1507070 文献标志码:A 中图分类号:TP311.1315 关键因子的构造方法
6 基于关键因子的正则表达式匹配
7 实验测试与分析
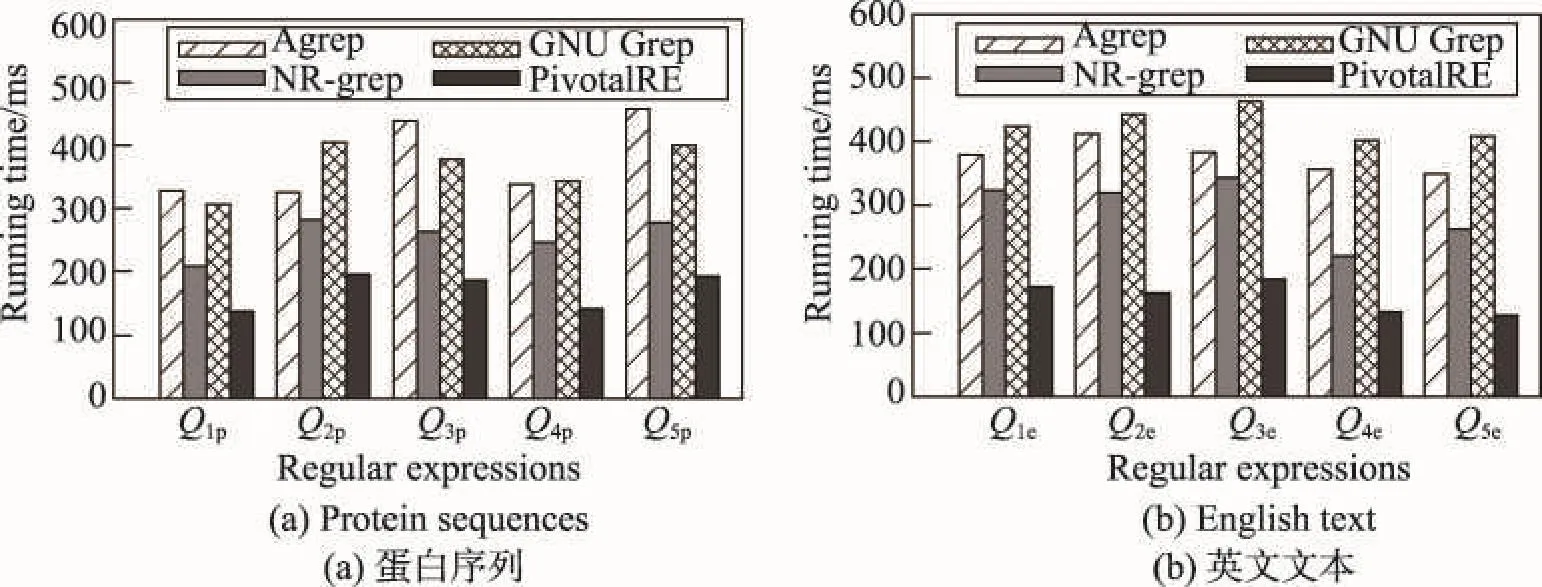
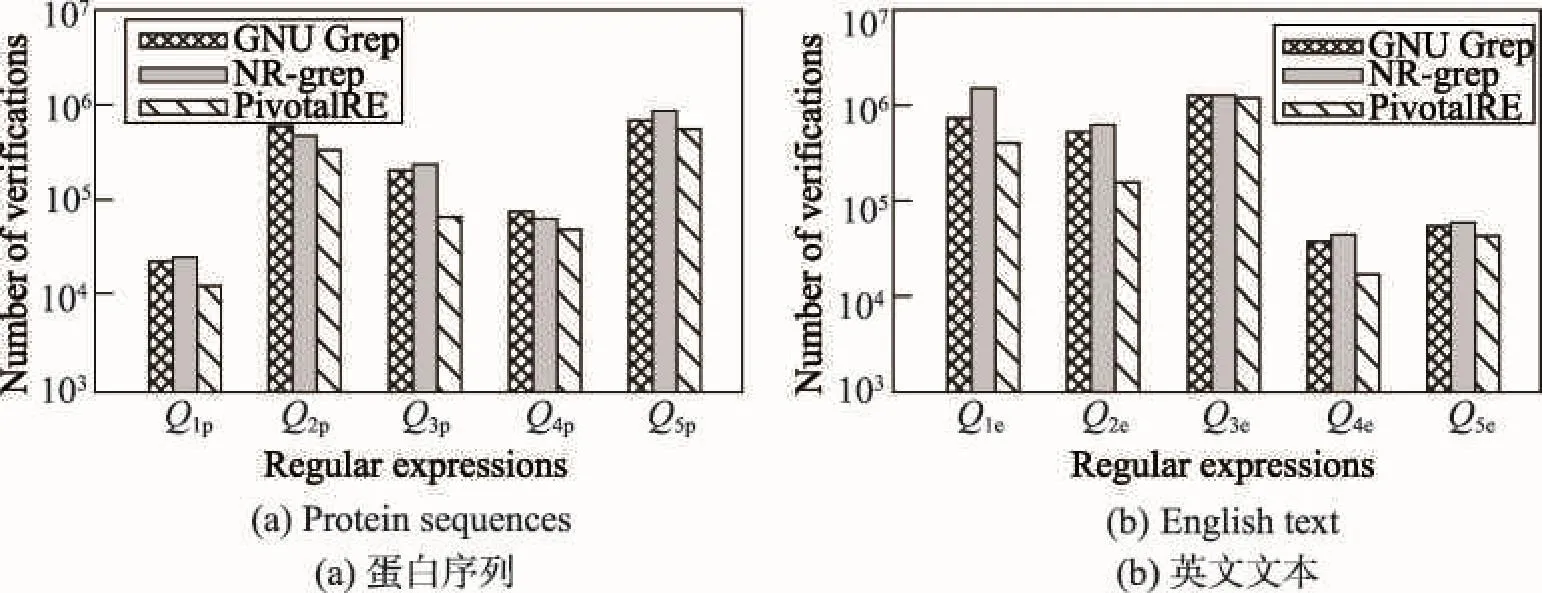
8 结束语



College of Information Science and Engineering, Northeastern University, Shenyang 110819, China
+ Corresponding author: E-mail: qiutao@stumail.neu.edu.cn
