
大数据背景下网络借贷的信用风险评估
——以人人贷为例
2016-06-02 10:17柳向东
统计与信息论坛 2016年5期
柳向东,李 凤
(暨南大学 经济学院,广东 广州 510632)
大数据背景下网络借贷的信用风险评估
——以人人贷为例
柳向东,李凤
(暨南大学 经济学院,广东 广州 510632)
摘要:在大数据时代,网贷平台每天流动着海量交易数据。为充分利用这些数据控制信用风险,运用数据挖掘算法建立了信用风险评估模型。由于网贷数据多为非平衡数据,所以通过多次尝试使用SMOTE算法进行处理,提高了模型评估性能。研究发现:随机森林模型更适合用于信用风险评估,其次是CART、ANN、C4.5。用户的婚姻、房/车产(贷)等信息重要程度较低,而公司规模、工作时间等信息,历史借款、信用评分等信用档案信息在信用风险评估中尤为重要。
关键词:P2P网络借贷;非平衡数据;SMOTE算法;数据挖掘;随机森林
一、引 言
随着互联网的发展和民间借贷的兴起,P2P网络借贷作为一种依托于互联网的新型金融模式开始兴起并迅速发展壮大。互联网金融平台利用搜索引擎、社交平台、云计算等,搜集和记录数据,基于这些数据,运用数据挖掘技术可以提高金融风险监控能力。用户信息、历史交易数据等的收集和记录,促进了资金供求双方的信息交流,在一定程度上降低了由于信息不对称等带来的金融风险。然而,由于中国P2P网络借贷起步较晚,信用体系不完善,相关法律法规缺失,平台跑路和借款人不按时还款甚至携款潜逃等问题仍时有发生,暴露出了较为严重的资金安全问题。另一方面,步入大数据时代,P2P网络借贷平台每日产生的交易数据数量大,包含的借贷信息多样,更新速度快,如何及时、合理、有效地利用这些数据获取有用信息,提高平台的风险监控能力至关重要。由此,利用平台的海量交易数据,采用数据挖掘技术,建立信用风险评估模型,为P2P网络借贷平台监管、投资者选择投标项目提供依据,具有重要的现实意义。
目前,国外在P2P网络借贷方面的研究较为系统深入,在P2P网络借贷的基本理论、风险问题、借款成功率等方面研究较多。在借款成功率方面,学者们研究了个人信息如性别、相貌等对借款决策和借款成功率的影响,并运用统计分析方法为借款人提供借款策略选择的量化分析工具[1-3]。在信用风险方面,学者们运用国外P2P网络借贷平台Prosper、Lending Club等提供的交易数据建立模型,进行了深入的研究,Emekter等探索了P2P网络借贷违约的影响因素,发现信用等级、收入债务比、FICO分值与周转利用率对违约行为有显著影响[2]。Malekipirbazari等建立了以随机森林为基础的分类方法进行信用风险评估,证明该方法在识别高信誉借款人上优于FICO信用评分和LC信用等级划分[3]。另外,近年研究发现,社交网络在网络借贷中具有一定的作用,Lin等发现借款人的社会资源越丰富,就越容易以较低成本获得贷款,且违约率更低[4]。Freedman等认为社交网络能够传递关于借款人信用风险的软信息,潜在地弥补了Prosper上硬信息的缺失[5]。
国内相关方面的研究起步较晚,对P2P网络借贷的研究仍处于较为初级的阶段,主要集中于发展现状与前景、运营模式、法律制度建设和监管分析、投资决策影响因素[6]。P2P网络借贷为个人提供了融资便利,但也存在个人信用体系不健全、逆向选择和道德风险问题。在风险研究方面,以信用风险的研究为主,包括违约特征分析、平台信誉等级预测、信用风险评估等。廖理等指出,非完全市场化的利率对借款人的违约概率有一定的预测作用,但仍有较高比例的违约风险反映在个人其他公开信息上[7]。王会娟等研究发现人人贷的信用认证机制能揭示信用风险,但评价指标单一,决定了揭示作用的局限性[8]。
总的来说,国内对于P2P网络借贷的研究有待继续深入,与国外相比,中国P2P网络借贷起步较晚,迅速发展也是在2012年以后,对外公布数据较少,实证研究方面的文献极少且大多运用的是美国Prosper、Lending Club公布的数据,方法和结论不一定适用于国内P2P网络借贷研究。本文使用R语言和Python编写网络爬虫程序抓取了国内P2P网络借贷平台的交易数据,不同于传统的方法,使用平衡效果更佳的SMOTE算法对非平衡数据进行处理,再运用6种数据挖掘算法建立信用风险评估模型,更贴近国内网络借贷的实际情况,也是针对大数据背景下的网络借贷信用风险问题研究的一种新的尝试。
二、模型描述
(一)常用数据挖掘分类模型
1.决策树。决策树是经典的分类技术之一,它以一棵有向无环树将分类过程展现出来,简单直观,在实践中应用广泛。在进行数据分类的过程中,从根节点到叶节点,采用贪心算法选择节点划分变量,使用局部最优决策构造决策树。根据划分方法的不同分为:基于信息论的方法如ID3、C4.5,基于Gini指标的方法如CART、SLIQ和SPRINT,根据χ2检验选择划分点的CHAID等,其中ID3只能用于离散型变量。本文选取最常用的CART、C4.5算法。
2.AdaBoost算法。AdaBoost算法是一种提升算法,可以自适应地改变训练样本的分布,使得基分类器侧重于那些难以分类的样本上。AdaBoost对每一个分类器Cj的预测值,根据训练样本权值更新参数αi=0.5ln((1-εi)/εi)(其中εi为错误率)进行加权:
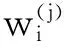
3.支持向量机。国内学者傅彦铭等曾运用支持向量机评估网络借贷信用风险,预测准确率为85.6%。支持向量机(support vector machine,SVM)是统计学习理论的一种实现方法,其基本思想是基于Mercer定理运用非线性映射把特征空间映射到Hilbert空间,在Hilbert空间使用线性的决策边界来划分样本。SVM可以用于分类和非线性回归问题以及高维数据分析。
4.人工神经网络。人工神经网络(Artificial Neural Network,ANN)是由大量的节点相互联结构成,是对生物神经网络的组织结构和活动规律的模仿。在前向反馈神经网络中上一层节点仅和下一层节点相连,在迭代过程中首先使用前一次迭代所得到的权值计算网络中每个节点,先计算第k层的输出再计算第k+1层的输出,然后根据误差大小从相反方向进行权值更新,重复上述过程,直到误差达到允许范围之内。它可以解决大量互相相关变量的回归和分类问题,但对噪声较为敏感,并且权值更新使用的是梯度下降方法,容易陷入局部极小值。
(二)随机森林
随机森林(random forests, RF)是Breiman首次提出的一种基于决策树的组合分类器算法,采用 CART算法建立的决策树作为元分类器,使用bagging方法生成不同的训练集,在单棵树的构造过程中,随机地选择特征(变量)进行节点分裂[9]。因此,该算法对噪声更加鲁棒,对多重共线性不敏感,对非平衡数据处理得到的结果比较稳健。
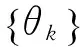
第一,生成训练样本集。采用自助法重采样技术,从含有N个样本的原训练集中有放回地随机抽取k个新的自助样本集,建立k棵决策树,每次未被抽到的样本形成k个袋外数据(OOB)。
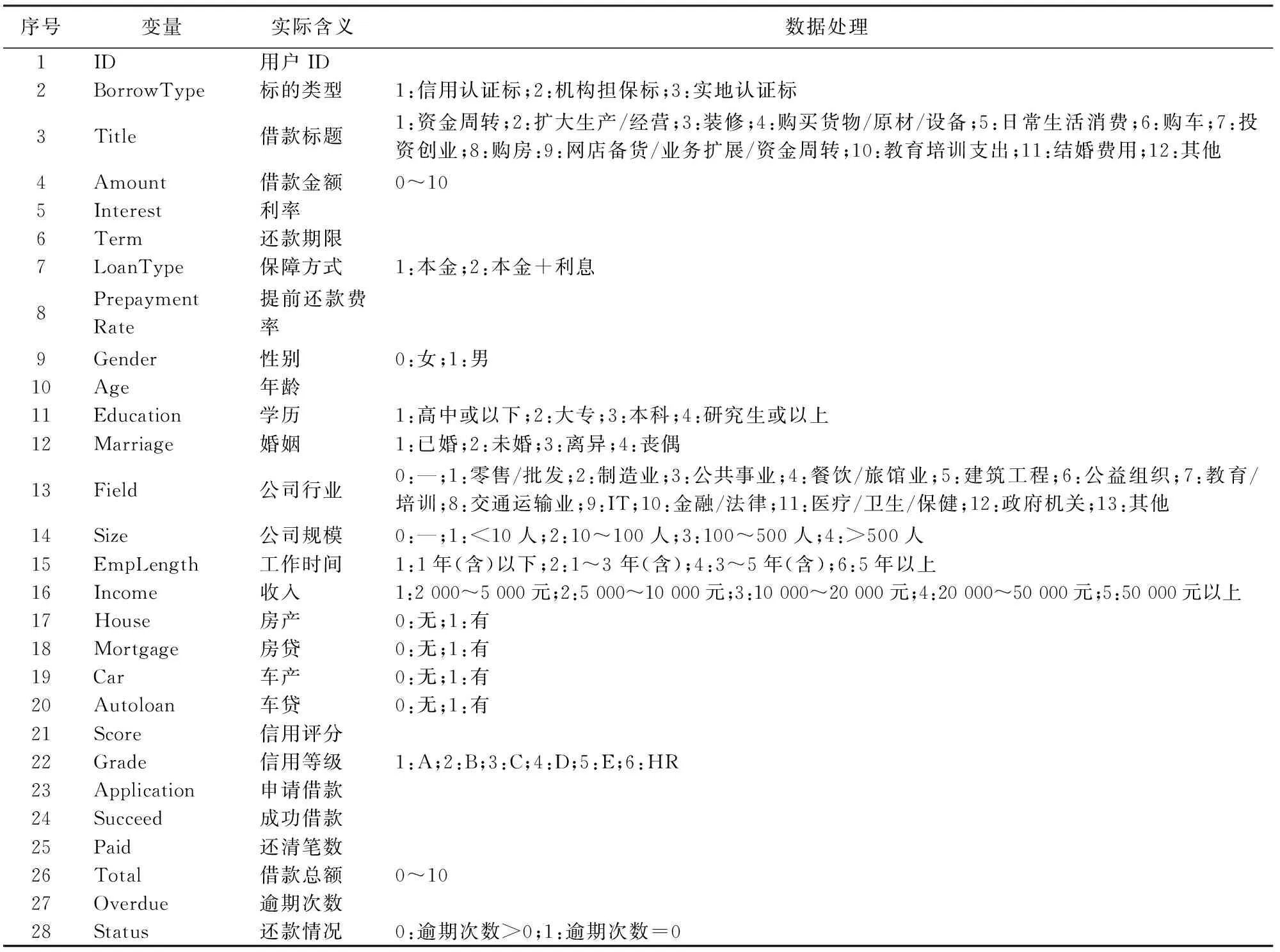
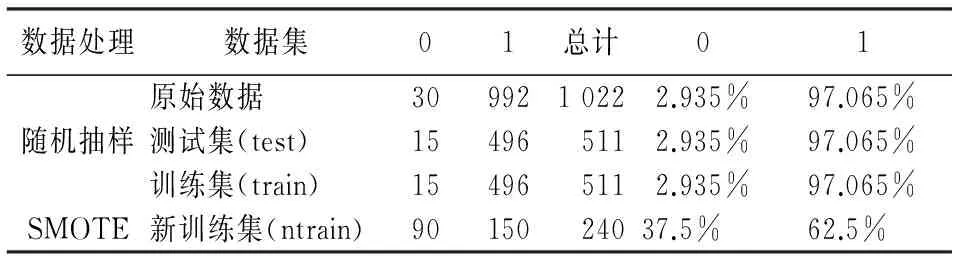
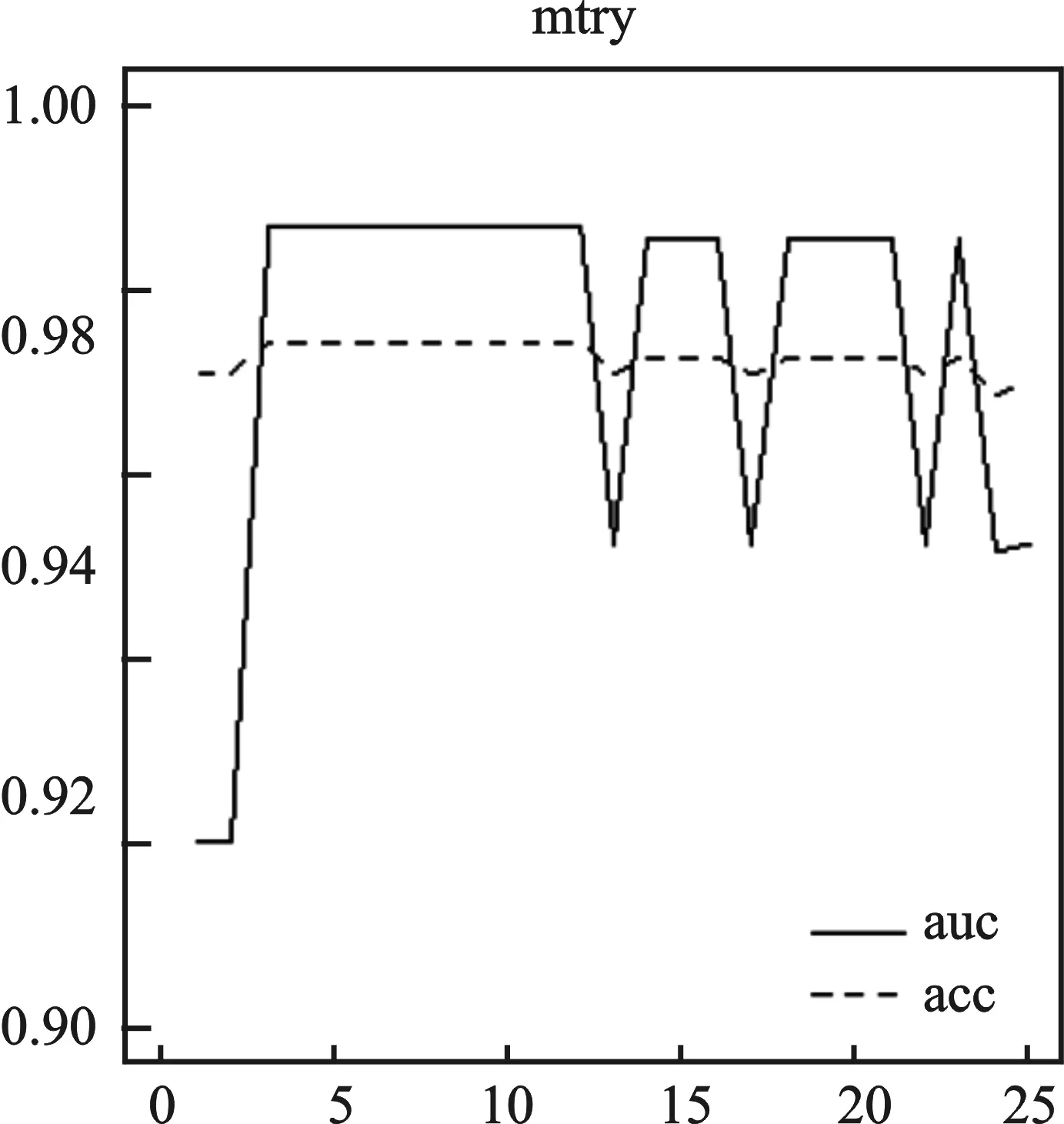
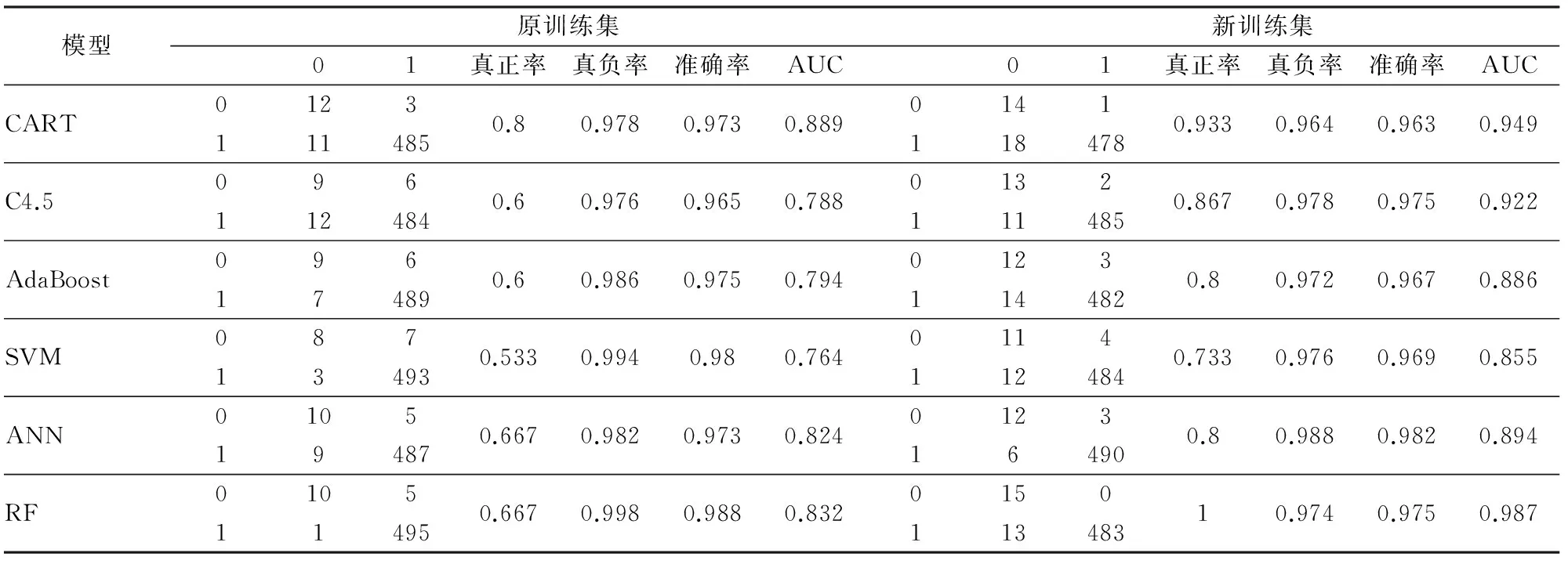
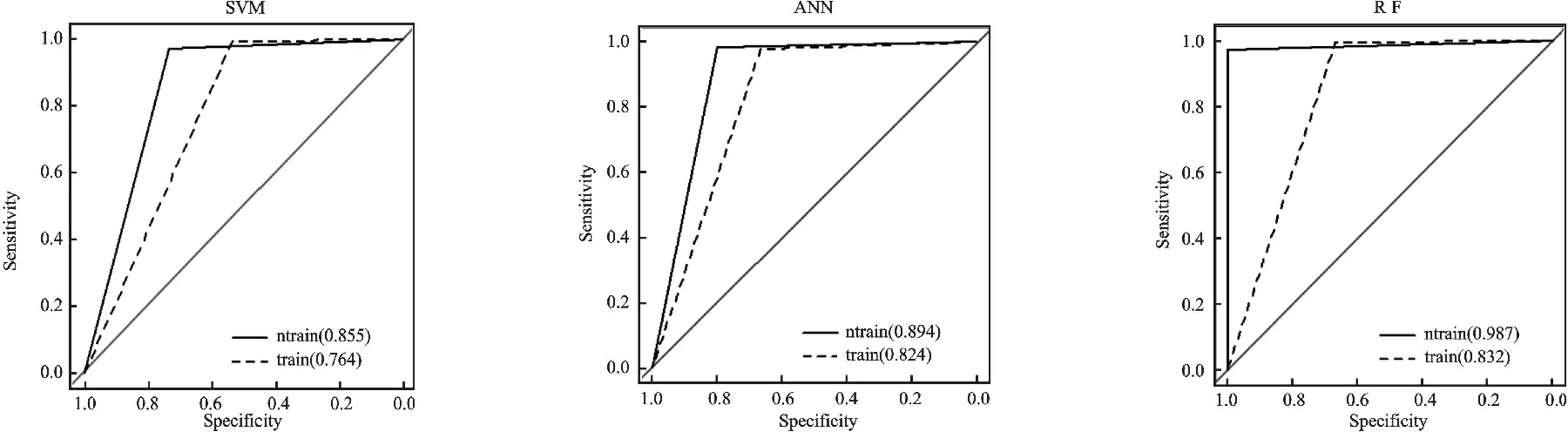
第二,决策树节点分裂。假设共有M个特征(变量),给定m 第三,组合决策树。根据生成的多棵决策树,采用多数表决平均所有决策树的输出结果得到最终结果。 2. 泛化误差。泛化误差是指一个分类器对训练集以外数据的错误分类概率,Breiman通过定义随机森林的间隔函数,结合大数定律(契比雪夫不等式),从理论上证明了当树的数目足够大时随机森林的泛化误差上界收敛[10]178-179。随机森林对给定样本(x,y)的间隔函数为: (h(x,θk)=j) 于是,分类器集合{h(x,θ)}的强度为: s=EX,Ymr(x,y) 间隔函数值越大,强度越大,分类器正确预测给定样本的可能性越大。那么泛化误差: 3. OOB估计及特征重要值。第一,OOB估计。使用bagging方法进行自助抽样时,没有被抽中的数据被用来预测模型分类的正确率,进而得到错误率的OOB估计,作为评估模型分类性能的指标。每一棵决策树都可得到一个OOB估计,将所有决策树的OOB估计取平均值,得到随机森林的泛化误差估计。第二,特征重要值。随机森林可以计算单个特征的重要程度,对已生成的随机森林模型中的每棵树,用袋外数据测试其性能,得到一个OOB准确率;随机地改变袋外数据中某个特征v的值即人为加入噪声干扰,用新的数据测试该决策树的性能,得到一个新的OOB准确率。原OOB准确率与新OOB准确率的差值即为特征v在该决策树上的重要值。将特征v在随机森林中所有决策树上的重要值进行平均,得到特征v的重要值。当原始数据中特征数目较多时,根据重要值排序选择部分重要特征输入模型可得最佳模型。 三、数据收集及处理 (一)数据来源 P2P网络借贷的借贷过程通过第三方平台实现,目前国内P2P网络借贷平台已达1 700多家,人人贷是国内最大、成立最早的P2P网络借贷平台之一。本文使用R语言和Python编写网络爬虫程序获取了人人贷公布的投资列表数据(http://www.renrendai.com/lend/loanList.action),包括每一个借款项目的借款详情,收集数据共1 022条,包含ID、金额、利率等近50个变量。 (二)数据预处理 1.剔除部分变量。取值均相同的变量,如还款方式(均为按月还款/等额本息)、严重逾期、逾期金额、超出金额(均为0)等;含义重复的变量,如项目ID(与信用等级对应)、信用额度(等于借款总额)等;与研究目的无关的变量,如昵称、允许访问等;数据严重不完整的变量,如加入人次、满标用时等。 2.缺失值处理。部分借款项目中缺失公司行业、公司规模、岗位/职称三个变量的值,经分析发现,这些项目的借款人均为网商,于是将公司行业记为电子商务,公司规模记为0,岗位/职称记为个人店主。 3.数据规范化处理。将逾期次数为0的标记为1,大于0的标记为0,作为输出变量;将性别、房(车)产、房(车)贷等二值型变量值以0和1表示;标的类型、借款标题、学历等变量以整数(1,2,3,…,n)标记;工作时间为时间段形式,取中位数作为变量值;将借款金额和借款总额转换成0~10之间的值:x′=(X-min(X))/(max(X)-min(X))×10。预处理后数据的基本情况见表1。 四、基于数据挖掘算法的信用风险评估模型 (一)非平衡数据处理 本文收集的数据中违约项目为30个(2.935%),非违约项目为992个(97.065%),属于非平衡数据集。由于类的分布是不平衡的,传统数据挖掘算法在处理这类数据时容易倾向于多数类,对少数类的关注较少,得到的模型分类性能降低。 表1 数据基本情况 注:表中数据经过了处理,其中第15行中工作时间是按中位数值处理。 1.SMOTE算法。国内外学者对非平衡类数据问题进行了深入的研究,提出了多种不同的处理方法:一类是使用数据采样方法来平衡数据集,比如向上采样(人为地增加少数类的样本)、向下采样(人为地减少多数类的样本)等;另一类是对数据挖掘算法进行改进,比如代价敏感学习等。向下采样容易导致一些重要样本信息的丢失,因此在实践中使用较多的是向上采样。最简单的向上采样方法是通过随机复制少数类样本来平衡数据,但容易导致过拟合[11]111-117。 合成少数类过取样算法(简称SMOTE)利用少数样本生成人工样本来平衡数据,在一定程度上解决了过拟合问题,该算法是由Chawla等提出的,通过在特征空间中相邻近样本之间插入人工样本来增加少数类样本的数目[12]。对少数类Smin中的每一个样本Xi∈Smin,搜素k个最近邻点,近邻可以根据距离(欧氏距离等)或相似系数(相关系数等)选择。从k个最近邻点中随机地选择一个样本点Yj。计算Xi与Yj对应特征向量的差值,并产生一个0~1之间的随机数δ,最后合成一个少数类的人工样本Xnew为: Xnew=Xi+(Xi-Yj)×δ 若向上采样倍率为n,那么在k个最近邻点中随机地选择n个样本点,即j=1,2,…,n。重复上述步骤,直到所有少数类样本都被处理完成为止。 在实践中,Chawla等(2012)将向下取样与SMOTE算法结合进行取样,取得了良好效果。SMOTE算法可通过R语言的DMwR包中的SMOTE函数实现,SMOTE (formula, data, perc.over=n1,k=5, perc.under=m1)假设原数据中少数类和多数类的样本数分别为N、M,向上采样倍率n=n1%,向下采样倍率m=m1%,最后得到的数据集中少数类样本数为N+nN、多数类样本数为nNm。 2. P2P网络借贷数据平衡性处理。首先,运用简单随机抽样方法将原始数据分为训练集和测试集。然后,采用SMOTE算法平衡训练集数据,少数类N=15、多数类M=496,取n=500%、m=200%、k=5,平衡后的训练集中少数类与多数类的比例为3∶5,运用于后续模型建立效果最好。 表2 数据构成情况 注:0,1表示还款情况类别。0:逾其次数>0违约,1:逾期次数=0(非违约)。 (二)模型实证分析 本文以还款情况作为分类变量,使用R语言编程,根据准确率和AUC的变化进行各个模型的参数选择,获得各个数据挖掘模型的分析结果。 1.模型参数选择与模型结果。这里主要介绍随机森林的参数选择,根据准确率和AUC的变化选择生成树的棵数(ntree)和节点分支所选变量个数(mtry)。在基于新训练集建模的过程中,当生成树的棵数小于40时,错误率均在0~0.05之间不规则变动,当其大于40时预测错误率等于0;节点所选变量个数在3~12之间时,准确率和AUC均达最大且处于平稳状态。因此,选取ntree=800、mtry=3建立模型,训练集中所有类别均预测正确,错误率的OOB估计值为0。具体见图1。 表3列出了各个模型的参数选择结果和重要变量,综合来看,变量Paid、Succeed、Application、Score、Field、Size、Grade、Emplength等较为重要,而AdaBoost和随机森林的运行结果显示House、Marriage、Autoloan、Mortgage、Car、LoanType、PrepaymentRate等变量重要值较小甚至为零,说明信用档案中的历史借款信息(成功借款、还清笔数、申请借款)以及信用等级和信用评分、个人信息中的工作情况(公司规模、工作时间)等在信用风险评估 中起着重要作用,而个人信息(婚姻状况、房/车产(贷)等)重要程度较低。信用等级和评分是人人贷根据借款人提交的材料按照信用评级机制(加减分规则)进行加工处理之后呈现给投资者的,在一定程度上综合反映了借款人的信用情况。历史借款信息之所以也是重要变量,是因为成功借款次数为1,还清借款次数为0的借款人为新用户,不存在逾期记录;借款人的工作时间、公司规模等情况,反映了借款人工作状况的稳定性,说明了其按时还款的能力。平台应加强重要信息的收集和储存,以提高审核阶段对劣质借款的筛选准确率,使投资者能够在保证资金安全的前提下获得收益。 图1 随机森林参数选择 表3 各个模型参数选择及重要变量 2. 数据平衡性处理前后模型性能比较。在实践中,一般采用准确率来评价分类器的性能,但在非平衡数据分类问题中,通常少数类的正确分类更有价值,而准确率将各个类同等对待,如果仅采用准确率来评价模型是不合适的,因此也考虑其他度量如灵敏度(真正率)和特指度(真负率)、ROC曲线与AUC(ROC曲线下方的面积)等。总的来说,使用SMOTE算法对训练集进行处理后建立的模型优于使用原训练集建立的模型。 表4 各个模型分类结果汇总 第一,准确率。使用新训练集建立的模型准确率在0.963~0.982之间,排名前三是ANN、RF、C4.5,虽然CART、AdaBoost、SVM、RF的准确率略有下降,但是6个模型对少数类(违约项目)的预测准确率即真正率均有明显提高,其中C4.5和ANN模型无论是对多数类还是少数类的预测准确率都高于使用原训练集建立的C4.5和ANN模型。 第二,ROC曲线和AUC。图2为两组模型的ROC曲线,ROC曲线越靠近左上角说明模型的分类性能越好,使用新训练集建立的模型ROC曲线更集中于左上角。使用SMOTE算法进行平衡性处理后建立的一组模型的AUC有明显提高且均达0.85以上,排名前三的为RF、CART、C4.5,其中随机森林(RF)的AUC达0.987接近于1,明显优于其他模型。 在信用风险问题研究中,一般来说,准确预测少数类样本,对投资者确定投资项目、平台筛选借款项目,保证资金安全,更有价值。因此,本文引入SMOTE算法对原训练集数据进行处理,提高了信用风险评估模型的性能。 图2各模型的ROC曲线 3. 各个模型性能比较分析。由表4可知使用新训练集建立的模型中,随机森林模型的真正率为1,AUC为0.987,准确率亦较高,并且它正确识别了所有的违约样本,可以初步判定随机森林模型的性能最佳。 本部分引入3折交叉验证,进行最佳模型的最终判定。原始数据中因变量有非违约和违约两个类别,为了平衡,将两个类别中的每一类都随机地分为3份,最后得到包含两类别的3份数据集。每次运行,选择一份作为测试集,剩下两份作为训练集,运用SMOTE算法对训练集数据进行处理,再用于模型建立,并用测试集检验模型的分类性能。 由表5可知,真正率的均值跨度较大即差异较大,排名靠前的是RF、CART、ANN,均达0.85以上,说明这3个模型对少数类的识别能力较强;而真负率(0.949~0.978)和准确率(0.946~0.976)的差异较小,真负率排名前3的是RF、AdaBoost、C4.5,准确率排名前3的是RF、C4.5、AdaBoost,由于准确率将少数类和多数类样本同等对待,因而只能作为判定的一个参考,不作为考虑的主要因素。除SVM和AdaBoost外,AUC均大于0.9,AUC排名靠前的是RF、CART、ANN。因此,随机森林模型的性能最好,可以用于P2P网络借贷的信用风险评估。 表5 3折交叉验证结果 注:少数类记为正类,多数类记为负类,TP为被正确预测的正类样本数,FP为被错误预测的负类样本数,FN为被错误预测的正类样本数, TN为被正确预测的负类样本数。 五、结论与展望 本文针对P2P网络借贷中的信用风险问题进行深入研究,并建立数据挖掘模型评估借款人的信用风险,为平台做好信用风险评估模型的建立和应用提供一定的参考。研究结果显示: 第一,针对非平衡数据,采用SMOTE算法对原训练集进行处理,再用于建模,模型整体预测的准确率变化较小,ROC曲线更靠近左上角且AUC有明显提高,模型对存在违约风险项目的识别能力显著提高。因此,SMOTE算法能够提高各个信用风险评估模型的性能。第二,使用3折交叉验证评估模型性能。无论是真正率、真负率和准确率,还是ROC曲线和AUC,随机森林模型都优于其他几个模型,其次是CART算法、人工神经网络、C4.5算法。第三,变量重要性。借款人的个人信息中公司规模、工作时间较为重要,而婚姻状况、房/车产(贷)等信息重要程度较低,信用档案信息包括历史借款信息如申请借款、成功借款、还清借款,信用评估信息如信用分数、信用等级等也尤为重要。因此,平台应加强上述重要信息的收集和审核。 随机森林模型对违约项目的识别能力最好,且整体评估性能最佳,可以用于P2P网络借贷中借款人的信用风险评估。此外,信用风险评估模型的建立和应用有助于平台有效地对海量借款信息数据进行分析,推动以大数据为基础的新型信用评分体系的建立和完善,也将对平台的风险控制起到良好的推进作用。未来研究将致力于以下几个方面:引入用户行为分析相关理论对借款人进行用户行为分析,并探索实时用户信用风险评估系统的建立。 参考文献: [1]Puro L, Teich J E, Wallenius H, et al. Borrower Decision Aid for People-to-people Lending[J]. Decision Support Systems, 2010, 49(1). [2]Emekter R, Tu Y, Jirasakuldech B. Evaluating Credit Risk and Loan Performance in Online Peer-to-Peer (P2P) Lending[J]. Applied Economics, 2015, 47(1). [3]Malekipirbazari M, Aksakalli V. Risk Assessment in Social Lending Via Random Forests[J]. Expert Systems with Applications, 2015, 42(10). [4]Lin M. Peer-to-peer Lending: An Empirical Study[R]. AMCIS 2009 Doctoral Consortium, San Francisco, California,2009. [5]Freedman S, Jin G Z. Do Social Networks Solve Information Problems for Peer-to-peer Lending? Evidence from Prosper[J]. Ssrn Electronic Journal, 2008(8). [6]李焰,高弋君,李珍妮,等.借款人描述性信息对投资人决策的影响——基于 P2P 网络借贷平台的分析[J]. 经济研究,2014(A1). [7]廖理,李梦然,王正位.聪明的投资者:非完全市场化利率与风险识别——来自P2P网络借贷的证据[J]. 经济研究,2014(7). [8]王会娟,廖理.中国网络借贷平台信用认证机制研究——来自“人人贷”的经验证据[J]. 中国工业经济,2014(4). [9]Breiman L. Random Forests[J]. Machine Iearning, 2001, 45(1). [10]陈封能,斯坦巴赫, 库码尔.数据挖掘导论[M]. 范明,范宏建,译.北京:人民邮电出版社,2011. [11]Japkowicz N. The Class Imbalance Problem: Significance and Strategies[C]∥ In Proceedings of the 2000 International Conference on Artificial Intelligence (IC-AI'2000): Special Track on Inductive Learning, Las Vegas, Nevada, 2000. [12]Chawla N V, Bowyer K W, Hall L O, et al. SMOTE: Synthetic Minority Over-sampling Technique[J]. Journal of Artificial Intelligence Research, 2002, 16(1). (责任编辑:李勤) The Evaluation of the Borrower's Credit Risk in Peer-to-Peer Lending under the Background of Big Data:Evidence from RenRen Dai LIU Xiang-dong, LI Fen (School of Economics, Jinan University, Guangzhou 510632, China) Abstract:Massive transaction data is flowing on the Peer-to-Peer lending platforms every day in the age of big data. For the purpose of making the most of these data to control the credit risk effectively, we established the credit risk evaluation model of Peer-to-Peer lending using data mining methods. Moreover, due to the imbalance of the data, we decided to use the synthetic minority over-sampling technique (SMOTE) to improve the performance of the credit risk model after several tries. The empirical study found that Random Forests is more suitable for the evaluation of credit risk. CART, ANN and C4.5 also perform well. In addition, the borrower's marital status and possession of house, car, mortgage and auto loan is of no importance, but their personal information (company size, employment length, etc.) and credit information (loan information, credit score, etc.) play an important role in the evaluation of credit risk. Key words:Peer-to-Peer lending; imbalanced data; SMOTE; data mining; random forests 收稿日期:2015-11-18 基金项目:国家自然科学基金面上项目《带Lévy跳的多因子市道轮换框架下的仿射利率结构模型》(71471075);教育部人文社会科学研究一般项目《基于市道轮换框架下带Lévy跳的高频数据的波动率》(14YJAZH052);中央高校基本科研业务费专项资金资助项目“暨南跨越计划”《PMCMC算法在市道轮换框架下利率结构模型中的应用》(15JNKY003) 作者简介:柳向东,男,湖南浏阳人,理学博士,教授,博士生导师,研究方向:大数据理论及统计分析; 中图分类号:F832∶C812 文献标志码:A 文章编号:1007-3116(2016)05-0041-08 李凤,女,重庆黔江人,硕士生,研究方向:大数据统计与计量分析。 【统计应用研究】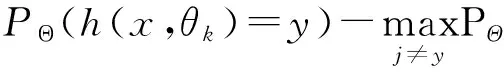




猜你喜欢
大众投资指南(2021年35期)2021-02-16
中国交通信息化(2020年1期)2020-07-27
安徽农学通报(2017年1期)2017-02-15
软件(2016年7期)2017-02-07
南水北调与水利科技(2016年6期)2017-01-06
时代金融(2016年27期)2016-11-25
大经贸(2016年9期)2016-11-16
电脑知识与技术(2016年23期)2016-11-02
智能系统学报(2013年1期)2013-01-28
智能系统学报(2013年2期)2013-01-28
