
基于二次随机森林的不平衡数据分类算法
2017-02-07 15:54刘学张素伟
软件 2016年7期
刘学+张素伟


摘要:不平衡数据集的分类问题是现今机器学习的一个热点问题。传统分类学习器以提高分类精度为准则导致对少数类识别准确率下降。本文首先综合描述了不平衡数据集分类问题的研究难点和研究进展,论述了对分类算法的评价指标,进而提出一种新的基于二次随机森林的不平衡数据分类算法。首先,用随机森林算法对训练样本学习找到模糊边界,将误判的多数类样本去除,改变原训练样本数据集结构,形成新的训练样本。然后再次使用随机森林对新训练样本数据进行训练。通过对UCI数据集进行实验分析表明新算法在处理不平衡数据集上在少数类的召回率和F值上有提高。
关键词:模式识别;不平衡数据;随机森林;模糊边界
引言
不平衡数据集是指数据集内各类别所占比例不均,其中某个或某几个类别比例远远小于其它类别。它广泛存在于真实的应用场景中,例如利用用户提交数据检测用户诈骗的可能性,一般诈骗用户数量远远小于普通用户;利用检测数据检测病人的疾病,如癌症,患癌症的病人数量远远小于检查的病人;其他有利用卫星图片油井定位、文本自动分类、垃圾邮件过滤等。在上述应用中,人们更关心的是对于少数类别的判断,事实上少数类错判带来的损失远远大于对多数类的错判,例如对于癌症病人如果错判,延误了最佳治疗时机,会给癌症病人带来致命威胁。因此研究不平衡数据集分类问题具有重大的现实意义。
传统分类方法以分类精度作为评判学习器的指标,在不平衡数据集中,学习器的预测结果肯定更加偏向比例更大的类别。weiss的实验,以分类精度为准则的学习器模型会导致识别少数类准确率下降,这样的分类学习器模型会倾向将样本预测为多数类。
本文在研究不平衡数据集特点和随机森林的特性基础上,提出了针对不平衡数据的二次随机森林分类算法,通过改变样本数据结构改善分类性能。
1不平衡数据的分类研究
由于多数类分类问题可以转化为二分类问题,因此本文研究是基于二分类的不平衡数据集分类问题加以研究。正类为多数类,负类为少数类。
除了类间不平衡度较大易造成对少数类的识别率降低外,Japkowicz等人的实验研究表明,类间不平衡度(正负类比例)并不是导致传统分类算法性能下降的首要原因,事实上当类间重叠度低时,传统的机器算法如C4.5、BP神经网络和SVM的分类性能仍较好,而当类间重叠度较高时,传统分类算法性能下降。以二维数据为例,如图1所示,当类间重叠度较低时,正负类边界清楚,少数类的信息并没有被淹没,而当图2所示类间重叠度高意味着正负类之间的边界模糊,少数类信息淹没在多数类中。分类算法的实质是建立一套规则,将数据集空间划分为不同类的区域,由于重叠度较高势必导致分类算法的学习性能下降。
由于样本比例悬殊和重叠度较高是导致不平衡数据集学习困难的主要原因,现有的研究也是集中在数据抽样技术和分类算法改进两方面。
1.1基于数据采样
数据抽样技术的目的是调整少数类和多数类的比例,降低数据不平衡度,抽样技术分为两类:向下抽样,即减少多数类数量;向上抽样,即增加少数类数量。常用的方法有:
随机向下抽样:随机去掉样本中的多数类,以降低不平衡度。可能会造成多数类表达能力的缺失。
随机向上抽样:随机复制样本中的少数类达到增加少数类样本数量的效果,可能会造成对于少数类的过学习。
虚拟少数类向上采样(synthetic minority over-sampling technique,SMOTE):它基于如下假设,两个距离较近的少数类样本之间仍是少数类,人工构造新少数样本。SMOTE算法步骤如表1:
SMOTE算法虽然避免了抽样的随机性,但依然存在一些不足,例如新样本的有效性,如有k个近邻中有散列点可能造成新样本点的有效性差。另外可能增加边界的点,使两类的边界更加模糊。对于孤立少数样本,smote算法会产生更多噪声。
以上都是基于采样技术,改变原样本数据集的分布结构,以达到降低数据集不平衡度的效果。
1.2算法改进
支持向量机利用核函数将线性不可分转化为特征空间线性可。传统SVM(支持向量机)分类面会偏向少数类,Wu等人通过调整边界,修改核函数修正偏差。传统集成分类算法错分样本和正分样本的权重相同,导致对少数类分类效果差,Joshi等人针对此提出在每次迭代时赋予正分样本和错分样本不同的权重,提高对少数类的分类效果。
基于分类算法的改进没有改变原样本数据集分布结构,其核心是侧重对少数类的划分,加大少数类的误判代价,使学习器对少数类敏感。但当少数类样本不能反映其真实分布时,容易出现过拟合现象。
2随机森林
随机森林(Random Forest,RF)是一种基于Bagging和随机子空间技术得到集成分类学习器模型,2001年,由Breiman明确提出。它由多个分类回归树(Classification and Regression Tree,CART)组成,并最终通过投票来决定最优分类结果。RF算法流程如表2:
随机森林已经被证明有分类效果更加准确、不易产生过拟合、平衡误差和多分类泛化能力显著等优点,此外随机森林根据需求不仅可以输出所属类别还能输出属于该类别的概率。因为CART树也是对特征空间进行随机子空间划分从而判断类别,故CART树错判的样例也集中在两类之间边界和类间重叠度较高的区域,因此可以利用随机森林的特性,根据错判率找到重叠度较高的区域。
3基于二次随机森林的算法改进
分类算法的改进多是在算法进行优化没有改变数据集的结构,而随机森林可以侦测出混杂在少数类样本空间中的多数类,不妨利用这种特性,将利用随机森林侦测到的噪音去除或者将多数类别去除,再对修改过的训练集进行随机森林训练,这样可以减小数据集的不平衡度,同时降低数据重叠度,可以称这种算法为TRF(two randomforst)流程如表3:
4不平衡数据集分类评价方法
根据具体应用场景,不同分类学习器模型考虑的评价指标不同。不过常见的评价指标是基于表4的混淆矩阵。
5实验结果
为了验证TRF算法对不平衡数据集的分类性能,选择5组不平衡程度大小不一的UCI数据集来交叉验证算法有效性。
5.1数据集的预处理
对具备多个种类的数据集合并某些类或者单独比较两个类别;对类型数据采用one-hot编码,变成数值型数据;对错值进行改正,对空值进行填充,对数据集进行随机排序和抽样。UCI的数据集信息如表5。
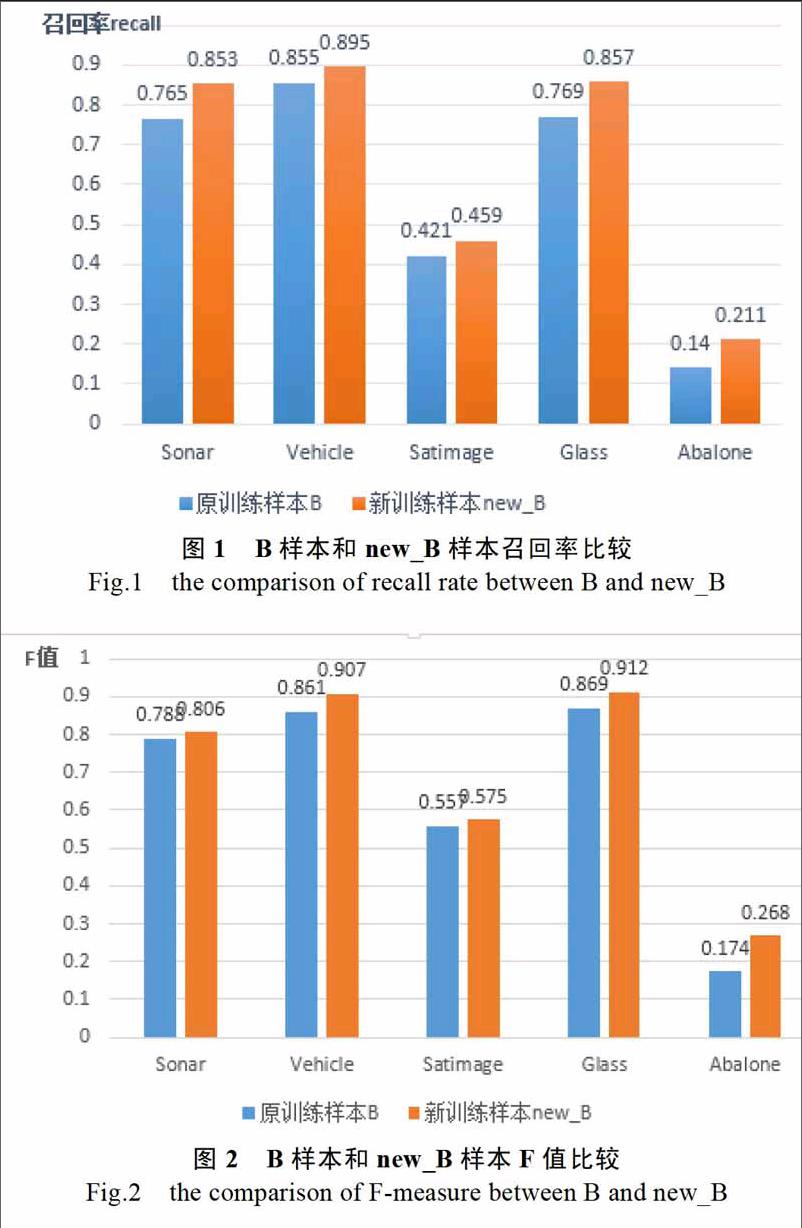
由于在不平衡数据集的实际应用场景中,少数类的召回率(识别出少数类的数目)提高对业务至关重要,同时不应该出现准确率降低太多(识别少数类的范围扩大)的情形出现,由于F值兼顾了准确率和召回率,并偏向两者之间较小的值,因此如果F值增大说明准确率和召回率都得到了一定提高。因此最终确定召回率和F值作为分类性能的评价指标。为了让算法之间性能比较更加具备客观性,以下结论都是进行10次实验平均以后得到的结果。
图1和图2分别给出了一次随机森林和二次随机森林算法在不同数据集上召回率和F值的比较。
可以看出在Sonar数据集上表现性能良好,说明基于二次随机森林的分类算法适用于一般数据集,在不平衡度同时在Vehicle、Satimage、Glass和Abalone基于二次随机森林的分类算法的两个度量指标都优于一次随机森林算法,实验结果表明基于二次随机森林的分类算法在处理不平衡数据集问题上有良好的性能。
6结论
不平衡数据集的分类学习由于其特殊性给传统分类算法带来极大挑战,本文从抽样技术和算法改进两方面概述了现今对不平衡数据集的学习研究,根据随机森林的特性,提出采用二次随机森林算法,改变原训练数据集结构,通过在UCI数据集上的实验证明此算法较普通的随机森林算法在召回率和F值指标上表现较好,在处理不平衡数据集上有明显优势。
猜你喜欢
中成药(2018年2期)2018-05-09
电子测试(2017年23期)2017-04-04
智能系统学报(2017年5期)2017-01-22
南水北调与水利科技(2016年6期)2017-01-06
海军航空大学学报(2015年1期)2015-11-11
现代电子技术(2015年15期)2015-08-14
现代电子技术(2015年8期)2015-07-09
智能系统学报(2015年3期)2015-01-29
河南科技(2014年5期)2014-02-27
