
数据挖掘在独立学院招生录取评鉴中应用
2016-05-30 11:13:18舒懿,李栋
长春大学学报 2016年4期
舒 懿, 李 栋
(1.北京理工大学 珠海学院,广东 珠海 519085 ;2.澳门城市大学,澳门 999078)
数据挖掘在独立学院招生录取评鉴中应用
舒懿1, 李栋2
(1.北京理工大学 珠海学院,广东 珠海 519085 ;2.澳门城市大学,澳门 999078)
摘要:云技术、数据挖掘、互联网+等概念已经渗透到各个行业领域。高校每年招生产生的大量数据也逐渐被学校重视起来重新考量。本研究使用数据挖掘技术决策树ID3算法和其改进算法C4.5,探究这些数据运用在招生宣传决策中的可行性和有效性,并寻找录取新生的信息之间的关联规则。提出了把数据挖掘技术应用于高校招生工作和高校管理工作的新思想,并建立了高校招生的数据挖掘模型。
关键词:数据挖掘;独立学院;ID3算法;C4.5算法;招生决策
1研究背景及意义
中国的高等教育过去几十年飞速发展,迅速从精英教育阶段跨入大众化教育阶段。伴随高等教育改革而新兴的独立本科院校扮演着重要角色。独立本科院校的招生宣传工作与公办高校相比较有着明显差异。随着中国人口红利的逐渐消失,独立本科院校的招生工作面临学费高昂、学校名誉较低、招生形式灵活、生源稳定性不佳等特点,招生宣传工作的好坏直接关系学校的生存与发展。
随着大数据时代的到来,云技术、数据挖掘、互联网+等概念已经渗透到各个行业领域。与此同时,高校每年招生产生的大量看似无用的数据也逐渐被学校重视起来重新考量。如何从这些数据中提取潜在价值,使其成为高校招生宣传工作参考的重要指标,演变为一个迫切的议题。由于现代数据的大、多、繁、冗等特点,如何更有效地、更精准地、更快速地对数据进行分类和挖掘是广大科研工作者的不懈追求。
在目前独立本科院校每年给定招生配额的大背景下,如何优化各个省份不同专业的配置,不同专业的招生名额分配,都成为影响学校招生计划完成率以及新生报到率的重要考量。录取考生的信息不是进行简单的图表化,而应该找寻各个信息之间的关系。因此,把数据挖掘技术应用于独立本科院校的招生宣传决策中有着巨大的实用意义。
2研究方法及分析
本研究以广东省某独立学院2015年招生录取数据为研究基础,选择决策树ID3算法进行分类规则的研究,分析录取学生中不同性别、不同生源地等等因素影响下的新生报到特点;根据数据间的联系,对于未来新开设的专业,或者新投放的招生地区,通过此算法,来判别某一专业或某一地区未来生源是否充足,亦或某一招生地区是否存在潜在的生源对象,实证宣传策略的可行性及可靠性,利用数据挖掘算法来实现广东省独立本科院校招生宣传效果的重点研究。在现有的招生宣传中遵循的一些基本性原则文献、高校生源竞争的宣传策略文献、ID3算法的改进研究、C4.5算法等文献的基础上,针对招生宣传的质量评价以实例数据为基础,尝试运用C4.5算法进行定量的评价研究,对改进招生宣传工作缺少量化指标与依据进行改善。[2][3]
(一)ID3算法
ID3算法是对1966年Hunt等学者提出的CLS决策树概念学习系统基础上进行改进的,可以称作是决策树算法的经典。ID3算法能够揭示隐藏的模式和关系,通过把最大信息的增益(Gain)的属性作为节点进行划分,将所有信息根据节点来构建一颗树[1-3],例如:对于学校而言,树的主体就是被录取的学生读还是不读,接着根据生源地、分数、性别等等确定节点进行自上而下枝叶的生长,构建一棵简洁明了的决策树。信息增益是期望信息或者信息熵的有效减少量,意味着信息增益(Gain)值越大信息的意义就越大,也可以理解为某种信息的出现率[2,3]。具体计算方法如下:
(1)以决策属性分类的样本集信息熵的推导公式: (公式2.1)

其中E(D)表示信息熵值,将整个样本集分为P正例集和N反例集,|P|表示P正例集的元素个数,同理|N|表示N反例集的元素个数。
(2)以各个条件属性划分样本集的类别条件熵的推导公式:(公式2.2)


(3)以条件属性划分样本集的信息增益推导公式:
例如:属性A的信息增益推导公式:
Gain(A)=E(D)-E(D|A) (公式2.4)
本研究以广东省某独立学院2015级录取新生名单,选取20人作为样本数据集合T(如下表1)

在数据集合中“是否报到”属于决策属性,“性别”“生源地”“参加宣讲”“考生特长”属于条件属性,对以报到为类标记的样本元组进行统计分析(如下表2)。

决策属性条件属性性别生源地参加宣讲考生特长报到男女广州深圳是否有无是(12)577512093否(8)53530853
(二)接着我们依据以上公式2.1-2.3探究构造决策树的模型:
(1)计算样本数据集合T的决策属性“是否报到”的信息熵:
(2)分别计算四个条件属性划分样本集的条件熵:
4.根据以上结果,运用公式2.4来求取四个属性的信息增益值分别为:
Gain(性别)=Info(报到)-Info(报到|性别)=0.9716-0.94065=0.03095
Gain(生源地)=Info(报到)-Info(报到|生源地)=0.9716-1.06866=-0.09706
Gain(参加宣讲)=Info(报到)-Info(报到|宣讲)=0.9716-0=0.9716
Gain(考生特长)=Info(报到)-Info(报到|考生特长)=0.9716-0.96412=0.00748
此时,选取信息增益值进行分类,“参加宣讲”的条件属性的信息增益值为0.9716,在四个条件属性中具有最强的分类能力,通过ID3算法把信息进行了初步规整,分为参加过宣讲的数据和没有参加过宣讲的数据两部分:
数据集合A=参加过学校宣讲会的12名考生
数据集合B=没有参加过学校宣讲会的8名考生
因为“参加宣讲”进行信息分类带来的不确定程度最小。所以,在构建招生信息决策树时,首先选择“参加宣讲”作为根节点,下一步对数据集合A和B进行以上往复运算分类,从其他三个条件属性中继续寻找信息增益值最大的属性做下一步分类属性,直到分析完毕,建构一颗完整的决策树。决策树如图1:
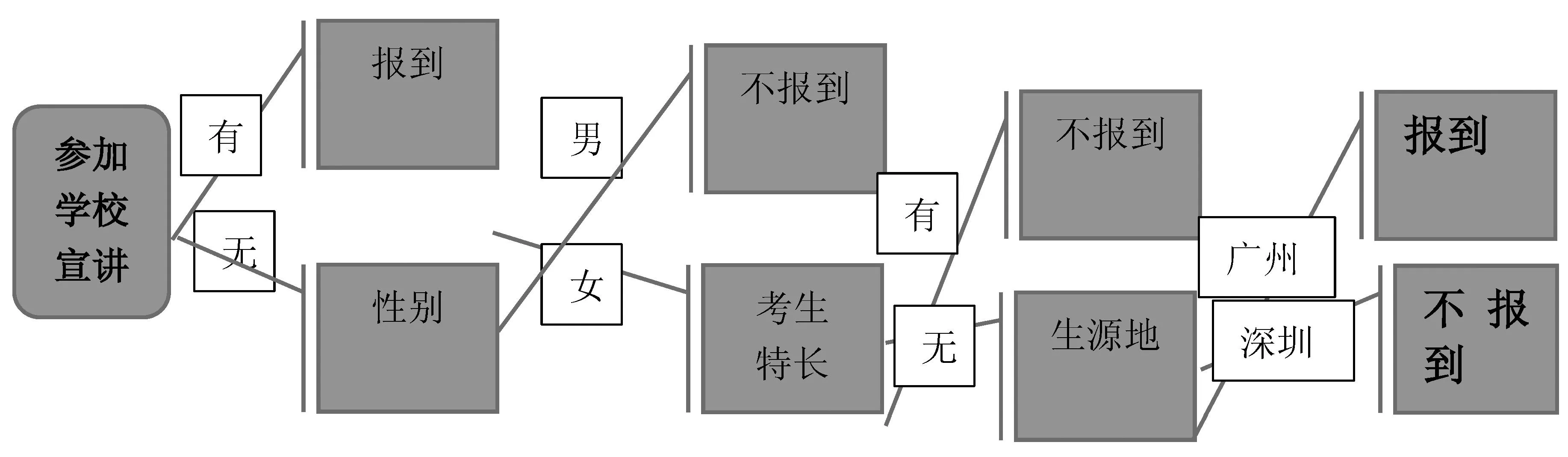
图1 决策树
以上分析仅仅选取20个学生信息作为阐述ID3算法,数据虽然真实,但在数量上以及条件属性关系上略有欠妥之处,另外在实际研究录取学生是否报到上,高考分数、志愿情况、专业配置、家庭收入、父母教育背景均属于研究范围内的条件属性。而通过ID3算法在构造决策树时只能对离散型信息进行分类,对连续性数值类型的高考成绩无法处理,通过计算信息增益值来确定决策树的根节点,这样算法的选择偏向于取值较多的属性[1,2],但是这样的属性在招生决策时不一定是最优属性。
(三)C4.5算法
C4.5算法是在ID3算法的基础上进行的改进,克服ID3算法缺陷提出了新的决策树构建算法。使得C4.5算法成为2006年以来IEEE数据挖掘国际会议选入数据挖掘十大经典算法[1]。在ID3算法基础上提出的改进有:
(1)ID3算法实用信息的增益值来衡量信息的属性标准,而C4.5算法改进为使用信息增益率(Gain Ratio),如此改进可以避免在进行信息属性选择时候出现对取值较多属性的偏向情况。其原理就是求得特定信息增益值与其分裂属性的信息熵的比值[1][3]。具体公式如下:
其中,A表示屬性,T表示按照属性A划分的样本集,K表示條件屬性A的K個屬性值通过上文引用的例子来解释C4.5算法的具体运用,样本集中共有20个样本,其中14个样本属性为有“考生特长”,6个样本属性为没有“考生特长”,上文已经计算了Gain(考生特长)=0.00748,那么属性“考生特长”的信息增益率计算如下:
Gain(考生特长)=Info(报到)-Info(报到|考生特长)=0.9716-0.96412=0.00748
Gain Ratio(考生特长)=0.00748/0.88129=0.00849
(2)C4.5算法可以处理连续数值型属性,处理方法按照连续数值属性进行排序,然后将该属性划分若干分割点,对每个分割点的信息增益率进行计算,取信息增益率最大的方案最为最终的分割方案实现连续数值属性的离散化,选取决策树的根节点。具体改进方法如下所示:

样本T1T2T3T4T5T6T7T8T9T10成绩511512519520522523524528538540报到是否是是是是是否是否
首先将T1-T10十个属性值划分9个分割点,然后分别计算9个分割点的信息增益率,例如第四分割点在T4与T5之间,将属性划分为{T1,T2,T3,T4}和{T5,T6,T7,T8,T9,T10}两部分,

报到考生成绩≦S4≧S4是(7)34否(3)12
因此我们可以求得决策属性“报到”的信息熵:
以属性“考生成绩”划分的“报到”的条件熵:
Gain(考生成績)=Info(到)-Info(到|考生成績)=0.8813-0.8755=0.0058
由公式计算属性“学生成绩”的信息熵:
由公式计算属性“学生成绩”的信息增益率:
Gain Ratio(考生成绩)=0.0058/0.9709=0.1282
通过分别计算9个分割点的信息增益率,取最大信息增益率的分割点就可以将“考生成绩”属性进行离散化,进而进行根节点的划分和决策树的构建。
3发现及结论
综合前期对该独立学院2015年录取学生做出的问卷调查,部分信息结合C4.5决策树构建方法,做出详细分析,针对招生宣传工作兹提出以下发现和结论:
(1)获得C4.5决策树模型,以及对于影响决策树分类的变量,从影响程度高低排列分别为:参加宣讲会、性别、成绩、高考类型、年龄、宣传登记、所在地区,其中是否接受学校宣传对报到影响程度较大,而宣传登记的影响程度大于考生所在地区的影响程度。
(2)提前确定报考院校考生录取率较高。研究发现考生在高三及高考填报志愿期间选择目标学校的占79%,特别在高考填报志愿期间选择目标学校的占39%。在志愿填报时,有明确目标的,自己心中有数占40.39%,比较茫然和查阅资料再定的占57%。而在高三期间确定报考志愿的考生报到率同比高考填报志愿期间高出7.8个百分点。
(3)考生关注“校园环境”,“教学、师资”宣传大有空间。数据显示2015级新生选择本学校最主要的原因是“校园环境”(68.16%),其后依次是 “学校的社会声誉”(32.94%)和“专业特色”(32.79%)等。但在不同省份学生的关切点略有差异,因此对于招生宣传工作人员应该有策略讲方法的针对不同省份考生的关切点进行重点宣传。
(4)多媒体成为考生获取信息的主渠道。研究发现在参与调研的4597名广东考生中有将近88%的新生都未看到过学校招生简章,2015级学生获知我校信息的来源最主要的渠道是当地招生报考目录(63.27%)、学校招生简章和海报(26.44%)亲戚朋友推荐(22.46%)。另外,部分学生通过报刊网站、微信、贴吧等获悉我校信息。2015级学生以学校招生指南作为我校信息渠道同比2014级学生高出17个百分点。我校新生报到的人数中有77%新生没有参加我校在各地举行的高考招生咨询会,而只有23%新生参加了招生咨询会,参与情况较2014年略微提升。另外,值得我们注意的是,在参加过我校招生咨询会的同学中,有854人接近65%的学生认为参加招生咨询会对报考有直接影响。
(5)专业信息获取渠道较为狭窄。2015级新生对“专业的培养目标和就业范围”普遍有所了解,63.23%的考生通过学校网站获取报考专业信息,通过招生宣传人员了解专业情况的考生占比5.76%。此外,学生对于学校优势学科及专业情况不甚了解,在参加招生咨询会过程中工作人员对考生的问题解答满意度直接影响考生报考学校的意愿。
4思考及建议
(1)全面更新线上宣传端口,发挥宣传正面效果。
以上结果显示,学校的官方网站是独立类本科院校获取专业信息,了解学校情况的主要网络传播媒介。从资源的投入产出比来看,学校官网是一种不需耗用额外费用的自有电子媒体,独立本科院校要善用此媒介,使其发挥具备详细、便捷、快速、准确的为考生提供报考参考咨询的功能。除此之外,可以增加考生与校方互动功能,以利于来年招生传销和决策,强化效果与无形。
(2)灵活调整宣传方式,准确选择宣传时机。
研究发现学校可以在宣传招生期间,对于不同省份县市灵活选择招生宣讲会的时间、地点、对象,学校招生海报等宣传资料根据宣传需要动态增减并且宜采取进校进班全面铺开的形式进行张贴宣传,对于招生宣传工作时机赶早不赶晚,并与下一级教育机构保持长期稳定的合作关系,以提高我校知名度和声誉,促进招生。
(3)突出宣传学校优势,提升宣传人员专业素养。
研究结果发现,录取学生中参加招生咨询会考生报到率高于未参加招生咨询会考生,现场宣传人员左右考生选择就读院校之意向。因此,对于参加各类招生宣传工作人员,宜经过专业训练,将学校硬件、软件、学科、师资之优势规整总结,便于解答。期望使咨询学生家长留下良好影响,杜绝派公差、轮值方式派出不适任人员[2]。
我国高等教育已经步入改革的关键时期,长期以来积累的众多数据应该为学校招生决策提供参考,通过数据挖掘技术的应用,可以促进教育和改革的良性发展。中国的高考招生制度具有非常强的计划性和政策性。因此,本研究通过一个小的数据集阐释了ID3算法和C4.5算法在招生决策中的具体应用,具有一定现实意义。具体实践不一定对所有地区的独立学院均适用,后续可以进步一探讨相关改进方法的运用,将理论研究付之于实际,产研结合,通过开发建立高校的招生录取分析系统为高校个体提供更精准有效的招生决策服务。
参考文献:
[1]姚亚夫,邢留涛.决策树C4.5连续属性分割阈值算法改进及其应用[J],中南大学学报(自然科学版),2011,42,(12):3772-3776.
[2]杨学兵,张俊.决策树算法及其核心技术[J],计算机技术与发展,2007(1):44-46.
[3]刘玉文,数据挖掘在高校招生中的研究与应用[D].上海:上海师范大学,2008.
[4]朱巍,谭峰.高校局域网考试系统设计[J].黑龙江八一农垦大学学报,2013(2):81-83.
责任编辑:程艳艳
Application of Data Mining in Enrollment Assessment in Independent Colleges
SHU Yi1, LI Dong2
(1.Zhuhai School, Beijing Institute of Technology, Zhuhai 519085, China;2.City University of Macau, Macau 999078, China)
Abstract:The concepts of cloud technology, data mining and Internet+ have been penetrated into various industries. A large number of data generated from enrollment each year are gradually being taken and reconsidered by colleges. The study uses data mining techniques decision tree ID3 algorithm and its improved C4.5 algorithm to explore the feasibility and effectiveness of these data in the application of enrollment propaganda decisions and to seek for the rules of association between information among enrolled students, presenting the ideas of applying data mining technology to college enrollment and management and establishing data mining models of college enrollment.
Keywords:data mining; independent college; ID3 algorithm; C4.5 algorithm; enrollment decision
中图分类号:TP311
文献标志码:A
文章编号:1009-3907(2016)04-0022-06
作者简介:舒懿(1982-),女,安徽旌德人,硕士,助理研究员,主要从事招生政策、高等教育管理方面研究;李栋(1988-),男,山东烟台人,讲师,博士研究生,主要从事教育管理、成人教育、思政教育方面研究。
基金项目:2015年广东省教育统计科学研究计划项目(14TJ0015)
收稿日期:2015-10-28
猜你喜欢
北京航空航天大学学报(2021年6期)2021-07-20 07:23:56
大众投资指南(2021年35期)2021-02-16 01:06:26
电子制作(2019年19期)2019-11-23 08:41:36
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年19期)2018-11-14 02:37:02
电子制作(2018年16期)2018-09-26 03:27:06
电力与能源(2017年6期)2017-05-14 06:19:37
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
信息通信技术(2015年6期)2015-12-26 01:16:46
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
