
基于Apriori算法的事件识别方法研究
2016-05-14 04:35张梅程利伟
数字技术与应用 2016年5期
张梅 程利伟
摘要:事件的识别对人们社会生活具有重要意义。本文借鉴Apriori方法进行事件规则挖掘,采用对扩展触发词进行规则约束的方式来完成事件识别任务,具体采用扩展触发词方式进行数据筛选,得到初步结果集;采用触发词方式获得的语料结果作为规则挖掘集合,从中得到适合事件识别的规则。通过与扩展触发词方法结果的对比,结果表明采用机器学习方法进行规则挖掘对事件识别具有很好的适用性。
关键词:Apriori算法 新闻语料 事件
中图分类号:TP391.1 文献标识码:A 文章编号:1007-9416(2016)05-0000-00
1引言
事件抽取隶属于信息抽取领域,旨在把非结构化的信息用结构化的自然语言表达出来,使用户可以得到对感兴趣的事件信息的直观反应,事件抽取的研究是科学发展的需要,具有深远的理论意义和广泛的应用价值。它可以结合数据挖掘、机器学习、数据库等多个学科的技术和方法,在自动文摘、自动问答、信息检索等多个领域体现出广泛的应用价值[1,2]。
近些年事件抽取的相关工作进展得如火如荼,国内外涌现出大量学者对其进行研究,研究的方法主要有两种:模式匹配的方法和机器学习的方法。其中,模式匹配的方法通过将待抽取的事件和已知的模式进行匹配来完成抽取任务;机器学习的方法则是依赖于分类器的构建和事件特征的发现,选择合适的事件特征并应用适当的分类器来完成。
本文介绍的内容试图找到一种方法,以此方法可以在大量的新闻内容中筛选出事件[3]。此方法结合传统分类方法与机器学习的分类方法且借鉴ACE中对于事件抽取的相关概念[4],对其做出相应调整,并将其应用到新闻中事件的类型识别上。
2基于Apriori的事件识别算法
事件类型识别是事件抽取的一个子任务。目前处理事件抽取的方法一般分为两个步骤:事件类型识别和事件元素识别。在事件类型识别的常用方法中,基于触发词的识别方法具有准确率高,抽取方法简单易行等优点。但是这种抽取方法往往得到的结果集比较小,可以使用《同义词词林(扩展版)》扩展事件触发词的方法虽然可以使得结果集增大,但是却使得准确率有所下降。
本文采用Apriori算法进行事件识别。一般对于给定的项目集合,算法通常尝试在项目集合中找出若干相同子集。该算法采用自底向上的处理方法,即频繁子集每次只扩展一个对象(该步骤被成为候选集产生),并且候选集由数据进行检验。当不再产生符合条件的扩展对象时,算法终止。
算法约定,事务的集合用D表示,X=>Y表示关联规则,其中“=>”是关联操作,X表示关联规则的先决条件,Y表示关联规则的结果。事务集合D中关联规则X=>Y由支持度S和置信度C来约束。支持度表示在规则中出现的频率,其公式表示为
S(X∪Y)= Count(X∪Y)/Count(D),
即事务集D中包含X和Y的事务所占的比例;置信度表示规则的强度,其公式表示为
C(X=>Y)= S(X∪Y)/S(X)
即事务集D中包含X的事务中有多大可能性包含Y。
Apriori算法是一个基于两阶段频繁集理论的递推方法,算法设计分为两部分:预设支持度,找出所有支持度大于该最小支持度的集合;根据支持度得到的集合进一步迭代得到最终结果。
其步骤如下:
(a)扫描:通过单趟扫描事务集合D计算出各个1项集的支持度,排除那些不符合预设支持度的项,得 到频繁1项集的集合,记作L(1);
(b)连接:假设集合L(k-1)已求得,现需要用L(k-1)求得L(K),L(k-1)中的每个项集与其他项集进行相互连接操作,可以得到候选集C(K);
(c)剪枝:根据算法性质,任何非频繁项集合都不肯可能是频繁项集合的子集,排除C(k)那些不包含在频繁项集合中的集合,即删除C(k)中所有其(k-1)项子集不包含在L(k-1)的项集;
(d)再次扫描:通过单趟扫描事务集合D计算C(k)中每项的支持度,排除那些不符合预设支持度的项,得到频繁项k项集的集合,记作L(k);
重复上述步骤直到L(k)为空,对L(1)到L(k)取并集即为最终结果。
实际应用过程中,应结合本身业务及数据特点将数据集合尽可能压缩,从而缩小频繁项目集合。
3实验
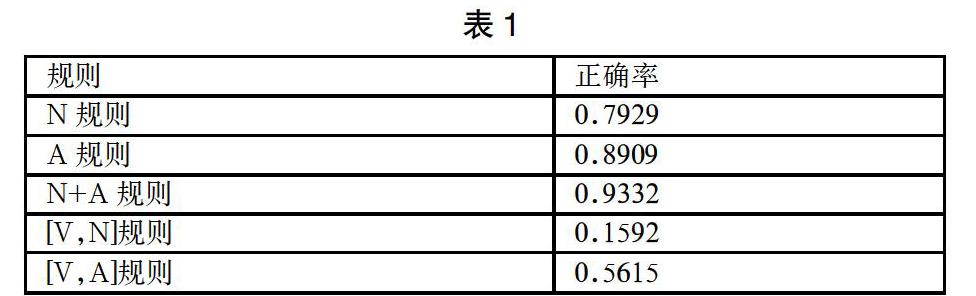
本文实验数据采用搜狐研发中心提供的2012年的全网新闻数据(SogouCA),该数据内容来自若干新闻站点2012年6月到7月期间国内、国际、体育、社会、娱乐等18个频道的新闻数据。在事件的类型识别中,应用Aprior方法对已知事件的语义角色及命名实体进行关联规则的挖掘。将基于Apriori方法挖掘出的规则模板在7000条数据测试集上进行测试,部分结果如表1所示:
分析测试结果,除[V,N]规则外各规则均表现良好,[V,N]规则属于不适用的规则,虽然其在开发集上的支持度比较高,但是测试结果其表现不佳。造成这种现象的原因可能是测试集数据分布不均衡,以致测试数据中符合[V,N]规则的数据稀少。
4 结语
本文借助规则模板的自动挖掘来缩小扩展触发词结果的范围,排除掉很多反例,使得性能得到提高。本文中提出的方法会挖掘出普适性规则(谓词规则)或是效率低下的规则([谓词,地名]规则),这些不适用规则的识别是需要进一步研究的工作。
参考文献
[1]王伟,赵东岩,赵伟.中文新闻关键事件的主题句识别[J].北京大学学报(自然科学版),2011,47(5).
[2]杨亮,林原,林鸿飞.基于情感分布的微博热点事件发现[J].中文信息学报, 2012,26(1).
[3]赵军,刘康,周光有,蔡黎,开放式文本信息抽取[J].中文信息学报,2011,25(6).
[4]涂新辉,张红春,周琨峰,何婷婷.中文维基百科的结构化信息抽取及词语相关度计算方法[J].中文信息学报,2012,26(3).
猜你喜欢
计算机应用(2016年12期)2017-01-13
电子技术与软件工程(2016年22期)2016-12-26
新闻界(2016年7期)2016-12-23
电子技术与软件工程(2016年20期)2016-12-21
安徽师范大学学报(2016年3期)2016-12-14
考试周刊(2016年92期)2016-12-08
新闻前哨(2016年11期)2016-12-07
计算机教育(2016年7期)2016-11-10
中国市场(2016年36期)2016-10-19
电脑知识与技术(2016年1期)2016-03-22
