
基于云平台MapReduce的Apriori算法研究
2016-12-21 11:19邵天会
电子技术与软件工程 2016年20期
邵天会
摘 要 随着医疗大数据剧增,医疗数据体现的价值更加明显,而传统的数据分析方案已经无法满足日益增长的数据要求,数据挖掘技术的更新更加体现出重要性,针对医疗数据挖掘算法的改进优化成为瓶颈,Apriori算法进行医疗数据的应用中发现众多优点,特别是基于兴趣度的改进算法,让医疗数据挖掘体现出更多的价值,并对改进的算法进行MapReduce化进行模型实验,获得更多的医疗价值。
【关键词】云平台 MapReduce Apriori算法
1 MapReduce工作原理
MapReduce是通过JAVA开发并简化了编程模型,让缺乏相关经验的程序员不需要了解底层,高效的开发分布式程序。MapReduce对大数据并行处理有突出的优点,尤其针对超过1TB数据更加明显,主要包括Map (映射)和Reduce (规约)两个步骤,中心思想是“任务分解,结果合并”。
2 常见的MapReduce化的Apriori算法
2.1 DD算法(Data Distribution)
CD算法的优点是不必要将候选集分布到每个节点,只要分割原始的事务集,从而扫描事务集的次数得到极大的降低。CD算法的缺点是随着节点数量的增加,内存的浪费也会同比增加。DD算法与CD算法不当节点数量不断增加,消耗的内存不断增长,在进行数据处理的过程中,处于事务集和候选集的交互节点,明显增加了交互次数,导致开销增大。
2.2 CaD 算法(Candidate Distribution)
DD算法的缺点产生原因在于频繁项集发生于每次的计算,如果某个节点出现停滞,其他节点需要等待,这样无形中消耗了时间。CaD算法解决了这个问题,在进行第一次计算时,每个节点通过频繁项集独立产生候选集Cm。同时,事务集也被有选择地分配给各个节点以独立计算的计数。这样大大减少了候选集对节点的依赖。
2.3 生成频繁项算法
具体过程如下:
(1)过InputFormat把事务集划分N个数据块,每个数据块的格式为(TID,LIST),同时M个节点进行独立的运算各自的数据块,格式中的LIST为事务标志TID相对应的项目号。
(2)通过程序Map的执行,每个数据块分别生成各自对应的局部候选项集,此时的候选集算法应用经典的Apriori算法,然后计算每个局部的候选项集的支持度,并且输出对应的中间值对。
(3)运行Combiner程序于每个节点,对每个节点Map程序的结果进行Combiner合并,然后将每个节点产生的中间值利用Hash进行分区,针对不同的分区执行Reduce过程。
(4)将第三步生成的不同分区的Reduce结果进行候选集支持度求和,进而由局部支持度得到全局支持度。
(5)利用局部支持度和最小支持度的阈值进行比较获得局部的频繁项集。
(6)通过把各个局部频繁项集融合得出全局频繁项集
(7)迭代重复操作,直到算法完成。
相应的伪代码:
输入:事务集分块后Ti,最小支持度的阈值m-sup;
输出:相应的频繁项集I
I=查找频繁项集(Ti)
i=2;
While(I not null){
i++;
Ci=apriori算法结果;
for 每个候选集扫描;
Ci=Map();}
I=Reduce();
Reduce I;
Map程序:
For 每个属于Ci的I
EmitInter(I ,局部支持度);
Reduce(I 局部支持度);
Result 为0;
For 每个属于Ci 的I;
Result=局部支持度的求和;
Emit(本次的I,result);
2.4 关联规则算法的发现
经过上述方法获得频繁项,进而发现相应关联规则:
(1)数据按照行分块,即每行对应一个数据块,每个数据块生成一个键值对(L,li),L作为偏移量,li为数据块生成的项。
(2)利用Map进行键值对扫描,进而生成相对应的关联规则。
(3)对第二部生成的关联规则进行Reduce规则约束,把结果进行输出并保存。
(4)把预先设置的阈值和我们生成的关联规则中的置信度进行对比从而得出算法的关联规则。
2.5 实例分析
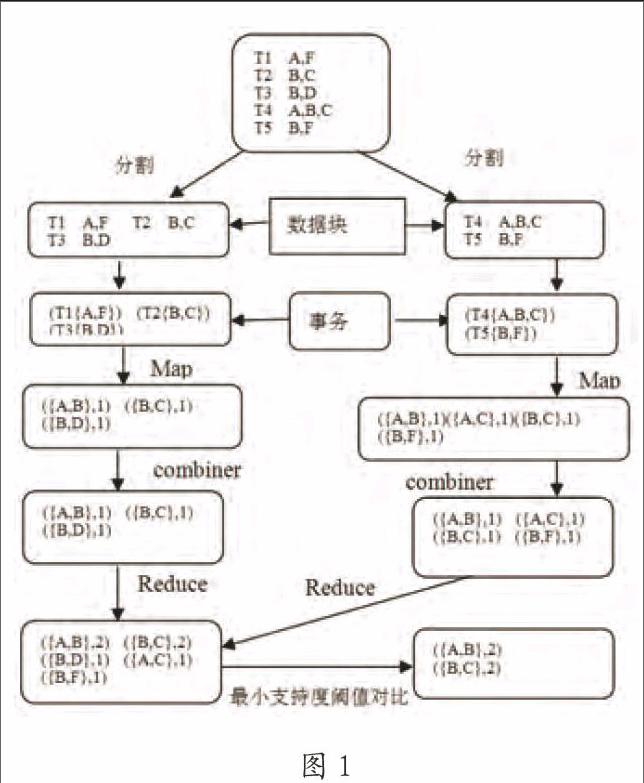
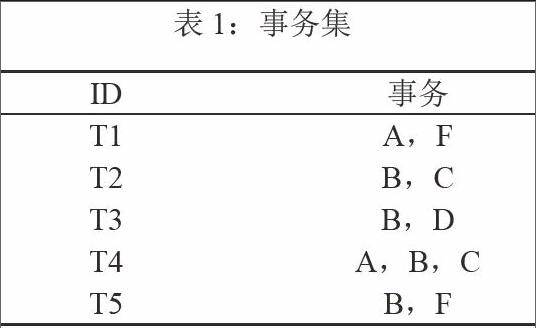
为了验证该算法,进行事务集算法实例分析,如表1。
按照改进的算法进行事务集挖掘流程如图1所示。
由此得出经过改进的MapReduce化的Apriori算法实现了频繁项集的挖掘,得出({A,B},{B,C})为频繁项集。这仅仅是简单的事务集挖掘,随着事务集数量的增多,结点分配运算的增加,大数据挖掘效率提升更加显著。
参考文献
[1]http://Hadoop.apache,org/hdfs.
[2]Amazon simple storage service(Amazon S3)[OL]. http://aws.amazon.com/s3/,2009.
[3]Amazon simple queuing service (Amazon SQS)[OL].http://aws.amazon.com/sqs/, 2009.
[4]刘永增,张晓景,李先毅.基于Hadoop/Hive的web日志分析系统的设计[J].广西大学学报:自然科学版,2011, 36(01):314-317.
[5]MongoDB官网[DB/0L],http://www. Mongodb.org/display/docs/home.
作者单位
吉林医药学院 吉林省吉林市 132013
