
基于词干的蒙古语语音关键词检测方法的研究
2016-05-03 13:03高光来王宏伟
中文信息学报 2016年1期
飞 龙,高光来,王宏伟
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
基于词干的蒙古语语音关键词检测方法的研究
飞 龙,高光来,王宏伟
(内蒙古大学 计算机学院,内蒙古 呼和浩特 010021)
为了提高蒙古语语音关键词检测任务中的集内词检测性能,该文结合蒙古文的构词特点提出了基于词干进行检测的蒙古语语音关键词检测方法。首先,该文采用基于分割识别的蒙古语语音识别系统将语音解码成了网格文本,并对网格文本进行了混淆网络的转换;其次,采用关键词的词干部分对混淆网络文本进行了关键词的检测。实验结果表明,基于词干进行检测的蒙古语语音关键词检测方法明显优于基于词混淆网络的蒙古语关键词检测方法,并有效提高了系统的召回率和精确率。
蒙古语;词干;混淆网络;置信度
引言
语音关键词检测技术是根据用户给定的查询(Query),从指定的语音数据集中返回与其对应的语音片段。开展蒙古语语音关键词检测技术的研究不仅具有重要的实用价值,并对繁荣和发展少数民族文化、维护国家安全及边疆少数民族地区的稳定有重要意义。
蒙古语语音关键词检测系统可以分为两个阶段进行处理。第一阶段为识别阶段,通过蒙古语大词汇量连续语音识别(Large Vocabulary Continuous Speech Recognition, LVCSR)系统[1]将语音识别成文本;第二阶段为检测阶段,从识别的文本中查询对应关键词,并返回结果。蒙古文属于黏着语,蒙古文单词是由词根缀加多个后缀组成,而所有的词根和后缀可以组合成大规模的蒙古文单词。为了让蒙古语LVCSR系统能识别大规模的蒙古文单词,我们在以前的研究中提出了基于分割识别的蒙古语语音识别方法[2]。该方法将蒙古语LVCSR中的识别单位从蒙古文单词转换成了独立的词干和结尾后缀形式,很好地解决了大规模蒙古文单词的识别问题,并且该方法对语言模型的稀疏问题起到了适当的改善作用。
在之前的研究中,我们提出了基于词混淆网络的蒙古语语音关键词检测方法[3],并且证明了该方法明显优于基于词网格的蒙古语语音关键词检测方法,但是基于词混淆网络的蒙古语语音关键词检测方法的性能依然较低。本文结合蒙古文的构词特点,改进了基于词混淆网络的蒙古语语音关键词检测方法,并且得到了较好的实验结果。
1 蒙古文构词特点
蒙古文单词一般可以分解为词根和词缀两部分。蒙古文没有前缀和中缀,而只有后缀,后缀可以依次相加。蒙古文的后缀可以分为构词后缀、构形后缀和结尾后缀。结尾后缀是处于词末位置仅表示单纯的语法意义(主要是关系意义)的一种后缀。蒙古文的词根、词干和后缀的关系如图1所示。构词后缀和构形后缀属于词干后缀。结尾后缀则不属于词干后缀,它包含静词的格后缀、领属(物主)后缀、式动词(时间、人称)后缀和副动词后缀。在一般情况下,后缀的次序是构词后缀在前,构形后缀在后,结尾后缀在最后。单词中构词后缀和构形后缀都可以有一个以上,但结尾后缀一般只有一个[4]。
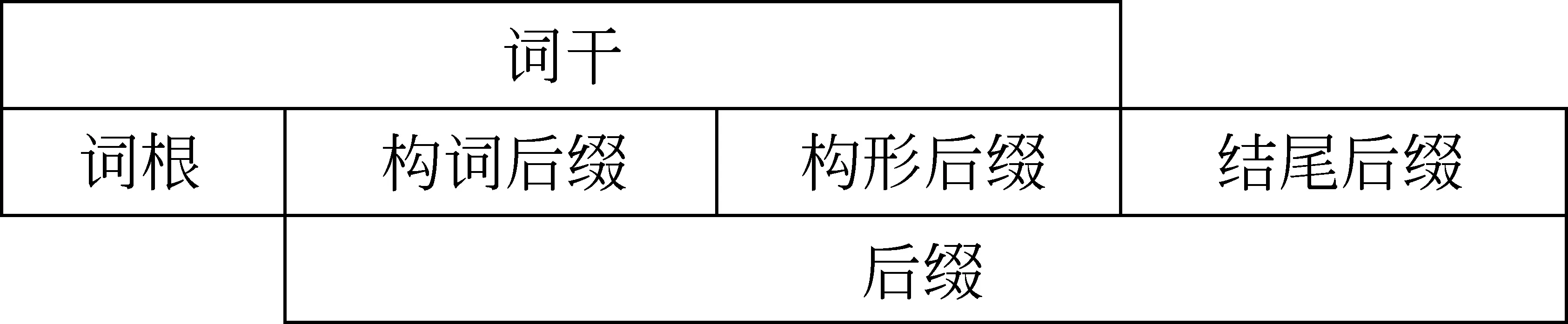
图1 蒙古文词根、词干和后缀关系图
2 基于词混淆网络的蒙古语关键词检测方法
基于词混淆网络的蒙古语关键词检测系统框架如图2所示。首先,本文将蒙古文语音文件通过蒙古语语音识别系统进行解码,并生成词网格文件;其次,将词网格文件转化成词混淆网络结构的文件,并建立索引;最后,从索引库中进行关键词的搜索和确认。
2.1 蒙古语LVCSR解码

图2 基于词混淆网络的蒙古语关键词检测系统框架
本文采用了基于分割识别的蒙古语LVCSR系统对蒙古语语音进行了解码。蒙古语语音文件通过蒙古语LVCSR系统进行多遍解码后可以生成词网格形式的文件。网格是一个有向非循环图,每一个节点表示一个时间点,每一条边表示一个识别单元假设(词干和结尾后缀)。网格中的每一个节点包含对应的时间信息和上下文信息,每一条边包含开始节点、结束节点、识别单元假设和该识别单元假设的声学模型得分、语言模型得分等。
网格可以用来进行音频文档检测,但是,网格的结构比较复杂,占用的存储空间也比较大。Mangu等人[5]提出的混淆网络结构是一种新颖的语音识别多候选存储结构,是对网格进一步处理的结果,比网格占用的存储空间更小,结构简单,能提供的信息比较丰富,并且研究表明混淆网络能获得比网格更小的词错误率[6-7]。本文将识别后的网格文件转换成了混淆网络文件,混淆网络结构图如图3所示。图中百分号开始的是结尾后缀, sil表示静音;null表示空弧,其他表示蒙古文词干,粗线表示正确的解码路径。

图3 混淆网络机构图
2.2 关键词检测
为了加快对词混淆网络的检测速度,我们对词混淆网络文件建立了索引。本文对蒙古文混淆网络文件建立了前向索引和逆向索引,建立前向索引的目的是便于产生逆向索引,逆向索引类似与信息检索技术中的倒排索引,用于快速定位关键词[8]。关键词检测和文本检索的不同之处在于语音要考虑关键词的发生时间和结束时间,语音的发生时间相当于文档中词条的出现位置。对于关键词检测,即使检测出的查询词与发生时间不一致也认为是错误的。另外由于语音识别结果的不确定性,必须对每个识别结果标注置信度,以衡量该项结果的可靠程度。
假设关键词Q,首先对关键词中的蒙古文单词进行词干和结尾后缀的切分,并表示为Q=(k1,k2,...,kn),其中n≥1,每个ki(1≤i≤n)称为一个查询项(蒙古文词干或结尾后缀),“关键词检测”就是以Q作为查询,从语音数据集中检测出与其相似的所有语音片段。如果相邻两个单词的时隙大于0.5秒(经验值),词干和结尾后缀的间隙大于0.2秒(经验值),就认为两个单词之间或词干和结尾后缀之间有插入项,否则认为这两个之间有前后连接关系。对于候选结果的确认,采用了后验概率作为了置信度得分。
3 改进的关键词检测方法


拉丁转写:ene masin-i gadagadv-aqa wrwgvlvgsan yvm.
中文意义:这个车是进口的。

拉丁转写:edeger masin tohogerumji-yi bur gadagadv-aqa wrwgvlba.
中文意义: 这些全部都是进口设备。

蒙古文的结尾后缀主要表示的是语法关系意义,单词切掉结尾后缀后词本身的基本意思不会发生变化。本文提出了对关键词进行结尾后缀的切分,并利用关键词的词干进行检测的方法。该方法有以下几个优点。
(1) 关键词的结尾后缀很可能带有一些关键词主要意思之外的额外信息,这样结尾后缀反而在关键词检测时变成了噪音,影响检测的召回率和精确率,而切掉结尾后缀则可以避免这种情况。切除结尾后缀的方法类似于信息检索中的停用词的去除。
(2) 本文采用了词干和结尾后缀分开识别的基于分割识别的蒙古语LVCSR方法对语音进行了解码。该方法解决了蒙古文大部分单词的识别问题,但是识别结果中会出现一些结尾后缀的错误识别问题。利用关键词的词干进行检测,则即使结尾后缀识别的不正确,也不会影响检测结果。

score(Q′,t,D)=
(1)
其中Pr (ki′|ti,D)为蒙古文词干ki′(1≤i≤n)在ti时刻的后验概率,Brank(ki′|t,D)为取值范围为0到1的提升系数。其中γ=1/n,查询词Q的持续时间为tn-t+dn。对∀1≤i≤n,蒙古文词干之间的时隙0≤ti-(ti-1+di-1)≤0.5秒(经验值)。

图4 改进的关键词检测系统的流程图
4 实验
本文采用的性能评价标准为召回率(Recallrate)、精确率(PrecisionRate)和虚警率(FalseAlarmRate,FA)。召回率是指关键词被正确找到的比例,精确率是指所有找到关键词中正确的比例,虚警率是指每个小时关键词平均被虚报的次数。关键词检测实验中使用的测试语音为21小时的录音语料。本文的实验选择了十个关键词对测试语音进行了检测,每个关键词包含两个到五个蒙古文单词。该十个关键词全部为集内词(IV),并且所有关键词在测试集上至少都出现过十次以上。每个关键词中有1~3个单词包含结尾后缀。实验使用的工具是隐马尔可夫模型工具HTK3.4[9]和语言模型训练工具SRILM[10]。
本实验对采用基于词混淆网络的关键词检测方法时不切掉结尾后缀的关键词和切掉结尾后缀的关键词的检测结果进行了比较。我们通过11点的召回率-精确率曲线分析了在混淆网络上两种关键词的检测结果,比较结果如图5所示。表1给出了11点召回率-精确率曲线的平均精确率、对应的召回率和虚警率。从表1和图5可以看出关键词切掉结尾后缀后进行检测的精确度和召回率都高于未切分的检测结果,并且虚警率也略低于未切分的检测结果。实验结果表明,基于词干进行检测的关键词检测方法不会受到结尾后缀的不同或结尾后缀的错误识别等问题影响,所以系统的性能会得到明显的提升。
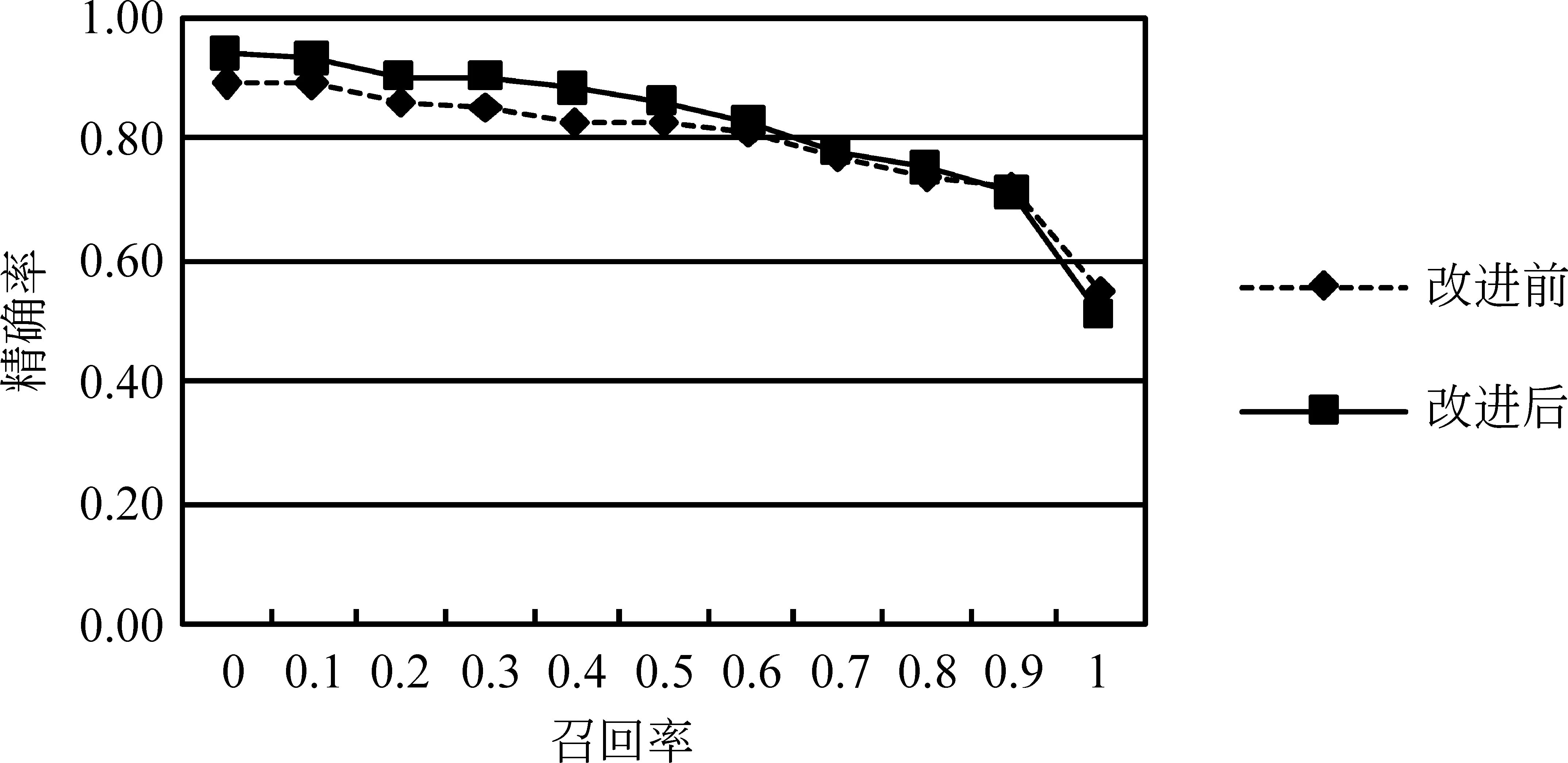
图5 改进后关键词检测方法和未改进方法的召回率-精确率曲线

表1 改进关键词检测方法和原来方法的比较
5 小结
本文结合蒙古文的构词特点,对基于词混淆网络的蒙古语语音关键词检测方法进行了改进。首先采用基于分割识别的蒙古语LVCSR系统对蒙古语语音进行了解码;其次,对生成的网格文件进行了混淆网络的转换,并对混淆网络文件建立了索引;最后,将关键词中的每个蒙古文单词进行了词干的切分,并利用切分后的词干对索引库进行了关键词的检测。实验结果表明,本文提出的改进的关键词检测方法明显优于基于词混淆网络的蒙古语语音关键词检测方法,系统的精确度和召回率得到了一定的提升。
[1] Feilong Bao, Guanglai Gao. Improving of Acoustic Model for the Mongolian Speech Recognition System[C]//Proceedings of The Chinese Conference on Pattern Recognition (CCPR2009), Nanjing, 2009: 616-620.
[2] Feilong Bao, Guanglai Gao, Xueliang Yan. Segmentation-based Mongolian LVCSR Approach[C]//Proceedings of The 38th International Conference on Acoustics, Speech, and Signal Processing (ICASSP2013), Vancouver, 2013: 8136-8139.
[3] Feilong Bao, Guanglai Gao, Yulai Bao. The Research on Mongolian Spoken Term Detection Based on Confusion Network[C]//Proceedings of The Chinese Conference on Pattern Recognition (CCPR2012), Beijing, 2012: 606-612.
[4] 清格尔泰. 蒙古语语法[M], 内蒙古人民出版社,1992.
[5] L Mangu, E Brill, A Stolcke. Finding consensus in speech recognition: word error minimization and other applications of confusion networks [J]. Computer Speech and Language, 2000, 14(4): 373-400.
[6] 黄湘松. 基于混淆网络的汉语语音检索技术研究 [D]. 哈尔滨工程大学博士学位论文. 2010.
[7] J Mamou, B Ramabhadran, O Siohan. Vocabulary independent spoken term detection[C]//Proceedings of ACM-SIGIR’07, Amsterdam, 2007: 615-622.
[8] P Yu, K Chen, C Ma, et al. Vocabulary-independent indexing of spontaneous speech[J]. Speech Audio Process. 2005, 13(5): 635-643.
[9] Young S, et al. The HTK book (Revised for HTK version 3.4.1) [M]. Cambridge University .2009.
[10] A Stolcke. SRILM—An Extensible Language Modeling Toolkit[C]//Proceedings of International Conference Spoken Language Processing, Denver, Colorado, 2002.
Mongolian Speech Keyword Spotting Method Based on Stem
BAO Feilong, GAO Guanglai,WANG Hongwei
(College of Computer Science, Inner Mongolia University, Hohhot, Inner Mongolia 010021,China)
To improve in-vocabulary performance in Mongolian speech keyword spotting task, we propose a Mongolian speech keyword spotting method by searching the stem according to the characteristic of Mongolian word-formation rule. First, Mongolian speech is decoded to lattice file by Segmentation-based LVCSR system, and this lattice file is converted to a confusion network. Then, we detect the keywords according to their stems among the confusion network. Experimental results show that the proposed method outperforms baselines based on word confusion network.
Mongolian; stem; confusion network; confidence measures

飞龙(1985—),博士,讲师,硕士生导师,主要研究领域为蒙古文信息处理、语音识别、语音合成。E⁃mail:csfeilong@imu.edu.cn高光来(1964—),硕士,教授,博士生导师,主要研究领域为模式识别、自然语言处理。E⁃mail:csggl@imu.edu.cn王洪伟(1989—),硕士研究生,主要研究领域为蒙古文信息处理。E⁃mail:wanghongwei6136@163.com
1003-0077(2016)01-0124-05
2013-06-08 定稿日期: 2014-03-20
国家自然科学基金(61563040,61263037);内蒙古自然科学基金(2014BS0604);内蒙古大学高层次人才引进科研项目
TP391
A
猜你喜欢
中文信息学报(2022年3期)2022-04-19
蒙古学问题与争论(2021年0期)2022-01-19
记者观察(2019年14期)2019-11-08
草原歌声(2019年1期)2019-07-25
蒙古学问题与争论(2019年0期)2019-03-29
草原歌声(2018年3期)2018-12-03
中国新通信(2016年17期)2016-11-17
电脑知识与技术·经验技巧(2016年1期)2016-03-14
辽金历史与考古(2016年0期)2016-02-02
民族古籍研究(2014年0期)2014-10-27
