
基于微博用户模型的个性化新闻推荐
2016-05-03 13:03古万荣董守斌曾之肇何锦潮
中文信息学报 2016年1期
古万荣,董守斌,曾之肇,何锦潮,刘 崇
(华南理工大学 计算机学院,广东 广州 510641)
基于微博用户模型的个性化新闻推荐
古万荣,董守斌,曾之肇,何锦潮,刘 崇
(华南理工大学 计算机学院,广东 广州 510641)
新闻推荐是互联网推荐系统的研究热点之一,传统的新闻推荐方法是在新闻网站内,通过记录用户浏览的新闻来实现推荐应用。然而,许多新闻网站并不强制要求用户必须注册才能浏览新闻。微博作为目前最主流的自媒体形式,它由用户自己发起或传递,进而实现草根媒体的职能。对新闻进行高效组织并使用微博进行新闻推荐,这是之前研究欠缺的。该文通过提出基于微博分析的新闻推荐,提出了基于新闻和微博本身特点的解决方法,从而实现微博和新闻的关联。实验表明,该文设计的各模块具备较高的效率和实用效果。
新闻推荐;文本分类;微博分析
1 引言
随着互联网技术的发展,越来越多的用户在线或使用移动设备浏览新闻,而不再购买报纸。据中国互联网信息中心报告,新闻应用是最热门的互联网应用之一,仅略低于网络音乐。然而,海量的新闻和微博会带来信息过载的问题,因此帮助用户筛选或推荐有用的新闻信息成为重要的研究课题。
尽管新近有不少研究是关于解决新闻推荐问题的[1-3],然而,新闻推荐仍然面临至少以下三个问题: 首先,需要快速而高效的新闻组织方式来处理每天产生的海量新闻,如何快速将新闻分类或聚类;其次,如何解决阅读上下文的问题,即用户更偏好于热点的新闻,如何获得热点新闻并考虑其权重;最后,受欢迎程度和新鲜性时刻变化着,如何正确设计变化模型也是目前的研究难点。
本文提出一个基于微博分析的新闻推荐系统,旨在完善新闻分类整理和用户兴趣偏好模型的建立。总体来说,本文的贡献主要有以下两点。
1) 提出了一个高效的新闻整理方法(第四节)。在新闻推荐过程中,新闻整理是必不可少的一个前提步骤,如何进行高效整理也制约着后续处理步骤的可行性。
2) 基于微博分析的用户模型建立方法(第五节)。本文通过对微博消息进行分析,从而构建用户模型,通过该用户模型实现新闻推荐。
文章其他部分组织如下: 第二节对国内外新近的推荐方法进行总结讨论;第三节介绍本文提出的新闻推荐系统框架;第四节介绍了本文根据新闻文本的特点提出的新闻分类整理方法;第五节介绍了本文提出的用户模型构建方法;第六节介绍了本文的推荐模块,将新闻和用户联系起来,并选择合适的新闻提供给用户;第七节是本文的实验部分;第八节中对本文工作进行了总结和展望。
2 国内外研究现状和相关工作
新闻推荐是推荐系统研究中的重要研究和应用方向,近年来也受到越来越多的科研人员注意。现有的新闻推荐方法可以大致分为三类: 基于内容的方法,基于协同过滤的方法和混合方法。
(1) 基于内容的方法。该方法是通过匹配用户以前使用过的新闻内容来进行后续的新闻推荐。Schafer[4]中称之为Item-to-Item协同方法。一般做法是将新闻文本表示成为向量空间模型(VSM),文献[5]使用TF-IDF构建VSM并利用了K-Nearest方法来推荐新闻。文献[6]使用了朴素贝叶斯方法来将新闻分类并构建用户模型。本文也使用SVM模型构建新闻并利用TF-IDF来表示索引词权重。基于内容的新闻推荐方法易于表示和实现,但未必任何数据都能方便地使用该方法,如视频、图片新闻。另外一个问题是内容过相似问题,即用户不希望总是被推荐类似的新闻甚至是一样的新闻。文献[7]提出了针对过相似问题的解决方法以提供给用户兴趣相似但不同的新闻推荐。
(2) 基于协同过滤的方法。该方法的提出促进了推荐研究领域的蓬勃发展,即使用用户的行为挖掘进行物品推荐。从另一个角度看,该方法与物品的内容无关,它可以粗略再细分为两类: 基于启发式的协同过滤和基于模型的协同过滤。前者是通过现实世界的现象,从而推断未来的推荐方式[8],后者是通过建立数学模型来进行推荐[9]。一般而言,购买和评分行为是推荐系统中的重要行为,而在新闻推荐应用中将评分行为二值化,即浏览过的为1,未浏览的为0[10]。协同过滤可以取得有效的推荐结果有赖于海量的物品和用户数据。但大多数用户只对少量的物品产生行为,因此会产生非常稀疏的用户物品矩阵并导致糟糕的推荐效果[11]。其中一个解决方式是使用人口统计学方法综合考虑用户的年龄、性别、教育水平、籍贯和职业等,另外一种解决方式是使用用户之间的相关性以及其他行为,如评论、转发和收藏等行为。本文利用了用户的微博数据来改进这些问题。
(3) 混合方法: 该方法将以上两种方法融合而成[12]。本文在一定程度上来看是一种混合方法,使用了基于内容的方法进行新闻分类,并使用微博数据的分析构建用户模型。
从新闻推荐的目的来看,本文和SCENE[2],EMM新闻浏览[13]和Newsjunike[14]类似。但SCENE没有考虑使用现有的关键人物和地点分析方法,EMM则没有提供个性化的新闻服务,Newsjunike则没有进行有效的用户模型构建。
3 系统架构
系统主要模块有三个,即新闻分类模块、用户模型建立模块和推荐模块,如图1所示。
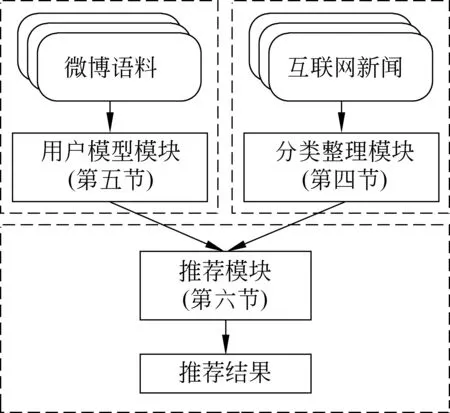
图1 推荐系统框架图
各模块的功能如下:
1) 分类整理模块。新闻的分类采用中国新闻出版总署制定的新闻出版分类标准,一共分为23个一级分类。考虑到新闻中人物作为重要的因子之一,本文将新闻的关键人物作为分类因子,融合到分类算法中。大量实验表明,使用关键人物作为分类因子,可以显著提高新闻分类的精度。
2) 用户模型模块。该模型的目的在于提取用户感兴趣的新闻方向。本文使用用户发表或转发的微博,通过倾向性分析、关注人物和地点数据等信息创建用户偏好模型。在这个模块中容易遇到用户冷启动问题,即当新用户刚注册或用户没有足够的微博数据时,该模型偏差就较大,在实际应用中,可以推荐热门新闻给这类用户以解决冷启动问题。
3) 推荐模块。本文将分类好的新闻和构建好的用户模型通过推荐选择方法找到合适的新闻。首先通过计算新闻和用户模型的相似度,然后通过候选集和用户模型获得推荐分布,最后根据新鲜度等因素调整推荐列表排序。
4 分类模块
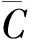
4.1 特征选择
在文本语料的处理中,每个文档的表示为SVM模型会导致向量维度灾难(可能会超过十万维),在这种情况下,一般都需要事先采用降维的方法将维度减小,然后再进行后续处理。一般来说,文本语料降维的方法有: 互信息量[15]、信息增益[16]、CHI统计量[17]。但这些方法都倾向于选择低频的词汇,而对于有噪声的互联网文本语料,这对分类精度没有好处。因此本文提出的特征选择方法对低频词倾向的选择方法进行了改良,首先挑选具备一定频度的高频词汇,具体做法如下。
1. 特征词粗选择
在训练语料中,设ti是一个词,Dfi定义为该词的文档相关频率,表示该词出现的文档除以所有文档,即词ti在所有文档中的分布情况。当Dfi大于某一阈值α时,说明该词具备一定的分布广度,这样可以初步过滤掉一些偶然噪声。Dfik定义为相关类的词频率,即在某个类Ck中,含有词ti的文档除以该类的文档数。当Dfik大于某一阈值β时,说明该词在类中具有较高频率。对于特征的粗选择,本文通过实验调整为α=0.01和β=0.1。通过这两个阈值可以选出两个不同的词集合Tem1和Tem2,这两个集合的交集Tem′=Tem1∩Tem2。
2. 使用词和类间的差异指标来进行精选择
本文使用文献[18]的方法来定义词和类间的差异性,如式(1)所示。
(1)
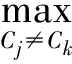
(2)

讨论:CHI统计量方法[17]是一个比较好的特征选择方法,但在互联网文本分类中,偶然的文本噪声会在CHI统计量方法中被放大,而这类词对分类是有副作用的,本文提出的方法先处理掉这些偶发的噪声,满足一定分布的词才会选为候选词。同时,在精细化选择阶段也借鉴了CHI方法的思想。本文采用的特征选择相当于两个阶段的融合,在特征选择方面,未来工作还可以尝试使用多种特征选择方法进行融合,以便选出对各种特征选择都表现较好的特征词。
4.2 新闻分类
在互联网海量新闻的环境下,对文本新闻语料进行分类需要耗费较多的计算内存和时间,同时,由于自然语言的特点,新闻文本一般存在复分类的特性,因此分类精度很难保证,本文在OneVs.All方法[19]的基础上,结合新闻语料本身的特点,融合了新闻关键人物等信息进行分类。OneVs.All方法将分类问题转化为一系列的二类分类问题,对于一个文档di,如果属于类Ck,则将其标注为1,否则可以将其标注为-1。二类分类问题可以表示为文本矩阵A和类向量y的映射pk,本文采用脊回归方法构建这个映射,如式(3)所示。
(3)
其中θ是一个正参数,用于调整估计偏差。为解决最小化的问题,一般需要对pk求偏导数,并使之为0,进而求的pk如式(4)所示。
(4)
其中I是与A矩阵同维度的单位矩阵。因为训练集的类别数为K,因此,可以得到一组映射向量P={p1,p2,…,pk}。可以使用码矩阵M来描述两个类别之间的相关性。假设Ck有Nk个训练文档Dk,j,其中j属于[1,Nk],M的元素表示两个类之间的相关因子,如式(5)所示。
(5)
其中pk′是Ck′的映射向量。如果
(6)
其中B表示新文章,最后,可以通过寻找最大相似度的分类,找到新文章所属的分类,如式(7)所示。
(7)
为了有效利用新闻语料的特点,在二类分类的基础上,本文利用新闻的特点,加入新闻关键人物,作为分类的一个权重因子,如式(8)所示。
(8)
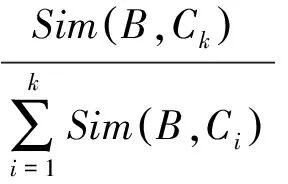
(9)
其中,P(Ci|Bk)为:
(10)
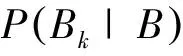
讨论: 不同的经典方法融合关键人物进行分类都具有不同的权重因子α,许多分类法都适用于中文文本分类[20-21],但本文的方法更适合于实施新闻文本分类。在本文实验部分,通过对其他经典算法加入关键人物因子的分类效果略有提高。
5 构建用户模型
为了能准确获知用户所偏好的新闻类别,本文提出了一种新的用户模型构建方法。一般而言,推荐系统中,用户模型都是通过用户历史行为和物品内容来构建的,但对于新闻推荐而言,极少有新闻网站提供新闻浏览服务之前,要求用户注册后才浏览,因此,传统的用户模型构建方法在新闻推荐应用中遭遇了现实困难。对用户模型构建的研究可以参考文献[22]。本文使用用户微博来构建用户偏好模型。原因在于,用户对于感兴趣的话题,一般会在微博有所体现。例如,如果某用户频繁在微博讨论或转发与篮球、NBA、CBA等,那么至少在内容上可以认为该用户可能对体育类感兴趣。另外,大多数人看新闻,兴趣度都集中于关注新闻中的人物,例如,作为姚明的球迷,如果标题或摘要中出现了姚明的字眼,则该新闻对该用户吸引力会更大,因此本文的模型也考虑了关键人物实体因素。最后,地方新闻对该地用户更具有吸引力,本文也将地域考虑到模型中。基于以上的分析,本文提出的用户模型包括的因素有: 微博内容、感兴趣的地域和感兴趣的人物。为了方便推荐时的快速计算,本文将类偏好也放在用户模型的数据结构中,将用户模型表示为一个四位复向量,Upf={τ,ρ,κ,υ},各分量如下:
1)τ表示将用户微博内容向量化后的表示方式,可以表示为{
2)ρ表示用户微博中出现的地名,可以表示为{
3)κ表示用户对关键人物的偏好,可以表示为{
4)υ表示用户对新闻分类的偏好程度,即以上三者综合获得的结果,可以表示为{
讨论:Li[2]也提出了一个类似的用户模型构建方法,即使用历史新闻内容、实体名称和相似用户构建用户模型,其中实体名称使用了开源工具GATE[23]进行抽取和标注。但在互联网新闻语料中,使用GATE进行抽取具有一定的噪声,需要进一步过滤。本文利用现有标注资源,并可以确保地名(省市)稳定,具有较高精度,同时也降低了推荐时的计算复杂度和过拟合的现象,具体参考本文实验部分。然而,前文也讨论过冷启动问题,用户模型的构建同样面临这一问题,同时还需要定期更新用户模型数据库以保证模型的新鲜度。
6 个性化推荐模块
一般而言,个性化新闻推荐即挖掘用户和新闻之间的联系或效用度,并通过联系或效用度权重来对推荐结果列表进行排序。每条新闻都有以下特性: 内容、新鲜度、主题、类别、受欢迎程度、人物、地点等。这些特性有些是动态的,如新鲜性、受欢迎程度,这些都与时间因子相关,有些则是静态的,如分类、主题、人物、地点和内容。本文对新闻物品也构建一个和用户模型类似的模型,即Ipf={τ,ρ,κ}。根据以上分析,可以设计用户u对新闻物品i的效用函数如式(11)、(12)所示。
(11)
(12)
其中,tnow是目前的时间点,ti是新闻的发布时间。为简单起见,本文将这些参数都设置为1。设当前有将被推荐的新闻候选集为ζ{
(13)
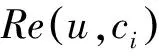
7 实验与分析
本文实验采用南方报业传媒集团历史数据作为分类实验语料,并通过抓取用户最新微博语料作为推荐测试语料。
7.1 语料集
本文选用的语料共有280 737篇新闻,来自于2009年8月至2012年8月的《南方日报》,该语料已按照原国家新闻出版总署制定的新闻出版分类法,分成23个一级分类,并对新闻的题材、关键人物、地点等进行了标注。对于用户模型构建的微博语料,本文使用从新浪微博中抓取的语料,以用户为单位整理好,在实验过程中,剔除字数太少的微博(少于五个字)和微博数太少(少于五条)的用户。以及在新浪网站中爬取的新闻以及评论人员账号,对于评论人员对应的微博账号,本文剔除掉少于十条(信息太少)并多于100条的用户(热用户很可能是广告用户)。共11 150条新闻以425个评论人员的微博账号。
7.2 实验
本文的主要模块有: 分类整理模块、用户模型建立模块和推荐模块,实验的设计主要围绕这些模块展开。
7.2.1 分类实验
在文本分类的研究中,出现了许多经典的中文文本分类算法。本文使用前文中的语料实现以下几种算法:Cheng[20]、ZGuo[21]、朴素贝叶斯(NB)和Rocchio算法。Cheng提出了一种基于概念索引的分类算法,ZGuo使用遗传算法来实现分类处理,而NB和Rocchio是两种经典的分类算法。本实验将语料平均切分为十份,其中九份作为训练集,一份为测试集,使用十次交叉验证方法进行分类实验,并将十次分类的平均结果作为实验结果。在分类实验前,需要确定式(8)中的α参数值,并找到合适的特征选择比例。如图2所示,T-10%表示特征选择选取10%的词作为索引词。从图中可知,α取0.2时会达到最好的分类效果,同时,特征选择比例在20%、30%和40%的差别不大,为降低运算复杂度,本文实验确定特征选择比例为20%。
表1展示了分类实验的结果,从这些结果可以知,本文提出的方法明显优于经典的分类算法和新近的中文分类算法。一个直观的解释是本文使用了较少的文本特征,以及二类分类方法降低了计算复杂程度,同时,使用关键人物作为新闻分类的因子,更适合于中文文本,特别是新闻语料的分类。从表中可以看到,使用一般的中文分类方法,特别是经典方法,分类精度不高, 原因在于, 本文使用的语料是新闻语料,同时按照国标分类法将其分为23个类,有些类具有重叠性,另外新闻文章普遍都存在复分类的情况,即一条新闻同属两个甚至多个分类,工作人员将分类号按照主观经验进行排序,本文实验暂时只以第一个分类号为准。分类实验中,使用intel2.7GHz处理器,2G物理内存,每次实验都在刚开机时进行,受限于进程服务的不稳定性,每次运行的时间都有波动,本文实验剔除掉运行时间最长的实验后(实验一般会受到其他系统程序干扰而延长运行时间,因此只剔除最长时间,而不剔除最短时间),剩余实验取平均值得到运行时间结果。
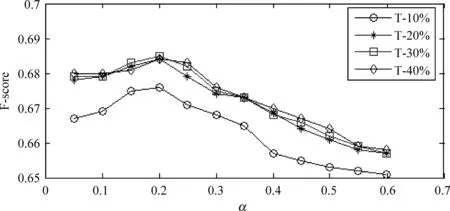
图2 参数与特征选择

表1 分类方法对比
注: F1是指微平均F1测度,T表示运算时间(单位: 分钟),为训练和测试平均时间之和。
7.2.2 用户模型实验
用户模型的好坏在推荐系统中直接影响到推荐效果。本文构建用户模型时使用的素材有: 内容、地点和人物。新近的用户模型构建方式一般只基于内容或通过相似用户或物品对用户模型进行调整。Li[2]使用了内容、实体和访问方式进行推荐模型构建,其实体通过开源工具GATE[23]进行抽取。使用GATE开源工具进行提取具有可行性,但对于新闻语料推荐来说,地点和关键人物是相对稳定的素材,使用算法或软件工具进行实体抽取会带来噪声,同时也增加运算量,同时,使用抽取方式也很难区分地名的从属性。本实验在新浪新闻的评论用户中挑选50个用户作为测试用户。如果用户对测试集新闻进行了评论,则本实验认为该用户已阅读该文。图3展示了本文的推荐方法的准确率,其中T@n表示Top-n推荐,即推荐列表长度为n。

图3 使用不同因子的用户模型在推荐准确度中的对比注: C表示基于内容的用户模型构建,GATE表示使用了该开源工具进行实体提取,P表示地域实体,K表示新闻人物实体。
从图3的结果可以发现,使用本文的方法比仅依赖于内容的方法要好,同时也比使用GATE抽取工具要好。原因可能是微博语料并没有非常多的描述性内容,更倾向于表达人物和地点等实体,同时,利用新闻语料中常见的人物和地点可以较好地构建用户模型。
8 总结与展望
本文提出了一种基于微博语料分析的新闻推荐系统,其中包括有效的新闻分类算法和针对新闻推荐的用户模型构建方法。实验结果表明,本文提出的方法和架构具有较好的运行效果。新闻推荐的另外一个不可忽略的因素就是时新性和关注热度,在接下来的研究中,本系统将会扩展相关功能,包括对新闻子类热点的跟踪, 其中就包括对大类新闻进行切分聚类,并对聚类结果进行热点跟踪和周期预测,并在推荐算法中考虑热点因子和时间衰减因素,使之更适合新闻推荐的科研和应用特点。由于微博是实时更新较快的互联网应用之一,本文提出的系统还需要进一步解决用户模型构建的及时更新、效率性、噪声去除等问题,这也是将来工作的研究重点之一。
[1] A S Das, M Datar, A Garg, et al. Google news personalization: scalable online collaborative filtering[C]//Proceedings of the 16th international conference on World Wide Web, ACM, 2007: 271-280.
[2] L Li, D Wang, T Li, et al. Scene: a scalable two-stage personalized news recommendation system[C]//Proceedings of the ACM Conference on Information Retrieval (SIGIR), 2011.
[3] J Liu, P Dolan, E R Pedersen. Personalized news recommendation based on click behavior[C]//Proceedings of the 15th international conference on Intelligent user interfaces, ACM, 2010:31-40.
[4] J Schafer, J Konstan, J Riedi. Recommender systems in e-commerce[C]//Proceedings of the 1st ACM conference on Electronic commerce, ACM, 1999: 158-166.
[5] D Billsus, M J Pazzani. A personal news agent that talks, learns and explains[C]//Proceedings of the third annual conference on Autonomous Agents, ACM, 1999: 268-275.
[6] M Pazzani, D Billsus. Learning and revising user profiles: The identification of interesting web sites[J]. Machine learning, 1997,27(3):313-331.
[7] D Billsus, M Pazzani. User modeling for adaptive news access[J]. User modeling and user-adapted interaction,2000, 10(2):147-180.
[8] R Cota, A Ferreira, C Nascimento, et al. An unsupervised heuristic-based hierarchical method for name disambiguation in bibliographic citations[J]. Journal of the American Society for Information Science and Technology, 2010, 61(9):1853-1870.
[9] J Breese, D Heckerman, C Kadie. Empirical analysis of predictive algorithms for collaborative filtering[C]//Proceedings of the Fourteenth conference on Uncertainty in artificial intelligence, Morgan Kaufmann Publishers,1998: 43-52.
[10] A S Das, M Datar, A Garg, et al. Google news personalization: scalable online collaborative filtering[C]//Proceedings of the 16th international conference on World Wide Web, 2007: 271-280.
[11] M Balabanovic, Y Shoham. Fab: content-based, collaborative recommendation[C]//Proceedings of the Communications of the ACM, 1997,40(3):66-72.
[12] M Claypool, A Gokhale, T Miranda, et al. Combining content-based and collaborative filters in an online newspaper[C]//Proceedings of ACM SIGIR Workshop on Recommender Systems, 1999.
[13] C Best, E van der Goot, M de Paola, et al. Europe media monitor emm[C]//Proceedings of the JRC Technical, 2002.
[14] E Gabrilovich, S Dumais, E Horvitz. Newsjunkie: providing personalized newsfeeds via analysis of information novelty[C]//Proceedings of the 13thinternational conference on World Wide Web, 2004: 482-490.
[15] G Wang, F H Lochovsky. Feature selection with conditional mutual information maximin in text categorization[C]//Proceedings of the thirteenth ACM international conference on Information and knowledge management, 2004: 342-349.
[16] C Lee, G G Lee. Information gain and divergence-based feature selection for machine learning-based text categorization[J]. Information processing & management, 2006,42(1):155-165.
[17] A Moh′d A MESLEH. Chi square feature extraction based svms Arabic language text categorization system[J]. Journal of Computer Science, 2007,3(6):430-435.
[18] Y-S Lai, C-H Wu. Meaningful term extraction and discriminative term selection in text categorization via unknown-word methodology[C]//Proceedings of the ACM Transactions on Asian Language Information Processing (TALIP),2002: 34-64.
[19] R Rifkin, A Klautau. In defense of one-vs-all classification[J]. The Journal of Machine Learning Research, 2004,5:101-141.
[20] X Cheng, S Tan, L Tang. Using dragpushing to refine concept index for text categorization[J]. Journal of Computer Science and Technology, 2006,21(4):592-596.
[21] Z Guo, L Lu, S Xi, et al. An effective dimension reduction approach to chinese document classification using genetic algorithm[C]//Proceedings of the Advances in Neural Networks ISNN 2009, 2009: 480-489.
[22] S Gauch, M Speretta, A Chandramouli, et al. User profiles for personalized information access[DB/OL]. The adaptive web, 2007: 54.
[23] H Cunningham, D Maynard, K Bontcheva, et al. Gate: an architecture for development of robust hlt applications[C]//Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, 2002: 168-175.
A Personalized News Recommendation Based on Micro-blog User Profile Modeling
GU Wanrong, DONG Shoubin, ZENG Zhizhao, HE Jinchao, LIU Chong
(School of Computer, South China University of Technology, Guangzhou, Guangdong 510641,China)
News recommendation is one of the most popular research issues, which is often realized on the log of users’ behaviors. However, many news sites couldn’t force users to register before browsing news articles. As a mainstream self-media form, the Micro-blog is rich in individual tweets or retweets. In this paper, we propose a novel personalized news recommendation based on micro-blog user profile, which classifying news items and analyzing micro-blog for user profile construction. The experimental results show that our system has better efficiency and practical effect compared with the state-of-the-art algorithms.
news recommendation; text classification; Micro-blog analyze

古万荣(1982—),博士,高级工程师,主要研究领域为大数据处理和分析、信息检索和推荐应用研究。E⁃mail:40840582@qq.com董守斌(1967—),通信作者,博士,教授,博士生导师,主要研究领域为高性能计算、信息检索及海量信息处理等。E⁃mail:sbdong@scut.edu.cn何锦潮(1988—),硕士,工程师,主要研究领域为海量数据处理。E⁃mail:76287324@qq.com
1003-0077(2016)01-0093-08
2013-06-20 定稿日期: 2014-03-09
广东省重大科技专项(2014B010112006);广东省自然科学基金(2015A030308017)
TP391
A
猜你喜欢
通信技术(2021年12期)2022-01-25
数学小灵通(1-2年级)(2021年4期)2021-06-09
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
自动化学报(2017年5期)2017-05-14
电子制作(2017年23期)2017-02-02
智能系统学报(2015年4期)2015-12-27
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
