
一种短正文网页的正文自动化抽取方法
2016-05-03 13:03郗家贞俞晓明程学旗
中文信息学报 2016年1期
郗家贞,郭 岩,黎 强,赵 岭,刘 悦,俞晓明,程学旗
(1. 中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190; 2. 中国科学院大学, 北京 100080)
一种短正文网页的正文自动化抽取方法
郗家贞1,2,郭 岩1,黎 强1,2,赵 岭1,刘 悦1,俞晓明1,程学旗1
(1. 中国科学院 计算技术研究所 中国科学院网络数据科学与技术重点实验室,北京 100190; 2. 中国科学院大学, 北京 100080)
随着互联网的发展,网页形式日趋多变。短正文网页日益增多,传统的网页正文自动化抽取方式对短正文网页抽取效果较差。针对以上问题,该文提出一种单记录(新闻、博客等)、短正文网页的正文自动化抽取方法,在该方法中,首先利用短正文网页分类算法对网页进行分类,然后针对短正文网页,使用基于页面深度以及文本密度的正文抽取算法抽取正文。
短正文;正文抽取
1 引言
1.1 自动化的短正文网页正文抽取
面对层出不穷的信息来源,数量呈指数级增长的网络页面,网页正文抽取技术越来越受到学术界和工业界的重视,Microsoft、Google 、百度、腾迅等公司均在相关方向进行了研究。网页内容抽取技术被广泛应用在互联网服务和应用中,例如,信息检索、文本自动分类、话题跟踪、机器翻译、自动摘要等。从网页中抽取出高质量的正文对于这些应用来说非常关键。例如,对于信息检索,正文抽取的质量会直接影响检索的准确率。在这些应用中,网页正文抽取作为必不可少的一个步骤,为后面的分析、挖掘提供了最基础的数据。因此,近年来网页正文抽取吸引了很多的研究者从事相关研究。
通常研究者关注的网页内容是比较常规的(正文文本量较多,文字较为集中),已有的内容抽取方法的假设基础也都普遍基于常规网页的特点。但随着网络的迅猛发展及其应用的日益丰富,大量的非常规网页涌现出来。多媒体技术的广泛应用使得网页的内容不再拘泥于文本,而是变成了包含文字、图形、图像、动画、声音和视频等各种媒体的信息综合体。大量的娱乐新闻网页中的新闻可能只由一张图片和一句话组成。这就引入了一类新的网页,它们的共同点是正文内容短,本文将此类网页称为“短正文网页”。这类网页通常是新闻网页或博文网页。研究人员在设计正文抽取算法时,通常基于标签密度、文本链接比等特征做假设,而短正文网页的特点明显不符合这些常规意义上的假设,短正文网页的文本量较少,甚至少于版权声明以及网页中其他噪音文本,导致一些常规的正文抽取方法对其无能为力。
目前网页正文抽取的主流技术大致可以归为两大类: 基于模板的抽取以及完全自动化的抽取。基于模板的抽取又可以分为自动生成模板以及人工配置模板两种。自动生成模板的方式需要我们预先对输入网页进行筛选,选择结构相近或者同一模板生成的网页作为输入的训练网页,生成这一类网页的公共模板,用来抽取结构相近的网页中的信息。其优点是当模板质量较高,且待处理页面的结构与训练网页足够相似时,抽取效果较好,且抽取速度快;缺点是生成模板的正确性严重依赖于训练网页之间的相似程度。另外,每一个信息源的网页都需要此类网页对应的、个性化的模板,一旦新网页的结构发生改变,模板就会失效,需要重新生成模板。人工配置模板的抽取准确率高这一优点很明显,但需要大量的人工操作这一缺点也同样突兀,而且也如同自动化生成模板一样,当此类网页结构发生改变时,需要重新配置模板。因此,虽然基于模板的抽取方式可以解决短正文网页的正文抽取问题(人工配置或者通过网页间相似性确定正文),但是该抽取方式需要为不同的网页配置大量的模板,模板的生成、维护成本非常高,而且还要求输入网页必须符合模板要求的相关特征。
在对抽取结果的准确性没有严格要求的情况下,自动化的信息抽取方式便派上用场。随着网页规模的快速增长,正文抽取的研究热点已经转向自动化抽取方法的研究。自动化信息抽取不依赖于模板,仅根据网页自身的相关特征对网页进行抽取。常见的方式有: 基于文本密度(标签密度的倒数)、基于文本链接比例、基于视觉信息以及基于自然语言处理等方式。自动化信息抽取的优点是使用便捷、通用性强等。缺点是抽取效果不是非常准确,尤其是在正文比较短的情况下,通常的算法出错率很高。基于视觉信息的抽取虽然可以在一定程度上解决短正文网页的抽取问题,但是需要对网页进行深度解析以获得相关的视觉信息,因此抽取效率较低,不能满足实际工程对效率的要求。
1.2 研究内容
在实际工程应用中,我们发现常规的正文抽取算法对网页的抽取效果已经比较好,但是当我们深入研究时会发现,抽取错误的网页中正文长度较短的网页占有很大比例,错误率远远超过了文本长度较长的网页的抽取错误率。针对以上问题,我们采用了分而治之的方式来提升网页的正文抽取效果,如图1所示,先对网页进行分类,通过我们的分类算法将网页分为长正文网页和短正文网页;对长正文网页采用传统的抽取方式(本文采用的是基于文本密度的方式)进行处理,对短正文网页采用新的抽取算法进行处理。因此,本文的主要研究内容有两部分: 1)对短正文网页的分类;2)设计短正文网页正文抽取算法SCEDD(Short Content Extraction via Depth of DOM tree)。

图1 一种短正文网页的正文自动化抽取方法流程示意图
1.3 相关工作
正文抽取一词由Rahman 等人在 2001年提出[1]。目前,根据我们的调研,并没有研究人员对短正文网页的正文抽取做专门的研究,一般都是将待抽取的网页看作是通常的网页(正文文本量大、标签少、链接少、行块密度大等),或者对输入网页类型不做限制[2]。
基于包装器的归纳方法(Wrapper Induction)是Web信息抽取中的常用方法。 Hammer 等研究者在 TSIMMIS[3]中首次提出这个方法,文献[4-6]对该方法作了全面而透彻的综述。经典方法例如,基于监督学习的方法 STALKER[7],基于半监督学习的方法 OLERA[8],以及无监督方法 RoadRunner[9]。此类方法可以解决短正文网页抽取问题,但如前面所述,由于网页的异构性,通常对每一个信息源都需要生成至少一个包装器,模板生成、维护成本较高。
自动化抽取方法是当前Web信息抽取领域的研究热点。文献[10]中采用基于标签密度的正文抽取方式,但是当正文较短,甚至与版权声明等噪音信息相当时,由于版权声明等噪音中标签很少,因此容易导致正文抽取错误。文献[11]采用了文本链接比的特征,但对短正文网页的处理效果同样不好,因为版权声明类噪音不包含超链接,因此无法准确判别正文位置。文献[12]中采用视觉信息对网页进行分割,从而可以获取网页正文,但需要计算视觉信息,开销大,无法满足实际应用需求。
一些研究者把自然语言处理、机器学习等技术引入内容抽取中。文献[11]把网页内容的识别问题看成一个标注问题,这是机器学习和自然语言理解领域中的一个经典问题。文献[13]引入决策树进行新闻网页的正文抽取。这样做的优点是能够提高抽取准确率;缺点是多多少少都需要人工参与,且开销较大,不适合在实际应用中处理大规模的网页抽取问题。
目前关于短正文、短文本的研究集中在分类、聚类问题上,而非如何获取短正文、短文本。例如,文献[14]关注的是短文本聚类问题,文献[15]关注了短文本分类问题。
2 短正文网页的定义以及分类
2.1 基本思路
我们首先要解决的关键问题是短正文网页的分类问题。
何为短正文网页,目前尚未有一个严格的定义,直观意义上来讲,就是正文比较短、在自动化抽取中容易与噪音信息混合,导致抽取结果错误的网页。以下是两种定义方式: (1)根据网页正确的正文信息长短来定义,这需要我们事先对网页进行标注,从而根据正文长短对网页进行分类;(2)结合网页特征并基于经验假设,设计一种分类算法,简单来说,就是一个粗略的正文抽取算法,根据抽取结果的长度对网页进行分类。第一种定义方式明显更符合我们的常识,但是在工程应用中,我们并不能预先得知网页正文的准确长度(如果知道了,那就是标注过的样本网页,也就是说正文已经正确抽取,也就不需要我们对其进行处理了),因此,我们采用第二种定义方式,对网页进行特征提取之后,对其分类。
经过分析,可以发现网页的原始大小、网页内部全部标签的数量都与分类关系不大,因为同一个模板生成的网页,我们假设为A和B,A是长正文网页,B为短正文网页,A与B仅在正文以及标题、作者等方面具有明显差异, 而其他方面(网页的大小、标签数量)基本一致,而很明显他们属于不同类别。假设我们定义文本长度小于阈值thres的网页属于短正文网页,而文本密度最大的标签所对应的文本长度与网页是否是短正文息息相关: 如果此文本正是网页的正文,那么当它的长度L小于阈值thres,则恰好满足我们对短正文的定义;如果该文本不是网页的正文,而是网页的噪音信息,那么一般来说网页正文长度Content_L<文本长度L<阈值thres,也同样满足短正文的定义。基于以上分析,我们提出了短正文网页分类算法。
2.2 短正文网页分类算法
我们设计此分类算法的目的是为了将使用传统的自动化正文抽取算法处理的网页中效果较差的短文本网页与其他网页区分开来,对分类得到的短正文网页进行单独处理,以提高整体的抽取效果。
图2是我们提出的短正文网页分类算法流程图。该算法的输入是待分类网页源码,输出是正在处理的网页的类型: 短正文网页或长正文网页。
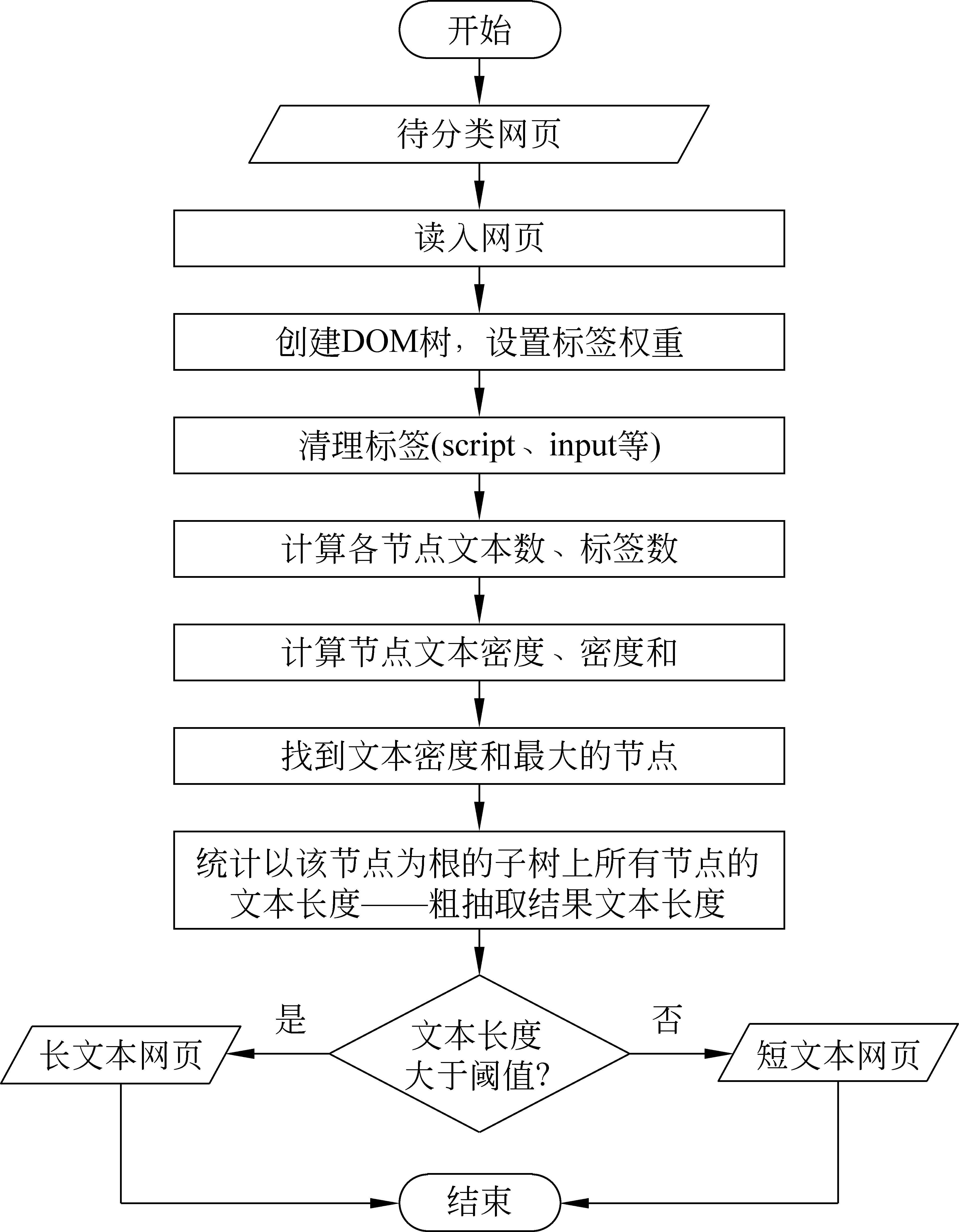
图2 短正文网页分类算法流程图
在短正文网页分类算法中,需要设定粗抽取文本长度阈值。如图2所示,粗抽取结果中文本长度大于该阈值的网页定义为长正文网页,否则为短正文网页。为了找到合理的阈值, 准确地定义短正文网页,我们做了统计实验,实验细节参见第四节。通过统计分析,我们定义粗抽取结果中,文本长度小于450字节的网页为短正文网页。
时间复杂度为O(n*k),n为输入网页的数目,k为网页中标签的数目。
3 短正文网页的正文自动抽取
3.1 基本思路
通过上述分类算法区分出短正文网页后,需要解决的关键问题就是如何从网页中自动抽取出正文。
对短正文网页进行分析后,发现短正文有以下几个特点:
1) 由于文本较短,正文节点经常位于一个单一的、文本密度较高的标签之下,也就是说它的兄弟节点虽然可能文本密度很高,导致他们的父节点的文本密度和很高,但是我们只取文本密度最大的节点,而不是文本密度和最大的节点;
2) 短正文抽取错误的结果中相当一部分是因为抽取到的是网页末尾的版权声明模块;
3) 短正文抽取中,当标记的正文节点过于靠前时,一般是出现了将正文定位到了正文之前的噪音上面的情况。
针对以上观察到的三种情况,我们提出如下应对措施:
1) 对于短正文网页,我们采取寻找最大文本密度的节点来代替寻找最大文本密度和的方式来作为正文的统领节点(也就是说以该节点为根的子树上面的文本即为正文);
2) 我们对每个标签大致在网页中出现的高度值进行统计,将非常靠后的疑似正文节点舍弃,下一次遍历的时候只遍历此节点之前的所有节点。然后继续从DOM树根节点进行遍历,直到找到位置合法(偏网页中上位置)且拥有最大文本密度的节点作为正文节点;
3) 与第2)步相反,是将最前面的节点(超出合法位置的疑似正文节点)删除,在其后寻找位置合法(偏网页中上位置)且拥有最大文本密度的节点作为正文节点。
基于以上思路,我们提出了短正文网页抽取算法SCEDD。
3.2 SCEDD算法
SCEDD算法的流程如下:
输入: 待抽取的短正文网页
输出: 抽取结果文件。
操作步骤:
1) 读入文件,建立DOM树,并为每个节点设置密度的权值(链接等标签权值较小);
2) 清理form标签(input、noembed、noscript等等);
3) 遍历DOM树。根据块级标签的个数求出各标签大致所在的行数;
4) 抽取标题。清除标题之前的全部内容,然后清理副标题;
5) 计算文本数,计算标签数,计算各个节点的标签密度;
6) 设记录当前文本密度最大节点的变量为A,记录当前文本密度最大节点行数的变量为line,网页一共有line_sum行,top_coef代表正文节点所能出现的最上方的位置所对应的系数(也就是说当正文节点所在的行数小于line_sum*top_coef,则认为抽取位置不对,需要继续往下查找拥有最大文本密度的节点),bottom_coef代表正文节点所能出现的最下方的位置所对应的系数。最多重复查找五次便停止,以防止空页面导致算法进入死循环。细节如图3所示。

图3 SCEDD算法中基于DOM树深度的正文节点定位代码示例
7) 取上一步中最终得到的变量A作为正文的统领节点,并对其进行回溯,一直回溯到祖先节点(html标签),将回溯过程中遇到的所有祖先节点中文本密度的最小值作为阈值;
8) 标记正文节点,获取相应节点上面的文本,组成正文。
3.3 SCEDD算法时间复杂度
由于只需要对网页的标签节点进行常数次的遍历,所以,时间复杂度为O(n*k),n代表待抽取网页的个数,k代表单个网页内部的标签数目。
4 实验与分析
4.1 实验数据集
我们构建了两个实验数据集:
(1) 数据集1中有2 823个新闻类网页,这些网页的来源覆盖各种类型的新闻网站;
(2) 根据我们提出的短正文网页分类算法,区别出144个短正文网页,这些网页构成数据集2。
4.2 短正文网页分类算法的阈值设定
在短正文网页分类算法中,需要设定粗抽取文本长度阈值。我们使用数据集1中的2 823个新闻类网页作为统计语料。首先按照第2.2节的分类算法,获取各个网页对应的粗抽取结果。然后,按照粗抽取结果的文本长度分区间进行统计,统计结果如表1所示。我们做了两种统计:
(1) 计算相应区间的页面总数、抽取错误页面数、抽取错误率(表1中“错误率1”所示);
(2) 累加各区间的总页面数、抽取错误页面数,计算抽取错误率(表1中“错误率2”所示)。
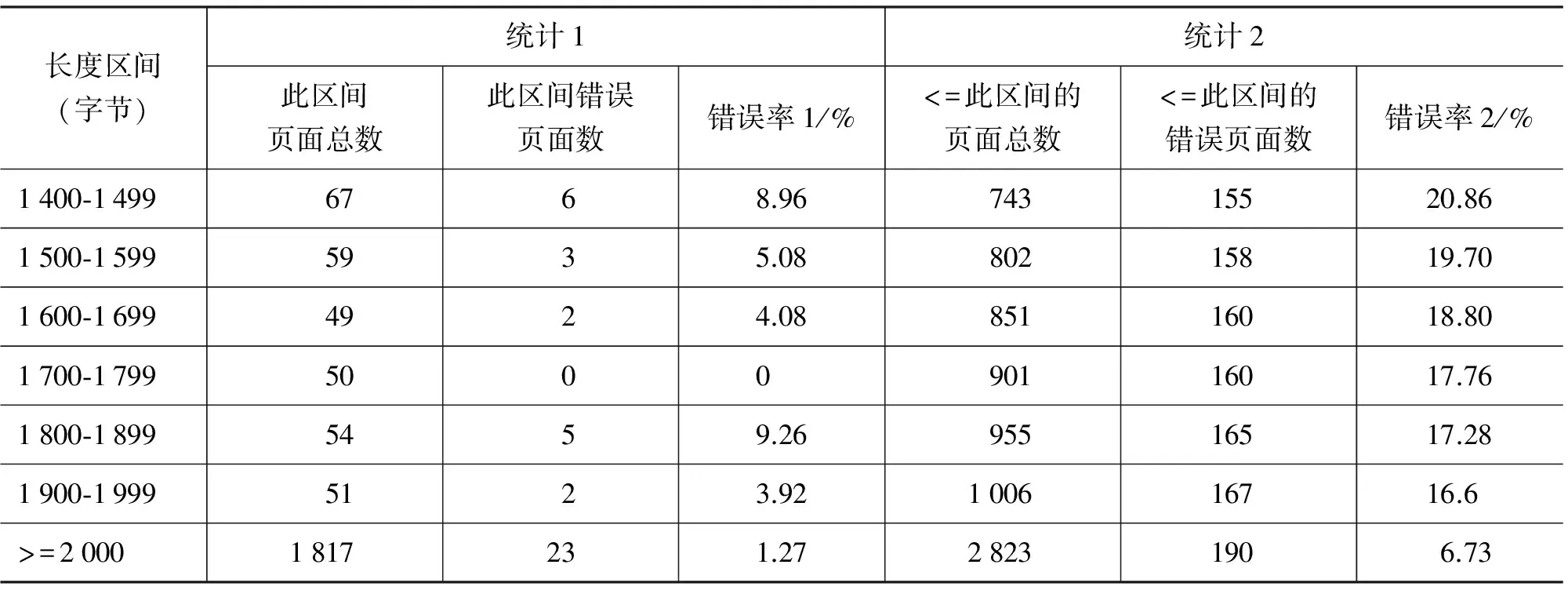
续表
根据表1列出的结果,我们发现当文本长度小于450字节时,总体的抽取错误率为72/144,即50%,抽取错误率较高,而且错误页面数(即72)占所有抽取页面错误数(190)的比例(即召回比,72/190=37.89%)也比较高,因此,我们定义经分类算法处理之后,得到的结果中文本长度小于450字节的网页为短正文网页。
4.3 短正文网页的正文抽取算法
在短正文网页抽取算法实验中,我们使用数据集2,即144个短正文网页。
4.3.1 参数选择
短正文网页抽取算法中需要设定两个参数bottom_coef和top_coef。
图4和图5代表的是bottom_coef和top_coef两个参数的值所对应的抽取错误页面数。由于两个参数所对应的处理流程中不存在相交的情况出现,所以,我们对参数分别进行训练。

图4 参数bottom_coef对应的抽取错误页面数
根据图4,我们选择bottom_coef = 0.95,因为自0.95之后错误页面数开始稳步上升。
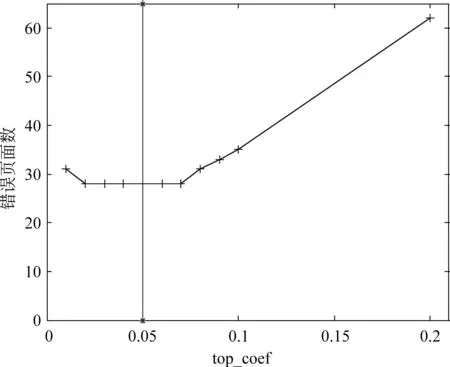
图5 参数top_coef对应的抽取错误页面数
根据图5,我们选择top_coef = 0.05,因为此时的抽取错误页面数最少而且位于稳定区间的中位数附近。
4.3.2 正文抽取实验
我们选择了三个抽取算法与本文提出的SCEDD算法做比较: CETD,Constor,ConstorV2.0。CETD是文献[2]中提及的算法,采用文本链接比与标签密度相结合的方式进行正文抽取;Constor是本实验室在工程项目中使用的正文抽取算法,该算法是对文献[16]中CoreEx算法的改进版,在实际应用中表现出色;ConstorV2.0是本实验室针对CETD算法做的改进版抽取算法,整体抽取效果出色。由于基于文本链接比或标签密度的方式在正文抽取中表现出色,因此,作者选择了以上三种抽取算法来与本文提及的短正文抽取算法进行对比。
我们使用以下指标评价四种算法的抽取效果:
其中,P是抽取错误率,Precise_length为抽取结果与标注结果(人工标注的结果,认为是准确的正文)的最长公共子序列长度,Result_length为抽取结果长度。
由于短正文网页的抽取结果容易受到一些疑似噪音信息(主要是指正文开头、结尾的来源、作者信息,严格意义上并不属于噪音信息)的影响,因此,我们将错误率的阈值提高到20%,即错误率大于20%的抽取结果,我们认定为是错误的。

图6 错误页面的DOM树结构示意图
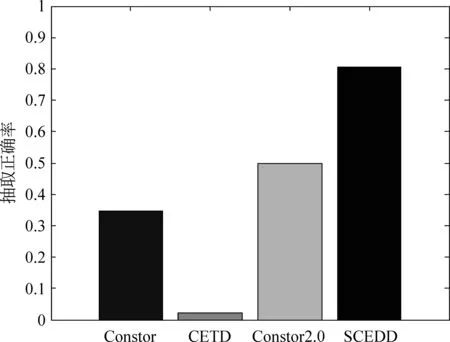
图7 不同算法对应的短正文网页正文抽取正确率
图7为四种算法对短正文网页的抽取结果。可以看出,相比较而言,SCEDD算法表现出色。这是因为其他三个算法所基于的假设条件(正文文本长度大,含标签少,含链接少)不能很好地适用于短正文网页,SCEDD中加入了节点在DOM树中的深度作为考量,有效地去除了网页开头、结尾处的噪音信息,因此表现良好。另外,可以看到,仍有近20%的短正文网页的正文抽取效果不好,这是因为有一些网页的噪音信息同样位于合法位置(总行数的5%到95%之间)而且文本密度要大于正文的文本密度,导致正文定位出错。例如,图6所示网页,“网友发言…”与正文都位于合法位置(总行数的5%到95%之间),但是噪音信息(“网友发言…”)的文本密度大于正文所在节点的文本密度,导致抽取结果出错(将“网友发言…”误当作正文抽取出来)。
5 总结
本文针对目前日益增多的短正文网页设计了一种正文抽取方法,通过分类算法先对输入网页进行分类,然后根据分类结果对短正文网页使用基于DOM树深度以及文本密度的正文抽取算法进行抽取。实验结果表明,本文设计的正文抽取算法在处理短正文网页时,与常规的自动化正文抽取算法相比有明显优势。
未来,我们考虑将DOM树中疑似正文节点与网页中的一些标志性节点(title body等)之间的相对位置作为考量的一部分加入到短正文网页的正文抽取算法中,并考虑将节点深度与节点的文本密度做加权,以获取更好的正文抽取效果。
[1] A F R Rahman, H Alam, R Hartono. Content Extraction from HTML Documents[C]//Proceedings of 1st International Workshop on Web Document Analysis (WDA2001), 2001.
[2] F Sun, D Song, L Liao. Dom based content extraction via text density[C]//Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information, ACM, 2011:245-254.
[3] Hammer J, McHugh J. Semi-structured Data: The TSIMMIS Experience[C]//Proceedings of the First East-European Symposium on Advance in Databases And Information Systems,1997:1-8.
[4] Line Eikvil. Information extraction from world wide web-a survey [M].Norway: Norweigan Computing Center,1999:8-9.
[5] Alberto H F Laender, et al. A brief survey of web data extraction tools[A]. ACM Sigmod Record, New York, NY, USA. ACM,2002,31:84-93.
[6] Chia-Hui Chang, et al. A survey of web information extraction systems[J]. Knowledge and Data Engineering, IEEE Transactions on, 2006, 18(10):1411-1428.
[7] Ion Muslea, et al. A hierarchical approach to wrapper induction[C]//Proceedings of AGENTS ’99, New York, NY, USA. ACM, 1999: 190-197.
[8] Chia-Hui Chang, Shih-Chien Kuo. Olera: semisupervised web-data extraction with visual support[J]. Intelligent Systems, IEEE, 2004,19(6):56-64.
[9] Valter Crescenzi, et al. Roadrunner: Towards automatic data extraction from large web sites[C]//Proceedings of VLDB ’01, San Francisco, CA, USA. Morgan Kaufmann Publishers Inc.2001: 109-118.
[10] T Weninger, W H Hsu, J Han. CETR-content extraction via tag ratios[C]//Proceedings of WWW ’10, New York, NY, USA, 2010:971-980.
[11] Gibson John, Wellner Ben, Lubar Susan. Adaptive web-page content identification[C]//Proceedings of the 9th annual ACM international workshop on Web information and data management, ACM New York, NY, USA.2007: 105-112.
[12] D Cai, S Yu, J Wen, et al. Extracting content structure for web pages based on visual representation[C]//Proceedings of APWeb’03, 2003: 406-417.
[13] 黄文蓓, 杨静, 顾君忠. 基于分块的网页正文信息提取算法研究[J]. 计算机应用, 2007,27(51):24-26.
[14] 彭泽映,俞晓明,许洪波,等.大规模短文本的不完全聚类[J].中文信息学报, 2011,25(1):54-59.
[15] 宁亚辉, 樊兴华, 吴渝. 基于领域词语本体的短文本分类[J].计算机科学, 2009, 36(3): 142-145.
A Content Extraction Method for Short Web Pages
XI Jiazhen1,2,GUO Yan1,LI Qiang1,2,ZHAO Ling1,LIU Yue1,YU Xiaoming1,CHENG Xueqi1
(1. CAS Key Laboratory of Network Data Science & Technology, Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190,China; 2. University of Chinese Academy of Sciences, Beijing 100080,China)
To deal with the ever-growing short content web pages, this paper puts forward to first classify the web pages into two types: short content pages and long content pages. Then, an algorithm for content extraction from short content web pages is designed by combining DOM tree depth and text density.
short content; content extraction

郗家贞(1990—),硕士,主要研究领域为信息抓取、抽取,新闻去重、垃圾新闻识别、质量识别等预处理工作。E⁃mail:jiayu1990@gmail.com郭岩(1974—),博士,主要研究领域为网络信息处理。E⁃mail:guoy@ict.ac.cn黎强(1989—),硕士,主要研究领域为网页信息抽取、众包、机器学习。E⁃mail:liqiang@software.ict.ac.cn
1003-0077(2016)01-0008-08
2013-08-10 定稿日期: 2014-04-10
国家重点基础研究发展计划(973)(2014CB340401,2013CB329602);国家自然科学基金重点项目(61232010);国家科技支撑专项(2012BAH39B04)
TP391
A
猜你喜欢
保健医苑(2022年1期)2022-08-30
科学养鱼(2021年6期)2021-11-30
动漫界·幼教365(中班)(2021年4期)2021-05-23
成都信息工程大学学报(2021年6期)2021-02-12
电脑爱好者(2020年17期)2020-09-14
电子制作(2018年10期)2018-08-04
魅力中国(2018年5期)2018-07-30
电子制作(2017年2期)2017-05-17
爆笑show(2015年5期)2015-07-09
中国应用生理学杂志(2013年1期)2013-03-30
