
人身保险公司反欺诈风险预警模型研究
2016-04-13 05:51:20拯中国人寿保险股份有限公司刘中国人寿保险股份有限公司广西省分公司
上海保险 2016年1期
杨 拯中国人寿保险股份有限公司刘 云 中国人寿保险股份有限公司广西省分公司
人身保险公司反欺诈风险预警模型研究
杨拯中国人寿保险股份有限公司
刘云中国人寿保险股份有限公司广西省分公司
一、引言
保险欺诈是保险业自诞生以来从未彻底治愈的一个顽疾,严重威胁了保险公司的健康发展。据国际保险监督官协会的测算,全球每年约有20%~30%的保险赔款涉嫌保险欺诈。美国反保险欺诈联盟公布的资料显示,1969年到1998年期间,美国有44家保险公司因为保险欺诈而破产,占同期保险公司破产总数的7%;仅1996年这一年,保险欺诈就给美国保险行业带来853亿美元的损失(国际保险监督官协会,《预防、发现和纠正保险欺诈指引》,2006年)。
近年来,随着我国保险事业的发展,保险领域的违法犯罪案件也呈上升态势,严重扰乱了保险市场秩序,侵害了诚实投保人的合法权益,威胁着保险行业的健康发展,识别与防范欺诈风险成为保险业日益关注的一个重要问题。2012年,中国保险监督管理委员会印发了《关于加强反保险欺诈工作的指导意见》,明确了保险业今后一段时期反欺诈工作的指导思想、基本原则和目标任务,并规划了行业反欺诈工作的具体内容,有力地推动了行业反欺诈工作的进步,国内保险公司联手打击保险欺诈的声势越来越大,范围也越来越广。
然而,囿于当前我国社会信用体系建设尚不完备、保险欺诈识别与防控行业技术标准缺失以及人身保险行业数据共享程度低等原因,目前我国尚未完全形成“政府主导、执法联动、公司为主、行业协作”四位一体的反保险欺诈工作体系,人身保险欺诈风险的防范与控制很大程度上需要各保险公司立足自身管理来研究相应的对策。本文结合人身保险公司反保险欺诈工作的实践经验,通过对欺诈案件风险特征的分析,研究人身保险切实可行的欺诈防范方法和反欺诈策略,并对构建人寿保险欺诈风险预警数据模型进行了初步探索。
二、人身保险欺诈风险特征浅析
截至目前,我国保险行业尚无全行业详细的保险欺诈数据统计,笔者将以国内某大型人身保险公司的保险欺诈数据为标的,对人身保险欺诈的特征进行分析。
(一)人身保险欺诈行为分布特征
我国保险业尚无官方制定的保险欺诈行为识别与定性标准,《刑法》第一百九十八条列举了保险诈骗罪的五种情形,但细化程度略有不足,且第1种和第4种情形仅适用于财产保险。为更好地研究人身保险欺诈的特征和规律,笔者根据业界长期以来积累的反欺诈工作实践数据,进一步细化了人身保险欺诈行为的分类。机构、团体或个人存在以下情形的,可以视为具有人身保险欺诈嫌疑:
1.故意编造未曾发生的保险事故。如未发生保险事故谎称发生保险事故,并以虚假证明材料进行佐证。
2.出险后再投保。但部分团体保险业务中符合“追溯生效日规则”的除外。
3.伪造、变造证明材料和其他证据,或者指使、唆使、收买他人提供虚假证明资料骗取保险金。如伪造变造身份证明材料、医疗证明材料、死亡证明材料,开具虚假发票等。
4.编造虚假的事故原因。如出险原因本为疾病而谎称意外,自然死亡伪称意外事故死亡,非约定意外事故谎称约定意外(从事危险活动造成意外谎称一般性意外)等。
5.故意制造保险事故。如投保人故意造成被保险人死亡、伤残或者疾病,被保险人自残等,但被保险人投保2年内自杀是否认定为欺诈应视具体情况确定。
6.故意不履行如实告知义务。如被保险人带病投保、重大风险事项故意不如实告知等。
7.夸大损失程度。如虚报伤残等级、虚增医疗费金额、挂床套取医疗津贴等。
8.冒名顶替。如冒用他人身份证明,篡改、套用他人医疗证明材料等。
9.其他违反法律、法规和契约精神的保险欺诈行为。
根据以上标准定性保险欺诈,我国某大型人身保险公司2014年度共查获涉嫌保险欺诈的案件7536件,总计涉案金额约为3.21亿元,各类保险欺诈行为分布情况如图1所示。
从上述统计数据可以看出,故意不履行如实告知义务、出险后投保、编造虚假的事故原因和冒名顶替,是该保险公司2014年度查获的保险欺诈案件中欺诈行为占比最多的四种类型,合计占比达85.9%,这提示了人身保险公司反欺诈的关注重点和工作方向,应重点就这四类保险欺诈行为特征进行定向和定量的分析。
(二)人身保险欺诈的险种分布特征
2014年度,该人身保险公司查获的保险欺诈案件的险种分布情况(险种分类依照中国保监会统计信息系统产品四级分类规则,结合人身保险业务实践特点进行划分)如图2所示。
从人身保险欺诈案件的险种分布情况来看,短期健康险、重大疾病保险和意外险是欺诈风险的多发区,这三类险种涉案数量合计占比达全部欺诈案件总量的86.16%,反映出射幸性强的险种更容易发生保险欺诈。
(三)人身保险欺诈的案件金额分布特征
从该公司人身保险各类险种欺诈案件的涉案金额分布来看,与案件险种分布情况呈高度趋同的特点,重大疾病保险、意外险、短期健康险三类险种涉案金额较大,占全部欺诈案件涉案金额总和的85.74%,具体分布情况如图3所示。
进一步分析可以发现,2014年该人身公司全部欺诈案件的总体件均涉案金额为4.24万元,该数字较2013年增长5.74%,近年来呈逐步增长态势。从各类险种的件均涉案金额来看,重大疾病保险、年金保险、定期寿险和两全保险等人寿保险的件均涉案金额相对较高,皆高于总体件均涉案金额;而意外险件均涉案金额略低于总体件均涉案金额,短期健康险则最低,件均涉案金额仅1.3万元。这些数据说明,人寿保险欺诈案件呈多发且案值高的特点,而短期健康险欺诈则呈多发但案值较低的特征。
从上述分析我们可以看出,信息不对称带来的博弈地位巨大差异和保险本身的强射幸性是保险欺诈难以禁绝的重要原因,保险欺诈的行为分布特征和险种分布特征都佐证了这一点。由于射幸性是保险的天然属性,因此,尽可能地消除保险公司与投保人、被保险人之间的信息不对称便成为了防范与控制保险欺诈的主要途径。
由于我国公民信息管理较为碎片化,社会信用体系建设也相对滞后,保险公司为消除这种信息不对称需要付出较大的努力。一般来说,通过商业调查的方式来消除信息不对称虽然效果较好,但投入大、耗时长、成本高,不宜作为一种普遍方式应用于每一单业务,故而保险公司需要探索一条高效低廉的方式进行全业务风险扫描,筛选出高风险业务加以重点防控。因此,构建保险欺诈风险预警模型是保险公司必要并且现实的一个选择。
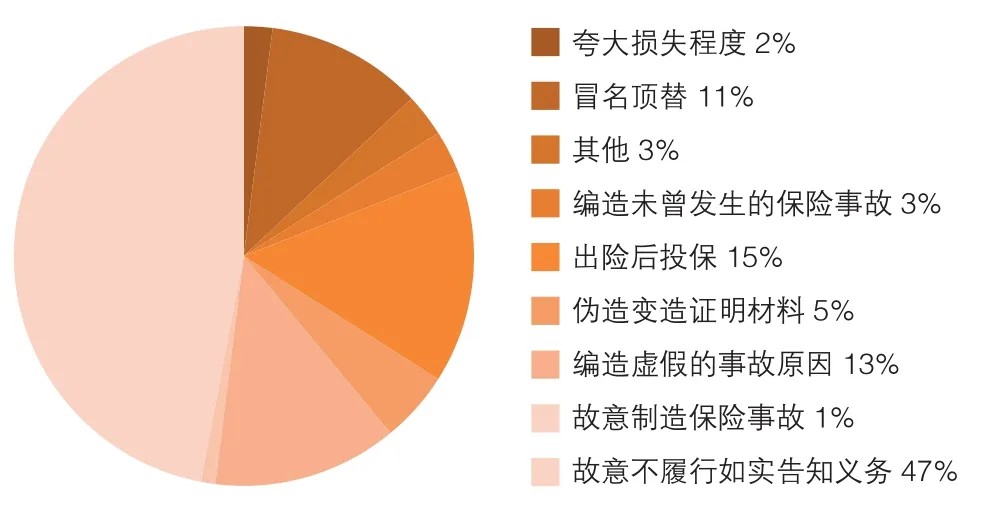
图1 某大型人身保险公司2014年查获之人身保险欺诈行为分布情况
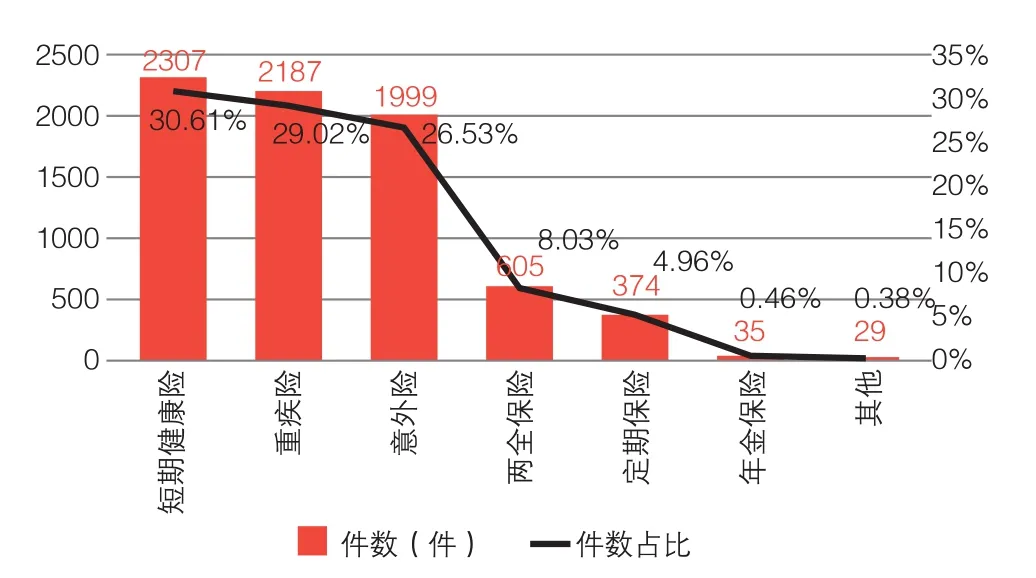
图2 保险欺诈案件险种分布情况
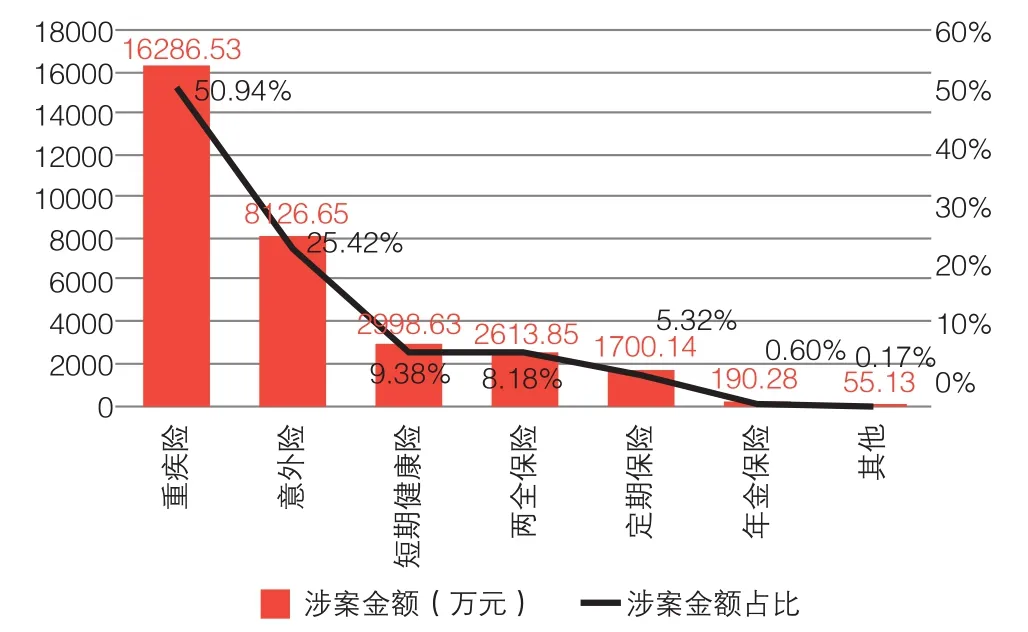
图3 保险欺诈案件各类险种涉案金额分布情况
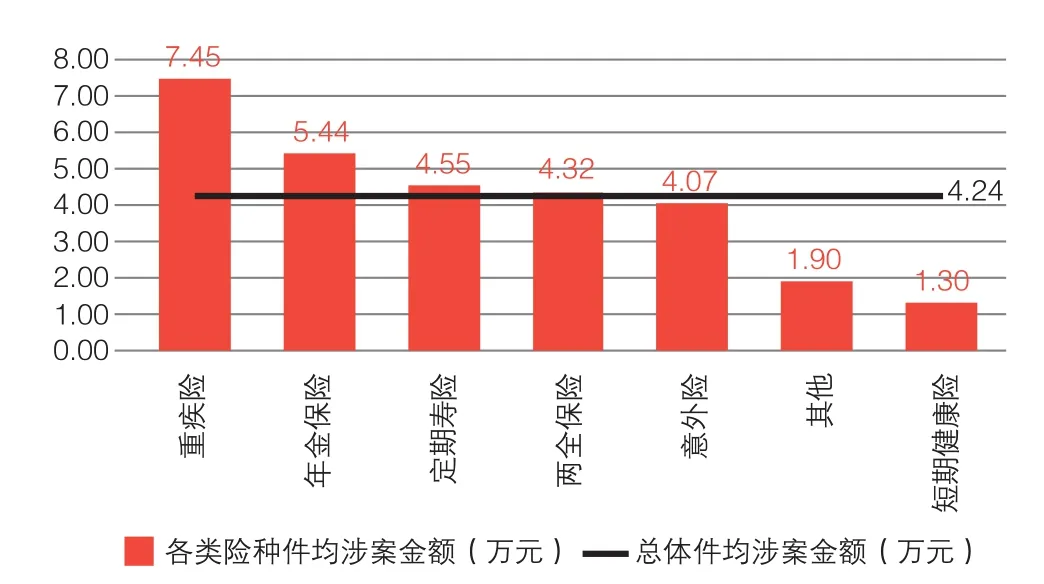
图4 保险欺诈案件中各类险种件均涉案金额分布情况
三、人寿保险欺诈风险预警模型构建
(一)因子分析法在保险欺诈风险预警上的应用
人寿保险是《保险法》赋予人身保险公司特许经营的业务,而短期健康险和意外险人身保险公司与财产保险公司均可经营,但从运营和风险管理的内在规律看,人寿保险与健康保险、意外伤害保险具有较大的差异。为使构建的欺诈风险预警模型更加科学和准确,应将人寿保险与健康保险、意外伤害保险区别开来分别建模。同时,前文的分析显示,人寿保险的欺诈呈案件多发且件均案值高的特点,是现阶段我国人身保险公司反欺诈工作的主要矛盾。因此,为强化模型的指向性和应用性,本文以人寿保险作为研究对象,尝试基于因子分析构建人寿保险欺诈风险预警模型。
大量的经验数据显示,各类人寿保险欺诈风险虽然在表现形式、欺诈手段上有所不同,但本质规律是趋同的,并且欺诈行为的发生与保险业务各项要素之间呈现出较强的相关性。因此,通过对各类型欺诈案件进行要素分解和风险细分,找到理赔案件信息中隐藏的风险因子对其分类量化,并将欺诈风险因子研究成果应用于风险预警,可以更快速准确地定位高风险案件并加以重点调查取证,从而提升保险公司风控资源的使用效率和效果。
(二)基于因子分析的欺诈风险模型构建
农村土地确权可以让广大农民的权益得到有效保障,这是因为农民本身是农村土地的使用者以及支配者,在农村土地的权属得到明确的基础上,农民的维权需求也在提升。农村土地确权的完成让农民以往在土地使用上的弱势地位得到改善,并能使农民群众在对土地进行使用时结合自身的情况,实现对土地的合理分配。现阶段在土地征收的实际工作中,政府对农村土地确权是大力支持的,农民可以结合农村土地确权维护自身的权益,避免在土地被征后由于没有足够的生活技能无法维持生计。
1.建模可行性
因子分析是从研究变量内部相关的依赖关系出发,把一些具有错综复杂关系的变量归结为少数几个综合因子的一种多变量统计分析方法。它的基本思想是通过对变量的相关系数矩阵或协方差矩阵内部结构的研究,找出能控制所有变量的少数几个随机变量去描述多个变量之间的相关关系,然后化繁为简,通过数据的回归建模用直观简洁的数学公式对复杂的问题进行分析和解释。因子分析的主要步骤包括:①对数据样本进行标准化处理;②计算样本的相关矩阵R;③求相关矩阵R的特征根和特征向量;④根据系统要求的累积贡献率确定公因子的个数;⑤计算因子载荷矩阵;⑥确定因子模型。本文选取某人身保险公司G省辖区2012年至2014年全部人寿保险理赔案件数据为样本,将拒绝赔付和协议给付案件作为高欺诈嫌疑风险案件,对其数据分布的偏态与峰度进行分析。利用偏态函数SKEW计算出拒绝赔付和协议给付数据偏态系统SK= 4.55,认为该数据为高度右偏分布,利用函数KURT计算峰度系数K=18.75,数据呈现尖峰分布特征,数据分布集中,表明开展分析建模研究可行。
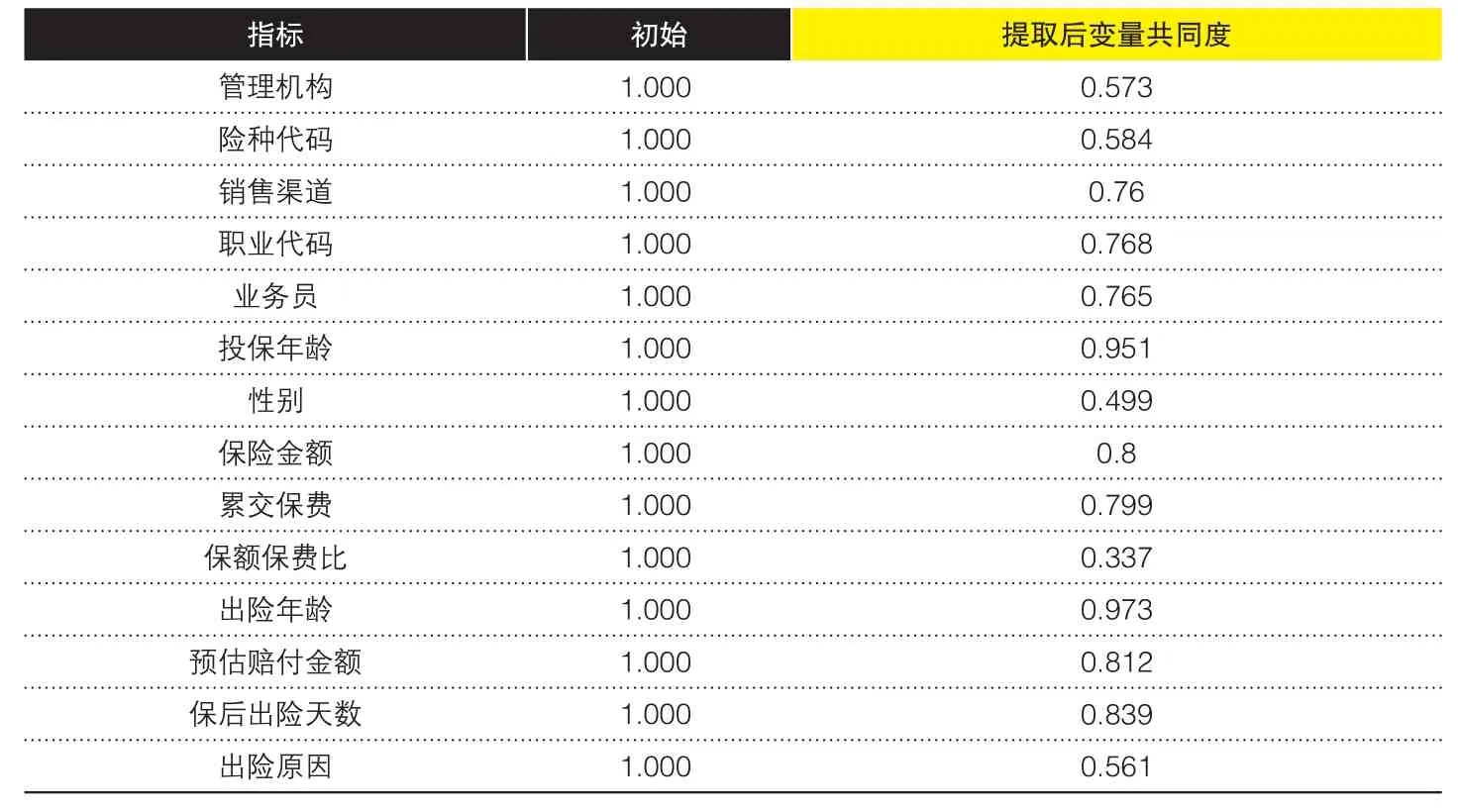
表1 提取公因子后原始指标的变量共同度
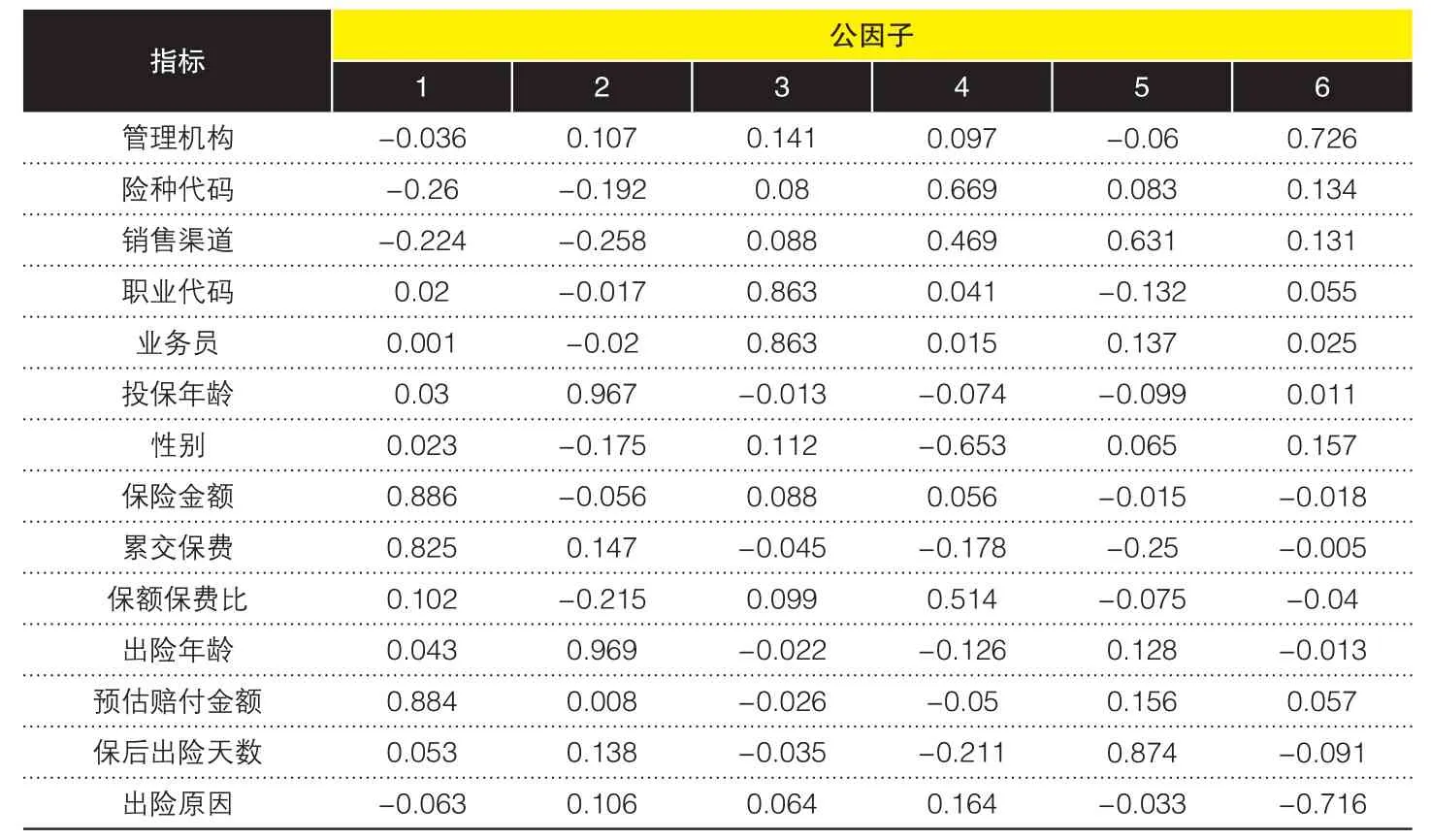
表2 因子旋转后公因子对14个原始变量的载荷矩阵
2.指标因子选择
该人身保险公司G省全辖2012年至2014年的全部人寿保险理赔案件共26024件,其中,拒绝赔付和协议给付案件1098件。本文从客户层、保单层、销售层和行为层四个特征角度,从理赔案件信息中共选取了14个指标作为原始自变量进行风险因子分析,分别为:
客户层:投保年龄、职业代码、性别、出险年龄。此特征角度均指被保险人。
保单层:险种代码、累交保费、保险金额、保额保费比。
销售层:管理机构、销售渠道、业务员。
行为层:保后出险天数、预估赔付金额、出险原因。
因“管理机构、险种代码、销售渠道、业务员、职业代码、性别、出险原因”等7项指标为非数值型数据,为便于比较分析,用类比法对原始数据进行标准化处理,规则如下:
用类似的方法对管理机构、销售渠道、业务员、职业代码、出险原因进行标准化处理,得到:
管理机构标准化值=(该机构理赔案件总量/全辖理赔案件总量+该机构拒绝赔付和协议给付案件数量/该机构理赔案件总量)/2
销售渠道标准化值=(该销售渠道理赔案件总量/所有销售渠道理赔案件总量+该销售渠道拒绝赔付和协议给付案件数量/该销售渠道理赔案件总量)/2
业务员标准化值=(该业务员理赔案件总量/所有业务员理赔案件总量+该业务员拒绝赔付和协议给付案件数量/该业务员理赔案件总量)/2
职业代码标准化值=(该职业代码被保险人理赔案件总量/理赔案件总量+该职业代码被保险人拒绝赔付和协议给付案件数量/该职业代码被保险人理赔案件总量)/2
出险原因标准化值=(该类出险原因的理赔案件总量/理赔案件总量+该类出险原因拒绝赔付和协议给付案件数量/该类出险原因理赔案件总量)/2
对“性别”指标的标准化处理方式略有差异,规则如下:性别指标原始数据为保单被保险人性别。数据显示,样本期(三年)内26024件理赔案件中,被保险人为男性的案件有13357件,占比51.33%;样本期(三年)内1098件拒绝给付和协议给付案件中,被保险人为男性的有676件,占比61.57%。因此,视男性被保险人为相对高风险类别,对指标赋值为1;视女性被保险人为相对低风险类别,对指标赋值为0。
3.原始数据整理和风险因子提炼
(1)检验待分析的原始变量是否适合做因子分析。运用SPSS软件对26024个案件的14个指标共364336个数据进行分析,通过相关系数矩阵和Bartlett球体检验判断数据是否适合作因子分析。运行结果显示,相关系数矩阵中存在许多比较高的相关系数,且相关系数显著性检验的P值中存在大量的小于0.05的值,说明原始变量之间存在较强的相关性,具有进行因子分析的必要性。然后同步进行Bartlett球形度检验,检验结果P值为0,进一步说明数据比较适合进行因子分析。
(2)提取公因子。用SPSS软件的主成分分析法进行因子筛选,提取了6个公因子;验证提取公因子后原始指标的变量共同度都较高,说明损失的信息较少(如表1所示)。
进一步验证提取公因子的特征值和累计方差贡献率,SPSS软件的运行结果显示,提取的6个公因子特征值都大于1,累计方差贡献率达到71.575%,表明提取6个公因子进行分析建模比较合适。同时再结合碎石图观察,因子特征值到第7个公因子时变化相对趋于平稳,进一步确定提取6个公因子加以分析是合适的。
(3)因子载荷分析。测量提取的公因子对14个原始变量的影响程度,形成因子载荷矩阵。通过观察,提取的6个公因子在各指标变量上的载荷差不大,无法明确解释各公因子的含义进而命名,因此须进行因子旋转后进一步观察。进行因子旋转后的载荷矩阵见表2。
从旋转后的因子载荷矩阵可以看出:第一个因子与保险金额、累交保费及预估金额具有较强的相关性,可以归为一类,命名为额度因子L;第二个因子与投保年龄和出险年龄有较强的相关性,命名为年龄因子A;第三个因子与被保险人职业代码和业务员有较强的相关性,命名为职业因子O;第四个因子与险种和被保险人性别有关,命名为险种因子I;第五个因子与销售渠道和保后出险天数有较强的相关性,命名为时间因子T;第六个因子与管理机构和出险原因有较强的相关性,命名为管理因子M。
4.风险预警模型构建
(1)计算因子得分。将管理机构等14个原始变量分别命名为变量运用回归法测算公因子对各原始变量的影响系数,结果见表3:
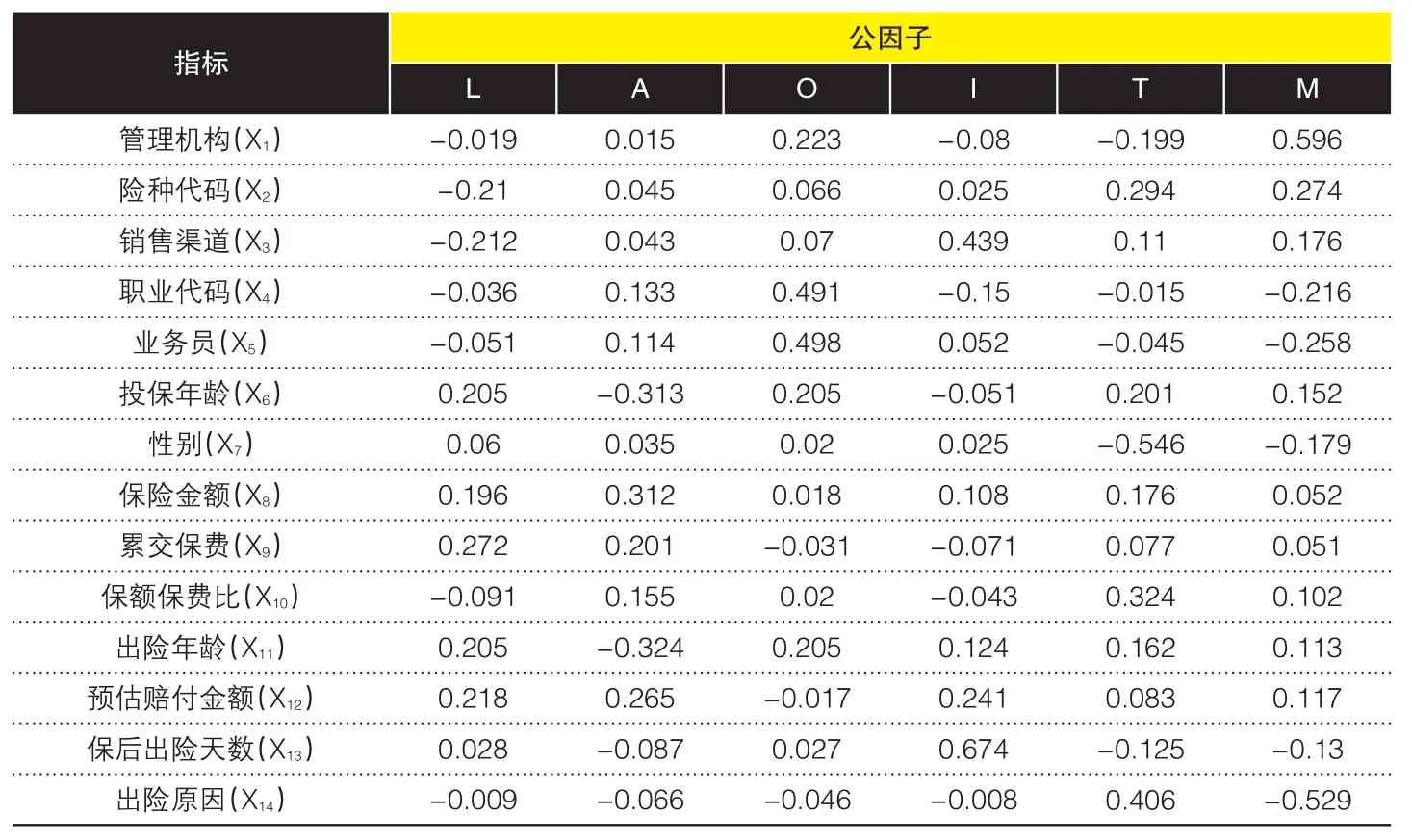
表3 公因子对14个原始变量的影响系数
根据以上测算结果可写出各公因子的数学表达形式,如公因子L为:
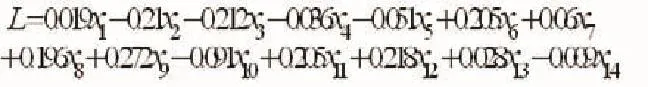
其余五个公因子A、O、I、T、M的数学表达式亦可照此写出,此处不再一一赘述。
(2)数据建模。以F表示一件申请理赔的案件欺诈风险值得分,建立多元线性回归模型如下:
F=a+bL+cA+dO+eI+fT+gM
其中:a为常数,b、c、d、e、f、g分别为各因子系数。
对提炼的6个公因子得分与拒绝赔付和协议给付案件数据进行回归建模,拟合回归方程如下:
F=0.0422-0.0124L + 0.0522A + 0.107O-0.0337I-0.0023T-0.0253M
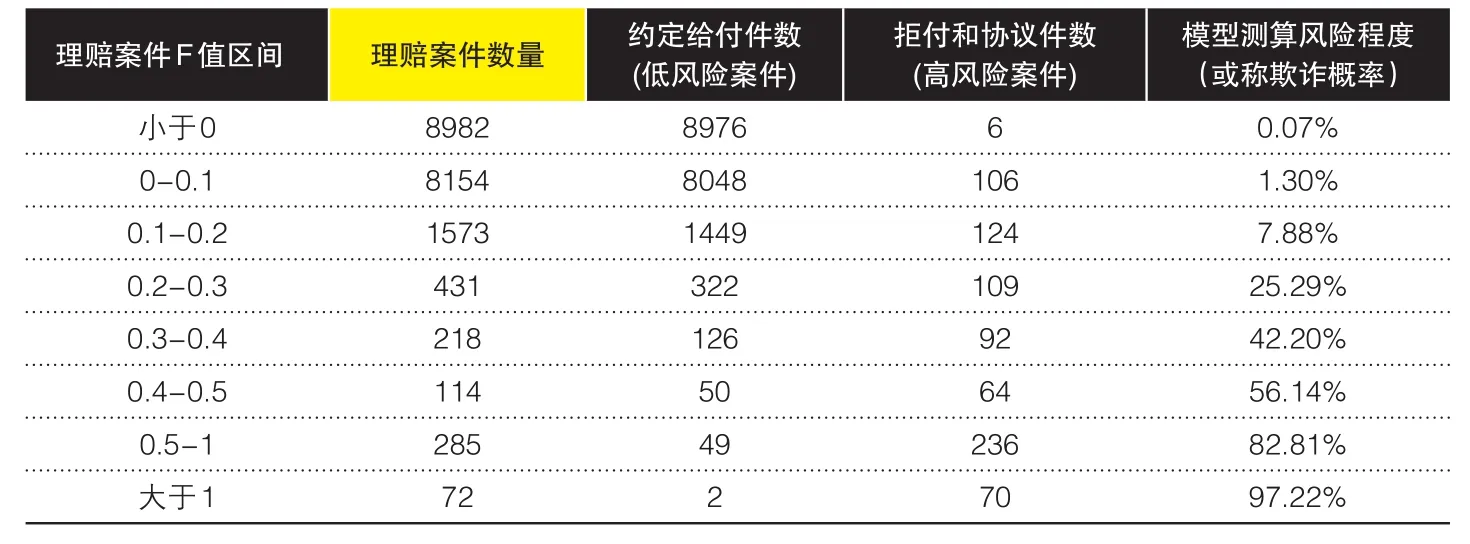
表4 规模数据验证欺诈风险预警模型数据统计情况
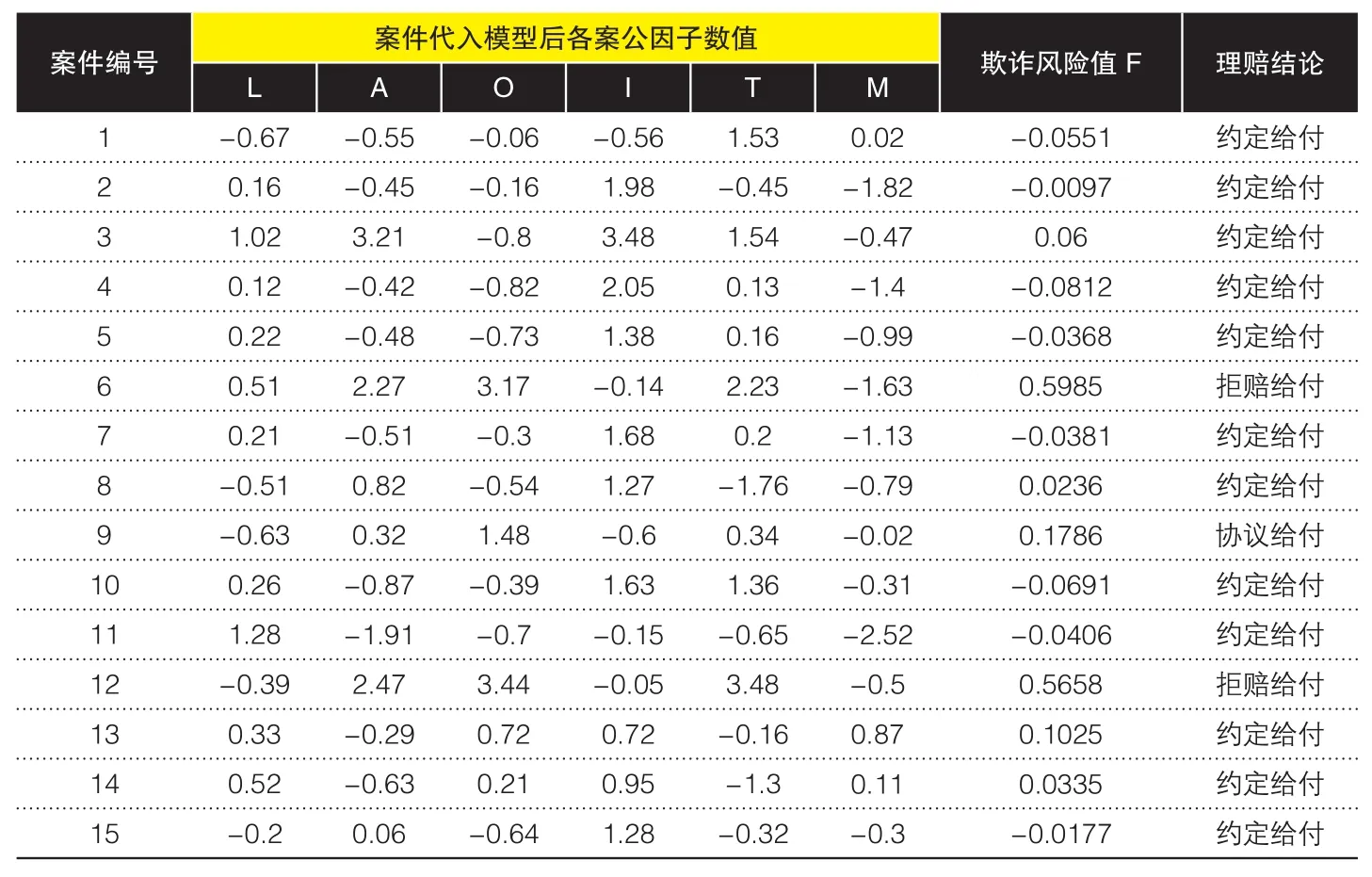
表5 随机抽样验证欺诈风险预警模型数据统计情况
得到适合于该人身保险公司的人寿保险理赔案件欺诈风险预警模型。
(三)模型有效性验证及应用
1.模型有效性验证
对于涉嫌保险欺诈的理赔案件,保险公司在查实相关欺诈证据后一般以拒绝赔付处理,难以充分锁定证据或仅能锁定部分证据的情况下多以协议赔付进行处理,因此可以通过观察每个理赔案件的F值与最终理赔处理结论之间的关系来验证模型的有效性。
(1)规模数据验证。规模数据验证采用历史数据回溯印证的方法,选取该人身保险公司与G省分公司经济发展水平、业务结构和管理状况相近的另一省份H省分公司,提取其辖内2013年和2014年全部19829件人寿保险理赔案件,并逐一计算欺诈风险值(F值),然后根据理赔案件的实际赔付情况对应观察模型的风险测评效果,结果见表4。
从表4可看到,随着欺诈风险值F的增长,理赔案件以拒绝赔付和协议赔付进行处理的比例逐渐增大,也就是说案件的欺诈可能性在逐渐增强。当F值小于0时,8982件理赔案件中仅有6件是以拒赔或协议方式处理的,风险程度极低;而当F值大于1时,几乎所有的理赔案件都是以拒赔或协议方式处理的,风险程度高达97.22%。该统计结果在规模数据层面验证了模型的有效性。
(2)随机抽样个案验证。随机抽样个案验证采用预测印证的方法,随机选取H省辖区内5个地市刚刚申请理赔的15个人寿保险理赔案件,用欺诈风险预警模型计算其F值;不管其F值大小如何,均对上述15个理赔案件运用最高程度的风险控制手段,并进行全方位商业调查以证实或证伪各潜在风险点,最终得到的理赔处理结果见表5。
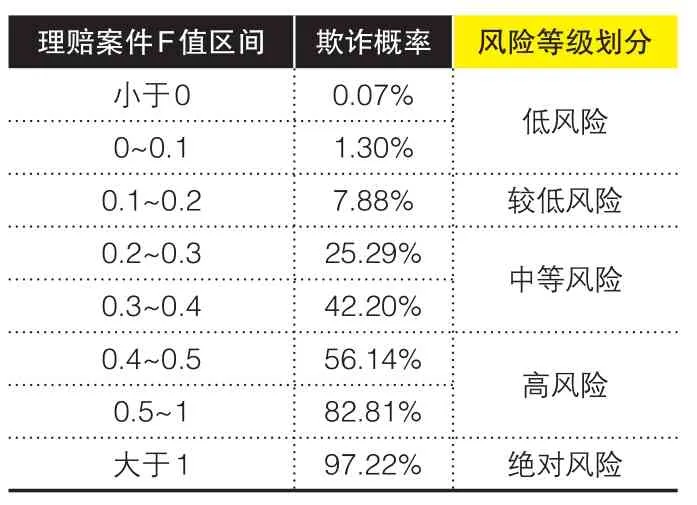
表6 F值各区间段对应风险等级划分
验证数据显示,15个理赔案件中有12件以约定给付处理,其中8件F值小于0,3件介于0~0.1之间,处在模型计算的低风险区域;1件F值介于0.1~0.2之间,处在模型计算的较低风险区域。另外3个理赔案件拒赔2件、协议赔付1件,其中协议赔付处理的1件其F值介于0.1~0.2之间,处在模型计算的较低风险区域,但已接近中等风险区域;2件拒赔处理的其F值介于0.5~1之间,处在模型计算的高风险区域。该验证结果在个案风险评估层面验证了模型的有效性。
2.模型在人身保险公司反欺诈实践中的应用
在保险公司与投保人、被保险人之间的博弈中,保险公司是处于信息弱势的一方,需要依靠商业调查来消除这种弱势。但前文已经提到,商业调查成本高、耗时长,不宜也不可能作为一种普遍手段应用于每一单业务,而欺诈风险预警模型正好能够解决这一关键问题。
欺诈风险预警模型在保险公司运营管理中最有价值的应用在于提示风险和发起调查。通过预警模型对全部理赔案件进行风险扫描,测算每件理赔案件潜在的欺诈可能性,并从中筛选出风险程度较高的案件进行重点调查。这样能够有效提升保险公司风控资源的使用效率和效果。下面列举一种简便易行的应用方式。
(1)根据F值各区间段对应的欺诈概率划分理赔案件风险等级。以表6有关数据为例,作风险等级划分。
(2)设定每一风险等级的理赔调查率和调查等级。对绝对风险、高风险2个等级的理赔案件,设定100%的调查率(即每案必调),并设置最高的调查等级,调查核实每一个潜在的风险点;对中等风险的理赔案件,采用随机抽取或重要特征值抽取的方式,设定40%~60%的调查率,同时设置较高的调查等级,对重要风险点进行一一核实;对较低风险的理赔案件设定10%~20%的随机抽样调查率,设置普通调查等级,对关键风险点进行核实;低风险案件则不进行调查。
(3)欺诈风险预警模型的系统植入。利用信息技术将欺诈风险预警模型嵌入保险公司的理赔业务处理系统,以IT系统自动化智能发调替代人工审核发调工作,这样一方面能够节省大量人力,另一方面又能减少人工介入带来的各类操作风险。
(4)设置必要的风险管控安全阀。任何模型都不可能是完美的,也不可能全部替代人工作业。对欺诈风险预警模型初筛后定义为低风险的理赔案件,实施一定比例的人工审核发调的风险管控措施,持续观察该部分案件后续的理赔处理情况,重点观察模型风险误判的理赔案件,积累特征值数据,对欺诈风险预警模型定期进行必要的参数修正和模型完善。

从某种意义上说,保险业的发展史同时也是一部反欺诈斗争史。
四、小结
保险行业本身是一个经营风险的行业,保险欺诈是这个行业诞生和成长过程中形成的伴生体,从某种意义上说,保险行业的发展史同时也是一部反欺诈斗争史。保险公司应对欺诈的策略,一是通过提高产品定价来弥补欺诈造成的损失,但这种方式较为被动且会损害善良客户的利益,最终会影响保险公司的市场竞争力;二是通过完善风险管理体系,主动防范和打击保险欺诈。通常情况下这两种策略同时被使用,但保险公司天然偏向于后者,特别是市场竞争的加剧和技术手段的发展从两个角度推动了保险公司做出更有倾向性的选择。
本文依托于人身保险公司的长期商业实践,通过对大量数据的统计,分析了人身保险欺诈的行为分布特征、险种分布特征和金额分布特征;并以人寿保险作为建模对象,基于因子分析构建了人寿保险欺诈风险预警模型,通过规模数据回溯印证和随机抽样个案预测印证两方面验证了模型的有效性,并介绍了实证结果在保险公司反欺诈工作实践中的应用方法,希望能对我国保险欺诈风险防控提供一定的参考。当然,由于笔者能力有限以及一些客观条件的限制,本文的研究还存在一些不足的地方,需要在今后的研究中进一步完善:比如,为实现预警模型在实务中的便捷应用,需要对指标体系做进一步的拆分和细化,完善指标体系的覆盖面和针对性,并尽量简化指标评价繁复的演算过程,推导基于原始指标的预警函数模型,增强实践可操作性;此外,还应进一步扩大研究样本数据容量,使预测模型更加准确、稳定,提高后续基于模型构建风险预警系统的鲁棒性(robustness)。
展望未来,相信随着我国社会征信体系建设的日臻完善和保险大数据研究与应用的发展,反保险欺诈的工具与手段将会更加丰富和完备,为保险业的健康发展营造更为和谐的氛围。
猜你喜欢
眼科新进展(2023年9期)2023-08-31 07:18:36
眼科新进展(2022年12期)2022-12-29 06:00:50
河北金融年鉴(2021年0期)2021-08-25 08:59:08
河北金融年鉴(2020年0期)2021-01-21 08:37:20
中国外汇(2019年10期)2019-08-27 01:58:04
北方工业大学学报(2019年5期)2019-03-30 06:31:56
东北电力大学学报(2018年2期)2018-05-21 09:51:14
数学理论与应用(2017年2期)2017-06-27 07:39:00
公民与法治(2016年24期)2016-05-17 04:21:39
河北金融年鉴(2014年0期)2014-02-27 13:22:56
