
大数据环境下的图书馆异构数据统一访问与转化系统
2016-04-11 03:51南京晓庄学院
图书馆理论与实践 2016年2期
曹 畋(南京晓庄学院)
大数据环境下的图书馆异构数据统一访问与转化系统
曹畋
(南京晓庄学院)
摘要:现代图书馆对信息技术的应用是全方位的,对数据的存储和管理早已达到TB级别,并且,随着图书馆信息的多元化,数据来源将越来越多样。如何将这些数据以TB级别计量的、具有巨大差异的数据源、数据格式进行统一的处理和分析将成为未来图书馆数据应用中面临的重要问题。
现代化图书馆对各类数据库的采购、部署和新建的快速增长,使数字信息的访问与转化问题逐渐上升为制约图书馆发展的关键问题。图书馆通过多年的信息化建设,几乎都已自建和购买了大量由不同核心技术构建的信息系统或数据库。这些曾经推动图书馆信息化建设的信息系统或数据库,正演变成一个庞大的异构数据源群体,这样的异构数据源逐步成为制约图书馆数字资源平台联通的沟壑。目前,通用信息统一访问和转化方面的研究还属于起步阶段,实现数据共享的途径可以分为两种:数据的转换和数据的集成。数据的转换是将物理意义上的数据集中,这种方式在类似图书馆这样的海量数据进行迁移和管理时存在非常大的风险,并且需要在硬件设备及相关软件上进行巨额投资,即便是完成了这种数据的集中,访问速度慢也是一个大问题。数据的集成属于逻辑上的集中,这种方式比较适合图书馆信息资源分布存储、分散管理、统一访问接口的现状,能最小限度地回避和减少对现有图书馆数据系统和数据库的改造。
通过大数据技术,特别是大数据技术中的服务数据对象(Service Data Objects,SDO)技术可以大大简化实现异构数据统一访问难题。大数据技术可以相对简单地实现统一方式访问和异构数据库操作,使得图书馆有可能自行完成异构数据统一访问和转换的部署,因此可能成为最适合当前图书馆异构数据统一访问和转换方案。当然,需要真正实现图书馆大数据环境下异构数据统一和转换的问题,除了用到SDO技术外,还需要涉及大数据技术中的Hbase数据库技术和模型驱动数据转换技术(Model Driven Architecture,MDA)。
1 相关技术介绍
1.1服务数据对象技术简介
服务数据对象其实是一个信息的容器,这个容器可以提供在整个单位应用程序中表示信息的方法,包括表示层、业务逻辑层和持久层之间的通信。不但如此,SDO还解决了异构数据的兼容问题,提供一个简单、统一的模式处理相关数据。下面通过图1来看一下在SDO下各个层次是如何进行通信的。[1]
SDO通过统一不同数据源类型的数据编程,屏蔽了数据库底层的差异。对于那些无法预先知道的数据类型,SDO可以动态地组合数据,添加、修改属性。通过SDO应用程序、框架和工具,数据变得更容易被查询、绑定、读取和更新。
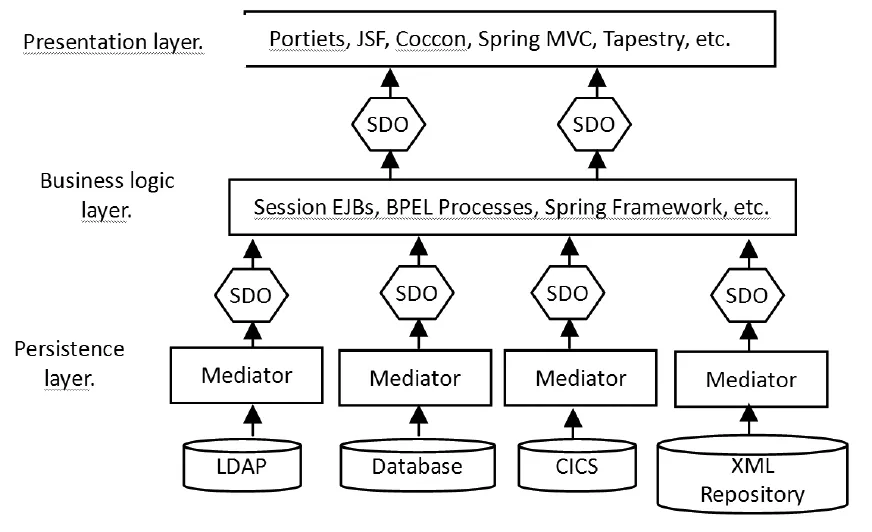
图1 SDO应用通信图
1.2HBase数据库技术简介
Hadoop Database通常缩写为HBase。HBase是一种分布式存储系统,具有高性能、高可靠性、可伸缩、面向列等一系列特点,利用它可以方便地搭建大规模机构化存储集群。
2007年10月,HBase第一个版本随着Hadoop 0.15.0捆绑发布。很快,2010年5月,HBase从Hadoop子项目升级为Apache的顶层项目。如图2中Hadoop构成图所示,Haddoop System的层次关系及各层次系统模块的相互关系都得到清晰体现。不难发现,Hadoop HDFS为位于结构化存储层的HBase底层存储提供高可靠性支持,Zookeeper为HBase提供了failover机制和稳健的服务,Hadoop MapReduce为HBase提供了高性能的计算支持,HBasede的高层语言支持由Pig和Hive提供。在HBase上进行数据统计而被变大简化,Sqoop为HBase提供的便捷的数据导入功能正是这种特别、便捷的导入功能,使得传统数据库迁移到HBase变得非常方便。[2]
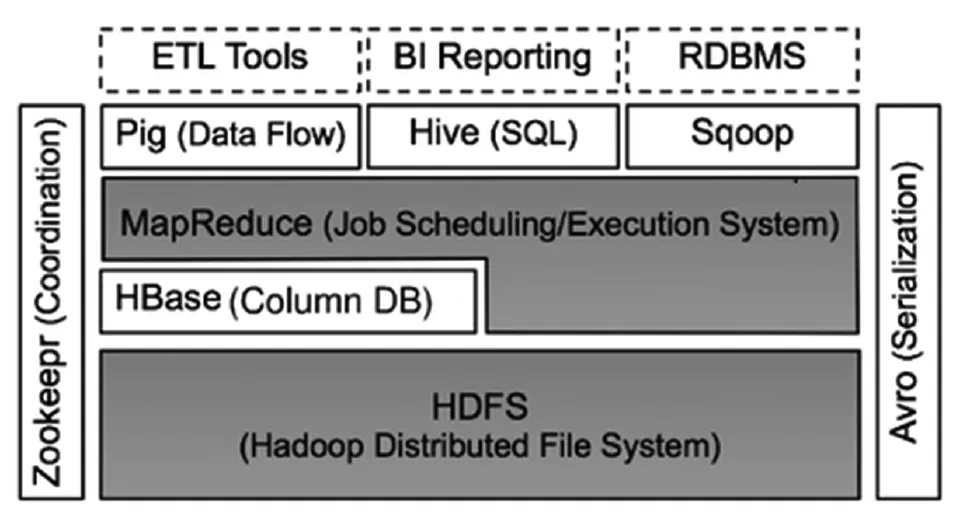
图2 Hadoop构成图
在HBase系统架构中,HBase Client与HMaster和HRegionServer进行通信是由HBase的RPC机制实现的(见图3)。其中,管理类操作控制的RPC由HMaster 与Client进行;数据读写类操作由HRegionServer与Client运行。除-ROOT-表的地址和HMaster的地址都存储在Zookeeper中以外,Zookeeper还存储以Ephemeral方式注册的HRegionServer。这样不但避免了HMaster的单点问题,而且使得HMaster可以随时感知到各个HRegionServer的健康状态。HRegionServer 是HBase中最核心的模块,它负责响应用户I/O请求,向HDFS文件中读写数据。[3]
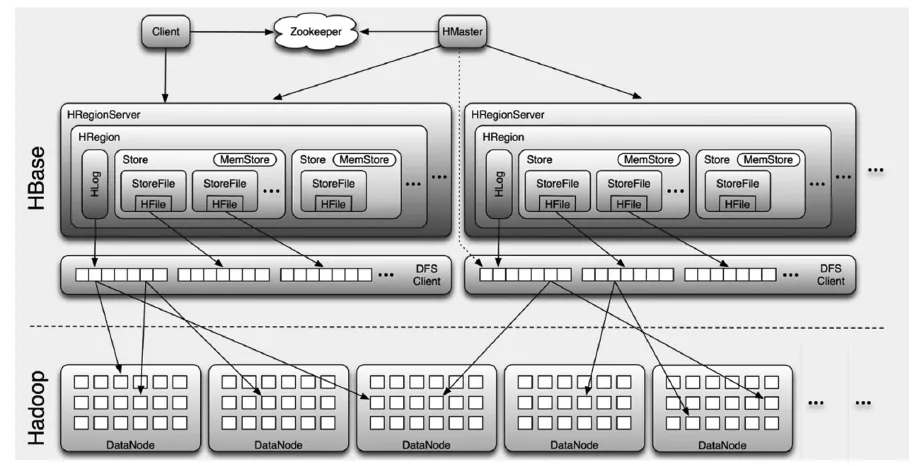
图3 HBase系统架构
1.3Hadoop MapReduce框架
Hadoop MapReduce是一个软件框架,基于这个框架开发的程序可以运行在集群服务器上,并且以高容错的方式处理T级别的数据群。Google公司对于海量原始数据的处理有大量的技术经验,且这些技术中很关键的一部分就是海量数据的处理办法。海量数据处理一般包含以下步骤:首先在输入数据的逻辑记录上得出一个中间key/value集合(应用Map操作得到),然后在所有具有相同key值的value值上应用Reduce操作,合并中间数据并最终得到结果。[4]
1.4模型驱动的数据转换技术
热门的基于大数据的模型驱动架构(Model Driven Architecture,MDA)是由对象管理组织OMG定义的,是基于UML和其他工业标准的一种开发框架。设计MDA的核心思想是:将与完整描述业务功能的核心平台无关且与实现技术无关的模型(Platform Independent Model,PIM)抽象出来后,可以根据不同的具体实现技术指定多种特定的转换规则,在相关辅助工具和特定转换规则共同作用下,将PIM转换到实际的(Platform Specific Model,PSM)相关技术平台相关的模型上,最后将经过填充的PSM变为特定平台相关代码。MDA通过PIM和PSM实现了底层平台技术和业务模型的分离,这样就让不同技术平台迁移不会影响到建模的成果(见图4)。
中心圆中的元对象设施(Meta Object Facility,MOF)、公共数据仓库元模型(Common Warehouse Metamodel,CWM)及UML构成了MDA的核心技术。中间环上标注了当前主流的平台技术JAVA、WebServices、CORBA、XML、.NET等。MDA的一项重要工作就是将这些基于不同技术平台建立的PIM转换到不同的中间件平台,从而得到相应的PSM。[5]
本文主要需要用到MDA框架下的模型转换语言ATL。ATL的全称是ATLAS,它的出现使得一种符合OMG的QVT提案的模型转换成为现实。所以也有人认为ATL其实本质应当是一种模型转换语言。如果把ATL看成一种语言,那么它可以被认为是一种混合语言,因为它既可以含有命令语句的内容,也可以描述语言的特征。首先要弄清楚一个ATL程序需要包含哪些内容。而要弄清这些内容,就需要先看ATL的整个框架结构(见图5)。
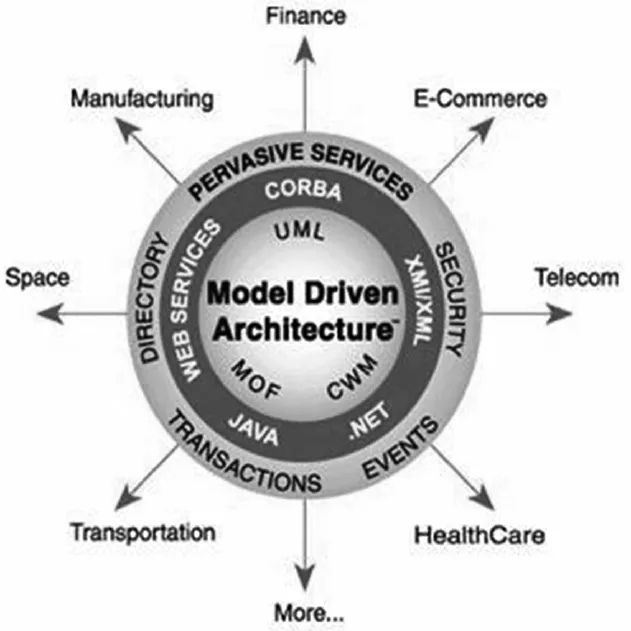
图4 MDA结构示意图
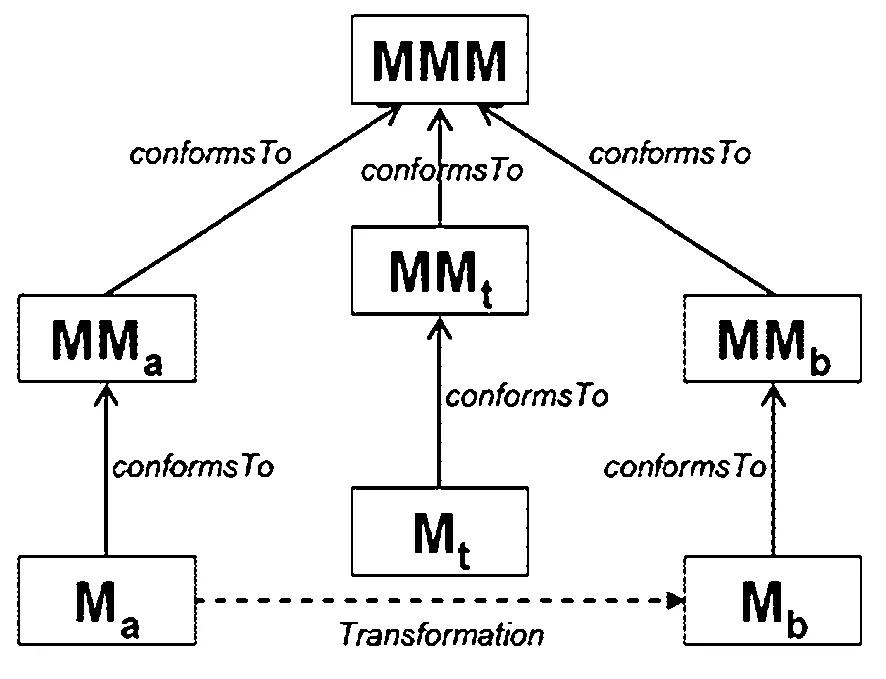
图5 ATL转换层次结构
Ma代表源模型,Ma符合元模型MMa。Mb代表目标模型,Mb符合元模型MMb。同样,MMa和MMb都符合唯一的元元模型MMM。Mt是一个模型转换的实例,当然它也是一种模型,它也就符合模型转换的元模型MMt。同样,MMt也就必然符合唯一的元元模型MMM。那么,ATL中,Ecore可以被看作那个唯一的元元模型,它的地位类似于DOF。Ecore创建出诸如元模型MMa和MMb等。Ma和Mb则是符合这些元模型的实例具体化。如果MMt已被ATL定义好了,那么Mt就是使用者自己要定义的模型转换模型,也就是模型转换程序。[6]
2 图书馆应用数据统一访问和转换的需求分析
通过对当前大部分图书馆实际应用情况进行抽象分析,可以得出数据统一访问和转换的功能性需求(见图6)。
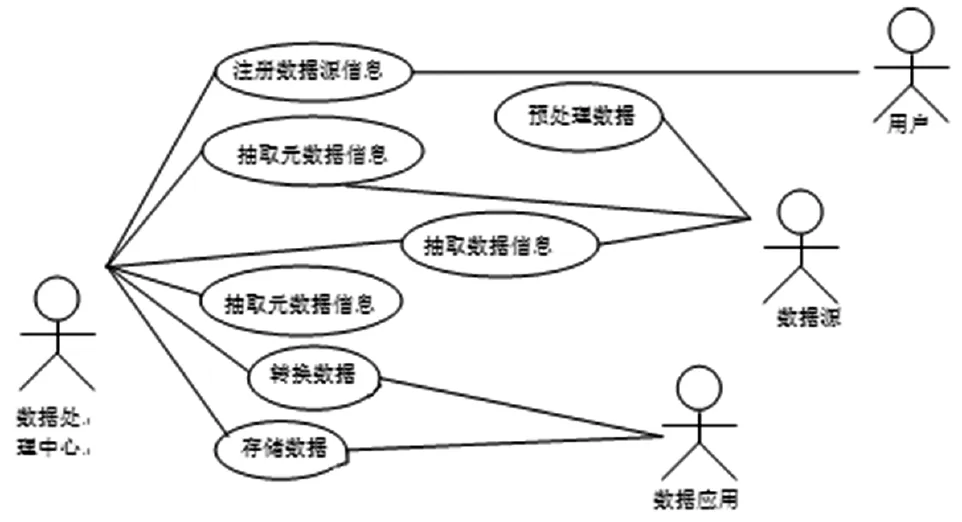
图6 图书馆数据统一访问和转换用例
图书馆数据的统一访问和转换需要实现的主要功能有:数据处理中心抽取相关异构数据源的元数据并依据这些元数据建立映射模式;数据处理中心抽取数据源中的数据信息;数据处理中心对异构数据进行转换并储存转换后的数据;图书馆用户注册数据源信息到数据处理中、异构数据源对数据源中数据进行预处理。当然,图书馆异构数据是庞大的,在抽取这些数据信息并进行转换的过程中需要上文介绍的Hadoop大数据平台和相关技术保障数据高效率、快速准确地运算和存储。[7]
总体说来,图书馆异构数据统一访问与转化系统需要满足七点基本要求:①数据的统一性;②数据的一致性;③数据的完整性;④数据的安全性;⑤访问透明;⑥准确性;⑦及时性。[8]根据以上要求,并结合图书馆应用实际,对图书馆数据统一访问与转换平台的中体系统设计架构如图7所示。

图7 图书馆数据统一访问与转换架构图
整个框架结构图可以看作七个部分组成:数据源部分、数据抽取管理、数据转换管理、元数据抽取及管理部分、模式映射管理、数据存储管理和目标数据应用。模式映射管理与元数据管理组成了模式管理模块。在模式管理模块中元数据管理模块主要负责元数据的抽取和解析。模式映射管理和数据转换管理组成数据转换管理模块,则为用户需要定义各转换节点的转换规则,创建任务的工作流则是依据模式映射构建了源到目标的字段映射的转换等操作。这些被映射的元数据(或者说是操作规则)存储在元数据管理模块中,元数据抽取管理部分和数据抽取管理构成了数据源访问模块。在执行任务时,系统会从元数据管理模块中查询转换映射规则并完成数据的转换。该模块中使用的技术主要有分布式云计算Haddoop平台、HBase数据块技术以及分布式MapReduce计算框架。数据存储管理则主要负责模式映射管理模块创建的映射模式存储以及转换规则、转换中间数据存储等。[9]
3 图书馆异构数据统一访问与转化系统设计
图书馆异构数据统一访问与转化系统设计的整体详细架构图如图8所示。
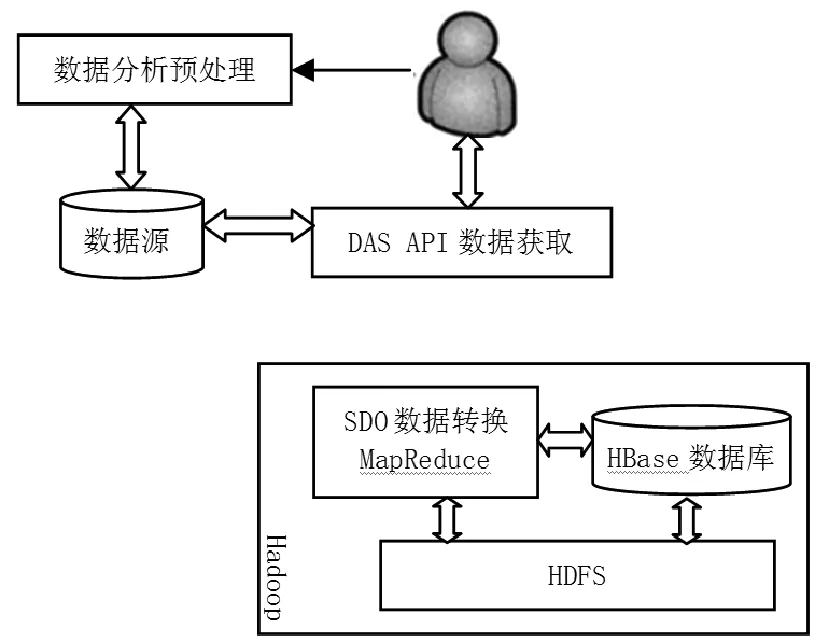
图8 异构数据统一访问与转化系统设计架构
大数据环境下,图书馆异构数据统一访问与转化需要对数据源数据依据用户要求作预处理分析,在此基础上通过DAS对异构数据源实现统一访问,并使用SDO结合MapReduce完成海量数据并行转换应用处理。
4 图书馆异构数据统一访问与转换系统实际部署中需要注意的事项
4.1数据分析、数据审核和数据修正
为了满足图书馆大量数据的具备统一处理规则,需要数据分析、数据审核和数据修正三个部分进行协调保障,具体流程如图9所示。
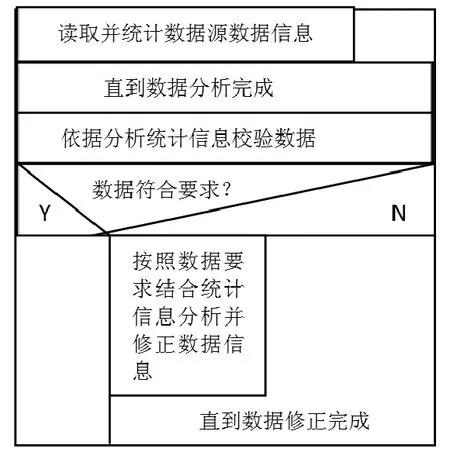
图9 数据分析及预处理N-S流程图
数据分析是对数据可用性的一个统一检查和统计分析过程。可以借助统计计量描述一些数据集或者样本集特征,如可以借助与类似OWB这样的ETL工具,也可以借助统计学中非常实用的图表工具Box plot进行数据分析。接下来的数据送审,主要是评估数据是否满足后期数据统一处理的规则要求,主要审核指标包括:数据的完整性、一致性和准确性。[10]
4.2构建基于DAS的图书馆数据源统一访问
图书馆异构数据统一访问需要统一的异构源数据结构多种多样,比如:关系数据库和其他文本、XML等。而关系数据库中常见的就有Oracle、SQL Server、DB2、MySQL等。图书馆既然要实现通过统一的接口访问数据,就是要屏蔽这些异构数据源访问中可能的差异性(见图10)。
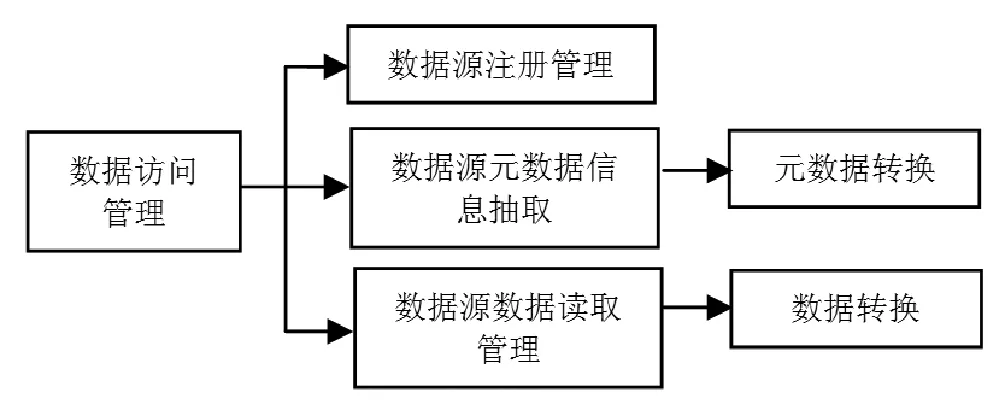
图10 图书馆数据源访问结构图
图书馆异构数据访问模块主要由数据源注册管理、数据源元数据信息抽取和元数据转换、数据源数据读取管理及数据转换组成。其中,数据源数据的读取是关键,该模块完成所有实际数据的读取功能,包括将数据源的数据读取到数据处理中心。由于图书馆各类数据源的数据存储结构差异巨大,在数据源数据读取中往往涉及海量的数据,对系统的数据处理性能提出了巨大挑战,从数据源端读取数据的阶段面临这种性能调整尤为突出。另外,大量的I/O操作也可能成为数据读取中的硬件性能瓶颈。实际应对策略,除提高硬件性能外,还可以综合应用诸如建立索引、External Loading、Bulk Loading,建立连接池、缓冲池这些方法提高服务器的效率,同时充分利用对应数据库可能涉及的优化技巧,不断总结和提高数据的读取速度,当然定期升级数据库也是其中重要的一环。最后,通过基于SDO的技术来统一处理图书馆大数据,可以最大限度提升数据处理性能。因为通过DAS将数据源数据加载到数据对象中后,对数据对象的处理都可以采用标准SDO方式进行。下面用图书馆数据源数据获取流程图描述数据源数据访问过程中的数据流导向(见图11)。[11]
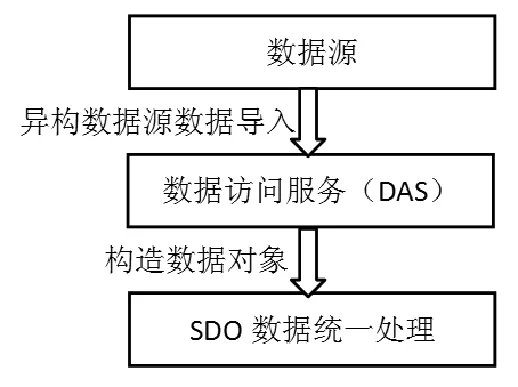
图11 图书馆数据源数据获取数据流图
本文分析并设计了一个适合图书馆未来发展的基于服务数据对象的异构数据统一访问系统。该系统能满足图书馆当前及未来很长一段时间的异构数据统一访问及转换,为图书馆数字资源建设与数字服务提供了新的契机。
[参考文献]
[1]徐青翠,等.SDO在高校数据集成平台的应用研究[J].科技广场,2013(10):69-72.
[2]宫夏屹,等.大数据平台技术综述[J].系统仿真学报,2014(3):489-496.
[3]靳小龙,等.大数据的研究体系与现状[J].信息通信技术,2013(6):35-43.
[4]张小艳,等.基于模型驱动架构的煤质管理系统测试研究[J].工矿自动化,2014(2):36-39.
[5]张小艳,文辉.基于ASL的模型驱动架构测试方法[J].计算机工程与科学,2014(4):662-666.
[6]王宇英,等.面向信息物理融合系统的异构模型转换方法[J].西安电子科技大学学报,2015 (2):124-131.
[7]曹畋.试论图书馆信息化项目的需求工程[J].内蒙古科技与经济,2013(13):79,93.
[8]郑悦,杨勇.SDO2JSON:一种业务数据模型到表现层模型的转换方法[J].计算机应用与软件,2012(3):13-15,73.
[9]亢丽芸,等.MapReduce原理及其主要实现平台分析[J].现代图书情报技术,2012(2):60-67.
[10]Hua-Dong,etal.Thekinematicsofanuntwistingsolar jet in a polar coronal hole observed by SDOIAIA [J].Research in Astronomy and Astrophysics,2012 (5):573-583.
[11]耿玉水,寇纪淞.云计算下异构数据集成模型的构建[J].济南大学学报(自然科学版),2012(4):384-389.
Uniform Access and Transformation System for Heterogeneous Data in the Big Data Environment of Library
Cao Tian
Abstract:The application of information technology in modern library is extensive, and the storage and management of the data in modern library has already reached the level of TB.Along with the diversification of library collection, data resources are becoming increasingly diverse.The libraries are encountering the fact that the data are heterogeneous and various databases are of different performance and data formats,which makes processing and analysis of these data the primary problem for the libraries inthe future.Keywords: Big Data; Heterogeneous Data; Access; Conversion
[收稿日期]2015-10-09[责任编辑]刘丹
[作者简介]曹畋(1981-),男,南京晓庄学院工程师,研究方向:图书馆信息化,新媒体,大数据。
中图分类号:G50.73
文献标志码:A
文章编号:1005-8214(2016)02-0080-05
关键字:大数据;异构数据;访问;转换
猜你喜欢
小学教学研究(2022年5期)2022-04-28
活力(2021年6期)2021-08-05
艺术品鉴(2020年6期)2020-08-11
小学生学习指导(低年级)(2019年3期)2019-04-22
商周刊(2019年1期)2019-01-31
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
中国洗涤用品工业(2017年2期)2017-04-16
通信电源技术(2016年6期)2016-04-20
浙江大学学报(工学版)(2015年2期)2015-05-30
