
我国高校中文学位论文相似度检测技术研究
2016-02-07 05:10蔡晓君
唐山师范学院学报 2016年2期
蔡晓君
(泉州师范学院 图书馆,福建 泉州 362000)
我国高校中文学位论文相似度检测技术研究
蔡晓君
(泉州师范学院 图书馆,福建 泉州 362000)
对如何遏制中文学位论文抄袭严重现象提出一种基于词频的相似度检测技术,并研究设计出相应的计算机检测算法。首先分析了中文学位论文的标准格式和中文语句、结构的语言特点,总结出中文学位论文抄袭的判断方法;对中文学位论文的统一表达形式提出一种基于树结构的数据结构模式;在论文内容相似度检测机制中引入向量空间模型的相似度检测方法,通过信息熵理论改善和规范了向量空间的特征项权重值计算问题。最后给出了中文学位论文基于树形结构存储计算的向量空间模型相似度检测算法。
相似度;树结构;信息熵;向量空间模型
近些年来,学位论文的抄袭剽窃、重复发表,低水平重复等道德失范的现象愈演愈烈,从一个侧面反映出高校教学质量和人才素质培养的缺陷问题。这些问题不仅影响教育教学质量的提高,而且严重影响了学术声誉、阻碍学术创新和学术进步,特别是研究型、知识型人才的培养。这对我国科教兴国战略的实施和伟大中国梦的实现提出了挑战。根据文莉和谢荷锋[1]对国内某些大学抽样调查,论文抄袭现象非常普遍,坦白存在严重抄袭和较多抄袭的人为65.9%,仅有1.6%的受调查访问者明确表示不存在抄袭行为。如何有效地制止和避免论文抄袭现象的出现成为近些年来热门的研究课题,引起了社会各界的广泛关注,因此进行中文学位论文抄袭检测技术的研究就很有意义了。
1 中文学位论文抄袭判定和检测机制
1.1 论文抄袭判定的方法
学位论文是指为获得所修学位,按要求被授予学位的人所撰写的论文。根据《中华人民共和国学位条例》的规定,学位论文分为学士论文、硕士论文、博士论文三种。学位论文的撰写是被授予学位的人运用相应学位知识进行再加工、再创造的知识过程,其成果是学位论文。学位论文的独创性体现在作者发现问题、研究问题到解决问题过程中付出的巨大脑力和体力劳动,其成果可证明其研究解决能力已达到相应学位等级水平,或具备同学位水平的科研技术水准推进扩宽科学技术研究水平的深度和研究领域的广度。从论文的创作本身而言,很大一部分是建立在前人工作和研究的基础上的,所以在撰写中都会包含对前人的成果的吸收和合理利用,在论文本身中引用和借鉴是其主要的表现形式,同时也存在着对他人研究成功的适当化加工而引述,这种合理的学术过程为论文抄袭的识别增加了难度。抛开这种合理的学术借鉴引用,整句整段落的原文抄袭是非常容易识别的,因此论文抄袭人员往往会对抄袭内容进行翻译加工,使其带有很强的隐蔽性和欺骗性,同时中文语句又有很强的语境意义,又会给抄袭的辨识增加额外困难。因此中文抄袭的判定需将内容和语义结合起来进行判定[2]。
论文的抄袭现象可以概括为如下三种情况,一是论文题目相同或相近,且研究的内容成果相同或是相近;二是将别人论文的内容进行表达上的转述或“翻译”作为自己的论文成果;三是在自己的论文中,直接引用或摘录别人的文章的内容而没有引用标注说明的。如果论文检测中存在这三种情况中的任何一种就可以判定论文为抄袭。根据论文抄袭的程度不同,可以将抄袭划分为部分抄袭和完全抄袭两类:第一类部分抄袭,也就是论文的内容有部分相似或相同,存在部分文字的抄袭;第二类是完全抄袭,也就是论文不论是内容还是表述方式都从原文进行复制过来,只是对部分文字进行了替换或修饰。
1.2 论文文本检测机制
论文的文本检测机制在技术实现上分为两类:一是基于签名的检测机制,基于签名的文本检测是在文档中加入“签名”,通过检测“签名”来识别该文本是否为“原创”或是“抄袭”的文档,例如运用数据存储技术在文档保存的数字格式中加入特定人眼无法辨识的数字水印,通过对应的检测数字水印技术来判断是否为“抄袭”的文档,但“签名”机制存在可通过物理录入去除数字水印的漏洞和无法进行文本部分复制的检测缺陷;二是基于内容的文本复制检测机制,将待测的文档通过预处理后和现存文档数据库的内容比较,当待测文档和文档数据库中文档内容间相似度超过一定程度,系统就报告存在复制现象,现象量化程度达到预先规定的抄袭阈值后,待测文档判定为抄袭。
对中文学位论文是否抄袭的判定如果采用基于内容相似度检测的方式进行,那么就可以运用计算机的高运算性和大容量存储的特性针对高校中文学位论文的相似度的检测系统设计。图1描述了该系统的检测业务流程。

图1 文本相似检测系统结构图
格式化检测文档和格式化抽取是一种文本处理过程,将整篇待查中文学位论文和庞大的样本库中文资料进行存储和计算是不现实的,因此需要采用相同的计算机表达方式将中文文档进行一定的加工,方便于计算机的存储和计算。
匹配计算一般有两种处理方式,一种是进行性中文的字符串匹配计算,而本文采用的是另一种方式,基于词频的统计算法方式。基于词频的统计算法是将中文文档转化成向量空间模型(VSM)进行表示,从文档中抽取一系列词语和关键性短语作为向量,用向量空间表示全文,通过向量计算进行相似度判定。
2 中文学位论文抄袭检测的文本表示
要进行中文学位论文相似度的检测首先要解决如何将中文论文文本转化成统一的文本格式,同时将自然语言的文本结构化处理为便于相似度检测的文本格式。我国国家标准GB7713-87统一了学位论文的编写格式,给出了学位论文的标准结构,并对学位论文进行了明确定义。学位论文的构成包括两个部分:前置部分和主体部分,如图2所示。
论文的前置部分是论文的一些重要信息部分,主要用于论文的管理。论文的主体部分是论文的创作主体区域,主体部分是作者表达思想和写作的集中区域,因此将论文加工为计算机表达的格式,就需要将结构和内容进行结合。在内容上,论文的前置部分概括了全文,正文是文章的主体;在结构上,前置部分将全文的信息精要概括,正文层次分明,上层信息概括下层信息,每层标题概括本层段落文字信息。这种结构分明的文本格式结构可以采用树形结构进行计算机存储表达。
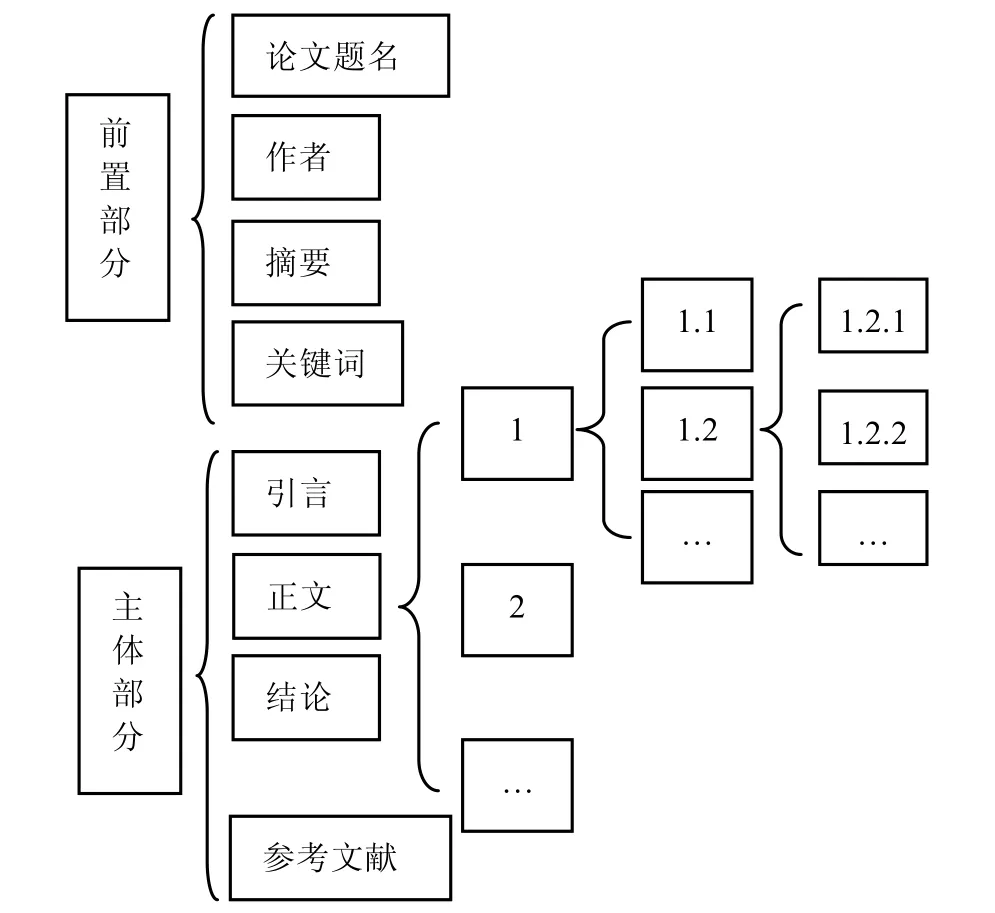
图2 学位论文构成结构
如图3,论文的作者可以作为树形结构的根部,向下的一层叶子是前置部分和主体部分,前置部分叶子的下一层叶子是前置部分各个组成部分,主体部分的下层叶子由引言、正文、结论和参考文献组成,每一层叶子的下一层叶子由其各个组成部分组成。这种树形的层次结构可以体现论文的各个部分的结构关系,同时也契合计算机的存储和表达的特点。
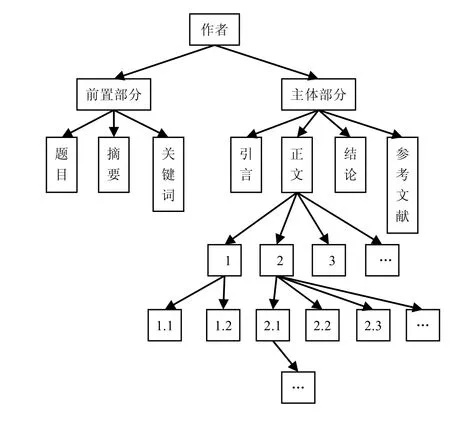
图3 论文结构的树形表达方式
如何准确地表达自然语言的文本内容一直是计算机文本处理的一大难题。显然最为精准和全面的方式就是将文本内容全文作为计算机的计算对象,一字不差地存储到计算机内,但过长的篇幅会浪费计算机的计算能力,这在计算的时间复杂度是不允许的。同时全文的存储会增加计算机存储的成本,这在空间复杂度上也是不允许的。另外全文中存在的“噪音”也会对计算产生误差。因此,通常的做法是将文章进行分词和分段处理,选取其中关键性和有代表性的词语、句子或段落组成的特征集合来代表整篇文章。特征集合要求能概括整篇文章的内容,而且又能同时体现文章的独特性。
特征集合的选择有两个关键问题,一是特征集合的选取能而且必须代表文本的内容;二是基于特征集合的文章表达在相似度检测计算中的时间、空间复杂度应在可接受范围内。在特征集合的大小和数量的选择上都有一定的要求,总而言之,为简化计算提高精度的同时要选取最能代表原文全文的文本来进行文本处理,在进行文本相似度计算时,将采用向量空间模型表示文档中的文字内容,通过抽取文档中的关键词语组成文档的词的特征集合,将文档表示成词的向量空间,通过向量计算进行文档间相似度检测。
将文档进行特征词的向量空间转化后采用树形结构表达论文,通过该方法可以将论文的结构和内容形成计算机的表达。
3 向量空间模型
向量空间模型是文本表示领域常用的一种表达方式,由Gerard Salton[3]在上世纪60年代提出的,该表达方式是从文本中抽取有代表性的特征项,并对特征项进行加权处理,最终将文本转化为向量形式。文本的向量空间D可表示为
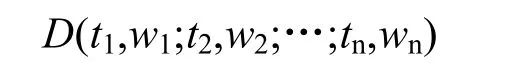
式中向量空间D代表某一具体文档,tn表示第n项特征项,wn为该n项特征项的权重值。文本的空间向量表达方式忽略了文本的结构信息和文本特征项之间的结构关系,使文本的表示集中在相似度检测上,避免结构表示的资源消耗。
判断两文本的相似性就可以通过两向量间的向量点积或夹角余弦值的计算来进行。向量夹角余弦值越大所表示的两文本相似度越高。
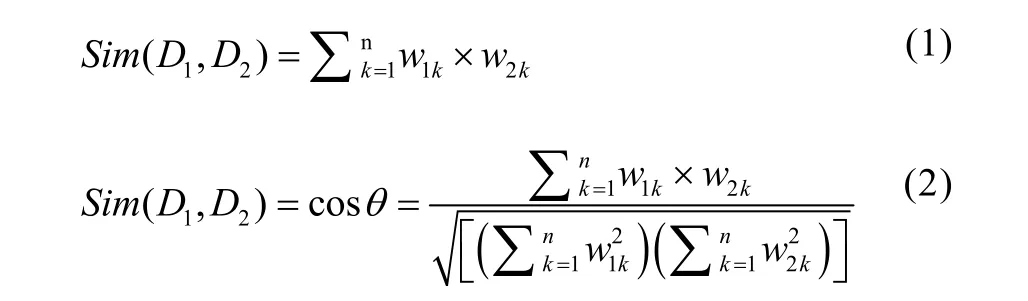
式(1)和式(2)可用来计算两文本间的相似度,Sim值越高,说明两文本间的相似度越高。从向量空间的定义式和向量空间相似度计算公式可以看出,采用向量空间的文本相似度计算的关键问题是如何选取文本的特征项以及如何对选定的特征项的权重值进行计算。
文本的特征项选取是建立在中文“分词”基础上的,中文的语句是由字组成的字序串,字首先组成词,词再组成句子,词是中文中最小能够表达语法的单位。只有将中文文本进行分词后,才能录入到计算机中进行分析,在相似度检测中文本表示成向量空间模型又需要在分词的基础上进行特征词选取。分词是整个文本向量空间模型建立的基础,常用的分词方法有:第一种是基于字符串匹配的分词法,俗称机械分词法,就是将待分词中文字串与中文词“大词典”进行字符串匹配,匹配成功则认定为中文词,并记录下来;第二种是基于理解的分词方法,这种分词方法是通过计算机程序模拟人对中文句子的理解,达到识别是否是中文词的方法;第三种是基于统计的分词方法,通过统计待分词文本中相邻的中文字组成的字组在文本中出现的频数来判断是否为中文词,当频数高于预设的阈值时则认定为中文词,从而达到分词的目的。
完成分词后,就可以从分词集合中依照一定的计算方法进行文本特征项选取组成特征词集合。特征项的选取既要简明扼要又要突出重点,也就是要选取最具有代表性的特征项。传统的特征项选择方法有词频方法、文档频次方法、期望交叉熵方法、互信息方法、信息增益方法、X2统计量方法、文本证据权法[4]。中国科学院计算技术研究所的汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)是当前世界上最好的汉语词法分析器,中文分词的正确率可以达到98.45%。利用ICTCLAS工具进行中文分词,可以从文本中提取系统需要的特征项集合,并根据词频统计进行关键词抽取。
特征项的权重值计算对文本相似度计算的结果影响非常大,重要的特征项的权重值要大,次要的特征词权重值相对较小。特征项的权重一般都是以特征项的频率为基础进行计算的,目前运用最广泛的特征权重计算方法是TF-IDF[5]。如式(3),其中tfk是特征项tk在文本中的频数,而idfk表示特征项tk的反比文本频数,即文本集合中含有特征项tk的文本个数。

根据香农的信息熵理论[6],如果项在所有文本中出现的频率越高,那么它的信息熵就越少,如果项的出现较为集中,只在少量的文本中有较高的出现频率,那么它就拥有较高的信息熵。式(4)体现了式(3)的信息熵理论思想。
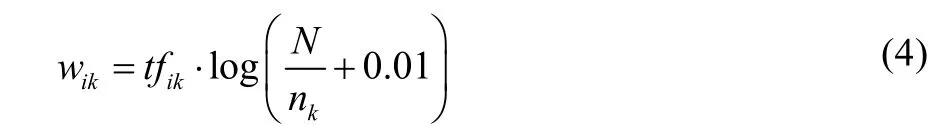
同时文本与文本间进行相似度计算比较中,应消除不同文本长度对权重值的影响,将特征项权值规范到[0,1]区间内,如式(5)所示。运用该式就可以完成文本向量空间模型特征项的权重值计算。
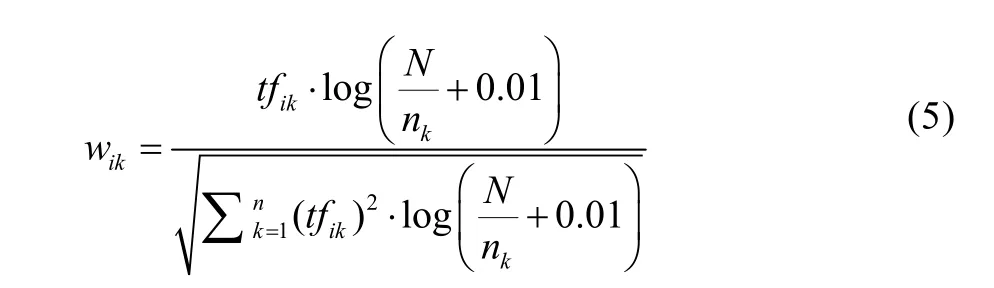
将学位论文进行树形结构表达后,再将对应文本内容进行向量空间化,树形结构中的叶节点的存储内容就转化为原文章的向量空间表达形式。对学位论文相似度的检测就可以通过遍历树与树间叶节点的向量空间模型的夹角余弦值计算来实现。
4 中文学位论文抄袭的判定算法
本文中的中文学位论文抄袭的判定算法应用的环境为我国高校的学位论文相似度检测,其写作格式和规范应严格按照我国学位论文的管理规定,该算法可以检测出不同作者的中文论文间的相似度值;设定部分抄袭阈值A为0.15、完全抄袭阈值B为0.5;算法的输入为待检测中文论文S;输出为抄袭判定结果,有三种输出情况,无明显抄袭、部分抄袭、完全抄袭。
算法的计算步骤如下:
步骤一:对S进行中文论文规范化检查,符合则将S转化为树形结构T表达形式,不符合则结束;
步骤二:通过ICTCLAS工具对T的叶节点进行遍历,从叶节点内容中抽取出该内容的特征项集,并运用式(5)对特征项集进行权重值计算,形成该叶节点的向量空间模型。T的叶节点遍历完成后,形成待测中文论文的向量空间模型的树形表达方式D;
步骤三:遍历D,将D中的叶节点的向量空间与中文数据库DB的向量空间进行向量夹角余弦值计算,累加余弦值的绝对值到C;
步骤四:C小于A,输出无明显抄袭;C大于A且小于B,输出部分抄袭,结束;C大于B,输出完全抄袭,结束。
步骤五;将D存入数据库DB中,结束。
算法步骤中,DB为国内学术期刊运营商提供的中文学术、会议和期刊资料以及迄今被检测无明显抄袭的中文学位论文的数据库,其每一条记录为中文资料的向量空间表示;相似度C在每次检测时初始化为0。
5 结束语
本文通过空间向量模型对论文相似度检测技术进行研究,可以有效地发现论文间的相似性,其相似性的准确性依赖于中文分词、文本特征项的提取技术和特征项的权重值计算。同时中文文档资料转化成树形结构的表达方式不仅有利于文章结构的保留,同时也适用于计算机的存储和计算操作。在进行相似性检测过程中是通过树的遍历算法来实现的,如果能将树结构转换成标准的二叉树结构,那么就需要消耗更多的空间复杂度,但可以换来时间复杂度的降低,提高检测的效率。从整个检测过程中可以发现,中文文本表达形式的优劣性、中文分词特征项的选取的准确性和检测数据库的完备性是影响检测结果的关键。如何使中文文本的表达形式的转换更便捷更低开销、如何提升向量空间模型的计算的效率和如何实现检测样本数据库对中文学术期刊运营商数据库的无缝高效采集是今后研究的进一步方向。
[1] 文莉,谢荷锋.大学文科类毕业论文质量影响因素的实证研究[J].黑龙江高教研究,2010(3):49-51.
[2] 王毅.论抄袭的认定[J].法商研究,1997(5):63-66.
[3] Salton G, Wong A, Yang C S. A Vector Space Model for Automatic Indexing[J]. Communications of the Association for Computing Machinery, 1975, 18(11): 613-620.
[4] 周茜,赵明生,扈旻.中文文本分类中的特征选择研究[J].中文信息学报,2004,18(3):17-23.
[5] 代劲,宋娟,胡峰.云模型与文本挖掘[M].北京:人民邮电出版社,2013:61-62.
[6] 金新政,李宗荣.理论信息学[M].武汉:华中科技大学出版社, 2014:129-132.
(责任编辑、校对:赵光峰)
The Research on the Similarity Measurement of Chinese Dissertation in Chinese Colleges and Universities
CAI Xiao-jun
(Library, Quanzhou Normal University, Quanzhou 362000, China)
This essay present a similarity detection technology to curb Chinese academic plagiarism seriously proposed based on word frequency, and design a corresponding computer detection algorithm. This essay firstly analyzes the standard format, the structure and the characteristics of the Chinese language. It presents a new data structure model based on tree-structure, which solves the problem of storage and operation of Chinese dissertation. In this essay, the similarity detection method based on vector space model was introduced, and the problem of calculating the weight value of vector space is improved by using the information entropy theory. At last, the essay presents a calculating method for the similarity detection by vector space model based on tree structure storage and computation.
similarity; tree- structure; entropy of information; vector space model
TP391
A
1009-9115(2016)02-0061-04
10.3969/j.issn.1009-9115.2016.02.018
泉州师范学院自选项目(2014KJ02)
2015-10-24
蔡晓君(1987-),女,福建泉州人,硕士研究生,助理实验师,研究方向为数据库技术。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
科教新报(2021年11期)2021-05-12
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
文苑(2018年21期)2018-11-15
新城乡(2017年8期)2017-08-26
电脑爱好者(2017年7期)2017-05-06
