
改进的GHSOM算法在文本聚类中的应用
2016-02-06 00:31陈林
电脑与电信 2016年5期
陈 林
(福建中医药大学人文与管理学院,福建 福州 350108)
改进的GHSOM算法在文本聚类中的应用
陈 林
(福建中医药大学人文与管理学院,福建 福州 350108)
信息时代,文本信息极其巨大。本文运用一种改进GHSOM算法进行文本聚类,该算法具有显著的文本聚类能力,能够将文本的相似性用多种手段表现。实验结果表明改进GHSOM算法整体上是优于SOM算法,它的先进性主要体现在更短的计算时间,并提供更丰富的有序性表达能力。
文本聚类;成长型分级自组织映射;SOM
1 引言
信息时代信息量极大,可以用“信息爆炸”来形容,对信息的查询、存取、处理都要前期对信息进行分类处理。在浩如烟海的信息中,文本信息占据的比重较大,同时很多其他的信息也可以转换成文本或者以文本的某种形式体现,而这些信息的处理可以归结为文本分类问题。如何从这些繁多的文本信息中找到满足用户的文本信息是文本挖掘的重要研究内容。利用文本聚类将文本进行自动分类是解决这类问题的重要手段。众多学者对文本聚类算法进行了研究,取得了很多成果[1~8]。文本聚类的基本思想就是通过计算文本间的相似度,将文本划分成若干个子类,使得同一子类中文本尽可能相似,而不同子类中的文本尽可能不同。文本聚类已得到广泛的应用,比如数据挖掘、信息检索等方面[4]。
本文针对文本聚类问题,提出一种改进的成长型分级自组织映射(Growing Hierarchical Self-organizing Map,GHSOM)算法处理[9~11]。实验显示改进的GHSOM算法具有明显的文本聚类能力,能够将文本的相似性用多种手段表现。将最相似的文本映射到同一神经元,同一映射相邻神经元、不同映射间由全局导向作用导致的相邻也都体现着一定程度的相似性。改进GHSOM算法整体上是优于SOM算法[12~15],它的先进性主要体现在更短的计算时间,并提供更丰富的有序性表达能力。
2 改进的成长型分级自组织映射(GHSOM)的原理及算法实现
2.1 GHSOM原理
GHSOM是多层分级结构,每一层包含数个独立的成长型SOM,通过增长规模来在一定详细程度上描述数据集。表示过分复杂数据的神经元被扩展,在下层形成一个小的成长型SOM,而表示一个相似数据集的单元将不需要进一步扩展。因此,通过它特有的结构与数据固有的分级结构,GHSOM的结果更加反映出它的适应性。
在图1中给出了GHSOM的典型结构。第一层映射提供输入数据中主要聚类的粗略组织。在第二层中的六个单独的SOM提供数据的更详细的表示。值得注意的是,由于数据结构的不同,映射的规模也不同。第0层为虚拟映射,为成长过程提供服务。
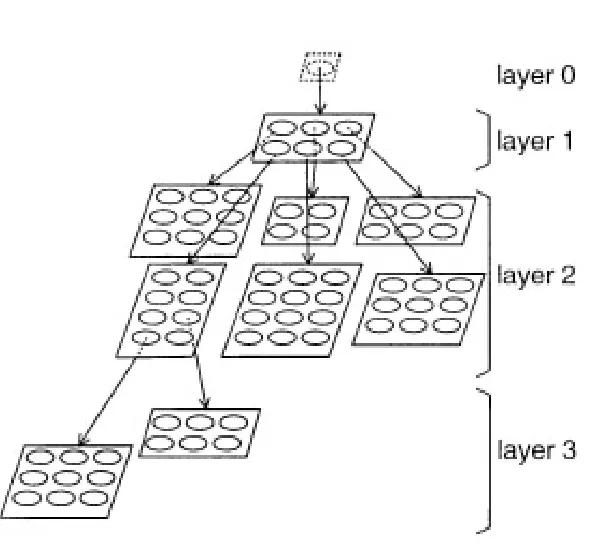
图1 GHSOM的典型结构
2.2 GHSOM核心算法流程
根据GHSOM的原理,设计了算法的主要步骤如下:
(1)计算第0层单元的量化误差qe,计算式如下:

其中,C0为映射到第0层单元上的输入向量集,即为全部向量集;m0代表输入向量的平均值。
(2)构建第1层映射为2*2个单元的SOM,采用K-means方法对向量权值进行初始化,并设置此网络为活动网络,活动网络层级数为1,训练数据集为全部数据集[11]。
(3)使用SOM训练算法训练活动网络。
(4)计算活动网络内所有神经元的量化误差qei,并根据平均量化误差MQE定义式:

计算当前网络的MQEm值。其中,m为活动网络所在层级数,qei出自数据投射到的映射单元的子集μ。
(5)验证级内终止条件:MQEm<τ1·qeu,其中,qeu是相应的上层单元的量化误差。条件成立时,转第7步。
(6)选取活动网络中qe值最大的单元,标记为错误单元e。然后按下式得到最相异的邻居d:d=argmax(‖ ‖me-mi), mi∈Ne,其中Νe是e的邻居集。在e和d之间插入一行新的单元,重置SOM参数,转第3步。
(7)对活动网络单元逐个验证全局终止条件:qei<τ2·qe0。发现不满足条件的单元时,计算该单元四个邻居的模型向量值,然后构建以此四个向量值为初始值的2*2新映射网络,并设置新建网络为活动网络,层级数加1。将映射在该单元上的数据作为训练数据,转第3步。
(8)完成一个活动网络的验证时,将此网络父亲单元所在网络设置为活动网络,层级数为1时结束。否则,层级数减1,转第7步。
上述算法步骤仅仅列出了GHSOM网络的构建和训练过程,不包含对数据的预处理以及输入输出操作。
2.3 GHSOM算法实现的改进
为了完善和改进GHSOM算法,以得到更好的性能,本文提出了以下改进方法:
(1)使用自定义的映射结构和相应的训练函数。本文中算法实现时GHSOM结构中每一个映射都是由一个SOM网络结构和其它相关信息组成的结构体表示的,这其中SOM网络结构包含了在GHSOM算法中并无用处的数据项和函数,使用自定义的映射结构,可以更贴近GHSOM算法中各个函数的需要,这样不但可以明确映射结构包含的数据项内容,有效防止计算中意外情况的发生(如未使用数据默认值对计算的影响),而且可以提供以下所有改进意见中对数据结构支持的要求。此处训练函数指的是一层映射的训练函数,即是用自定义的函数代替原算法实现中SOM的标准训练函数。采用自定义的函数的最大好处就是可以充分利用GHSOM的特点,加快训练时的计算速度。
(2)从算法流程的角度改进,可以将本文中采用的深度优先的结构构建过程改为广度优先的构建过程。这样处理需要对训练过程中的数据保存和内存使用进行合理的安排,否则算法将出现逻辑错误。改为广度优先的构建方法的一个最大优势在于提供继续计算功能,即首先设定全局成长参数为比较大的数值,使GHSOM成长过程在聚类精度较粗时暂时停止计算,经过人工检验不满意时,再将全局成长参数设置得更小一些,并以先前计算得到的GHSOM网络结构为初始继续进行计算。
(3)根据耗散结构论理论,系统有序结构形成过程中,“负熵流”起到的作用至关重要,而信息即可以看作一种典型的“负熵流”。如在上述GHSOM结构形成过程中,仅仅依靠了程序设置参数的信息和映射中每个神经元权值向量的量化误差信息。由此可以想到,只要在有序结构的形成过程中提供更多的信息,就可以得到有序程度更高的结构。举例来说,在上述GHSOM算法中,上层映射向下层映射转移的过程中,数据样本向量要进行删减,在算法中删减掉的特征值未发挥作用。仔细分析发现,这些删减掉的特征值实际是对上层映射起到重要作用的特征值,即具有这些特征的数据样本很可能属于删减这些特征的上层映射。如果将删减信息传递给上层映射,并利用此信息对以后的聚类提供导向性信息,则可以加快训练的速度。
3 输入文本数据及处理
程序训练使用的数据集为NSF(The National Science Foundation国家科学基金会)在基础研究领域授奖情况(1990-2013)的摘要描述文集。每一篇摘要保存为一个文件,这些文件以NSF标准的摘要格式存储。这些摘要文件集经过名为NSFAbst的文本自动分析器处理,输出四个文本文件。程序训练所采用的数据集为docwords.txt文件,其内容与格式如下:
docwords.txt=docid wordid freq (e.g.,1 9792 1)
其中,docid表示摘要文件的被处理时的编号;wordid表示关键词编号,编号从文件word.txt中获得;freq表示关键词在相应摘要中出现的次数。
算法中,程序用docid代表文本,在聚类效果检查时,使用idnsfid.txt文件查找得到文本的NSF编号,进行人工聚类效果检查。
GHSOM算法实现程序要求输入数据为一个二维数组,其中列向量表示一个个数据样本。原始的输入数据样本集不是满足这一要求的,因此要对输入数据进行处理以便满足程序要求,同时,应该尽量保证更好的训练效果。
本次实验所用的数据集文件docwords.txt刚好符合稀疏数组的形式;另外,本数据集每一文本中只包含数百单词,而作为关键词出现的单词数目高达数千并接近一万,最终以向量表示文本时,存在固有的稀疏特性。因此可以使用标准的稀疏数组生成函数来处理输入数据集文件,得到程序输入要求的fulldata.mat数据文件。
此时输入数据的向量表示包含了大量的特征值,即向量长度都很长。数据向量包含的特征值过多时,一方面会增大计算量,也就降低了计算速度;另一方面,由于在算法中每个特征值的权重是相同的,大量对聚类效果不大的特征值的存在,可能会干扰正常的聚类计算。因此,在输入数据作为训练数据对网络进行训练之前,应该先对输入数据的特征值进行选择。
在特征值的选择上,我们删减出现概率过高和过低的特征,因为这些特征对聚类的贡献相对比较小(从信息量角度)。
4 聚类效果及分析
4.1 文本聚类结果
在本文实验时,训练数据样本数目采用100个。由于数据样本中前14个存在噪音,因此修改程序,取编号101-200的样本。
删减样本向量长度时,采用的特征值概率上下限分别为:0.5和0.03,即仅仅保留在3篇摘要以上、50篇摘要以下出现的特征。经过删减后,输入数据样本转换为594*100的二维数组。成长参数采用默认值:层内成长参数τ2=0.15,全局成长参数τ1=0.03,训练后得到如图2的分级结构。整个计算过程用时大约为100秒至110秒。

图2 GHSOM算法得到的文本分级结构
计算得到的GHSOM结构共有三级,第一级为2*4映射,第二级多数为2*3映射,只有2个为2*2映射,第三级只在个别位置出现,绝大多数为2*2映射。整个GHSOM结构中共有70个叶神经元节点(即不再扩展子映射的节点),其中有10个节点为没有文本映射在上面的死节点。
为了能够与普通的SOM算法进行对比,在本次实验中,还编写了使用SOM标准算法解决此文本聚类问题的程序。
在使用SOM算法时,将SOM网络规模定义为7*10(根据GHSOM结果),并采用与GHSOM相同的迭代次数。SOM整个算法实现就是一系列的命令调用,本文将其全部保存于imsom.m文件。利用与GHSOM中函数visualmap()类似的方法,编写了SOM聚类结果的图表输出函数visualsom(),得到如图3的聚类结果图表。

图3 SOM算法得到的文本聚类
使用SOM算法进行训练时,使用与上面GHSOM算法时相同的训练数据,最终计算时间大约为160秒至170秒。
4.2 聚类效果分析
由于是进行的文本聚类计算,没有期望的分类对计算的结果进行定量的检验。本次实验在检验聚类结果时,将程序运行所用数据调出,由人工定性检查GHSOM网络的聚类效果。
在检验聚类结果之前,先规定每一映射中神经元的编号。由于分级结构的存在,低层级中神经元的编号中包含其父亲神经元的编号,不同层级间用→隔开。同一映射中,神经元的编号自左下向右上依次编号为1、2、……,如图4。

图4 神经元编号
按此编号方法,GHSOM分级结构中,左下角包含61的神经元编号为[1→1],包含52的神经元编号为[1→3→4],右上角包含99的神经元编号为[8→6→4]。
观察分级映射的左上角[7→4],有三个文本(14 15 21)聚类为一类,为2级映射神经元,这三篇摘要实际上是针对同一个奖项的摘要。此映射下面有四个3级映射神经元(由神经元[7→2]扩展得到),代表的四篇摘要均是关于大学内的计算机相关系统,但是具体内容有所差别。由此看来,尽管[7→4]、[7→2]两个神经元相邻,它们代表的摘要内容相似性却很差,造成这种情况的原因主要是因为[7→4]代表的内容过于特别,而没有与之相似的文本。
神经元[1→4]内容为北太平洋新生代板块模型和马尔代夫周围环境和沉积物研究,均属于地壳研究内容;它的右边神经元[1→5]内容为东太平洋的地震摄影术研究,也涉及地壳研究内容;它的上面神经元[3→1]则是关于大气层热量与紫外线研究,与地壳研究相关性不大。由此可以看出,同一映射下相邻关系邻近度要高于全局导向的邻近度。神经元[1→1]内容为海洋生态系统中捕食者间的相互作用研究,它的右侧[1→2]内容为海洋漂流物研究和海洋表面水域的研究,这两个神经元间内容相似性较强,但是与神经元[1→4]的相似性仅仅体现在研究领域中均出现了太平洋。由此可以看出,GHSOM算法也可能导致专断的划分,即将两个相似程度不高的两类强行聚类成相邻关系。
神经元[4]扩展成的映射包含密度最大的文本,神经元[4→1]包括的内容有DNA变异研究、几何变形容忍、机械加工容忍、机器人动作计划,这四篇文章虽然研究领域各异,但主要内容均是从几何学出发,说明聚类算法是一种按内容分类的方法。向右方,神经元[4→2→1]为机器人任务分派算法,神经元[4→2→3]为随机网络产量优化算法,这都是数学问题。向上方,神经元[4→3]是关于物理学中表面现象的研究,再向上,神经元[4→5]都是几何学在特殊领域中的应用。而它们的右边,有的文本聚类的结果并不理想,文本37、78都涉及了地壳的内容,即与主要研究地壳的左下角神经元相距较远。因此,GHSOM算法依然存在相似聚类间联系丢失的问题。
综上所述,GHSOM算法具有明显的文本聚类能力,能够将文本的相似性用多种手段表现。将最相似的文本映射到同一神经元,同一映射相邻神经元、不同映射间由全局导向作用导致的相邻也都体现着一定程度的相似性。不同级别的映射也体现了不同程度的相似性,低级别的相邻神经元体现了更高的相似性,如3级神经元相邻的相似性要高于2级相邻。GHSOM算法也存在问题,首先是对于独特的文本,算法会专断地将其与某类文本相邻。这个问题更可能出现在少量文本聚类问题中,因为在海量文本中不会出现“独特”的文本。其次,GHSOM表现相似性能力只能以树型方式,比起网络状还有一定差距,因此会造成部分子聚类间联系无法体现。
与SOM算法对比,SOM算法在已经知道合适的网络(70)的情况下,它的计算时间也要长于GHSOM算法,并且产生了更多的死节点(17),因此在计算性能上,GHSOM算法要优于SOM。
聚类效果方面,SOM表现相似性的手段比GHSOM少,只有一种相邻性来体现。SOM算法中,文本35、40、41、50的分别比较接近的神经元中,并且也与文本23、53、66映射的神经元相邻,体现了GHSOM中神经元[7→1]、[7→2]对相似性的体现,但是,SOM算法中相似级别只有一种,而GHSOM中在此处的相似级别有两种。
关于地壳相关文本,SOM算法将原来GHSOM算法中[1→4]和[3→1]映射到了右下角,而对于GHSOM中海洋相关的研究[1→1]和[1→2]的文本也专断的进行了映射。对于GHSOM算法中密度最大的文本映射,SOM算法将这些文本映射在了网络的中部偏右的位置,特别注意的是,在GHSOM算法中未能体现出来的文本37、78与地壳研究相关性,在SOM中得到了一定的体现,这两个文本映射在了接近右下角(地壳研究内容)的位置。出现这种情况,并不能说明SOM有更好的有序性表达能力,只是算法中随机性的一种体现。
因此,GHSOM算法整体上是优于SOM算法的,它的先进性主要体现在更短的计算时间,并提供更丰富的有序性表达能力。
5 结束语
实现的改进GHSOM算法在文本聚类领域中的应用体现了自组织性:在毫无教师信号的前提下,自动将文本分成了不同的类别,并用不同映射神经元的相邻关系显示了文本的相似性。文本的相似性表现手段也是多样的:映射到同一神经元的文本具有最高的相似性,同一映射神经元的相邻、不同映射间由全局导向作用导致的相邻也都体现了一定程度的相似性;不同级别映射神经元相邻也体现了不同程度的相似性,低级别的相邻神经元体现了更高的相似性,如3级神经元相邻的相似性要高于2级相邻。改进GHSOM算法整体上是优于SOM算法,它的先进性主要体现在更短的计算时间,并提供更丰富的有序性表达能力。
[1]MAHDAVI M,ABOLHASSANI H.Harmony K-means algorithm for document clustering[J].Data Mining and Knowledge Discovery,2009,18(3):370-391.
[2]徐森,卢志茂,顾国昌.解决文本聚类集成问题的两个谱算法[J].自动化学报,2009,35(7):997-1002.
[3]ZHENG Hai-tao,KANG B Y,KIM H G.Exploiting noun phrases and semantic relationships for text document clustering[J].Information Sciences,2009,179(13):2249-2262.
[4]赵卫中,马慧芳,李志清,等.一种结合主动学习的半监督文档聚类算法[J].软件学报,2012,23(6):1486-1499.
[5]BASAVARAJU M,PRABHAKAR R.A novel method of spam mail detection using text based clustering approach[J].International Journal of Computer Applications,2010,5(4):15-25.
[6]卜东波,白硕,李国杰.文本聚类中权重计算的对偶性策略[J].软件学报,2002,13(11):2083-2090.
[7]赵军,金千里,徐波.面向文本检索的语义计算[J].计算机学报,2005,28(12):2068-2078.
[8]管仁初,裴志利,时小虎,等.权吸引子传播算法及其在文本聚类中的应用[J].计算机研究与发展,2010,47(10):1733-1740.
[9]Rauber A,Merkl D,Dittenbach M.The Growing Hierarchical Self-organizing Map:Exploratory Analysis of High-dimensional Data[J].IEEE Transactions on Neural Networks,2002,13(6):1331-1341.
[10]Yen G G,Wu Zheng.Ranked centroid projection:A data visualization approach with self-organizing maps[J].IEEE Transactions on Neural Networks,2008,19(2):245-259.
[11]Alahakoon D,Halgarmuge S K,Srinivasan B.Dynamic self-organizing maps with controlled growth for knowledge discovery[J].IEEE Transactions on Neural Network,2000,11(3):601-614.
[12]谭长贵,动态平衡态势论研究——一种自组织系统有序演化新范式,电子科技大学出版社,2004.
[13]Kohonen T.Self-organizing Maps[M].Berlin:Springer,2001.
[14]Kohonen T,Ritter H.Self-organizing semantic maps[J].Biological Cybernetics,1989,61(4):241-254.
[15]Yen G G,Wu Zheng.Ranked centroid projection:A data visualization approach with self-organizing maps[J].IEEE Transactions on Neural Networks,2008,19(2):245-259.
An Improved GHSOM Algorithm for Text Clustering
Chen Lin
(Fujian University of Traditional Chinese Medicine,Fuzhou 350108,Fujian)
In the information era,the text information is very great.An improved GHSOM algorithm for text clustering is presented in this paper.This algorithm which has obvious text clustering ability can use a variety of means to show the similarity of text.The experimental results show that the improved GHSOM algorithm is better than SOM algorithm on the whole,and its advanced nature is mainly reflected in the shorter computation time and more expression.
text clustering;growing hierarchical self-organizing map;SOM
TP181
A
1008-6609(2016)05-0057-05
陈林,男,福建福州人,硕士,助教,研究方向:计算机应用与软件,信息管理。
猜你喜欢
数学物理学报(2022年5期)2022-10-09
河北画报(2020年8期)2020-10-27
铁道通信信号(2019年6期)2019-10-08
现代装饰(2018年5期)2018-05-26
雷达学报(2017年6期)2017-03-26
浙江大学学报(工学版)(2016年2期)2016-06-05
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
中国生化药物杂志(2015年4期)2015-07-07
弹箭与制导学报(2015年1期)2015-03-11
