
基于云计算环境的Web数据挖掘算法分析
2016-02-06 00:31姜学文
电脑与电信 2016年5期
姜学文
(鄂州职业大学培训鉴定中心,湖北 鄂州 436000)
基于云计算环境的Web数据挖掘算法分析
姜学文
(鄂州职业大学培训鉴定中心,湖北 鄂州 436000)
本文对Web数据挖掘算法分析进行了研究,首先简述了云计算关键技术,提出了如何在海量信息中提取出有用信息的重要性,其次指出了在云计算环境中进行Web数据挖掘提供更多数据挖掘的解决方案,最后对云计算环境下Web数据挖掘常用算法进行了探讨。
云计算;Web;数据挖掘;算法
1 引言
在Web网页中存储了众多重要的数据,如何在海量Web数据中挖掘到有用信息至关重要。在互联网迅速发展的背景下,Web数据信息呈现大爆炸的趋势,网络环境也日趋复杂,传统的Web数据挖掘算法难以实现有效的数据挖掘。云计算能够实现海量数据的处理和计算,可以为Web数据挖掘提供多种解决方案。
2 云计算概述
2.1 云计算概念
云计算技术是在分布式计算、并行计算以及网络计算基础上新提出的一种共享型编程结构方法。云计算以互联网为依托,能够为用户提供硬件服务、软件服务、存储服务和计算服务,用户可以利用远程服务器来根据任务需求访问计算机存储系统,可以有效提升计算机软硬件资源的利用效率。云计算是网络技术和传统计算机计算方法结合的产物,其扩展性较强,能够实现对海量数据的有效处理,而在网络迅速发展的背景下,Web数据量逐渐增多,这就给Web数据挖掘计算带来了困难,而在云计算环境下,Web数据挖掘计算复杂的问题可以迎刃而解。
2.2 云计算关键技术
2.2.1 分布式存储技术
在云计算环境中,通过分布式存储方式来进行数据存储,通过冗余存储能够有效保证数据存储的可靠性,通过软件的可靠性来弥补硬件存在的不足,这就有效保证了数据存储的经济性。
2.2.2 数据管理技术
云计算环境中需要对大数据集进行分析处理,以此来保证服务的高效性,这就对数据管理提出了更高的要求,云计算的数据管理技术能够有效处理海量数据,能够实现在海量数据中寻找到特定数据的功能。
2.2.3 虚拟化技术
云计算虚拟化技术隔离应用系统的硬件、网络、软件、数据等各个层面,保证架构的动态化,实现对计算资源的集中管理和调配,其不仅能够对物力资源进行管理,还能够对虚拟资源进行管理,有效提升了结构弹性,降低了计算资源管理成本,对于保证服务质量有着重要的意义[1]。
2.2.4 并行编程技术
云计算资源的高效利用是保证用户更方便享受云计算服务的基础,这就对编程模型提出了更高的要求,编程模型要能够在后台进行并行执行,实现后台对任务进行调度,且编程模型要对编程人员和用户透明化。云计算采用编程模式为MapReduce,实现对任务的划分,其编程主要分为两个步骤,分别是Map步骤和Reduce步骤,这两个步骤能够将划分的子任务分配到系统大量的计算节点中,这就实现了对任务的有效调度和分配,保证了云计算资源的高效利用,从而能够提供给用户更加方便、快捷的云计算服务。
3 Web数据挖掘分析
3.1 Web数据挖掘概述
数据挖掘就是从海量信息中提取对人们有用信息的过程,这些有用的信息是隐含的,可能是用户事先不知道的,有用信息的形式是多样化的,可能是概念信息、规则信息,也可能是规律信息、模式信息。数据挖掘过程中涉及到对数据及数据关系的考察和建模,涉及到许多数据或数据关系的计算,将大容量数据转化为有用信息[2]。
Web数据挖掘是指的是从文档结构和使用结构中挖掘有用信息的过程,其涉及到的技术涵盖多个领域,例如数据库领域、统计学领域、神经网络学习领域等。
3.2 Web数据特点
Web数据有着自身的特点,具体来说体现在以下几个方面:①异构数据库环境:在Web中,每一个站点都可能产生数据,都相当于一个数据源,这些数据源都是异构的,其信息和组织都存在着差异性,从而构成了异构数据库环境;②分布式特点:Web以互联网为基础,其页面能够分布在世界各地的Web服务器之上,这就决定了数据源的分布式特点;③半结构化:Web上的数据异常复杂,没有一个统一的模型来对数据进行描述,其结构化不完全,常常呈现出半结构化数据的形式化[3];④动态性:Web各个站点的动态性较强,每一个站点的链接信息、访问记录信息等信息的更新是十分快速和频繁的;⑤复杂性:Web包含的数据和信息形式是多样的、复杂的,有文本信息、图表信息、图像信息、超文本信息、音频信息、视频信息等多种复杂的多媒体数据信息。
3.3 Web数据挖掘分类
3.3.1 内容挖掘
Web内容挖掘就是从大量的Web页面、页面链接所指向内容及数据库中数据发现并提取有用信息的过程。Web内容挖掘可以分为文本挖掘和多媒体挖掘两种形式,这两种内容挖掘形式在数据信息提取特征上有着一定的差异性。而从具体的挖掘方法上来看,Web内容挖掘主要可以分为信息抽取方法和数据库方法,数据库方法能够从数据库中数据来搜索信息、发现信息,通过信息抽取方法能够将数据库中的有用信息进行抽取,从而实现有用数据的挖掘。
3.3.2 结构挖掘
Web结构挖掘就是从Web结构中挖掘有用信息的过程,Web结构主要可以分为组织结构、文档结构以及Web链接关系结构等,具体来说,在分析Web结构的过程中,能够对页面结构和链接关系进行分析,在二者之间能够发现隐含的有用模式,同时可以实现对链接以及链接页面的分类,从中发现并挖掘出权威页面,这就是Web结构挖掘的主要过程。
3.3.3 使用挖掘
Web使用挖掘指的是对用户访问模式挖掘的过程,其依赖于数据挖掘技术,能够有效提升网络信息服务质量,对于改进Web服务器性能也有着重要的作用。
4 基于云计算环境的Web数据挖掘算法
近年来,互联网技术的发展迅猛,在Web结构信息中隐藏着众多的信息,这就需要寻找高效率的算法来从海量的信息中寻找并选择有效的信息,下面本文简要介绍两种云计算环境下Web数据挖掘的常用算法。
4.1 PageRank算法
PageRank算法是拉里·佩奇提出的Web结构挖掘经典算法,在谷歌搜索引擎中有着重要的应用,且取得了重大的成果。PageRank算法的核心思想是对网页进行评价,之后对每一个网页进行合理的权值分配,这样每一个网页都有着不同的权值,最后根据权值的大小和高低来对网页进行排序,这样网页就能够根据权值的高低确定一个显示顺序,权值越高的网页越优先被显示出来。在确定权值的过程中,入链页面和出链页面共同决定权值,具体来说,其算法可以进行如下描述:①网页之间的权值可以通过入链网页的方式进行传递,这里的权值指的就是PageRank值,也就是说,如果一个网页的入链页面越多,则此网页的权值就越大,说明此网页的重要性越大[4];②如果一个权值较大的网页是(设为网页i)另一个网页(设为网页j)的入链网页,那么则说明网页j比网页i的权值更大,网页j的重要性更大。
网页的PageRank值不仅受到其入链网页PageRank值的影响,同时也会受到其出链网页数目的影响,如果一个网页是其他多个网页的入链网页,则其他多个网页会平均分配这个网页的PageRank值。其初始定义公式如下:
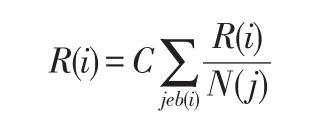
在公式中,R(i)表示i网页的PageRank值,R(j)表示j网页的PageRank值,b(i)表示所有i的入链网页,N(j)表示j网页的超链接数,而C则是常数项。
互联网超链接结构有着一定的特殊性,其幂法的收敛受到封闭情况的影响,如果出现封闭,则幂法的收敛将受到限制,不能收敛,其中封闭指的是网页之间互相为对方的入链网页,但不是其他的入链网页,这样一来幂法将不会收敛,在进行网页PageRank值计算的过程中会出现不断累加的情况,结果收敛受到限制,在点击网页的过程中,如果沿着链接点进行点击,则不会转换到其他网页中,而是在互为入链网页的几个网页中徘徊,这就对PageRank值算法提出了更高的要求,为了避免这种情况出现,需要对上述公式进行改进,增加一个逃脱因子,以此来保证幂法能够收敛,保证在点击网页的过程中能够跳转到除了互为入链网页的几个网页之外的其他网页中[5]。改进之后的公式如下:
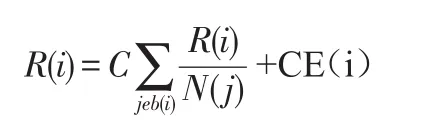
4.2 MapReduce算法
从本质上来讲,MapReduce是在云计算环境下的归并算法,是一种编程的模型,在计算的过程中应用了函数式的编程语言,在编程的过程中,编程人员能够很方便地将自己编写的程序在分布式系统中运行,计算过程主要分为两个步骤:第一个步骤是映射计算过程,第二个步骤是归并计算过程,实现对数据信息的拆分,数据信息拆分之后会转化为键值,之后就能够实现对数据的传递。而在数据信息传递的过程中,涉及到系统的架构,具体来说如下:
4.2.1 服务层
服务层对应着客户端,其主要功能是对客户端的任务要求进行接收,并将数据挖掘结果传递给客户端。
4.2.2 控制层
控制层对应着主控节点,在Web数据挖掘的过程中,主控节点控制所有的挖掘,控制层是整个数据挖掘系统最为关键的部分,客户端的任务要求经过服务层来传递给控制层的主控节点,主控节点根据具体的任务要求来选择数据挖掘算法,选择的算法会由算法节点发送至存储原数据的存储器中,在数据挖掘完成之后,计算结果会传送至客户端。
4.2.3 数据挖掘层
数据挖掘层对应着算法节点和服务节点,各种云计算环境下的数据挖掘算法都存储在数据挖掘层中,主控节点就是在数据挖掘层中来选择合适算法的。
4.2.4 存储层
存储层对应着存储节点,Web会收集到各种类型的文件,而存储层的主要功能就是将这些文件进行解析,从而变为XML文件,系统的瘫痪会导致数据的瘫痪,为了避免数据瘫痪所造成的数据丢失,存储层还有着对XML文件复制的功能[6]。客户端原始数据以及挖掘计算后的结果都存储在存储层中,如果系统出现崩溃等问题,数据也能够在缓存中存储,能够有效地实现文件恢复,避免了数据丢失。
5 结语
随着互联网技术的快速发展,Web数据信息量日渐增多,Web网页中存储着大量的重要数据信息,如何在海量信息中提取出有用的信息至关重要,这就对Web数据挖掘提出了更高的要求。PageRank算法适用于统计Web文档中的字段出现次数,计算网站的平均响应时间;MapReduce算法适用于根据关键字key构建网站的索引排序。这两个算法是Web数据挖掘算法中常用的算法,可以帮助使用者在云环境中更快地查找到相应的数据信息。
[1]张鑫.WEB数据挖掘在云计算环境下的研究[J].数字技术与应用,2013(03):92.
[2]王勃,徐静.基于云计算的Web数据挖掘Map/Reduce算法的研究[J].计算机与数字工程,2014(07):1157-1159+1164.
[3]李悦,高晶,雷鸣.基于云计算技术的Web数据挖掘的算法研究[J].科技资讯,2014(18):17.
[4]黄佳倩,何明昌,盛丽芬,等.基于云计算的移动学习平台[J].2015(3):40-43.
[5]刘辉.基于云计算的网络学习资源共建共享关键技术研究[J].电脑与电信,2015(6):19-20.
Analysis of Web Data MiningAlgorithm Based on cloud computing
Jiang Xuewen
(Ezhou Polytechnic,Ezhou 436000,Hubei)
In this paper the Web data mining analysis algorithm is studied.At first,this paper introduces the cloud computing key technology,proposed how the mass of information extract useful information of importance,followed by that of the in cloud computing environment for Web data mining provides more data mining solutions.Finally,on cloud computing environment Web Data Mining algorithms commonly used are discussed.
cloud computing;Web;data mining;algorithm
TP311.13
A
1008-6609(2016)05-0051-03
姜学文,男,湖北鄂州人,大学本科,讲师,研究方向:软件工程、数据库等。
猜你喜欢
消费电子(2022年7期)2022-10-31
北京航空航天大学学报(2022年8期)2022-08-31
成都信息工程大学学报(2022年3期)2022-07-21
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01
当代陕西(2019年14期)2019-08-26
电子制作(2017年20期)2017-04-26
自动化学报(2017年7期)2017-04-18
现代电子技术(2016年15期)2016-12-01
中学数学杂志(初中版)(2016年5期)2016-11-01
信息通信技术(2015年6期)2015-12-26
