
采用MapReduce模型的甚长基线干涉测量并行处理方法
2015-12-26 08:51田斌何强王佳郑雨西
西安交通大学学报 2015年4期
田斌,何强,王佳,郑雨西
(1.西安交通大学电子与信息工程学院,710049,西安;2.西安卫星测控中心,710043,西安)
采用MapReduce模型的甚长基线干涉测量并行处理方法
田斌1,2,何强2,王佳2,郑雨西2
(1.西安交通大学电子与信息工程学院,710049,西安;2.西安卫星测控中心,710043,西安)
针对传统甚长基线干涉测量(very long baseline interferometry,VLBI)并行处理方法存在逻辑复杂、数据存储和计算扩展性较差等缺点,基于MapReduce模型设计了一种VLBI观测数据相关的并行处理方法。该方法采用模型周期作为数据并行处理基本单元,构建数据关联算法分割观测数据使各台站同一模型周期数据对齐到同一波前,设计实现数据相关计算的Map过程,使用Reduce对各模型周期结果进行综合处理以得到最终结果。实验结果表明:该方法在积分周期包含的模型周期数量大于节点CPU核数时性能比传统方式低25%左右,在积分周期包含的模型周期数量小于节点CPU核数时通常能提供更高的计算效率,并且能简化VLBI并行相关处理的复杂度,具有更好的数据存储和计算可扩展性。
甚长基线干涉测量;数据相关处理;并行处理;MapReduce模型
甚长基线干涉测量(very long baseline interferometry,VLBI)技术利用分布在不同地理位置的两个或多个天线分别接收记录同一空间目标发射的信号,经相关处理后获取目标相对两个测站天线的时延和时延率观测量,转化后得到目标视向相对于基线向量的角位置信息。VLBI自20世纪60年代问世以来,在射电天文大地测量等领域得到了广泛的应用,特别是在此基础上发展起来的差分单向测距测速、双差分单向测距测速和同波束干涉测量等干涉测量技术,已成为深空探测器精密导航定位的主要技术手段,为各类深空探测任务的成功实施提供了可靠的技术保障。
近年来,随着观测台站数目的增加,以及观测带宽的日益提高,对VLBI数据处理的要求越来越高,如何高速处理大量观测数据是一个迫切需要解决的问题。VLBI处理的核心是数据相关处理,它是一种能够高度并行的应用,具有数据密集和计算密集的双重特征。首先,VLBI观测设备采样率很高,产生的数据量非常大。当前中国VLBI网有5个台站,每个台站8个通道,单个通道最大带宽为8 MHz,采用2 bit量化时,其数据速率可达16 MB/s,5台站总数据速率为80 MB/s。其次,相关处理使用快速傅里叶变换(fast Fourier transformation, FFT)将产生大量中间结果数据,例如对于通道数为C的M点输入数据,在Linux 64位操作系统中使用双精度复数数据类型,计算后的结果长度将扩展至原始数据的16MC倍。最后,相关处理中的条纹旋转、FFT运算和叉乘等均涉及大量浮点运算,需要耗费很多CPU计算时间。对N台站、M点数据的FFT变换,需要执行MN(5Nlog2M+2N+6.5)[1]次浮点运算。事实上,由于还需进行大量其他运算,实际计算量远比该值大。
VLBI最初采用专用硬件处理机,但是随着通用计算机性能的提高,使用软件相关处理机处理数据成为当前流行的趋势,DiFX[2]、Softc[3]、K5[4]和NRC[5]等软件相关处理机就是典型代表。这些软件相关处理机大都将处理数据集中存储在存储服务器上,采用消息传递接口(message passing intorface,MPI)或MPI+OpenMP等经典并行计算模式,能较好地进行数据并行处理工作,但是存在程序结构复杂、数据存储和计算扩展性较差等缺点。
MapReduce是近年来随着云计算兴起的一种新型并行计算模型,被广泛应用于海量数据的高速处理。与传统并行方法相比,MapReduce通过采用一种称为无依赖并行和串行同步的计算抽象,并在内部提供数据划分、并行任务调度、通信、容错和负载均衡等机制,实现了程序的自动并行处理,极大地降低了开发人员的难度,具有高可扩展性和高度并行性。本文基于云计算模型MapReduce提出和设计了一种称为MR-VLBI的并行相关处理方法。
1 VLBI相关处理原理
VLBI的几何原理如图1所示[6-7]。假设空间目标发射的射频信号为
s(t)=sB(t)ej2πφt
(1)
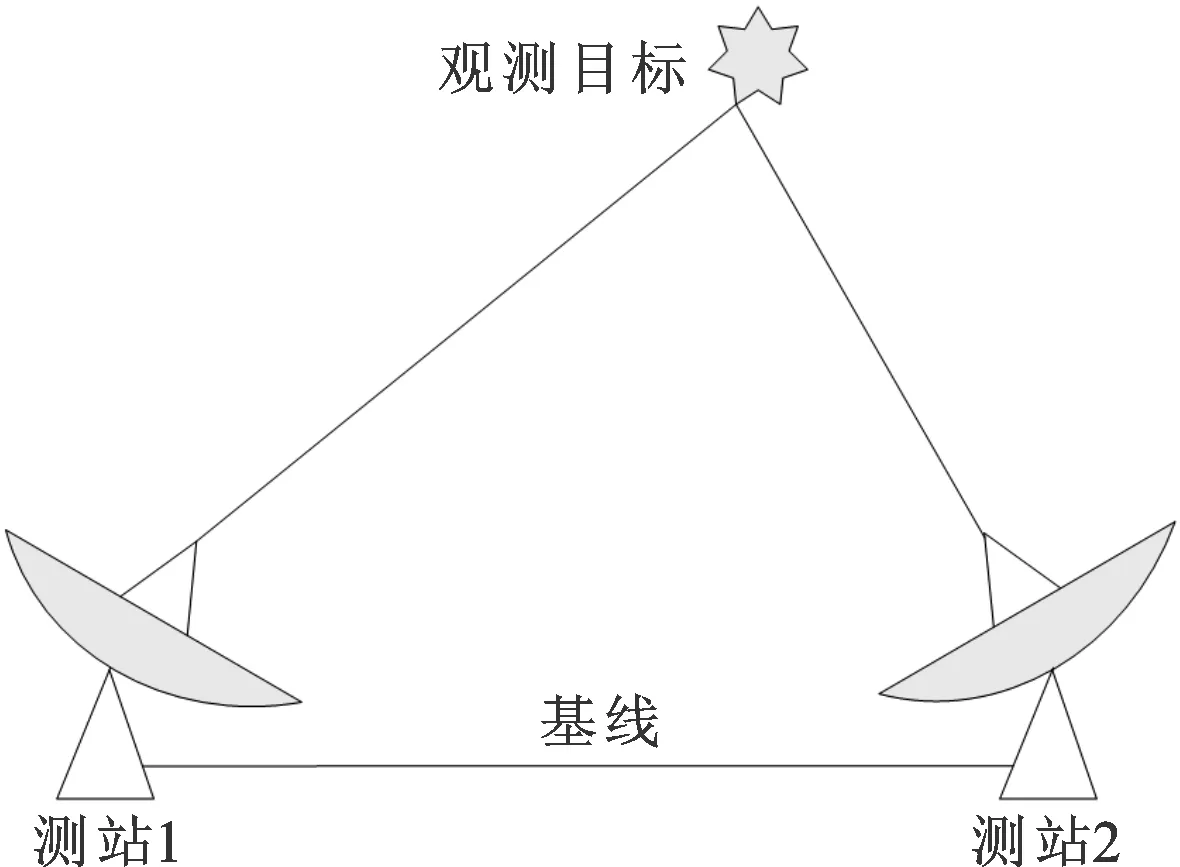
图1 VLBI几何原理图
式中:sB(t)为带宽为B的基带信号;φ为射频频率。同一基线的两测站同步接收的信号分别为(以测站1为参考)
s1(t)=sB(t)
(2)
s2(t)=sB(t-τg(t))ej2πf(t-τg(t))
(3)
式中:两测站本振频率都为f;τg(t)为目标相对两测站的时延差,是数据处理时提取的观测量。
按照进行傅里叶变换和乘法运算的顺序,VLBI数据相关处理机被分为FX和XF两种类型。XF型先按一条基线的两个测站的观测数据两两相乘,获得互相关函数及干涉条纹,然后再进行傅里叶变换得到干涉条纹的功率谱;FX型是先对测站观测数据进行傅里叶变换,然后再按各基线的两测站数据进行相乘,获得干涉条纹的功率谱[7]。虽然算法流程不一致,但是两者获得的最终结果是相同的。
图2显示了FX相关处理机的计算流程,采集信号vi(t)先后经历整数比特时延补偿、条纹旋转、FFT、小数比特补偿和互谱累加5个环节的处理。
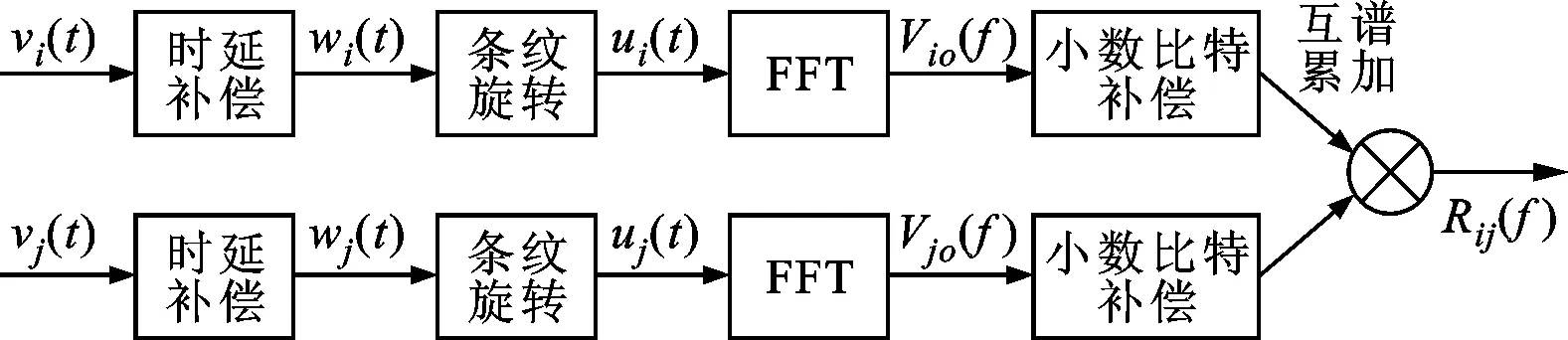
图2 FX型相关处理机的计算流程
整数比特时延补偿利用先验轨道预报模型对原始数据进行补偿,目的是将两路信号对准到同一波前,它是粗补偿,只精确到采样时间间隔(整数比特);条纹旋转的目的是降低条纹频率,消除相位因子;FFT的目的是对输入的两路信号进行FFT运算,将其从时域变换到频域;小数比特补偿是精补偿,完成整数比特补偿后剩余的时间误差补偿;互谱累加积分是为了提高信噪比,从而提高后续残余时延、时延率提取的精度。
2 MR-VLBI算法设计
2.1 MR-VLBI处理框架
MapReduce的基本思想是将待处理的数据集分割成多个不相关的子集,每个子集分别由一个Map独立操作以产生中间结果,然后这些中间结果通过Reduce归约合并成最终结果[8]。Map和Reduce的模型分别为Map(k1,v1)→list(k2,v2)和Reduce(k2,list(v2))→list(v2)。其中,Map以键值对(k1,v1)为输入,其操作后将产生一系列中间键值对list(k2,v2),该结果经内部排序会产生Reduce的输入list(k2,list(v2)),Reduce函数合并所有具有相同key的list(v2)输出最后的结果。
从并行方法的角度看,VLBI相关处理属于数据并行。按照数据分解方式的不同,VLBI并行方式可分为基线并行、测站并行、通道并行和时间并行4类[9]。基线并行按照基线对观测数据进行划分,设置与基线数目相同的计算节点,每个节点只负责处理指定基线的数据;测站并行按照测站对观测数据进行划分,针对每个测站设立一个FFT计算节点,首先由它负责对该站观测数据进行FFT,然后再将变换后的结果传递给相关节点进行互谱计算;通道并行按照通道对观测数据进行划分,每个计算节点仅负责处理某一通道所有测站观测数据,不同通道数据由不同相关节点处理;时间并行按照时间对观测数据进行划分,每个计算节点负责处理某一时段的数据,各时间片数据由不同的节点处理。
这些模式都存在一些问题,例如基线并行会产生大量的数据存储冗余和计算冗余,测站并行会因在节点间交换FFT产生的临时结果而导致产生大量的数据传输,通道并行的调度逻辑则非常复杂。这4种类型都可映射到MapReduce模型中,但综合比较起来,时间并行最为理想,它不会产生计算冗余,也不要求大量的数据交换。MR-VLBI采用了这种模式,其处理框架如图3所示,包括数据分割、相关计算和结果综合3个步骤。
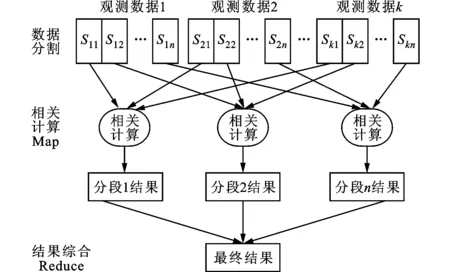
图3 MR-VLBI处理框架
数据分割按照时间将各台站的观测数据划分成不相关的片段,奠定并行计算的基础。当分割完成后,各台站相同模型周期的数据将被输入到同一个相关计算处理单元,也即相关计算Map,进行观测信号的相关处理,计算将产生各基线在该模型周期上的分段结果。最后,所有分段计算输出结果输入到结果综合Reduce,进行综合处理产生最终结果。
2.2 数据分割
对于MR-VLBI,数据分段可以采用积分周期、模型周期或FFT周期为划分单元。积分周期是相关处理中进行积分运算的最小时间段,模型周期是对时延模型进行校正的最小时间间隔,FFT周期是进行FFT计算的数据长度。模型周期长度=模型周期时间×采样频率,而积分周期则包含积分周期时间/模型周期时间个模型周期。从提高并行度、降低通信开销和实现负载均衡的角度考虑,MR-VLBI采用模型周期为数据分割单元。
VLBI相关处理以同一时刻各测站观测数据为输入,但是由于时延的存在,各站采集到的数据并没有对齐到同一波前,使得各测站数据的各个模型周期并不是起始于文件中的同一位置,因而它不适合采用MapReduce中通常的按照数据长度连续分割的方法,需要自定义数据分割方法。
MR-VLBI数据分割需要在各站观测数据文件中对齐同一模型周期的起始位置。一个模型周期对应的数据可由四元组
Ocurr=(δcurr-δlast)SB-Olast
Olast=Ocurr+L
(4)
式中:δcurr和δlast分别为当前和上一模型周期整数比特时延补偿值;S为信号采样频率;B为比特量化位数;B和S都是设备观测参数。
一路信号在某个模型周期的时延补偿为
τ=α0+α1τ1+α2τ2+…
(5)
式中:αi(i=0,1,2,…,r)为数据处理前给定的时间延迟模型的多项式系数。可将τ分为整数比特部分τ1和小数比特部分τ2两部分
τ=τ1+τ2
τ1=NT
τ2=τ-[τ1×S]/S
(6)
式中:T=1/S为采样时间间隔;N表示整数。
根据式(5)和式(6)可计算出i和j两路输入信号的整数比特补偿值τi1和τj1。按照补偿信号路数的不同,时延补偿可分为基线时延和地心时延两类。基线时延只对两路输入信号中的一路进行补偿,在计算偏移位置时,取δi=0和δj=τj1-τi1。地心时延对两路信号都进行时延补偿,令δi=τi1和δj=τj1。
在分割完成后,待处理数据将转换成包含M×N个分片的集合{Sij|i∈M,j∈N},M为测站数量,N为模型周期数量。该集合中同一模型周期的数据分片形成键值对
2.3 相关计算Map
相关计算Map用于实现各台站数据的相关处理,它按照条纹旋转、FFT、小数比特补偿和互谱累加积分的顺序对输入数据进行处理。
对信号进行条纹旋转,就是用理论条纹相位θ(t)进行补偿,即
u(t)=w(t)e-jθ(t)
θ(t)=2πfδ
(7)
式中:f为本振频率。对于基线时延,在对第i路信号进行时延补偿后,只需对另一路(第j路)信号使用整数比特补偿时延δj进行条纹旋转。对于地心时延模式,两路信号均需进行条纹旋转操作。
对输入信号u(t)使用FFT将其从时域变换到频域,得到频谱表示为
(8)
实际运算中,FFT采用的是有限长度的离散数据。输入信号ui(t)和uj(t)分别以FFT点数为一个单元进行FFT计算,FFT点数根据计算要求的频率分辨率来确定。
由于信号是以数字信号记录的,小数比特时延补偿无法在时域内用类似整数比特数据移位的方法完成,其处理将在频域内完成
V(f)=V0(f)ejfτ2
(9)
互谱累加积分操作将第i路信号每个数据单元的复数数据点与第j路信号相应的数据单元的共轭复数数据点按照下式两两对应相乘
(10)
在相关计算完成后,将输出结果键值对
2.4 结果综合Reduce
结果综合Reduce以一个积分周期的所有模型周期计算结果集合
3 性能测试
本文在hadoop 2.4.1基础上开发了MR-VLBI程序,相关计算Map和结果综合Reduce模块采用C++实现,其余部分使用Java语言编写。此外,本文还开发了串行及基于文献[9]MPI+Pthreads方法的并行VLBI处理程序(根据该方法实现了并行执行逻辑,但是采用的数据处理算法与串行和MR-VLBI相同)。
本文实验环境由10个Slave节点组成,每节点配置4路AMD Opteron 6212 @ 2.70 GHz CPU,64 GB内存,1 TB硬盘,单节点具有32核,总共320核。在此平台上,当将数据复制参数设为2时,可提供5 TB的存储空间。即使将该参数增大,例如设置为5(考虑到数据冗余和可靠性等因素,很少有实际系统将该参数设置大于5),也可提供2 TB的存储空间。
在相同参数设置下,使用MR-VLBI、串行和MPI+Pthreads对同一观测数据进行处理得到的结果完全相同。图4给出了使用MR-VLBI处理嫦娥三号任务2013-12-04T09:00对标校射电源1226+023观测数据的残余时延结果,其方差为0.025。该数据由佳木斯—喀什基线组成,时长30 min,数据总大小26.8 GB。计算采用积分周期59.965 44 s,模型周期0.156 16 s。
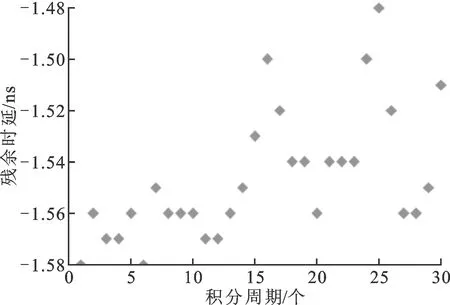
图4 残余时延处理结果
图5给出了在上述参数下串行程序、MR-VLBI和MPI+Pthreads方式的平均运行时间。其中,后两者都使用了10个计算节点。相对于串行程序,MR-VLBI的效率有很大提升,其加速比达到了100.5。但是,与MPI+Pthreads方式相比,其计算效率有一定差距,运行时间为后者的1.25倍左右。通过分析日志,其效率较差的原因在于MR-VLBI的任务调度开销较高。系统将所有Map任务调度完毕需要花费30 s左右,但是对那些较早调度运行的Map任务,其执行时间与MPI+Pthreads方式相差无几。
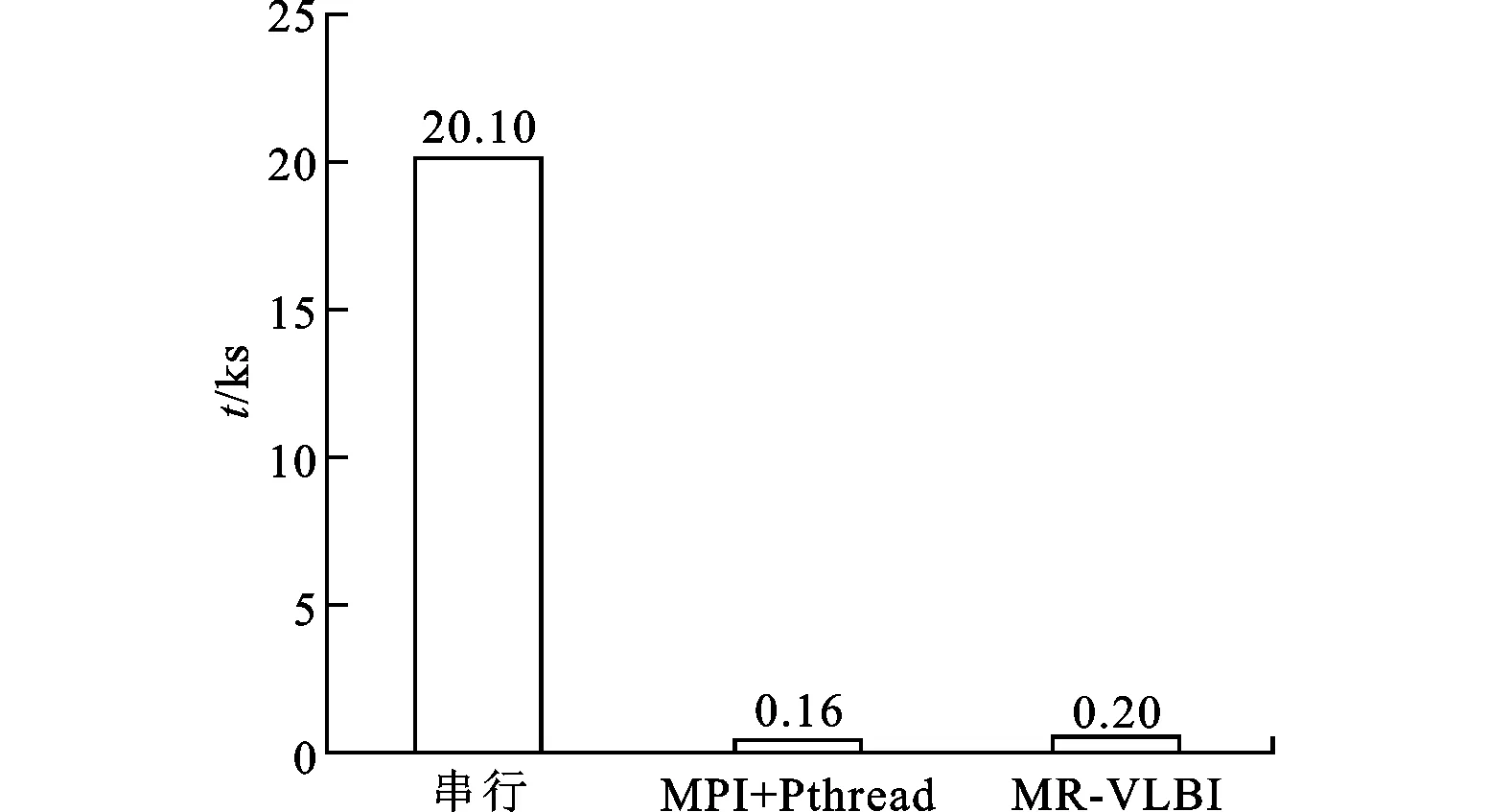
图5 串行、MPI+Pthreads和MR-VLBI运行时间对比
图6给出了模型周期为0.156 16 s,采用不同数据复制策略和节点个数时MR-VLBI的运行时间。从该结果可以看出,MR-VLBI的性能随着节点数的增多呈线性上升的趋势,但是它对数据复制策略不敏感。
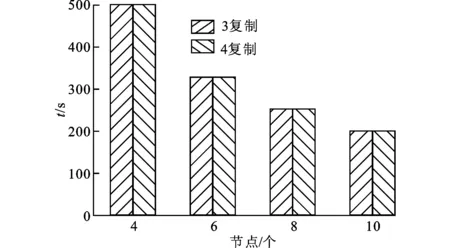
图6 不同系统参数下MR-VLBI的运行时间对比
MR-VLBI采用模型周期作为并行计算单元,而MPI+Pthreads方式采用双层并行结构,节点间采用积分周期,节点内部使用模型周期,这一差异使两者具有不同的负载均衡能力。因为模型周期粒度较小,而且其数量通常较多,MR-VLBI能在全局计算资源上进行良好的负载均衡,但对MPI+Pthreads方式,当积分周期包含的模型周期数量少于节点CPU核数时,节点上的每个核并不能都分配到计算任务,会形成一定程度的闲置,使计算效率降低。
图7和图8分别示意了积分周期为59.965 44 s、模型周期取不同值时,MR-VLBI和MPI+Pthreads的运行时间和它们实际运行的并行任务数量。当模型周期较大时,例如7.495 68 s和3.747 84 s,MR-VLBI具有更快的运算速度,因为此时它具有更多的并发任务,但是随着模型周期的逐渐减小,MPI+Pthreads的运行效率越来越高,此时其并行任务数量随着积分周期包含模型周期个数的增加而增多,从而能更充分地利用CPU资源提高计算速度。

图7 不同模型周期时MR-VLBI和MPI+Pthreads方式运行时间对比
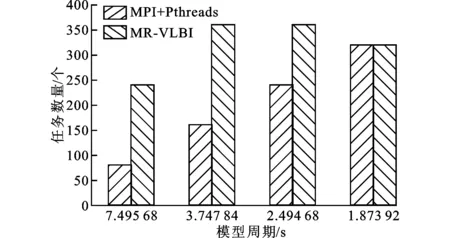
图8 不同模型周期时MR-VLBI和MPI+Pthreads方式的任务数量
4 结 论
VLBI相关处理具有数据密集和计算密集的双重特征,对其进行高速处理是一个亟需解决的问题。本文基于云计算模型MapReduce提出和设计了一种称为MR-VLBI的并行处理方法,虽然其运行效率相对于传统并行处理方式并不是完全领先,例如在积分周期包含的模型周期数量多于节点CPU核数时的性能就要差一些,但是它具备逻辑简单、实现容易、扩展性强和负载均衡能力强等传统方式所缺乏的一系列优点,因而具有良好的应用前景。
目前,MapReduce实现技术有了新发展,出现了例如Spark等具有更高性能的框架,未来将它们应用到MR-VLBI中,会进一步提高和改善系统的运行效率。
[1]韩松涛, 唐歌实, 刘成军, 等.VLBI并行处理方式比较分析 [J].遥测遥控, 2013, 34(1):29-33.HAN Songtao, TANG Geshi, LIU Chengjun, et al.Analysis on parallel processing of VLBI [J].Journal of Telemetry, Tracking, and Command, 2013, 34(1):29-33.
[2]DELLER A, TINGAY S J, BAILES M, et al.DiFX:a software correlator for very long baseline interferometry using multiprocessor computing environments [J].Publications of the Astronomical Society of the Pacific, 2007, 119(853):318-336.
[3]LOWE S T.Softc:an operational software corelator [C]∥Proceedings of the International VLBI Service for Geodesy and Astrometry 2004 General Meeting.Washington, DC, USA:NASA, 2004:191-194.
[4]MACHIDA M, ISHIMOTO M, TAKASHIMA K, et al.K5/VSSP data processing system of small cluster computing at Tsukuba VLBI correlator, NASA/CP-2006-214140 [C]∥ Proceedings of the IVS 2006 General Meeting.Washington, DC, USA:NASA, 2006:117-126.
[5]ZHENG Weimin, ZHANG Dong.Parallel algorithm of VLBI software correlator under multiprocessor environment [C]∥Proceedings of the SPIE 15th International Symposium on Multispectral Image Processing and Pattern Recognition.Bellingham, WA, USA:SPIE, 2007:15-22.
[6]李元飞, 郑为民.VLBI数据软件相关处理方法研究 [J].中国科学院上海天文台年刊, 2004, 25:150-158.LI Yuanfei, ZHENG Weimin.VLBI very long baseline interferometry data simulation algorithms study [J].Annals of Shanghai Observatory Academia Sinica, 2004, 25:150-158.
[7]钱志瀚, 李金岭.甚长基线干涉测量技术在深空探测中的应用 [M].北京:中国科学技术出版社, 2012:46-48.
[8]DEAN J, GHEMAWAT S.MapReduce:simplified data processing on large clusters [C]∥Proceedings of the 6th Symposium on Operating Systems Design and Implementation.Berkeley, CA, USA:USENIX, 2004:137-150.
[9]张冬.集群环境下的VLBI软件相关处理方法研究 [D].上海:中国科学院上海天文台, 2007.
[本刊相关文献链接]
崔继岳,梅魁志,刘冬冬.面向OpenCL的Mali GPU仿真器构建研究.2015,49(2):20-24.[doi:10.7652/xjtuxb201502 004]
袁通,刘志镜,刘慧,等.多核处理器中基于MapReduce的哈希划分优化.2014,48(11):97-102.[doi:10.7652/xjtuxb2014 11017]
张虹,郑霄,赵丹.GPU加速窦房结计算机仿真的实现及优化.2014,48(7):60-64.[doi:10.7652/xjtuxb201407011]
史椸,耿晨,齐勇.一种具有容错机制的MapReduce模型研究与实现.2014,48(2):1-7.[doi:10.7652/xjtuxb201402001]
熊金波,姚志强,马建峰,等.云计算环境中的组合文档模型及其访问控制方案.2014,48(2):25-31.[doi:10.7652/xjtuxb201402005]
田乐,陈庶樵,黄慧群,等.利用域转换的三态内容寻址存储器报文分类算法.2013,47(10):97-102.[doi:10.7652/xjtuxb201310017]
鲍军鹏,宋楠,陶斌.依赖知识的服务组合算法.2013,47(8):1-6.[doi:10.7652/xjtuxb201308001]
张保,董小社,白秀秀,等.CPU-GPU系统中基于剖分的全局性能优化方法.2012,46(2):17-23.[doi:10.7652/xjtuxb 201202004]
唐轶轩,吴俊敏,陈国良,等.并行片上网络仿真器ParaNSim的设计及性能分析.2012,46(2):24-30.[doi:10.7652/xjtuxb201202005]
张保,曹海军,董小社,等.面向图形处理器重叠通信与计算的数据划分方法.2011,45(4):1-4.[doi:10.7652/xjtuxb 201104001]
刘洋,赵慧,尹兴良,等.线性检测中的最优空时编码设计与分析.2011,45(2):59-63.[doi:10.7652/xjtuxb201102012]
韦远科,赵银亮,宋少龙,等.面向片上多核处理器的推测多线程机制下的独立栈模型.2010,44(12):10-15.[doi:10.7652/xjtuxb201012003]
李远成,赵银亮,阴培培,等.一种应用代价评估的推测多线程路径预测方法.2010,44(12):22-27.[doi:10.7652/xjtuxb 201012005]
(编辑 武红江)
A Parallel Processing Approach of Very Long Baseline Interferometry Using MapReduce
TIAN Bin1,2,HE Qiang2,WANG Jia2,ZHENG Yuxi2
(1.School of Electronics and Information Engineering, Xi’an Jiaotong University, Xi’an 710049, China; 2.Xi’an Satellite Control Center, Xi’an 710043, China)
A VLBI parallel processing approach based on MapReduce is proposed to solve such problems in traditional VLBI parallel processing patterns as logic complexity, poor data storage and computing scalability.Model periods are used as primary data processing units, and a related data splitting method is constructed to align each model period’s data of every station.A data correlation mapping is designed and the final correlation results are obtained by using Reduce to synthesize each model period’s processing result.Experimental results show that the efficiency of the new approach is about 25% lower than traditional ways when the number of model periods in an integration period is larger than CPU cores, but it provides better performance when the number of model periods in an integration period is less than CPU cores.Also the approach reduces the complexity of VBLI parallel processing and provides good data storage and computing scalability.
very long baseline interferometry; data correlation; parallel processing; MapReduce
2014-09-13。 作者简介:田斌(1971—),男,在职硕士生,西安卫星测控中心研究员。
时间:2015-03-04
http:∥www.cnki.net/kcms/detail/61.1069.T.20150304.1653.003.html
10.7652/xjtuxb201504010
TP311
A
0253-987X(2015)04-0061-06
猜你喜欢
地理空间信息(2022年11期)2022-11-26
测绘地理信息(2022年2期)2022-04-02
陕西水利(2021年5期)2021-06-21
科学(2020年5期)2020-11-26
通信电源技术(2020年8期)2020-07-21
中国惯性技术学报(2019年3期)2019-10-15
电子制作(2019年23期)2019-02-23
信息通信技术与政策(2018年9期)2018-10-09
舰船电子对抗(2016年5期)2016-12-13
现代防御技术(2016年1期)2016-06-01
