
基于知识发现的Nanopublication语义模式研究
2015-12-25 02:07武建光苏云梅山西医科大学图书馆网络技术部太原030001
山西医科大学学报 2015年8期
武建光,苏云梅(山西医科大学图书馆网络技术部,太原 030001)
随着科学文献数据剧增以及信息技术、数据库技术的快速发展,Nanopublication(纳米出版物)[1]的研究越来越受到科研工作者的重视,此项研究由英国皇家化学学会的“Prospect”项目开始探索,概念网络联盟于2009年明确提出Nanopublication概念[2],随后2010年该联盟专家Paul详细剖析了Nanopublication的信息模型结构,经过科研工作者的不懈努力,目前化学、医学、物理等领域均有较深的研究应用。本文以人类遗传疾病塞克尔综合征的Nanopublication为例,通过知识挖掘发现来探讨Nanopublication语义关联。
1 Nanopublication概念及模型
“Nanopublication”本文不是指与“长度单位”或“纳米科学技术领域”相关的出版物,而是借用“Nano”微小之意,表示一种具有科学依据、机器识别的、最小的、可打印出版的信息元。Nanopublication与传统出版物本质是相同的,是一种新的语义表达。Nanopublication是传统出版物的模型化、结构化表达,形式定义为一个五元组:Nano-Structure=(ID,IK,Pr,As,SI),其中 ID 为主关键字,唯一标识一“本”Nanopublication出版物,IK(Integrity Key)表示完整性密钥(约束数据一致、相容、有效),Pr(Provenance)表示出处,As(Assertion)表示结论,SI(Support Information)表示支撑信息,其中ID,IK是不可拆分的最小单位,Pr,As,SI均为N个三元组组成。Nanopublication的模型图见图1。
2 基于知识发现研究Nanopublication语义模式
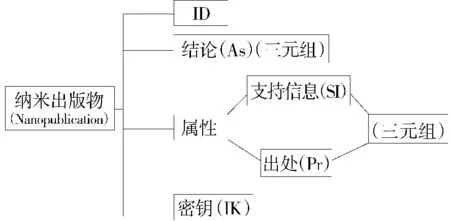
图1 Nanopublication模型图
以人类遗传疾病塞克尔综合征的Nanopublication为例进行研究,塞克尔综合征辐射的Nanopublication数量庞大,以下给出的是一小段人类基因CENPJ具有 P值0.000 07的塞克尔综合征 Nano publication源文件[3](见图2),源文件采用RDF标记语言[4]及XML扩展标记语言准则,类似C语言编码框架,有规范的语法规则、可控词表,主体为函数,以及声明、调用、引用,单句采用三元组S-P-O(主语-谓语-宾语)格式,即将概念作为句处理对象,以“;”分割,这样形成的文件可受计算机推理、查询、重组开采,因此对于Nanopublication而言,在利用知识发现研究内在关联的时候需要借助数据结构、程序语言发现、挖掘它们的内在联系。
2.1 利用知识发现研究有向关联
“Nanopublication”是传统出版物的微观表达,将出版文献的主体内容(研究背景、研究方法、研究结论、引用观点等)与相关信息(作者信息、出版信息、引用文献、相关课题信息等)予以结构化语义标注,继而提取元组信息,最后将文献的核心知识信息以结构化、模块化、机器可识别处理的形式表现。因此大量的纳米出版物会因为具有相同的引用文献、参考图表、研究方法进行各种链接、聚合从而形成一个庞大的信息网络:分有向网络和无向网络。对于有向网络需要采用数据结构之有向图结构的算法与程序操作揭示隐含关系,在塞克尔综合征Nanopublication有向网图中进行知识发现,可以挖掘发现三种情况:①具有直接有向路径的两个Nanopublication具有明显直接关联;②途经若干个Nanopublication沿着有向路径强连通(双向到达)的两个Nanopublication可以确定二者具有潜在关联;③没有任何一条有向路径可以双向强连通的Nanopublication可以确定二者没有潜在关联,由此可知,利用知识发现可以很好地挖掘庞大Nanopublication网络图错综复杂的关联关系,帮助研究人员更好地发现塞克尔综合征直接、间接的基因及病理关系。取塞克尔综合征的Nanopublication的其中6个结点为例直观解析,见图3,图4(Nap为Nanopublication的缩写)。

图2 Nanopublication源文件图
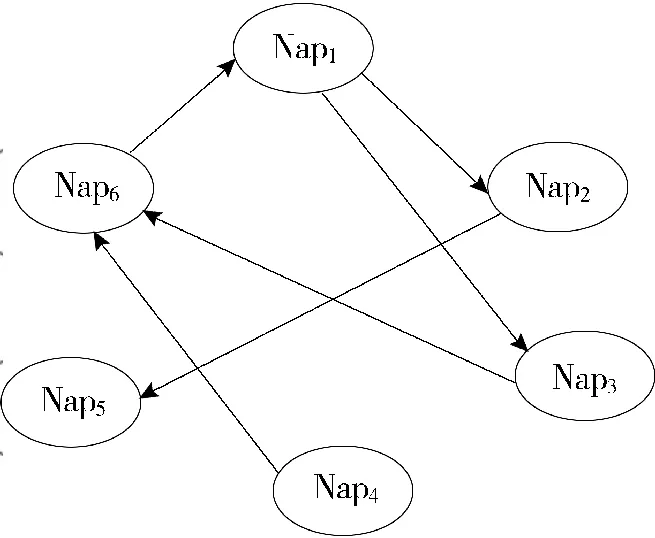
图3 Nanopublication结点有向图
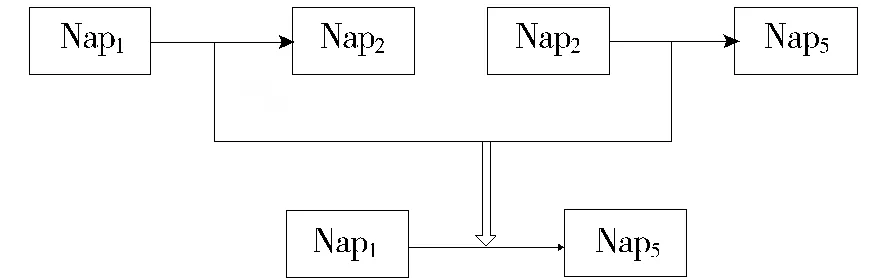
图4 Nanopublication结点有向关联图
2.2 利用知识发现研究无向关联
由大量的塞克尔综合征的Nanopublication形成的网络图并不总是有向的,有时会出现无向的。而对于这些无向的Nanopublication网图进行知识发现的时候需要采用数据结构之无向网图的算法、程序操作去揭示相互间的关系。在塞克尔综合征Nanopublication无向网图中进行知识发现,会出现和有向关联完全不同的三种情况:①具有直接无向路径的两个Nanopublication具有明显直接关联;②途经若干个Nanopublication沿着无向路径连通的两个Nanopublication可以确定二者具有潜在关联;③没有任何一条有向路径可以连通的Nanopublication可以确定二者没有潜在关联。知识发现的过程中,无向关联与有向关联的最大区别为前者算法程序不考究Nanopublication网图结点间的方向性,后者算法程序必须大篇幅处理方向带来的双向复杂问题。为比对说明问题同样选取Nanopublication网图中的6个结点为例直观解析,结果见图5、图6(Nap为Nanopublication的缩写)。
专家研究开发Nanopublication是为了利用比传统出版物更直观、深入、立体、简化的优点,缩减研究人员通读大量的传统文献的时间,改变研究人员旁征博引停留在文献层面的现状,突破研究人员知识结构的局限,但是Nanopublication网图所带来的复杂图结构一定程度上给研究人员带来新的难题,而通过知识发现可以较好地解决有向网图、无向网图所带来的有向关联和无向关联的问题。
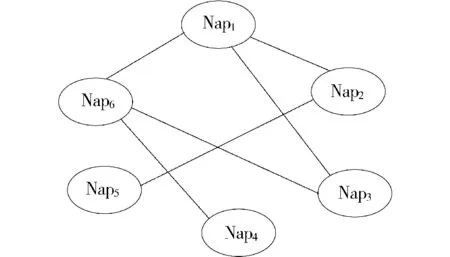
图5 Nanopublication结点无向图
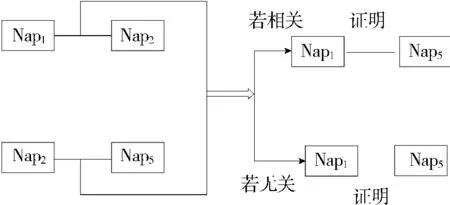
图6 Nanopublication结点无向关联图
3 研究结果
在某个具体领域中生成的Nanopublication网图个数较多,且某个网图中结点个数也较多,有向网图采取有向关联措施,无向网图采取无向关联措施。最后经过程序分析、整合,能够得出一个完整的Nanopublication网络图,如塞克尔综合征知识发现之后得到的完整网络图的部分如图7所示。
“Nanopublication”与知识发现从表象看,前者是软件语义研究,后者是信息学,二者属于不同的研究范畴,但是由于可视化技术的桥梁作用,使得二者建立了密不可分的联系,在Nanopublication的出版模式下,研究者借助Nanopublication的知识网络可以促进信息分析、知识发现的快速发展,而知识发现亦可使软件语义研究者发现语法歧义、漏洞,规范标准,完整词表,改进算法,规范Nanopublication数据库三大范式,大大促进其发展、普及、平衡。
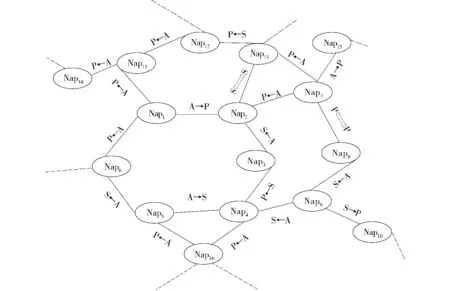
图7 Nanopublication的知识网络图
借助知识发现能够很好地揭示Nanopublication的内在关系,但是由于Nanopublication还处于发展完善阶段,很多领域的中外文出版文献并没有与之相对应的Nanopublication,所以在发现的过程当中会遗漏很多相关文献资源。另外,对于现有的Nanopublication的关系揭示程度与知识发现所采用的程序的健壮性以及数据可视化技术有很大关系。Nanopublication自身的规范标准、完整词表亦有待继续发展。因此,基于知识发现研究Nanopublication是一个持续的课题。
4 结语
目前,描述全面并且支持Nanopublication完整性密匙的的系统PHACTS正在筹备开放,这将为知识发现带来一场信息革命,Nanopublication的模式具有扩张接口,新要素可以通过完善、添加元组随时创建,随时丰富知识网络实体内容,由于Nanopublication具有动态连接性,必须要求作者提供的纳米数据正确、规范,避免在知识发现的过程中发生错误堆积的想象。研究Nanopublication不是为了取代传统出版物,也无法取代传统出版物,研究的目的恰恰是为了科学研究、知识发现。
[1]吴思竹,李峰,张智雄.知识资源的语义表示和出版模式研究——以 Nanopublication为例[J].中国图书馆学报,2013,39(4):102-109.
[2]Netherlands bioinformatics centre.Concept web alliance[EB/OL].http://www.nbic.nl/about-nbic/affiliated-organisations/cwa/introduction.2015-02-25.
[3]The open PHACTS RDF/Nanopublication Working Group.The open PHACTS Nanopublication guidelines[EB/OL].http://www.nanopub.org/guidelines/recent.2015-03-26.
[4]RDF Working Group.Resource description frameword(RDF)[EB/OL].http://www.w3.org/RDF.2015-02-25.
[5]Nanopub.org.What is a Nanopublication[EB/OL].http://nanopub.org/wordpress/?page_id=65.2015- 02-27.
猜你喜欢
电子制作(2021年14期)2021-08-21
科学与信息化(2021年8期)2021-03-31
英语文摘(2019年9期)2019-11-26
活力(2019年21期)2019-04-01
数学物理学报(2018年1期)2018-03-26
快乐作文·中年级(2015年3期)2015-03-26
电测与仪表(2014年10期)2014-04-04
电子设计工程(2014年12期)2014-02-27
重庆交通大学学报(自然科学版)(2012年4期)2012-02-09
课外阅读(2009年7期)2009-04-08
