
基于ESB的服务排队路由
2015-12-23 01:06刘建明李宏周彭智勇
计算机工程与设计 2015年8期
刘 岩,刘建明,李宏周,彭智勇
(1.桂林电子科技大学 计算机科学与工程学院,广西 桂林541004;2.桂林电子科技大学 电子工程与自动化学院,广西 桂林541004;3.桂林电子科技大学 生命与环境科学学院,广西 桂林541004)
0 引 言
由于网络环境处于动态变化中,所以有很多不确定性因素影响静态路由的效能,很多研究已经展开用于设计企业服务总线动态路由。文献 [1,2]提出了基于ESB的动态适应方案用以适应动态网路环境变化,例如服务接口改变、反应时间过大和服务饱和等,各个适应方案都提到了对等效服务的利用,也就是对功能相同服务的利用;文献[3]提出了在运行时测试评估的动态路由方法,文中的抽象服务名映射实际的功能等同的服务提供者列表;文献[4]引入了DWT 组件和侦听器组件来实现动态可靠的服务路由,文中的服务发现引擎用于查找等效的服务提供者列表;文献 [5]提出了一个策略配置动态路由模型,文中消息分析器组件用于查询得到服务提供者列表。
动态服务路由的研究都收集了服务提供者列表以应对网络中的动态变化需求,也都是采用增强ESB 功能的方式在运行时实现动态服务路由。本文提出将服务提供者预先进行科学分析,根据平均状态下的性能进行排队,得到一个固定的具备优先权的队列。在ESB 中利用得到的队列是一种静态布置,但由于有一个有效的优先权队列,队列中包含了一些运行良好的服务提供者,这种方式提高了ESB服务路由的效能。同时设计中的程序控制充分利用队列,使其能够很好地应对网络中的动态变化,也实现了类似动态服务路由的效果。本文利用排队的方法,在保证服务路由高可靠性的情况下,兼顾高效性、稳定性,提高了ESB服务路由的整体效能。
1 服务的排队
1.1 服务的排队条件
Web服务技术以其跨平台可互操作的特性在互联网上得到了快速地发展和应用。互联网上存在大量的Web 服务,很多可以利用UBRs(UDDI business registries)和服务搜索引擎进行查找[6],其中有一部分免费的Web服务可以提供给研究者调用。在这些Web服务中很多都显示了功能相同或者相似的特点,对这些功能相同或相似的服务加以利用,可以提高应用服务的效能,例如在可靠性、高效性和稳定性等方面。
ESB充分利用了消息机制和XML、Web服务的跨平台特点,实现了面向服务架构 (service-oriented architecture,SOA)的模型,利用它可以实现更广领域的集成。其最核心的功能是消息转换和消息路由。消息转换能够消除消息在传输过程中协议和格式的差异性,也能够消除最终的反应消息的差异性,将功能相似的服务变成功能相同的服务。消息路由是消息经过所选择的通道正确传达给服务提供者,由服务提供者将最终的反应消息返回给服务请求者。
现实网络的实际情况是并不是所查找到的服务提供者效能都非常好,而把效能很差的服务提供者随意加入服务提供者列表中,会降低整个的服务路由的效率和可靠性,而且在网络中的动态变化不是时时都发生,而是在某一时间段或者在某一时间点发生,所以不需要ESB 在每一次运行中都进行复杂的应对环境变化的工作。
1.2 服务的排队依据
许多相关文献都谈到了QoS (quality of service)属性问题[7],QoS属性是为了区分服务特别是功能相同的服务而定义的一系列非功能属性,其中包括反应时间、可用性、吞吐量、成功率及可靠性等等。这些属性值的获取一般是通过专业的测试工具,而且这些属性值在一定时间间隔内度量得到的平均水平,也是通过统计分析得到的平均水平。由于属性值的变化不是时时刻刻都在进行的,其更新可以由一个统一的服务代理周期性完成。这些属性值可以被用户用来选择满足特定需求的服务,也可以用来选择总体评估好的服务。
服务的属性值是一个服务执行的平均状态,可以收集很多的属性值用以更好地选择特定服务[8]。要将功能相同的服务组成一个整体队列供服务请求者调用,而由于单个服务的可用性、吞吐量、成功率等属性值综合到一个队列里面整体体现出的相应值会很大,可以忽略这些因素而仅仅利用反应时间提高队列整体的高效性和可靠性等性能。可以自己统计得出平均反应时间,仅仅利用平均反应时间来完成服务排队路由。
在网络环境中可能会发生很多情况致使服务失效,例如暂时的服务器故障、某个特定服务器负载量太大或者传输时延在某一段网络中过大等等。这些失效大都属于临时失效,会维持一段时间的失效状态,一段时间过后会重新恢复原来的平均状态。在ESB 中功能相似的服务转换为功能相同的服务,在互联网上可以搜集这些功能相似或者相同的服务,得到一个服务提供者列表。失效本身是一种随机的不确定的现象,当服务提供者列表中有不少于3个的服务提供者,全部失效的概率是很小的。综合考虑网络变化中的所有情况,全部失效也是可能的,但一定以一个小概率出现,而这样可以保证高可靠性。
因服务提供者反应的结果相同,所以平均反应时间越短,服务本身性能就越好。服务提供者按照平均反应时间排序,选择前面少数几个服务提供者就可以组成一个具备优先权的服务队列。排队体现了排队论中排队的概念[9],但它不是针对用户的排队,而是针对网络中可利用的服务资源的排队。队列靠前的服务提供者失效后,紧随的服务提供者提供服务,保证了整体运行的高效性,利用排队进行整体设计的效率很高。同时由于排队中服务的合作关系整体设计也体现出了服务反馈结果的稳定性。
1.3 服务的排队选择模型
假设有4个功能相同的服务,考虑到服务会发生失效的情况,设计的排队选择模型通过3 种策略来应对,这3种策略将充分利用具备优先权的服务队列。服务的排队模型如图1所示。

图1 服务的排队选择模型
第一种策略是将用户请求消息同时发送给备份服务。计算机软硬件的设计中都考虑到了用备份来提高可靠性,如果原来的主要工作单元没有发挥应有作用,备份就会恰当地作为补充发挥作用,在服务的排队选择模型中利用备份这一概念。当用户请求消息到来的时候,按照一般方法将其发送到排队的优先权高的服务上。而用户请求消息会同时额外地发送给备份服务,优先权高的服务失效后,备份服务即可发挥作用;另外一个方面,虽然优先权高的服务未失效但偶然反应时间过多,备份服务发挥作用可以降低反应时间,使服务提供结果消息具有很好的稳定性。
第二种策略是在前两个服务都失效的情况下,程序控制语句探测到并自动向后执行移位操作,然后重发用户请求消息。而且只有一个服务失效的情况下,程序控制语句也会执行移位操作,保证下一次请求消息发送给两个服务。计算机软硬件资源的查找都会用到移位操作,最终定位所要查找的有效资源。服务的排队选择模型引入移位操作能大大提高服务反应消息的成功率,通过这种策略实际上是增加了服务成功返回结果消息的机会。
最后一种策略是服务的出队归队操作,使用这种策略能够更好地应对网络环境中的动态变化。当某一个服务失效后即执行出队操作,后续请求消息的调用将不会考虑失效服务,除非其恢复后归队。通过这种方式所维持的队列依然是一个具备优先权的服务队列。因为失效只是维持一段时间的失效状态,一段时间后会重新恢复原来的平均状态,归队操作会让优质服务归队参与运行。
2 基于ESB的服务排队路由
实验的平台是开源软件Mule ESB。Mule ESB 是一个轻量级消息架构,能方便地集成各种应用,并具备很强的可扩展性[10]。其内部的各种组件可以很轻便地转换各种消息格式等差异,实现非常好的消息转换功能;同时其组件也可以通过各种方式路由消息,实现较高效的消息路由功能。在实验中服务排队路由就是很好地利用了Mule ESB的消息转换和消息路由功能。
在Mule ESB中利用计算机语言或者说程序控制语句可以很好地实现服务排队选择模型。按照实验的设想,选择4个功能相同的Web服务进行研究,它们能够利用IP地址查询国家信息。服务排队路由利用服务排队选择模型实现的整体流程如图2所示。

图2 服务排队路由的整体流程
(1)用户端发送请求消息,请求消息传输到位于图2下方的基础流和位于图2上方的测试流。基础流是一般情况下选择服务对用户请求消息进行处理的流程,同时负责对失效服务的出队操作;测试流是在排队中有失效服务情况下的测试流程,也就是说测试流测试失效服务并负责对恢复效果的服务进行归队。
(2)请求消息发送到基础流后,需要查询排队信息。具备优先权的排队信息可以保存在数据库中,也可以保存在文件中。
(3)基础流控制语句从排队中按照优先权依次选择两个未失效的服务,选择成功后两个服务和用户请求消息一并向后传输。在控制语句中如果探测到依次选择的两个未失效服务及测试流都未正确返回结果消息,则重新从排队中向后选择两个未失效的服务,选择成功后两个服务和用户请求消息再次一并向后传输。
(4)总的消息负载中所确定的有效服务接收用户请求消息并进行相关处理最终得到反应结果消息。
(5)失效控制语句一旦从两个服务反馈消息中探测到服务失效后,将排队中相应位置的值置为 “失效”,并保存到数据库或者文件中,“失效”服务会在下一次运行时被测试流利用,从而完成了服务的出队操作。
(6)请求消息发送到测试流后,测试流同样需要查询位于数据库或者文件中的排队失效信息。
(7)测试流控制语句从排队中选择全部的失效服务,和用户请求信息一起一并向后传输。
(8)利用用户请求消息对总的消息负载中所确定的失效服务进行探测以判断失效服务是否已经能够正确返回结果消息。
(9)恢复控制语句探测到测试的失效服务已经恢复后,将排队中相应位置的值置为 “有效”,完成了服务的归队操作。如果测试的服务先于基础流提供的服务反馈结果消息,则立即起用测试流提供的结果消息,使服务排队路由效率更高。
(10)测试流的所有调用的服务和基础流的两个服务都有可能提供结果消息,这些结果消息利用互斥的方法将只有一个最终输出给用户,而且输出的是反应时间最少的那一个,这样使服务的反应时间围绕着一个平均值不会出现较大的波动,而更保证了服务反馈结果消息具有更高的稳定性。
3 服务排队路由的效能分析
3.1 服务排队路由的稳定性分析
利用服务排队选择模型的服务排队路由在具体实施时测试流所调用的服务和基础流的两个服务都可能提供结果消息,而输出的是反应时间最少的那一个服务。这样在服务失效时不仅能够保证提供结果消息,而且在具体网络环境中服务的反应时间的变化不会特别大。为了分析稳定性实验中考虑两种情形,第一种是用户请求消息到来只发送给服务1,也就是将服务请求固定路由给服务1;第二种情形是在服务排队路由中服务1反应时间过长而起用后续服务提供结果消息。
实验中选择15 个IP 地址进行针对两种情形的测试,测试的结果如图3所示。只有一个服务参与的情形下,网络环境动态变化会增加对服务反应时间的影响。从两个折线的对比就可以看到利用单一服务进行路由服务反应时间幅度变化可以很大,稳定性不够好。而利用服务排队路由,其它功能相同的后续服务能够提供支持,所以服务反应时间变化不大,服务反应时间会维持在一个小范围内浮动,而且整体的反应时间是少的,具有较高的稳定性。
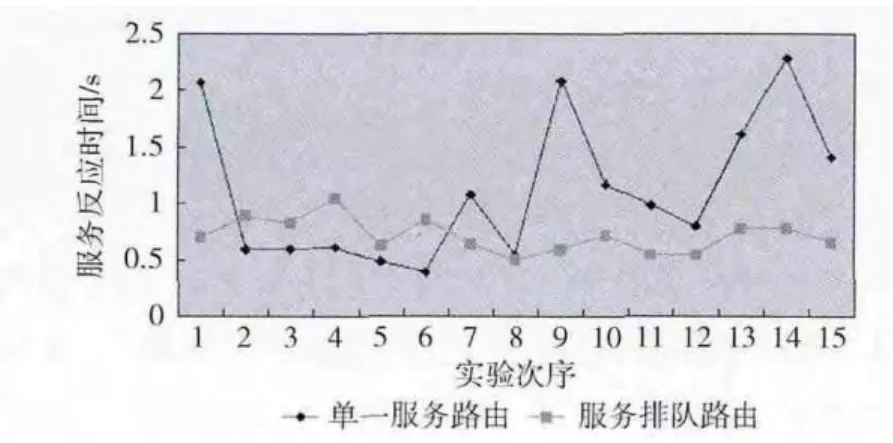
图3 服务排队路由的稳定性分析
3.2 服务排队路由的高效性分析
排队是根据反应时间多少来进行的,反应结果由于利用了ESB的消息转换而都是相同的,所以反应时间越少,服务本身性能就越好,于是组成了一个具备平均反应时间优先权的排队。当排队中第一个服务没有失效时,第一个服务就可满足用户调用需求。有可能会有排队中后续服务的参与,因为偶然的延迟过大会利用排队后续服务的结果消息。而当第一个服务失效时,第二个服务就会起作用,反应时间虽然会多一些,也可以满足用户需求。这样整体的用户请求总是会选择排队靠前的服务,说明服务排队路由基于服务排队选择模型保证了用户请求调用的高效性。
为了验证高效性,可以从众多可能出现的情况中选取4个服务执行典型事件。①服务执行典型事件为调用服务1;②服务执行典型事件为服务1失效而调用服务2;③服务执行典型事件为服务1、服务2失效而调用服务3;④服务执行典型事件为服务1、服务2、服务3均失效而调用服务4。为实验测试可选取10个IP 地址。在测试时记录每次的反应时间,如果10个IP 地址中对应的反应时间有偏离太大的,则对其进行重新测试。最后得到每个IP请求对应的反应时间,并计算得出平均反应时间,最后得到4个服务执行典型事件依次的平均反应时间如图4所示。
由图4可知,服务排队路由面对网络变化时会选择排队靠前的服务,因此平均反应时间在4个服务执行典型事件中依次增加,从而保证了服务排队路由的高效性。
3.3 服务排队路由的可靠性分析
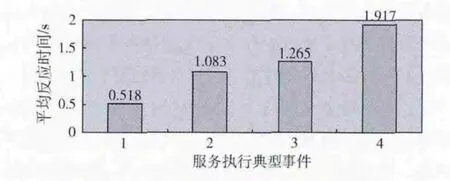
图4 服务排队路由的高效性分析
由科学分析建立的具备优先权的排队中服务全部失效的概率很小,保证了服务排队路由的高可靠性。为了最大程度地考查程序控制和整体设计在面对网络动态变化时对可靠性的保证,在测试时先设计一个测试列表。在测试列表中每次对整体流程的执行涉及3种对服务的操作,分别是失效即某一服务失去效果、恢复即某一服务失效后恢复效果、保持有效即服务保持上一次的有效状态。在整个列表中失效操作是从前往后进行,恢复操作是从后往前进行,更好地展现整体设计必须面对的网络变化。假设全部失效以一个小概率出现,这样更接近于真实世界的网络状况。
在实验测试中每40次运行记录一个成功次数并得出成功率,一共进行600次实验,得到如图5所示的成功率图。在折线图中可看出成功率在很接近1的小范围内波动,因为实验运行会偶然地有几次失败的情况,而这种成功率可以满足高可靠性,而且如果不考虑服务全部失效的情况,成功率更接近1,从而使高可靠性得到了很好的保证。
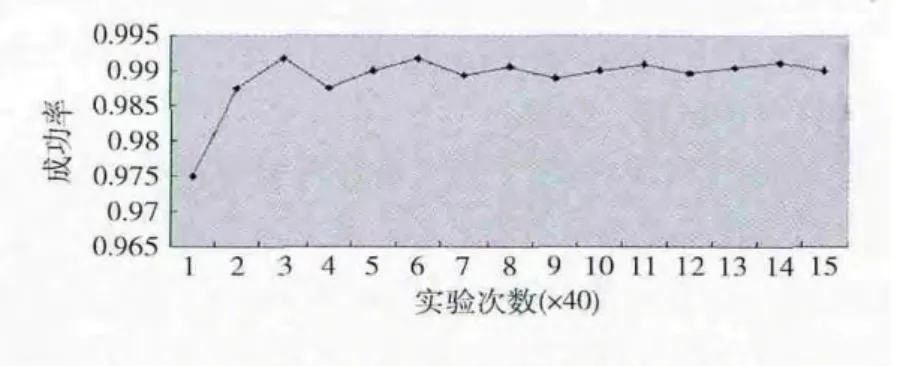
图5 服务排队路由的可靠性分析
4 结束语
经过科学分析得到一个有序的具备优先权的排队在ESB中能够产生很大的效用,在ESB 服务路由时利用这些已知的规律能提高用户请求调用服务的整体效能。在具体实施中利用程序语句进行运行控制特别是针对出队和归队操作的控制,整体流程得以有效运行。从排队中可以看到,在服务中只要反应时间快整体高效性就会得到体现,而只要结果消息能尽快得到整体稳定性和可靠性也会得到很好的体现。利用服务排队路由能够在更大的方向上促进服务的交互和服务的组合,可实现更加稳定可靠的组合服务,而利用排队整合服务资源会优化整个系统的业务活动。
[1]Laura González,Raúl Ruggia.Towards dynamic adaptation within an ESB-based service infrastructure layer [C]//Proceedings of the 3rd International Workshop on Monitoring,Adaptation and Beyond,2010:40-47.
[2]Laura González,Raúl Ruggia.Addressing QoS issues in service based systems through an adaptive ESB infrastructure[C]//Proceedings of the 6th Workshop on Middleware for Service Oriented Computing,2011:1-7.
[3]Bai Xiaoying,Xie Jihui,Chen Bin,et al.DRESR:Dynamic routing in enterprise service bus [C]//IEEE International Conference on e-Business Engineering,2007:528-531.
[4]Wu Bin,Liu Shijun,Wu Lei.Dynamic reliable service routing in enterprise service bus [C]//IEEE Asia-Pacific Services Computing Conference,2008:349-354.
[5]Zhou Chunyan,Zhang Xin.A policy-configurable dynamic routing mechanism in enterprise service bus[C]//International Conference on Educational and Information Technology,2010:480-485.
[6]Eyhab Al-Masri,Qusay H Mahmoud.Investigating web services on the world wide web [C]//Proceeding of the 17th International Conference on World Wide Web,2008:795-804.
[7]Al-Masri E,Mahmoud Qusay H.QoS-based discovery and ranking of web services[C]//Proceedings of 16th International Conference on Computer Communications and Networks,2007:529-534.
[8]The QWS Dataset [EB/OL].http://www.uoguelph.ca/~qmahmoud/qws/,2008.
[9]Yang Shuo,Chen Haopeng.An improving fault detection mechanism in service-oriented applications based on queuing theory [C]//IEEE International Symposium on Service-Oriented System Engineering,2008:245-250.
[10]Mule fundamentals [EB/OL].http://www.mulesoft.org/documentation/display/current/Mule+Fundamentals,2013.
猜你喜欢
法制博览(2020年11期)2020-11-30
西部论丛(2019年25期)2019-10-21
山东大学法律评论(2018年0期)2018-08-04
资源节约与环保(2018年1期)2018-02-08
中国知识产权(2017年2期)2017-03-13
法制博览(2017年16期)2017-01-28
新课程(2016年3期)2016-12-01
新课程(2016年3期)2016-12-01
湖湘论坛(2015年4期)2015-12-01
世界海运(2015年8期)2015-03-11
