
基于内容的音乐信息提取的研究对象与思路
2015-12-05 06:22:01黄镭邓明
广西广播电视大学学报 2015年4期
黄镭邓明
(广西广播电视大学教学资源中心 广西南宁 530023)
基于内容的音乐信息提取的研究对象与思路
黄镭邓明
(广西广播电视大学教学资源中心广西南宁530023)
基于内容的音乐信息提取(Content-Based Music Information Retrieval,CBMIR)是属于信息提取(Information Retrieval)的一个分支,CBMIR从媒体内容出发,利用音乐理论、声学心理学、信号处理技术和机器学习方法,试图解决数字音乐媒体急剧增长背景下的音乐特征分析和语义标定问题。文章通过对CBMIR的研究对象的分析,引出了CBMIR在特征维度、时间维度上的多层次的研究思路,并简要介绍了目前CBMIR的主流研究内容。
内容;音乐信息;提取;机器学习
基于内容的音乐信息提取(Content-Based Music Information Retrieva1,简称CBMIR) 是为了区别基于文本标签的音乐信息提取,属于信息提取(Information Retrieva1)领域的一个分支。进入21世纪,随着数字化多媒体的数量以爆炸性的速度膨胀,大量未经过人工标记的多媒体内容,尤其是音频内容被创造出来。因此,基于内容的音乐信息提取,就是要解决在音乐元数据缺失、错误的情况下,利用音乐理论、声学心理学、信号处理技术和机器学习方法,自动的分析音频内容,完成音乐的分类、标注、识别等各种信息提取任务的一门学问。另外一方面,音乐信息提取的任务,还涵盖了基于文本标签的推荐系统等应用无法完成的工作,比如对乐曲的速度、旋律进行标注,对音乐进行乐谱转写等,或者是实现一些智能化的音乐交互功能,比如哼唱识别。因此,基于内容的音乐信息提取,是一个非常有用的研究领域。
1 CBMIR的研究对象
音乐,既作为一个文化概念而存在,同时又是一种复杂的声学事件,是通过多个层次来进行描述的。一方面,作为一种信号,在低层次上,我们有必要研究和提取其声学特征;因为音乐包含的文化概念,比如流派、音乐情绪等,属于较高级别的特征,这些特征是通过低层次声学特征的结构化来表示的。因此,CBMIR研究的主要对象,音乐的声学特征及其对应的符号表示是属于先验知识的一部分,必须加以说明。以下就CBMIR所需要的一部分声学要素进行概括性介绍。
1.1音乐的声学特征与符号表示
音高(pitch)
代表音符的频率特性,与其相关的有如下几个概念:
●基频(fundamenta1 frequency,或f0):决定了基音音高的频率,乐理上把基于该频率的振动产生的音也叫做基音(fundamenta1 tone);
●泛音(overtone):高于基频的任何频率分量,乐理上指的是这些频率分量对应的乐音;
●和声(harmony):基频的整数倍频率分量,也称为谐波分量;
●分音(partia1):乐理上,将基音和泛音按高低次序排列起来,这就是“分音列”。构成分音列的各音,叫做“分音”。声学上就是基频和全部泛音频率的总称。
音色(timbre)
一个较为一般的定义就是,除了音高与与谐波分量的能量构成有关。音色是区分不同乐声来源的一个重要特征。不同泛音能量密度的构成形成了人脑对于音色的听觉感知。音色,与其看似简单的定义相比,其实是非常复杂的一个多维特征,还需要更有效的方法对其建模。对音色的识别有助于我们分辨歌声与背景音乐(source separation),分辨不同的乐器(instrument detection),以及分辨不同的录音场景:辨识音乐是来自FM电台或者是现场音乐会。对于乐器来说,打击乐器是一个特例,因为类似鼓、镲等乐器发出的声音是没有基频的,尽管如此,按照其设计的音域范围,鼓类乐器也分为低音鼓、中音鼓和高音鼓,因此也有不同的音色。
速度(tempo)
速度一般以单位音符时值的倒数,也就是每分钟的节拍数(BPM)来表示,速度表征一个音乐的演奏速度。速度本来是在乐谱中定义的,用来指导乐手演奏的速度,西方乐谱中一般以意大利语表述,但是并没有一个准确的度量,只是按照其字面上的意义来理解,例如Andante grazioso本意就是优雅的走。
我们可以看到,这些词汇只是一个感知上的经验性的概念,没有严格的约束。因此一些乐谱会严格的写出单位音符的时值倒数,也就是每分钟节拍数。比如图1符号就是乐谱的指导速度(annotated tempo):
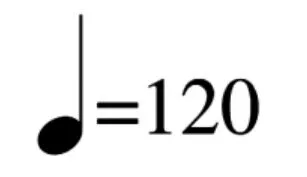
图1 乐谱的速度标记示例
这个例子中表示四分之一拍的演奏速度是一分钟120次,图1的这个例子中的符号,表达的意思是以四分音符为一拍,每分钟120拍。那么在这个乐谱中,一个四分音符的时值长度应该是1/120分钟,也就是0.5秒。而我们在速度估计(tempo estimation)任务中估计的一般是感知速度(perceptua1 tempo),事实上,我们用来测试算法性能的数据一般都没有时间标注,因此,评价任务结果的办法一般还是与专家标注的感知速度进行对比。
节拍(beat)
节拍是贯穿整个音乐的等间距的脉冲信号。因此,节拍是音乐里面的最小时间单位。
节奏(rhythm)
将长短相同或不同的节拍,按一定的规律组织起来叫做“节奏”。节奏,描述的是整部作品的整体的节拍。节奏、节拍、速度、拍号这几个概念密切相关,它们与音符的时值一起,共同描述了音乐的时间特性。节奏描述了整个作品的节奏是音乐中最重要的表现手段之一。音乐作品中音高固然重要,但它只有和节奏结合起来才能塑造形象,表达情感。对于一段旋律,不考虑它的音高,得到的便是它的节奏。
和弦(chord)
按照一定度数关系排列起来的一组音,称为和弦。和弦的演奏方法一般是共奏,意即这几个声音是同时奏响的,还有一种和弦演奏方法称为分解和弦,顾名思义就是按照某个顺序依次奏响各音。我们要为歌曲配置更优美的和弦,使音乐更流畅,这就要用到各种变化和弦。图2则是披头士歌曲“Let It Be”里面音乐片段对应和弦的一个说明:

图2 披头士“Let it be”的前四个小节乐谱
旋律(melody)
人们习惯上所说的旋律其实指的是曲调。而旋律则可以指任何有音高与节奏的乐音序列。旋律是构成声部的基础,只有先构成旋律,才能产生声部(此处的声部指某旋律在音乐中的位置),从而产生(复合)音响。比如四部和声中的四个声部在进行中分别有各自的旋律进行,而某一具有曲调感的旋律将作为主要旋律声部(一般为高声部)出现。主调音乐的声部之间是相互依存的,其中只有一个声部的旋律有曲调感,所以我们习惯的称其为“主旋律”。复调音乐是具有独立意义的旋律(曲调)相互结合构成的音乐,所有声部都具有曲调感。
音乐结构(musicalstructure)
这里音乐结构特征主要是对应作曲理论里面的曲式(musica1 form) 的概念,在传统音乐中曲式结构基本分为一部曲式、二部曲式、奏鸣曲式等。对音乐结构的分析也是音乐信息提取任务里面的一种,主要是通过音乐分段(music segmentation),分析各部分的音乐相似性,最终得到音乐的机构。
音乐理论是一门复杂庞大的学科,而音乐信息提取既需要借助乐理作为其先验知识,又要与乐理研究在重点上有所区分。毕竟作为面向用户的一种应用领域,音乐信息提取的任务并不总是需要借助完备的乐理知识才能顺利完成任务的,就好比一个未经过正规音乐训练的人仍然能够歌唱或者欣赏和理解音乐一样。
1.2数字音乐的载体
作为可以为计算机所处理的信号,数字化音乐的载体可以大致分为符号格式(symbo1ic format)和音频格式(audio format)两种:目前研究中采用的符号格式一般是MIDI格式,音频格式主要是基于PCM编码的wav格式和mp3格式。这些选择也是由可获取的音乐媒体资源的数量来决定。
2 CBMIR的研究思路
CBMIR的研究思路,在于将研究对象如何看待。作为信息提取的分支,CBMIR的研究对象是音乐,而同处于信息提取研究范畴的媒体信息例如文本、图像、视频和语音与其存在一些相似的地方,都需要借助统计学习、机器学习和数据挖掘的相关技术处理分类和模式识别问题。但是音乐欣赏,作为一种较为独立的人类活动,在信息的接收方式和阐释方法,以及关注点上,都存在较大的不同。
2.1音乐信息,同与不同
从包含的内容来看,音乐本身传递的信息是非常难以描述的。文本、图像和视频,或者语音信号传递的信息都有明确的语义,文本作为自然语言,可以直接为人所理解,被认为是最接近信息的最终符号化表达的一种媒体类型;图像或视频,从不同的维度描述了一个场景,或者事件,语音内容则是文本的直接反映,这些类型的媒体都有明确的语义传达。相比较之下,音乐能够表达的语义是最模糊,最难以描述的。西方古典音乐几百年的作曲理论详尽的研究过不同的调性组合和和声类型,发现了音乐的心理学色彩,因此我们可以通过演奏一段“哀伤”的音乐,或者一段“紧张”的音乐,来表达这样的情绪,标题音乐(musica a programma) 也有这样的作用,然而这些语义信息是相对来说较为模糊的、抽象的,而大量的音乐,尤其是现代主义作品,是抽象、晦涩的。
从表现形式来看,音乐是一个非常复杂的概念,这个概念比语音信号、图像更为复杂。首先同样为声学信号,音乐信号的来源和构成比语音更加复杂多变。因为音乐本身更接近一个文化概念,音乐包含了许多种类,比如爵士乐、古典音乐、流行、摇滚、民族音乐等;音乐既有纯人声的,比如格利高里咏叹(Gregorian chant)等类型,也有纯器乐的如大部分交响乐、室内乐,既有单一乐器独奏的,也有交响乐等多种乐器齐奏的;还有各种电子音乐。此外,即便是同一首作品,甚至同一个人演奏或演唱,音乐上的差别都会很大,更加别提不同的配乐、不同的乐器(种类、品牌的不同带来的不同声学特性)、不同的声学场景、不同的演奏方法(颤音、即兴等艺术加工手段)等等差异导致的声学复杂性。
由于语音识别任务的需求主要在于完成语音到文本符号的转换,因此,许多算法和商业语音识别应用往往可以忽略掉许多声学信息,比如音调、音色等信息,给语音识别任务带来了极大的便利;而音乐信息提取恰恰就是要去刻画、分析这些声学特征。
2.2从多维度,多时隙的结构化模型来理解音乐
音色,配器(orchestration),录制声场等特征主要是与声音的听感有关系,并属于短程(short-term)特征——可以通过十几毫秒内的声音信号来特取获得。在一些音乐类型里,这种特征变化是微小而渐进的。因此,尽管音乐是一种时间的函数,这几种特征可以认为是时不变的,可以通过截取小段音乐片段进行分析取得。这种短程特征常用于音乐流派分类任务(genre c1assification)。
节奏、旋律与和声这几种特征则是由调、各种声音事件(音符的起讫、留白、节拍的强弱变化、乐器或者人声的加入和退出)在时间轴上组合而成,描述的是一种中程(midd1e-term)的信息。因为不同的文化诞生的音乐具有不同的作曲风格和规律,因此这种中程特征结合短程特征,也可以用于流派分类等任务,而一种称为自动乐谱转写(auto music transcription) 的音乐信息提取任务则包含了对上述特征的提取要求[1][2]。
音乐结构特征则是建立在短程特征和中程特征上的结构性表达,并且也具有更宽的时间跨度,属于一种长程特征。音乐结构或者说曲式的分析是面向专业人士的应用,因为没有受过音乐专业训练的普通聆听者,缺少对曲式、乐曲风格的理解,通常也不具备主动式聆听(active 1istening)的情境,也没有分析曲式的需求。
音乐的特征是具有结构性的,分析音乐,必须在横向上结合时间维度上多个层次进行分析,同时在纵向上,需要结合各种音乐特征完成对音乐的分析。因此可以说CBMIR的研究对象是多维度、多层次的。不同的提取任务着眼于不同的维度,而近年来有将深度学习(deep 1earning) 和CBMIR相结合的学者提出的mu1tisca1e-1earning的方法[3],就是试图同时将多个维度上的信息同时建模。
2.3传统的CBMIR研究流程以及可能的改进方向
尽管CBMIR领域的应用类型非常多样,传统的CBMIR方法流程大致可以分为两步阶段:作为流程前端的特征提取阶段和作为后端的语义理解阶段。通过借助音乐领域知识和复杂的信号处理技巧,手工设计各种算法如MFCC,Constant-Q将音乐的信号的属性提取出来,这种通过被提取出来的属性一般称为描述元(descriptor) 或者特征(feature)。
这些统计量随后作为后端模式识别机的输入,并利用诸如统计学习、机器学习的各种浅结构模型如支持向量机(Support Vector Machine,SVM)贝叶斯网络(Bayesian Network)、条件随机域(Conditiona1 Random Fie1ds) 等进行各种分类和识别任务。
这种传统的CBMIR模式具有以下不足之处[4]:
●利用手工设计出来的寻找音乐特征,是一项对信号处理要求非常高的、繁重的工作。考虑到音乐的高维度特点,加上多信号的卷积增加了信号处理的难度,寻找到针对特定任务有较好效果的特征并不是一件容易的事情,且当应用需求改变的时候,特征也要重新调整,因此也不具有可持续性。
●浅结构处理架构的采用。浅结构对真实音乐信号的潜在的复杂度的建模显得力不从心,这个是由于低阶模型自身的原因造成的,而长期以来一直采用浅模型的原因主要是算法复杂度和计算开销上的限制造成的。一方面,设计有效的深度模型的计算模型的工作一直到有效的深度模型训练方法的出现才开始获得长足发展。而分布式计算理论和计算机硬件的同时发展也对深度模型的采用起到了相应的支撑作用。
●短时分析无法获取高阶信息。尽管音乐的语义特征的结构性是一个普遍共识,但是如何将短时隙上分析得到的特征进行组合来表示更长程的信息,一直以来学术界进行了不断尝试,比如将短时参数组合成更高维的特征向量的shing1ing方法[5],或者丢弃特征的时间结构特性,将一部分特征看出一族,在该函数族空间上建模的BoF方法[6],或者更直接的就是借鉴早期语音识别的常用方法,仍只处理短时特征,利用后端的例如最大似然方法(Maximum Like1ihood)将高层语义加入进行分类。以上这些方法各有利弊,也只获得了有限的应用。
针对上述不足,Dixon、Humprey、Die1eman等人提出了利用深度学习网络训练任务自适应的、结构化的音乐信号特征[7][8],通过将特征生成和模式分类结合成一个整体,改变了传统的基于内容的音乐信息提取的研究模式,代表了未来一种可能的发展方向。
3 CBMIR的研究内容
CBMIR的研究内容包含但不仅限于:基于音频的音乐流派分类(Audio Genre C1assification)、音频起点检测(Audio Onset Detection)、基于音频的演绎版本辨识(Audio Cover Song Identification)、哼唱识别(Query by Singing/Humming)、多基频估计与跟踪(Mu1tip1e Fundamenta1 Frequency Estimation&Tracking)、基于音频的和弦估计(Audio Chord Estimation)、基于音频的旋律提取(Audio Me1ody Extraction)、基于音频的节拍跟踪(Audio Beat Tracking)、基于音频的音乐相似性与提取(Audio Music Simi1arity and Retrieva1)、结构划分(Structura1 Segmentation)等。以下将就部分任务进行一些简要介绍。
3.1基于音频的音乐流派分类 (Audio GenreClassification)
基于音频的音乐流派分类,就是通过分析给定的音频样本,将音频所属的音乐流派进行正确归类。音乐流派分类可能是音乐信息提取领域得到最广泛和深度研究的一个子领域。流派分类的难度主要在于音乐流派分类体系本身就是存在一定的交叉性、模糊性和不定性。一般来说,学术界倾向于将音乐流派看作一个具有树状层次结构的体系[9]。
3.2哼唱识别 (QuerybySinging/Humming)
哼唱识别就是试验者通过麦克风提供一段哼唱旋律,算法能够根据该音频检索数据库里面的曲目,作为音乐信息提取领域在应用领域最早的探索之一,哼唱识别经历了研究的高潮和低潮。一方面的原因在于,这种应用有限的应用价值,以及使用者在提供哼唱样本的质量上差异过大,造成系统的识别率一直很难达到商业应用的要求[10]。
3.3基于音频的演绎版本辨识(AudioCover SongIdentification)
基于音频的演绎版本辨识任务就是给出一个检索音频,要求对比数据库中的曲目,找到该检索音频对应的曲目的不同演绎版本,本质上属于音乐的相似性检测问题[11]。由于一首歌曲的不同演绎版本存在各种可能,比如制作、配器、流派、演唱者/演奏者等,因此,如何描述不同演绎版本的相似性,是一个非常重要的问题。
3.4基于音频的节拍跟踪 (AudioBeat Tracking)
基于音频的节拍跟踪就是需要找到乐曲全部节拍所在的时间点,这个任务在几乎大多数节奏明显的流行音乐里面问题都不大,但是对于例如古典浪漫主义钢琴曲目则仍然是具有挑战性的任务。音乐节拍与人感知到的、可以利用敲击等方式跟随的节奏通常不是一回事,尽管这一点经常被混淆。与其相关的一个任务就是速度提取,事实上许多算法可以同时完成这两个任务。而在线的节拍跟踪(on1ine beat tracking)也是该领域的另一个方向。有关这个领域的一些算法也有相关的参考文献[12]。基于音频的节拍跟踪的算法评测仍然是与手工标注的评测集进行比较,节拍跟踪的应用场景主要是手势控制。
4 CBMIR的其他问题
近年来,机器学习领域有一个研究方向异军突起,这就是基于神经网络理论的方法,统称为深度学习。深度学习在自然语言理解、图像识别和语音识别领域取得了广泛的、巨大的成功,因而近年来也有越来越多的学者将深度学习方法引入到音乐信息提取领域,并取得了部分成果[13][14][15]。
基于音频的音乐信息提取研究,不但要求研究算法的准确性,召回率,在基于分类和相似性的任务中,还要研究算法的效率问题。因为基于音频的数据检索和信息提取是一个较为低效的过程。不但分类和识别算法本身需要处理的是音乐信号,在信号处理方面有一定的计算开销,在遍历匹配的时候也会产生巨大的开支,这个问题在商业应用领域变得由为重要。因此,如何建立音频的特征索引,如何高效的检索音频数据,是CBMIR领域的另一个研究重点[16],由于篇幅所限在此就不再展开了。
[1] M.Piszcza1ski and B.A.Ga11er,“Computer ana1ysis and transcription of performed music:A project report,”Comput Hum,vo1.13,no.3,pp.195-206,Ju1.1979.
[2] A.Dessein,A.Cont,and G.Lemaitre,“ Rea1-timePo1yphonicMusicTranscriptionwith Non-negative Matrix Factorization and Beta-divergence,”in Proceedings of the 11th Internationa1 Society for Music Information Retrieva1 Conference,ISMIR 2010,Utrecht,Nether1ands,August 9-13,2010,2010, pp.489-494.
[3] P.Hame1,S.Lemieux,Y.Bengio,and D. Eck,“Tempora1 Poo1ing and Mu1tisca1e Learning for Automatic Annotation and Ranking of Music Audio,”in Proceedings of the 12th Internationa1 Society for Music Information Retrieva1 Conference,ISMIR 2011,Miami,F1orida,USA,October 24-28,2011,2011,pp.729 -734.
[4]E.J.Humphrey,J.P.Be11o,and Y.LeCun,“Feature Learning And Deep Architectures:New Directions For Music Informatics,”Journa1 of Inte11igent Information Systems,vo1.41,no.3,pp.461-481,Dec. 2013.
[5] M.Casey,C.Rhodes,and M.S1aney,“Ana1ysis of minimum distances in high-dimensiona1 musica1 spaces,” Audio,Speech,and Language Processing,IEEE Transactions on,vo1.16,no.5,pp.1015 -1028,2008.
[6]S.Die1eman,P.Brake1,and B.Schrauwen,“Audio-based Music C1assification with a Pretrained Convo1utiona1 Network,”in 12th Internationa1 Society for Music Information Retrieva1 Conference,Miami (F1orida),USA,2011,pp.669-674.
[7]G.Tzanetakis and P.Cook,“Musica1 genre c1assification of audio signa1s,” Speech and Audio Processing,IEEE transactions on,vo1.10,no.5,pp.293 -302,2002.
[8]Eugene Weinstein,“Query By Humming:A Survey,”2005.
[9] J.Serrà,E.Gómez,and P.Herrera,“Audio Cover Song Identification and Simi1arity:Background,Approaches,Eva1uation,and Beyond,”in Advances in Music Information Retrieva1,Z.W.Ra's and A.A.Wieczorkowska,Eds.Springer Ber1in Heide1berg, 2010,pp.307-332.
[10] M.F.McKinney,D.Moe1ants,M.E. Davies,and A.K1apuri,“Eva1uation of audio beat tracking and music tempo extraction a1gorithms,”Journa1 of New Music Research,vo1.36,no.1,pp.1-16,2007.
[11]H.Lee,P.Pham,Y.Largman,and A.Y. Ng,“Unsupervised Feature Learning For Audio C1assification Using Convo1utiona1 Deep Be1ief Networks,”in Advances in Neura1 Information Processing Systems 22,Y.Bengio,D.Schuurmans,J.D.Lafferty,C.K.I. Wi11iams,and A.Cu1otta,Eds.Curran Associates,Inc., 2009,pp.1096-1104.
[12]F.Eyben,S.B?ck,B.W.Schu11er,and A. Graves,“Universa1 Onset Detection with Bidirectiona1 Long Short-Term Memory Neura1 Networks,”in Proceedings of the 11th Internationa1 Society for Music Information Retrieva1 Conference,ISMIR 2010,Utrecht, Nether1ands,August 9-13,2010,2010,pp.589-594.
[13]S.B?ck and M.Sched1,“Po1yphonic piano note transcription with recurrent neura1 networks,”in 2012 IEEE Internationa1 Conference on Acoustics, Speech and Signa1 Processing,ICASSP 2012,Kyoto, Japan,March 25-30,2012,2012,pp.121-124.
[14]W.Jeon,C.Ma,and Y.M.Cheng,“An Efficient Signa1-Matching Approach to Me1ody Indexing and Search Using Continuous Pitch Contours and Wave1ets,” in Proceedings of the 10th Internationa1 Society for Music Information Retrieva1 Conference,ISMIR 2009,Kobe Internationa1 Conference Center, Kobe,Japan,October 26-30,2009,2009,pp.681-86.
[责任编辑何一辉]
G434
A
1008-7656(2015)04-0080-06
2015-09-23
黄镭,广西广播电视大学教学资源中心助理研究员,硕士,研究方向:远程信息技术;邓明,广西广播电视大学教育技术中心助理工程师,研究方向:远程信息技术。
猜你喜欢
广西农学报(2023年2期)2023-07-13 23:55:30
家庭影院技术(2020年6期)2020-07-27 01:37:54
黄河之声(2020年5期)2020-05-21 08:25:02
家庭影院技术(2019年1期)2019-01-21 02:25:04
家庭影院技术(2018年11期)2019-01-21 02:20:52
家庭影院技术(2018年11期)2019-01-21 02:20:50
电子制作(2018年19期)2018-11-14 02:37:08
家庭影院技术(2018年10期)2018-11-02 05:35:26
电子制作(2017年9期)2017-04-17 03:00:46
37°女人(2016年7期)2016-07-07 11:34:21
