
基于评论分析的评分预测与推荐
2015-12-02 02:29高祎璠余文喆晁平复郑芷凌
华东师范大学学报(自然科学版) 2015年3期
高祎璠,余文喆,晁平复,郑芷凌,张 蓉
(华东师范大学 数据科学与工程研究院 上海高可信计算重点实验室,上海 200062)
1 简 介
推荐系统广泛地应用在网络平台中,如在线广告,在线购物等.它能够有效地预测用户的喜好,帮助用户找到适合的电影、书籍、音乐等产品.目前的研究重点是如何准确地发现用户偏好和商品画像,以提高推荐性能.总体来说,推荐方法可以分为两大类[1]:协同过滤方法和基于内容的推荐.传统的协同过滤方法是根据用户的历史行为,例如:评分或评论过的电影;曾经购买过的商品等;对用户-商品关系进行建模,认为具有相似喜好的用户在选择产品时具有相同的偏好.另一方面,基于内容的推荐是挖掘具有相同或相似属性的商品,从而进行推荐.然而,基于内容的推荐会产生推荐商品过于单一化的问题[2].随着Web的流行,消费者的反馈信息即评论(包括评分)对电子商务特别是推荐性能起到积极的影响.用户的评论相较于评分包含了更丰富的对商品的意见和观点,这为生成用户偏好和商品画像提供了更多的信息[3].反过来看,利用评论产生的用户偏好和商品画像则能够更好地解释消费行为和评分.本文在协同过滤方法的基础上,试图通过结合用户的评分和评论信息构建混合的分析模型,刻画用户-商品关系,实现更为准确的推荐.
本文利用评分和评论内容,设计并实现了一种新颖的评分预测模型.与传统的只考虑评分的方法不同,本文通过提取评论文本中的潜在主题特征来构建用户偏好和商品画像.首先利用主题模型发现评论中潜在的主题分布,然后采用回归模型,训练出每个潜在主题对评分产生的影响,即发现潜在主题与真实评分的关系.因此,当已知用户偏好和商品画像,本文提出的方法可以做出较准确的评分预测,然后将评分高的商品推荐给用户.
传统模型由于只考虑评分,常常会发生冷启动(cold start)的问题,即当用户没有或只有较少历史记录时,系统将无法进行有效的推荐.对评论中的评分特征进行提取之后,可以为生成用户偏好和商品画像提供更丰富的信息,从而缓解推荐冷启动问题.此外,潜在的主题分布也可用于对评论进行排序,选出具有代表性的评论优先展示给用户.
因此,本文的主要贡献总结是:①基于概率主题模型的评论分析,发现评论主题分布有助于对用户和商品的准确描述,也有利于解释消费行为和评分;②结合潜在主题与回归模型,从语义分析和数字打分两个方面同时分析各潜在主题对评分的影响,实现准确的评分预测;③本文提出的模型可缓解冷启动问题,尤其是对由于评分较少导致的冷启动问题;④对评论的选择和展示提出了新的解决方案;⑤最后,在真实数据上的大量对比实验证明,该模型具有非常良好的性能.
2 相关工作
现有的协同过滤技术[4-6]通过分析用户历史评分行为,预测用户对为评价过的商品的感兴趣程度,而不考虑评论文本.另一方面,已出现很多主题发现[7-9]、情感分析[10]和意见挖掘[11-12]等方向的评论文本分析的工作.然而,这些推荐研究都未将评分和评论相联系[13-14].文献[13]提出的评论打分模型结合了文本分析;文献[14]利用意见打包的形式对评论进行建模,相较于一元和多元模型更具表现力.文献将评分视为是由一系列预定义的主题获得的综合衡量,而主题是基于评论发现的.而以上模型未考虑用户与商品间的关系,故需要给出评论内容才能做出评分预测,这样就不能直接地应用到推荐系统中.此外,文献[13]中的方法是给出一些总结性的意见,来传达一个特定商品的一些信息.
与本文设计思路最相似的研究是,结合了评分和评论分析的HFT(Hidden Factors as Topics)商品推荐模型[3].HFT模型将评分中的隐藏因素和评论中的隐藏主题相融合,生成模型用户/商品画像,映射到SVD(Singular Value Decomposition)模型[6]中做出评分预测.然而,在HFT模型中,每条评论文本只能属于两个维度中的一个,也就是说,这条评论或是从商品角度来分析(属于商品的评论分类),或是从用户角度来分析(属于用户的评论分类).这就意味着,发现的潜在主题只能从一个方面来反映评分,而另一个维度必须与潜在因素空间对齐.为解决这个问题,本文提出的模型将两个维度映射到相同的潜在主题空间,支持分别从用户和商品的角度分析评论文本,达到更好的效果.
3 模 型
3.1 背景知识——LDA模型[15]
与概率潜在语义分析模型(pLSA)相类似,潜在狄利克雷分布模型(LDA)是一种概率生成模型[15].LDA认为每一篇文档d服从K维主题分布θ,而文档中的每一个词有概率φ的可能性属于主题k·LDA模型通过在文本和词之间引入主题维度,对向量空间进行降维.本文中LDA模型用于对用户评论信息的分析,发现评论中潜在的主题.
如图1所示,一篇文档可视为N个单词组成的有序序列,一个文档集包含M篇文档.α和β分别是文本中主题的分布θ和主题中词的分布φ的超参数,服从先验狄利克雷分布,其中z表示主题.文档集的处理和参数的选择是应用LDA模型的关键,在实验部分会进行讨论.

图1 LDA模型的图形表示Fig.1 Graphical model representation of LDA
3.2 评分预测流程
基于评论的评分预测实现步骤见图2(文章中使用的符号标记说明见表1),模型中具有两大功能模块:画像生成和评分预测.
画像生成:输入商品评论集{dui},分别生成用户u的偏好pu和商品i的画像qi.
评分预测:输入用户u和商品i,模型预测用户u对商品i的评分.
模型的输入是评论集合{dui}和评分矩阵;然后使用LDA模型发现评论文本中的潜在主题(K维)分布θui,在K维潜在主题上分别生成用户偏好pu和商品画像qi.将用户偏好和商品画像与评分矩阵相结合,基于回归模型进行主题权重分布训练.训练后的模型支持对用户没有评价过的商品进行评分预测.
3.3 画像生成
非结构化的评论文本包含了用户对商品不同主题维度的喜好和意见,这些潜在的主题能够很好地反映用户评分的潜在因素.通过对评论文本的分析,分别将用户和商品映射到相同的空间S·为了潜在主题发现和映射空间的构建,将公认度较高的文本分析和特征提取工具——LDA模型应用到评论文本分析中.

图2 评分预测流程Fig.2 Rating prediction flowchart
不同于HFT方法,本文将每一条用户u对商品i给出的评论dui视为一篇文档.对评论集{dui}应用LDA模型,θui表示dui生成的K维主题分布.用户u所有的评论集合定义为Du,Di是商品i获得的所有评论的集合.每一个用户u(或商品i)对应于偏好pu(或画像qi).给定一个用户u,定义用户偏好pu为

其中pu=(pu1,pu2,…,puk),puj是用户u在第j个主题上的分布,θuij是评论dui在第j个主题上的分布.类似的方法定义商品i的画像qi为

简单来说,pu和qi分别是用户u和商品i所有评论主题分布的正规化结果.

表1 符号表Tab.1 Table of notations
3.4 评分预测
给定用户u和商品i,预测用户u对商品i可能给出的评分r^ui,根据r^ui向用户推荐其未给出过评价的商品.预测评分时,将评论文本中发现的主题维度视为影响评分的潜在因素.评分预测模型利用线性回归和逻辑斯蒂回归模型建立评分与评论dui主题分布θui的关系.
线性回归作为标准的回归分析模型广泛地应用在实践应用中[16].假设因变量与自变量存在线性关系,参数严格但易于拟合.多项线性回归方法的评分预测函数定义是

其中W=(W1,…,WK),Wj是第j个主题的权重,εui是误差变量.
逻辑斯蒂回归是一种用于分类的概率统计模型.本文中的多项逻辑斯蒂回归通过将概率得分作为因变量的值,从而衡量一个绝对因变量和K个自变量间的关系[17].换言之,逻辑斯蒂回归就是建立预测评分与K维主题分布的关系.假设评分∈{1,2,…,N},建立多项式逻辑斯蒂回归

其中n=1,2,…,N-1,βn=(βn1,βn2,…,βnk)为权重集.
两种模型均采用最大后验概率(MAP)估计权重向量(W或者βn).
评分预测给定用户u和未评论过的商品i,基于用户偏好pu和商品画像qi,估计主题分布是
3.5 代表性评论选择
本文的工作除了能够支持评分预测之外,也可以辅助解决代表性评论选择的问题.一件商品(特别是热门商品)可能包含成百上千条评论,这为用户浏览增加了困难.目前的评论网站一般按照时间顺序组织评论内容,或者提供简单的评论关键字搜索,但是这并不能满足用户从大量评论数据中获取有用信息的需求.本文提出基于主题分布的代表性评论选择方案.评论代表性能力定义为评论商品特征的潜在主题分布与商品画像主题分布的“相近”程度,旨在选择最能体现商品特征的评论.一条评论rui与商品i“相近”程度的定义为

选出具有较小d(rui,i)的评论展示给用户,作为商品i的代表性评论.

4 实 验
实验环境:四核8线程i7处理器,1TB硬盘,8GB内存台式机一台.
编程语言:Java.
本章节中,R-Linear和R-Logistic分别代表本文提出的分析模型与线性回归和逻辑斯蒂回归结合进行评分预测的方法.
4.1 数据集
大众点评网作为国内最大的餐饮品鉴类网站,包含了丰富的评论数据,是评估本文系统性能的最佳选择.爬取的数据集包括上海地区47,942家餐厅的1,205,981条评论,共涉及373,021名用户,详细的数据统计展示在表2中.每条数据包含用户ID、评论时间、评论文本和1-5的数值评分.餐厅共涉及19个大类,表2中展示了其中具有代表性的10个类别,这些类别可作为子数据集进行性能评估,其中“其他”代表未详述的9类数据集合.一名用户可访问不同类别的餐厅,但一个餐厅只属于一种类别.数据集中包括非常受欢迎的本帮江浙菜,也包括数量最少的贵州菜.平均来说,每家餐厅收到25.1条评论,每个用户撰写了3.2条评论,每条评论包含119.4个中文词汇.
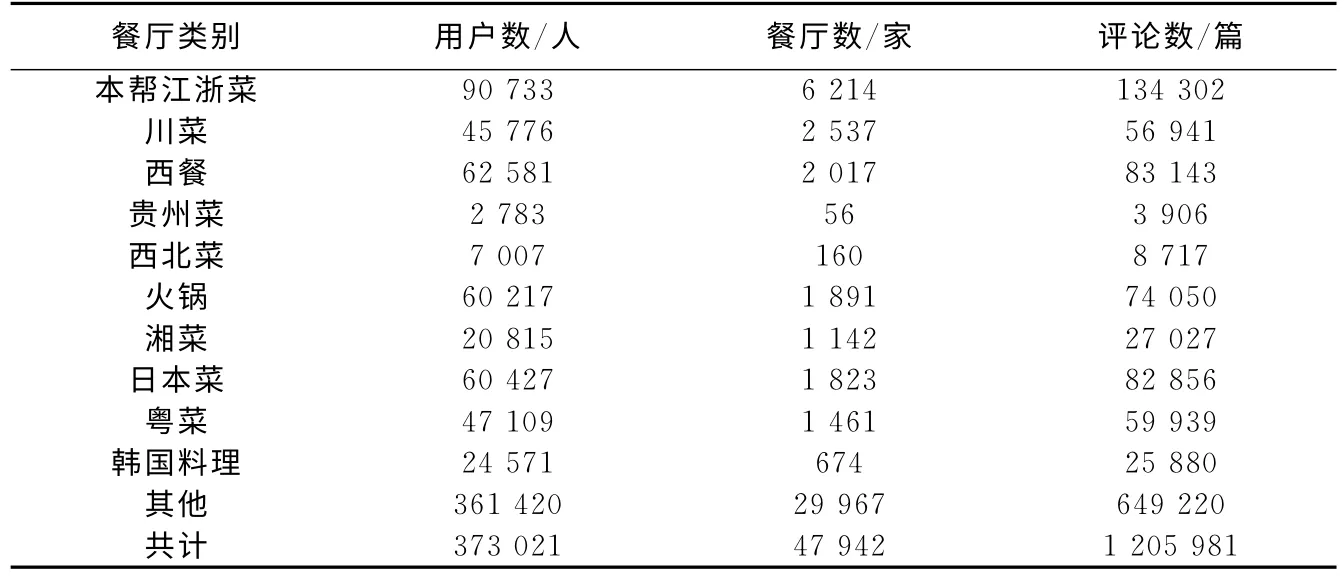
表2 分类别数据统计Tab.2 Data statistics on different category
将数据集按照9∶1的比例,划分为训练集和测试集.在测试集生成时,可采用两种方法进行划分:随机分配和时序分配.时序分配的方法认为较早的评论内容可能会对后续的评论产生影响,该方法根据评论时间选取最新的评论作为测试集,而随机分配方法不考虑时间因素而随机产生1/10的数据作为测试集.实验中共选取100 000条评论作为测试集.
4.2 评价指标
与HFT论文中方法相似,采用平均均方误差(MSE)来衡量预测评分与实际得分的误差
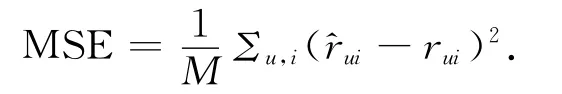
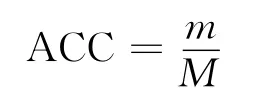
除了MSE,还引入了准确度(accuracy)来衡量评论预测的准确度,下式中m表示预测评分与实际评分一致的发生次数,即=rui.值得注意的是,实际得分只可能是1-5的整数,而线性回归方法得到的预测分数要进行取整后才能与实际得分rui相比较,实验中采用的是四舍五入法.
4.3 对比实现系统
正如相关工作中提到的,HFT将评论中潜在的主题与评分维度相结合,是与本文设计思路最为相似的模型.HFT由其作者提供的源码实现①http://www.cseweb.ucsd.edu/~jmcauley/..协同过滤方法(CF)假设有相似喜好的用户会选择相同的产品,而传统的CF是结合用户主观决定(比如评分)实现过滤.Slope One[18]是目前应用较为广泛的基于商品的协同过滤方法,具有简单和高效的优势,可由开源工具MyMediaLite 3.10[19]实现②http://www.mymedialite.net/index.html..实验中,会将以上两种方法作为性能测试的基准测试系统与本文提出的推荐策略进行对比.
4.4 LDA参数选择
超参数α和β分别取经验值0.2和0.1.分别对主题维度K取值5、10和20进行实验,线性回归结果展示在表3中.随着K数值的增长,系统性能逐步提高.然而,当K值从10增长到20,性能提高幅度较小.对实验结果进行核查,从主题关键词的分布可以看出,K=10时主题划分较为清晰.实验中选取K=10为默认主题数目,每个主题中频繁出现的10个代表词汇如表4所示.为LDA能够在评论数据上快速收敛,迭代次数设置为100.

表3 不同主题数目下结果对比Tab.3 Results with different topic numbers

表4 当K=10时,各主题中频繁出现的10个代表词汇Tab.4 Top ten words for each topic with K=10
4.5 结果和分析
首先,实验比较了我们的方法与Slope One和HFT方法的MSE结果.如图3所示,本文的方法表现的更加优异,线性回归方法效果最好,能够达到最小的MSE,随机分配(时序分配)方法相较于HFT降低了34%(49%).

图3 MSE结果对比Fig.3 MSE values
图4是评分预测准确度的对比结果.实际评分取值是1-5的整数,而Slope One、HFT和线性回归方法得到的预测评分均为小数,为计算ACC需将结果就近取整.逻辑斯蒂回归作为聚类模型,可以得到整数的预测评分.从结果来看,Slope One表现最好,本文的方法其次.测试集随机分配情况下,线性回归与逻辑斯蒂回归方法相差无几.整体来看,随机分配方法的评分预测性能优于时序分配方法.以下实验均采取随机分配的数据划分方法.

图4 ACC结果对比Fig.4 ACC values
在各种测试情况下,Slope One均表现出较好的性能,但是作为标准的CF(协同过滤)方法,它会受到数据稀疏性带来的严重影响.当数据稀疏时,CF方法预测结果的准确度难以得到保证.在表2中的10个类别的子数据集上,对各种方法进行实验,结果如图5和图6所示.可以明显地看出,线性回归方法在所有情况下都表现的最好,但是当数据稀疏时,如贵州菜,Slope One的效果发生了巨大的波动.实验证明,本文提出的方法相较于CF方法具有更好的稳定性,在数据稀疏的情况下亦能得到较好的MSE和ACC结果.

图5 10种类别的MSE对比Fig.5 MSE of 10 various categories
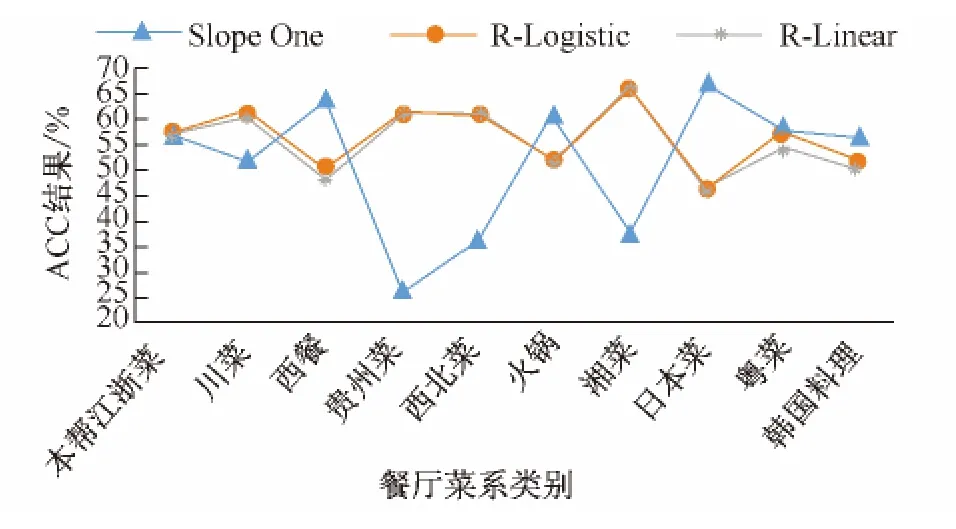
图6 10种类别的ACC对比Fig.6 ACC of 10 various categories
4.6 讨论
冷启动是推荐系统常见的问题.少量的数据导致模型难以训练,系统难以对新用户做出推荐.引入评论内容,丰富已知信息,是冷启动问题的解决办法之一.另一方面,对用户偏好和商品画像进行建模,相较于其他随机方法,能够更加准确地获得对象的属性,有助于模型的训练.CF作为传统推荐方法,有较好的推荐效果,但是受到数据稀疏情况的巨大限制.已有工作将CF方法与基于内容分析的方法相结合,本文提出的基于内容分析的商品和用户画像分析技术与最新的HFT方法相比,已经具有较大的优势,同时我们与传统的CF相比,拥有较好的稳定系,因此后续可以考虑把我们的方法与CF方法结合使用.
4.7 代表性评论选择
当系统将一件商品推荐给用户时,用户会通过阅读评论来了解该商品.图7中显示的是餐厅平均评论数目的分布.首先将餐厅按照评论数目进行降序排列,前10%的餐厅平均拥有超过180条的评论,半数以上的餐厅评论数目超过50条.为方便用户的浏览,代表性评论的选择是非常必要.本文提出了基于商品画像的代表性评论选择方法.如图8中案例,老板娘海鲜大排档的主题分布描述为(0.05,0.07,0.13,0.05,0.21,0.11,0.01,0.13,0.06,0.15),表中展示了本文方法选取出的具有代表性的前五条评论,评论内容是极能表现餐厅概况的.虽然还可以从覆盖度和多样性[20]等方面对代表性评论做出选择,但该方法为评论选择提供了新的参考因素.

图7 餐厅评论分布Fig.7 Restaurant review distribution
5 总 结
本文提出了一种同时利用评分和评论分析的商品推荐模型.利用评论文本中的潜在主题分布,将用户和商品映射到统一的空间中,分别生成了用户偏好和商品画像.评分预测模型建立在回归模型之上,将主题分布与预测评分相拟合.根据预测评分做出商品推荐.并且本文提出的方法能从语义上支持代表性评论选择的实现.实验证明,本文提出的评分预测方法表现出稳定良好的性能,特别是针对稀疏性数据.未来的工作中将会考虑把本方法与协同过滤方法相结合,实现更为优良的性能.

图8 代表性评论选择实例Fig.8 Representative review example
[1]RAJARAMAN A,ULLMAN J D.Mining of Massive Datasets[M].London:Cambridge University Press,2011.
[2]BLANCO-FERNÁNDEZ Y,PAZOS-ARIAS J J,GIL-SOLLA A,et al.A flexible semantic inference methodology to reason about user preferences in knowledge-based recommender systems[J].Knowledge-Based Systems,2008,21(4):305-320.
[3]MCAULEY J,LESKOVEC J.Hidden factors and hidden topics:understanding rating dimensions with review text[C]//Proceedings of the 7th ACM conference on Recommender systems.ACM,2013:165-172.
[4]SARWAR B,KARYPIS G,KONSTAN J,et al.Item-based collaborative filtering recommendation algorithms[C]//Proceedings of the 10th international conference on World Wide Web.ACM,2001:285-295.
[5]KOREN Y,BELL R,VOLINSKY C.Matrix factorization techniques for recommender systems[J].Computer,2009,42(8):30-37.
[6]KOREN Y,BELL R.Advances in collaborative filtering[M]//KANTOR P B,RICCI F,ROKACH L,et al.Recommender Systems Handbook.New York:Springer,2010:145-186.
[7]BRODY S,EIHADAD N.An unsupervised aspect-sentiment model for online reviews[C]//Human Language Technologies:The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics.Association for Computational Linguistics,2010:804-812.
[8]JO Y,OH A H.Aspect and sentiment unification model for online review analysis[C]//Proceedings of the fourth ACM international conference on Web search and data mining.ACM,2011:815-824.
[9]TITOV I,MCDONALD R.Modeling online reviews with multi-grain topic models[C]//Proceedings of the 17th international conference on World Wide Web.ACM,2008:111-120.
[10]TITOV I,MCDONALD R T.A Joint Model of Text and Aspect Ratings for Sentiment Summarization[C]//ACL,2008(8):308-316.
[11]POPESCU A M,ETZIONI O.Extracting product features and opinions from reviews[M]//KAO A,POTEET S R.Natural Language Processing and Text Mining.London:Springer,2007:9-28.
[12]PANG B,LEE L.Opinion mining and sentiment analysis[J].Foundations and Trends in Information Retrieval,2008,2(1-2):1-135.
[13]QU L,IFRIM G,WEIKUM G.The bag-of-opinions method for review rating prediction from sparse text patterns[C]//Proceedings of the 23rd International Conference on Computational Linguistics.Association for Computational Linguistics.2010:913-921.
[14]GANU G,ELHADAD N,MARIAN A.Beyond the stars:Improving rating predictions using Review text content[C]//WebDB,2009.
[15]BLEI D M,NG A Y,JORDAN M I.Latent dirichlet allocation[J].The Journal of Machine Learning Research,2003,3:993-1022.
[16]BAMMANN K.Statistical models:theory and practice[J].Biometrics,2006(62):943.
[17]BISHOP C M.Pattern recognition and machine learning[M].New York:Springer,2006.
[18]LEMIRE D,MACLACHLAN A.Slope one predictors for online rating-based collaborative filtering[C]//SDM,2005,5:1-5.
[19]GANTNER Z,RENDLE S,FREUDENTHALER C,et al.MyMediaLite:A free recommender system library[C]//Proceedings of the fifth ACM conference on Recommender systems.ACM,2011:305-308.
[20]TSAPARAS P,NTOULAS A,TERZI E.Selecting a comprehensive set of reviews[C]//Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM,2011:168-176.
猜你喜欢
黄河之声(2022年10期)2022-09-27
小哥白尼(神奇星球)(2022年3期)2022-06-06
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
中学生数理化(高中版.高二数学)(2022年4期)2022-05-25
新世纪智能(高一语文)(2020年9期)2021-01-04
非公有制企业党建(2020年10期)2020-10-27
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
中学生数理化·八年级物理人教版(2017年11期)2017-04-18
小学教学参考(2015年20期)2016-01-15
