
一种基于LDA模型的关键词抽取方法
2015-10-13 03:22朱泽德李淼张健曾伟辉曾新华
中南大学学报(自然科学版) 2015年6期
朱泽德,李淼,张健,曾伟辉,曾新华
一种基于LDA模型的关键词抽取方法
朱泽德1, 2,李淼2,张健2,曾伟辉2,曾新华2
(1. 中国科学技术大学自动化系,安徽合肥,230026 2. 中国科学院合肥智能机械研究所,安徽合肥,230031)
为解决现有方法未能综合考察文档主题的全面性、关键词的可读性以及差异性,提出一种基于文档隐含主题的关键词抽取新算法TFITF。算法根据大规模语料产生隐含主题模型计算词汇对主题的TFITF权重并进一步产生词汇对文档的权重,利用共现信息排序和选择相邻词汇形成候选关键短语,再使用相似性排除隐含主题一致的冗余短语。此外,从文档统计信息、词汇链和主题分析3方面来进行关键词抽取的对比测试,实验在1 040篇中文摘要及5 408个关键词构成的测试集上展开。结果表明,算法有效地提高文档关键词抽取的准确率与召回率。
信息抽取;关键词抽取;LDA模型;主题相似性
关键词多为几个词或短语构成的文档内容概要,关键词抽取是信息时代人们从海量文档数据中快速、准确地掌握感兴趣内容的重要途径。关键词抽取也称关键词标注,被大量用于文档摘要、文本分类、信息过滤和全文检索等文本处理领域。随着Web2.0时代的到来,关键词抽取被注入新的活力,网站标签的自动推荐系统为关键词抽取提供了广阔的应用空间。近年来,文档隐含主题分析被研究者大量应用于自然语言处理领域,该技术在关键词抽取方面也发挥了重要的价值。Chen等[1]利用候选关键词的潜在语义索引权重频率来选择关键词,Liu等[2]根据文档主题和候选关键词主题分布的相似度抽取关键词。此类方法通过大规模文档集合学习隐含主题,避免了单篇文档信息不足的缺陷。然而在主题层次推荐的关键词倾向于主题常用词,无法全面覆盖文档的主旨信息;单个词汇表达主题的准确性不强,推荐的关键词可读性较差;同义词或近义词与文档有相似的主题关系,导致推荐的关键词出现冗余,无法实现词汇的差异性。针对上述问题,以文档隐含主题分析为基础提出一种新的关键词抽取算法词频−逆主题频率(TFITF),该算法基于LDA(latent dirichlet allocation)模型对文档主题分布进行分析,在关键词与文档主题一致的条件下增强词汇对不同主题的表征性,选取能够充分反映文档主题且富含更多信息的短语作为候选关键词,并进一步根据词汇的主题分布的相似性消除冗余短语。此外,从文档统计频率信息和词汇链2个方面选择关键词与主题分析进行实验对比。
1 相关工作
关键词抽取方法可分为有监督和无监督2类,有监督方法将关键词抽取看成二元分类问题:训练时提取关键词特征构造分类模型,分类时根据模型判断词语是否为关键词。李素建等[3]采用最大熵模型抽取关键词;Nguyen等[4]利用显著的形态特征抽取科学文献关键词;Treeratpituk[5]使用随机森林识别关键词;为改变分类方法无法区分关键词代表文档的强弱,Jiang等[6]提出学习产生排序器来排序不同的候选关键词。然而有监督方法标注训练集耗时耗力,分类器受限于特定领域且存在过拟合问题。
无监督方法涉及统计方法、图模型和语义方法。统计方法主要利用词频、词频-逆文档频率、词性、词语位置、词语同现频率等信息抽取关键词;Liu等[7]将关键词抽取作为文档到关键词的翻译。在图模型的研究中,Mihalcea等[8]基于词汇的共现链提出TextRank模型排序关键词;Wan等[9]根据邻近文档知识将TextRank扩展成ExpandRank;Litvak等[10]将网页排序的HITS算法引入关键词抽取;李鹏等[11]在TextRank基础上通过Tag引入相关文档来估计词项图的边权重并计算词项的重要度;Bougouin等[12]将词汇聚类后作为TextRank图的顶点。在语义的方法中,隐含主题[1−2]通过分析候选关键词的主题分布抽取关键词;胡学钢等[13]利用词语在文档中语义联系将文档表示成词汇链形式抽取关键词。
基于语义的方法是一种重要的无监督方法,因无需标注文档的关键词作为训练集,又有效利用外部知识辅助关键词抽取。因此,目前关键词抽取研究广泛关注语义的方法。本文也在隐含主题模型分析文档语义的基础上,针对现有方法无法现实文档主题全面性、关键词可读性和差异性的综合考察,提出关键词抽取算法TFITF模型。
在此,重点介绍本文实验对比中的3个经典无监督模型。
TFIDF模型词汇的TFIDF权重与词汇在文档中出现的频率成正比,与词汇在所有文档中出现的频率成反比:
其中:N为词汇在文档中出现次数,N为文档中所有词总数,为文档集中所有文档的数目,D为包含词汇的所有文档数目。
TextRank模型 借鉴于网页排序的PageRank算法,TextRank将文档看作一个词的网络,网络链接表示词v与词v之间的语义关系。TextRank认为一个词的重要性S(v)由链向它的其他词的重要性决定:
其中:w为顶点v和v的权重;数值由1个窗口内共现次数确定;A(v)为邻近顶点集;为衰减因子,设置为0.85。
ExpandRank模型 通过邻近文档扩展更多的知识提高关键词抽取的准确性。针对文档d先用余弦相似性从文档集中选择个近邻的文档,共现词汇链由1个文档构建。文档用1个TFIDF计算词权重的词向量表示,给定文档d和个邻近文档构成+1个文档集,={0,1,2,…,}。顶点来自中词汇,窗口内共现词汇v和v顶点链接构成边,边的权重(v,v)为
其中:simdoc(0,d)为文档0和d的余弦相似性;countdp(v,v)为文档d中词汇v和v的共现次数。
2 关键词抽取
文档的关键词集合应具备完备性、确定性和独立性,即关键词的全体能够全面覆盖文档的主题信息,每个关键词应能表达准确的意义,同时关键词间应具有一定的差异性。本节主要阐述为保持关键词集合具备上述特征而提出的TFITF模型具体计算方式,该模型先根据TFITF权值计算候选关键词对文档的权重,随后根据同现率合并相邻候选关键词再按权重大小排序,最后根据短语的主题分布消除冗余。
2.1 LDA模型
LDA作为一种主题模型被广泛地用于自然语言处理[14−15],实现对文本数据的主题信息进行完全建模。LDA模型包含词、主题和文档三层结构,如图1所示。LDA最早是Blei等[16]以pLSI为基础,提出一个服从Dirichlet分布的维隐含随机变量表示文档的主题概率分布,模拟文档的产生过程;Griffiths等[17]对参数施加Dirichlet先验分布,使得LDA模型成为一个完整的生成模型。
图1中:φ为主题中的词汇概率分布,θ为第篇文档的主题概率分布,φ和θ服从Dirichlet分布,φ和θ作为多项式分布的参数分别用于生成主题和单词;和分别为φ和θ的分布参数,反映了文档集中隐含主题间的相对强弱,为所有隐含主题自身的概率分布;为主题数目;为文档集中文档数目;N为第篇文档的词总数;ω和Z分别为第篇文档中第个单词及其隐含主题。
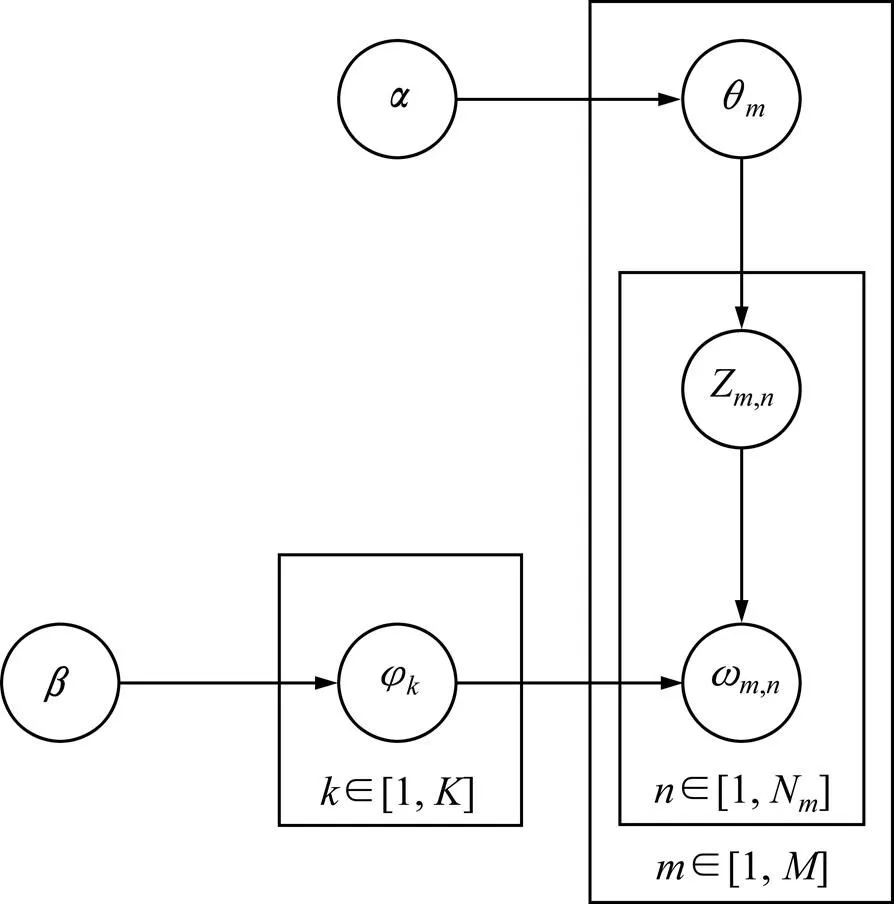
图1 LDA的图模型
2.2 TFITF模型
TFITF模型在分析文档主题信息的基础上进行文档关键词抽取,基本流程如图2所示,主要分为以下5个步骤;
1) 预处理:为排除无关信息对训练主题模型和关键词抽取的干扰,依据关键词多为名词性短语的特点,对训练主题文档和待抽取关键短语文档分别进行分词、词性标注和选取名词与形容词等预处理。
2) 主题分析:利用训练文档集产生主题模型,预测新文档集的词汇对主题的权重以及主题对文档的权重。
3) TFITF权值计算:根据词汇对主题的权重以及词汇在所有主题中出现频率计算词汇对主题的TFITF权值,并进一步计算词汇对文档的权重。
4) 词汇合并:利用词性搭配规则从未预处理的原始文档筛选出二元候选短语,根据候选短语中各词汇的共现率以及候选短语权重计算短语构成候选关键短语的权值,对预处理文档中二元短语进行排序形成候选关键短语集合{H}。
5) 冗余消除:根据短语的主题分布筛选{H}权值较大且反映文档不同子主题的个短语构成关键词短语输出。
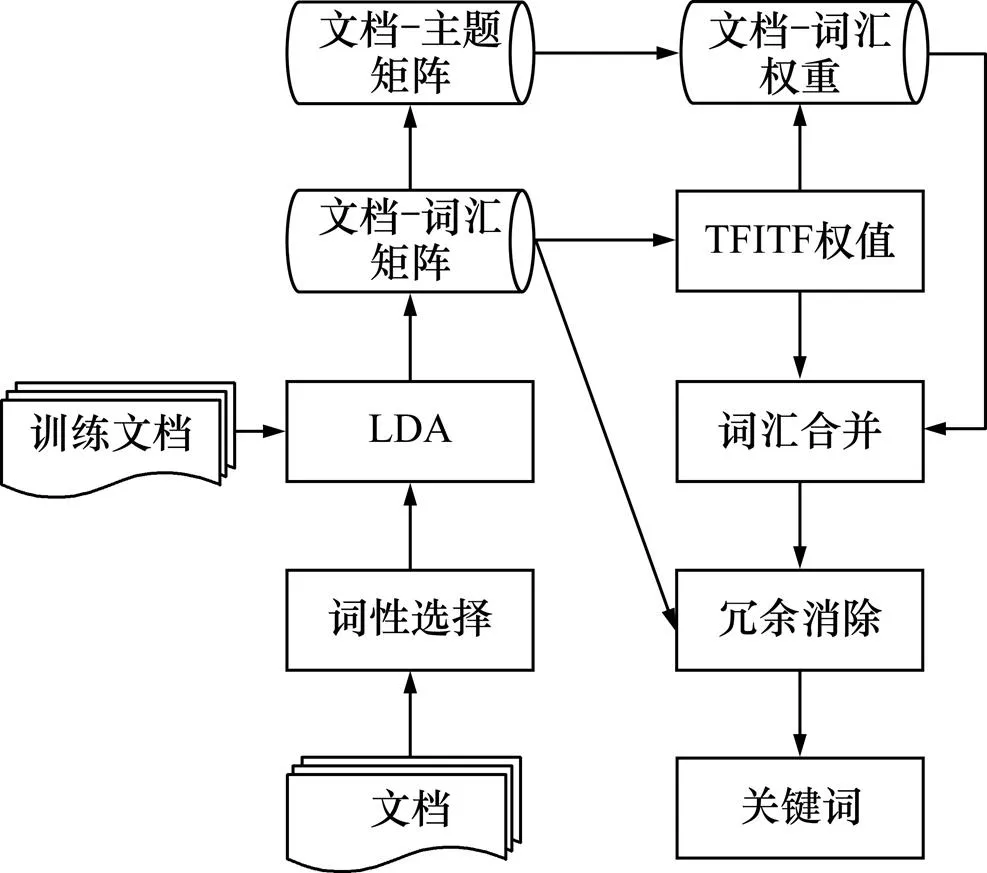
图2 基于TFITF的关键词提取流程
本小节后续内容重点讲述以上TFITF权值计算、词汇合并以及冗余短语消除三步骤的具体实现方法。
2.2.1 TFITF权值计算
选择Collapsed Gibbs采样法抽取文档集的主题模型,具体实现通过每个单词的主题进行采样,在获得单词ω的主题标号的条件下,计算主题Z中词汇的概率为
文档D中主题Z的概率为
其中:C为语料库中词被赋予主题Z的次数,C为文档d中词被赋予主题Z的次数。
词汇权重不仅与单一主题相关,也与所有主题集合相关。类比TFIDF模型的思想,词汇对主题的权值TFITF定义为与词汇在主题中出现的概率成正比,与词汇在所有主题中出现的频率成反比。其中,词频(TF)为词汇对主题的频率,词汇对主题Z的词频Tf取为φ,反映词汇对主题Z的重要性;逆主题频率(ITF)为词汇对所有主题的逆主题频率,避免了某些词汇出现在主题的频数过高而降低对不同主题的区分能力,n对Z的逆主题频率如下式计算:
则在给定词汇条件下,对主题Z的TFITF权重定义为:
其中:为词汇对主题的噪声阈值。在LDA概率主题模型中,所有词汇都以一定的概率出现在每个主题,小概率的词汇无法体现主题的实际内容且构成计算相似度的“噪音”。实验中设定阈值为0.005,即若φ<,则认为主题Z不体现在词汇上。
根据对主题Z的权重,结合主题Z在文档D的概率θ,词汇对文档D的权重计算公式如下:

2.2.2 词汇合并
短语比单个词汇具有更强的可读性和语义的完整性,能准确地表达文档的主旨信息。根据大部分手工标注的关键词为二元结构的名词短语,文中构成名词短语的搭配模板采用“名词+名词”或“形容词+名词”的结构。
为检测搭配模板构成短语的可能性,针对短语的内部词汇计算共现概率,通过共现概率的大小反映不同词汇间相关性的强弱。当2个词汇的共现概率越高,它们具有的相关性越强,构成短语的可能性越大。选择待抽取关键词文档中满足搭配模板的词汇1和2,计算构成候选短语的可能性如下式:
其中:(1,2)为1和2在待抽取关键词文档中满足词法构成规则共现的次数,(ω)(=1,2)为词ω在待抽取关键词文档中出现次数。
根据的构成词汇ω对文档D的权重,按式(10)计算对D的权重(|D)。
候选短语对文档D的综合权值P(|D)融合了自身构成的可能性和对D的权重,如式(11)计算。
(11)
根据综合权重大小排序二元短语构成形成候选关键短语集合{H}。
2.2.3 冗余短语消除
关键词集合中所有词汇或短语应尽可能反映文档的不同主题或从不同的角度反映文档主题,避免出现同义或近义的冗余短语。短语对主题Z的权值定义为所有构成词汇ω对主题的乘积,如式(12)所示。
根据贝叶斯公式计算短语的主题Z概率为:
其中:参数(Z)/()近似为训练集中主题Z出现的次数N除以出现的次数N。
由式(13)计算短语对各主题的分布(|),候选关键词集合{H}中的词汇或短语H和的相似性由主题分布的余弦来衡量,如下式:
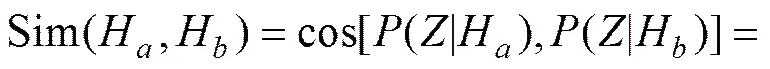
利用短语的相似性排除{H}中与权值较大的短语相似度过高的短语,形成新的候选关键短语集合{H′}。当限制关键词输出数目时,则截断输出{H’}中权值排序较大的短语形成关键词集合。
3 实验
3.1 实验数据与评价
选取硕博论文数据进行关键词抽取实验,数据由1 040篇论文摘要构成,涵盖了基础科学、工程科技、农业科技、医药卫生科技、哲学与人文科技、社会科学、信息科学和经济科学领域,手工标注了5 408个关键词,平均每篇文档关键词个数为5.2,数据集称为THESIS。对THESIS中的文档进行分词和词性标注,过滤停用词,将名词、动词和形容词作为候选关键词。因THESIS包含文档数较少,不足以训练隐含主题模型,在THESIS的基础上增加网络获取的中文新闻语料,过滤长度小于200个词的短小文本,得到10 640篇文档训练隐含主题模型。
实验采用准确率、召回率和1(Precision/Recall/F1-Measure)来评价关键词抽取的效果。correct/extract,correct/standard,1/ ()。其中,correct为正确抽取的关键词数目,extract为所有抽取的关键词数目,而standard为所有人工标注的标准关键词数目。
3.2 结果和分析
为测试本文提出的关键词抽取算法的性能,计算了TFITF模型抽取文档关键词的准确率和召回率,并同词汇频率信息、词汇链信息、扩展词汇链信息其他3个无监督算法进行对比,最后进一步阐述了各算法的参数选择依据。
3.2.1 实验对比
实验中采用的文档关键词抽取的无监督算法分别为:
1) TI1:基于词频−逆文档频率TFIDF的关键词抽取,文档集的词汇频率信息;
2)TR:基于TextRank的关键词抽取,单文档的局部词汇链关系;
3) ER:基于ExpandRank的关键词抽取,扩展邻近文档的局部词汇链关系;
4) TI2:基于词频−逆主题频率TFITF的关键词抽取,训练集的全局词汇关系;
上述各算法对文档的关键词抽取的准确率−召回率曲线如图3所示。在每条准确率−召回率曲线上,每个点代表推荐不同的关键词数目时的评价结果,从左上=1至右下=15,曲线越靠近右上方,说明算法的效果总体越优。每一算法都为参数调整后的最优结果,对于TR设置窗口为6,ER设置近邻文档数为1,TI2设置隐含主题数为200。
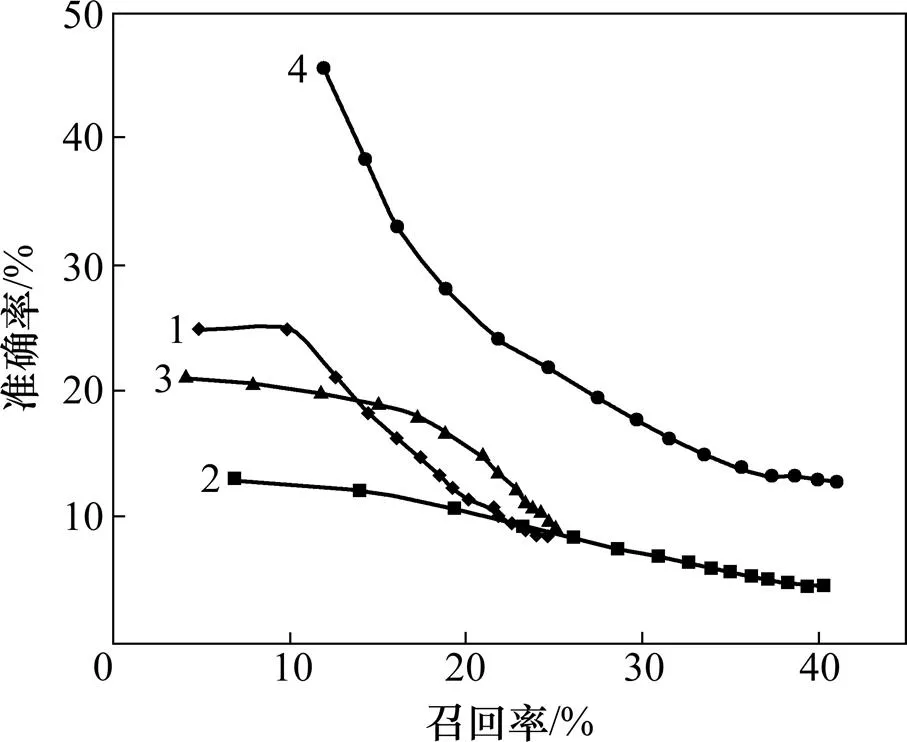
1—TI1;2—IR;3—ER;4—TI2
由图3可知:算法TI1虽在几种无监督算法中最易实现,但在抽取文档中少量的关键词时TI1的准确率优于算法TR和ER;随着关键词数量的增长,算法的准确率迅速下降,同时召回率增长缓慢,反映了TI1在抽取的关键词数量增多时正确抽取的关键词数量增幅较小。TI1通过统计文档集中词汇出现的频率信息抽关键词,对部分高频的关键词反应敏感。
算法TR抽取关键词的召回率同TI1基本一致,准确率在抽取的关键词数量增加时略优于TI1。TR通过词汇在文档中出现的连续性建立词汇链,词汇的关联信息局限于单个文档,无外部知识进行补充和修正,且仅仅从词汇的层面分析重要性,制约了文档抽取关键词的效率。
算法ER扩展于TR,然而ER抽取关键词的准确率最低,ER采取的策略是在文档层面引入外部资源,供词汇共现信息来进行分析。然而文档集中相关性较弱会导致大量无关的噪音产生;召回率在抽取的关键词数量增加时有较快的增长。
算法TI2抽取关键词的准确率和召回率都明显优于其他无监督算法。TI2通过大量的数据集产生主题信息,并强化词汇对不同主题的区分性,进一步结合待抽取关键词文档的词汇共现信息和词汇间相关性信息。该方法综合了文档隐含主题信息和文档词汇信息实现了关键词抽取,一方面使关键词对文档主题具有良好的覆盖度,另一方面避免了被抽取的关键词趋向主题的常用词。
3.2.2 参数选择
分别考察了带参数的单一无监督算法TR,ER和TI2中参数对关键词抽取的影响,为3.2.1节中各组合方式中参数选择提供依据。
图4所示为TR模型中窗口大小取2,4,6和8情形时,关键词数从1增长至15的过程中准确率−召回率曲线随关键词数目从左上渐变至右下。当窗口增长至8时,抽取的性能与为6时基本保持一致,却增加了系统的时间消耗,因此确定最优为6。
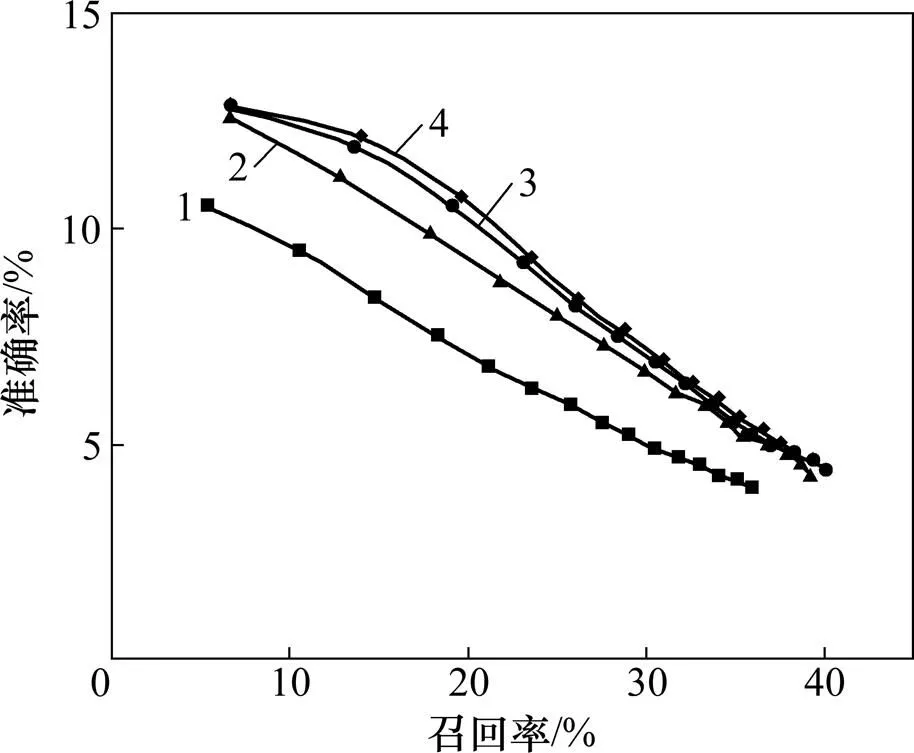
w:1—2;2—4;3—6;4—8
图5所示为取6,ER的邻近文档数分别为0,1和2时,准确率−召回率曲线图从左上递渐变至右下,当为1时,算法获得最佳的效果。当邻近文档数继续增长时性能下降,主要因ER是在文档层面引入外部知识,导致无关的噪声引入,取决于文档集中文档间的相关程度。
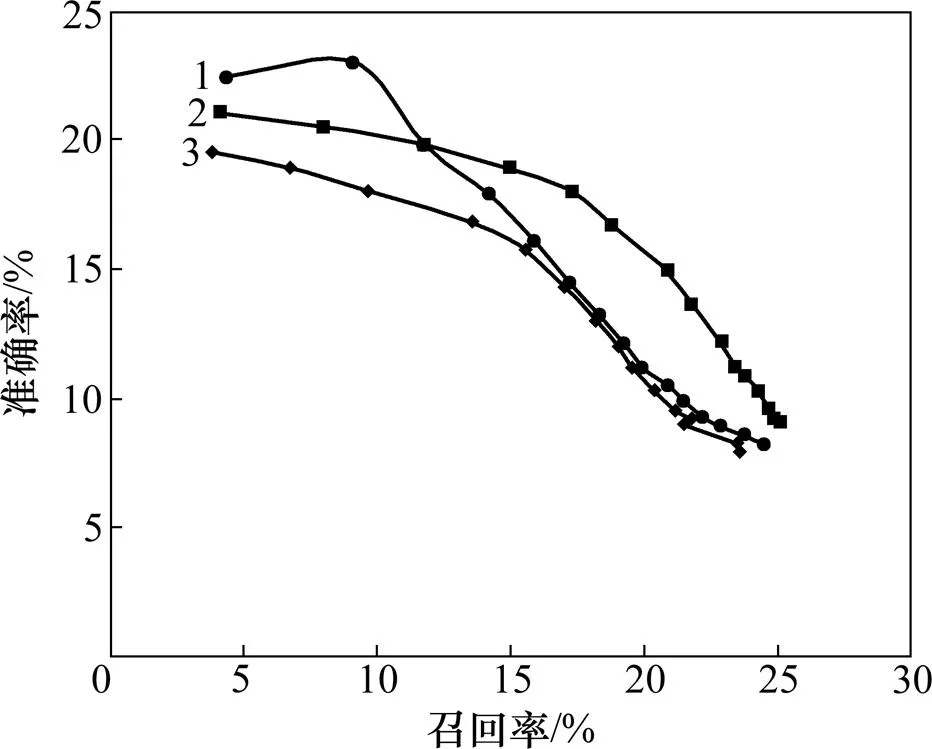
h:1—0;2—1;3—2
Fig. 5 Precision−recall curves of ER adopting nearest neighbor documentsas 0, 1 or 2
图6所示为随隐含主题个数不同,TI2抽取关键词的性能随着主题个数变化波动较小,这表明TI2利用文档和词汇的主题分布进行关键词抽取的鲁棒性高,在达到200时模型的性能基本稳定,增至300时几乎不再提高。
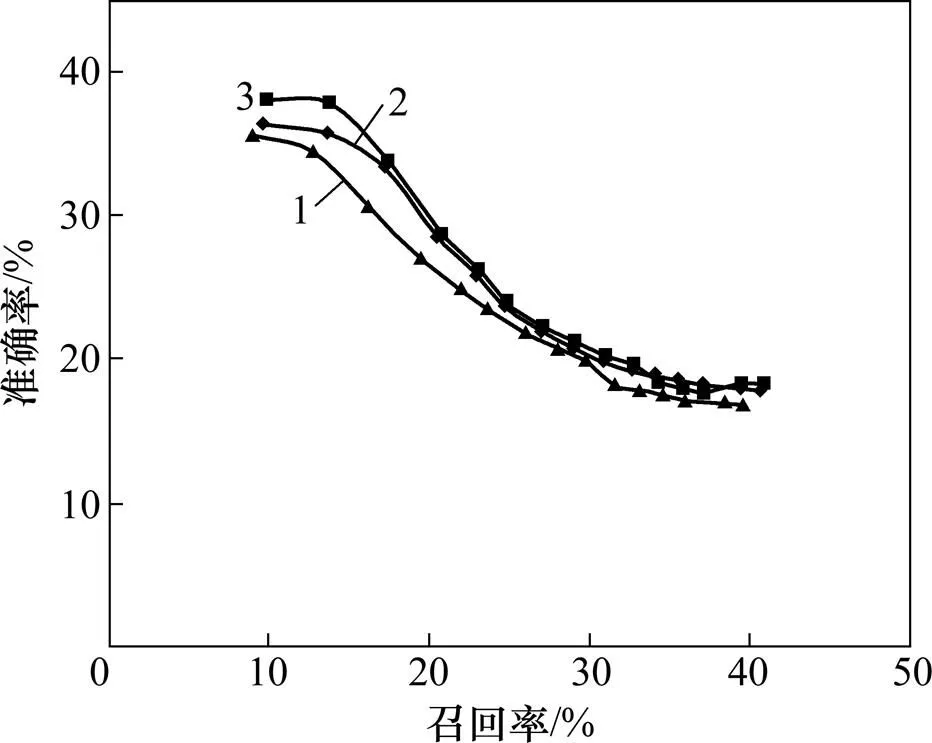
k:1—100;2—200;3—300
4 结论
针对传统的无监督方法抽取关键词未能很好地解决关键词未能全面和准确地覆盖文档主旨信息,提出了一种基于LDA模型的TFITF算法抽取关键短语,该方法通过增强词汇对不同主题的表征能力,避免推荐关键词汇倾向于常用词;再根据相邻词汇的共现率和权重合并产生候选关键短语,提高对关键词的信息量和可读性;最后利用不同短语描述不同的主题信息,排除关键词组合的冗余性。通过同现有无监督关键词抽取算法的对比测试,实验显示了很好的效果。
如何在词汇层面引入更精准的外部信息,避免从文档层面或主题层面导致主题漂移,是今后改进和完善关键短语提取方法的重点。
[1] CHEN Jilin, YAN Jun, ZHANG Benyu, et al. Diverse topic phrase extraction through latent semantic analysis[C]// Proceedings of the Sixth International Conference on Data Mining. IEEE, 2006: 834−838.
[2] LIU Zhiyuan, SUN Maosong. Domain-specific term rankings using topic models[M]. Berlin Heidelberg: Springer, 2010: 454−465.
[3] 李素建, 王厚峰, 俞士汶, 等. 关键词自动标引的最大熵模型应用研究[J]. 计算机学报, 2004, 27(9): 92−97. LI Sujian, WANG Houfeng, YU Shiwen, et al. Research on maximum entropy model for keyword indexing[J]. Chinese Journal of Computers, 2004, 27(9): 92−97.
[4] Nguyen T D, Kan M Y. Keyphrase extraction in scientific publications[M]. Berlin Heidelberg: Springer, 2007: 317−326.
[5] Treeratpituk P, Teregowda P, Huang J, et al. Seerlab: A system for extracting key phrases from scholarly documents[C]//Proceedings of the 5th International Workshop on Semantic Evaluation. Association for Computational Linguistics, 2010: 182−185.
[6] Jiang X, Hu Y, Li H. A ranking approach to keyphrase extraction[C]//Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval. ACM, 2009: 756−757.
[7] LIU Zhiyuan, CHEN Xinxiong, ZHENG Yabin, et al. Automatic keyphrase extraction by bridging vocabulary gap[C]// Proceedings of the Fifteenth Conference on Computational Natural Language Learning. Association for Computational Linguistics, 2011: 135−144.
[8] Mihalcea R, Tarau P. TextRank: Bringing order into texts[C]//Proceedings of the Conference on Empirical Methods in Natural Language Processing. Association for Computational Linguistics, 2004.
[9] WAN Xiaojun, XIAO Jianguo. Single document keyphrase extraction using neighborhood knowledge[C]//Proceedings of the 23rd National Conference on Artificial Intelligence. American Association for Artificial Intelligence, 2008: 855−860.
[10] Litvak M, Last M. Graph-based keyword extraction for single-document summarization[C]//Proceedings of the Workshop on Multi-source Multilingual Information Extraction and Summarization. Association for Computational Linguistics, 2008: 17−24.
[11] 李鹏, 王斌, 石志伟, 等. Tag-TextRank: 一种基于Tag的网页关键词抽取方法[J]. 计算机研究与发展, 2012, 49(11): 2344−2351. LI Peng, WANG Bin, SHI Zhiwei, et al. Tag-TextRank Extraction Method Based on Tags[J]. Journal of Computer Research and Development, 2012, 49(11): 2344−2351.
[12] Bougouin A, Boudin F, Daille B. TopicRank: Graph-Based Topic Ranking for Keyphrase Extraction[C]//Proceedings of the International Joint Conference on Natural Language Processing (IJCNLP). Nagoya, 2013: 543−551.
[13] 胡学钢, 李星华, 谢飞, 等. 基于词汇链的中文新闻网页关键词抽取方法[J]. 模式识别与人工智能, 2010(1): 45−51. HU Xuegang, LI Xinghua, XIE Fei, et al. Keyword extraction based on lexical chains for Chinese news web pages[J]. Recognition and Artificial Intelligence, 2010(1): 45−51.
[14] 石晶, 胡明, 石鑫, 等. 基于 LDA 模型的文本分割[J]. 计算机学报, 2008, 31(10): 1865−1873. SHI Jing, HU Ming, SHI Xin, et al. Text Segmentation Based on Model LDA[J]. Chinese Journal of Computers, 2008, 31(10): 1865−1873.
[15] Hoffman M, Bach F R, Blei D M. Online learning for latent dirichlet allocation[C]//Advances in Neural Information Processing Systems, 2010: 856−864.
[16] Blei D M, Ng A Y, Jordan M I. Latent dirichlet allocation[J]. Journal of Machine Learning Research, 2003, 3: 993−1022.
[17] Griffiths T L, Steyvers M. Finding scientific topics[C]// Proceedings of the National Academy of Sciences of the United States of America. The National Academy of Sciences, 2004, 101(Suppl 1): 5228−5235.
(编辑 陈爱华)
A LDA-based approach to keyphrase extraction
ZHU Zede1, 2, LI Miao2, ZHANG Jian2, ZENG Weihui2, ZENG Xinhua2
(1. Department of Automation, University of Science and Technology of China, Hefei 230026, China;2. Institute of Intelligent Machines, Chinese Academy of Sciences, Hefei 230031, China)
Due to the shortage of the comprehensive analysis of the coverage of document topics, the readability and difference of keyphrases, a new algorithm of keyphrase extraction TFITF based on the implicit topic model was put forward. The algorithm adopted the large-scale corpus and producted latent topic model to calculate the TFITF weight of vocabulary on the topic and further generate the weight of vocabulary on the document. And adjacent lexical was ranked and picked out as candidate keyphrases based on co-occurrence information. Then according to the similarity of vocabulary topics, redundant phrases were eliminated. In addition, the comparative experiments of candidate keyphrases were executed by document statistical information, vocabulary chain and topic information. The experimental results, which were carried out on an evaluation dataset including 1 040 Chinese documents and 5 408 standard keyphrases, demonstrate that the method can effectively improve the precision and recall of keyphrase extraction.
information extraction; keyphrase extraction; LDA model; topic similarity
10.11817/j.issn.1672-7207.2015.06.023
TP391
A
1672−7207(2015)06−2142−07
2014−06−13;
2014−08−20
模式识别国家重点实验室开放课题基金资助项目(201306320);中国科学院信息化专项(XXH12504-1-10);国家自然科学基金资助项目(61070099)(Project (201306320) supported bythe Open Projects Program of National Laboratory of Pattern Recognition; Project (XXH12504-1-10) supported by the Informationization Special Projects of Chinese Academy of Science; Project (61070099) supported by the National Natural Science Foundation of China)
李淼,研究员,博士生导师,从事人工智能与知识工程研究;E-mail:mli@iim.ac.cn
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
计算机与数字工程(2018年5期)2018-05-29
计算机测量与控制(2018年3期)2018-03-27
电脑爱好者(2017年7期)2017-05-06
自动化学报(2017年7期)2017-04-18
海峡姐妹(2016年2期)2016-02-27
