
一种基于公共词块的英文短文本相似度算法
2015-08-01 11:23黄贤英刘英涛饶勤菲
重庆理工大学学报(自然科学) 2015年8期
黄贤英,刘英涛,饶勤菲
(重庆理工大学计算机科学与工程学院,重庆 400054)
文本相似度是指文本在语义表达上的相似程度,两个文本的相似度值越大,文本所表达的含义也就越接近。文本相似度的计算在信息检索、图像检索、文本摘要自动生成、文本复制检测等方面都有着广泛的应用[1]。随着网络的普及和人们生活节奏的加快,短文本越来越多地出现在人们的视野中。短文本具有内容较短、特征稀疏、口语化等特点,因此传统的文本相似度量方法在短文本的处理方面效果较差。改进相似度度量方法,提高短文本相似度度量效果成为自然语言处理方面的一个研究热点。
对于短文本相似度的研究,大多都是通过扩展短文本文本信息来提高短文本相似度计算。文献[2]利用概念网络扩展文本信息进行短文本分类。文献[3]利用动态变量来发现短文本间的内在关联以计算短文本相似度。文献[4]通过构建概念树来计算短文本相似度值。文献[5-6]针对微博短文本,分别利用隐主题分析技术和相关度模型来度量短文本相似度。以上方法都是在牺牲效率的前提下来提高短文本相似度计算的准确率。文献[7]提出了基于语义和最大匹配度的短文本相似度算法。文献[8]提出了一种基于语义信息和词序的短文本相似度算法。文献[9]提出了一种基于语义信息和句法信息的短文本相似度算法。文献[10-11]通过改进基于《知网》的语义相似度计算方法来提高短文本相似度的计算准确率。这些方法都是结合语义信息计算短文本相似度,对语义词典有很强的依赖性。
考虑到词序对短文本相似性的影响,本文引入公共词块信息,在基于词项重合的关键词重叠相似度算法基础上,集合公共词块在文本中出现的次序,提出一种利用公共词块作为计算单元的短文本相似度的算法——公共词块相似度算法(common chunks similarity algorithm,CCS)。该算法主要是将两个文本中所有连续出现的相同关键词看做一个词块单元,利用所有公共词块中的关键词计算重叠相似度,并考虑这些公共词块在两个文本中的出现次序对短文本相似度的影响,做加权处理,以提高文本相似度计算的算法性能。
1 相关算法
1.1 基于词项重合的重叠相似度算法
基于词项重合的重叠相似度算法将短文本内容看成是独立关键词的集合,通过两个短文本的共现词的个数来判断两个短文本的相似性[12]。若两个短文本中共现词的个数越多,则两个短文本就越相似;反之,两个短文本的相似度就越低。同时,为保证两个短文本的相对相似度一致,采用相似度计算公式如下:
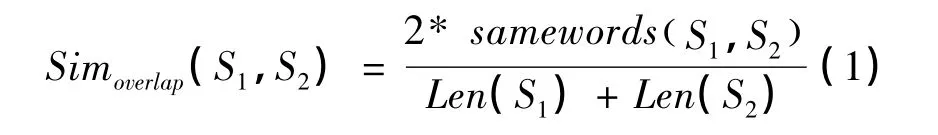
其中:samewords(S1,S2)表示S1与S2中都出现的关键词个数;Len(S1)表示S1中的关键词个数,Len(S2)表示S2中的关键词个数。
1.2 基于词项的词序相似度算法
基于词项的词序相似度算法对两个短文本的每个关键词给定各不相同的距离值来表示每个关键词的位置信息,通过每个关键词在两个短文本里的位置关系来判断两个短文本的相似性[8]。当关键词在两个短文本里的位置越相近,相对距离越小,两个短文本相似度值就越大;反之,相对距离越大,两个短文本相似度值越小。该算法提取出两个短文本的所有关键词的词序信息,按“先短文本一、后短文本二”的顺序将两短文本不同的关键词合并在一起,且关键词的相对位置保持不变,同时每个关键词只保留第一次出现的位置,组成一个新的关键词集合。根据每个关键词在组合关键词集合中的次序给每个关键词设置距离值,根据这些关键词在两个短文本中的相对距离计算两个短文本相似度值,若短文本中无该词,则距离值设为0。相似度计算公式如下:
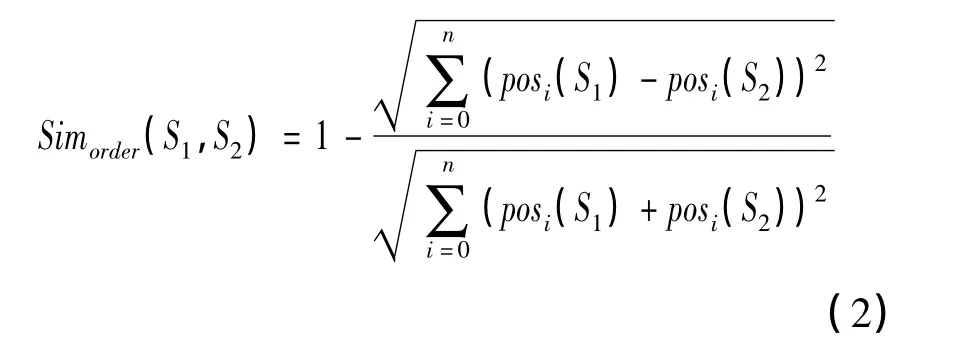
其中:posi(S1)表示第i个关键词在S1中的距离值;posi(S2)表示第i个关键词在S2中的距离值;posi(S1)-posi(S2)表示第i个关键词在S1与S2中的相对距离。
2 公共词块改进相似度算法
2.1 文本预处理
英文文本相比中文文本处理更为方便。英文文本的词是以空格或标点自然隔开,所以对于英文文本的分词处理较简单,主要是对关键词进行词根化处理。示例如下:

分词处理并进行词根化后的结果为:

基于词项重合的重叠相似度算法在计算S1与 S2相似度时,samewords(S1,S2)=7,Len(S1)=Len(S2)=7,S1与S2的相似度值为1。从上面的例子中可以看出:S1与S2讲述的主题是相同的,且关键词相同,但由于关键词的词序差别,它们的语义不同,相似程度也不是完全相同。然而基于词项重合的重叠相似度算法存在着独立性假设的条件,将短文本中的各个关键词看成是独立存在的个体,忽略了关键词间的序列信息,导致相似度计算出现误差。如果考虑词序的影响,可以更好地提高短文本相似度计算的准确率。
在对S1与S2的关键词距离值设定时,所确定的组合关键词集合为:
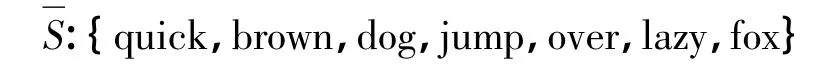
为方便计算,取距离值的间隔为1,每个关键词在S1与S2中的距离值分别为:
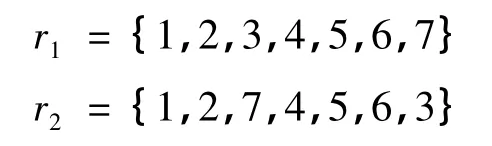
基于词项的词序相似度算法在计算相似度时,连续的相似关键词可能因为位置的不同导致相对距离的和值较大,计算得到的相似度较小。然而实际上,连续的关键词数量越多,两个短文本就越相似。对此,本文结合公共词块信息,对基于词项的词序相似度计算方法做了改进。
2.2 基于公共词块的文本向量表示
本文算法在基于词项重合的重叠相似度算法的基础上做出改进,词序方面的相似度算法仅考虑两个短文本中的共现词。因此,要先从处理后的两个短文本关键词集中提取出共现词,然后在共现词集合中查找在两个短文本中都连续出现的共现词组,将其标注为一个词块(每个词块中关键词的个数大于等于1),并标注这些词块在两个短文本中的距离值。
对于S1与S2,提取的公共词块集合为:{{quick,brown},{dog},{jump,over,lazy},{fox}}
每个关键词在S1与S2中的距离值分别为:
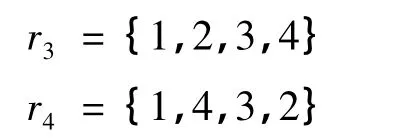
2.3 文本相似度计算
利用结合公共词块信息得到的短文本词序表示向量来计算两个短文本间的词序相似度,综合考虑重叠相似度计算方法与基于公共词块的相似度计算方法得到新的相似度值,对式(1)和式(2)做加权处理,得到本文的公共词块相似度值。基于公共词块的相似度计算方法仅考虑共现词的情况,当两个短文本的共现词数量较多时,共现词间的词序因素对两个短文本相似度值的影响较大;反之,基于词项重合的重叠相似度算法就起到决定作用。对此,本文采用了一种基于共现词的自适应系数分配方案来确定两种相似度算法的权重。相似度计算公式如式(3)所示。
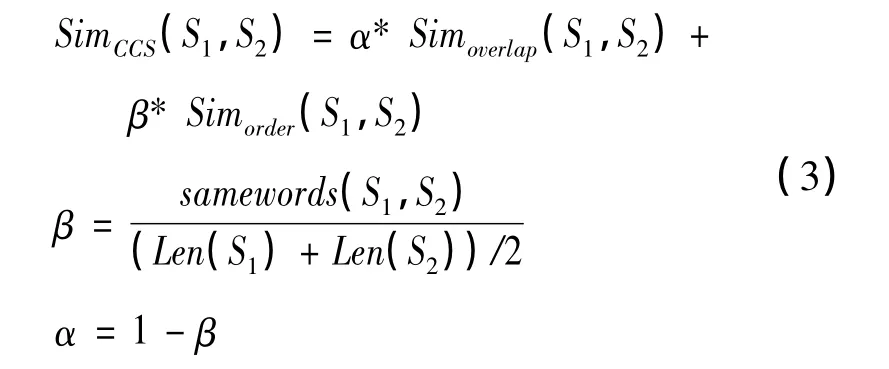
对 于 S1与 S2,Simoverlap(S1,S2)=1.0,Simorder(S1,S2)=0.732 7,则两短文本的相似度值为 SimCCS(S1,S2)=0.732 7。
3 实验结果与分析
3.1 实验数据
选取微软研究院释义语料库(MSRP)[13-14]数据集作为测试文本,数据集中包含从数千个网页源中收集的5 801条句子对,同时挑选一定量的测试者对句子对之间的相似性进行人工判断,从而决定该句子对是否相似。相似的记为1,不相似的记为0。
3.2 实验结果
本文采用基于词项的余弦相似度算法、基于词项的关键词重叠相似度算法、基于词典的语义相似度算法、最长公共子序列相似度算法[15]和本文算法,分别对数据集进行相似度值的计算,并做对比研究。
方法1:基于词项的余弦相似度算法;
方法2:基于词项的关键词重叠相似度算法;
方法3:基于词典的语义相似度算法;
方法4:基于词项的最长公共子序列相似度算法;
方法5:本文的相似度算法。
表1是在数据集中提取了前N条句子对时,5种算法计算的人工标注状态为1的句子对的相似度平均值。由于该数据集句子对间的相似性经过较严格的人工标注,若句子对的相似性状态为1,则该句子对的相似值也应较高。很明显,本文算法的相似度平均值要高于其他5种方法,并保持在0.84附近,且最大值与最小值之差不超过0.01,表明本文算法在相似度的计算和算法稳定性方面都有着比较好的效果。表1中,方法1、方法2和方法4的相似度平均值也较高,而方法3的相似度平均值却保持在较低的水平。方法1、方法2和方法4的相似度平均值的起伏超过0.01。
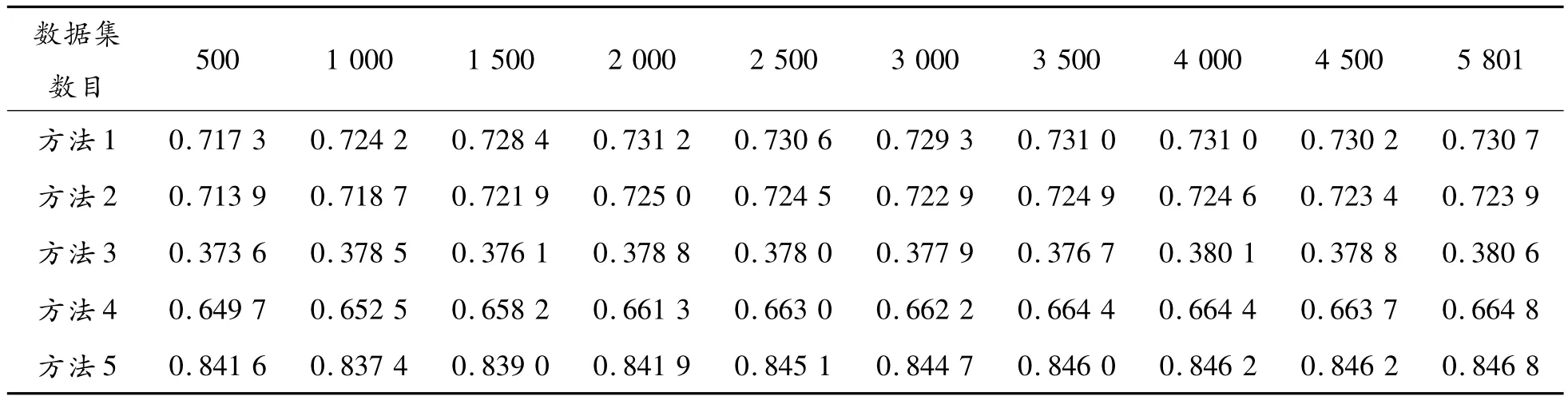
表1 各算法在不同数据集数目时状态为1的句子对的相似度平均值
图1是不同相似度阈值下5种方法对数据集相似性计算得到的准确率的比较。由图1可见:方法3在相似度阈值低于0.55时,准确率要高于其他算法;在相似度阈值超过0.55之后,方法3的准确率逐渐低于方法4、方法2、方法1;在相似度阈值超过0.95后,方法3的准确率达到100%,高于其他算法;当相似度阈值低于0.3时,方法1、方法2、方法4和方法5的准确率基本相同;当相似度阈值超过0.3后,方法5(即本文方法)计算所得的准确率明显低于其他4种方法。
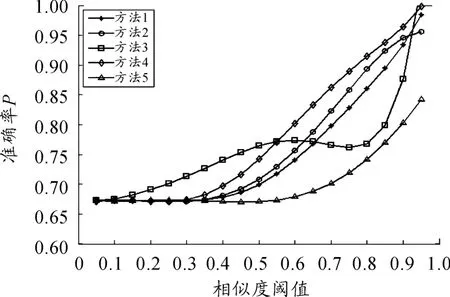
图1 不同相似度阈值下5种方法的准确率比较
图2是不同相似度阈值下5种方法对数据集相似性计算得到的召回率的比较。由图2可见:方法3的召回率要低于其他方法;当相似度阈值低于0.3时,方法1、方法2、方法4和方法5的召回率基本都是100%;当相似度阈值大于0.3时,方法5的召回率最大,方法1和方法2的召回率基本相同,只小于方法5,大于其他方法,其中方法1略大于方法2。从图2还可以看出,方法5即本文方法的召回率要远大于其他方法。
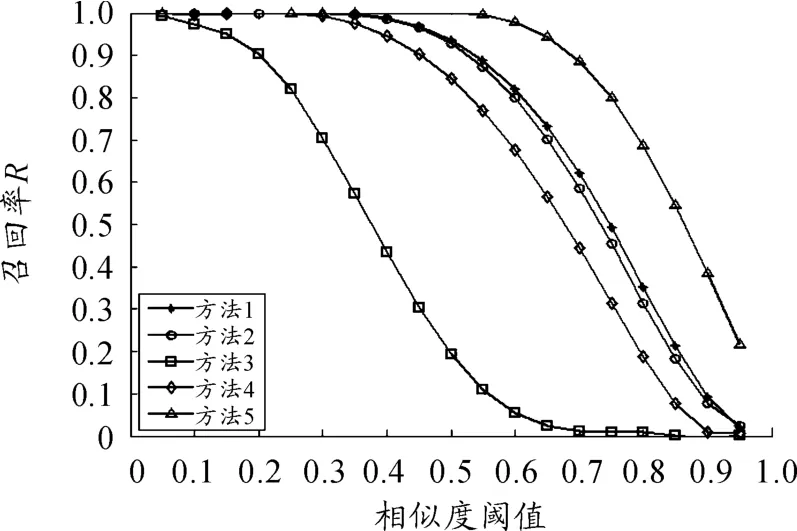
图2 不同相似度阈值下5种方法的召回率比较
图3是不同相似度阈值下5种方法对数据集相似性计算得到的F值的比较。各方法计算所得的F值情况基本与计算得到的召回率情况相同,这是由于F值综合考虑了算法的准确率和召回率的情况。各算法的准确率的增大速率要低于它们召回率的减少速率,因而召回率的值对F值影响较大,F值的变化曲线接近于召回率的变化曲线。
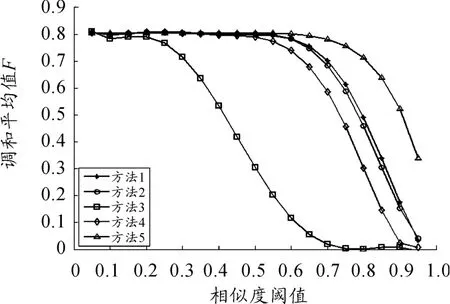
图3 不同相似度阈值下五种方法的F值比较
3.3 结果分析
实验部分主要比较了基于词项的余弦相似度算法、基于词项的关键词重叠相似度算法、基于语义工具的语义词典相似度算法、基于词项的最长公共子序列相似度算法和本文算法。
MSRP数据集中,句子对之间的词项重复较多,相似度值主要取决于词项间的关联关系,基于语义工具的语义词典相似度算法集中于关键词间的相似关系,缺乏对句子中词项间深层次含义的挖掘,计算所得的相似度均值较低,F值也较低。基于词项的余弦相似度算法和基于词项的关键词重叠相似度算法只集中于独立词项的相同数量关系,未考虑词项间的词序关系,虽然相似度均值较大,但F值较低。基于词项的最长公共子序列相似度算法集中于句子对间的最长公共子序列,考虑了词序信息,但仅提取了部分共现词,相似度均值不高。本文算法加入了公共词块信息,考虑词序关系影响,通过句子对中共现词的数量自动调整加权系数,既考虑了共现词的词项信息,又兼顾了词项间的词序信息,得到了较高的相似度均值和较好的F值曲线,且算法具有较好的稳定性。
4 结束语
本文在关键词重叠相似度算法的基础上,结合公共词块信息,设计了一种新的短文本相似度算法。该算法增加了基于公共词块的关键词位置信息约束条件,兼顾了文本的词项信息和词序因素。实验结果显示:该算法在英文短文本相似度计算方面具有较好的性能。此方法的不足之处是忽略了词意相近、词形不同的词对对相似度计算的影响,仅适用于共现词较多的数据的相似度计算。若进一步添加语义信息进行相似度计算可能会提高算法的算法性能,但语义相似度计算应尽量减少对于词典的依赖,同时避免无用或错误词项的添加,防止词典约束和噪声加入对相似度计算的影响。
[1]华秀丽,朱巧明,李培峰.语义分析与词频统计相结合的中文文本相似度量方法研究[J].计算机应用研究,2012,29(3):833 -836.
[2]林小俊,张猛,暴筱,等.基于概念网络的短文本分类方法[J].计算机工程,2010,36(21):4 -6.
[3]金春霞,周海岩.动态向量的中文短文本聚类[J].计算机工程与应用,2011,47(33):156 -158.
[4]赵小谦,郑彦,储海庆.概念树在短文本语义相似度上的应用[J].计算机技术与发展,2012,22(6):159-162.
[5]路荣,项亮,刘明荣,等.基于隐主题分析和文本聚类的微博客中新闻话题的发现[J].模式识别与人工智能,2012,25(3):382 -387.
[6]郑斐然,苗夺谦,张志飞,等.一种中文微博新闻话题检测的方法[J].计算机科学,2012,39(1):138 -141.
[7]孙建旺,吕学强,张雷瀚.基于语义与最大匹配度的短文本分类研究[J].计算机工程与设计,2013,34(10):3613-3618.
[8]Yuhua Li,David McLean,Zuhair A.Bandar,et al.Sentence Similarity Based on Semantic Nets and Corpus Statistics[J].Knowledge and Data Engineering,2006,18(8):1138-1150.
[9]IslamA,Inkpen D.Semantic Text Similarity Using Corput-based Word Similarity and String Similarity[J].ACM Transactions on Knowledge Discovery from Data,2008(2):10.
[10]朱征宇,孙俊华.改进的基于《知网》的词汇语义相似度计算[J].计算机应用,2013,33(8):2276 -2279,2288.
[11]张瑞霞,杨国增,吴慧欣.基于《知网》的汉语未登陆词语义相似度计算[J].中文信息学报,2012,26(1):16-21.
[12]程佳.热点新闻间关系的研究[D].上海:上海交通大学,2011.
[13]Quirk C,Brockett C,Dolan W B.Monolingual Machine Translation for Paraphrase Generation[C]//EMNLP.USA:[s.n.],2004:142 -149.
[14]Dolan B,Quirk C,Brockett C.Unsupervised construction of large paraphrase corpora:Exploiting massively parallel news sources[C]//Proceedings of the 20th international conference on Computational Linguistics.Association for Computational Linguistics,2004:350.
[15]Irvine V C,Samir Khuller.Design and Analysis of Algorithms Lecture Notes[R].Maryland,USA:Dept of Computer Science University of Maryland,2003.
猜你喜欢
孩子(2019年12期)2019-12-27
哲学评论(2018年1期)2018-09-14
中学生英语·外语教学与研究(2018年2期)2018-03-16
校园英语·上旬(2017年8期)2017-08-04
广东教育·综合(2017年7期)2017-07-27
大学教育(2017年5期)2017-05-10
心理与行为研究(2016年4期)2016-12-16
北方文学·中旬(2016年6期)2016-08-01
西南交通大学学报(社会科学版)(2015年4期)2016-03-29
中学生英语(2015年48期)2015-08-15
