
基于敏感度的个性化(α,l)-匿名方法
2015-06-27 08:26赵爽,陈力
计算机工程 2015年1期
赵 爽,陈 力
(天津财经大学管理信息系统系,天津300222)
·安全技术·
基于敏感度的个性化(α,l)-匿名方法
赵 爽,陈 力
(天津财经大学管理信息系统系,天津300222)
目前多数隐私保护匿名模型不能满足面向敏感属性值的个性化保护需求,也未考虑敏感属性值的分布情况,易受相似性攻击。为此,提出基于敏感度的个性化(α,l)-匿名模型,通过为敏感属性值设置敏感度,并定义等敏感度组的概念,对等价类中各等敏感度组设置不同的出现频率,满足匿名隐私保护的个性化需求。通过限制等价类中同一敏感度的敏感属性值出现的总频率,控制敏感属性值的分布,防止相似性攻击。提出一种基于聚类的个性化(α,l)-匿名算法,实现匿名化处理。实验结果表明,该算法能以与其他l-多样性匿名模型近似的信息损失量和时间代价,提供更好的隐私保护。
隐私保护;l-多样性;敏感度;聚类;个性化;相似性攻击
1 概述
随着信息化时代的到来,数据的高共享和大容量存储技术,便于各类机构收集和发布数据。其中大量数据与个体存在对应关系,这种对应关系往往会泄露人们的隐私信息,如收入水平、健康状况、消费记录等敏感信息。因此,如何在数据发布的过程中保护隐私信息成为当前研究的热点,目前匿名化方法已成为隐私保护在数据发布方面的重要技术。
自1998年Samarati等人[1]提出匿名化以来,国内外专家对匿名化技术开展了广泛研究。文献[2]进一步对k-匿名模型进行了阐述,通过发布一定数量不可区分的个体,使攻击者不能判别隐私信息所属的个体,从而防止链接攻击。文献[3]在k-匿名的基础上提出了l-多样性(l-diversity)模型,对敏感属性值的多样性提出要求;文献[4]提出(α,k)-匿名模型,对敏感属性值的出现频率提出要求;p-sensitivek-匿名模型[5]要求发布的数据满足k-匿名的同时,还要求同一等价类中至少出现p个不同的敏感属性值。这些在k-匿名基础上改进的模型,可以有效防御k-匿名不能防御的一致性攻击和背景知识攻击。
然而以上研究,都没有考虑不同个体对于同一敏感信息保护程度的差异,即没有考虑隐私自治的需求。文献[6]提出个性化匿名的概念以及解决相应问题的方法;文献[7]分析了不同类型的个性化服务需求及相应的匿名模型;文献[8]提出完全(α,k)-匿名模型,通过给各敏感值在等价类中设置不同的出现频率来实现个性化保护;文献[9]提出一种面向个体的个性化扩展l-多样性隐私匿名模型。但这些研究大多只针对敏感属性值的字面差异,而设置不同的约束条件,往往不能抵御相似性攻击。
本文基于这些研究,定义了敏感度和等敏感度组的概念,考虑到敏感属性值之间的语义相似关系,提出一种基于敏感度的个性化(α,l)-匿名模型,该模型在满足l-多样性原则的同时,通过为不同的敏感度设置不同的α频率约束来实现隐私匿名的个性化要求,并且通过控制敏感属性值在等价类中的分布,避免相似性攻击。给出基于局部泛化的贪心聚类算法能减少信息损失量,个性化的约束条件也可使数据可用性更高。
2 基本概念和问题定义
2.1 基本概念
数据表中包含的属性按功能分为以下3类[10]:
(1)标识符:即惟一标识个体身份的属性,如姓名、身份证号等,一般标识符在发布时,都会直接删除来保护隐私;
(2)准标识符:与其他数据表进行链接以标识个体身份的属性或属性组合,如出生日期、性别、种族等。准标识符取决于进行链接的外表,不同的外表,准标识符的选择不同;
(3)敏感属性:描述个体隐私信息的属性,如诊断结果、健康状况、收入水平等。
定义1(k-匿名) 数据表T包含n个属性,设QI是T的准标识符,T[QI]表示T在QI上的投影,当且仅当在T[QI]上出现的每组值至少要在相应的投影上重复出现k次,则称T满足k-匿名。
定义2(等价类) 如果数据表T满足k-匿名,则把T中在准标识符上具有相同值的元组的集合,称作等价类。
由此可得,k-匿名表中的每个等价类的大小至少为k,攻击者以准标识符与外表进行链接时,至少能对应到k个不同的个体,就无法判别出个体与敏感属性的对应关系,因此,k-匿名可以防御链接攻击。然而,k-匿名并没有对敏感属性进行约束,同一敏感属性值可能集中出现在一个等价类中,这样即使满足k-匿名,攻击者也很容易能直接或凭借已知的相关知识推理出敏感属性值与个体的对应关系,k-匿名易受到一致性攻击和背景知识攻击[11]。l-diversity模型和(α,k)-匿名模型在此基础上进行了改进。
定义3(l-diversity模型) 如果一个等价类中所含不同敏感属性值的个数大于等于l(l≥2),则称该等价类满足l-diversity原则。如果给定数据表T,经泛化后得表T′,其中每个等价类都满足l-diversity原则,则称T′满足l-diversity模型。
定义4((α,k)-匿名模型) 给定数据表T,经泛化后得表T′,若T′满足k-匿名的同时,每个等价类中任何一个敏感属性值出现的频率小于等于α(0<α<1),则称T′满足(α,k)-匿名模型。
2.2 问题定义
定义5(相似性攻击) 在同一等价类中,敏感属性值虽然字面上存在差异,但语义上相似或相近,攻击者可以通过这些语义相似的敏感属性获得个体隐私信息的大体范围。
l-diversity模型和(α,k)-匿名模型虽然对敏感属性进行了约束,却忽略了敏感属性值的语义相似关系,尤其是针对一些“高危相似”的敏感属性值,若都集中分布在一个或几个等价类中,就会给个体造成较严重的隐私泄露。当然,对于那些“非高危”的敏感属性值,可以降低对其的保护程度。匿名模型应该根据个体对敏感属性值的保护程度,对不同的敏感属性值设定不同的约束条件,从而减少过度保护带来的信息损失。
例如,表1所示的原始诊断结果,当编号8,9,10的3条记录经泛化后组成一个等价类时,若设l=3或α=0.4,该等价类虽然是符合约束原则的,但“骨癌、肺癌、胃癌”都属于语义相似的“高危”敏感属性值,攻击者如果确定某个体在该等价类中,就可以推测其患了较重的癌症,同样造成隐私泄露。但对于“流感”等被保护的需求程度普遍较低的敏感属性值,即使被攻击者推断出大致范围,对多数个体来说也是可以接受的。

表1 原始诊断结果
因此,应该从控制敏感属性值的分布入手,同时为不同的敏感属性值设定不同的约束条件,提出既能防止相似性攻击又能满足个性化需求的匿名模型。
3 基于敏感度的个性化(α,l)-匿名模型
3.1 个性化隐私保护
对于个性化隐私保护的模型,一般分为面向个体和面向敏感属性值[7],面对庞大的数据量,如果为每个个体设置约束条件,将产生巨大的工作量,因此面向个体的个性化隐私保护模型具有一定的局限性。而面对敏感属性值的保护模型中,由于不同敏感属性值的敏感程度有很大差别,就需要为不同的敏感属性值提供不同的保护程度。
定义6(敏感度) 设数据表T中的敏感属性为S,si表示S中的敏感属性值,根据si需要被保护的程度,为其设定敏感级别,将敏感级别数值化后相应的值称作si的敏感度,记作Di(0<Di<1)。si需要被保护的程度越高,敏感级别越高,Di越大。由此给表1中疾病属性的不同敏感值设敏感度,如表2所示。

表2 疾病敏感度
定义7(等敏感度组) 将具有相同敏感度的敏感属性值所在的元组构建的集合,称作等敏感度组,记作SD,|SD|表示组内所含元组的个数,等敏感度组的敏感度即为该组中敏感属性值的敏感度。例如,由表1、表2可知,编号8、编号9、编号10的元组组成了一个SD,且|SD|=3,该组的敏感度为0.7。
3.2 个性化(α,l)-匿名模型
定义8基于敏感度的个性化(α,l)-匿名模型,给定数据表T,经泛化后得表T′,若T′满足ldiversity,且每个等价类E中任一等敏感度组SDi都满足,其中,αi=1-Di,|E|表示等价类E中的元组个数,则称数据表T′满足基于敏感度的个性化(α,l)-匿名模型。
例如,将原始表1经泛化匿名后得到表3,其中包括3个等价类,按照表2设定的敏感度并要求l=2,第1个、第2个等价类都符合该模型,在第3个等价类中,由{肺癌,骨癌}组成的等敏感度组的敏感度为0.7,由αi=1-Di得,该等敏感度组中的元组出现频率应该小于等于0.3,而实际的0.3,不符合该匿名模型,因此,表3不是符合基于敏感度的个性化(α,l)-匿名的匿名数据表。

表3 泛化匿名后的诊断结果
4 基于敏感度的个性化(α,l)-匿名算法
4.1 信息损失的度量
在匿名化过程中,数据处理会产生一定量的信息损失,信息损失的度量作为评价数据可用性的指标,也用于衡量匿名化算法的优劣并指导其策略[12]。本文通过构造加权确定性代价模型,表示数据处理过程中所产生的信息损失量。
定义9(泛化层次) 在对属性值泛化的过程中,通常将泛化层次树作为泛化规则。设属性A的泛化层次树为TA,RA表示根节点,LA表示叶节点的集合,层次树由最底层的LA按分类关系,依层向上递增直到RA。当属性A为数值型时,TA表示域泛化的规则,图1表示“年龄”属性的层次泛化树;当属性A是分类型时,TA表示值泛化的规则,图2表示“省份”属性的层次泛化树。
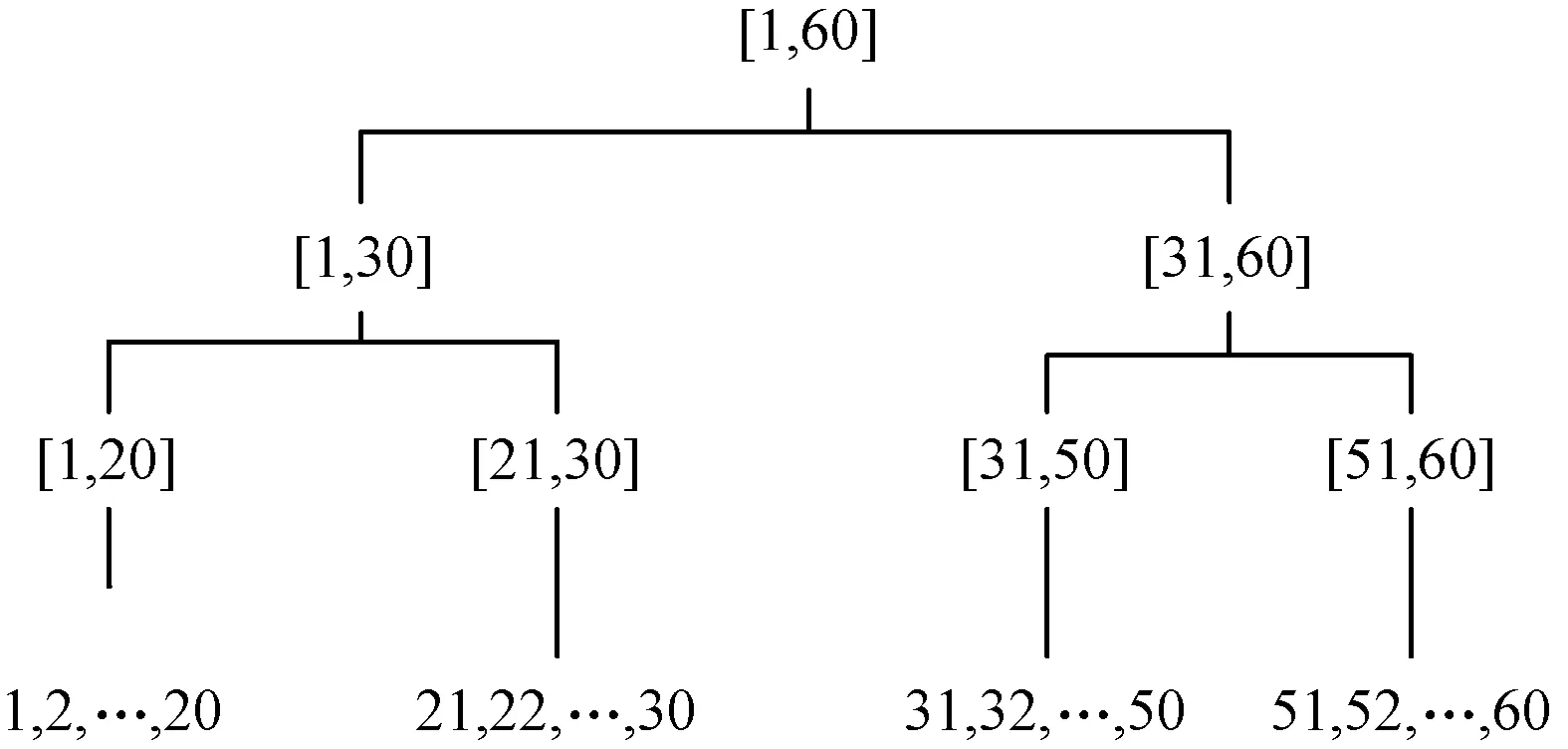
图1 “年龄”属性的层次泛化树

图2 “省份”属性的层次泛化树
定义10(属性值的信息损失) 对于属性A,用确定性代价模型度量其属性值被泛化到s的信息损失量,记作NCPA(s):
若A为数值型属性,则NCPA(s)其中,Range(s)表示属性值s的区间大小;Range(RA)表示属性A的值域。
若A为分类型属性,则其中,Sub(s)表示以s为根节点的子树中所含叶节点的集合;表示该集合的大小。
定义11(元组的信息损失) 对于包含n个属性的元组t,用加权确定性代价模型度量其信息损失量,记作NCP(t):

其中,wi表示属性Ai的权重;NCPAi(t.Ai)分为数值型和分类型分别计算。
定义12(总信息损失) 对于聚类形成的聚簇e,进行泛化处理所产生的信息损失NCP(e)定义为:

对于匿名表T′,设E为T′中等价类的集合,则T′的总信息损失NCP(T)定义为:

4.2 个性化(α,l)-匿名算法
本文提出一种基于敏感度的个性化(α,l)-匿名算法,该算法以满足敏感度个性化(α,l)-匿名模型为约束,通过基于贪心策略的聚类算法,将数据集分成若干聚簇后进行局部泛化,过程中以信息损失最小化为目标。
该算法具体思路是:
(1)根据不同敏感属性值将数据集分成若干元组集合,同一集合中的元组具有相同的敏感属性值,那么每个元组集合都有相应的敏感度,将各元组集合按敏感度由高至低排列。
(2)从非空最高敏感度的元组集合中任选一个元组作为原型,然后按照敏感度由低到高的顺序,依次从1个~l个非空元组集合中各抽选一个元组从而建立l-多样性聚簇。每次抽选的元组,要使得新形成的聚簇满足:1)基于敏感度的个性化(α,l)-匿名模型;2)增加的信息损失量最小。
(3)重复操作步骤(2),形成若干聚簇,直到非空元组集合的数量不足 l,或剩余元组不符合步骤(2)中的抽选约束。
(4)将剩余元组按照步骤(2)中的约束插入到已有聚簇中,再将无法插入的元组进行隐匿。
(5)对每个聚簇的准标识符进行泛化处理,形成若干等价类,产生符合匿名条件的数据表。
算法基于敏感度的个性化(α,l)-匿名算法
输入原始数据表T,敏感属性值的敏感度表,多样性参数l,属性权重wi
输出满足基于敏感度的个性化(α,l)-匿名的数据表T′
步骤:
(1)计算数据表T中敏感属性值个数n,若n<l,则返回重新设置多样性参数l;
(2)根据敏感属性值si将数据表T分为若干元组集合ti(i=1,2,…,n),将这些集合按相应的敏感度Di降序排列为:t1,t2,…,tn;
(3)按照i从1~n的顺序,对每个元组集合ti,循环:
如果ti为非空集,且非空元组集合的总数大于等于l,循环:
1)从ti中任选一条记录r;
2)准聚簇e′={r};
3)按照敏感度由低到高的顺序,依次从1个~l个非空元组集合中各抽选一条记录,加入准聚簇e′,使e′满足基于敏感度的个性化(α,l)-匿名的要求且增加的信息损失最小;
4)如果步骤3)可执行:将准聚簇e′作为聚簇e加入聚簇集,将抽选的记录从相应的的原元组集合中删除;否则将准聚簇e′清空,将抽选的记录保留在相应的原元组集合中。
(4)如果存在非空的元组集合,循环:
1)从非空ti中任选一条记录r;
2)选取聚簇集中的一个聚簇e,使r加入其后仍满足基于敏感度的个性化(α,l)-匿名的要求且增加的信息损失最小;
3)如果步骤2)可执行e=e∪{r},ti=ti-{r};否则将r做隐匿处理。
(5)返回聚簇集,对其中各聚簇e做准标识符的泛化处理,形成符合条件的匿名表T′。
5 实验结果及分析
5.1 实验数据及参数
实验采用UCI机器学习数据库中的Adult数据集,该数据集由美国人口普查数据构成,经过删除缺省值处理后,包含45 222条记录,本文选取其中的7个属性,将Occupation作为敏感属性,其他6个属性为准标识符,数据集结构设置见表4,对敏感属性Occupation的14个敏感属性值设置敏感度见表5。

表4 Adult数据集结构

表5 敏感属性值的敏感度设置
实验从信息损失度与执行时间2个方面进行分析,将本文算法与文献[3]中基于全域泛化的l-多样性匿名算法以及文献[13]中l-clustering聚类算法进行比较,实验运行环境为 Intel Core(TM)2 Duo CPU@1.80 GHz,2.00 GB内存,操作系统为Microsoft Windows XP,环境为Visual C++6.0与Matlab7.0。
5.2 信息损失度分析
数据表的信息损失按定义7中总信息损失NCP(T)的式子度量,当准标识符属性个数为6、元组数为45 222且l值变化时的3种匿名算法的信息损失量的比较,如图3所示。由此可知,3种算法的信息损失度会随着l值的增大而增加,因为l值越大,生成聚类所含元组的个数增多,对元组泛化的程度会更高,从而引起更多的信息损失。另外,本文算法与l-clustering聚类算法信息损失度相近,相对于l-多样性算法都产生较小的信息损失。因为l-多样性算法采用全域泛化策略,其信息损失通常要远高于局部泛化策略。可见,本文算法以与l-clustering算法类似的信息损失量获得可以防御相似性攻击的个性化隐私保护。

图3 不同l值下各匿名算法的信息损失度
5.3 执行时间分析
当准标识符属性个数为6、数据集大小为45 222且l值变化时,3种匿名算法的执行时间比较,如图4所示。由此可知,3种算法的执行时间会随着l值的增大而增加,因为当l值增大时,等价类中的元组数、聚类次数、泛化次数、执行时间也都相应增加。另外,本文算法与l-clustering聚类算法执行时间相近,都高于l-多样性算法的执行时间,但为了更好地实现个性化隐私保护,本文算法的时间开销是可接受的。
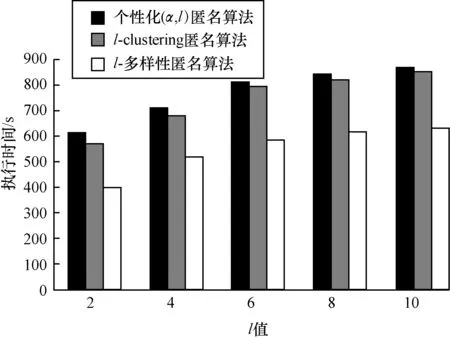
图4 不同l值下各匿名算法的执行时间
6 结束语
本文针对敏感属性值个性化隐私保护的需求以及l-多样性匿名模型不能解决的相似性攻击问题,提出基于敏感度的个性化(α,l)-匿名模型。该模型通过为敏感属性值设置敏感度,并对等价类中各等级敏感度组的出现频率按照敏感度进行设置,来实现隐私匿名的个性化需求。此外,本文在敏感度的基础上提出等敏感度组的概念,通过限制等价类中同一敏感度的敏感属性值出现的总频率,控制敏感属性值的分布,防止相似性攻击。本文还提出个性化(α,l)-匿名算法,通过基于聚类的局部重编码策略进行匿名化处理,有效地实现了基于敏感度的个性化(α,l)-匿名模型。实验结果表明,该算法与传统基于聚类的l-多样性算法有相似的信息损失度和执行效率,在可接受的时间开销下,信息损失量明显小于全域泛化的l-多样性算法,且更有效地实现了个性化隐私保护。
由于本文只是针对单一的敏感属性值,因此今后将探讨在多敏感属性值情况下对敏感度的设定和分组,以及多敏感属性值的个性化隐私保护等问题。
[1] Samarati P,Sweeney L.Generalizing Data to Provide Anonymity When Disclosing Information[C]// Proceedingsofthe 17thACM SIGACT-SIGMODSIGART Symposium on Principles of Database Systems.New York,USA:ACM Press,1998:188.
[2] Sweeney L.K-anonymity:A Model for Protecting Privacy[J].International Journal of Uncertainty,Fuzziness and Knowledge-based Systems,2002,10(5):557-570.
[3] Machanavajjhala A,GehrkeJ,KiferD.I-diversity: Privacy Beyond k-anonymity[J].ACM Transactions on Knowledge Discovery from Data,2007,1(1):24-35.
[4] Wong R,Li J,Fu A,et al.(α,k)-anonymity:An Enhanced k-anonymity Model for Privacy Preserving Data Publishing[C]//Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining.New York,USA:ACM Press,2006:754-759.
[5] Traian T M,Bndu V.Privacy Protection:p-sensitive kanonymity Property[C]//Proceedings of the 22nd International Conference on Data Engineering Workshops. Washington D.C.,USA:IEEE Computer Society,2006: 94-103.
[6] Xiao Xiaokui,Tao Yufei.Personalized Privacy Preservation[C]//Proceedings of ACM SIGMOD Conference on Management of Data.Chicago,USA:ACM Press, 2006:229-240.
[7] 王 波,杨 静.数据发布中的个性化隐私匿名技术研究[J].计算机科学,2012,39(4):168-171.
[8] 韩建民,于 娟,虞慧群,等.面向敏感值的个性化隐私保护[J].电子学报,2010,38(7):1723-1728.
[9] 王 波,杨 静.一种基于逆聚类的个性化隐私匿名方法[J].电子学报,2012,40(5):883-890.
[10] 周水庚,李 丰,陶宇飞,等.面向数据库应用的隐私保护研究综述[J].计算机学报,2009,32(5):847-858.
[11] 王平水,王建东.匿名化隐私保护技术研究进展[J].计算机应用研究,2010,27(6):2016-2019.
[12] 朱 拯,王智慧,汪 卫.基于个人隐私约束的k-匿名模型[J].计算机研究与发展,2010,47(21):271-278.
[13] 王智慧,许 俭,汪 卫,等.一种基于聚类的数据匿名方法[J].软件学报,2010,21(4):680-693.
编辑 陆燕菲
Personalized(α,l)-anonymity Method Based on Sensitivity
ZHAO Shuang,CHEN Li
(Department of Management Information Systems,Tianjin University of Finance&Economics,Tianjin 300222,China)
Currently,the majority of anonymity model for privacy preservation neither meets the need of personalized preservation oriented to sensitive attribute values,nor considers the distribution of sensitive attribute values,therefore they are vulnerable to similarity attack.This paper proposes a personalized(α,l)-anonymity model based on sensitivity.This model provides sensitivity for different sensitive attribute values,and defines the concept of equ-sensitivity group, implements the personalized needs of privacy anonymity by setting the frequency constraints for different equ-sensitivity group in every equivalence class.This model also can defense similarity attack by limiting the total frequency of sensitive attribute values for same sensitivity in every equivalence class,and control the distribution of sensitive attribute values. This paper proposes a personalized(α,l)-anonymity algorithm based on clustering to achieve the purpose of anonymity. Experimental results show that the proposed algorithm provides better privacy preservation than otherl-diversity anonymity models with the similar information loss and time cost.
privacy preservation;l-diversity;sensitivity;clustering;personalized;similarity attack
1000-3428(2015)01-0115-06
A
TP309.2
10.3969/j.issn.1000-3428.2015.01.021
赵 爽(1989-),女,硕士研究生,主研方向:信息安全;陈 力,副教授。
2014-08-13
2014-09-09 E-mail:zhaoshuang_tjufe@163.com
中文引用格式:赵 爽,陈 力.基于敏感度的个性化(α,l)-匿名方法[J].计算机工程,2015,41(1):115-120.
英文引用格式:Zhao Shuang,Chen Li.Personalized(α,l)-anonymity Method Based on Sensitivity[J].Computer Engineering,2015,41(1):115-120.
猜你喜欢
新高考·高三数学(2022年3期)2022-04-28
电脑报(2021年14期)2021-06-28
党员生活(2020年2期)2020-04-17
计算机与生活(2019年5期)2019-07-18
铁道通信信号(2018年10期)2018-12-06
吉林大学学报(理学版)(2018年2期)2018-03-29
中文信息(2017年12期)2018-01-27
中央民族大学学报(自然科学版)(2015年2期)2015-06-09
中国石油企业(2014年4期)2014-11-30
郑州大学学报(理学版)(2014年2期)2014-03-01
