
支持异构集群并行的高能物理数据处理系统
2015-06-27 08:26雷晓凤孙功星
计算机工程 2015年1期
霍 菁,雷晓凤,李 强,孙功星
(1.中国科学院高能物理研究所,北京100049;2.中国科学院大学,北京100049)
·专栏·
支持异构集群并行的高能物理数据处理系统
霍 菁1,2,雷晓凤1,2,李 强1,2,孙功星1
(1.中国科学院高能物理研究所,北京100049;2.中国科学院大学,北京100049)
传统集群计算系统无法充分利用本地磁盘的存储资源和I/O,大量网络I/O成为系统瓶颈,导致资源利用率降低,并造成高昂的存储和网络成本。使用Hadoop处理分析作业可有效利用本地磁盘存储和I/O资源,而集群资源统一管理工具Mesos则使用轻量化的设计和高效的通信机制,能在不同计算集群之间动态共享集群资源。为此,分析高能物理数据处理的特点,利用Mesos构建异构集群间资源共享的高能物理实验数据处理系统,实现Torque/Maui和Hadoop集群的集成。测试结果表明,该系统能够在集群间动态分配集群资源,并利用本地存储和磁盘I/O显著降低网络I/O,提高集群资源利用率。
高能物理;集群资源管理;资源共享;Mesos工具;Hadoop平台;Torque/Maui系统
1 概述
高能物理实验是一项庞大的系统工程,数据处理是其中的关键步骤。高能物理实验产生的数据量非常庞大,欧洲核子中心(CERN)使用的大型强子对撞机LHC(Large Hadron Collider),每年产生约25 PB的实验数据;北京正负电子对撞机(BEPCII)和北京谱仪(BESIII)在经过改造以后,2012年产生的数据量超过了过去几年的总和,总规模超过3 PB。
高能物理实验数据处理有多种不同的类型作业。传统集群使用的批作业处理系统Torque[1]/Maui[2]采用计算资源和数据存储相分离的系统架构,适用于蒙特卡洛模拟等计算密集型应用。而Hadoop[3]平台使用MapReduce[4]的方式,能够利用计算节点本地磁盘组建HDFS[5],使分析作业读取本地磁盘数据,减轻网络I/O压力,更适合数据密集型的分析作业[6]。由于高能物理数据处理具有随时间分布的特征,2个集群的作业分布密度不同,在集群间动态共享资源能够有效提高集群资源利用率。集群资源统一管理工具Mesos[7],使用轻量化的设计和高效的通信机制,可以在不同的集群之间动态共享资源,比虚拟机技术更加高效。目前Mesos已支持多种应用,例如Hadoop,Spark,Hypertable等。已有多家著名公司使用Mesos管理集群资源,包括国外著名公司Twitter和国内著名视频网站爱奇艺等,但在高能物理实验中还没有应用。
本文分析高能物理实验数据处理的不同作业类型和特点,以及Torque/Maui集群和Hadoop集群的特性,以提高集群资源利用率和利用本地存储空间为目标,利用集群资源管理工具Mesos集成Torque/ Maui和Hadoop框架,实现一个支持混合集群并行的高能物理实验数据处理平台,并应用BESIII高能物理实验数据进行初步评估。
2 研究背景
2.1 BESIII实验数据处理的流程和作业类型
BESIII数据处理的作业类型主要有模拟作业、重建作业和分析作业3种。
实验数据由对撞机产生,生成原始数据(RAW Data)后存储在 Lustre[8]中。为了验证数据的正确性,需要一定量的模拟数据来进行对比,因此,使用蒙特卡洛模拟产生模拟数据。原始数据和模拟数据在经过重建(Reconstruction)后,生成可以供物理学家进行分析的DST数据。对DST数据的分析是典型的一次写多次读的应用。不同的物理学家使用自己编写的分析程序分析DST数据,挑选自己感兴趣的物理事例,最后生成图表等结果。本文设计的混合集群的目的是使用传统集群计算系统处理主要消耗CPU资源的模拟和重建作业,使用Hadoop处理主要消耗I/O资源的分析作业,如图1所示。
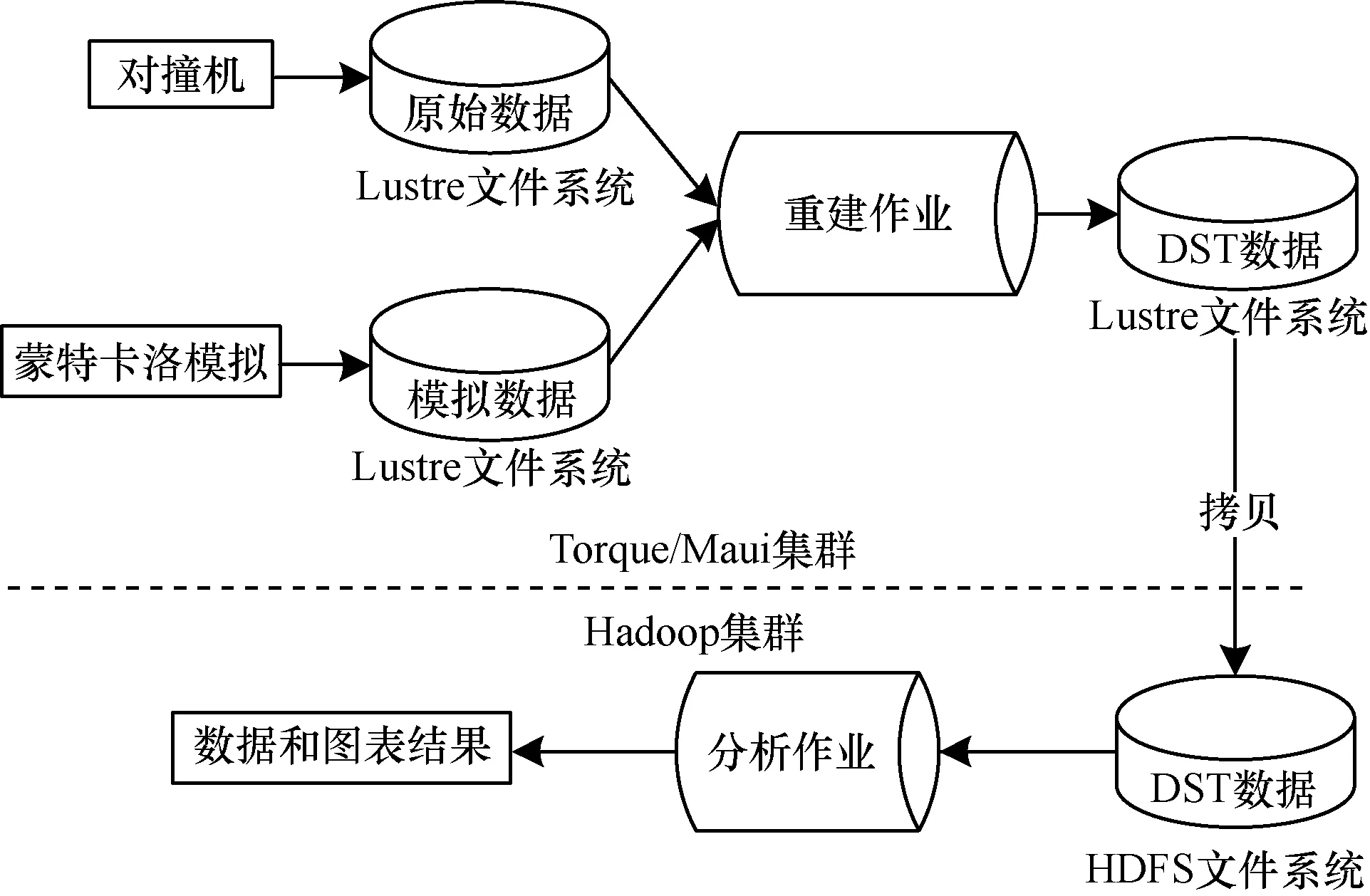
图1 BESIII实验数据处理的作业类型和步骤
2.2 Mesos集群资源统一管理框架
Mesos同大多数分布式系统一样,采用的是Master-Slave的架构,如图2所示。该架构主要由4个部分构成:Master,Slave,Framework和Executor。Master负责资源管理和分配,Slave负责汇报资源和管理本地资源,并负责启动作业执行器Executor。在Mesos中,所有接入系统的分布式计算框架都成为Framework,这些框架在Slave节点上用来运行作业的执行器称为Executor。

图2 Mesos架构
Mesos的Master在设计上实现了轻量化,仅保存Framework和Slave的部分状态信息,这些信息通过注册的方式由Framework和Slave汇报给Master,因此Mesos使用ZooKeeper[9]解决Master的单点失效问题,提高系统容错能力。Mesos的各组成部分之间通过LibProcess和Protocol Buffers组成的高效的通信系统。
在Mesos中,资源以Resource Offer的形式进行调度。Resource Offer是一种基于资源数量的调度机制,不同于Hadoop中的基于Slot的调度机制, Mesos中的资源可以根据不同应用的资源需求灵活的进行资源分配。同时,Mesos采用一种支持多维资源向量的Max-Min Fair资源分配算法Dominant Resource Fairness[10],使不同应用的不同作业需求能够得到公平的资源分配。
实现集群间资源动态分配需要建立一个全局的资源和作业信息系统,因此,任何一个分布式计算框架,如果想接入Mesos获取资源运行作业,需要开发2个组件:用于获取Mesos分配的资源信息的资源调度器 Framework Scheduler和用于管理作业并向Mesos同步作业信息的作业执行器Executor。
3 系统设计与实现
经过调研,本文设计了一种新的系统架构,在同一个物理集群上并行运行 Torque/Maui集群和Hadoop集群,使用Mesos进行集群资源管理和分配。系统架构如图3所示。
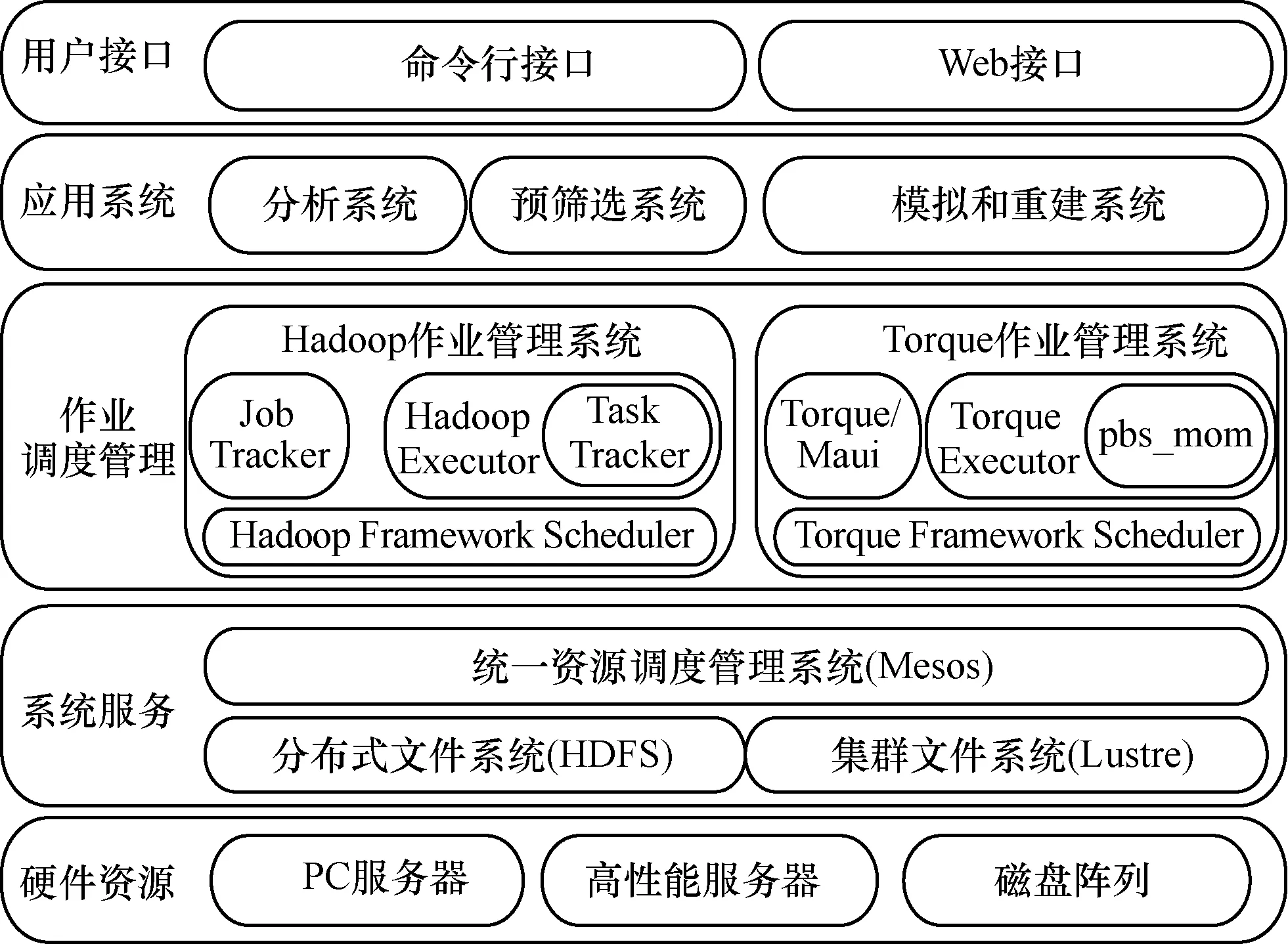
图3 高能物理数据处理系统框架
该系统使用PC服务器和高性能服务器作为计算节点,使用由Lustre管理的磁盘阵列和由计算节点本地磁盘构建的分布式文件系统HDFS提供数据存储。使用Mesos作为系统资源调度管理器。
该系统在应用层提供模拟和重建作业,分析作业,事例预筛选等应用。另外,提供给用户命令行接口和Web接口来提交和查询作业。本文使用AFS进行用户认证与权限管理,使用Puppet[11]和Ganglia[12]进行集群管理和监控。
系统的设计和实现的关键技术和本文的主要工作集中在 Torque/Maui和 Mesos的集成部分。Mesos和Hadoop的集成和资源分配策略采用了开源社区提供的代码。
3.1 Torque/Maui与Mesos的集成
Torque/Maui与Mesos的集成主要分为2个部分:(1)资源调度器Framework Scheduler的设计和实现;(2)作业执行器Executor的设计和实现。
3.1.1 Framework Scheduler的设计与实现
在资源调度器Framework Scheduler的设计中,主要实现2个功能:(1)从Mesos处获得可用资源信息,并将这些信息传递给 Torque的作业调度器 Maui; (2)Maui对分配到的资源进行处理后,将需要执行的作业信息传递给Mesos,以便分配资源和启动作业。
在原系统中Maui使用Torque提供的API(定义在头文件pbs_ifl.h中)从pbs_server中获取进行调度所需要的信息,包括:队列信息QueueInfo,节点信息NodeInfo,作业信息JobInfo。然后对根据节点状态,队列和作业的优先级等信息,把作业跟可用资源进行匹配,并将匹配的结果返回给 pbs_server,由pbs_server发命令到相应slave节点上的pbs_mom来执行作业,流程如图4中粗实线和细实线所示。
为了将Torque/Maui与Mesos集成,必须建立一个全局的资源及作业信息系统,因此,修改Maui中的资源查询函数,使其改向资源调度器Framework Scheduler查询可用的资源信息,并在作业调度结束后,将作业的调度结果反馈给资源调度器。资源调度器接收到作业信息后,由Mesos确定其需要的资源数量,为各节点上的pbs_mom分配资源。由于Maui是使用C语言编写的,而Mesos使用C++编写,因此本文使用Socket在2个程序间交换信息。
新系统中Maui和Framework Scheduler的架构设计和资源、作业的调度流程和信息交互如图4中细实线和虚线所示。
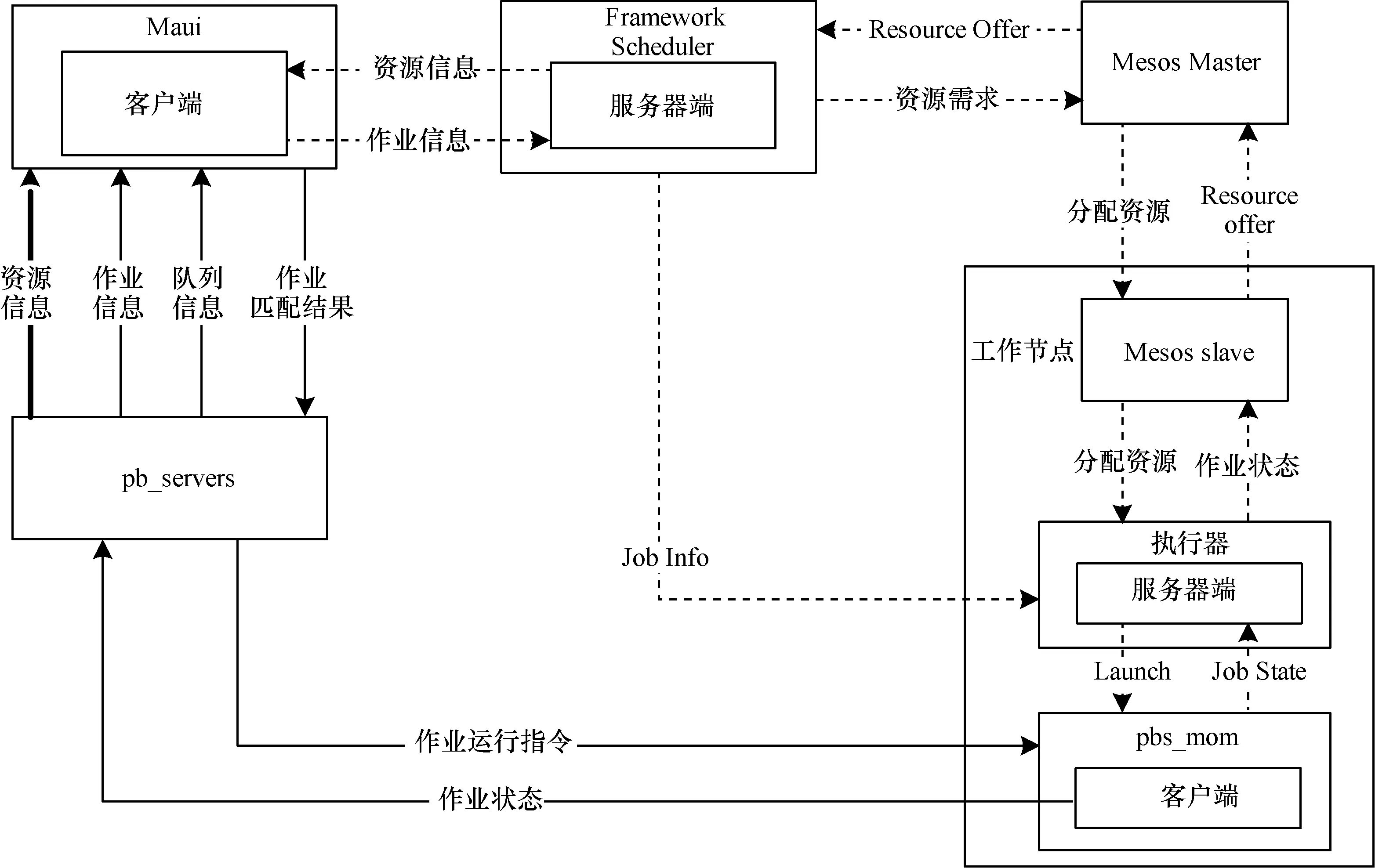
图4 Torque/Maui与Mesos的集成架构
由于Mesos资源分配拉(pull)的模式和Maui作业分配推(push)的模式有冲突,本文设计了一个Hashmap作为缓冲数组来接收Mesos分配的资源,在资源接受完毕后,由Maui查询并进行作业分配,将每个资源分配到的作业信息写入数组中,作业信息用邻接链表来保存。对于没有分配作业的offer,调用offer.decline()方法回收资源,分配给另外的框架使用。资源数组和作业信息结构如图5所示。
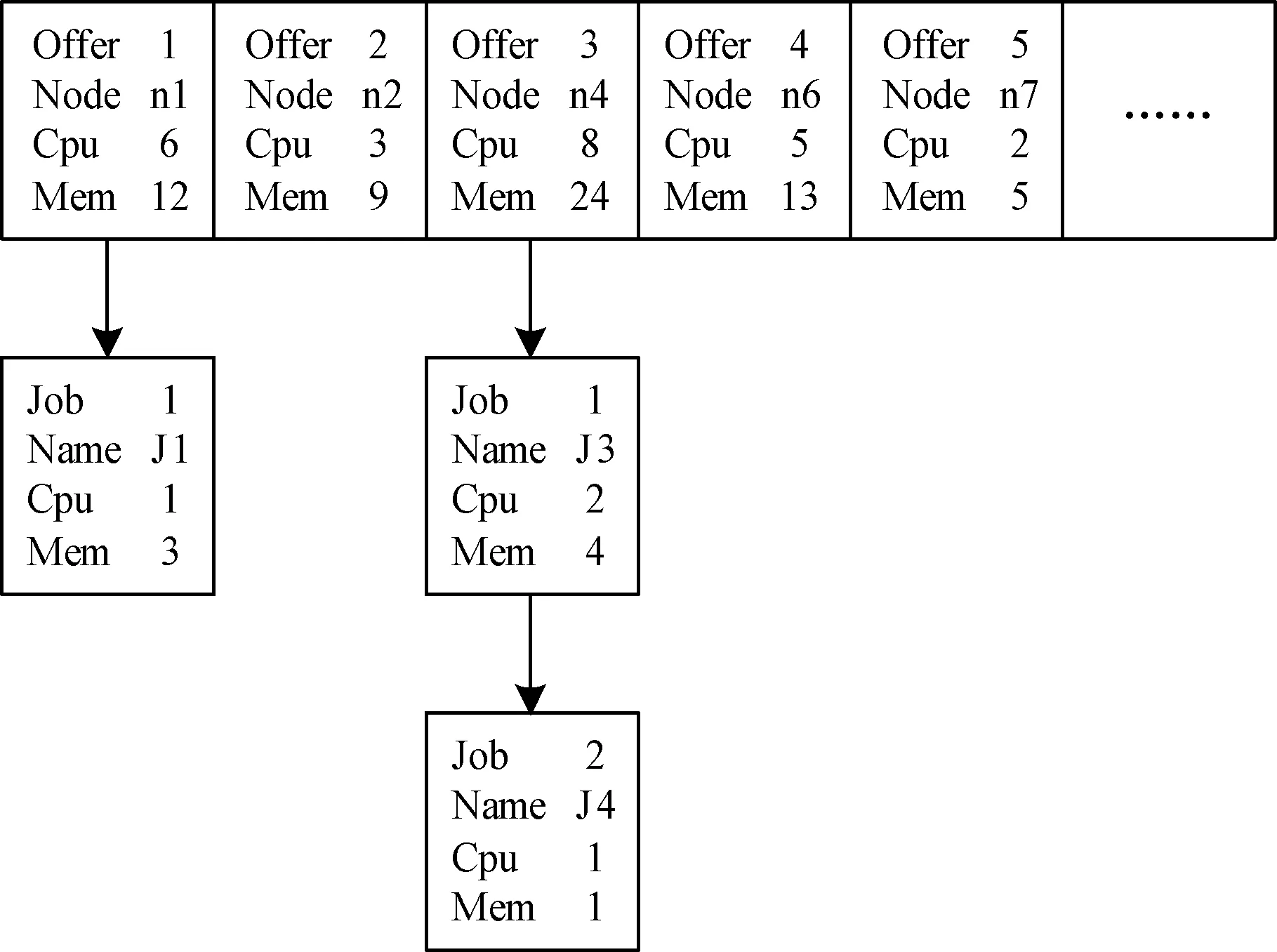
图5 Framework Scheduler中的资源和作业信息
3.1.2 Executor的设计与实现
Executor的功能是获取节点上Mesos分配给它的资源,对作业进行操作和更新作业状态。在作业执行的过程中,Mesos需要监控作业的运行状态,并根据作业状态决定对该作业的操作和释放资源。
在Executor的设计中,只需要让Executor启动pbs_ mom,具体作业的执行和操作由pbs_mom来进行。pbs_mom在作业执行的过程中,会向pbs_server汇报作业状态信息,本文利用这个动作来更新Mesos中的作业状态。在这里仍然使用Socket进行进程间的通信。
Executor在启动作业时,为每一个作业都创建了一个线程负责更新该作业的状态,并通过一个全局变量的数组来保存正在运行的作业的状态。pbs_ mom在修改作业状态的同时,会通过Socket把作业的状态发送给本地的Executor。Executor在接收到作业状态信息后,更新数组中对应作业的状态,并触发相应的作业线程去更新Mesos中的作业状态,或触发完成作业释放资源、杀掉作业等操作。Executor的结构设计如图4右下角所示,这样的设计可以把2个系统之间的通信分散在各个计算节点上,保证系统的稳定性。
3.2 信息交互格式定义
为简化消息处理机制,使2个系统之间的信息交互更简单高效且易读,本文定义了一个结构体request来传递消息:


结构体request中各字段的名称和含义如表1所示,其中,req_type指定消息类型;hostname指定消息相关的节点名称;message指定消息内容;value指定消息的值。表1中的示例为:更新节点host01上的作业job0103的状态为6。

表1 结构体request各字段定义及示例
4 系统评估测试
系统的实现基于 HDFS2.0,MapReduce0.20, Torque2.5.5,Maui3.2.6和Mesos0.14.0。通过部署在X86架构的服务器,每个节点的配置为8× 2.4 GHz CPU,24 GB内存,千兆以太网卡,2×2 TB的SATA硬盘,形成一个由1个服务器节点、6个计算节点组成的混合集群。
系统测试采用真实的BESIII实验数据和真实的高能物理实验数据处理软件BOSS[13]和BEAN,运行真实的模拟作业、重建作业和分析作业作为测试程序。
图6显示的是Torque/Maui集群在运行真实物理作业的CPU资源使用情况,可以看到,CPU核平均有约20%左右的空置。
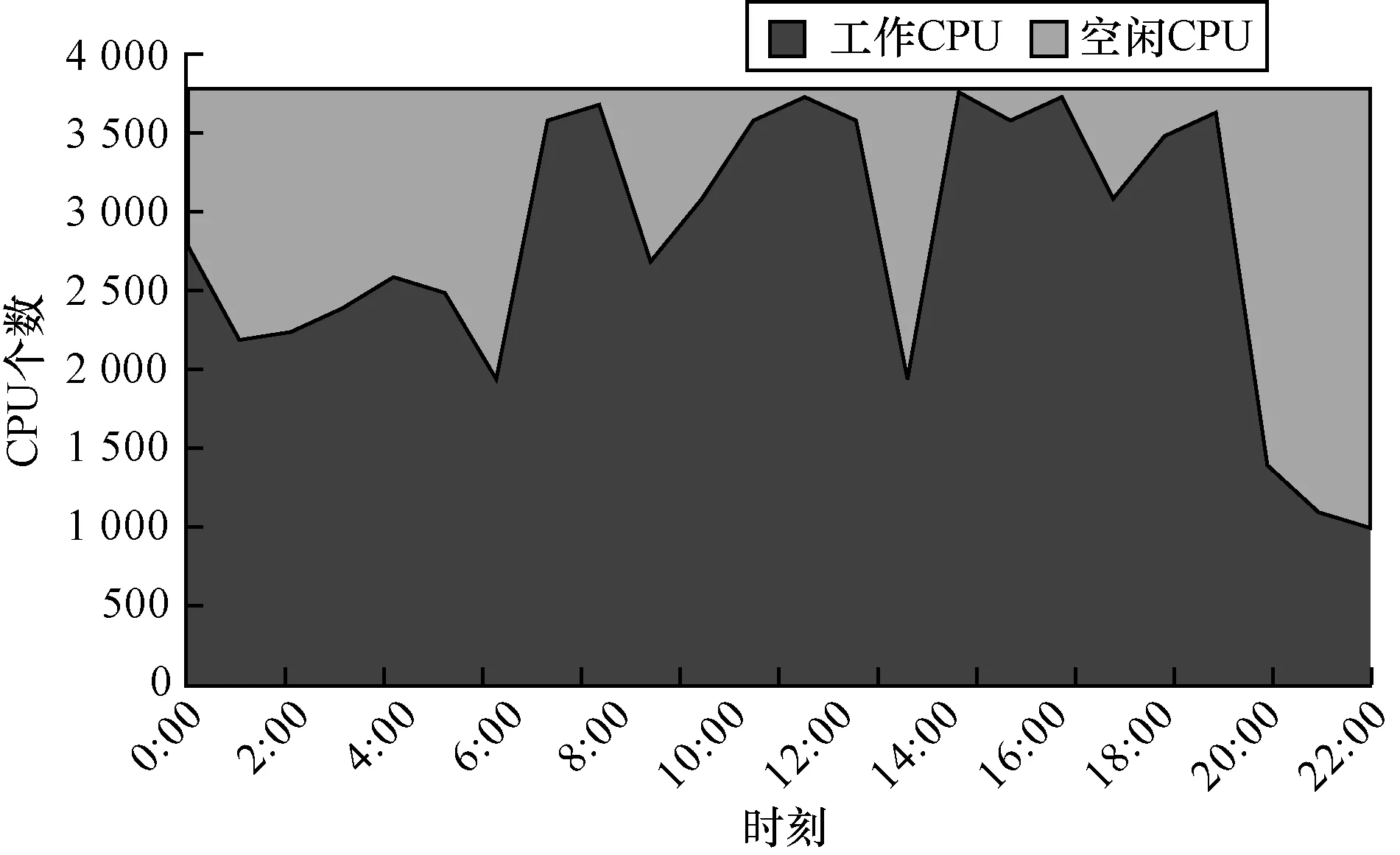
图6 BESIII集群CPU使用情况
图7显示的是采用新的系统架构后集群的整体CPU使用情况和CPU在2个框架间的动态分配情况。本文设置2个集群的资源使用比例为Hadoop: Torque=5:7。由图7可见,当没有Hadoop作业时, Torque集群可以独占集群的CPU资源,当Hadoop中有作业时,资源占用比例逐渐变为5:7。当Hadoop中作业数量减少时,Torque占用资源增加,当Torque作业数量减少时,Hadoop资源占用量增加,集群资源可以根据2个集群的作业数量动态地进行调整。
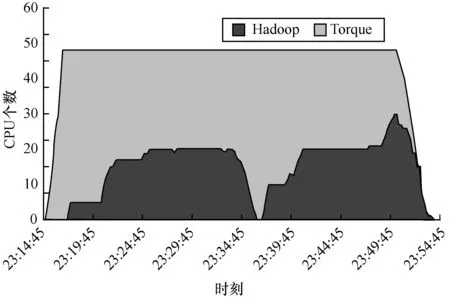
图7 Hadoop与Torque占用资源比例
图8显示的是测试集群分别运行Torque/Maui和混合集群时的网络I/O速度。由图8可见,仅运行Torque/Maui时,6个计算节点的总I/O速度约为200 MB/s,平均每个节点33 MB/s。如果以现在BESIII集群1 000个节点的规模估算,总带宽约为33 GB/s,所以BESIII集群的带宽压力很大。而运行混合集群时,由于Hadoop集群基本上都从本地读取数据,混合集群的网络I/O速度下降了40%,因此大大降低了带宽压力。
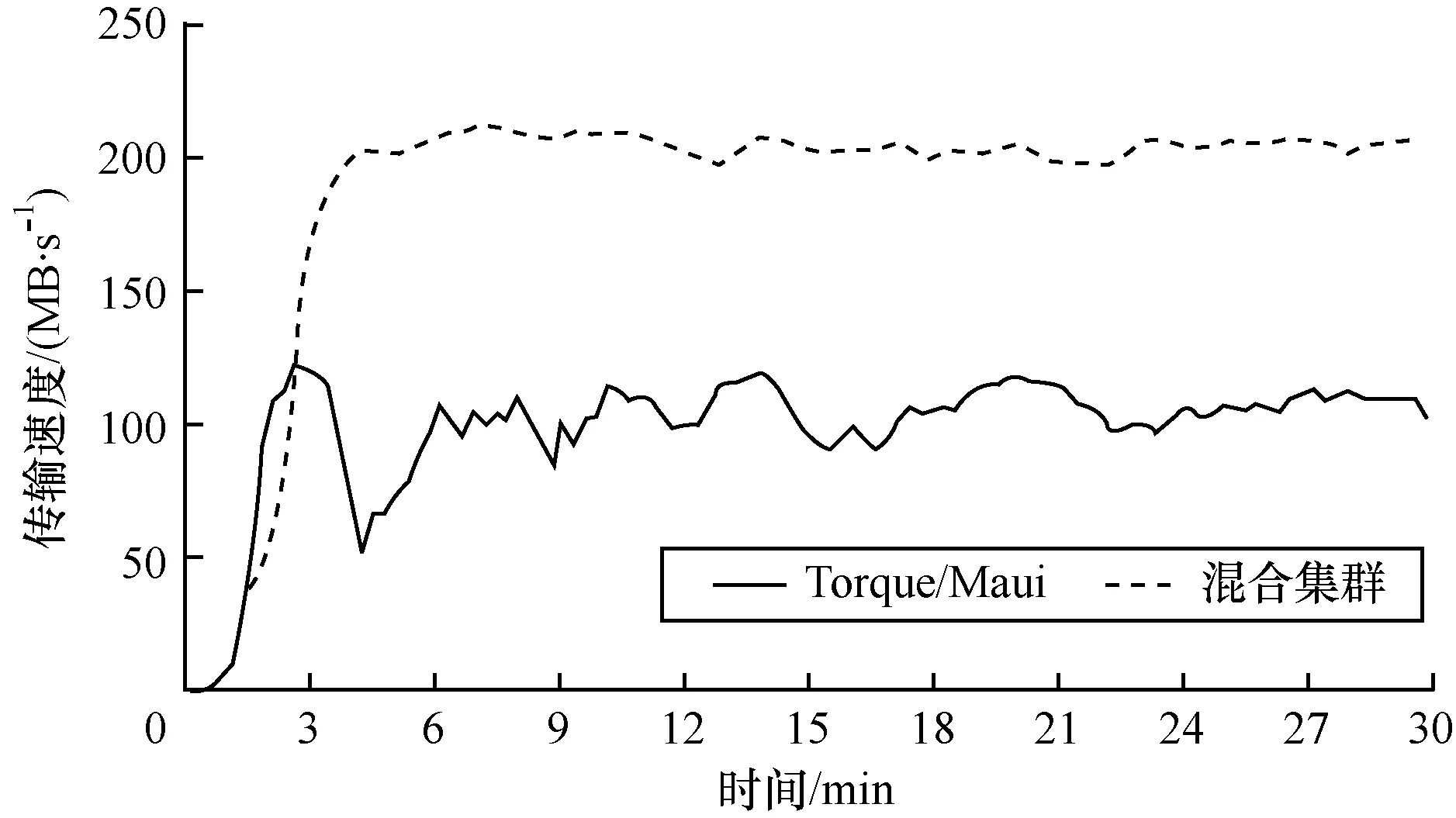
图8 测试集群网络I/O速度
图9显示的是测试集群分别运行Torque/Maui和混合集群时的磁盘I/O速度。
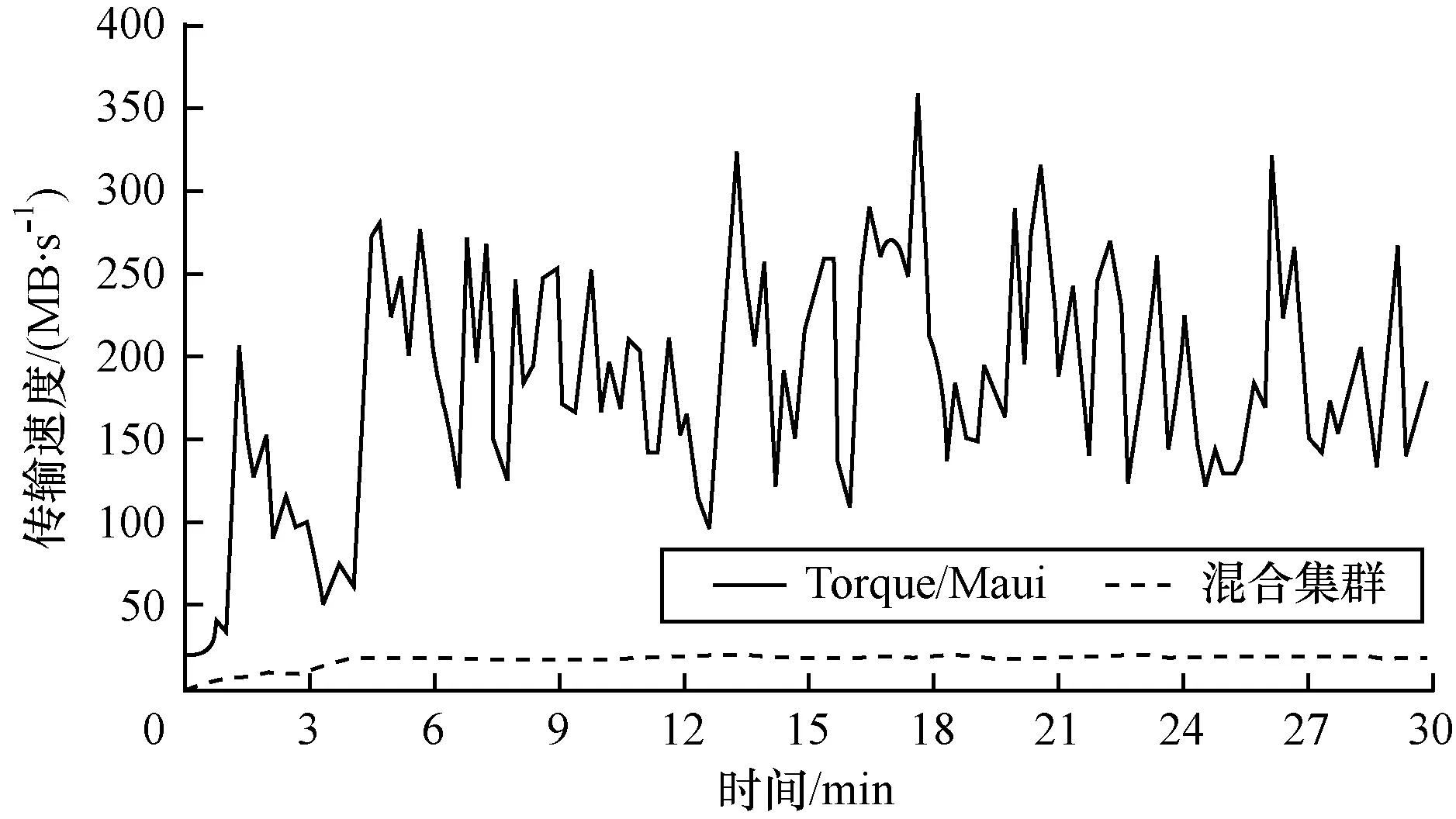
图9 测试集群本地磁盘I/O速度
可以看到,因此Torque集群运行时,作业数据全部从网络读取,所以磁盘I/O速度很低,共20 MB/s左右。但是Hadoop集群由于需要从本地磁盘读取数据,因此磁盘I/O速度较高,平均有200 MB/s左右。这个数值是图8中网络I/O下降数值的2倍,也说明了使用Hadoop处理分析作业时的数据读取效率比Torque/ Maui集群要高。
5 结束语
本文在分析高能物理数据处理的实际需求和集群特点后,利用Mesos构建了一个支持集群间资源动态分配的高能物理实验数据处理框架。经过初步测试,证明该系统架构可以在不同的框架间动态地分配集群资源,有效降低网络I/O压力,利用计算节点本地磁盘扩充系统存储容量,显著提高了资源利用率。
在实际应用中会遇到更多问题,在资源分配上还需要进一步改进,例如同一集群中的机器性能和配置上可能有较大差异,如何为不同的应用分配合适的机器是资源分配时需要考虑的因素之一。
[1] Staples G.TORQUE Resource Manager[C]//Proceedings of 2006ACM/IEEE ConferenceonSupercomputing. New York,USA:ACM Press,2006.
[2] Adaptive Computing.Maui[EB/OL].[2014-02-15].http:// www.adaptivecomputing.com/products/open-source/maui/.
[3] Yahoo.Apache Hadoop[EB/OL].[2014-02-15]. http://hadoop.apache.org/.
[4] Dean J,GhemawatS.MapReduce:SimplifiedData Processing on Large Clusters[J].Communications of the ACM,2008,51(1):107-113.
[5] Shvachko K,Kuang H,Radia S,etal.The Hadoop Distributed File System[C]//Proceedings of the 26th IEEE Symposium on Mass Storage Systems and Technologies. Incline Village,USA:IEEE Press,2010:1-10.
[6] 臧冬松,霍 菁,梁 栋,等.基于MapReduce的高能物理数据分析系统[J].计算机工程,2014,40(2):1-5.
[7] Hindman B,Konwinski A,Zaharia M,et al.Mesos:A Platform for Fine-grained Resource Sharing in the Data Center[C]//Proceedings of NSDI’11.Berkeley,USA: USENIX Association,2011:22-22.
[8] Schwan P.Lustre:Building a File System for 1000-node Clusters[C]//Proceedings of 2003 Linux Symposium. Ottawa,Canada:[s.n.],2003:380-386.
[9] Hunt P,Konar M,Junqueira F P,et al.ZooKeeper:Waitfree Coordination forInternet-scale Systems[C]// Proceedings of 2010 USENIX Conference on USENIX Annual Technical Conference.[S.l.]:USENIX Association,2010:11.
[10] Ghodsi A,Zaharia M,Hindman B,et al.Dominant Resource Fairness:Fair Allocation of Multiple Resource Types[C]//Proceedings of NSDI’11.Berkeley,USA: USENIX Association,2011:323-336.
[11] Puppet Labs.What is Puppet?[EB/OL].[2014-02-15]. https://puppetlabs.com/puppet/what-is-puppet/.
[12] IBM.Ganglia Monitoring System[EB/OL].[2014-02-15]. http://ganglia.info/.
[13] Li Weidong,Liu Huaiming,Deng Ziyan,et al.The Offline Software for the BESIII Experiment[C]//Proceedings of CHEP’06.Mumbai,India:[s.n.],2006.
编辑 金胡考
High Energy Physics Data Processing System with Parallel Heterogeneous Clusters
HUO Jing1,2,LEI Xiaofeng1,2,LI Qiang1,2,SUN Gongxing1
(1.Institute of High Energy Physics,Chinese Academy of Sciences,Beijing 100049,China; 2.Graduate University of Chinese Academy of Sciences,Beijing 100049,China)
The traditional cluster computing system can not make best of the local disks and disk I/O resources, therefore the network becomes the bottleneck of the whole system.And this is the reason of low utilization of the cluster resources and high cost on data storage and network equipment.Using Hadoop to process analysis can significantly reduce the pressure on network I/O by using the local disks as a distributed file system.Mesos is a cluster resource manager with light-weight design and efficient communication mechanisms that can dynamically share resources among clusters.This paper introduces the features of High Energy Physics(HEP),data processing,presents a new HEP data processing system by using Mesos to provide dynamic resource sharing among clusters,and implements integration of Toruqe/Maui and Hadoop which can avoid the disadvantages.The test result shows that the new system can dynamic distribute the cluster resource,and reduce the network I/O,improve the resource utilization.
High Energy Physics(HEP);cluster resource management;resource sharing;Mesos tool;Hadoop platform; Toruqe/Maui system
1000-3428(2015)01-0001-05
A
TP391
10.3969/j.issn.1000-3428.2015.01.001
国家自然科学基金资助项目(11375223,11375221);国家自然科学基金A3前瞻计划基金资助项目(61161140454)。
霍 菁(1985-),男,博士研究生,主研方向:分布式计算,集群资源管理;雷晓凤、李 强,博士研究生;孙功星,研究员。
2014-02-17
2014-03-20 E-mail:huojing@ihep.ac.cn
中文引用格式:霍 菁,雷晓凤,李 强,等.支持异构集群并行的高能物理数据处理系统[J].计算机工程,2015, 41(1):1-5.
英文引用格式:Huo Jing,Lei Xiaofeng,Li Qiang,et al.High Energy Physics Data Processing System with Heterogeneous Clusters[J].Computer Engineering,2015,41(1):1-5.
猜你喜欢
科学文化评论(2022年1期)2022-06-27
心理学报(2022年4期)2022-04-12
水泵技术(2021年3期)2021-08-14
电脑爱好者(2019年2期)2019-10-30
网络安全和信息化(2018年2期)2018-11-09
网络安全和信息化(2017年3期)2017-03-10
网络安全和信息化(2016年8期)2016-11-26
中国惯性技术学报(2015年1期)2015-12-19
测绘科学与工程(2013年3期)2013-03-11
网络传播(2009年7期)2009-07-31
