
模糊C均值聚类区间型模糊化参数模型
2015-06-01 12:30肖满生文志强于惠钧
系统工程与电子技术 2015年4期
肖满生,肖 哲,文志强,于惠钧
(1.湖南工业大学科技学院,湖南株洲412008;2.湖南工业大学计算机与通信学院,湖南株洲412008)
模糊C均值聚类区间型模糊化参数模型
肖满生1,2,肖 哲1,文志强2,于惠钧1
(1.湖南工业大学科技学院,湖南株洲412008;2.湖南工业大学计算机与通信学院,湖南株洲412008)
针对经典模糊C均值聚类算法中模糊加权指数对聚类的影响及其取值范围不确定性问题,提出了一种区间型模糊加权指数的设计模型。分析该模型设计的理论依据及对聚类结果的影响,推导出包括模糊隶属度划分矩阵、模糊聚类中心等基于该模型的模糊化参数表示方法。理论分析和实验证明,区间型模糊化参数模型的设计在基于模糊划分的数据处理中取得了很好的效果。
模糊C均值;区间型模糊加权指数;模糊化参数;不确定性
0 引 言
经典的模糊C均值(fuzzy C-means,FCM)聚类是一个基于目标函数的带约束的非线性规划过程,通过对参数的优化求解获得样本集的模糊划分或聚类,该方法及其改进技术在信息技术和控制决策等领域获得了广泛的应用,如图像处理[12]、模式识别[3]、数据挖掘[4]、模糊决策[5]等。
然而,随着研究深入,经典的FCM聚类算法在实际应用过程中还要受到诸多限制,相关理论也有待进一步完善。如在处理不确定性问题时,经典的FCM算法对样本的划分有明确的隶属度约束,这类算法叫1型FCM(1-TFCM)[6];而客观世界在对样本进行分析和模式识别时存在各种各样的不确定性,因此,如果合理地给出样本隶属度的模糊程度,即样本的模糊隶属度,则更能恰当地描述集合的模糊性,这种改进的FCM算法叫2型FCM算法(2-TFCM),在这方面,文献[6- 9]取得了一定的研究成果。另外,在研究围[1.1,5]以后,文献[11- 14]进行了大量研究。文献[11]从聚类有效性实验中得到m的最佳区间为[1.5,2.5];文献[12]基于模糊决策提出了一种m值的优选方法;文献[13]通过在标准FCM的隶属度μik的约束条件中引入幂指数r,提出一种双指数模糊C均值算法(double index fuzzy C-mean,DI-FCM),该算法在理论上有效地扩展了m的取值范围;文献[14]从粒子群优化的角度,得到了一个模糊加权指数值,并由此解释了FCM聚类对初始聚类中心敏感的问题。这些方法对模糊加权指数m的确定都是凭经验或实验进行,缺乏理论依据和有效的评价方法。另外,文献[9]通过α-平面截集描述模糊集,可以得到m值的设计与具体聚类样本集有关,但其精确选取是非常困难也是不可能的。
基于此,本文在分析现有的FCM聚类及其改进算法的模糊化参数过程中,模糊加权指数m是FCM聚类算法中重要参数,其直接影响到聚类结果的不确定性程度。在实际应用过程中,自文献[10]引入并给出m经验值范基础上,受文献[15- 17]中改进的FCM聚类特点和模糊化参数设计启发,包括模糊隶属度函数的设计与评价、模糊聚类中心及聚类数目的确定、样本与聚类中心的距离计算等,提出了一种区间型FCM聚类模糊化参数设计模型。即首先通过分析模糊加权指数的不确定性及其对聚类的影响,提出了区间型模糊加权指数m的设计方法,基于区间型模糊加权指数,推导出模糊隶属度、模糊聚类中心(质心)的设计方法,通过“反模糊化”后得到确定的模糊化参数,并将该方法应用于图像分割、模式识别等实验。理论分析和实验对比表明,本文提出的FCM模糊化参数模型不但改善了FCM算法的聚类性能,提高了样本划分的效率,而且对模糊聚类算法的进一步研究和拓展有很好的指导意义。
1 模糊加权指数的不确定性分析与设计
FCM聚类目标函数为

该目标函数中,模糊加权指数m控制着样本在类间的分享程度。理论分析和实际应用表明,随着m的增加,聚类的目标函数值单调下降,这与最小化目标函数的思想一致,而且较大的m还有平滑聚类结果、抑制噪声的功能,但是,参数m还控制着FCM聚类结果的模糊性,m越大,聚类结果越模糊,模糊边界越大,从这个角度来说,又希望m取值不要太大。因此,合理的m值应该取多少,一直是FCM聚类中备受关注的问题。
m取值的不确定性及对聚类结果的影响可用图1、图2表示。

图1 划分类容量相近时参数m对模糊聚类的影响
图1 中,C1、C2是两划分类,v1、v2分别为两划分类的聚类中心,两划分类之间的垂直平分竖线(阴影区域)为其模糊边界,也叫决策边界,位于边界左侧(右侧)的样本归属于类C1(C2),而位于边界上的数据样本则对于类C1(C2)有相同的隶属度,其所归属某类的程度非常模糊。图1中,对于容量相近的两划分类,当m=1时,其模糊边界是一条直线,由于边界区域很窄,当受到噪声等不确定因素影响时,边界(竖线)附近的样本很容易产生错误划分的情况,如图1(a)所示;随着取值的增大,模糊边界将变宽,如图1(b)中的阴影部分所示,边界的扩展可将更多不确定的数据点纳入模糊边界中,使其具有相同的隶属度,以便减小聚类中心更新时不确定因素的影响;当m进一步扩大,使模糊边界扩展到图1(c)所示的位置时,此时的边界区域最为理想,划分结果最为明晰,此时除了划分类C1、C2之间的样本(全位于边界区域)外,其余样本都有明晰的归属类;然后,当m进一步扩大,以致m→∞时,模糊边界充满全域,如图1(d)所示,此时模糊化程度达到最大,所有样本的隶属度(c为划分类数目),因而FCM算法失去了划分特性。
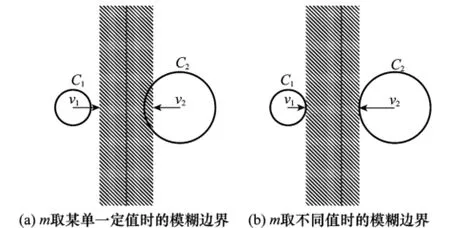
图2 划分类容量不同时参数m对模糊聚类的影响
上述是两划分类容量相等或相近的情况,对于划分类容量不同的样本,当m取某一定值时,模糊边界如图2(a)所示,这时,本来属于划分类C2中的样本却归属到模糊边界,而左边模糊边界之外的本不归属于划分类C1的样本则被划到类C1中,这样的模糊边界不理想,模糊聚类的不确定性高,如果能针对不同的划分类容量设计不同的参数m,使模糊边界达到一个理想区域,如图2(b)所示,这时,在保证每个聚类中心v1、v2与竖线的距离(位置)不变的情况下,所有样本数据都有较理想的隶属度,即除了模糊边界(两划分类之间)的样本外,其余样本都能较好地归属于相应的类,这种情况下,模糊聚类的准确性有很大的提高。
针对上述模糊加权指数m取值的不确定性及对不同容量的划分类的模糊聚类影响,将模糊加权指数区间化,即设计一模糊区间:m=[m1,m2],其中m1、m2分别对应于较小、较大容量差异的划分类,这样,当划分类容量不同时的样本进行聚类分析时,根据最大、最小划分类设计的区间模糊加权指数求取样本的隶属度,并确定聚类中心,这样能显著改善聚类性能,同时也降低了模糊加权指数设计的不确定性。
2 FCM聚类模糊化参数模型
本节根据第1节所提出的区间型模糊加权指数,设计并推导FCM聚类中其他模糊化参数模型,并通过“反模糊化”得到具体的聚类参数,包括模糊隶属度、模糊聚类中心等。
2.1 区间型模糊隶属度及聚类中心计算模型
隶属度是FCM聚类中的重要参数,它直接反映某一样本隶属于某一划分类的程度,在第1节中,当模糊加权指数被设计为区间型参数后,相应的模糊隶属度也可以设计为区间型参数,即为形式,其中表示样本xi对于划分类j的最小隶属度;¯μj(xi)为最大隶属度。以图2中的v1和v2连线之间的一维样本为例,设v1=0,v2=1,则样本集X∈[0,1],取模糊加权指数m1=2.0,m2=4,则基于区间型指数[m1,m2]的样本集X对于划分类C1的隶属度表示形式如图3所示。
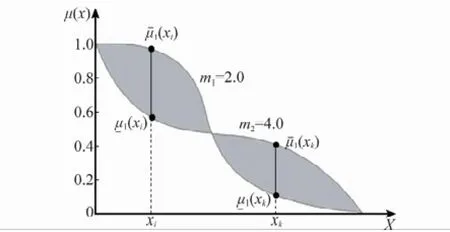
图3 模糊隶属度的区间型表示方法
图3 中参数m1和m2所对应的隶属度曲线所包含的阴影部分即为样本的区间型隶属度。参考经典FCM聚类的隶属度计算方法,区间型隶属度计算模型设计为
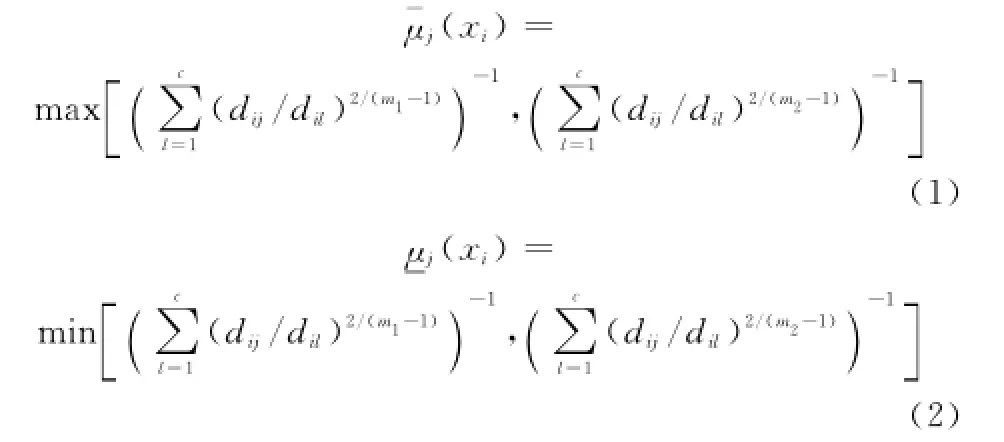
当用式(1)和式(2)来更新FCM聚类中心时,必然也将得到一个区间型聚类中心,设某一区间型聚类中心为,根据经典FCM聚类中心更新的推导方法,区间型聚类中心表示为
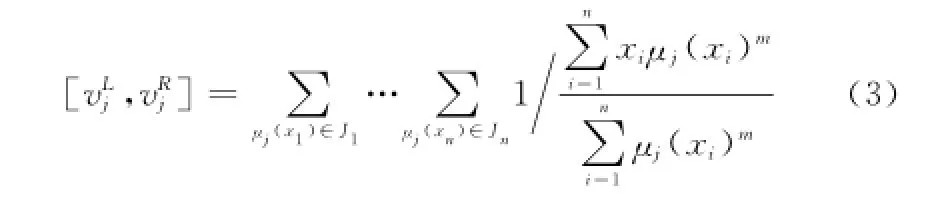
式中,J1,J2,…,Jn为样本隶属度区间,即分别为聚类中心的左边界值和右边界值(即最大值和最小值),模糊加权指数m根据式(1)和式(2)可以在m1、m2之间变换,至于怎样推导并得到该公式可参考文献[10],此处不再赘述。
2.2 区间型参数的反模糊化处理
区间型模糊化参数的设计使得模糊聚类更能表达聚类的不确定性需求和人们对于事务判断的意愿。然而,在实际应用过程中,却遇到了很大的困难:一是区间型参数的存在使得聚类更为模糊,对一些需要明确划分的类增加了其不确定性程度;二是基于区间型参数的模糊划分,其计算复杂度增加,特别对于大量的高维(多属性)样本集,其计算的复杂度将线性增长。基于此,本文设计了区间型参数的反模糊化处理方法,使得模糊聚类既能很好表达聚类的不确定程度,又能方便计算,实现类别的客观划分,两者得兼。
第2.1节中式(3)只是区间型聚类中心表示形式。在实际应用中,我们必须事先确定其左、右边界值vLj和vRj,当和确定后,可以利用式(4)进行反模糊化,得到确定的聚类中心vj。

区间型聚类中心右边界vRj确定算法如下:
设样本集X包含n个样本x1,x2,…,xn,每一个样本由M维属性组成,即xi=(xi1,xi2,…,xiM),通过对所有样本的M个属性分别进行升序排序后计算,得到样本集聚类中心的右边界(即聚类中心的最大值),具体描述如下:
给定加权指数m一个任意区间,即m=[m1,m2];
FOR
所有样本xi=(xi1,xi2,…,xiM);
END FOR
用式(5)和式(6)计算样本集的M维聚类中心v′j=(v′j1,v′j2,…,v′jM);

对n个样本的M维特征,分别进行升序排序,即

设一比较判断变量com=F;
FOR
所有样本属性
WHILE(com=F)
查找一个索引值k(1≤k≤n-1),使得xkl=v′jl=x(k+1)l(1≤l≤M);FOR所有样本
如果i≤k,则μj(xi)=μj(xi),
END FOR
用更新的μj(xi)重新计算某一维聚类中心v′jh′(1≤l′≤M);
如果v′jh==v′jh′,则com=T,否则设v′jh=v′jh′
END WHILE
END FOR
最后,得到的v′jh为所求,即vRj=(v′j1,v′j2,…,v′jM)。
上面算法得到了聚类中心的右边界vRj,对于左边界,只要对“FOR所有样本”语句进行修改即可。
FOR所有样本
END FOR
从上述算法中,确定样本隶属度函数,可以通过反模糊化来实现:假设在计算聚类中心vRj时的隶属度函数为则样本xi最终模糊化隶属度可以设置为时为

考虑到样本xi是由M维属性组成,因此和可由式(8)和式(9)来计算。

至于式(8)和式(9)中的μj(xi)的取值,采用的是还是可根据情况进行交换。
3 基于区间型模糊化参数的FCM聚类
有了第2节的模糊化参数定义,改进FCM聚类实现过程如下:
步骤1 给定聚类类别数c及区间型模糊加权指数[m1,m2],n为数据集样本总数,设定迭代停止阈值为ε,迭代次数计数器t=0;
步骤2 初始化聚类中心v(l);
步骤3 根据第2.1节中的式(1)和式(2)分别得到隶属度区间的上下边界值,即和
步骤5 利用第2.2节中提出的反模糊化公式(4),确定实际的模糊聚类中心v(t+1);
步骤6 如果‖v(t+1)-v(t)‖<ε,则停止迭代,输出聚类中心v(t+1),转步骤7,否则t=t+1,根据新的v(t+1),返回步骤3,继续;
步骤7 根据步骤6得到的模糊聚类中心以及由此确定的区间型模糊隶属度,对区间型模糊隶属度进行反模糊化处理,即μ=(μL+μR)/2,得到最后的模糊划分隶属度矩阵,再按最大隶属度原则得到聚类结果。
4 实验结果分析
为了验证本文提出区间型模糊化参数模型的有效性,引入了如下评价指标:
划分系数vpc。基于模糊划分矩阵的划分系数表示为

式中,n为样本数量;c为聚类数;μij∈[0,1]为样本xi相对于划分类j的隶属度,样本的隶属度越大,即μij越大,划分系数越大,聚类效果越好。
划分熵vpe。其表示为

从式(11)中可看出,μik越大,则vpe值越小,故划分熵越小,聚类效果越好。
划分类内部均匀性测度(uniformity measure,UM)评判函数。该评判函数用来评价各划分类内部样本分布均匀的程度,其定义为

式中,Ri表示第i个划分类(划分区域);Ai为该划分类的样本个数;N为归一化系数,本文可设为样本总数。从式(12)可分析出,划分类内部样本分布越均匀,即样本xk与内部其他样本相差越小,则UM值越小,因此,UM反映了各类样本内部分布均匀性的程度。
实验1 图像分割实验
图4(a)为图像处理中常用的图像Camera man(128× 128),对其进行分割实验。同时为了比较实验效果,采用经典的FCM聚类算法与本文提出的基于区间型模糊化参数模型的FCM(interval-FCM,IFCM)方法进行对比分割。由于经典FCM算法本身无法自动获取分类数目,因此采用读入图像灰度直方图的方法获取聚类数c及初始聚类中心v。经典FCM算法m=2.0,IFCM算法选择m1=1.5,m2=4.0。算法共进行了50次迭代。实验环境:Visual C++6.0编程,操作系统Windows 7,Dell Precision M4500,Intel Core i7 CPU,8G RAM。实验将图像按灰度不同分成人物、草地、天空3类。分割实验结果如图4(b)和图4(c)所示,实验中各评价参数对比如表1所示,其中time为实验中计算耗时。

图4 Cameraman图像分割结果

表1 Cameraman图像分割效果比较
从实验中可以看出,对于评价指标vpe,IFCM>FCM,对于评价指标vpe及UM,IFCM<FCM,因此,本文提出的IFCM方法在图像分割中其应用效果要比经典的FCM算法好。但本文提出的方法其计算的时间复杂度远远超过经典FCM算法。
实验2 人造数据划分
一个干净无噪声的人造实验样本数据集如图5(a)所示,由一大两小的3类样本子集组成,采用高斯分布的随机向量发生器产生,其主要参数如表2所示。另外,以此样本集为基础,在其中不断增加均匀分布的噪声点来进行实验,每次增加30个,共进行11次,最后一次噪声点数目达到300个。采用3种方法进行实验:①经典FCM算法取m=1.5;②经典FCM算法取m=4.0;③本文方法IFCM取区间型m=[2.0,5.0]。为了评价在加权指数m取不同值时,该样本集中划分类大小非均衡的聚类性能,各次实验中采用均匀性测度值UM进行比较,实验中UM比较曲线如图6所示。

图5 人造样本数据集

表2 无噪声人造样本集的主要参数

图6 各次实验中UM值比较
从图5可以看出,在无噪声干扰的情况下,各种方法划分的效果都比较好,随着噪声增加,实验中U M值不断增加,表明实验效果变差。另外,在各次实验中,总体情况IFCM算法的UM值比其他两种FCM测试方法所得到的UM值要小(除test case1中其UM值高于FCM m=1.5的情况外),表明区间型模糊参数化方法的聚类效果要比经典FCM算法中模糊加权指数m取单一值的聚类效果好,特别是在模糊划分类大小分布不均衡的情况下。
实验3 IRIS数据分类实验
本次实验采用文献[18]中提供的标准测试数据IRIS,它由四维空间的150个样本组成,共有3个类(c=3),每一个类50样本,所有划分类大小相等。对比实验中,经典FCM算法模糊加权指数分别取m1=1.5、m2=2.5,IFCM方法中取m1=2.0、m2=4.0组成区间值[2.0,4.0],实验环境与实验1中一致,实验中聚类中心和隶属度更新迭代次数为50次,实验评价指标除了划分系数vpc、模糊划分熵vpe、均匀性测试度UM以及计算耗时time外,还增加了错分样本数(error)及错分率(error ratio),实验结果如表3所示。

表3 IRIS样本聚类结果比较
从表3可以看出,当模糊加权指数m取不同值时,对标准测试数据集IRIS的模糊聚类效果不一样。其中,当模糊加权指数取区间型值时,其划分系数vpc最大,而划分熵vpe、均匀性测度UM以及错分率最低,表明其聚类效果好。另外,当m取单个值时,只要其值在一定范围内,其聚类效果的好坏难以评价,例如本实验中,当m=1.5或m=2.5时,两种情况下FCM聚类划分的效果难以比较。
上面分别从图像分割对比实验、划分类大小非均衡的人造数据划分实验以及标准测试样本IRIS聚类对比实验中,分析了模糊化参数对模糊聚类的影响,得出了区间型模糊化参数在模糊聚类中有较好的划分效果,但区间型模糊化参数在聚类划分过程中,由于计算复杂,故其计算耗时比经典的FCM算法要多,这一点从上述实验结果中可以明显看出,有关计算时间复杂度的分析受篇幅所限,本文未有述及。
5 结 论
本文通过分析经典FCM聚类算法中模糊加权指数m取值存在的困难及不确定性现状,提出了一种区间型模糊加权指数设计模型,并由此探讨了包括模糊隶属度、模糊聚类中心在内的模糊化参数模型的设计方法。实验的结果分析表明,采用区间型模糊化参数方法,不但可以较好解决样本集划分类之间差别悬殊问题,而且使划分结果更好,细节更详尽,特别对噪声干扰的数据划分有很强的鲁棒性。但是,在实际应用中,该方法还存在如下几个问题亟待解决:一是由于采用区间型参数计算,其计算复杂度较高,数据处理时间长;二是模糊加权指数的区间值大小是根据不同划分类样本而主观设计的,到底取多少没有统一标准和规范化方法,这些问题也正是作者及课题组成员下一步要研究解决的问题。同时需要指出,本文针对FCM聚类算法本身的参数进行区间化研究,与相关文献[19- 20]中提出的区间型数据的聚类研究是两个不同的概念,如何将这两者联系起来进行研究,即采用区间型模糊化参数研究区间型数据集,这也是我们正在研究的范畴。
[1]Ji Z X,Pan Y,Chen Q,et al.Natural image segmentation algorithm with unsupervised FCM[J].Journal of Image and Graphics,2011,16(5):773- 783.(纪则轩,潘瑜,陈强,等.无监督模糊C均值聚类自然图像分割算法[J].中国图象图形学报,2011,16(5):773- 783.)
[2]Tan K S,Lim W H,Isa N A M.Novel initialization scheme for fuzzy C-means algorithm on color image segmentation[J].Applied Soft Computing,2013,13(4):1832- 1852.
[3]Chen J S,Pi D C,Liu Z P.An insensitivity fuzzy C-means clustering algorithm based on penalty factor[J].Journal of Software,2013,8(9):2379- 2384.
[4]Sambasivam S,Theodosopoulos N.Advanced data clustering methods of mining web documents[J].Issues in Informing Science and Information Technology,2006(3):563- 579.
[5]Wang D D,Li B,Chen W F,et al.An improved FCM algorithm based on multiple objective programming[J].Journal of Image and Graphics,2008,13(8):1492- 1495.(王丹丹,李彬,陈武凡.基于多目标规划的模糊C均值聚类算法[J].中国图象图形学报,2008,13(8):1492- 1495.)
[6]Mendel J.Uncertain rule-based fuzzy logic systems:introduction and new directions[D].Upper Saddle River:Drentice-Hall,2001.
[7]Zhai D,Mendel J M.Uncertainty measures for general type-2 fuzzy sets[J].Information Sciences,2011,181(3):503- 518.
[8]Hwang C,Rhee F C H.Uncertain fuzzy clustering:interval Type-2 fuzzy approach to C-means[J].IEEE Trans.on Fuzzy System,2007,15(1):107- 120.
[9]Ondrej L,Milos M.General Type-2 fuzzy C-means algorithm for uncertain fuzzy clustering[J].IEEE Trans.on Fuzzy System,2012,20(5):883- 897.
[10]Bezdek J C.Pattern recognition with fuzzy objective function algorithm[M].New York:Plenum Press,1981.
[11]Pal N R,Bezdek J C.On clustering for the fuzzy C-means modeling[J].IEEE Trans.on Fuzzy System,1995,3(3):370 -379.
[12]Gong G Y,Gao X B,Wu Z D.An optimal choice method of parameter m in FCM clustering algorithm[J].Fuzzy Systems and Mathematics,2005,19(1):143- 147.(宫改云,高新波,伍忠东.FCM聚类算法中模糊加权指数m的优选方法[J].模糊系统与数学,2005,19(1):143- 147.)
[13]Wang J,Wang S T.Double indices FCM algorithm based on hybrid distance metric learning[J].Journal of Software,2010,21(8):1878- 1888.(王骏,王士同.基于混合距离学习的双指数模糊C均值算法[J].软件学报,2010,21(8):1878- 1888.)
[14]Wang Z H,Liu Z J,Chen D H.Research of PSO-based fuzzy C-means clustering algorithm[J].Computer Science,2012,39(9):166- 169.(王纵虎,刘志镜,陈东辉.基于粒子群优化的模糊C均值聚类算法研究[J].计算机科学,2012,39(9):166- 169.)
[15]Kannan S R,Ramathilagam S,Chung P C.Effective fuzzy C-means clustering algorithms for data clustering problems[J].Expert System with Applications,2012,39(7):6292- 6300.
[16]Wang X E,Han D Q,Han C Z.Selection method for parameters of rough fuzzy C-means clustering based on uncertainty measurement[J].Journal of Xi’an Jiaotong University,2013,47(6):55- 61.(王学恩,韩德强,韩崇昭.采用不确定性度量的粗糙模糊C均值聚类参数获取方法[J].西安交通大学学报,2013,47(6):55- 61.)
[17]Wu J J,Xiang H,Liu C,et al.A generalization of distance functions for fuzzy C-means clustering with Centroids of arithmetic means[J].IEEE Trans.on Fuzzy System,2012,20(3):557- 571.
[18]Newman D J,Hettich S,Blake C L,et al.UCI repository of machine learning databases[EB/OL].[2014- 04- 08].http:∥www.ics.uci.edu/~mlearn/ML-Repository.html.
[19]Chen J S,Pi D C.Improved fuzzy C-means model based on quadratic[J].Systems Engineering and Electronics,2013,35(7):1548- 1553.
[20]Li D,Gu H,Zhang L Y.A fuzzy C-means clustering algorithm based on nearest-neighbor intervals for incomplete data[J].Expert System With Applications,2010,37(10):6942- 6947.
Interval type fuzzifier parameter model in fuzzy C-means clustering
XIAO Man-sheng1,2,XIAO Zhe1,WEN Zhi-qiang2,YU Hui-jun1
(1.College of Science and Technology,Hunan University of Technology,Zhuzhou 412008,China;2.College of Computer and Communication,Hunan University of Technology,Zhuzhou 412008,China)
Aiming at the problem about the effect of the fuzzy weighted index in classical fuzzy C-means clustering algorithm and the value of uncertainty,the model of interval type fuzzy weighted index is proposed.Theoretical basis of the model and its effect on the clustering results are analyzed.Based on this model,the fuzzifier parameter such as fuzzy membership partition matrix,fuzzy clustering center representation is derived.The theoretical analysis and experimental results show that the interval type fuzzifier parameter model designing has achieved good effect based on data processing of fuzzy partition
fuzzy C-Means(FCM);interval fuzzy weighted index;fuzzifier parameter;uncertainty
TP 391
A
10.3969/j.issn.1001-506X.2015.04.22
肖满生(1968-),男,教授,主要研究方向为智能计算和智能信息处理。E-mail:xiaomansheng@tom.com
肖 哲(1977-),女,讲师,硕士,主要研究方向为智能信息处理。E-mail:snakexz@sina.com
文志强(1973-),男,副教授,博士,主要研究方向为数据挖掘和图像处理。E-mail:zhqwen20001@163.com
于惠钧(1975-),男,副教授,主要研究方向为数据挖掘、智能控制。E-mail:463298180@qq.com
1001-506X(2015)04-0868-06
2014- 04- 21;
2014- 09- 01;网络优先出版日期:2014- 10- 30。
网络优先出版地址:http://w ww.cnki.net/kcms/detail/11.2422.TN.20141030.1134.011.html
国家自然科学基金(61170102);湖南省自然科学基金(13JJ9017);湖南省教育厅科研项目(13C032)资助课题
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
厦门大学学报(自然科学版)(2022年4期)2022-07-15
现代装饰(2020年7期)2020-07-27
中国外汇(2019年13期)2019-10-10
商(2016年28期)2016-10-27
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
中学理科·综合版(2008年9期)2008-10-15
