
维基百科中翻译对的模板挖掘方法研究
2015-04-21 09:26段建勇闫启伟
中文信息学报 2015年2期
段建勇,闫启伟,张 梅,胡 熠
(1. 北方工业大学 信息工程学院, 北京 100144;2. 腾讯公司 搜索产品部, 上海 200230)
维基百科中翻译对的模板挖掘方法研究
段建勇1,闫启伟1,张 梅1,胡 熠2
(1. 北方工业大学 信息工程学院, 北京 100144;2. 腾讯公司 搜索产品部, 上海 200230)
双语翻译对在跨语言信息检索、机器翻译等领域有着重要的用途,尤其是专有名词、新词、俚语和术语等的翻译是影响其系统性能的关键因素,但是这些翻译对很难从现有的词典中获得。该文针对维基百科的领域覆盖率和结构特征,提出了一种从维基百科中自动获取高质量中英文翻译对的模板挖掘方法,不但能有效地挖掘出常见的模板,而且能够发现人工不容易察觉的复杂模板。主要方法包括三步: 1)从语言工具栏中直接抽取翻译对,作为进一步挖掘的启发知识;2)在维基百科页面中采用PAT-Array结构挖掘中英翻译对模板;3)利用挖掘的模板在页面中自动挖掘其他中英文翻译对,并进行模板评估。实验结果表明,模板发现翻译对的正确率达90.4%。
双语翻译对;维基百科;模板挖掘;信息抽取
1 引言
跨语言信息检索(CLIR)提供了一种方便的途径,使得用户能够使用自己熟悉的语言提交查询,检索另一种语言的文档。CLIR中常见的方法有同源词匹配、文档翻译、中间语言和查询翻译等[1]。查询翻译为CLIR中采用最广泛的方法,查询翻译方法在检索前采用各种资源将查询翻译成文档集合所采用的目标语言,然后进行单语言查询(MIR)。但是查询中有很多词为专有名词(Proper Names),包括人名、地名等,还有新词和专业术语,如果不能对这些词进行正确的翻译,会使不相关文档排序较前,从而严重降低系统性能。因此未登录词(Out of Vocabulary,OOV)的查询翻译是影响CLIR性能的关键因素之一[2]。
维基百科作为自由、开放的在线百科全书,具有准确性高、领域覆盖广的优点。截至2012年8月8日,中文维基百科拥有508 701个词条,这给未登录词的译文挖掘提供了有利的条件[3]。大部分中文词条均能通过语言工具栏找到对应的英文翻译,这是较易获得和可靠的可用资源。而词条内容中也包含很多互为译文的中英文翻译对。通过挖掘这些潜在的双语资源,可获得大量的包括专有名词、新词、流行词、俚语、术语的中英文翻译对,支持查询翻译任务。
2 相关工作
双语翻译对挖掘是跨语言检索中查询翻译的关键问题。根据所使用的资源不同,查询翻译的方法可具体分为:基于词典的查询翻译方法、基于语料库的查询翻译方法和基于搜索引擎的查询翻译方法。
基于词典的查询翻译方法,是最简单的CLIR技术。但是现有的双语词典均在充分性、可更新和适用多领域等方面存在局限。而人工添加词条,虽然具有较高的准确率,但构建大规模的双语词典需要耗费大量的人力物力,而且覆盖面依然受限。
基于语料库的查询翻译方法。Huang等人[4]和Resnik等人[5]利用平行语料库进行未登录词译文的挖掘。Tao等人[6]和Talvensaari等人[7]利用从网络挖掘的可比较语料库进行未登录词翻译。平行语料库通常质量较高,但可用的平行语料库很有限,且通常是具体领域的。可比较语料库不存在互为翻译关系,从中挖掘的未登录词译文质量较低。文献[3,5,8]均是首先从双语网站中抽取双语文档,然后使用句子对齐技术,从中挖掘双语资源。基于语料库的翻译方法存在的一个关键问题是如何自动构建大规模的、多领域的、及时更新的语料库[3]。
基于搜索引擎的查询翻译方法: 一种是利用搜索引擎返回的链接列表,下载全文网页,然后进行查询的译文抽取[9-10],这需要较大的带宽和更大的存储空间和更多的计算时间;另一种方法是仅利用搜索引擎返回的混合语言摘要信息进行查询翻译。限于复杂性考虑,大部分方法都是利用前N条返回数据,但对于N的值没有固定的标准,总之,N远小于搜索引擎的所有返回结果数。但是如果网络数据中,低频词鲜有中英文翻译对共现的情况,则很难通过搜索引擎找到其翻译。使用搜索引擎抽取这样的中英文翻译对时,中英文共现的网页出现在查询结果列表前面的可能性会比较小。
很多研究者均发现东亚(包括中国、日本、韩国)的文本中,经常在专有名词注释相关的英文翻译。Zhang[11]发现,如果英文出现在括号中,那么周围的中文很可能是其对应的翻译。她将出现在括号中的英文前面的中文分为两种情况:一种是前面的中文出现在书名号或者引号当中;另一种是前面的中文不出现在书名号或者引号中。郭稷[12]等先对候选翻译单元的中文部分进行分词、词性标注和命名实体识别,然后使用多种识别特征自动挖掘网站中存在的双语翻译对。但主要是处理的固定格式翻译对,即英文出现在括号中时,其前面的中文出现在书名号或者引号中的中英文翻译对。由于互联网中双语资源格式自由灵活,还有很多以其他形式存在的中英文翻译对。罗阳[13]面向单一中日双语网页,使用以频繁序列模板为特征的SVM分类方法。Jiang[14]利用网页DOM Tree的结构特点,采用词对齐的方法自动进行双语资源的挖掘,并且允许不规则的噪声片段。
部分研究者利用维基百科进行未登录词译文的研究[3]。采用频度变化信息和邻接信息实现候选单元抽取,并建立基于频度-距离模型、表层匹配模板和摘要得分模型的混合译文挖掘策略。但是很多低频词不能通过维基百科提供的伪相关反馈获得,或者不能获得中英文词共现的页面。
本文利用维基百科语言工具栏和中文页面的中英文翻译对模板特点,抽取语言工具栏中双语翻译对作为启发式知识,自适应挖掘条目内容中翻译对模板,进而在条目内容中挖掘中英文翻译对,对于候选翻译对,结合多种特征对其准确性进行评估。
3 维基百科中的中英翻译对考察
维基百科(Wikipedia)是一个自由、免费、内容开放的百科全书协作计划。大部分的中文词条都可以通过其语言栏中的多语言链接获得对应的外文翻译。维基百科在词条所涉及领域的内容覆盖方面,文献[14-16]使用美国国会图书馆3 000篇随机文章与维基百科的随机词条进行对比,大部分领域维基百科几乎都很好地进行了覆盖。文献[15]统计了维基百科词条数目在不同领域的具体分布,发现与传统知识库相比,其在专有名词、新词、流行词、俚语、术语和新近事件等方面具有较大覆盖优势,较好地解决了双语资源领域限制问题。
3.1 存在目标语言链接
当某中文词条在语言栏中存在唯一对应的英文链接时,可以直接提取链接词条的标题作为对应的翻译。若中文条目只有重定向页面,则暂时将重定向词条的英文翻译作为其翻译,但需要经过进一步验证,所以将其准确度设为0.9。总结存在目标语言链接分为两种情况:
1) 无歧义的目标语言链接;
2) 只存在重定向页面,而重定向后页面语言栏中存在英文链接。

图1 存在目标语言链接
例如,中文条目“数学”的语言栏中,存在英文链接,指向英文维基条目“Mathematics”,属于第一种情况,将“Mathematics”作为“数学”的对应英文翻译。中文词条“欧盟”,是个重定向页面,指向“欧洲联盟”这个词条,而“欧洲联盟”页面语言栏中,存在唯一英文链接,指向英文条目“European Union”,属于第二种情况,将“European Union”作为“欧盟”的英文翻译。
3.2 词条页面中存在中英翻译对
词条页面中有些中英文翻译对的格式自由灵活,很难通过固定的模板去匹配抽取,如图2所示。

图2 中文词条“加利福尼亚”中职位翻译对
由不同人编辑的页面,采用的注释风格往往不同,但对于单个页面来说,其上下文中注释风格具有局部效应。可以使用通用模板和个别模板相结合的方式在维基页面中挖掘中英文翻译对。
3.3 维基百科内容文件
维基百科提供了所有完整内容的电子文件,下载得到一个大的XML文件,其中包含了所有页面的详细内容。每个中文维基页面均对应该XML中的一个page节点,每个page节点包含了条目的标题、最新版本的贡献者、词条内容等信息。与网页中展示的不同,词条内容中使用了维基百科自己的标记格式。双中括号“[[”与“]]”之间的信息对应维基页面中的超链接,“en”表示后面的字符为英文。词条内容中包括了正文、信息框和语言栏等信息。双语资源的挖掘主要是在正文和语言栏中抽取中英文翻译对。
4 主要方法
将维基百科的中英文翻译对挖掘环境分为两种: (1)存在目标语言链接;(2)词条页面中存在中英翻译的情况。针对这两种情况,对维基百科中中英文翻译对的挖掘也分为语言栏抽取、词条页面挖掘两部分,下面分别介绍维基百科翻译对抽取过程。
4.1 语言栏翻译对抽取
对于语言栏中存在目标语言链接且没有歧义的中文词条,直接提取语言栏英文链接的题目作为其英文翻译,即语言栏一次挖掘。而重定向页面,获取重定向词条的英文翻译作为其英文翻译。首先从维基百科的XML文件中,解析出每个page节点,并将其存入数据库中;然后逐条读取page,抽取其语言栏中的英文链接。维基内容文件的page结构中,语言栏英文链接使用的是固定格式“[[en:英文词]]”,抽取方法是使用正则表达式进行匹配。抽取过程如算法1。
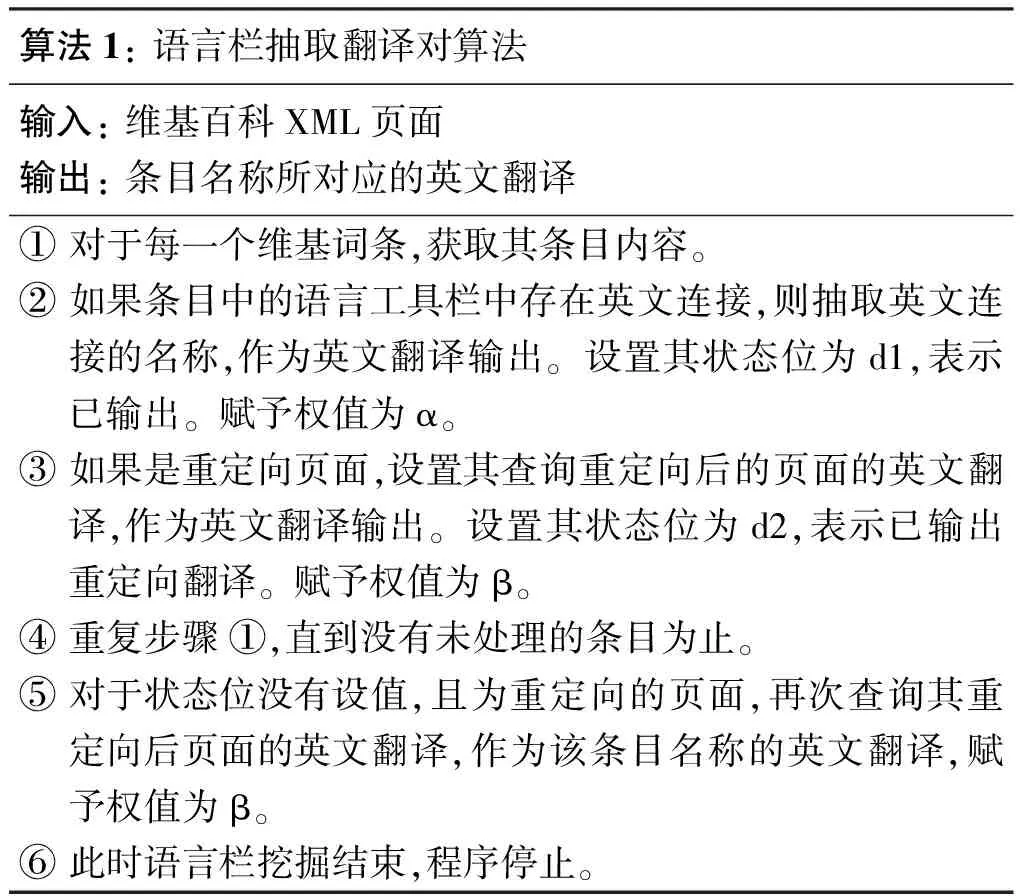
算法1:语言栏抽取翻译对算法输入:维基百科XML页面输出:条目名称所对应的英文翻译①对于每一个维基词条,获取其条目内容。②如果条目中的语言工具栏中存在英文连接,则抽取英文连接的名称,作为英文翻译输出。设置其状态位为d1,表示已输出。赋予权值为α。③如果是重定向页面,设置其查询重定向后的页面的英文翻译,作为英文翻译输出。设置其状态位为d2,表示已输出重定向翻译。赋予权值为β。④重复步骤①,直到没有未处理的条目为止。⑤对于状态位没有设值,且为重定向的页面,再次查询其重定向后页面的英文翻译,作为该条目名称的英文翻译,赋予权值为β。⑥此时语言栏挖掘结束,程序停止。
在抽取过程中参照文献[18]中的策略将以下三种情况的词对均移除: (1)中英文词对完全相同;(2)英文词条以数字开头,如“245”、“300BC”、“1991 in film”;或者英文词条匹配规则“List of .*”,例如,“List of birds”、“List of cinemas in Hong Kong”;(3)中文词条只包含ASCII码字符。
通过对维基百科2012年8月22日的XML进行初步处理,得到了524 592个中英文翻译对。翻译对的领域广泛性得益于维基百科的对领域的覆盖,包括了像“孙中山”、“高德纳”这样的人名,“亳州市”、“上海市”地名,还有“操作系统”、“自由软件运动”、“诺贝尔奖”等专业术语等,作为下一步挖掘的启发知识。
4.2 词条页面翻译对模式挖掘
维基百科中的双语资源具有一定的格式特征,通过匹配这些特征,可以挖掘出词条文本中大部分的中英文翻译对。本文提出了一种单词驱动模型,即以中文文本中出现的英文单词或词组为中心,以其所在的语句为候选挖掘单元,进行候选翻译对模板的识别和抽取,如图3所示。

图3 词条中的中英文翻译对的抽取过程
词条中的中英文翻译对的抽取过程,需要借助语言栏挖掘的结果。主要步骤有: ①候选模板记录抽取: 利用已有双语资源在文本中抽取中英文词对共现的语句片段;②模板挖掘: 从候选模板记录中利用Pat-Array挖掘模板;③中英文翻译对挖掘,利用挖掘的模板,抽取文本中存在的中英文翻译对;④模板启发式评估,采用启发策略优化模板抽取的结果。
4.2.1 翻译模板的挖掘
主要①候选模板记录抽取和②模板挖掘,这两步是内容页面翻译模板抽取的关键环节。内容页面中中英文翻译对的一般形式是:
前缀字符 中文词 模板中间字符 英文词 后缀字符
符号化为: PREFIX ZH_WORD PATTERN_M EN_WORD SUFFIX
其中,PREFIX表示中英文翻译对出现位置的前缀字符,ZH_WORD代表中文词,PATTER_M表示模板中间字符,中英文翻译对中间的符号,EN_WORD代表英文词(或词组),SUFFIX表示翻译对出现位置的后缀字符。当然中文词和英文词的位置也可能颠倒。为方便讨论,仅考虑前一种情况。
如果直接从文本中抽取前缀字符和后缀字符,将会发现前缀字符和后缀字符数量庞大,极端情况,整个翻译对前面和后面的文本都可以作为前缀和后缀字符。从文本中获取英文词的对应翻译往往需要分词才能进行抽取,而分词的准确性制约着模板挖掘的效果。如果把所有的中文词和英文词分别替换成ZH_WORD和EN_WORD,会发现中文词的左邻接熵和英文词的右邻接熵均较高。所以从模板中间字符(PATTERN_M)入手,利用从语言栏挖掘出的词对作为启发知识,进行模板抽取。
PAT-Array(又称Suffix Array)是一种数据结构[17],被广泛用在信息检索领域。设S=s0s1s2…sn-1为长度n的字符串;Li=sisi-1…s0,Ri=sisi+1…sn-1,分别称为字符串S中起始位置i的左右后缀字符串(Suffix String)。
在使用PAT-Array时只对目标字符抽取左右后缀字符串,分别对左右后缀字符串排序,然后抽取左右最长共有前缀(Longest Common Prefix,简称LCP)作为模板的左右边界。对词条中存在的中英文翻译对的模板抽取过程如算法2所示。

算法2:维基页面翻译模板挖掘算法输入:维基百科文本输出:中英翻译对抽取模板①利用语言栏抽取的中英文翻译对作为启发知识,读取维基百科词条文本,对遇到的每个中文英文词对,截取其左、右侧固定长度字符,并提取两者之间字符串(限制了最大长度)作为PATTERN_M。提取的字符串整体作为一条候选模板记录,保存留待进一步处理。②将第①步获得的候选模板记录按照PATTERN_M进行分组。对相同的PATTERN_M记录,分别抽取最长共有前缀与共有后缀,按照共有词缀进行排序。③将符合一定条件的共有后缀以及它们的模板中间字符PATTERN_M组合,组成PATTERN。④利用PATTERN,读取测试文本,抽取候选翻译单元。⑤对抽取的候选翻译单元的分散程度、边界长度进行度量。
抽取最长共有前缀可能得到多个最长共有前缀,需要进行进一步的筛选。如何过滤掉低频的边界字符串,并且保留适量个数的边界字符串来生成模板呢?也就是第⑤步的翻译模板的量化评价,分两步进行。
(1) 定义SUF_ENT为右边界字符串的分散程度的度量值,其计算公式为式(1)。

(1)
其中numi为第i个右边界字符串的频次。同理定义左边界字符串的分散程度PRE_ENT = info(num1,num2,numi…numn),使用信息论中的熵如式(2)所示。
(2)
左右边界字符串的分散程度越低,表明相应的边界字符串越固定,生成的中英文翻译对模板越准确;反之边界字符串越丰富,表明有多种翻译对的模板中间字符串PATTERN_M相同。
(2) 定义LCP_NUM为保留的右(左)边界字符串的个数,计算方法为式(3)。
(3)
对多个右(左)边界字符串,按照频次从高到低排序,只使用前LCP_NUM个生成翻译对模板,其他的暂视为噪声,可能是人为输入错误或者其他原因导致的。
维基百科中很多专有名称,虽然没有对应的词条,但是人为添加了超链接,不用分词即可比较准确地获取翻译单元。例如,词条“民族”中“印刷-资本主义”虽然没有对应的中文词条,但在XML文件中,标识了这可以创建词条,对其进行特征匹配,获取其英文翻译为“print-capitalism”,是由Benedict Anderson提出的一种国家理论。这避免了分词划分边界可能造成的无法找到正确的中文词问题。
4.2.2 翻译模板的启发式评估
对抽取获得的候选翻译单元,需要进行评估,才能进一步确定其正确性。评估采用的评价特征,包括:
(1) PATTERN本身的频度P_PATTERN。抽取中文维基百科前8 000个页面得到,候选模板记录14 361个,其中PATTER_M串“]](”的个数为2 603,分布在649个页面中。而PATTERN_M串“]] ”共有409个,分布在61个不同的页面中。因此PATTERN_M串“]](”的频度和分布广泛性要高于PATTERN_M串“]] ”。
(2) PATTERN中是否包含配对的符号。如果PATTERN中,包含配对的符号,例如前缀中有符号“(”,模板中间字符中包含“)”,则正确成词的概率更高。
(3) 中文词和英文单词的长度比例。如果抽取的中文词的长度过长或过短,其与英文互为翻译的可能性越小。如果过长,需要截断,如果过短,则需要向前扩展。语言栏抽取获得136 397个中英文翻译对,对这些中英文翻译对的中文词和英文词的长度进行统计,中文词的长度取汉字的个数,英文词的长度为单词的个数,得到中文词和英文词的平均长度比值为2.01,即一个英文单词平均对应2.01个汉字。
(4) 利用简易英汉词典进行对齐。英汉词典中仅包含常用英文单词或词组的中文翻译,对于组合词,拆分后查询英汉词典,可以对其正确性进行评估。对于中文词长度过长或过短的情况,需要进行截断或者向前扩展,以已有的中英词典为基础,对英文单词或词组进行直译,并利用标点符号,对候选挖掘单元进行分割。实验中使用的英汉简易词典,包含18 016个常见的英文单词或词组。另外,对于英文词中包含数字,而对应的中文词中不包含数字或者数字的英文,可以将这样的候选翻译对过滤掉。
5 实验结果及分析
5.1 实验数据 实验所使用的数据是中文维基百科截止2012年8月22日的所有页面,包括词条页面和重定向页面。下载的源文件zhwiki-20120822-pages-meta-current.xml.bz2,大小为934MB,解压后大小为4.99 GB,对其进行分割和解析,共获得890 579个页面节点。
5.2 实验结果
从语言栏翻译对挖掘、页面中翻译模板挖掘及其翻译对抽取方面进行三个实验。
5.2.1 语言栏翻译对挖掘实验
从语言栏中抽取得到524 592个中英文翻译对。语言栏一次挖掘和通过重定向得到的翻译对情况如表1所示。

表1 语言栏挖掘结果
可以看出,重定向获得的翻译对占了比较大的一部分。说明保留重定向页面的翻译是很有必要的,这能够降低跨语言信息检索时的未命中率。
将从维基百科语言栏中挖掘的中英文翻译对与LDC 2.0*美国语言数据联盟(The Linguistic Data Consortium简称LDC)由大学、公司及政府研究部门于1992年建立的非盈利组织。的数据重合度计算得到。

表2 语言栏挖掘数据与LDC 2.0比较
其中的LDC 2.0的数据,是综合了中英和英中两个词典后的数据。LDC词典是人工编制的,比较耗费人力。从维基百科语言栏中挖掘的中英文翻译对中,与LDC 2.0重合的部分只占很小一部分,其他绝大部分均是像LDC这样的词典所没有的,维基百科中的翻译对在跨领域方面表现出了较好的覆盖性能,而且维基百科本身是动态增长,挖掘其中的翻译对在查询翻译等方面的意义非常大。
5.2.2 页面中模板挖掘实验
取前10 000个页面作为页面挖掘的数据,使用其中80%,即8 000个页面进行模板抽取,剩余2 000个页面进行后期抽取翻译对的评估测试。
利用语言栏挖掘获得的中英文翻译对作为启发知识,对8 000个页面进行模板抽取。共得到14 361个候选模板记录。其中不相同的PATTERN_M个数为4 875。去掉只出现一次的低频序列和只适用于单个页面的序列,以及PATTERN_M中包含换行符的记录。这些模板中间字符序列并不具备一般适用性。最终得到200个候选PATTERN_M。
这200个候选PATTERN_M中,大部分均与人的直觉相符,并且发现了一些人工不易察觉的模板。对这200个候选PATTERN_M进行分组,分别抽取后缀字符和前缀字符的LCP,最终利用后缀字符和前缀字符的最长共有前缀和对应的模板中间字符PATTERN_M组合,得到用于抽取的PATTERN个数为241个。表3为部分模板。

表3 挖掘得到的部分中英文翻译对模板

续表
5.2.3 模板方法挖掘翻译对的性能评价实验
本文使用了241个通用模板,在2 000个页面中进行抽取。得到5 424个中英文翻译对。我们同时考察了针对具体页面的抽取过程,发现相同类型页面所使用的模板具有相似性,这为后期结果优化提供了很好的支撑。
随机选取其中200个页面进行人工验证。采用的评测标准是正确率、召回率和候选包含率。正确率评价指标计算公式为式(4)。

(4)
其中,n表示200个页面中抽取得到的正确的中英文翻译对个数。N表示200个页面抽取得到的
所有翻译对个数。召回率评价指标计算公式为式(5)。

(5)
其中,Nt为人工查看200个页面得到的中英文翻译对个数。候选包含率评价指标公式为式(6)。
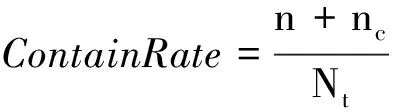
(6)
其中,nc为抽取的中英文翻译对中包含正确的中文词,但中文串长度过长的个数。实验结果表明,从200个页面中抽取出的428个中英文翻译对结果如表4所示。

表4 未评估的实验结果
计算得到Accuracy=76.63%,Recall=54.76%,ContainRate=63.44%。抽取的翻译对中,存在一些错误的中英文翻译对,主要原因是由于维基百科是由群体编纂的方式形成的,编写风格上难免有不统一的地方,由机器学习抽取出来的模板在一些情况下可能会失效,需要对这些模板进行评估(表5)。
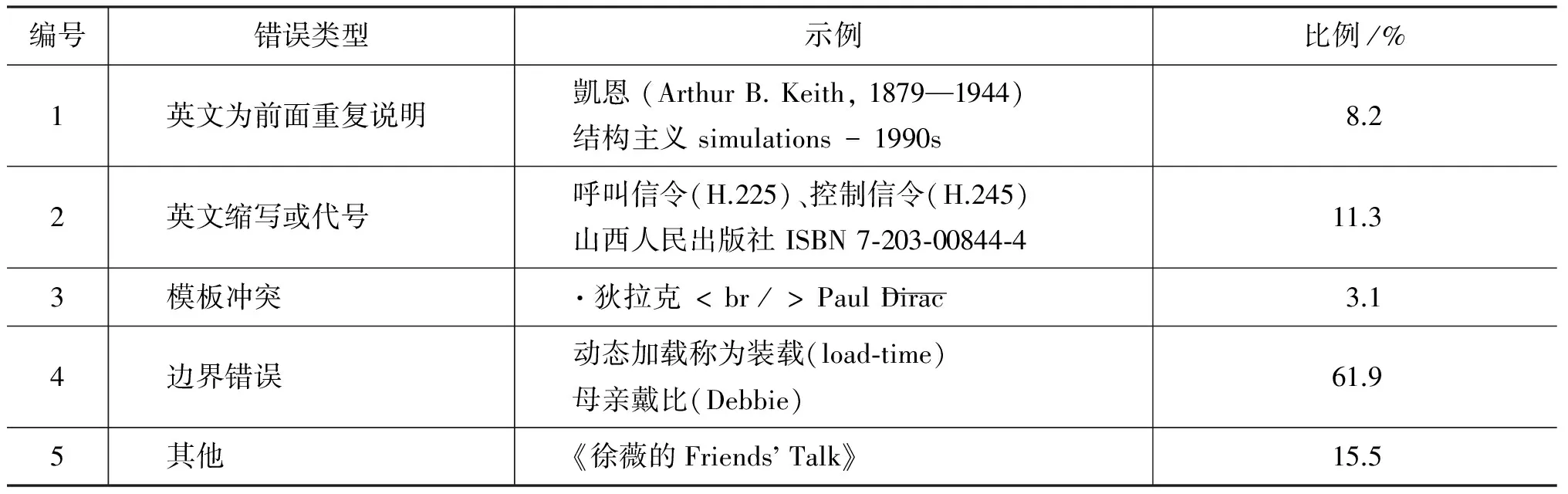
表5 错误的中英文翻译对示例
错误类型1、2、4,计算中文词和英文单词的长度比例,可以检测出异常。错误类型1、2,需要对翻译对中的特殊字符,包括数字,横线等是否对应;错误类型4,则一般需要向左进行截取获取扩展。这需要借助简易英汉词典进行对齐,寻找正确的边界;错误类型3,存在一个模板能够获取到正确的翻译对,可通过比较冲突模板的频率和是否包含配对的符号,过滤掉错误的翻译对。
在翻译对获取任务中,为了获取高质量的翻译对,将准确率的阈值提高,但是这也同时会降低召回率。实验加入中英文翻译对的评估后,准确率由原来的76.63%提高到90.4%。结果表明通过翻译对模板挖掘候选翻译对,进行评估能得到较高质量的中英文翻译对。
5.3 实验结果分析及改进
实验结果表明,利用模板抽取中英文翻译对的召回率偏低。对未召回的情况,分析发现很多特征明显的翻译对未能正确抽取,初步分析是由于模板的数量不足导致。前面对8 000个页面进行模板抽取,其中不相同的PATTERN_M个数为4 875,最终使用的候选PATTERN_M为200个,因此,设计如下两组对比实验查看模板的数量对实验结果的影响。利用所有的890 579个页面进行模板抽取,下表为前后两次模板抽取的数据对比,如表6所示。

表6 模板抽取数据对比实验结果
使用第二组实验的6 103个模板,在所有 890 579 个page中进行挖掘,共得到候选翻译对587 900个,进行中英文翻译对评估后,剩余352 454个中英文翻译对。
第一组实验选取的200个页面,采用相同的评测标准,统计得到: Accuracy=92%,Recall =67.8%, ContainRate =70.8%。
第二组实验的结果表明,增加模板数,使翻译对挖掘的召回率相比第一组实验,提升了13%,而且准确率也有所提高。分析剩余的仍没有被召回的翻译对,发现超过三分之一的翻译对,没有明显的符号边界,属于专业术语,还有部分是由于包含特殊字符不能通过模板获取到。但仍有很多不相邻的翻译对模板,很难通过模板挖掘出来。
6 总结
本文介绍运用模板方法从维基百科中获得高质量中英文翻译对。首先从语言工具栏中抽取词条的中英文翻译对,这些翻译对中绝大部分是人工编制的词典中所没有的;然后在词条文本中利用抽取的翻译对作为启发知识,结合模板方法挖掘存在的中英文翻译对。
未来的工作中有以下两个地方需要研究: 首先,在词条页面翻译对挖掘时,没有保留所有的左右边界字符串,这样牺牲了召回率。如何在提高召回率的情况下,保证较高的准确率以及翻译对模板数量增多时提高系统性能需要进一步探究;其次,中英文翻译对评估时,应该加入音译模型。
[1] JianYun Nie. Cross-Language Information Retrieval. Morgan & Claypool Publishers.2010.
[2] 孙常龙,洪宇,葛运东等.基于维基百科的未登录词译文挖掘[J]. 计算机研究与发展,2011,6: 1068-1076.
[3] Lei Shi, Cheng Niu, Ming Zhou, et al. A DOM Tree Alignment Model for Mining Parallel Data from the Web[C]//Proceedings of the ACL2006, 2006: 1-8.
[4] Huang F,Zhang Y, Vogel S. Mining key phrase translations from Web corpora[C]//Proceedings of the ACL2005,2005: 483-490.
[5] Resnik P,Smith N A. The Web as a parallel corpus [J]. Computational Linguistics, 2003, 29(3):349-380.
[6] Tao Tao, Zhai Chengxiang. Mining comparable bilingual text corpora for cross-language information integration[C]//Proceedings of the KDD2005, 2005: 691-696.
[7] Talvensaari T, Laurikkala J, Jarvenlink, et al. Creating and exploiting a comparable corpus in cross-language information retrieval[J]. ACM Trans on Information Systems, 2007, 25(1):1-21.
[8] J-Y Nie, M Simard, P Isabelle et al. Cross-Language Information Retrieval Based on Parallel Texts and Automatic Mining of parallel Text from the Web[C]//Proceedings of the SIGIR1999, 1999:74-81.
[9] M Nagata, T Saito, K Suzuki. Using the web as a bilingual dictionary[C]//Proceedings of the ACL 2001 Workshop Data-Driven Methods in Machine Translation. 2001: 95-102.
[10] W H Lu, L F Chien,H J Lee. Translation of web queries using anchor text mining [J]. ACM Trans. Asian Language Information Processing(TALIP).2002, 1(2):159-172.
[11] Y. Zhang and P. Vines. Detection and Translation of OOV Terms Prior to Query Time[C]//Proceedings of the SIGIR2004, 2004: 524-525.
[12] 郭稷,吕雅娟,刘群.一种高效的基于Web的双语翻译对获取方法[J].中文信息学报,2008,22(6):103-109.
[13] 罗阳,季铎,张桂平,等.面向单一双语网页的双语资源挖掘方法[J].中文信息学报,2011,25(1): 375-382.
[14] HALAVAIS A, LACKAFF D. An analysis of topical coverage of Wikipedia [J]. Journal of Computer-Mediated Communication, 2008, 13(2): 429-440.
[15] KITTUR A, CHI E H, SUH B W. What’s in Wikipedia? Mapping topics and conflict using socially annotated category structure [C]//Proceedings of the 27th International Conference on Human Factors in Computing Systems, 2009:1509-1512.
[16] 张海粟,马大明,邓智龙.基于维基百科的语义知识库及其构建方法研究[J].计算机应用研究,2011,28(8):2807-2811.
[17] MANBER U, MYERSG. Suffix arrays: a new method for on-line string searches[J]. SIAM Journal on Computing, 1993, 22(5):935-948.
[18] D Lin, S Zhao, B Durme et al. Mining Parenthetical Translations from the Web by Word Alignment[C]//Proceedings of the ACL-08. 2008: 994-1002.
Mining Translation Pairs with Learnt Patterns from Wikipedia
DUAN Jianyong1,YAN Qiwei2,ZHANG Mei1,HU Yi2
(1. College of Information Engineering, North China Univesity of Technology, Beijing 100144, China; 2. Searching Product Section, Tencent Corporation, Shanghai 200230,China)
Bilingual translation pairs play an import role in many NLP applications, such as cross language information retrieval and machine translation. The translation of proper names, out of vocabulary words, idioms and technical terminologies is one of the key factors that affect the performance of the systems. However, these translations can hardly be found in the traditional bilingual dictionary. This paper proposes a new method to automatically extract high quality translation pairs from Wikipedia based on the wide area coverage and data structure, the method not only can learn common patterns, but also learn many patterns that can hardly be found by human beings. The method contains three steps: 1) extract translation pairs from the language toolbox of the Wikipedia. They can be heuristic for the next step; 2) learn patterns of translation pairs with the knowledge of PAT-Array gained from the previous work; 3) extract other translation pairs automatically using the learned patterns. Our experimental results show the accuracy can reach 90.4%.
bilingual translation pairs; Wikipedia; pattern mining; information extraction

段建勇(1978—),博士,副教授,主要研究领域为中文信息处理。E⁃mail:duanjy@hotmail.com闫启伟(1989—),硕士研究生,主要研究领域为中文信息处理。E⁃mail:593202314@qq.com张梅(1980—),硕士,讲师,主要研究领域为中文信息处理。E⁃mail:javoncool@163.com
1003-0077(2015)02-0190-09
2013-07-12 定稿日期: 2013-10-22
国家自然科学基金(61103112);北京市哲学社会科学规划基金(13SHC031);北京市青年拔尖人才培育计划(CIT&TCD201404005);国家语委十二五规划基金(YB125-10)。
TP391
A
猜你喜欢
英语文摘(2021年8期)2021-11-02
疯狂英语·初中天地(2021年4期)2021-06-09
电脑知识与技术·经验技巧(2020年3期)2020-05-07
中国石油企业(2017年11期)2017-12-21
校园英语·下旬(2017年1期)2017-03-15
读者·原创版(2015年11期)2015-03-01
校园英语·中旬(2014年3期)2014-04-26
意林(2014年2期)2014-02-11
互联网天地(2012年12期)2012-11-18
