
微博检索的研究进展
2015-04-21 09:26:32卫冰洁
中文信息学报 2015年2期
卫冰洁,王 斌,张 帅,李 鹏
(1. 中国科学院 计算技术研究所,北京 100190;2. 中国科学院 信息工程研究所,北京 100093;3. 国家计算机网络应急技术处理协调中心,北京 100029)
微博检索的研究进展
卫冰洁1,3,王 斌2,张 帅1,李 鹏2
(1. 中国科学院 计算技术研究所,北京 100190;2. 中国科学院 信息工程研究所,北京 100093;3. 国家计算机网络应急技术处理协调中心,北京 100029)
随着微博的快速发展,微博检索已经成为近年来研究领域的热点之一。该文首先以TREC Microblog数据为基础,从分析微博文档和微博查询两方面出发,得出微博检索与传统文本检索之间的两点不同: 一是微博文档相较于网页具有很多独有的特征;二是微博查询属于时间敏感查询,即在排序时除了考虑文本的语义相似度,还需要考虑时间因素,将这类方法统称为时间感知的检索技术。这两点差异使得已有的信息检索技术不能满足微博搜索的需求。该文主要介绍了近年来这两方面的相关研究: 首先描述了微博本身的多种特征以及基于这些特征提出的检索方法;然后以传统信息检索过程为主线,分别介绍了将时间信息用于文本表示、文档先验、查询扩展三方面的排序模型,最后总结了已有工作并且对未来研究内容进行了展望。
微博检索;时间信息;微博特性;文本表示;文档先验;查询扩展
1 引言
随着Web 2.0近年来广泛应用,“人人参与、信息共享”逐渐成为了当今网络的主流,其中具有代表性的应用之一便是微博。微博(Microblog),即微型博客,Wiki*http://zh.wikipedia.org/上给出的定义是“微博是一种允许用户及时更新简短文本(通常少于140字)并可以公开发
布的微型博客形式”。截止今日,网络中已有多个微博平台,例如,Twitter、新浪微博、腾讯微博、 网易微博等。微博成为了近年来发展 最 快的热门互联网应用之一。
微博的广泛流行,带来的是快速增长的用户量和数据量。CNNIC发布的最新报告[1]指出,截止2012年底,我国微博用户达到3.09亿,同比增幅达到23.5%,有超过半数的网民在使用微博。同时,伴随着如此巨大的用户增长量,微博数据量也呈现出爆发式的增长趋势。据新浪微博统计,用户每日发博数量超过1亿条。与此同时Twitter的每日微博数量已超过4亿条。随着微博的快速发展,它已不仅仅是用户发表个人心情状态的一个社交场所,同时已经成为网民获取最新信息的重要渠道之一。面对如此海量的数据,用户获取个人所需信息的需求日益增强,微博检索的重要性不言而喻。
微博检索属于信息检索领域,更进一步说属于文本检索的范畴,是近年来检索领域的研究热点之一,相关论文在各大会议上频频出现。在已有的研究中,大部分工作是基于微博的某些特点提出新的检索模型得到效果的提高,没有对微博检索与信息检索的区别给予整理和总结。文献[2]通过对微博新型数据的分析,主要分析了实体搜索、情感分析、基于用户的元数据、时间因素等研究点,是一篇面向微博数据的相关检索研究问题的总结性文章。本文面向的是狭义的微博检索,即针对微博排序的研究,主要目的是通过对比微博检索与传统检索的不同而对已有的研究进行总结和整理,从而对微博排序的未来研究方向提出一定的建议。
经过多年研究之后,传统文本检索有相对成熟的理论基础,其检索的基本过程为: 由大规模文档数据构成被检索语料库,用户构造出可表达其信息需求的查询,经过检索模型对查询与文档的语义相似度进行打分,最终将结果按照降序返回给用户。文档数据和用户查询是检索模型的输入基础,选择合适的检索模型必须考虑用来检索的文档和用户输入查询的特点。然而,面向微博的检索从文档集和查询这两方面都表现出与传统文本检索的差异: 1)微博文档: 微博相对于传统文本具有很多自己的特性,包括不超过140个字的文字长度的限制、具有特殊意义的标签“#”和“@”、用户信息、链接信息等。这些特性带给微博不同于普通网页的特征,如何正确使用这些特征,使之有利于检索效果的提高,是微博检索面临的挑战之一。2)微博查询: Teevan Ramage等人[3]通过对比Twitter查询和Web查询,指出用户进行微博检索时的搜索意图大都与时间有关的,我们将这类查询称之为时间敏感查询(具体内容将在第3节中介绍)。针对时间敏感查询,在传统的检索技术中,仅仅考虑查询和文本的语义相似度是不够的,而需要在相关技术加入时间因素,统称为时间感知的检索技术。如何在微博的背景下,将时间和语义相似度完美结合,是微博检索面临的难点。
综上所述,微博检索从文档和查询上都具有自己的特点: 微博文档具有自己的特征、微博查询属于时间敏感查询。由于这两点区别,使得已有的检索技术不能很好适应微博检索的环境,对微博检索的研究提出了新的问题和难点。已有实验表明,在信息检索技术的基础上,考虑微博特性,融入时间因素均对微博的搜索性能有所提高。本文在以下章节中将从上述提到的两个不同点出发,分别介绍基于微博特性和面向时间敏感查询的已有研究工作,并进行整理和总结,同时列举多个未来有待深入研究的问题。
针对微博的研究,除了微博检索,还涉及多个方面: 1)微博网站是一个社交平台,微博用户是社交平台的基础组成。基于用户进行标签预测、关系挖掘、社区发现等是针对微博用户的研究方向之一[4-6]。2)由于微博的实时更新性,从微博文档中发现热点事件或者研究事件发展的相关论文也层出不穷[7-10]。总体来说,微博作为新型数据,对传统的文本技术提出了新的挑战,针对微博的研究还有很多有待解决的问题。
本文的组织结构如下: 第3节从微博文档和微博查询两方面对比微博检索和传统检索的区别;第4节分别介绍关于微博特性的检索技术相关研究和面向时间敏感查询的检索技术;第5节对本文进行了总结以及对未来的研究方向进行了简单的讨论。
2 微博检索与传统文本检索的对比分析
通过引言中对传统检索过程的描述可知,被检索文档和用户输入的查询是检索模型的基础,在选择合适的检索模型时,必须考虑文档和查询的特点。然而,面向微博的搜索从文档集和查询这两方面都表现出与传统文本检索的差异,下面将进行具体说明。
2.1 微博文档
微博,具有很多不同于网页的特点,例如,文本短(通常不超过140个字符)、含有特殊标签“#”和“@”、微博作者资料等。图1显示的是新浪微博“皓博睡吧”话题的两条微博截图以及微博用户“人民日报”的资料截图。以此为例,可以说明微博文档具有的特点。首先,观察“皓博睡吧”话题的两条微博。“#”和“@”符号在微博文本中,具有特殊含义。用两个“#”包含的文字代表该微博的主题,如“皓博睡吧”,是由发微博的作者给定的。“@”符号表示回复功能,一个用户可以在@符号之后写上另一个用户的微博名字,表示是回复给该用户的。同时,由于微博文字个数的限制,有些用户会添加网页的URL信息。其次,从微博用户“人民日报”的截图可以看出,微博作者包含关注者和粉丝。关注者是指你对这个用户的信息感兴趣,当你关注他之后,他的消息如果更新则会出现在你的微博页面中,粉丝则相反。在用户资料中也会有目前已发的微博数量以及个人的标签等信息。

图1 新浪微博“皓博睡吧”话题的相关微博和微博用户“人民日报”的资料截图
微博文档具有多种不同的特征,为了更好地理解微博特性,我们定义三个类别来划分微博的特征,分别为: 内容属性、用户属性、结果属性(或称为链接属性)。内容属性仅仅只是微博文本内容包含的特性,如hashtag、url以及短文本等;用户属性是指微博作者包含的特性,如作者的关注数和粉丝数等;结构属性,也可称为链接属性,是指以微博为统计单位用于表示微博之间的关系的特征,例如,微博hashtag信息等。利用这些特征提高检索的相关工作将在第3节介绍。
2.2 微博查询
文献[3]通过对Twitter查询和Web查询进行多方面分析,指出微博查询大都属于时间敏感查询(Topic-Sensitive Query)。通常在新闻、博客等文档集中进行的查询也具有相应特征。查询属于时间敏感查询的一个显式表现便是查询的相关文档集合在各个时刻的分布具有明显区别,文献[11]以来源于TREC的Web查询301、156和165为例进行了说明。在本文中,我们将对微博查询进行类似的分析,判断其是否具有相似的时间特性。
我们以2011的TREC Microblog Search任务发布的108个查询为分析对象*TREC一共发布了110个查询,其中查询MB050和MB076没有标注文档,因此忽略这两个查询。。文档集中共标注文档个数为113 829篇,其中标注为相关的文档共有9 150篇。当给定一个查询Q以及其标注相关微博集Dr,处理过程如下: 1)根据微博给定的唯一ID,划分其到指定的天数中。TREC发布的文档集是从2011年1月23日至2011年2月8日共17天的数据,因此每篇标注微博被指定了一个1-17的数字;2)统计每一天的相关微博个数,得到17个数字的统计分布;3)使用方差统计量*补充说明: 因为TREC发布的查询具有提交时间,也就是说该时间之后的微博集合不予考虑,因此在计算方差的时候,我们会以每个查询的提交时间作为截止时间,统计到此时间为止的时间段上的方差。表示该分布的变化差异性。也就是说如果一个分布的方差越接近0,则其越趋向于均匀分布,也就差异性越小;反之,如果一个分布的方差越大,则表明其在不同时刻的波动越大。需要说明的是,因为每个查询标注文档个数不同,为了避免其影响,我们对将绝对值分布转化为百分制,即每一个时刻的数值代表其在这部分所占有的比重。表1显示的是这108个微博查询的方差统计信息。
从表1可以看出,大部分微博查询的方差都处在20~500的范围内,少部分达到了超过1 000的数值。为了方便更直观地观察分布,我们在图2列出了其中四个查询的统计分布图。
观察图2,其中MB036的方差为2 500,是所有查询的最高值;MB078的方差为2.290 7,是最低值;除了这两个极端查询之外,MB020和MB099作为

表1 微博查询方差统计

图2 TREC 查询“MB036”,“MB078”,“MB020”,“MB099”的标注相关文档时间分布图
一般查询的代表,方差分别为 69.706 7 和 185.702 4。从图2可以看出MB036的所有相关文档都分布在了第二天,这也是其方差最大的原因;而MB078的分布更趋向于均匀分布。而查询MB020和MB099都具有很明显的波峰。综上所述,通过统计分析, 微博查询的标注相关文档在各个时刻的分布是不均匀的,大部分查询都具有明显的高峰时刻,这个观察结果也进一步证实了文献[3]的结论,即微博查询是时间敏感查询。
在从微博文档和微博查询两个角度分析微博检索与传统检索的区别后,我们可以了解到微博具有很多网页中不具备的特征,并且微博查询大都是时间敏感查询。因此,如何利用微博文档的独有特征,
如何考虑微博查询的时间敏感性,对微博检索技术研究提出了挑战。在下面的小节中,我们会从这两个方面分别整理已有工作,并对未来的研究问题进行总结和展望。
3 微博检索的相关研究
通过第2节的对比分析可以得知,微博检索和传统文本检索从文档和查询两方面具有不同: 微博文档具有多种特征;微博查询具有时间敏感性。针对这两方面,在如下小节中,我们将分别介绍基于微博特性的检索研究相关工作,以及对应于时间敏感查询的时间感知检索技术。
3.1 信息检索模型
信息检索定义为[12]“信息检索是从大规模非结构化数据(通常是文本)的集合(通常保存在计算机上)中找出满足用户信息需求的资料(通常是文档)的过程”。词袋模型(Bag of Words,BOW)是常用的文本表示方法。针对一个文本,该模型假设文本中的每个词都是独立的,词和词之间不存在依赖关系,文本中的词序、语法、句法等信息均被忽略。在本节中,我们将介绍基于BOW假设的两种代表性模型: 经典概率模型和一元统计语言模型。
3.1.1 经典概率模型
经典概率模型是基于概率论的理论基础提出的,其排序原则是针对一个给定查询,估计两个概率模型,分别为相关性模型和非相关性模型,然后基于优势率比率对文档打分,从而得到排序结果[12-13]。发展至今常用的基于Okapi BM25权重计算机制构建的检索模型的公式如下所示[14]。
(1)
其中t是词项;N是语料库中的文档个数;dft是该词项在语料库中的文档频率;tftd是该词项在文档D中的出现次数;同理,tftq是该词项在查询Q中的出现次数;Ld是文档长度;Lave是语料库的平均文档长度;k1,k2,k3,b为模型参数,已有实验表明,k1和k3的取值范围通常为1.2~2,b通常取值0.75。
3.1.2 一元统计语言检索模型
1998年,Ponte和Croft首次把统计语言建模技术(StatisticalLanguageModel,SLM)应用于信息检索领域,并获得了非常好的实验效果[15]。一元语言模型忽略了词和词之间的关系,其排序的基本思想是认为查询和文档都是语言单元的序列,因此可以对其构建语言模型。最早提出的基于语言模型的是查询似然模型(QueryLikelihoodModel)[15-17],即给定一个查询Q和一篇文档D,针对文档D构建描述该文档的语言模型,然后将文档D按照它与查询Q相关的似然分值p(D|Q)排序。根据贝叶斯理论,同时使用Jelinek-Mercer(简称JM)平滑方法[17],得到的最终排序函数如式(2)所示。
(2)

式(2)中的tft C是指词项t在语料库中的出现次数。
3.2 基于微博特性的微博检索研究
微博文档具有多种特征,下面所列举的论文涉及了有关于微博特性的检索研究工作,具体内容描述如下:
Nagmoti, Teredesai[18]针对微博搜索提出了几个微博特性,并进行了验证。论文中考虑的微博特性有: 微博作者发布的微博个数、微博作者的关注数和粉丝数、微博的长度、微博是否含有URL。其中,微博作者的关注数和粉丝数作为该用户的入度出度定义函数表示作者的权重。验证方法选择的是对特定查询在商业搜索引擎的top-k 结果进行重排序,判断重排序后的结果是否有提高。最终得到的结论是,后三者特性的结合得到的效果最好。
Ferguson, O’Hare[19]验证了传统检索模型中带来提升的词项频率(Term Frequency,TF)和文档长度归一化(Document Length Normalization,DLN)对于微博检索的影响,文中采取的排序模型为BM25模型(属于经典概率模型)。结果表明,忽略TF时,效果仅比最优结果的P30低了0.004 8,而忽略DLN时,效果达到最优。论文最后提出,TF和DLN都是在语言模型建模过程中会涉及的因子,所以在构建语言模型时应考虑如何减少二者的负影响。Massoudi, Tsagkias[20]在对微博构建语言模型的时候,便忽略TF的影响,即将词的出现记为1,不出现记为0,而不考虑词项出现的次数。
Efron[21]是基于统计语言模型,利用微博的hashtag以及hashtag之间的关系,提出了新的查询扩展方法,在数据集上证明hashtag有利于信息检索。论文将一个微博语料库中的hashtag提取出来,得到hashtag集合;通过含有该标签的微博构建标签的一元语言模型(记为Mtag)。设查询Q的语言模型为MQ,然后用KL公式计算Mtag和MQ的距离分值,选择出得分靠前的k个tag,用来反馈MQ。另外,论文中通过定义同时出现这两个标签的文本个数作为标签之间的关系权重,修改原有得分。
李锐和王斌[22]提出了一种基于作者建模的微博检索方法。论文首先在TRECMicroblogSearch任务的语料集中抽取作者信息,整理每个作者发布的所有微博记录构成新“文档”,然后基于语言模型理论构建用户的语言模型,提出了加入用户模型的平滑方式来估计新的微博文档词项概率。最后在该数据集上进行了检索实验。结果表明,合理使用作者信息可以提高微博检索的效果。
TREC(TextRetrievalConference),全称为文本检索会议,是文本检索领域最权威的评测会议,涉及多个方向,如传统Web检索、QA等。面对发展迅猛的微博,TREC于2011年添加了MicroblogSearch评测,提供了从2011年1月23日到2011年
2月8日共17天的Twitter数据以及50个查询(Topics)和标注的文档集。多个参与者将自己算法所得到的搜索结果提交到TREC负责组,然后TREC负责组按照评价指标进行排序,得到各个参与者的算法排名。在这里,由于篇幅所限,我们不对TREC2011MicroblogTrack前10名参与者*有一名参与者没有提交报告,所以共9篇报告。的相关报告进行详细介绍,而是直接进行总结(分别对应表2中的论文23~31)。
如2.1小节所指出,在本文中,我们将微博的特征划分到三个类别: 内容属性、用户属性、结构属性(或称为链接属性)。表2是对利用微博特征的检索研究工作的总结,其中标记“√”表示该篇论文所提的方法中涉及或者利用这种属性特征,这些特征的名称在表格下方有具体解释。

表2 利用微博特性的微博检索研究总结
①论文29与论文22是同一个作者的文章,29是以TREC报告的形式提交的英文文档。
(1) 内容属性
i) Term:
TF: 词频,即某个词在整个文档集中出现的次数
DF: 文档频率,即某个词出现的文档个数
Other: 广义的关于词的特征: 包括语义、词依赖、是否属于未定义词、句法信息、语义信息、N-Grams信息
ii) Length: 是否进行了文档长度归一化处理
iii) Hashtag: 是否包含Hashtag;Hashtag词内容
iv) Url: 是否包含Url;Url所指向的网页内容
v) Reply: 是否是另一篇微博的回复
vi) Mention(@): 微博内容是否@某个微博用户
(2) 用户属性
i) MCount: 用户发布的微博个数(Microblog Count)
ii) Fan&Follow: 用户的关注数和粉丝数
iii) TMT: 用户发布的微博全部内容(Total Microblog Text)
(3) 结构属性
B-Hashtag(Between Hashtag,即Hashtag之间的关系),使用共有Hashtag的微博个数来表示
总体来说,面向微博特性的检索研究中,基于内容属性的检索研究相对较多,利用用户信息和结构信息提高检索效果的研究较少。总结已有工作,有如下结论:
(1) 大部分论文都是基于已有检索模型进行修改,最常用的模型为BM25和统计语言模型;
(2) TF特征涉及次数较多是由于已有检索模型中含有TF,但是由于微博文本短,信息量不足,研究表明TF对于微博检索效果的提升并不明显;
(3) 微博中的Hashtag和Url特征对检索效果有提高,而文档长度归一化以及为Reply则有反作用;
(4) 引入Url所代表的网页信息用来提高微博文本,对检索性能有提高;
(5) 用户所发的其他微博信息被用于修改权重或者扩充文本都提高了检索性能。
3.3 面向时间敏感查询的检索相关研究
我们将针对时间敏感查询的检索方法统称为时间感知的信息检索技术,目的是在传统检索模型中融入时间因素从而得到更优的检索效果。在检索过程中考虑时间特性,并不是微博检索领域中特有的研究内容,它是近年来面向具有时间特性的文档集(如新闻、博客、微博等)的检索时的重要研究内容。接下来,我们将以基本的信息检索过程为思路介绍相关工作,图3显示的便是基本的信息检索过程。

图3 信息检索过程*图3中实线表明在检索过程中涉及的技术,虚线表明输入和输出。
如图3所示,用户将其需求信息表示为一个文本字符串(查询Q),它和语料库中的文档进一步分别得到查询和文档的文本表示,然后将其输入到定义好的排序函数中得到查询和文档的相似度分值,最终将所有文档按照得分从高到低返回给用户。不同的文本表示方法和排序函数定义代表不同的检索模型。
在检索过程中,查询扩展技术(Query Expansion)和引入文档先验信息(Document Prior)是期望获得更理想检索结果的两种常用的方法。查询扩展技术能解决用户查询和用户信息需求不一致的问题。通常用户查询是其需求的不完全不准确表述,查询扩展通过初步搜索结果调整或添加查询词获得更符合描述用户需求的查询。文档先验信息是指由于语料库本身具有的背景信息,不同的文档具有不同的重要性,文档的重要性会影响其在搜索结果中的排序位置。需要说明的是,这里的文档是泛化的概念,可以指代一篇微博、一个网页,也可以指一段视频、一张图片,在本文中,文档是指文本数据。PageRank算法是文档先验信息的代表方法,它通过网页之间的指入指出链接关系计算出每个网页的等级,作为网页的离线先验信息。
目前,基于时间感知的检索技术的相关研究非常多,以信息检索基本过程为主线(图3),我们将主要介绍针对以下三方面的相关研究: 文本表示、文档先验、查询扩展。
3.3.1 关于文本表示的研究
文本表示是排序模型的基础,查询和文档的形式化定义决定着排序函数的定义方式。在统计语言检索模型的背景下,文本表示便是对文本构建语言模型,即如何计算词项生成概率P(t|MD)。据我们所知,目前在p(t|MD)中加入时间因素的方法,主要有两种: 一种是通过引入时间因素对词项t定义时间权重[32-33],另一种是在对语言模型概率估计平滑的过程中引入时间[34]。
Kanhabua和Nrvåg[32]的研究中通过时间性语言模型(TemporalLanguageModel,TLM)来确定文档时间。虽然其并不是关于文本检索的研究,但是其中关于对词项t引入时间的思想可以用于文本检索。需要说明的是,此时的数据集会按照时间粒度分成多块,记为P,时间粒度可自由选取,例如,1个月、3个月等。作者在文中针对词项t定义了一个时间权重,称为时间熵(TemporalEntropy,TE),其计算公式如式(3)所示。
(3)


(4)

Efron和Golovchinsky[34]对文档语言模型的改进在于对平滑部分的改进,论文认为平滑权重的取值应该根据文档时间的不同而不同,文档越新,λ的取值应该越小,也就是说应该偏向考虑文档自身。据此假设,在平滑公式中,引入新的平滑参数λt,并给出两种计算公式,分别为:
(5)
(6)
其中n(D,t 卫冰洁和王斌[35]提出了一个融合聚类和时间的微博排序模型。作者在文中通过对比微博检索和传统信息检索得出,微博文档属于短文本,信息量的不够丰富不利于构造准确的语言模型;同时微博文本中含有主题概括词(#标签,称为Hashtag),有利于确定微博与查询的相关程度;微博查询大都是时间敏感查询,在计算查询与文档的语义相似度的同时应该考虑时间信息。这三个特点对于微博搜索都非常重要,因此,该文针对微博文档的特征和微博查询的时间性提出了融合多因素的检索方法。具体地,该工作使用聚类方法达到融合微博的Hashtag信息和对微博文本进行扩充的目的,并通过定义文档的时间先验在排序模型中引入时间因素。实验结果表明,与原始检索模型相比,该文提出的方法具有更优的微博检索性能。 3.3.2 关于文档先验的研究 文档先验是指语料库中的文档具有的不同重要性。考虑语料库背景定义不同的文档先验计算公式,再将计算结果用于检索模型以期得到更好的检索效果。目前考虑时间信息计算文档先验的研究工作可以分为两种: 一种定义文档先验和发表时间的变化关系,一种在其中加入时间特性定义链接关系来修改PageRank算法。 3.3.2.1 文档先验—PageRank算法 PageRank算法[36]属于链接分析的范畴,主要是对根据网页之间存在的超链接而形成的网络图进行分析,确定每个网页的重要程度。PageRank认为当网页A页面上存在指向网页B的链接时,就说明网页A认可网页B,由此,根据每个网页的指出链接和指入链接的数量和质量决定每个网页的等级。其基本思想为,设定一个用户从当前网页出发,在网络中进行如下随机游走过程: 在每一步中,用户会从当前网页的链出链接中随机挑选一个或者以一定概率直接跳转到别的网页,然后继续浏览。计算公式如式(7)所示。 (7) 其中,T代表一个网页;d是随机游走概率,取值范围为0到1;InLink(T)是指向网页T的网页集合;C(Ti)表示网页Ti的链出网页个数。 3.3.2.2 定义文档与发表时间关系的方法 Li和Croft[11]认为文档根据其发表时间不同,具有不同的先验概率。作者假设时间新的文档的重要度大于时间旧的文档,将文档重要度定义为指数分布,公式如式(8)所示。 其中TD代表文档的时间;TC代表文档集中的最新时间;γ是指数分布的参数,人工指定。论文以统计语言模型为基础,将上述文档先验P(D)代入到语言模型排序函数中。论文在TREC的新闻语料上做实验,结果表明,加入时间特性的排序结果优于没有时间的排序结果。 Efron和Golovchinsky[34]对文献[11]提出的方法进行了改进,论文指出在不同查询的条件下每篇文本的重要性是不同的,提出了根据查询伪相关反馈估计指数分布参数的方法,即将上面公式中的λ修改为查询相关的参数λq。设查询Q的伪相关反馈集合记为P={d1,d2,…,dk},用T={t1,t2,…,tk}表示集合P中文本的时间,根据最大似然估计思想,得到计算公式(9)。 (9) 卫冰洁和王斌[37]在微博环境下,以上面两篇论文为基础进行了微博先验研究。论文指出,已有方法。不论是否与查询有关,都基于假设“文本的时间越新越重要”。作者对微博查询的相关文档的时间分布进行了分析,发现大多数查询的分布图的最高点并不在最新时间,也就是说上述假设并不符合微博查询的特点。由此,论文定义相关文档时间分布的高点为查询热门时刻(HotTime),提出新假设“在给定查询的背景下,时间越靠近查询热门时刻,文本越重要”。基于该假设,当给定查询时,用该查询的伪相关反馈文档集合的时间分布来模拟真实相关分布,根据指数分布参数是否固定以及查询热门时刻个数是否自动化提出四个基于热门时刻的语言模型(HotTimeLanguageModel,HTLM)。最后,作者将查询无关模型看作是文档的背景时间信息(即文献[11]的方法),将查询有关模型看作是文档的独立时间信息(即文献[11]的方法和HTLM系列模型),引入平滑思想提出混合的时间模型(MixedTimedLM)。在TRECMicroblog数据集上的实验表明,HTLM系列模型提高了检索效果,同时混合模型的检索性能优于单一模型。 3.3.2.3 基于PageRank思想的方法 在信息检索中,PageRank(简称PR)通过分析网页和网页之间的链接关系表示文档的重要度。文献[38-41]是一系列通过修改原始PR算法加入时间因素的研究工作。 Yu,Li[38]提出传统的PageRank或者HITS算法在分析网页链接时忽略了时间维度的信息,因此基于此出发点提出TimedPageRank(简称TPR)算法,计算公式如式(10)所示。 (10) 其中wTi=b(max time(C)-time(Ti)),maxtime(C)是文档集C中的最新时间,time(Ti)是文档Ti的发表时间,b是经验常数。 Berberich,Vazirgiannis[40]改变加入时间的方式,提出了算法T-Rank。作者认为用户从当前页面跳转到该页面的链出网页上时,根据链出网页的不同,其跳转概率也不同;同时,用户随机选择一个页面的概率也因为当前页面不同而不同,由此文中定义了两种概率,也可称为权重: 一个是从页面T跳转到该页面的链出网页集中的某个页面Ti的传播概率,记为t(Ti,T); 一个是当前页面的随机跳转权重,记为s(T)。修改后的公式如式(11)所示。 TRank(T)= (1-d)*s(T)+ (11) 实验结果验证了上述方法的有效性。同理Amitay, Carmel[39],通过分析网页的last-modified 标签的特性,将其加入到PageRank当中,作为网页的之间边的权重。 Wan 和Bai[41]提出关于网页的一个新定义: 网页的time-activity程度,记为TR(T)。同时根据数据集,通过分析时间特性,得到了三个根据时间计算出来的常数。根据常数代表的数值范围,将网页分为四类: 1)强时间性;2)弱时间性普通质量;3)弱时间性高质量;4)无时间性。这里的质量即网页的PR值。最终的网页先验计算公式为式(12)所示。 (12) 3.3.3 关于查询扩展的研究 查询扩展是指在原查询基础上,加入与该查询相关联的新词,从而构成新的更准确的查询,它在一定程度上克服了查询信息不足以及词不匹配的缺陷,提高了信息检索的效果。随着网络的发展,信息更新速度加快,使得检索文档的新颖性在排序中越来越重要,因此出现了在扩展查询词的过程中考虑时间维度的查询扩展方法。下面介绍一些关于时间感知的查询扩展的相关工作,根据融入时间方式的不同主要分为两种: 一种是通过分析时间点上的文档分布特点,选择合适的时间点作为文档选择的基础,再进行查询词扩展;一种是利用词与词之间的关系构建图,通过迭代计算得到词对于给定查询的相关分值,从而选取得分高的词项进行扩展。 3.3.3.1 查询扩展 用户根据其信息需求构造的查询往往较短,导致查询词信息量不足,无法得到满意的搜索结果。查询扩展技术通过调整和添加与原始查询相关的词项以提高检索结果的精度。查询优化有多种方法,其中最常用的一种方法是伪相关反馈(PseudoRelevanceFeedback)技术。伪相关反馈是一种自动分析方法,它首先在已有语料库中进行正常的检索,然后得到一系列搜索出的文档,接下来假设排名在前的k篇文档是相关的,由此构成针对此查询的相关文档集合,再在这部分集合上进行分析计算得到新的更优的查询来表达用户的信息需求。查询扩展是提高信息检索效果的有效手段之一。 Rocchio相关反馈算法 Rocchio算法是Rocchio于1971年提出的[42],是最经典的查询扩展方法之一。Rocchio方法的主要思想是,给定一个查询,同时该查询的相关文档集合和不相关文档集合已知,那么在查询和文档被表示成为高维词项空间中的向量的情况下,我们的目标是找到最优化的查询向量,使得该向量与相关文档相似度最大同时与不相关文档相似度最小。根据上述描述,当相似度选择余弦相似度时,我们可得到修改查询的计算公式如式(13)所示[12]。 (13) 相关模型 相关模型(Relevance Model,RM)[43]是利用统计语言建模理论,采用伪相关反馈思想的查询扩展模型。相关模型是一个多项式分布方法,最终目的是估计出在给定查询的条件下词项的生成概率。设Q=q1…qk表示查询串,Dprf表示伪相关反馈文档集合。RM的计算公式如式(14)所示。 (14) 根据上述公式,我们得到所有词项在给定查询Q的条件概率,由此按照得分高低排序得到最有可能用于扩展的词项集合。然后通过线性方法,引入参数λ,结合原始查询和扩展查询,构造出新的查询,得到新的词项条件概率。 (15) 当查询模型采用相关模型,文档采用语言模型时,针对查询和文档的相似度计算变成了比较两个概率模型之间的差别[17]。最常用的做法是采用KL距离作为模型相似程度的标准,公式如式(16)所示。 (16) 3.3.3.2 利用时间点的方法 文献[44-45]提出的查询扩展方法是在伪相关反馈文档集上做统计处理,选取最终扩展词,实验均表明方法有利于信息检索。 Peetz,Meij[45]是按照文档时间T,统计在第一次搜索文档集中出现在每个时间t的文档个数,然后选择在出现个数最高的时间time附近的TopN篇文档,最后利用Rocchio算法计算每个词项的评分选择扩展词。论文在数据集上验证上述方法提高了检索效果。 Amodeo,Amati[44]将查询的第一次搜索文档集(R),根据每篇文档D的时间T,按照指定的规则,分为突发集B(可有一个或多个),突发集的集合记为bursts(R),然后根据式(17): (17) 计算每个词的打分。最终挑选出前TopN个作为查询扩展词。实验结果表明,该方法有效。 Keikha,Gerani[46]在博客检索的背景下,从相关模型的思想出发,定义了一个考虑时间的P(t|Q)生成式模型,计算得分,选取排序靠前的扩展词。论文认为P(t|Q)的生成过程为,查询Q首先选择了一个时间T,然后,再在T和Q的条件下选择一个t,由此得到的查询生成词的模型公式为式(18)。 (18) 在TREC数据集Blog08上的实验表明该方法提高了检索效果。 Miyanishi,Seki[47]通过对Twitter发布的微博查询进行分析, 指出微博查询具有两种时间表示特性: 分别为recency和temporalvariation。前者是指相关文档大多分布在查询被提交的时刻的现象;后者是指相关文档在不同时刻分布不同的现象。作 者认为这两者属性对于一个查询而言是缺一不可的,由此针对这两个属性分别提出一种查询扩展方法,最终通过总结这两个查询扩展方法得到最终的检索结果。实验表明,文中提出的方法有利于检索效果的提高。 3.3.3.3 基于图的方法 Whiting,Klampanos[48]是在微博检索的环境下,提出了一种基于PageRank理念,计算词权重的查询扩展方法。首先,从初次返回结果中抽取N-grams;然后,对N-grams构建有向图,N-grams作为点,把词项的TF为点的先验取值;边表示指向关系,权重为词和词之间的时间特性的相关程度;最后运用PageRank随机游走的思想,计算出每个N-gram的最终取值,选择部分用于扩展原始查询。实验是基于TREC的Twitter数据集,完成的结果验证了方法的有效性。 3.3.4 总结 表3列出的是时间感知的信息检索相关研究的总结。我们根据信息检索过程,主要介绍了利用时间在文档先验、查询扩展和文本表示三种技术中提高检索效果的已有工作。这些研究均表明运用时间的检索模型普遍对检索性能有提升,特别是针对具有时间特性的数据集上,例如,微博、新闻、博客等。与此同时,我们也发现基于时间感知的微博检索研究尚少,还存在很多有待深入研究的问题,是一个需要挖掘的研究方向。 表3 时间感知的信息检索研究总结 微博是当今互联网数据的重要组成部分,微博检索具有重要的研究和应用价值。首先,我们以TREC Microblog 数据为分析对象,从微博文档和微博查询两个方面出发,对比了微博检索与传统检索,提出当前的检索技术并不能直接用于微博背景下。原因有两个: 第一个是微博文档不同于传统网页,具有很多特点;第二个是微博查询属于时间敏感查询,需要在传统检索技术中引入这个重要因素。然后,本文对这两部分相关研究工作进行了整理和总结。首先介绍了针对微博特性的检索相关研究,研究表明将从微博提取出的特征用于信息检索模型,可以提高检索的效果。然后以信息检索基本过程为主线,分别介绍了时间信息融入文本表示、文档先验和查询扩展技术中的方法,并对相关工作进行了概括总结。研究表明,在对有时间特性的数据进行检索时,例如,微博、新闻、博客等,在检索模型中加入时间信息有利于优化检索性能,提高用户满意度。 通过对微博检索的国内外研究现状的调查,我们发现有待深入研究的微博检索问题还有很多,列举部分如下: 1. 微博各方面属性的研究程度尚浅,没有进行特征的分类整理和对比分析,也没有统一的检索框架可以融合多方面属性,这部分工作有待继续挖掘。 2. 在利用时间因素的各种检索方法中,均采用了文档的发表时间。但是针对微博文档,其还具有评论时间和转发时间,这些时间构成了微博的时间段,如何利用时间段改进已有技术是一个可研究的问题。 3. 微博文档短且口语化严重,如何在检索过程中扩充文本过滤掉噪音文档、保留更多相关文档是微博检索的一个难点。 4. 基于统计信息进行文本表示的前提是文本信息量足够,而微博由于字数限制导致信息严重缺失,因此如何扩充微博提高文本表示的信息量是一个长期的研究课题。 5. 微博之间存在多种链接关系,比如用户关注关系、微博转发关系、微博评论关系,如何利用这些关系计算微博的重要度以期优化检索结果有待进一步研究。 [1] 中国互联网络信息中心.第31次中国互联网络发展状况统计报告[R].2013. [2] Efron M. Information search and retrieval in microblogs[J]. Journal of the American Society for Information Science and Technology, 2011. 62(6):996-1008. [3] Teevan J., Ramage D.,Morris M. R. #TwitterSearch: a comparison of microblog search and web search[C]//Proceedings of the fourth ACM international conference on Web search and data mining.Hong Kong, China.2011: 35-44. [4] Girolami M.,Kab n A. On an equivalence between PLSI and LDA[C]//Proceedings of the 26th annual international ACM SIGIR conference on Research and development in informaion retrieval.Toronto, Canada.2003: 433-434. [5] 陈渊, 林磊, 孙承杰, 等. 一种面向微博用户的标签推荐方法[J].智能计算机与应用, 2011. 1(3):21-26. [6] Spiliopoulou M.Evolution in Social Networks: A Survey, Social Network Data Analytics[C]//Social Network Data Analytics. Springer US.2011:149-175. [7] Sakaki T., Okazaki M.,Matsuo Y. Earthquake shakes Twitter users: real-time event detection by social sensors[C]//Proceedings of the 19th international conference on World wide web.Raleigh. North Carolina, USA.2010: 851-860. [8] Petrovic S., Osborne M.,Lavrenko V., Streaming first story detection with application to Twitter[C]//Human Language Technologies: The 2010 Annual Conference of the North American Chapter of the Association for Computational Linguistics. PA USA.2010: 181-189. [9] Mathioudakis M.,Koudas N. TwitterMonitor: trend detection over the twitter stream[C]//Proceedings of the2010 International Conference on Management of Data. New York.2010: 1155-1158. [10] Cataldi M., Caro L. D.,Schifanella C. Emerging topic detection on Twitter based on temporal and social terms evaluation[C]//Proceedings of the Tenth International Workshop on Multimedia Data Mining.Washington, D.C.2010: 1-10. [11] Li X.,Croft W. B. Time-based language models[C]//Proceedings of the twelfth international conference on Information and knowledge management.LA, USA.2003: 469-475. [12] 王斌, 信息检索导论[M]. 人民邮电出版社, 2010. [13] Zhai C. Statistical Language Models for Information Retrieval[J].Synthesis Lectures on Human Language Technologies, 2008. 1(1):1-141. [14] Robertson S. E.,Walker S. Some simple effective approximations to the 2-Poisson model for probabilistic weighted retrieval[C]//Proceedings of the 17th annual international ACM SIGIR conference on Research and development in information retrieval.Dublin, Ireland.1994: 232-241. [15] Ponte J. M.,Croft W. B. A language modeling approach to information retrieval[C]//Proceedings of the 21st annual international ACM SIGIR conference on Research and development in information retrieval.Melbourne, Australia.1998: 275-281. [16] Song F.,Croft W. B. A general language model for information retrieval[C]//Proceedings of the eighth international conference on Information and knowledge management.Missouri, United States.1999: 316-321. [17] Zhai C.,Lafferty J. Model-based feedback in the language modeling approach to information retrieval[C]//Proceedings of the tenth international conference on Information and knowledge management.Georgia, USA.2001: 403-410. [18] Nagmoti R., Teredesai A.,Cock M. D.Ranking Approaches for Microblog Search[C]//Proceedings of the 2010 IEEE/WIC/ACM International Conference on Web Intelligence and Intelligent Agent Technology.Washington, DC.2010: 153-157. [19] Ferguson P., O'Hare N., Lanagan J., et al.An Investigation of Term Weighting Approaches for Microblog Retrieval[C]//Proceedings of the 34th European conference on Advances in Information Retrieval. Berlin Heidelberg. 2012: 552-555. [20] Massoudi K., Tsagkias M., Rijke M., et al.Incorporating Query Expansion and Quality Indicators in Searching Microblog Posts[C]//Proceedings of the 33rd European conference on information retrieval. Berlin Heidelberg. 2011:362-367. [21] Efron M. Hashtag retrieval in a microblogging environment[C]//Proceedings of the 33rd international ACM SIGIR conference on Research and development in information retrieval.Geneva, Switzerland.2010: 787-788. [22] 李锐,王斌. 一种基于作者建模的微博检索模型[J].中文信息学报, 2014.28(2):136-143. [23] Metzler D.,Cai C. USC/ISI at TREC 2011: Microblog Track[R]. Text Retrieval Conference (TREC).2011. [24] Amati G., Amodeo G., Bianchi M., et al. FUB, IASI-CNR, UNIVAQ at TREC 2011 Microblog track[R]. Text Retrieval Conference (TREC).2011. [25] Li Y., Zhang Z., Lv W., et al. PRIS at TREC2011 Micro-blog Track[R]. Text Retrieval Conference (TREC).2011. [26] Miyanishi T., Seki K.,Uehara K. TREC 2012 Microblog Track Experiments at Kobe University[R]. Text Retrieval Conference (TREC).2011. [27] Ferguson P., O'Hare N., Lanagan J., et al. CLARITY at the TREC 2011 Microblog Track[R]. Text Retrieval Conference (TREC).2011. [28] Roegiest A.,Cormack G. V. University of Waterloo at TREC 2011: Microblog Track[R]. Text Retrieval Conference (TREC).2011. [29] Li R., Wei B., Lu K., et al. Author Model and Negative Feedback Methods on TREC 2011 Microblog Track[R]. Text Retrieval Conference (TREC).2011. [30] Hong D., Wang Q., Zhang D., et al. Query Expansion and Message-passing Algorithms for TREC Microblog Track[R]. Text Retrieval Conference (TREC).2011. [31] Li Y., Dong X.,Guan Y. HIT_LTRC at TREC 2011 Microblog Track[R]. Text Retrieval Conference (TREC).2011. [32] Kanhabua N.,N rv g K., Using Temporal Language Models for Document Dating[C]//Machine Learning and Knowledge Discovery in Databases. Berlin Heidelberg. 2009:738-741. [33] Li X., Jin P., Zhao X., et al.NTLM: A Time-Enhanced Language Model Based Ranking Approach for Web Search Web Information Systems Engineering[C]//the 1st International Symposium on Web Intelligent Systems and Services.Berlin Heidelberg. 2010:156-170. [34] Efron M.,Golovchinsky G. Estimation methods for ranking recent information[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval.Beijing, China.2011: 495-504. [35] 卫冰洁,王斌. 一种融合聚类和时间信息的微博排序新方法[J].中文信息学报, 已录用. [36] Brin S.,Page L. The anatomy of a large-scale hypertextual Web search engine[J].Computer Networks and ISDN Systems, 1998. 30(1-7):107-117. [37] 卫冰洁,王斌. 面向微博搜索的时间感知的混合语言模型[C]//全国信息检索学术会议(CCIR).南昌,江西.2012. [38] Yu P. S., Li X.,Liu B. On the temporal dimension of search[C]//Proceedings of the 13th international World Wide Web conference.New York, USA.2004: 448-449. [39] Amitay E., Carmel D., Herscovici M., et al. Trend detection through temporal link analysis[J].Journal of the American Society for Information Science and Technology,2004. 55(14):1270-1281. [40] Berberich K., Vazirgiannis M.,Weikum G. Time-Aware Authority Ranking[J].Internet Mathematics, 2005. 2(3):301-332. [41] Wan J.,Bai S. An improvement of PageRank algorithm based on the time-activity-curve[C]//The 2009 IEEE International Conference on Granular Computing.2009: 549-552. [42] Salton G.The SMART Retrieval System: Experiments in Automatic Document Processing[M].Upper Saddle River. Prentice-Hall, Inc.1971. [43] Lavrenko V.,Croft W. B. Relevance based language models[C]//Proceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval.Louisiana, USA.2001: 120-127. [44] Amodeo G., Amati G.,Gambosi G. On relevance, time and query expansion[C]//Proceedings of the 20th ACM international conference on Information and knowledge management.Scotland, UK.2011: 1973-1976. [45] Peetz M.-H., Meij E., Rijke M. d., et al. Adaptive temporal query modeling[C]//Proceedings of the 34th European conference on Advances in Information Retrieval.Barcelona, Spain.2012: 455-458. [46] Keikha M., Gerani S.,Crestani F. Time-based relevance models[C]//Proceedings of the 34th international ACM SIGIR conference on Research and development in Information Retrieval.Beijing, China.2011: 1087-1088. [47] Miyanishi T., Seki K.,Uehara K., Combining Recency and Topic-Dependent Temporal Variation for Microblog Search[C]//Advances in Information Retrieval. Berlin Heidelberg. 2013:331-343. [48] Whiting S., Klampanos I. A.,Jose J. M. Temporal pseudo-relevance feedback in microblog retrieval[C]//Proceedings of the 34th European conference on Advances in Information Retrieval.Barcelona, Spain.2012: 522-526. A Survey of Microblog Search WEI Bingjie1,3, WANG Bin2, ZHANG Shuai1, LI Peng2 (1. Institute of Computing Technology, Chinese Academy of Sciences, Beijing 100190, China; 2. Institute of Information Engineering, Chinese Academy of Sciences, Beijing 100093, China; 3. National Computer Network Emergency Response Fechnical Team/Coordination Center of China, Bejing 100029, China) With the rapid development of microblog, microblog retrieval has become one of the hot research areas in recent years. Firstly, in this paper, we analyze microblog documents and queries based on the TREC Microblog dataset. We found that, in contrast to traditional text retrieval, microblog search significantly differs in two ways. One is that microblog has its own characteristics compared to webpage. And the other is that microblog queries are time-sensitive, which means time information should be used in addition to traditional text similarity. According to these two differences, traditional text retrieval methods cannot be directly used in microblog search. Then, the related work on the two aspects of microblog retrieval is summarized. We described some microblog features and retrieval methods based on these features. According to the process of information retrieval, search models which use temporal information as the document priori or for query expansion or for text representation are also introduced. At last, we provide the conclusion and discuss the future work. microblog search; temporal information; microblog feature; text representation; document priori; query expansion 卫冰洁(1987—),博士,中级工程师,主要研究领域为微博检索及数据挖掘。E⁃mail:weibingjie1986@163.com王斌(1972—),博士,研究员,主要研究领域为信息检索及自然语言处理。E⁃mail:wangbin@iie.ac.cn张帅(1987—),硕士,工程师,主要研究领域为微博分类及信息检索。E⁃mail:zhangshuai01@ict.ac.cn 1003-0077(2015)02-0010-14 2013-05-02 定稿日期: 2013-08-02 科技支撑计划(2012BAH46B02) TP391 A



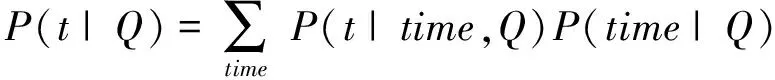

4 总结及未来工作展望

猜你喜欢
中国新闻周刊(2021年26期)2021-07-27 04:02:12
电子制作(2018年10期)2018-08-04 03:24:38
电子制作(2017年2期)2017-05-17 03:54:56
信息安全研究(2016年4期)2016-12-01 06:06:54
新闻传播(2016年18期)2016-07-19 10:12:06
现代计算机(2016年11期)2016-02-28 18:35:15
电子测试(2015年18期)2016-01-14 01:22:58
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
计算机与网络(2014年7期)2014-03-25 10:57:07
河南科技(2014年11期)2014-02-27 14:10:19
