
黄酒总酚含量检测:一种基于GA-LSSVM的近红外光谱波段选择方法
2015-03-29 05:59:54赵忠盖
红外技术 2015年7期
张 严,赵忠盖,刘 飞
黄酒总酚含量检测:一种基于GA-LSSVM的近红外光谱波段选择方法
张 严,赵忠盖,刘 飞
(江南大学轻工过程先进控制教育部重点实验室,自动化研究所,江苏 无锡 214122)
主要研究了近红外光谱技术对成品黄酒中总酚含量快速检测的可行性。针对近红外光谱样本少、非线性等特点,首次将最小二乘支持向量机(Least squares support vector machines, LSSVM)方法引入到传统遗传算法(genetic algorithms,GA)的波长选择中,提出一种基于GA-LSSVM的近红外光谱波段选择方法。该方法采用LSSVM建立小样本下不同波段的非线性模型,然后通过GA算法进行波长的优化选择。应用中,基于GA-LSSVM模型的总酚预测集相关系数(R)为0.9734,预测均方根误差(RMSEP)为5.5596,相比于传统方法,GA-LSSVM算法能够较好地提取非线性信息,预测效果更好。
近红外光谱;黄酒总酚;GA-LSSVM
0 引言
近年来,多酚类物质的研究受到高度关注,这类物质来源广泛,有较强的抗氧化能力,能清除人体内源性的活性自由基,具有减少癌症发病率,预防心血管疾病以及抗机体衰老等功效[1]。另外,酚类物质还可以通过抑制氧化酶、络合金属离子、过氧化自由基结合成稳定的化合物等方面起到重要的作用。因此,对黄酒中总酚含量快速测定十分必要,传统的测量方法需要配置溶液等繁琐耗时的操作,近红外光谱利用相关基团(例如C-H,O-H,N-H)的吸收,具有快速,无损,绿色等优点,广泛应用于农业、石油、医药、食品和环境等[2-5]诸多领域,能够对黄酒中总酚含量进行快速测定。
传统观点认为基于全光谱数据建立的模型具有更高的预测精度和鲁棒性,然而,大量的研究表明[6]适当的波长选择能够取得更好的预测效果,经适当的波长选择后,去除了光谱中大部分无效的信息,减少了建模数量,因此在一定程度上能够提高预测精度和简化模型复杂度。目前常用的波长选择算法有间隔偏最小二乘法(interval partial least squares,iPLS)[7],联合区间偏最小二乘法(synergy interval partial least squares,siPLS)[8],GA[9]等,这些波长选择方法有一个共同的缺点,即它们均建立在线性模型的基础上选择有效波长,忽略了光谱中存在的非线性因素对有效波长选择的影响,然而黄酒中总酚含量很低,能够有效吸收的基团较少,在含量很低的情况下,噪声对近红外光谱的吸光度影响较大,且在实际测量中存在温度变化,传感器灵敏度的变化,以及光源老化等[10]因素的影响,不可避免地引入噪声,利用线性模型选择有效波长无法获得较好的效果,因此,引入非线性模型选择有效波长十分必要。
支持向量机(support vector machine ,SVM)是一种基于统计学习理论的学习方法,已被广泛应用于故障诊断,图像分类,光谱分析等[11-12]多种领域。LSSVM[13]是对Vapnik提出的经典支持向量机(SVM)的一种改进,极大地降低了求解复杂度,同时加快了计算速度。本文结合GA具有的细划分策略与LSSVM具有的处理非线性问题具有的优点,将GA与LSSVM方法相融合,提出一种新的非线性波长选择算法,建立黄酒中总酚成分的近红外光谱分析模型,降低非线性因素对模型精度的影响。
1 原理和算法
1.1 GA-LSSVM优选谱区原理
遗传算法是一种用于解决最佳化的搜索算法,它包括遗传、突变、自然选择以及杂交等。该算法对结构对象操作,全局寻优能力强,采用概率寻优化方法,能自动获取优化空间,自动调整搜索方向[14]。
该算法用于近红外光谱波长选择是将需要进行光谱波段优选的原谱区分割成若干个子区间,然后采用遗传算法优选能够获取最大适应度值的子区间组合即为优选的光谱谱区。GA-LSSVM波段选择流程如图1所示,其主要步骤为:
1)编码:将光谱数据分成个等距离的子区间,每个子区间作为染色体的一个基因,对基因进行0-1二进制编码,若编码是1表示选中此波段;若为0则相反。一种0-1编码组合称为一条染色体,其长度为被编码的波段数。
2)选择初始群体:选择的目的是为了从当前群体中选出优良的个体,选择的原则是适应性强的个体为下一代贡献一个或多个后代的概率大。如果初始群体包含个个体,则随机产生个位的0-1二进制数作为初始群体。
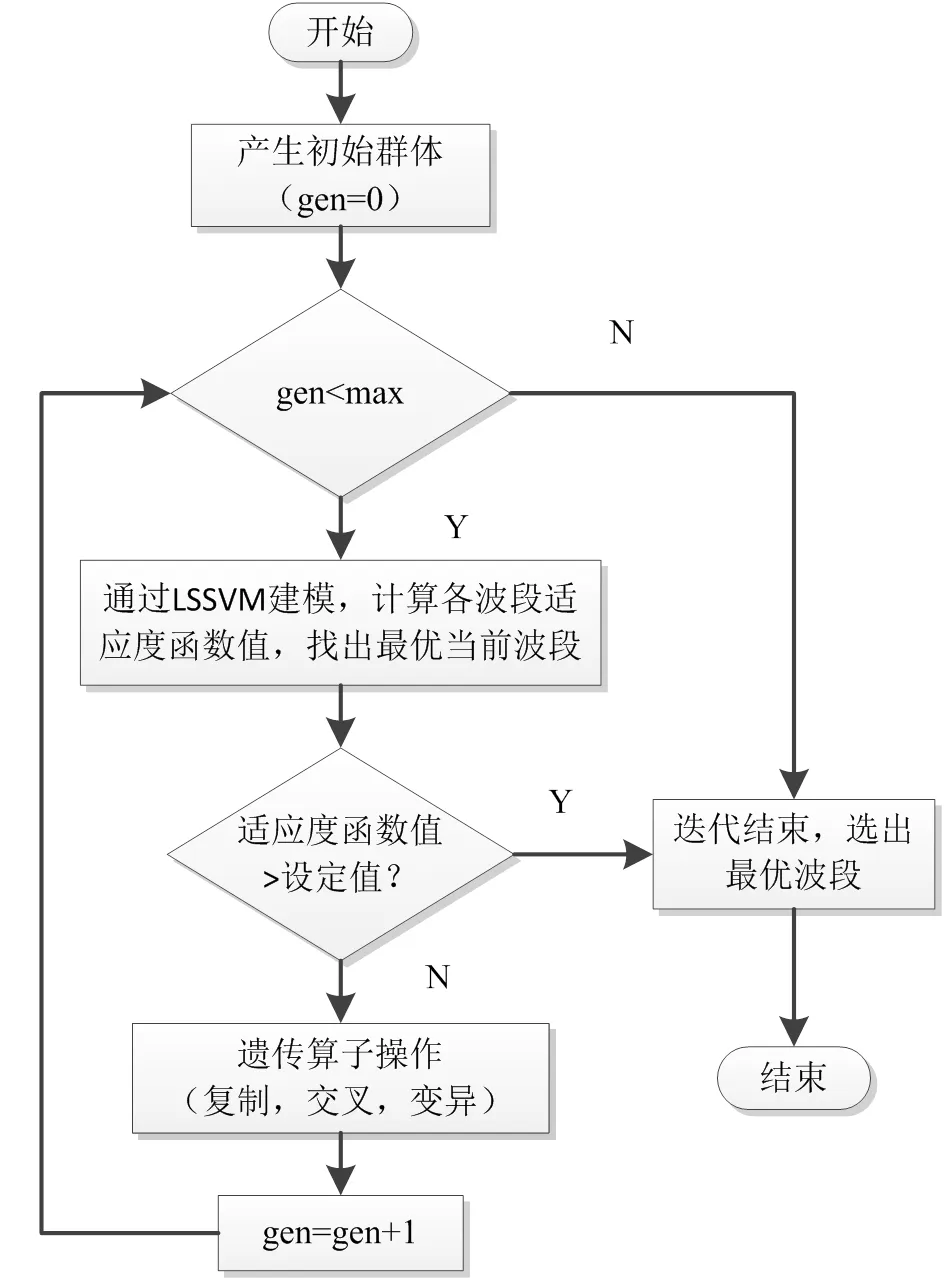
图1 GA-LSSVM波段选择流程
(gen代表迭代次数,max代表最大迭代次数)
3)适应度函数:采用完全交叉验证法评价模型的预测性能。在每一个子区间中利用LSSVM建立模型,计算每一段的交叉验证根均方误差RMSECV。RMSECV值越小,则模型具有较高的稳定性和较好的预测性能。为了使遗传算法对适应值较高的个体有更多的生存机会,设定适应度函数为:
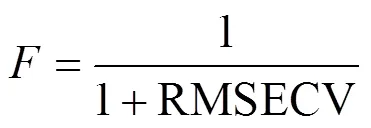
4)复制:复制采用“轮盘赌”的方式进行正比选择。
5)交叉:将配对的两个编码串的部分位进行交换,从而得到下一代编码串。本文采用的是普通单点交叉方式。
6)变异:变异是以一定的概率产生变异的基因数,用随机方法选出发生变异的基因。如果所选的基因的编码为1,则变为0;反之编码为0,则变为1。
重复4)、5)、6)直到最大繁殖代数时停止。
1.2 LSSVM算法
针对传统算法忽略非线性因素的缺点,考虑将最小二乘支持向量机用于非线性建模。假设所采集到的光谱数据为={(1,1), …, (x,y)},其中x∈R为输入向量,y∈为输出变量,是输入维数,=1, 2, …,。
首先,由一非线性映射(×)将原空间R映射到高维特征空间(x),然后在高维特征空间构造最优决策函数()=w×()+,并以结构风险最小化原则优化模型参数,。
LSSVM算法的目标优化函数为:
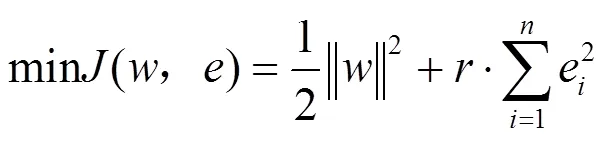
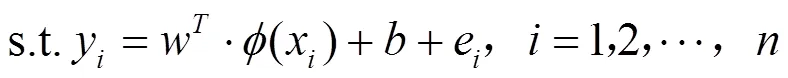
式中:为权重向量;为偏差量;e为误差变量;为正规化参数。
将以上优化问题转化为拉格朗日乘法求解:

式中:a为拉格朗日乘子。上述优化问题可以转化为求解线性方程:
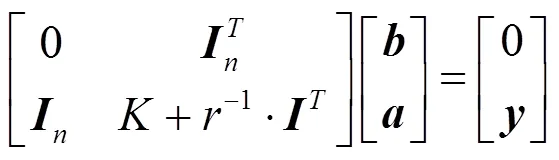
式中:=[1, …, 1],为单位矩阵;=<(x),(x)>=(x,x)为核函数,,=1, …,;=[1,2, …,a];=[1,2, …,y]。
令=+-1×,解矩阵方程可求得:
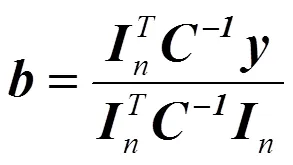
最终得到LSSVM的预测值为:
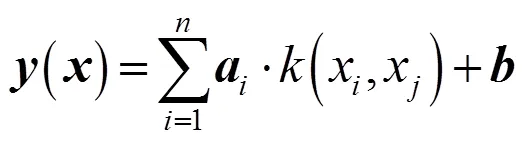
核函数有多种选择,其中包括线性内核、多项式内核、多层感知内核、径向基内核等,本文选用径向基函数为LSSVM的核函数建立模型,其计算公式如下:
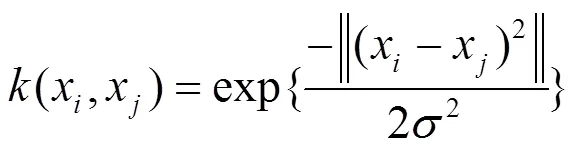
式中:2为径向基核函数参数。当采用LSSVM建模时,需要调节2和正规化参数,本文中采用交叉验证均方根误差(RMSECV)为评价指标,通过网格搜索法,对2和进行优化调整。RMSECV计算公式如下:
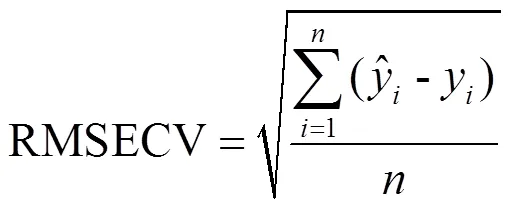
2 实验方法
2.1 样品与仪器
实验选用的黄酒样品购自无锡本地超市,包括沙洲优黄、古越龙山、和酒、石库门、塔牌、会稽山六种类型,共96个样本。
实验所用仪器为Thermo Antaris MX傅里叶-近红外快速分析仪,仪器的光谱范围是10000~4000cm-1,最小光谱扫描分辨率为2cm-1;光源是11.9 W/7V卤钨灯;SabIR光纤探测器;设定的仪器参数光谱范围是10000~4000cm-1,分辨率为8cm-1,工作电压6V,扫描次数16次。
2.2 光谱采集与黄酒总酚值测定
实验时,取30mL的黄酒样品依次放入编好号的50mL烧杯中,每次采集前用清水将光纤探头洗净,将光纤探头紧贴烧杯底部并测量2次,取其平均值作为真实光谱,减少人为抖动的影响,测量时,保持温度在20℃左右。
化学值测定:参考Slinkard等人的方法[15],使用福林-酚制剂,没食子酸作为标样进行测定。将1mL酒样用46mL蒸馏水稀释后,加入1mL的福林-酚制剂,充分加入3mL 2%的碳酸钠溶液,室温下放置2h,期间每隔一段时间震动一次,将混合液摇匀,以使反应完全,然后于760nm处测得吸光度值。实验重复3次,总酚含量根据下列公式进行计算:
吸光度值=0.0009×总酚含量+0.0183 (9)
校正集和预测集的划分采用Kennard-Stone(K-S)方法,该方法根据变量间的欧式距离,能够均匀的在特征空间选取样本。最终选取65个样本作为校正集,31个样本作为预测集。表1为总酚含量的分布情况。

表1 黄酒总酚分布情况
3 实验结果分析
3.1 光谱预处理
本文尝试对原始光谱分别使用平滑、多元散射校正(MSC)、标准正态变量变换(SNV)、一阶导、二阶导预处理,通过RMSECV对比可知,原始光谱经过SNV能取得更好的效果。原因如下:平滑能够对高斯白噪声有良好的消除效果,但在采用移动平均平滑法过程中,不可避免地损失一些光谱吸收峰信息,造成光谱失真,导数能够有效地消除基线漂移和其它背景的干扰,分辨重叠峰,但同时会引入噪声,降低信噪比,影响建模效果,MSC能够减小黄酒中物块和颗粒等大小不一引起的光散射的影响,然而黄酒中无较大的物块且颗粒大小差异不大,故影响较小。SNV能够黄酒内部固体悬浮物质颗粒散射表面散射和光程等的影响,黄酒中悬浮颗粒较多,一定程度上影响了光谱的吸收,故本文采用原始光谱经SNV预处理后对黄酒进一步分析,如图2所示。
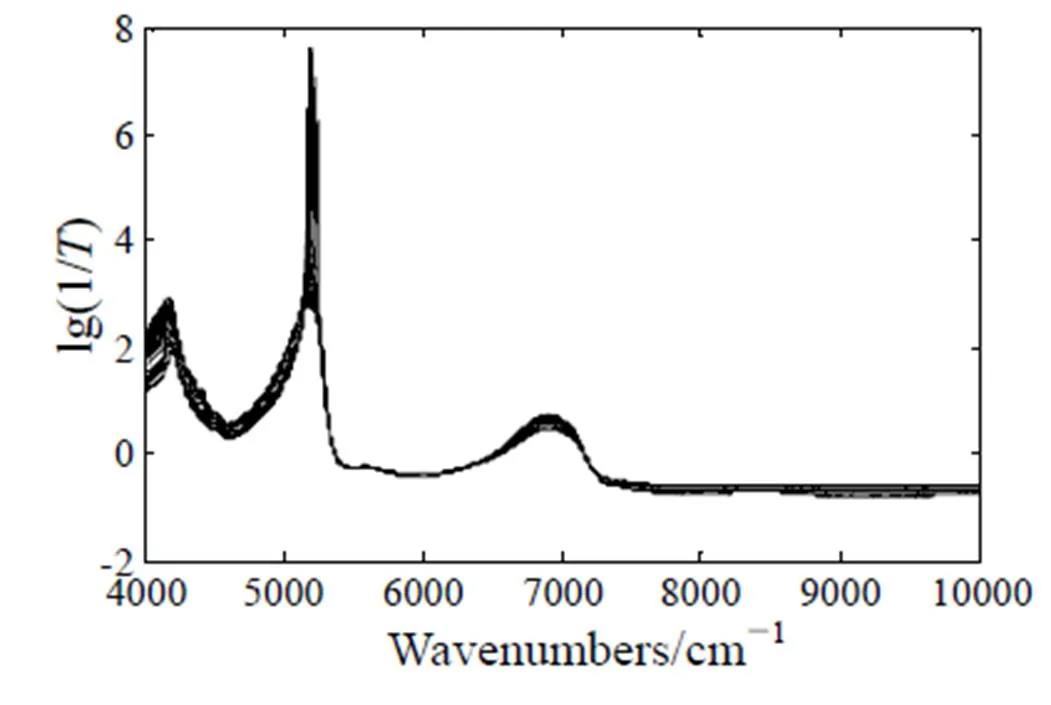
图2 SNV预处理后的光谱
3.2 GA-LSSVM算法优选波段
由于有些光谱波段的吸光度和总酚成分并不相关,且黄酒中存在大量的水分以及固体颗粒,将产生信息噪声,因此需要对光谱波段进行提取,消除无效光谱对建模精度的影响。遗传算法参数设置如下:初始群体大小为30,交叉概率为0.5,变异概率为0.01。以1/1+RMSECV构造适应度函数。
图3为经过GA-LSSVM运算后的波段选择结果。经过该算法优化后的最佳个体染色体为001100001111101101010001101110。染色体中“1”的个数为16,表示30个区间中保留了16个子区间,总波长点数为829,再把相邻(连续为“1”)的子区间合并后,所保留的谱区为7段,即为4400.8~4798.0cm-1,5604.1~6603.1cm-1,6807.5~7204.8cm-1,7409.2~7605.9cm-1,7810.3~8007.0cm-1,8612.5~9009.8cm-1,9214.2~9804.3cm-1。
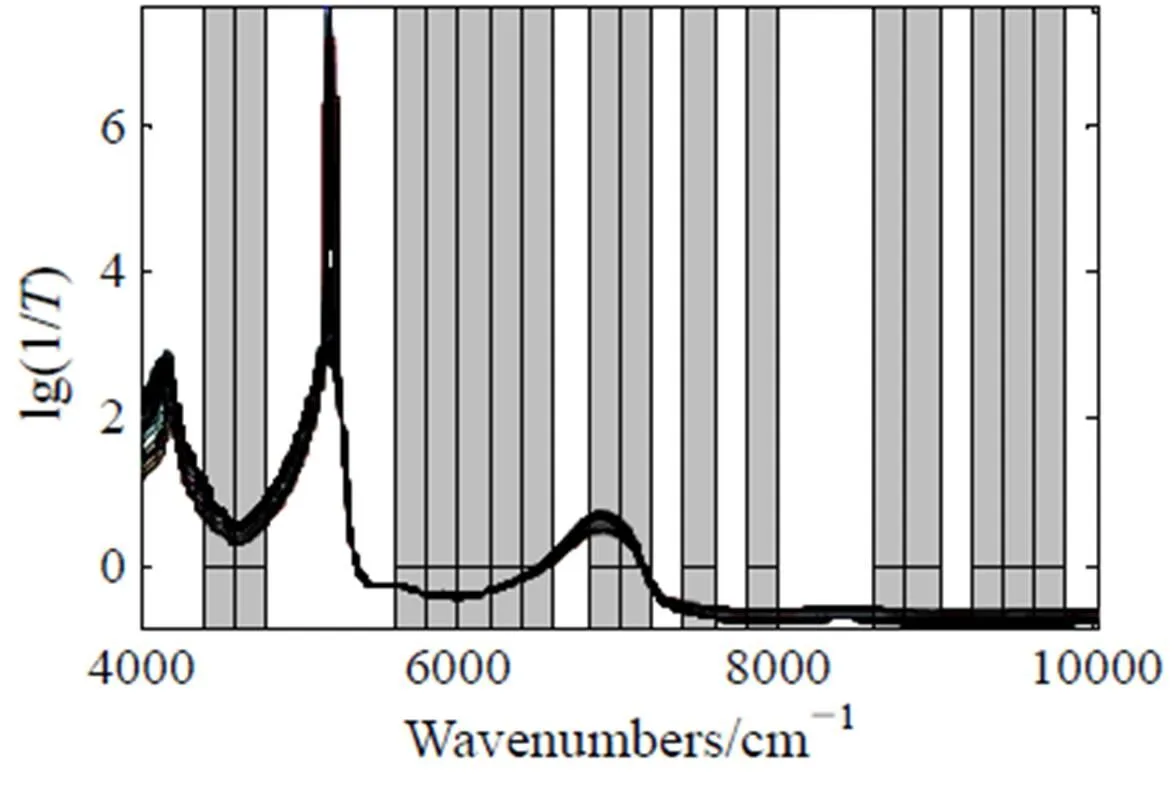
图3 GA-LSSVM波段选择
3.3 模型建立与评价
文中将校正均方根误差(RMSEC),预测均方根误差(RMSEP)和校正集相关系数(c),预测集相关系数(p)作为模型评价指标。评价校正集均方根误差、预测均方根误差及相关系数的计算公式如下:
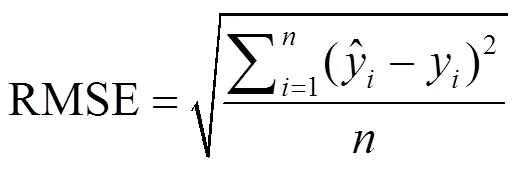
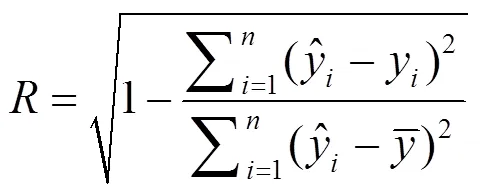
为说明本文方法的优越性,将GA-LSSVM方法与其它方法做对比,如表2所示。表2中,Full表示全光谱,GA和GA-LSSVM分别为子区间利用PLS和LSSVM所建模型选出的2种波长选择方法,PLS和LSSVM表示所用的分析模型。由表2可以得出如下结论:从p上看,GA-LSSVM所建立的模型比全光谱和siPLS选出的波长所建立的PLS和LSSVM模型都有一定程度的提高,从RMSEP上看,GA-LSSVM所建立的模型比全光谱使用PLS和LSSVM建立的模型分别提高了30.40%和18.43%,比iPLS和siPLS使用PLS建立的模型分别提高了14.70%,8.82%。特别地,与GA用PLS建立的模型相比,p上提高了3.19%,RMSEP上提高了9.58%。以上结果表明,对于存在非线性因素干扰的情况,线性波长选择方法不能够提取出最优的波长,而非线性波长选择方法能够有效的筛选非线性因素下的波长区间,从而提高模型的鲁棒性。
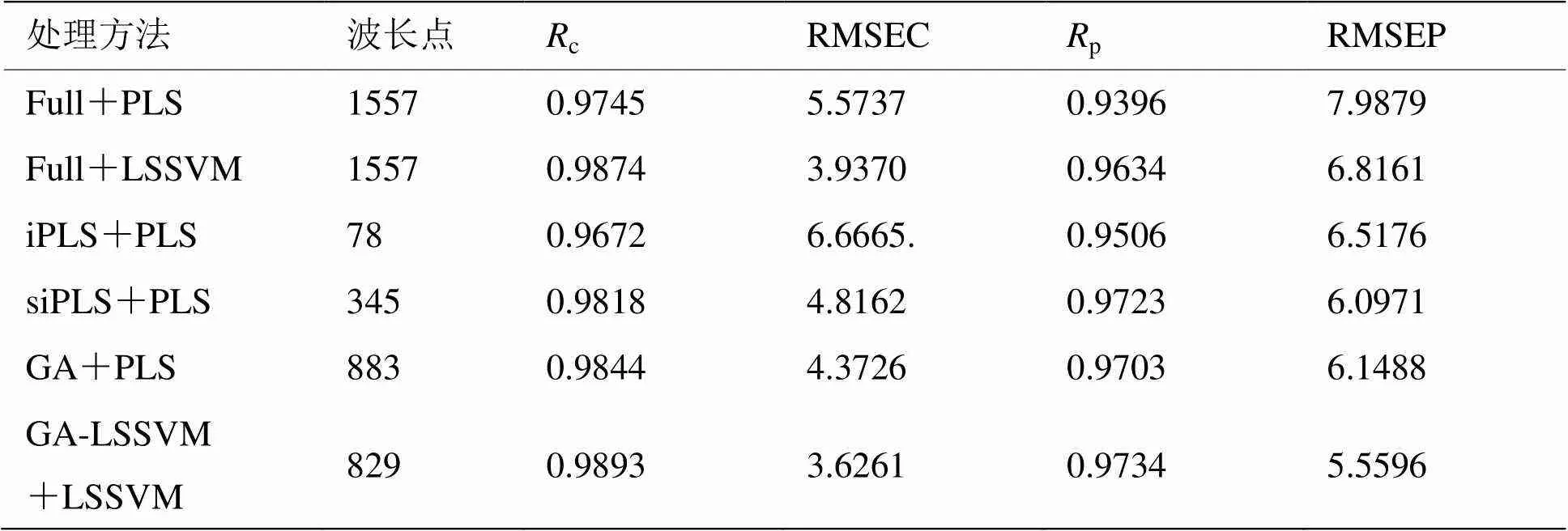
表2 GA-LSSVM方法与传统方法的对比
图4中为经过GA-LSSVM方法选择出829变量后经过LSSVM建模取得的效果图,总酚含量的校正集和预测集相关系数分别为0.9893、0.9734。校正集均方根误差和预测集均分根误差分别为3.6261、5.5596。两个模型的拟合度和预测精度均取得了较好的效果。预测精度可以满足近红外在实际黄酒参数检测中的要求。
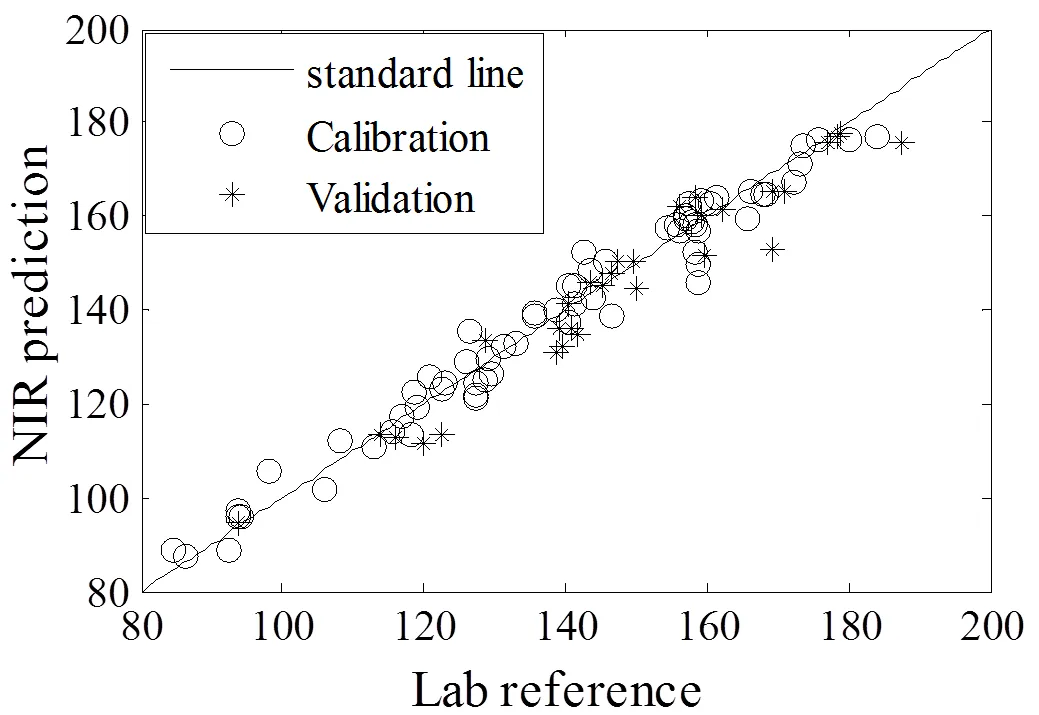
图4 总酚含量参考值与预测值对比图
4 结论
提出了一种新的基于GA和LSSVM相结合的波长筛选算法,克服了传统的波长选择方法忽略非线性因素的缺陷,将新的算法与近红外光谱结合应用到黄酒中总酚含量的检测,同时与传统的iPLS,siPLS,GA进行比较。结果表明,新算法可以在减少变量规模的同时,能够有效地提高预测精度,在近红外光谱检测黄酒总酚含量具有重要的实用价值。
[1] 袁珂. 从绿茶中提取茶多酚的工艺方法[J]. 林产化学与工业, 1997, 17(1):56-60.
[2] 黄常毅, 范海滨, 刘飞, 等. 近红外光谱法在红曲菌固态发酵过程参数检测中的应用[J]. 分析测试学报, 2014, 33(1):13-20.
[3] Cozzolino D, Kwiatkowski M J, Parker M. Prediction of phenolic compounds in red wine fermentations by visible and near infrared spectroscopy[J]., 2004, 513(1):73-80.
[4] Chen H Z, Song Q Q, Tang G Q. Optimal scheduling of cyclic batch processes for heat integration-basic formulation[J]., 2014, 60(3):595-601.
[5] Fernandez-Novales J, Lopez M I, Gonzalez-Czballero V. Shortwave- near infrared spectrescopy for determination of reducing sugar content during grape ripening, winemaking, and aging of white and red wines[J]., 2009, 42(2): 285-291.
[6] Xu L, Lu J G, Yang Q M. A new method of information interval selection near infrared spectral[J]., 1997, 17(1): 56-60.
[7] Norgaard L, Saudland A, Wagner J, Interval partial least-squares regression (ipls): a comparative chemometric study with an example from near-infrared spectroscopy[J]., 2000, 54(3): 413-419.
[8] Wang X F, Bao Y F, Liu G L. Study on the best analysis spectral section of NIR to detect alcohol concentration based on sipls[J]., 2012, 29: 2285-2290.
[9] Durand A. Genetic algorithm optimisation combined with partial least squares regression and mutual information variable selection procedures innear-infrared quantitative analysis of cotton–viscose textiles[J]., 2007, 595(1):72-79.
[10] Zou H Y, Wu H L, Fu H Y. Variable-weighted least-squares support vector machine for multivariate spectral analysis[J]., 2010, 80(5):1698-1071.
[11] Alves J C, Poppi R J. Biodiesel content determination in diesel fuel blends using near infrared (NIR) spectroscopy and support vector machines (SVM)[J]., 2013, 104:155-161.
[12] 刘雪梅, 柳建设. 基于LS-SVM建模方法近红外光谱检测土壤速效N和速效K的研究[J].光谱学与光谱分析, 2012, 11: 3019-3023.
[13] Chauchard F, Cogdill R, Rcussel S. Application of LS-SVM to non-linear phenomena in NIR spectroscopy: development of a robust and portable sensor for acidity prediction in grapes[J]., 2004, 72(2):141-150.
[14] 吴瑞梅, 王晓, 郭平, 等. 近红外光谱结合特征变量筛选方法用于农药乳油中毒死蜱含量的测定[J]. 分析测试学报, 2013, 32(11):1359-1363.
[15] Slinkard K, Singleton V L. Total phenol analysis: automation and comparison with manual methods[J]., 1997, 28(1):49-55.
Detection of Total Phenol of Chinese Yellow Wine: A NIRS Band Selection Method Based on GA-LSSVM
ZHANG Yan,ZHAO Zhong-gai,LIU Fei
(,,214122,)
The objective of the paper is to achieve the rapid detection of the total phenol in the Chinese rice wine by NIRS. In order to develop the model for nonlinear NIRS with small sample, least squares support vector machine (LSSVM) is introduced into the genetic algorithm-based (GA-based) wavelength-selection method, and a GA-LSSVM method is proposed. In the proposed method, each segment of wavelength is modeled by the LSSVM method, and the optimal segments are determined by the GA algorithm. By employing the GA-LSSVM model, the prediction correlation coefficient of the total phenol is 0.9734, and the root mean square error for prediction (RMSEP) is 5.5596. The application results demonstrate that compared with the conventional methods, the proposed method can achieve better extraction of the nonlinear information hiding in the NIRS, and get the better prediction performance.
NIR,total phenol in the Chinese yellow wine,GA-LSSVM
O657.33
A
1001-8891(2015)07-0613-05
2015-04-17;
2015-06-03。
张严(1989-),男,硕士研究生,主要研究方向为近红外光谱分析。
赵忠盖,男,博士,副教授,硕士生导师,研究方向:间歇过程统计监控、软测量与状态估计,E-mail:gaizihao@jiangnan.edu.cn。
国家自然科学基金项目,编号:61134007。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
食品工业(2022年1期)2022-02-21 01:30:38
基层中医药(2020年8期)2020-11-16 00:55:18
资源节约与环保(2018年1期)2018-02-08 02:18:31
高师理科学刊(2016年8期)2016-06-15 20:27:45
文化交流(2016年1期)2016-03-25 09:16:32
西藏科技(2015年4期)2015-09-26 12:12:58
济宁医学院学报(2014年4期)2014-08-16 13:44:19
河南科技(2014年18期)2014-02-27 14:14:53
食品科学(2013年8期)2013-03-11 18:21:26
