
基于连续预测的半监督学习图像语义标注*
2015-03-27 08:05:53郭玉堂
计算机工程与科学 2015年3期
郭玉堂,李 艳
(1.安徽大学计算机科学与技术学院,安徽 合肥 230601;2.合肥师范学院计算机科学与技术系,安徽 合肥 230601)
基于连续预测的半监督学习图像语义标注*
郭玉堂1,2,李 艳1
(1.安徽大学计算机科学与技术学院,安徽 合肥 230601;2.合肥师范学院计算机科学与技术系,安徽 合肥 230601)
为了在图像底层特征与高层语义之间建立关系,提高图像自动标注的精确度,结合基于图学习的方法和基于分类的标注算法,提出了基于连续预测的半监督学习图像语义标注的方法,并对该方法的复杂度进行分析。该方法利用标签数据提供的信息和标签事例与无标签事例之间的关系,根据邻接点(事例)属于同一个类的事实,构建K邻近图。用一个基于图的分类器,通过核函数有效地计算邻接信息。在建立图的基础上,把经过划分后的样本节点集通过基于连续预测的多标签半监督学习方法进行标签传递。实验表明,提出的算法在图像标注中的标注词的平均查准率、平均查全率方面有显著的提高。
连续预测;半监督;图像标注;图学习;多标签
1 引言
图像检索技术从诞生以来,经历了基于文本的图像检索TBIR(Text Based Image Retrieval)、基于内容的图像检索CBIR(Content Based Image Retrieval)以及基于标注的图像检索技术ABIR(Annotation Based Image Retrieval)。ABIR技术能有效地解决图像低层特征与高层语义之间存在的“语义鸿沟”问题,它的出现促进了自动图像标注技术AIA(Automatic Image Annotation)的发展。自动图像标注技术是利用计算机视觉、模式识别、机器学习等技术,让计算机自动地给未标注图像加上能准确反映图像语义特征的关键词,以便将图像检索技术转化为相对比较成熟的文本检索技术。
对于自动图像标注技术,目前已经取得一定的成果,也存在各种不同的标注方法。1999年,Mori Y等人[1]提出共生模型,它首创性地开辟了自动图像标注领域的研究。Jeon J等人[2]提出一种交叉媒体相关模型CMRM,将图像标注问题看作跨语言检索问题,通过计算图像区域类和标签集的联合概率对图像进行标注。文献[3]提出的基于机器翻译的识别模型,将图像分割的区域进行聚类,利用机器翻译模型在区域类与标签之间形成映射,再通过EM算法进行实现。Lavrenko V等人[4]提出的连续空间相关模型CRM(Continueness Relationship Model),则是用连续概率密度函数来描述区域类,进而利用区域类与标签的联合概率分布图像进行标注。有监督多标注方法SML(Supervised Multi-Label)[5,6]采用最小错误率的优化准则和统计分类的思想。文献[7]利用支持向量机SVM(Support Vector Machine)的多分类器为空间映射方法,将图像的低层特征映射成具有一定高层语义的模型特征,从而实现基于概念索引的图像标注。近年来,基于图学习的方法受到很多学者的关注。文献[8]提出了一种基于Gcap自动图像标注的方法,它运用图像分割算法把图像分割成一系列区域,用一个关联图表示图像与区域、图像与标注词、区域与区域的关系,以待标注的图像节点作为起点,运行随机游走算法对待标注图像进行标注。文献[9]介绍了图的半监督学习,并叙述了如何构建图等内容。文献[10]提出通过连续预测的方式传递标签的半监督学习方法,但这种方法是一种传统的二分类方法,在很多方面具有局限性。
为了提高图像标注的精确度,结合基于图学习标注方法和基于分类的标注方法,提出了基于连续预测的半监督学习图像语义标注,该方法利用标签数据提供的信息和标签事例与无标签事例之间的关系,根据邻接点(事例)属于同一个类的事实,以顶点对应事例,边权值对应相似性的形式,构建相似图,用相似图表示数据点之间的关系。用一个基于图的分类器,通过核函数有效地计算邻接信息。进而,每一个无标签节点相对于每个类都对应一个值,这个值用来度量属于这个类的程度,进而得出每个节点关于类的一序列的值,根据某一量度对这一序列的值进行取舍,便可得出这个无标签点对应的多标签。并可以应用两种不同方式:类标签(硬标签)和似然类估计(软标签)对图像进行标注。
2 基于连续预测的半监督学习
2.1 基于图的半监督学习
传统的基于分类的机器学习的方法仅仅利用标签集作为训练集得出分类器,然而困难的是如何得到这些标签集,因为这些标签集的得到是很费时费事的,需要大量的人力和物力。而无标签数据是很容易得到的,但无标签数据却很少被利用。半监督学习却可以充分利用少量的标签数据和大量的无标签数据建立分类器,进而对无标签数据进行分类,事实证明结果确实比较精确,很令人满意,同时节省了大量的人力。在理论和实践上有很大的意义和可行性,因此得到多数学者的青睐。
在半监督算法中,已知类标的训练数据和未知类标的测试数据都将参与到算法的学习过程中。在学习阶段利用更多的信息,如数据的分布特性等,它适用于总数据量较大、已标记训练数据量相对较小的情况。主要利用数据的总体空间分布特征和原始类标签信息,使得最终得到的分类结果在数据空间上能够总体充分平滑(相邻点的标签相似),并保证尽可能地拟合训练数据。
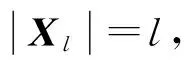
2.2 基于连续预测的半监督学习
传统的连续预测算法利用一个基于图的核光滑分类器和一个标准化机制,依次预测Xu内节点的标签。在给定相似矩阵Wr的情况下,首先进行光滑化,光滑矩阵Sr的元素是:
(1)
光滑矩阵Sr是一个随机矩阵,所有行之和等于1。然后在经过局部阶段的迭代后,预测出对任何一个v∈Xr的标签fv,fv是一个[0,1]的真实实数值,若v∈Xl,则fv=1。在局部阶段的基础上,全局阶段把局部阶段的值进行规则化。同时,这个正规化部分考虑到远离标签节点的无标签节点的分类更加不确定的事实,最终每一个样本点对应一个数值,这个数值表示它属于某个指定类的概率的大小。
3 基于连续预测的多标签半监督学习
传统的连续预测的半监督学习是一个二分类问题。对于传统的二分类,它的主要思想是:假设类与类之间相互独立,一个样本只归为其中的一个类。而在实际应用中,仅仅二分类并不能理想地解决一些现实问题,因为样本会和多个类相关联,需将样本同时归到多个类,如:图像标注问题,因为一个图像它可以同时拥有多个标签,假如一个人物山水画的图像,二分类标注只会把它标注为人物、山、水中的某一个标签,这具有局限性。而多标签分类则把上面的三个关键词同时标注出来,这能更准确和全面地反映出图像的特性。这就是多标签分类问题的优点。所以,仅仅用二分类的方法是很难合理解决一些问题的,但若用多标签分类方法来解决的话,问题就会变得简单易行。所以,在此基础上,我们提出基于连续预测的多标签半监督学习。
基于连续预测的多标签半监督学习是在传统的连续预测算法的基础上进行的扩展。基于连续预测的多标签半监督学习在光滑化的基础上,首先定义一个分类器,对于任何一个节点v∈Xr,分类器Hr(v)为:
(2)
其中Fr是标签预测矩阵,Fr∈Rn×c,且F0=YL。对每个节点v∈Xr对应的Hr(v)是一个Rn×c的矩阵。
多标签连续预测算法描述如下:
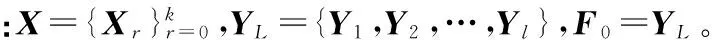
输出:Y=Fk。
从r=1开始进行下面两个阶段的循环:
(1)局部阶段:
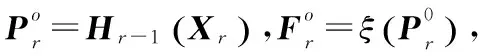
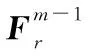
(2)全局阶段:


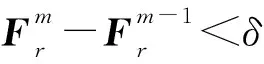

4 基于连续预测的半监督学习图像语义标注
首先我们从图像数据库中取出一小部分图像作为标签集,其余图像作为待标注点。然后对数据库中所有的图像进行视觉特征提取,为避免分割后的局部特征不能完整反映图像的全局语义信息的问题,我们采取提取图像全局特征的方法。这里的视觉特征包括颜色特征、边缘特征、边缘方向特征、纹理特征等。对于图像库我们分别进行某一视觉特征的提取。如颜色特征的提取:从布局与结构信息得到图像特征,对每个给定的图像求出其对应的颜色分布直方图,采用一定的量化方法(如:归一化)将颜色特征直方图转化为颜色特征向量。对以上图像特征我们分别进行了实验比较,发现颜色特征在我们实验中效果最好。
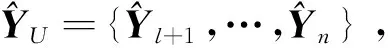
(3)
其中d(,)表示最短路径,调节参数τ>0。在距离的计算中,我们对欧氏距离、余弦角距离、直方图相交距离等,进行了一系列的实验比较,发现欧氏距离具有很大的优越性。

划分后,Xr对应的对称相似矩阵Wr,是权值相似矩阵W的子矩阵。对每个节点集Xr(r∈1,…,k)中的点利用多标签连续预测算法,分别进行局部和全局的处理,最终得出标签预测矩阵Fk。
5 实验结果与分析
对于实验数据集的选取,为了实验的可靠性,我们选取Corel 5000图像数据集作为实验对象,其中有花、熊、虎、人物、飞机、山脉、鸟,珊瑚等50类图像,每类中包含100幅图像,共计5 000幅图像作为实验数据,每幅图像与l~5个标注词关联,共371个词。取其中的500个图像作为已标签数据,其余的作为未标签样本数据,我们的最终目标是对未标签图像进行语义标注,我们用4到5个关键词描述每个图像的基本语义。用Matlab 7.10作为实验的平台。
由于每幅图像使用1~5个来标注,因此取概率最大的5个词作为该图像的标注词。对每个标注词用查准率(Precision)、查全率(Recall)和F-Measure标准对各种方法的性能进行分析。并用平均查准率(ave-precision)、平均查全率(ave-recall)和平均F值(ave-F)的三种情况的分布情况进行比较分析。
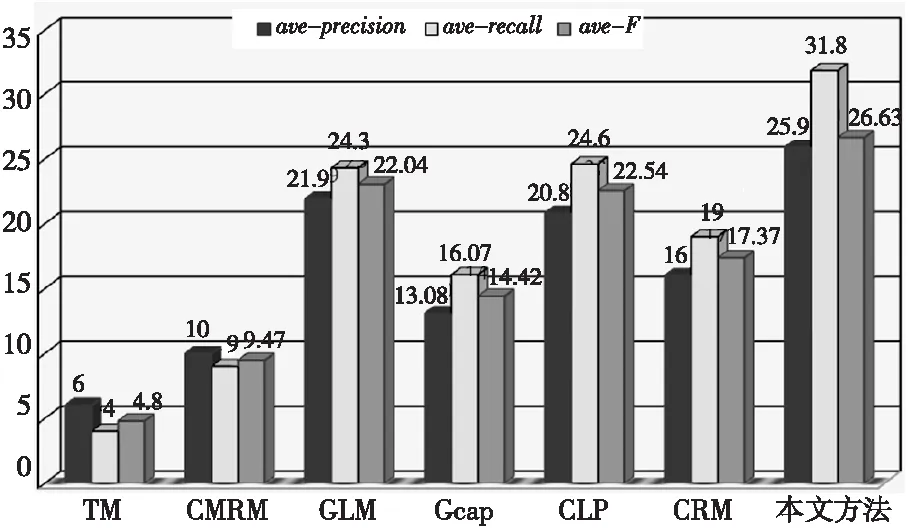
Figure 1 Performance comparison of several kinds of annotation algorithms
为了说明我们的算法标注图像的有效性,在图1中,把我们的算法与下面的几种传统的经典算法TM、CMRM、GLM(Graph Learning Model)[11]、Gcap、互相关传播模型(CLP)[12]和CRM在平均查准率(ave-precision)、平均查全率(ave-recall)、平均F值(ave-F)进行比较。其中GLM是采用传统建图方法的基本图像标注,CLP利用词汇间的相关性提高图像标注的性能。从图1可以看出,即使与标注性能比较好的GLM、CLP相比较,本文方法的标注性能都比GLM、CLP要好,因此可以知道:我们提出的算法的标注性能得到了显著的改进。

Table 1 Results of image annotation
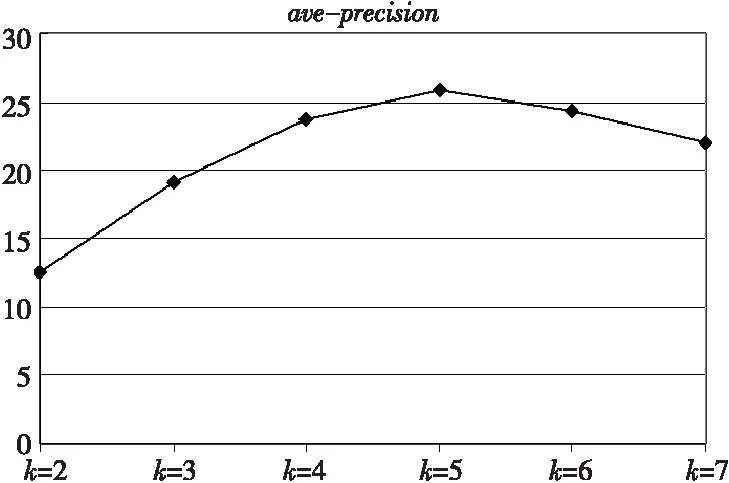
Figure 2 Effect of K values on experimental resutlts in the sparse graph

6 结束语
本文提出的基于连续预测的多标签半监督学习是在传统的连续预测算法的思想上进行的扩展。结合连续预测和半监督学习的思想,在传统的二分类的连续预测的基础上,进一步把连续预测算法扩展为多标签半监督学习,并利用这种方法进行图像标注。它根据图像之间的相似度建立图,把经过划分后的样本节点集通过连续预测的方法进行多标签传递。实验表明,本文提出的算法显著提高了图像标注的性能。与经典的算法相比,算法的实时性,有待于进一步提高。所以,在今后的工作中将考虑进一步提高算法的效率和半监督学习算法的研究。
[1] Mori Y, Takahashi H, Oka R. Image-to-word transformation based on dividing and vector quantizing images with words[EB/OL].[2013-06-13]. http://citeseer.ist.psu.edu/368129.html.
[2] Jeon J, Lavrenko V, Mnmatha R. Automatic image annotation and retrieval using cross-media relevance models[C]∥Proc of the 26th Annual Intelnational ACM SIGIR Conference on Research and Development in information Retrieval, 2003:119-126.
[3] Duygulu P, Barnard K, de Freitas J F G, et al. Object recognition as machine translation:learning a lexicon for a fixed image vocabulary[C]∥Proc of the 7th European Conference on Computer Vision Copenhagen, 2002:97-112.
[4] Lavrenko V, Mnmatha R, Jeon J. A model for learning the semantics of pictures[C]∥Proc of Information Retrieval(2003) Citeseer, 2003:553-560.
[5] Carneiro G, Chan A B, Moreno P J, et al.Supervised learning of semantic classes for image annotation and retrival[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2007,29(3):394-410.
[6] Vasconcelos N. Minimum probability of error image retrieval [J]. IEEE Transactions on Signal Processing,2004,52(8):2322-2336.
[7] Cusano C, Ciocca G, Schettini R. Image annotation using SVM [J]. Proceedings of SPIE,2004,53(41):330-338.
[8] Pan Jia-yu, Yang Hyung-jeong, Faloutsos C, et al. Gcap:Graphbased automatic image captioning[C]∥Proc of the 4th International Workshop on Muhimedia Data and Document Engineering(MDDE 04),in Conjunction with Computer Vision Pat-tern Recognition Conference(CVPR 04),2004:146-156.
[9] Zhu X. Semi-supervised learning with graphs[R]. Technical Report, Pittsburgh:Carnegie Mellon University, 2005.
[10] Culp M, Michailidis G. Graph-based semisupervised learning[J]. IEEE Transactions on Pattern Analysis and Mac-
hine Intelligence,2008, 30(6):174-179.
[11] Tong H,He J,Li M,et al.Graph based multi-modality learning[C]∥Proc of the 13th Annual ACM International Conference on Multimedia,2005:862-871.
[12] Kang F, Jin R, Sukthankar R. Correlated label propagation with application to multi-label learning[C]∥Proc of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition,2006:1719-1726.
[13] Liu Wei,Wang Jun,Chang S-F.Robust and scalable graph-based semisupervised learning[J]. Proceedings of the IEEE,2012,100(9):2624-2638.
[14] Tang Jin-hui, Hong Ri-chang, Yan Shui-chang, et al. Image annotation by kNN-sparse graph-based label propagation over noisily tagged web images[J].ACM Transactions on Intelligent Systems and Technology,2011,2(2):14.
[15] Gu Fang-ming,Liu Oayou,Wang Xin-ying.Semi-supervised weighted distance metric learning for kNN classification[C]∥Proc of IEEE International Conference on Computer, Mechatronics, Control and Electronic Engineering (CMCE)2010:406-409.
GUO Yu-tang,born in 1962,PhD,professor,his research interests include pattern recognition, and image processing.

李艳(1984-),女,安徽阜阳人,硕士生,研究方向为模式识别与图像处理。E-mail:274732046@qq.com
LI Yan,born in 1984,MS candidate,her research interests include pattern recognition, and image processing.
Semi-supervised learning image semantic annotation based on sequential prediction
GUO Yu-tang1,2,LI Yan1
(1.School of Computer Science and Technology,Anhui University,Hefei 230601;2.Department of Computer Science and Technology,Hefei Normal College,Hefei 230601,China)
In order to establish the relationship between low-level features and high-level semantics of the image,improve the accuracy of image automatic annotation,combining with graph learning and classification annotation algorithm,we propose an image semantic annotation method for sequential prediction-based semi-supervised learning,and analyze the complexity of the method.According to the fact that the adjacent vertexes (cases) should belong to the same class, by using the information provided by tag datum and the relationship between tag cases and cases with no labels,the method constructs a K relative neighborhood graph.We use a graph-based classifier and a kernel function to calculate the adjacency information effectively.On the basis of building graphs,we propagate the labels of the node sets derived from the samples by sequential prediction-based semi-supervised multiple labels learning method.Experiments show that the proposed algorithm for image annotation significantly improves the average precision ratio and the average recall ratio of the marked words .
sequential prediction;semi-supervised;image annotation;graph learning;multiple labels
1007-130X(2015)03-0553-06
2013-09-24;
2014-02-22基金项目:安徽省自然科学基金资助项目(11040606M134);安徽省高校自然科学基金资助项目(KJ2103A217)
TP391.41
A
10.3969/j.issn.1007-130X.2015.03.024

郭玉堂(1962-),男,安徽潜山人,博士,教授,研究方向为模式识别与图像处理。E-mail:aieyt@ah.edu.cn
通信地址:230601 安徽省合肥市合肥经济技术开发区九龙路111号安徽大学新区计算机科学与技术学院
Address:School of Computer Science and Technology,New Area,Anhui University,111 Jiulong Rd,District of Economic Technology Development,Hefei 230601,Anhui,P.R.China
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
车迷(2018年11期)2018-08-30 03:20:32
海峡姐妹(2018年3期)2018-05-09 08:21:02
电子测试(2018年1期)2018-04-18 11:52:35
光学精密工程(2016年4期)2016-11-07 09:05:00
光学精密工程(2016年3期)2016-11-07 09:03:33
现代语文(2016年21期)2016-05-25 13:13:44
公民与法治(2016年10期)2016-05-17 04:12:58
计算机工程(2015年8期)2015-07-03 12:20:27
大连民族大学学报(2015年2期)2015-02-27 08:28:11
