
基于在线多示例学习的协同训练目标跟踪算法
2015-03-15 10:53王从庆周大可
吉林大学学报(信息科学版) 2015年2期
李 飞,王从庆,周 鑫,周大可
(南京航空航天大学自动化学院,南京210016)
0 引 言
目标跟踪是人工智能和计算机视觉的重要研究课题,在智能监控、自动驾驶仪、交通监控和人机交互等领域均有重要的应用[1]。目标跟踪过程中会经常遇到光照、外观及形状变化,运动模糊以及部分甚至完全遮挡等问题,因此鲁棒的目标跟踪系统的设计依然是一项极具挑战性的研究课题。
近年来,基于检测的目标跟踪算法(Tracking-by-Detection)一直是研究热点[2-5],它将检测器与跟踪器相结合,利用跟踪器跟踪目标,同时利用跟踪结果不断更新检测器[6]。文献[2,6]以Online Boosting算法为框架首先提出了基于检测的目标跟踪算法,此后学者们提出了半监督跟踪算法(SST:Semi-Supervised Tracking)[7]、超半监督跟踪算法(BSST:Beyond Semi-Supervised Tracking)[8]、在线多示例学习跟踪算法(OMILT:Online Multiple Instance Learning Tracking)[9,10]以及协同训练目标跟踪算法[11-13]等目标跟踪算法。
在多示例学习中,训练样本是多个示例组成的包,通过估计包的概率去预测目标位置,大大提高了跟踪的鲁棒性。但该方法是利用分类器自身的结果更新分类器,这种基于自训练(self-training)的更新方法导致分类误差累积和跟踪精度下降。因此,笔者在多示例学习跟踪算法的框架下,结合协同训练,提出一种新的目标跟踪算法,该算法利用协同训练克服分类器自训练带来的误差积累问题,同时结合在线多示例学习提高了跟踪效果的鲁棒性。
1 改进在线多示例学习目标跟踪算法
1.1 在线多示例学习目标跟踪算法
多示例学习与传统机器学习的不同在于,训练数据集中每个数据作为一个包(Bag),每个包由多个示例(Instance)构成,每个包有一个可见的标签。如果包中至少包含一个标签为正(positive)的示例,则包的标签为正;如果包中所有示例的标签都是负(negative)的,则包的标签为负。文献[9]以基于检测的目标跟踪算法[6]为基础,提出基于在线多示例学习的目标跟踪算法。在文献[9]中,传统的模型更新只是利用前一帧的判决结果对当前的外观模型更新,而多示例学习却能在上一帧的结果上选取多个较好的样本组成一个包,避免了只利用上一帧不准确的结果,给分类器的更新造成误差累积的现象。由于多示例学习的这种性质,使基于多示例学习跟踪算法在各种挑战因素下具有很强的鲁棒性。
在基于检测的目标跟踪算法中,用lt(x)∈R2表示样本x在t时刻视频帧图像中的位置,x是用滑动窗口在帧图像中采样得到的样本,用f(x)表示样本x的图像特征向量,l*t-1(x)是t-1时刻已经跟踪到的目标位置。首先在t时刻,根据t-1时刻的目标位置设置搜索范围,假设目标运动是低速率的,即目标运动的范围不会超过以s为半径的搜索范围[9],在此范围内采样,得到样本集利用已经训练好的分类器,返回样本x为目标时正样本的概率分别表示样本的正负标记。然后可得t时刻的目标位置,最后在(x)附近采样得到正样本集负样本集其中α≤γ≤β,用得到的正负样本更新分类器,如此循环到最后一帧图像。
与传统的基于检测的目标跟踪算法不同,基于在线多示例学习的目标跟踪算法把样本x视为一个示例,用包含m个示例的包Xi={xi1,xi2,…,xim},i=1,2,…,n表示共有n个包,组成训练样本集{(X1,y1),…,(Xn,yn)},yi∈{0,1}是对应包的标记。一个包中如果至少有一个正示例,则该包的标记yi=1,否则yi=0,即是包中对应示例的标记,在多示例学习中把采样得到正样本放到一个包中。所有的负样本组成一个包,如果示例没有标记,可用包的标记代表示例的标记[10]。结合文献[2]中的Online Boosting算法,构建弱分类器hk(x),然后由弱分类器组成强分类器HK(x),表示如下

其中αk是对应弱分类器的权值,构建强分类器是为了预测示例的标记概率


因此

用特征向量函数f(x)=(f1(x),…,fK(x))表示样本x的特征,假设fk(x)是相互独立的,并且p(y=0)=p(y=1),弱分类器直接累加组合成强分类器,式(4)可表示为

可得到
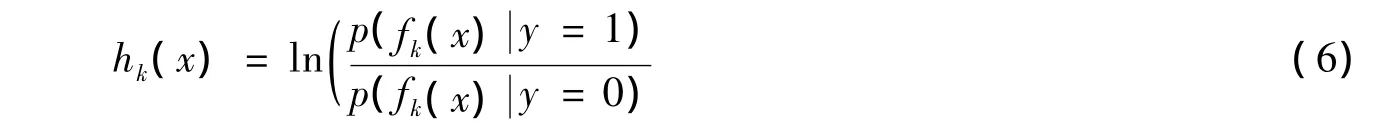
在式(6)中,每个弱分类器对应一种特征,根据文献[9]可知,),在分类器更新的过程中

其中P是正样本的个数,η是学习率,同理可得μ0,σ0的更新过程。再利用文献[14]中的Noisy-OR模型根据示例的标记概率可得包的标记概率
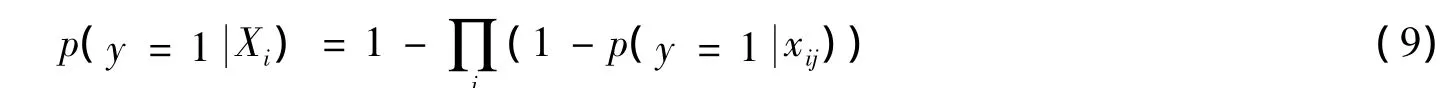
在分类器的更新过程中,维持一个弱分类器池Φ={h1,…,hM},在训练的过程中用贪婪算法从这M个弱分类器中选出 K个,组成强分类器,显然 M>K,即其 中 L=是包的似然函数。
1.2 改进的在线多示例学习目标跟踪算法
为更准确地选出有用的示例及确定目标位置,在训练过程中对正样本引入权重,在对示例标记概率加权的基础上,重新设计包的标记概率函数。靠近目标位置示例的权值高于远离目标位置示例的权值,也意味着靠近目标位置的示例对包的标记贡献大。
假设样本集中有 P 个正样本{x1j,j=0,…,P -1}和 N 个负样本{x0j,j=P,…,P+N -1},x10是当前跟踪目标位置,把正负样本分别放入正负包中{X+,X-},定义引入示例权值后的正负包的概率函数

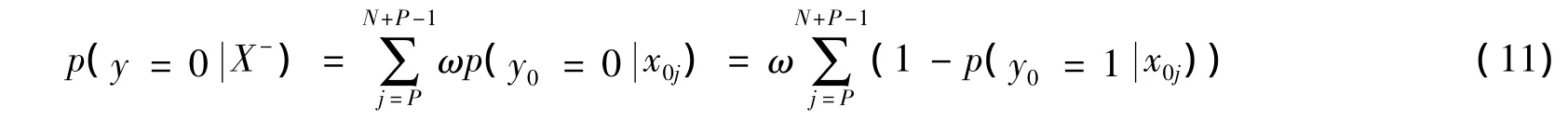
其中ω是参数,即认为负示例对负包标记的贡献是同等的。由式(10)和式(11)可得到包的似然函数
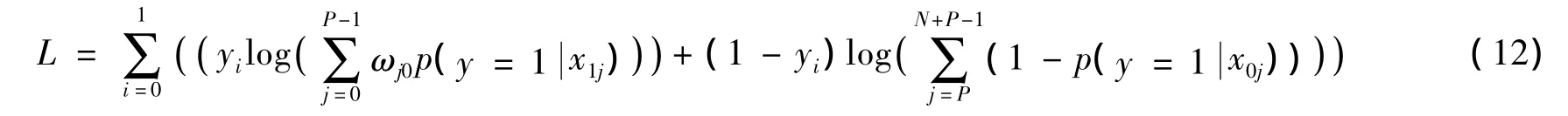
2 协同训练框架下的在线多示例学习目标跟踪算法
2.1 协同训练
协同训练是半监督学习的一种,是基于Multi-view[15]思想建立起来的。首先利用少量的有标记样本训练两个初始分类器,然后在学习过程中,这些分类器挑选若干个置信度高的未标记样本进行标记并用于更新对方分类器,此过程不断迭代,从而有效提高分类性能。然而,这需要两个前提[16]:1)如果训练样本足够,在每个特征集上都可学到一个强分类器;2)在给定类别标记时,每个特征集都条件独立于另一个特征集,协同训练算法可有效地利用未标记样本提升分类器的性能。
笔者利用Haar特征和LBP特征分别描述视频序列的帧图像,获得两个充分冗余的视图,并在这两个视图上进行协同训练,从而有效提高分类性能。Haar特征主要关注局部纹理变化信息(即对目标的姿态、形变等变化比较鲁棒性),而LBP特征更多关注边缘变化信息(即对光照等变化比较鲁棒性)。因此,对Haar特征难以区分的样本,LBP特征可能具有较好的区分能力,反之亦然。
2.2 基于改进在线多示例学习的协同训练目标跟踪算法
为了预测目标可能出现的位置,当新的视频帧到来时,对该帧重新采正负样本,利用上一帧训练好的Harr和LBP分类器分别对这些样本进行分类,从而得到相应分类器对应示例的置信值,最后对置信值进行线性加权。置信值最大的样本即是目标可能出现的位置。协同训练公式为

其中ωHaar和ωLBP分别为对应特征的权值,由式(13)、式(14)可知,当目标发生遮挡、光照或外观及姿态变化时,如果有一个分类器的置信值和权值都很小,这时目标跟踪则依赖于另一个分类器。通过这种特征融合,使跟踪器具有很好的鲁棒性。
对Haar分类器进行更新时,根据LBP(Local Binary Pattern)分类器组成的强分类器HLBPK(x)的输出。选择置信度最大的正示例,在其附近采样得到多个示例组成正包,选择置信度最小的负包,在其附近采样得到多个示例组成负包,送到Haar分类器中,对其进行更新。对LBP分类器的更新采用同样的策略,得到协同训练的目的。
在协同训练中,这样选取正负样本的优点是:一个分类器对某些负样本的判决困难时,让另一个分类器去学习,以区别这些难分的样本,当下次再遇到这些难分的样本,就可以依赖对方进行区分。这样,两个分类器不断互相帮助,学习对方觉得难分的样本,使整个系统对难分的样本更具鲁棒性。
基于改进在线多示例学习的协同训练目标跟踪算法的伪码如下。
算法1 基于改进在线多示例学习的协同训练目标跟踪算法
输入:样本集{X+,X-},X+={x1j,j=0,…,P -1},X-={x0j,j=P,…,P+N -1};

12)end for
13)计算式(13)和式(14)得到目标位置,然后采用协同策略更新分类器。
3 实验结果
实验采用跟踪结果的中心与理想目标位置的中心误差(Center Error)衡量跟踪算法的优劣,测试视频采用文献[14]提供的视频库,该视频库已经标注了测试视频序列的理想目标位置。把提出的改进在线多示例学习的协同训练目标跟踪算法(COWMIL:Co-Training Weignted Multiple Instance Learning)、半监督目标跟踪算法(SST:Semi-supervised Boosting Tracking)、多示例目标跟踪算法(MIL:Multiple Instance Learning)用测试视频序列进行对比,得到各个算法的优劣。
测试视频序列采用文献[14]的Car和David序列,首先在第1帧视频中标记出目标位置,并设定初始跟踪矩形框的大小为35×80像素,采样正负样本,对分类器进行初始化,然后算法自动运行跟踪目标。设置弱分类器的数目K=150,选择器的个数M=25,正样本采样数为10个,负样本采样数为20个,α=20,β=25,γ=40,搜索范围S=30,学习率η=0.85。这两个序列中,场景的光照变化较大,因此可用来测试跟踪算法的鲁棒性,图1和图2分别表示具体跟踪结果,实线的矩形框表示笔者的方法,虚线的矩形框表示多示例目标跟踪算法,点划线的矩形框表示的是半监督跟踪算法。实验在Intel Pentium 3.20 GHz,双核CPU,4 GByte内存的计算机上采用Matlab编程完成。图3、图4分别是Car和David的误差曲线。

图1 Car视频序列跟踪结果Fig.1 Tracking results of Car sequence


图2 David视频序列跟踪结果Fig.2 Tracking results of David sequence
在视频序列Car中,背景光照变化比较剧烈。从图1和图3中可以看到,半监督跟踪算法的准确度漂移最为严重,多示例学习跟踪算法相比半监督跟踪算法有很大改善。不管背景光照变化多剧烈,跟踪误差始终在一定范围内。但可以看到,在视频序列的后半段,由于光照背景影响剧烈这3种算法的跟踪结果都不太理想。由跟踪算法处理视频帧的速率(见表1)发现,这3种算法的处理速度相差不明显,但由于多示例目标跟踪算法相比半监督跟踪算法和笔者算法简练些,跟踪步骤较少,所以跟踪速率较快,对算法的优化也是后续的研究重点。综上所述,笔者的算法虽然能将跟踪误差限定在一个范围内,但对光照变化剧烈的场景,在视频序列的后半段跟踪结果差强人意,这也是进一步研究的重点。

表1 跟踪算法处理视频帧的速率Tab.1 The processed frame rate of the tracking algorithm(f/s)
在视频序列David中,由于目标是人脸,会出现目标旋转的情况。由图2和图4可以看到,跟踪误差随着视频序列的帧数变化曲线都比较平缓,这3种跟踪算法都能保持很好的跟踪效果。同时还可以看到,3种算法对目标旋转的情况都具有一定的鲁棒性,都能保持很好的跟踪结果。
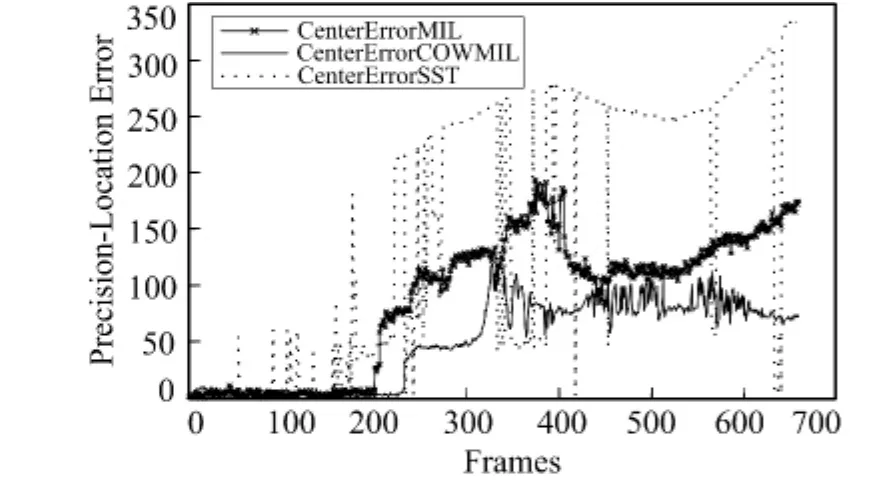
图3 视频序列Car误差曲线Fig.3 The center error curves of Car sequence

图4 视频序列David误差曲线Fig.4 The center error curves of David sequence
4 结 语
笔者提出一种改进的在线多示例学习协同目标跟踪算法,该算法的优点主要体现在:1)协同训练框架下两种分类器的结合更充分利用了现有的信息,克服了自训练带来的误差,当其中一种特征表现不显著时,可通过另一种特征帮助它克服困难;2)多示例学习分类器解决了协同训练带来的样本不准确性,多示例学习在更新样本的过程中并不像传统的分类器仅利用上一帧的结果作为更新样本,而是在此结果附近采样一些样本,放入一个包中,作为正包更新分类器,避免了在更新过程中样本的次最优问题。从仿真实验结果可见,笔者的算法相比传统算法在背景变化和目标旋转等方面具有优越性,但在跟踪速率和复杂场景的目标跟踪中表现仍不理想,这也作为进一步研究的重点。
[1]YILMAZ A,JAVED O,SHAH M.Object Tracking:A Survey[J].ACM Computing Surveys(CSUR),2006,38(4):13-16.
[2]GRABNER H,BISCHOF H.On-Line Boosting and Vision[C]∥Computer Vision and Pattern Recognition,2006 IEEE Computer Society Conference on.New York,USA:IEEE,2006,1:260-267.
[3]周鑫,钱秋朦,叶永强,等.改进后的TLD视频目标跟踪方法[J].中国图象图形学报,2013,18(9):1115-1123.
ZHOU Xin,QIAN Qiumeng,YE Yongqiang,et al.Improved TLD Visual Target Tracking Algorithm [J].Journal of Image and Graphics,2013,18(9):1115-1123.
[4]江伟坚,郭躬德.复杂环境下高效物体跟踪级联分类器[J].中国图象图形学报,2014,19(2):253-265.
JIANG Weijian,GUO Gongde.Efficient Cascade Classifier for Object Tracking in Complex Conditions[J].Journal of Image and Graphics,2014,19(2):253-265.
[5]王德建,张荣,尹东,等.中值流辅助在线多示例目标跟踪[J].中国图象图形学报,2013,18(1):93-100.
WANG Dejian,ZHANG Rong,YIN Dong,et al.Median Flow Aided Online Multi-Instance Learning Visual Tracking[J].Journal of Image and Graphics,2013,18(1):93-100.
[6]GRABNER H,GRABNER M,BISCHOF H.Real-Time Tracking via On-Line Boosting[C]∥BMVC.Leeds,UK:[s.n.],2006,1:6-9.
[7]GRABNER H,LEISTNER C,BISCHOF H.Semi-Supervised On-Line Boosting for Robust Tracking[C]∥Computer Vision-ECCV 2008.Springer:Berlin Heidelberg,2008:234-247.
[8]STALDER S,GRABNER H,VAN GOOL L.Beyond Semi-Supervised Tracking:Tracking Should Be as Simple as Detection,But Not Simpler than Recognition[C]∥Computer Vision Workshops(ICCV Workshops),2009 IEEE 12th International Conference on.Kyoto,Japan:IEEE,2009:1409-1416.
[9]BABENKO B,YANG M H,BELONGIE S.Robust Object Tracking with Online Multiple Instance Learning[J].Pattern Analysis and Machine Intelligence,IEEE Transactions on,2011,33(8):1619-1632.
[10]ZHANG K,SONG H.Real-Time Visual Tracking via Online Weighted Multiple Instance Learning[J].Pattern Recognition,2013,46(1):397-411.
[11]YU Q,DINH T B,MEDIONI G.Online Tracking and Reacquisition Using Co-Trained Generative and Discriminative Trackers[C]∥Computer Vision-ECCV 2008.Springer:Berlin Heidelberg,2008:678-691.
[12]LIU R,CHENG J,LU H.A Robust Boosting Tracker with Minimum Error Bound in a Co-Training Framework [C]∥Computer Vision,2009 IEEE 12th International Conference on.Kyoto,Japan:IEEE,2009:1459-1466.
[13]LU H,ZHOU Q,WANG D,et al.A Co-Training Framework for Visual Tracking with Multiple Instance Learning[C]∥Automatic Face& Gesture Recognition and Workshops(FG 2011),2011 IEEE International Conference on.Boston,MA,USA:IEEE,2011:539-544.
[14]WU Y,LIM J,YANG M H.Online Object Tracking:A Benchmark[C]∥IEEE Conference on Computer Vision and Pattern Recognition.Barcelona,Spain:IEEE,2013:2411-2418.
[15]XIE C,TAN J,ZHOU L,et al.A Joint Object Tracking Framework with Incremental and Multiple Instance Learning[C]∥IEEE International Conference on Digital Home.London,UK:IEEE,2012:7-12.
[16]GONG C,LIU Y,LI T,et al.The Extended Co-Learning Framework for Robust Object Tracking[C]∥IEEE International Conference on Multimedia and Expo.Berlin,Germany:IEEE,2012:398-403.
猜你喜欢
科学大众(2020年23期)2021-01-18
新世纪智能(语文备考)(2019年10期)2019-12-18
山东冶金(2019年5期)2019-11-16
山东冶金(2019年1期)2019-03-30
汽车观察(2019年2期)2019-03-15
中学生数理化·七年级数学人教版(2018年9期)2018-11-09
中国卫生(2016年5期)2016-11-12
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
生物进化(2014年2期)2014-04-16
