
带有多级制造环节的供应链能力分配方法及应用
2015-02-18 09:31:32魏成平张松柏
物流技术 2015年3期
魏成平,张松柏
(乌鲁木齐职业大学,新疆 乌鲁木齐 830002)
1 引言
基于市场机遇而构建的供应链网络是一个复杂的自组织系统[1],具有后效性,对上游供应商与下游需求商造成影响。增强系统的稳定性与环境适应性,提高系统的整体效率,成为供应链理论与实践应用面临的紧迫课题。
郭永辉[2]比较了供应链产能规划与传统产能规划的区别。齐二石等[3]通过对复杂零件协同制造任务进行分解,建立了协同制造资源优化配置模型。孙荣庭等[4]在需求为不确定的情况下,研究了存在零售商横向竞争的1:n结构的供应链协调问题。蔡建湖,黄卫来及周根贵[5]建立了供应商与零售商之间的动态博弈。桂云苗等[6]建立供应链网络设计的鲁棒优化模型,提出了模型求解的混合智能算法。刘小华和林杰[7]将供应链调度优化问题进行数学规划建模,构造了一种混合算法。
以往的研究内容缺乏对供应链上下游企业间的互动与协调方面的研究。但在当今这种经济环境下,生产往往是在一个多级制造系统中完成,在生产过程中会根据各种实际情况在上下游制造企业之间出现优先级的关系。所以,如果以提升整个供应链竞争力为目的来研究供应链,则对于生产环节的研究特别是对多级制造环节的研究显得尤为重要。本文旨在针对多级制造环节的供应链系统研究其能力分配问题,从而对该供应链上各企业进行把控,根据整个供应链的生产能力以及生产和销售需求情况及时发现瓶颈企业和异常问题,以销售需求为导向,调整生产计划和资源分配,对各种突发事件做出即时响应,以提高供应链的整体竞争力。
2 带有多级制造环节的供应链问题模型
2.1 模型描述
供应链问题共分为生产环节和销售环节。其中生产环节由原材料供应商和多级生产制造商组成,且最后一级为最终产品制造商(如图1所示)。每级的供应商或制造商均由多个企业组成,且同级各企业的产品在产品组成、产品用途方面有一定的相似度、而不同级别企业的产品是一种加工与被加工的关系,其中每一级的制造商所制造的产品均为下一级的制造商准备,相邻两级的供应商或制造商之间的供给存在一个多对多的关系。由于该供应链模型主要研究带有多级制造的生产环节,所以对销售环节进行简化,简化为由多个分销商组成一级销售环节,在以整体供应链效益最优的前提下,各个分销商之间是一种相互合作同时又相互制约的关系。由于是以整个供应链为研究对象,所以最终需要实现的目标是在充分满足销售需求的情况下尽可能的使整体供应链的利润最大化及合同饱和度最大化,从而提升其在市场中的竞争力。
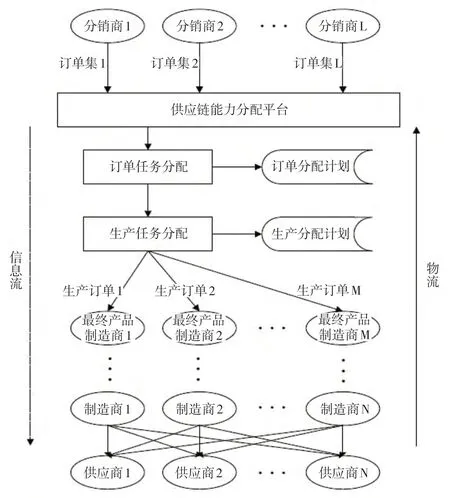
图1 带有多级制造环节的供应链能力分配问题
2.2 模型假设
为了便于建立数学模型,并使数学模型更接近现实生产,需要对该供应链模型提出一些假设条件。
(1)整个供应链中企业之间实现了信息共享,从而实现了供应与需求的有机衔接。
(2)整个供应链是以销售需求为导向来进行生产的,即根据最终分销商的合同需求量来安排生产流程及资源分配情况。
(3)假设所有企业生产的产品及整个销售市场物价稳定,暂不考虑随市场供需关系等影响而出现物价波动现象。
(4)每个分销商均会有多个订单需求即需求订单集,且在为每个产品选择最终制造商时也会有优先级的关系。
(5)每个供应商和制造商只生产一种产品,最终产品制造商生产的产品可能相同。
(6)为了能够有效的表示在生产环节中各个生产企业本身的差异性,即各个企业之间存在不同的生产成本、运输成本、企业间合作程度等,所以为每一个制造商所对应的上游供应商或制造商添加优先级。
(7)假设每个企业的生产能力有限,整个供应链的产能并不能完全满足销售需求,所以需要进行择优生产以实现利润最大化及合同饱和度最大化。
2.3 符号定义
在建立数学模型之前,首先定义符号如下:

2.4 数学模型
基于以上符号定义,并根据之前提出的假设条件,则带有多级制造环节的供应链问题的数学模型描述如下:
(1)目标函数。最大化产品利润:
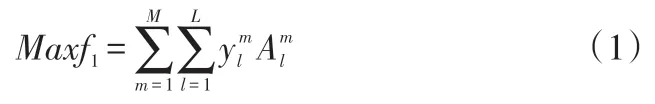
最大化合同饱和度:
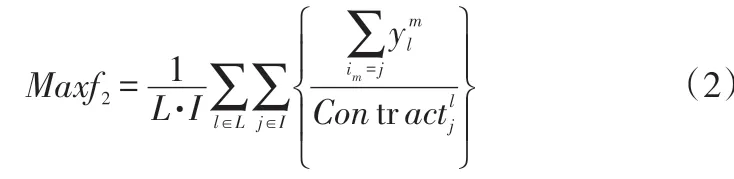
其中:和分别表示第m个最终产品制造商对其第l个分销商的产品供给量所对应的产品利润;Contr表示第l个分销商对产品j的合同需求量。
(2)约束。分销商的最大供给量约束:

供应商或制造商供应或生产的最大产能约束:
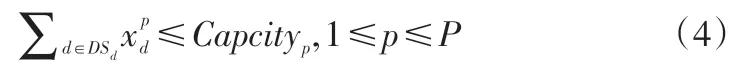
上游供应商或制造商对下游制造商的最大供应量约束:

下游制造商选择上游制造商或供应商的优先级约束:
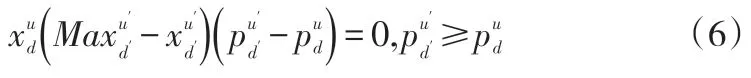
生产中某企业的上下游关系平衡约束:
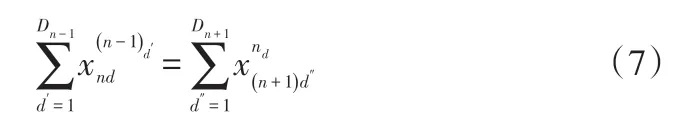
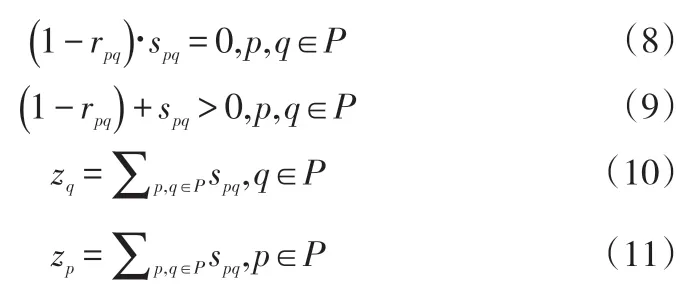
其中,约束(8)、(9)表示流向变量,其中约束(8)表示若产品p不能生产产品q则没有产品流量,约束(9)表示若产品p能生产产品q则一定有产品流量;约束(10)表示共享资源约束下的某企业生产量的计算公式;约束(11)表示共享资源约束下的某企业得到的分配量的计算公式。
3 基于邻域搜索的约束满足算法设计
3.1 适应度函数设计
根据第2 节的模型可以发现,式(1)、(2)两个目标函数均存在最大值,即所要求解的供应链模型存在理想点,即是当销售需求完全满足时,整个供应链系统能实现的利润是最大的,同时合同饱和度也是最大的。所以本文在设计算法的适应度函数时便采用理想点法。
首先,将式(1)进行无量纲化处理:
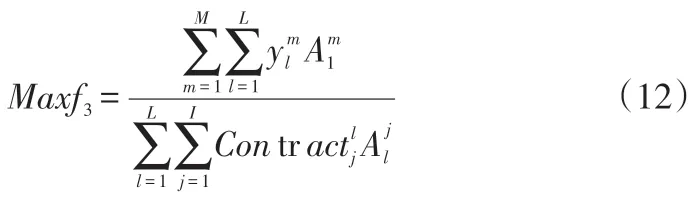
其中,表示第l个分销商在完成第j个产品的合同需求时只取该分销商对应的生产第j 个最终产品制造商集合中利润最大值。即如式(13)所示:
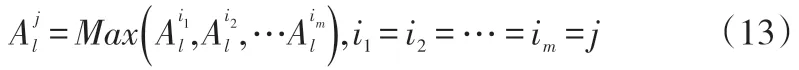
由上述分析可知,式(2)中f2和式(12)中的f3最大值均为1,所以解(1,1)即为该供应链模型的理想点。由于产能限制不能完成所有合同订单,所以真正所要求的最优解只能无限逼近理想点,故算法的适应度函数可以设为所有解与理想点之间的距离,即:
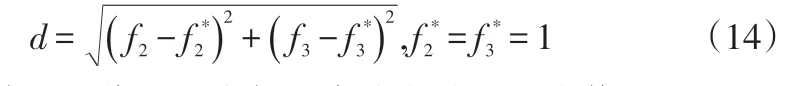
所以在算法迭代过程中便是求式(14)的最小值。
3.2 邻域的构造
本文所要求解的供应链问题模型为连续值组合优化问题,且编码设计采用的是整数编码制,所以本文采用交换的方式来构造邻域。结合本文所提出的数学模型,在交换操作后,由于存在每个订单的最大合同量及每个产品的最大产能,所以如果交换后出现冲突,则根据式(15)进行调整。
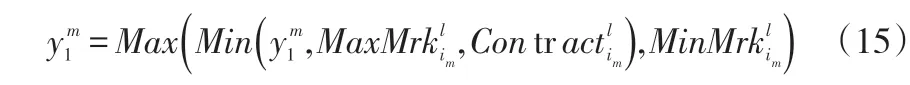
由于该模型中存在优先级,使得该数学模型变为非线性模型,一个值的变动会影响许多相关值的变动,所以经常会出现在生成邻域解时,当两个值交换后在均未超出最大产能和合同量的前提下,两个值仍存在冲突,导致整个解的不可行。根据式(1)可知,本文最终的最重要的目标是要实现利润最大化,所以当出现上述冲突时,优先保证要交换的两个合同订单中利润大的订单供应量为交换后的结果,之后再根据约束传播技术调整新解的可行性。
3.3 算法步骤
所设计的基于邻域搜索的约束满足算法首先通过贪婪思想生成初始解之后利用邻域搜索技术生成新的解集以跳出局部最优。整个算法是以约束满足算法为整体,同时在其中嵌入邻域搜索技术来实现的。具体算法步骤如下所述:
Step1(初始化变量选择规则)算法的决策变量根据分销商所提供的订单产品按盈利能力即按从大到小排序。
Step2(生成初始解)
Step2.1 依次选取未赋值的决策变量为当前变量,若决策变量集合中各变量均已赋值则转向Step8,否则转向Step3。
Step2.2为当前变量赋初始值。
Step2.3 根据当前变量的产品上下游关系确定上游变量集合USnd;若只有一个上游变量则转向Step2.4;若存在多个上游变量,则转向Step2.5;否则转向Step2.6。
Step2.6 根据已遍历路径依次为路径上各个变量赋值并转向Step2.1。
Step2.7 输出初始解。
Step3(终止条件判断)算法是否已达到迭代次数,未达到迭代次数则转向Step4.1,否则转向Step5
Step4(邻域搜索寻优)
Step4.1 随机交换解中任意两个决策变量的值,生成新的邻域解。
Step4.2 根据约束传播技术,将新生成的邻域解转化为可行解。
Step4.3 根据适应度函数更新当前最优解并转向Step3。
Step5(输出结果)输出最优解,算法结束。
4 钢铁企业实际应用
为了验证算法的实用性,应用算法对一些实际数据进行计算,并希望借此进一步挖掘算法对于实际应用的价值。本算法用C#语言编写,计算机配置:CPU:AMD Athlon(tm)Ⅱ×2 Processor2.90GHz;内存:2GB。
4.1 试验设计
模拟数据仿真实验采用随机生成数据的形式,分别对4、5、6、7 四个等级的供应链问题进行约束满足算法的求解。其中,在供应链中每一级均有6个企业,即d=6,且预先给定上下游企业间的优先级关系,同时模型中各种约束条件也以给定范围的随机数方式产生。
根据本文提出的供应链数据模型及求解算法的需要,具体实验数据设置如下:
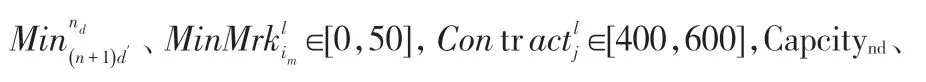
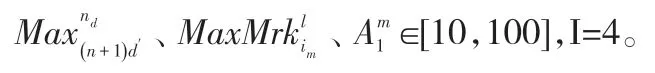
根据邻域搜索相关文献及实验数据规模设置算法最大迭代次数为100。
本实验上下游企业间优先级关系在求解前需预先给出,表1即为一个5级供应链问题上下游企业间的优先级关系。
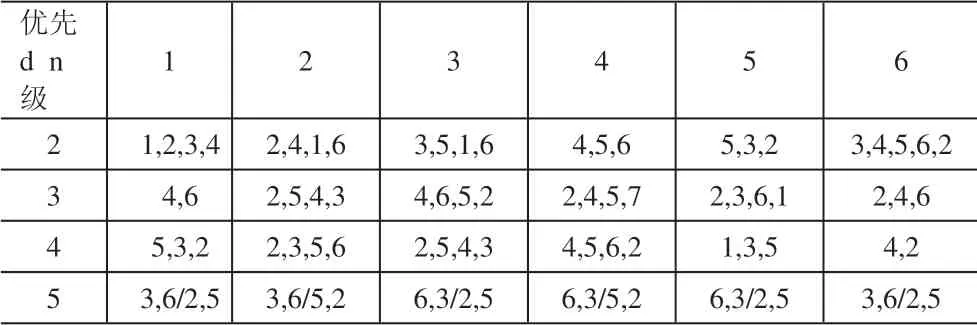
表1 供应链上下游企业优先级关系
表1 中列表示供应链等级,行表示每个等级下的企业编号,因为第1级为供应商,其没有上游企业,故表中是从第2级开始。表中的优先级序列即为其对应上一级企业的优先级关系,如第3 行第2 列的2,5,4,3 序列即表示第3 等级第2 号企业对应第2 级企业集的优先级关系为2 5 4 3,在实际计算时便会依照此序列顺序安排生产。最后一级为分销商,只有在最终产品制造商生产的产品相同时才会出现优先级的概念,所以如表中所示,即可发现3 和6 号及2 和5 号企业生产的是同种产品。
4.2 实验结果及分析
为了验证算法的有效性和实用性,将实验数据分别用传统的约束满足算法CSA与本文所设计的基于邻域搜索的约束满足算法NS-CAS求解计算,实验结果见表2、表3。
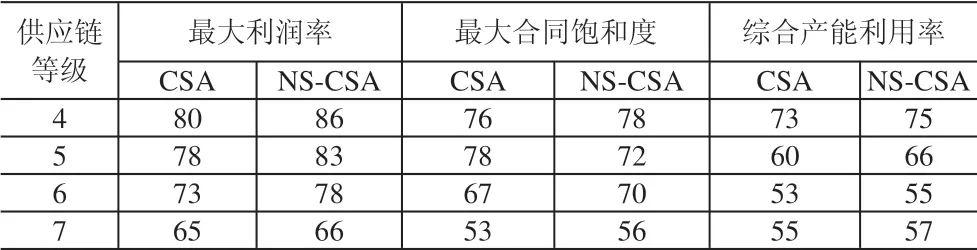
表2 CSA与NS-CAS计算结果比较
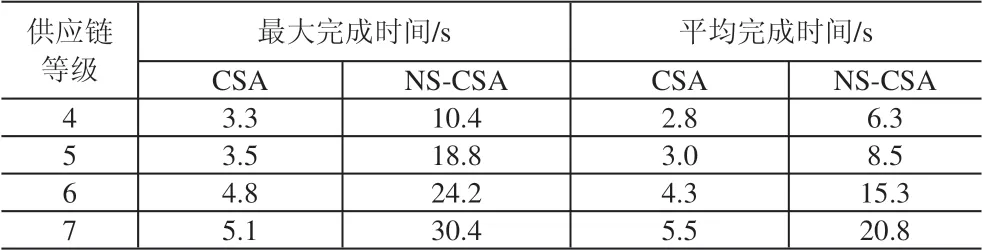
表3 CSA与NS-CAS求解完成时间比较
图2 给出了以6 级供应链为例将两种算法分别计算20 次后求解完成时间变化曲线。
为了挖掘算法应用价值,以4级供应链系统为例将具体每个订单的完成情况以及整个供应链具体各级企业的产能利用情况绘制成图进一步分析研究,具体如图3、图4所示。
通过上述对比实验,可以得出以下几点结论:
(1)通过表2 所示的数据可以得出,本文设计的约束满足算法以及为了进一步提高算法寻求能力而提出的基于邻域搜索的约束满足算法在处理4、5、6、7四个等级的供应链问题规模时均能求解出比较满意的最优解,证明所设计的算法具有良好的有效性和实用性,并且可以应对诸如7级供应链系统这样等级层次高,数据规模大且数据间逻辑关系复杂的情况。
(2)通过表2中两种算法的对比实验数据可以得出,在传统的约束满足算法中嵌入邻域搜索技术,增强算法跳出局部最优的能力,从而对算法的整体寻优能力的提高有着重要作用。基于邻域搜索的约束满足算法求解出的利润率和合同饱和度基本上均大于用传统约束满足算法计算出的结果,且提升效果较为显著,证明邻域搜索技术可以有效的和约束满足技术进行结合,互补两种技术的不足并提升整体寻优能力。

图2 CSA与NS-CAS求解时间变化曲线

图3 各订单满足情况
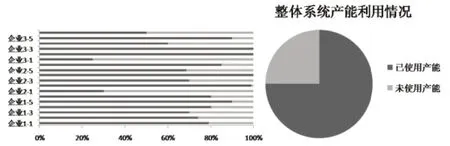
图4 各企业产能利用情况
5 结束语
(1)在问题模型方面,本文根据所提出的供应链问题的特点,提出了一个优先级的概念,并借此来表示多个企业之间关于运输成本、生产成本、库存能力等多方面的差异性,最终建立了一种带有多级制造环节的供应链问题模型。
(2)在求解算法方面,本文通过结合约束满足算法能较为快速的求出满意解的特点以及邻域搜索技术能够帮助算法跳出局部最优解的特性设计了一种基于邻域搜索的约束满足算法。该算法以约束满足算法为主体,并在其中嵌入邻域搜索技术从而提高了算法的整体寻优能力。
(3)在算法验证方面,利用C#语言实现了算法并设计了数据实验来验证算法的可行性和有效性。通过对比实验说明了基于邻域搜索的约束满足算法可以有效的解决带有多级制造环节的供应链问题,并比传统约束满足算法具有更好的全局寻优能力。
[1]夏文祥,王宗喜.浅析军队运用地方物流的基本方略[J].物流技术与应用,2003,(9):88-92.
[2]郭永辉.基于瓶颈思想的供应链多阶多厂产能规划[J].工业工程,2010,(4):62-66.
[3]齐二石,李辉,刘亮.基于遗传算法的虚拟企业协同资源优化问题研究[J].中国管理科学,2011,19(1):77-83.
[4]孙荣庭,孙林岩,李刚.不确定需求下多零售商竞争的供应链协调研究[J].工业工程与管理,2010,2(1):49-58.
[5]蔡建湖,黄卫来,周根贵.多零售商竞争环境下季节性商品订购策略研究[J].管理学报,2010,7(7):1 070-1 074.
[6]桂云苗,龚本刚,程幼明.不确定条件下供应链网络鲁棒优化与算法[J].统计与决策,2011,(8):172-174.
[7]刘小华,林杰.基于遗传粒子群混合算法的供应链调度优化[J].控制与决策,2011,26(4):501-506.
猜你喜欢
小哥白尼(军事科学)(2021年7期)2021-11-20 06:14:54
吉林大学学报(理学版)(2020年3期)2020-05-29 06:32:16
家用电器(2019年12期)2019-09-10 04:46:48
英语文摘(2019年5期)2019-07-13 05:50:22
自动化学报(2018年7期)2018-08-20 02:59:04
饲料博览(2017年5期)2017-07-25 09:26:04
周口师范学院学报(2016年5期)2016-10-17 06:36:47
卫星与网络(2016年12期)2016-02-05 09:23:28
九江学院学报(自然科学版)(2015年1期)2015-11-12 03:34:05
IT时代周刊(2015年9期)2015-11-11 05:51:53
