
基于特征加权张量分解的标签推荐算法研究
2015-01-17 02:07孙玲芳冯遵倡
江苏科技大学学报(自然科学版) 2015年6期
孙玲芳,冯遵倡
(1.泰州学院计算机科学与技术学院,江苏泰州225300)
(2.江苏科技大学计算机科学与工程学院,江苏镇江212003)
基于特征加权张量分解的标签推荐算法研究
孙玲芳1,冯遵倡2
(1.泰州学院计算机科学与技术学院,江苏泰州225300)
(2.江苏科技大学计算机科学与工程学院,江苏镇江212003)
针对标签推荐系统存在极度稀疏性的问题,通过提取标注过程的关键特征并计算元组的初始权重,构建加权元组集的张量模型;然后应用高阶奇异值分解(high order singular value decomposition,HOSVD)对张量模型降维,根据处理结果作标签推荐,从而达到提高推荐效率的目的;运用MovieLens数据集对基于特征加权张量分解的标签推荐算法进行了模拟,实验结果表明:基于特征加权张量分解的标签推荐算法比传统算法推荐效果更好。该方法能够有效改善数据稀疏性问题,提高了推荐效率.
大众标注;标签推荐;张量分解;特征加权;高阶奇异值分解
随着WEB2.0的快速发展,网络中社会标签(Social Tags)数据越来越多,大量标签数据处于无控制状态,存在冗余性和概念上的模糊性等问题,影响了大众标注系统的进一步发展.标签推荐(tag recommendation)是大众标注系统的重要应用之一,它能够简化标注过程,为用户提供个性化的标签并很好地控制数据的冗余性和模糊性[1].
为解决标签推荐系统存在数据极度稀疏性的问题,张量分解方法越来越多地被应用到标签推荐系统中.文献[2]中首先将张量应用于社会标签系统中,利用其能够完整地表示高维数据并且能维持高维空间数据的本征结构信息等特点来进行标签预测.文献[3]中尝试将K-means聚类与张量分解结合起来建立张量模型,既保证了数据初始聚合性又可以改善数据的稀疏性.然而,在现有国内外研究成果中,忽略了一些标注过程的重要特征.例如,用户使用不同标签的频率体现了标签在其心目中的重要程度;用户标注不同资源的频率体现了用户的兴趣大小.这些特征的忽略多少影响了推荐的个性化程度和准确度.
在此基础上,文中介绍了一种基于特征加权张量分解的标签推荐算法.首先提取标注过程中体现用户兴趣的重要特征进行加权,然后结合张量分解方法建立模型.在解决数据稀疏性问题的同时,提供更加准确和个性化的标签推荐.最后以MovieLens数据集对该方法进行检验.
1 大众标注与标签
大众标注(Folksonomy)又被称作大众分类、通俗分类,是在WEB2.0环境下伴随标签(Tag)技术的出现而产生的新型网络信息组织方式.大众标注允许用户对网络信息资源添加标签以方便对其进行管理和组织,并且可以和他人共享标注[4].大众标注不采用严格的分类标准,分类全部由用户提交,分类的形成过程是完全自发的,因此具备:①平面化、非等级的类目结构;② 低成本的信息组织方式;③多维度揭示信息资源等优势[5].随着WEB2.0的发展,大众标注以其独特的优势得到广泛的研究和应用,国外著名网站有Del.icio.us,Flickr,CiteUlike等,国内较受欢迎的有新浪微博、豆瓣等.图1给出了一则豆瓣电影标签示例,网页不仅包括电影基本信息,还显示用户常用的标签以供其他用户选择.

图1 豆瓣电影示例Fig.1 Example of movie.douban.com
与传统结构的“用户—资源”二元组关系不同,大众标注包括3个重要组成部分,即用户(User)、资源(Item)和标签(Tag).标签是用户根据各自需求、偏好对感兴趣资源的注释,是用户为资源添加的自定义关键词[6].用户可以为资源标注一个或者多个标签,也可以看到网络上的具有相同标签的网络资源,并以此建立与其他客户更贴心的联系和沟通.因此标签体现出了群体的力量,它进一步增强了网络资源之间的相关性和用户之间的交互性,让互联网用户接触到一个更加多样化的世界,一个关联度更大的网络资源.社会标签是标签的进一步延伸和扩展,当标签在信息关联中被大众关注和使用时,标签就具有了社会意义,从而转化为社会标签[7].
由大众标注过程可以看出,标注过程主要涉及到4个方面的内容:资源、标签、用户以及三者之间的交互关系.因此将大众标注形式化定义为一个四元组[7]:F(U,I,T,A),其中U为所有用户的集合; I为所有资源的集合;T为所有标签的集合,A⊆T ×U×I是T,U,I之间的交互关系,它是三元组(T,U,I)的集合,表示用户u使用标签t标注资源i.
2 标签推荐及其分类
标签推荐是大众标注系统重要应用之一,它通过挖掘分析信息资源的内容、用户的标注历史等为待标注信息资源提供一系列高质量的标签作为候选[8].目前国内外应用较为广泛的标签推荐技术主要分为两类:基于协同过滤的标签推荐和基于内容的标签推荐.
2.1 基于协同过滤的标签推荐
协同过滤是面向用户行为的标签推荐技术,是迄今最为成熟、应用最广泛的推荐技术.它基于一组相似的用户或项目进行推荐,根据相似用户的偏好信息产生对目标用户的推荐列表[14].根据考虑对象的不同,协同过滤算法又可以分为基于用户的协同过滤和基于项目的协同过滤.
基于用户的(User-based)协同过滤算法是根据与当前用户相似的用户信息预测产生对当前用户的推荐标签.它基于这样一个假设:如果一些用户对某一类项目的推荐结果比较接近,则他们对其他类项目的推荐结果也比较接近.首先查找与当前用户相似的用户,然后根据这些用户的标签信息去预测当前用户的标签信息.基于用户的协同过滤算法核心在于用户之间的相似度计算,常用方法有向量空间相似度和Pearson相关系数等[15].
基于项目的(Item-based)协同过滤是根据用户对相似项目的推荐结果产生对当前项目的推荐标签,它基于如下假设:如果用户对相似项目的推荐结果相近,则用户对当前项的推荐结果也会比较接近.基于项目的协同过滤算法核心在于项目之间的相似性计算,然后返回K个相似度最大的项目的标签[16-17].
以基于用户的协同过滤为例,协同过滤算法的计算过程如下:
1)获取用户ua和用户us评价过的相同项目,即两个项目集的交集,定义为项目集合Ia,s.
2)在Ia,s中,计算目标用户ua和用户us之间评分向量的相似度Sa,s.常用的相似度度量公式有以下3种[13]:
余弦相似度
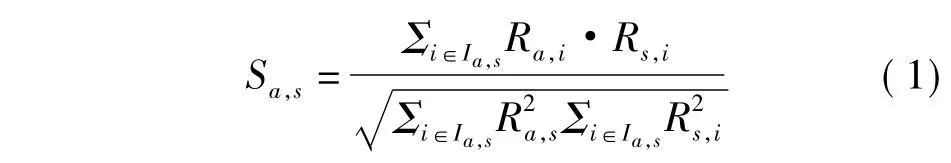
相关性相似度,即Pearson相关系数
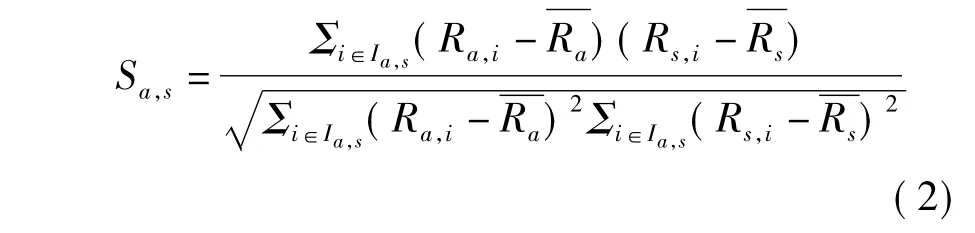
式中,Ra,Rs分别为用户ua和us对已评价项目的评分均值.Jaccard相关系数
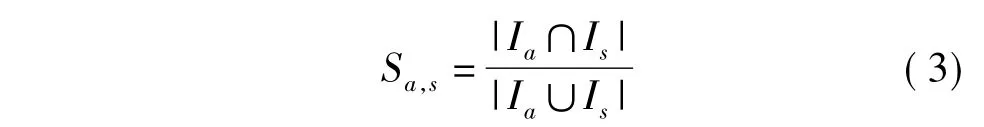
式中,Ia和Is分别为用户ua和us评价过的项目.Jaccard相关系数的计算就是用两个用户共同评价过的项目总数除以两个用户分别评价过的项目数的总和.
3)重复进行第1步和第2步,直至得到ua和所有用户的相似度集合Sa,并使用Top-N方法得到最临近集合UN.
4)预测用户ua可能对未评价项目ij的评分,公式如下:
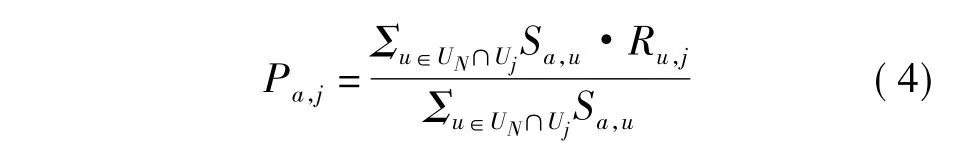
式中,Uj为评价过项目ij的用户集合.
5)重复上一步,直至得到用户ua对所有未评价项目的预测值集合Pa.然后采用Top-N方法,从集合Pa中选取前N个最高评分的项目推荐给用户.
协同过滤推荐的优点,如非结构化信息处理、个性化推荐以及自动化程度高等.但同时也暴露了一些缺点,如稀疏性问题、冷启动问题、实时性问题等[12].
基于内容的标签推荐是标签推荐的基本方法,是以文档的内容作为标签推荐的依据,一般使用文本内容,如新闻网页、博客等.该方法通常包括3个步骤:首先提取文本内容特征建立模型,然后比较已有标签与内容特征之间的相似度,得出有序的标签推荐候选集,最后选出相似度最大的前N个标签,推荐给用户[7].
使用基于内容的方法作标签推荐首先考虑内容特征粒度问题,即用什么粒度的特征来表示文本内容,作为标签推荐的依据.
词汇是一种表示文本内容的细粒度特征.当新的资源被提交时,推荐算法首先从文本内容中抽取关键词,找出关键词与已有标签之间的相似度,根据相似度选择前N个标签推荐给用户.关键词和标签的相关性计算有许多方法,最简单直观的是计算关键词和标签共同出现的次数占所有情况的比例.但是,由于标签的稀疏性,直接使用该方法可能使得相似性无法计算.因此,使用改进的Google距离公式[8]计算描述词和标签的相关性.
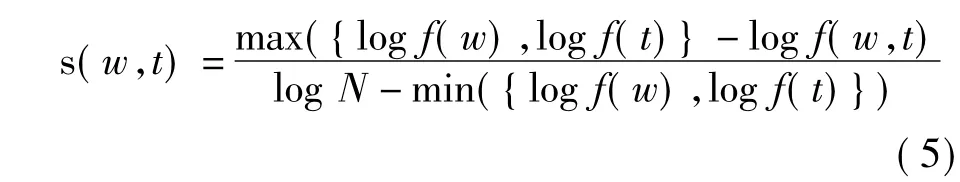
式中:f(w),f(t)分别为关键词和标签在词集和标签集的并集中出现的次数;f(w,t)为关键词和标签同时出现在并集中的次数;N为并集总计词数.
隐含主题是表示文本内容的粗粒度特征.在基于隐含主题的方法中,不再考虑单个词汇与标签之间的关系,而是将整个文本看作不同主题的混合,通过抽取文本与标签集的主题特征,找出两者之间的相似度,根据相似度,选择前N个标签推荐给用户.应用最广泛的是隐含狄利克雷分配模型(latent dirichlet allocation,LDA)[9].LDA模型最早是由Blei等人提出的无监督的概率图模型,它将文本表示为K个隐含主题上的一个分布,而文本中的每个词是由一个不可观察的隐含主题生成,这些隐含主题则是从文本对应的分布中采样得到.标准LDA模型的建模对象是文本中的词,为把标签引入LDA模型,同时建模文本资源的词汇集和标签集.文献[8]中对Author-Topic模型作改进,提出了新的模型Tag Topic来进行标签的推荐.标签的概率计算如下: PTT(ti|Tr)=Σzj=1p(ti|zi=j)p(zi=j|(Tr∪Dr))=
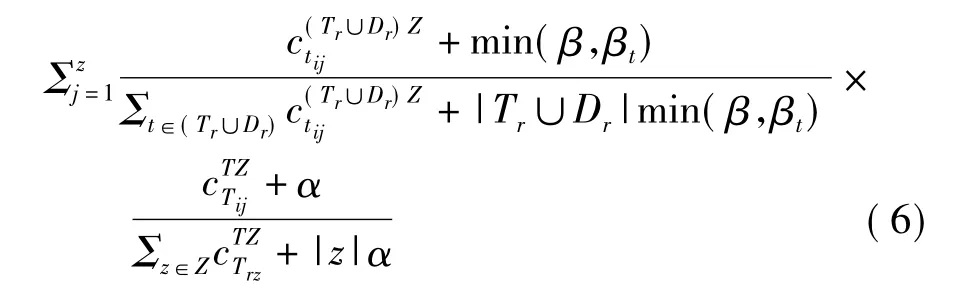
3 基于特征加权张量分解的标签推荐
3.1 计算元组的初始权重
在标签推荐系统中,用户的标注过程在一定程度上反映了用户的兴趣.注意到这样两个特征:用户使用特定标签进行标注的次数越多,表明用户对此标签的兴趣越大;用户对特定资源进行标注的次数越多,表明用户对此资源的兴趣越大.因此,用户的兴趣度就通过元组集中标签和资源出现的频率得以表现[10].据此特征为元组的初始权重进行加权计算,经过标准化处理之后,元组ti的权重T表示为:
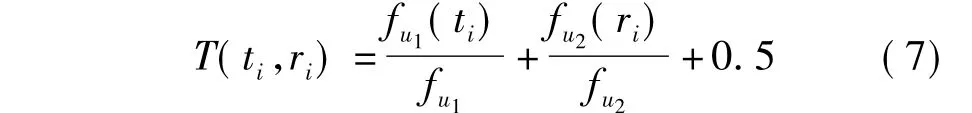
式中:fu1(ti)为用户u使用标签ti的频数;fu1为用户u的标签总频数;fu2(ri)为用户u标注资源ri的频数;fu2为用户的资源总频数;0.5为调节因子.
坡度空间数据由DEM数据在ArcGIS 9.3中,通过Slope功能生成。曼宁系数空间数据利用ArcGIS 9.3将查阅文献获得的曼宁系数属性数据(表1)与土地覆盖类型空间数据相关联生成。土壤饱和导水率与土壤储水能力,通过结合土壤类型组成及其土壤剖面等属性数据,借助于土壤水分运动参数模型RETC推导获得,空间数据在ArcGIS 9.3下通过建立土壤水分运动参数与土壤类型空间数据之间的关联生成。
3.2 初始三维张量的构建
基于用户标注关系,根据加权三元组集(user,item,tag)构建三维张量A∈Ru×i×t,使用p表示三元组的初始权重,其大小代表二元组(user,item)对tag的喜好程度,使用u,t和i分别表示用户、标签和资源的字序标识.
3.3 张量分解和重构
对张量A进行高阶奇异值分解,首先需要将张量进行矩阵展开,也就是将张量按照不同的维度(n-mode)重新排列成新的矩阵[11].文中张量为三维张量,因此根据定义将张量A的三个维度分别展开,可构成张量1-模、2-模、3-模展开式A1,A2,A3分别如下:
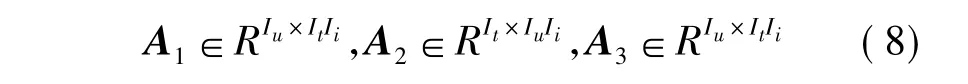
3.3.1 奇异值分解(SVD)
接下来对得到的展开矩阵分别作奇异值分解,通过奇异值分解,得到由矩阵An的奇异值组成的对角矩阵S(n).具体分解如下:
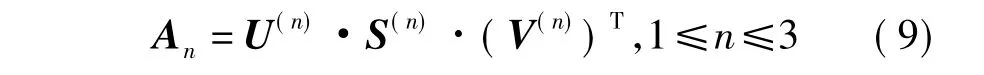
张量分解过程中,最重要的是矩阵的低秩逼近计算,即对矩阵An的奇异值进行删减(保留前c个较大的奇异值,且满足c<min{I1,I2},其中c可以通过实验保留对角阵si(1≤i≤3)中原始信息的百分比来确定.低秩逼近能够很好地过滤掉由小的奇异值引起的噪声,从而达到降噪的目的.
3.3.2 高阶奇异值分解
高阶奇异值分解是奇异值分解(high order singulr value decomposition,HOSVD)[18]在张量中的推广,张量的高阶奇异值分解是指将张量分解成与其大小相同的核心张量和多个矩阵的乘积形式.本文中,将三维张量A高阶奇异值分解表示为:
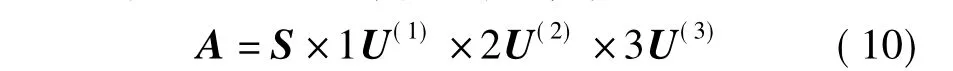
式中,核心张量S∈RIu×It×Ii是一个与张量A维数相同的正交张量,确定了实体user,item和tag之间的交互关系.S的数学表达式为:
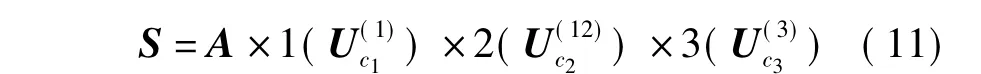
最后,由于张量数据中存在大量噪声,张量A并不具备低秩性,需要通过HOSVD构造张量A的近似张量^A.重构张量^A的数学表达式如下:
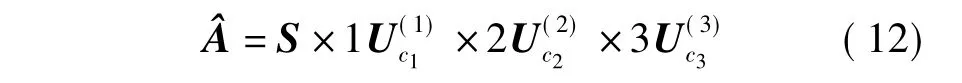
4 实验及结果分析
4.1 数据集
文中采用Mevie Lens标签数据集进行模拟分析(表1).该网站是历史最悠久的推荐系统,由美国明尼苏达大学计算机科学与工程学院的GroupLens项目组创办,是一个非商业性质的,以研究为目的的实验性站点,主要用途是向用户推荐他们感兴趣的电影.该数据集包含37个用户,671部电影及1 120个标签,共2 287个标注元组.实验过程中,将数据集划分为训练集和测试集,其中75%为训练集,25%为测试集.
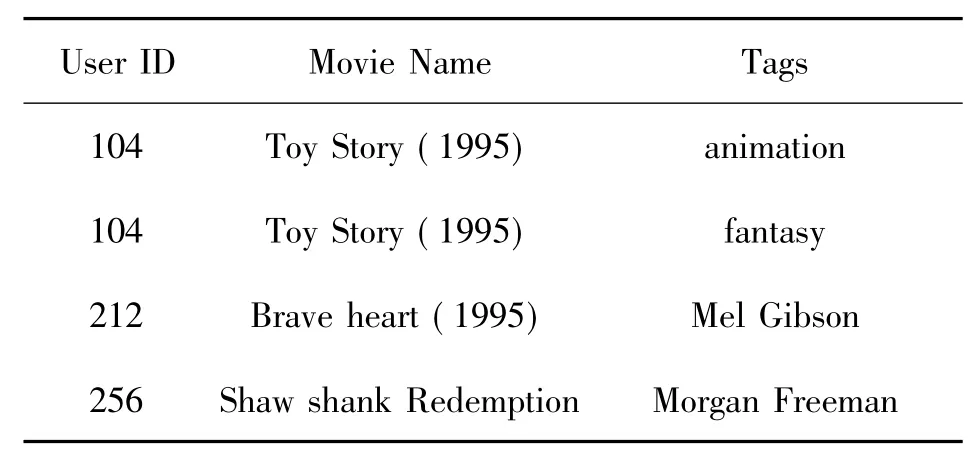
表1 部分Movie lens数据Table 1 Data from Movie lens
4.2 评估标准
文中采用准确率Precision和召回率Recall来评估推荐算法的准确性和有效性,这两个评估指标定义如下:
准确率
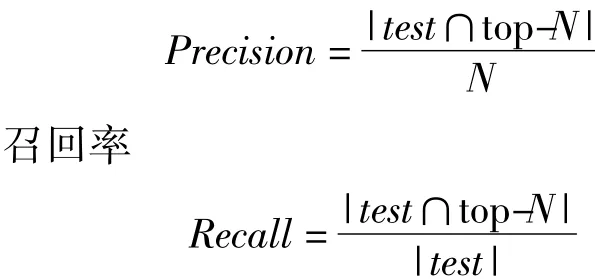
式中,test和N分别代表测试集的大小和推荐的数目,准确率和召回率分别表示算法成功推荐的比率和待推荐项目被推荐的比率[3].可见,这两个指标是冲突的,为寻找二者之间的平衡点,设定测度值F,F越大说明推荐效果越好:
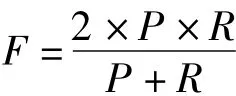
式中,P和R分别为准确率和召回率.
4.3 结果分析
实验过程中,为比较算法性能,文中采用经典的协同过滤算法进行对比,两种方法采用相同的数据集和评估标准.计算初始权重时将调节因子设为0.5以避免出现负数或较小的数值,在作低秩逼近计算过程中,经过数次测试调节,将参数ci(1≤i≤3)分别设置为40,56,56.另外,按照数据集标签的数量特征,实验中top-N值分别取2,4,6,8和10进行对比分析,计算结果如表2,3,两种算法性能比较如图2.
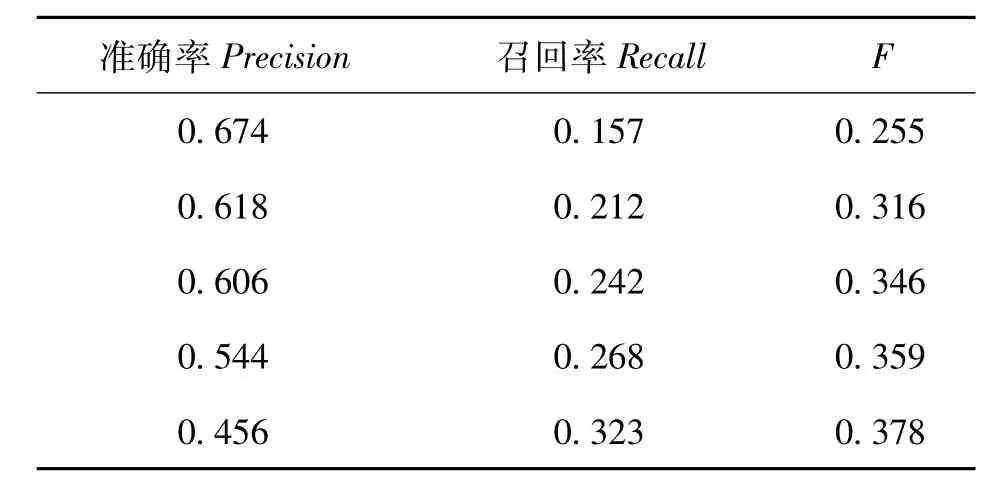
表2 文中算法推荐结果Table 2 Recommended results in this paper
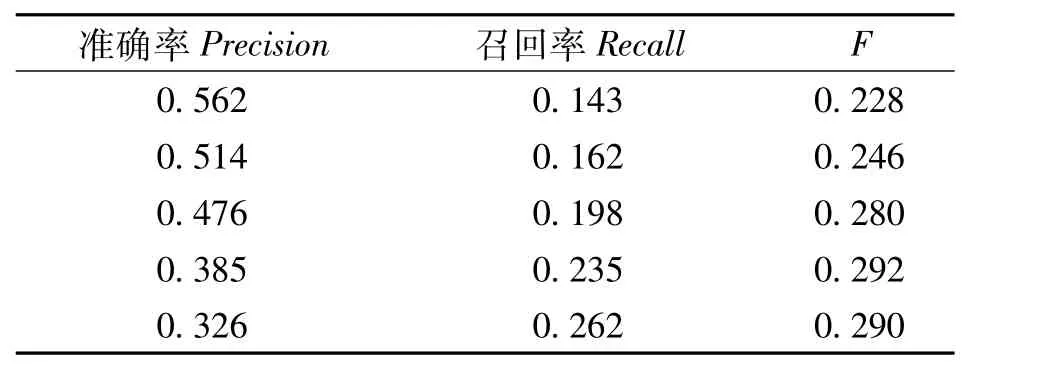
表3 协同过滤算法推荐结果Table 3 Recommended results of collaborative filtering algorithm
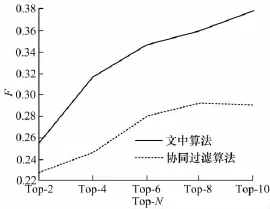
图2 两种算法性能比较Fig.2 Comparison of performances of two algorithms
综上所示,文中介绍算法所得F值在不同top-N值时均比协同过滤算法要大,而且随着N的增大,F值呈上升趋势,文中推荐算法最大值可达到0.38,而协同过滤算法得到的最大值略高于0.29.由此可以看出,基于特征加权张量分解的标签推荐算法比传统算法推荐效果更好.
5 结论
大众标注系统中的标注数据稀疏性非常严重,并且会时常出现缺失情况,张量分解是用来解决数据稀疏性问题的常用手段,但是由于算法相对复杂,处理稀疏性和缺失值的效果不甚理想.另外,传统张量分解算法对所有元组数据均一视同仁,采用相同的初始权重值,无法有效区分用户标注的重要特征.
文中的基于特征加权的张量分解算法,提取用户标注的重要特征,在张量分解算法基础上对元组初始权重进行改进,通过不同权重值反映用户的兴趣所在;同时使用相同数据集和评估标准与经典协同过滤算法推荐结果进行了比较,实验结果表明基于特征加权张量分解的标签推荐算法的推荐效果更好.
References)
[1]许棣华,王志坚,林巧民,等.一种基于偏好的个性化标签推荐系统[J].计算机应用研究,2011,28 (7):2573-2579.Xu Dihua,Wang Zhijian,Lin Qiaomin,et al.Personalized tag recommendation system based on preferences[J].Application Research of Computers,2011,28 (7):2573-2579.(in Chinese)
[2]Symeonidis P,Nanopoulos A,Manolopoulos Y.Tag recommendations based on tensor dimensionality reduction[C]∥Proceedings of the 2008 ACM Conference on Recommender Systems.New York,NY,USA:ACM,2008: 43-50.
[3] 孙玲芳,李烁朋.基于K-means聚类与张量分解的社会化标签推荐系统研究[J].江苏科技大学学报(自然科学版),2012,26(6):597-601.Sun Lingfang,Li Shuopeng.Social tagging recommendation system based on K-means cluster and tensor decomposition[J].Journal of Jiangsu University of Science and Technology(Natural Science Edition),2012,26(6):597-601.(in Chinese)
[4] 乔绿茵,张敏.我国基于Folksonomy的标签推荐方法研究综述[J].信息资源管理学报,2012(4):41 -46.Qiao Lvyin,Zhang Min.Review of tag recommendation method on folksonomy in China[J].Journal of Information Resources Management,2012(4):41-46.(in Chinese)
[5] 余金香.Folksonomy及其国外研究进展[J].图书情报工作,2007,51(7):38-74.Yu Jinxiang.Folksonomy and related research progress in some advanced countries[J].Library and Information Service,2007,51(7):38-74.(in Chinese)
[6] 吴思竹.社会标注系统中标签推荐方法研究进展[J].图书馆杂志,2010,29(3):48-52.Wu Sizhu.Research on tag recommendation methods in the social tagging system[J].Library Journal,2010,29(3):48-52(in Chinese)
[7]刘志丽.基于内容的社会标签推荐技术研究[D].哈尔滨:哈尔滨工程大学,2012.
[8] 靳延安,李玉华,刘行军.不同粒度标签推荐算法的比较研究[J].计算机应用研究,2012,29(2): 504-509.Jin Yan'an,Li Yuhua,Liu Xingjun.Comparative research on different grain-based tag recommendation algorithm[J].Application Research of Computers,2012,29(2):504-509.(in Chinese)
[9]司宪策.基于内容的社会标签推荐与分析研究[D].北京:清华大学,2010.
[10] 丛维强.基于数据仓库和语义分析的社会标签推荐技术研究[D].江苏镇江:江苏科技大学,2014.
[11] 李贵,王爽,李征宇等.基于张量分解的个性化标签推荐算法[J].计算机科学,2015,42(2):267-273.Li Gui,Wang Shuang,Li Zhengyu,et al.Personalized tag recommendation algorithm based on tensor decomposition[J].Computer Science,2015,42(2): 267-273.(in Chinese)
[12]王金辉.基于标签的协同过滤稀疏性问题研究[D].合肥:中国科技大学,2011.
[13] 万朔.基于社会化标签的协同过滤推荐策略研究[D].成都:电子科技大学,2010.
[14] 张兵.基于标签的协同过滤推荐技术的研究[D].杭州:浙江大学,2011.
[15]Symeonidis P,Nanopoulos A,Manolopoulos Y.A unified framework for providing recommendations in social tagging systems based on ternary semantic analysis[J].IEEE Transactions on Knowledge and Data Engineering,2010(22):1-14.
[16]Sarwar B,Karypis G,Konstan J et al.Item-based collaborative filtering recommendation algorithms[C]∥Proceedings of the 10th International Conference on World Wide Web.New York:ACM,2001:285-295.
[17]Linden G,Smith B,York J.Anlazon.com recommendations:item-to-item collaborative filtering[J].IEEE Internet Computing,2003,7(1):76-80.
[18]Harvey M,Baillie M,Ruthven I,et al.Tripartite hidden topic models for personalised tag suggestion[M]∥Advances in Information Retrieval.Berlin Heidelberg: Springer,2010:432-443.
[19]Jaschke R,Marinho L,Hotho A,et al.Tag recommendations in folksonomies[M]∥Knowledge Discovery in Databases:PKDD 2007.Berlin Heidelberg: Springer,2007:506-514.
[20]Lee S O K,Chun A H W.A web 2.0 tag recommendation algorithm using hybrid ANN semantic structures[J].International Journal of Computers,2007,1:49 -58.
(责任编辑:童天添)
Tag recommendation algorithm based on feature weighting and tensor decomposition
Sun Lingfang1,Feng Zunchang2
(1.College of Computor Science and Technology,Taizhou University,Taizhou Jiangsu 225300,China)
(2.School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang Jiangsu 212003,China)
Aiming at the problem that the tag recommendation system is extremely sparse,the tensor model of weighted tuble set is constructed by extracting the key features of the tagging process and calculating the initial weights of the elements;Then,we use the high order singular value decomposition(HOSVD)to reduce the dimension of the tensor model,So that it can improve the recommendation efficiency;The MovieLens data set is used to simulate the tag recommendation algorithm based on feature weighting tensor decomposition.The experimental results show that the tag recommendation algorithm based on feature weighting tensor decomposition is better than the traditional algorithm.The proposed method can effectively deal with the data sparsity problem and improve the recommendation effect.
folksonomy;tag recommendation;tensor decomposition;feature weighting;HOSVD
TP39
A
1673-4807(2015)06-0574-06
10.3969/j.issn.1673-4807.2015.06.012
2015-08-04
泰州市科技支撑项目(TS201515);教育部人文社科基金资助项目(10YJAZH069);江苏省“六大人才高峰”项目(2012XXRJ-013)
孙玲芳(1963—),男,博士,教授,研究方向为计算机应用技术.E-mail:slf0308@163.com
孙玲芳,冯遵倡.基于特证加权张量分解的标签推荐算法研究[J].江苏科技大学学报(自然科学版),2015,29(6):574-579.
猜你喜欢
数学物理学报(2021年1期)2021-03-29
科学大众(2020年23期)2021-01-18
五邑大学学报(自然科学版)(2020年4期)2020-12-09
汽车观察(2019年2期)2019-03-15
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
山西大同大学学报(自然科学版)(2016年2期)2016-12-12
中国卫生(2016年5期)2016-11-12
公民与法治(2016年10期)2016-05-17
少儿科学周刊·少年版(2015年2期)2015-07-07
