
基于哈希编码学习的图像检索方法
2015-01-17 02:07沈继锋于化龙胡春龙
江苏科技大学学报(自然科学版) 2015年6期
左 欣,沈继锋,于化龙,高 尚,徐 丹,胡春龙
(1.江苏科技大学计算机科学与工程学院,江苏镇江212003)
(2.江苏大学电气信息工程学院,江苏镇江212013)
基于哈希编码学习的图像检索方法
左 欣1,沈继锋2,于化龙1,高 尚1,徐 丹1,胡春龙1
(1.江苏科技大学计算机科学与工程学院,江苏镇江212003)
(2.江苏大学电气信息工程学院,江苏镇江212013)
针对传统的位置敏感哈希编码低效的问题,提出一种监督学习框架下基于正交子空间的判别投影哈希函数学习的海明编码方法.该方法首先根据特征值的能量分布进行子空间分解,其次基于Fisher判别分析准则,利用样本的分布信息学习一组最佳投影的哈希函数,实现原始特征空间向海明空间的紧致嵌入,最终生成一组紧凑且具有判别性的二进制编码,并用于图像检索.在公开数据集上的实验结果表明:该算法与其他经典算法相比,具有较好的稳定性,降低了内存消耗并提高了检索的平均准确率.
位置敏感哈希;正交子空间;判别投影学习;视觉字典;空间金字塔
图像数据资源的集中和规模增大给图像检索带来机遇的同时也带来了挑战,相较于传统的基于文本的图像检索管理和查询,其难度很大,很难满足实际要求,因此,基于内容的图像检索(contentbased image retrieval,CBIR)受到很多学者的广泛研究[1].如何有效地描述图像的特征信息,以及采用何种数据结构进行高效索引和快速相似性检索等一系列问题成为了这个方向的研究热点.此外索引的数据结构与查询性能是紧密相关的,可以大致分为精确近邻和近似近邻这两大类方法.前者主要研究如何准确地确定样本点在样本空间中的近邻关系,检索速度相对较慢;而后者主要研究如何设计高效数据结果确定样本点的近似近邻关系,将原始特征空间映射至海明空间,检索速度较快.
当前基于内容的图像检索主要利用图像的低层视觉特征,如颜色、纹理、形状等,来表示图像信息[2],其面临的主要问题是图像低层特征和图像高层语义间存在着语义鸿沟[3],即图像低层特征难以反映图像所蕴含的对象、事件和场景等丰富语义[4].为了解决这个问题,学者们进行了诸多方面的研究,并致力于建立一种有效介于图像低层视觉特征到图像高层语义之间的中间表示,称为中层特征[5].近年来随着计算机视觉的发展,尤其是图像特征、视觉字典法(bag of visual words,BoVW)[6]的提出及其应用,使得CBIR日趋实用化.BoVW是一种新颖的中层特征表示,该模型的主要思想是通过图像训练,用大量的局部特征向量聚类生成视觉字典,每幅图像相对于视觉字典都能生成一个码元频率向量,并作为特征用于表示图像.在物体识别领域,BoVW因其突出性能,已成为了目标识别领域的主流方法,受到越来越多的关注,一般在构造视觉字典时采用K-Means算法对特征点聚类,而该算法的每次迭代都要将数据点分配与之最近的聚类中心,因此在数据规模很大的情况下,大规模邻近查找的时间急剧增加,因此,文献[7]中提出一种层次化K-Means(jierarchical K-means,HKM)算法对大规模目标检索实现了进一步优化,提高了字典学习的速度和目标检索的效率.
基于视觉字典的图像检索还涉及高维数据的近邻查找问题,在数据规模较大的情况下,用于高维近邻查找的时间将急剧增加,使得算法效率很低.如果采用传统的索引结构,如R树、K-D树等进行检索,在特征维度较低时性能还比较高效,但当维数不断增加时,它们的搜索性能却随之急剧恶化,有时甚至不如线性搜索[8].文献[9]中首次将倒排序结构引入图像检索领域,该方法在文本检索中被广泛应用.然而该方法随着字典规模的扩大,检索速度会明显降低.文献[10]中提出了词汇树结构来表示视觉词典与索引,在图像维度较低和数据量较小的时候可以达到较好的效果.
文献[11]中提出的LSH算法成功克服了上述“维度灾难”问题,解决了高维特征的近似近邻(approximate nearest neighbor,ANN)搜索问题.然而由于LSH利用随机选取投影面进行哈希,因此算法具有一定的随机性,并且会导致以下两个问题:①存在LSH映射函数的随机性问题,进而随机产生多个哈希表,得出不同检索结果的现象,影响算法的性能;②LSH的随机性会导致内存消耗大,尤其对大规模的数据集.
鉴于上述问题,文中提出一种基于正交特征子空间的判别投影哈希函数学习模型,并将其应用于大规模数据集的图像检索.该方法首先利用特征值分配算法[12]对原始特征空间进行正交分解;其次利用标注图像之间的类别信息对每位哈希编码的投影方向进行学习,并组合各个子空间的二进制编码生成最终的编码;最后进行空间验证,进一步保证了算法的检索效率.经典图像库中的实验结果表明:文中算法与几种经典的算法相比,具有较好的稳定性,在不影响检索速度条件下,有效地提高了检索准确率.
1 位置敏感哈希
位置敏感哈希[13](locality sensitive hashing,LSH)近似查询的索引技术,是目前解决高维向量近似最近邻问题的经典算法,在图像检索等领域有着广泛的应用[14].LSH原理是利用一组基于稳定分布的哈希函数对高维数据进行降维映射建立多个哈希表,在某种相似度量条件下,使得原本空间中距离近的点经过映射操作后能够以较大的概率哈希到同一个桶中,而相距较远的点哈希到同一个桶中的概率很小[15],其数学表示如式(1):
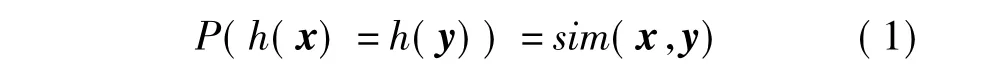
式中:h(x)=sign(wTx+b);sim(x,y)= w为随机超平面;b为随机截距;sign()为符号函数.由于每个哈希函数计算只得到一位编码,因而通常需要利用K比特编码图像特征信息,如式(2):
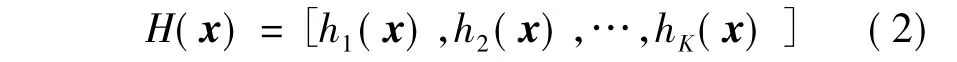
式中,H(x)∈{0,1}K,表示K维海明空间.
2 基于判别投影方向学习的哈希函数
2.1 判别投影哈希
文中基于监督学习框架,利用样本之间的相似度信息来学习一组最优的投影方向,将原始的特征空间Rd映射至海明空间H,F:Rd→H,其中投影函数为
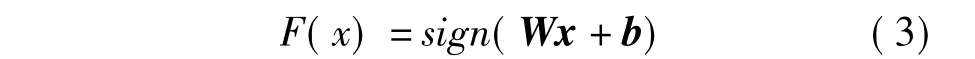
式中:W为优化求解后得到的投影方向的K×d维矩阵;b为K维偏置向量;x为d维图像特征.利用产生的海明距离度量可以刻画两个海明向量间的距离,如下式所示:
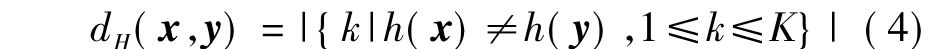
因此,文中利用已有的相似样本标注信息学习最优的投影矩阵W,使得相似样本间的海明距离小,不相似的样本间的海明距离大.
2.2 特征相似度表示
假设每个样本提取的原始特征向量为x∈Rd,P={(x,x')|x,x'∈C}表示相似样本集合,Ν= {(x,x')|x,x'∉C}为不相似样本集合.假设相似样本间的特征用Sx,y∈RD表示,定义特征采样函数fA(x),A为采样的维度序号,如A={1,2,3,10}表示只提取特性向量x的第1,2,3,10维作为特(y)>表示特征第i维的值,刻画了向量间的相似度.
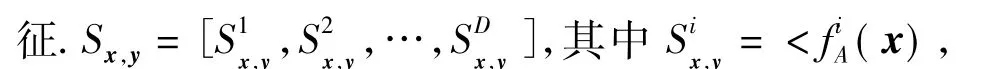
2.3 判别投影矩阵学习
假设给定相似样本对集合P与不相似性样本对集合N,希望通过样本对的信息学习一组最具判别能力的线性超平面,使得相似样本与不相似样本被正确的分类.这组线性超平面W可以通过线性判别准则进行学习,如下式所示:
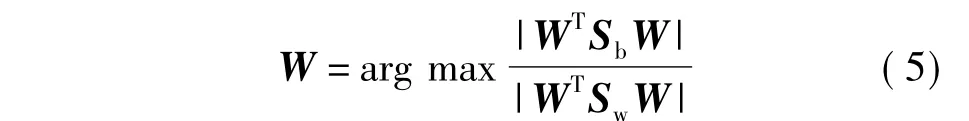
类间散布矩阵Sb、类内散布矩阵Sw的推导为:
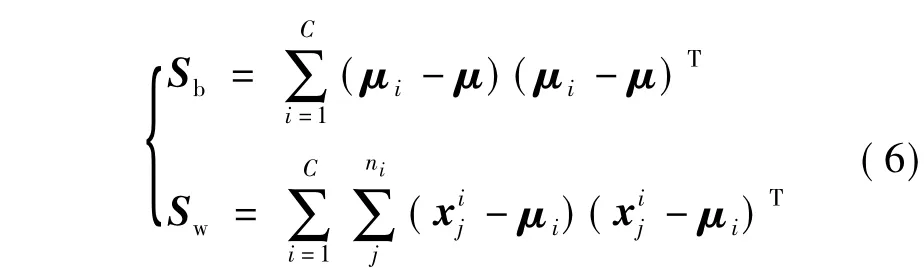
式中:C为类别数;μ为所有样本的均值;μi为第i类样本的均值;ni为第i类样本的数目.Sw与Sb分别对应于类内和类间散度矩阵.因此,通过最优投影方向可以得出其封闭解,如下式所示:
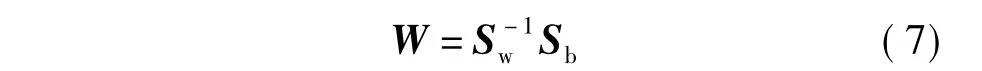
2.4 偏置阈值求解
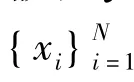
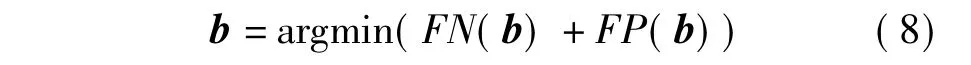
式中:FN(b)=|{(x,x')|min(y,y')+b<0,(x,x')∈P}|;FP(b)=|{(x,x')|max(y,y')+b>0,(x,x')∈N}|.P与N分别表示相似图片对集合与不相似图像对集合.上述目标函数可以利用简单的线性搜索方式求解.
3 基于正交特征子空间聚合哈希
3.1 特征子空间分解
由于特征向量不同维度分布具有不同的方差,因此如何有效地平衡不同维度间的方差是降低量化误差和提高检索性能的关键.文中的方法是通过对特征子空间的方差平衡与最优判别投影方向的学习,来提高检索的精度.假设原始特征空间为C,利用子空间分解成笛卡尔积的形式C=C1×C2×…× Cm,其中Ci表示原始特征空间的第i个子空间.假设原始的特征空间维数为RD,则子空间分解方法为等距划分各个子空间,即Ci=Rd,D=md.为了更好地平衡各个维度的方差,文中利用特征值分配的子空间分解方法[16]对每个维度进行排列,再进行等距划分来实现子空间的正交分解.
3.2 基于正交子空间的哈希编码
文中提出的基于特征子空间的判别哈希学习目标函数如式(9):
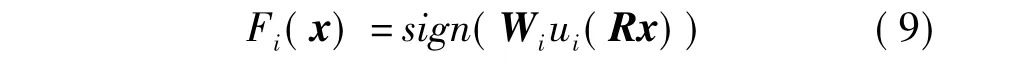
式中:R为随机旋转正交矩阵,用于平衡不同子空间的能量分布[17];ui(x)为子空间量化函数,用于提取原始特征空间的第i个子空间;Wi为第i子空间的最优判别投影方向,可以由式(7)计算获得.最后的二进制编码用每个子空间的编码组合而成,如式(10):如:假设特征空间被划分为两个正交子空间,F(x) =[F1(x) F2(x)]=[010 100],则最后x的二进制编码为010100.
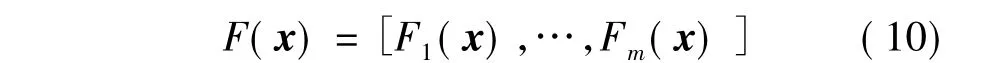
4 算法流程
基于BoWDA的目标检索算法可以按如下步骤执行:
训练阶段如图1a)所示:① 对图片库中所有图像进行兴趣点检测,并利用SIFT方法提取所有点的特征;②利用层次K-means方法进行聚类,构建视觉字典;③基于视觉词典,对图像库图像进行量化编码,生成特征向量;④基于空间金字塔技术构建每个图像的量化特征,得到图像的D维原始特征;⑤ 基于特征值分配的子空间正交分解;⑥基于监督学习框架,利用样本之间的相似度信息,学习最优的投影方向W;⑦利用学习得到的投影矩阵,将所有样本映射到哈希表,建立特征索引.
查询阶段如图1b)所示:①计算查询图像的特征(参见训练阶段的①与③);②基于维度序号采样的特征空间正交分解;③根据式(10)计算查询图像的二进制编码;④采用海明距离对图像进行相似性度量;⑤ 基于RANSAC的空间验证[18];⑥图像检索结果显示.
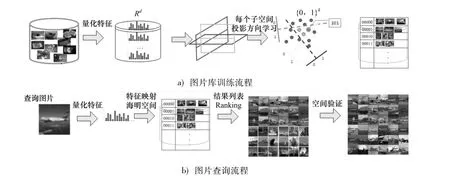
图1 图像检索系统Fig.1 Image retrieval system
5 实验与分析
5.1 实验设置
实验环境为:小型服务器,4个四核酷睿2.8GHz CPU,12GB内存,所有实验在MATLAB环境下运行.
分别在Oxford building 5k图像库[19]和INRIA Holiday图像库[20]上比较文中所提方法与几种传统方法的性能.Oxford building 5k数据库包含5 062幅,含盖11处标志性建筑的1024×768高分辨率图片.INRIA Holiday图像库主要包含存在大量变化场景类型(如自然、人造,以及水和火影响等)的个人假期照片,共500个图像组,每组代表一个明显不同的场景或目标.其中每组的第1幅图像为查询图像,组里其余的图像为正确的检索结果图像.这些假期的图像存在不同程度的旋转、视角、光照亮度差异以及模糊变化等.另外为了验证文中算法在大规模数据下的实验性能,引入Flickr60K数据库作为干扰项.
5.2 实验结果及性能评价
5.2.1 查全率与查准率
实验采用信息检索的标准评价方法.查全率(recall)与查准率(precision)分别反映文中算法检索的全面性和准确性,显然两个指标都越大越好.
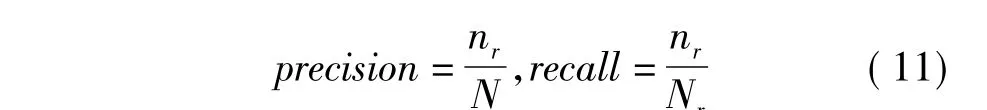
式中:nr为检索得到的正确的相关图像数目;N为检索得到的所有图像;Nr为图像库中与查询图像相关的图像数目.
INRIA Holiday图像库与Oxford building图像库的查全-查准曲线图分别如图2,3.从实验曲线图可以看出:词汇树的结果最差,倒排序方法其次;无论是查全率还是查准率,文中方法与传统方法相比都得到了明显的提高.
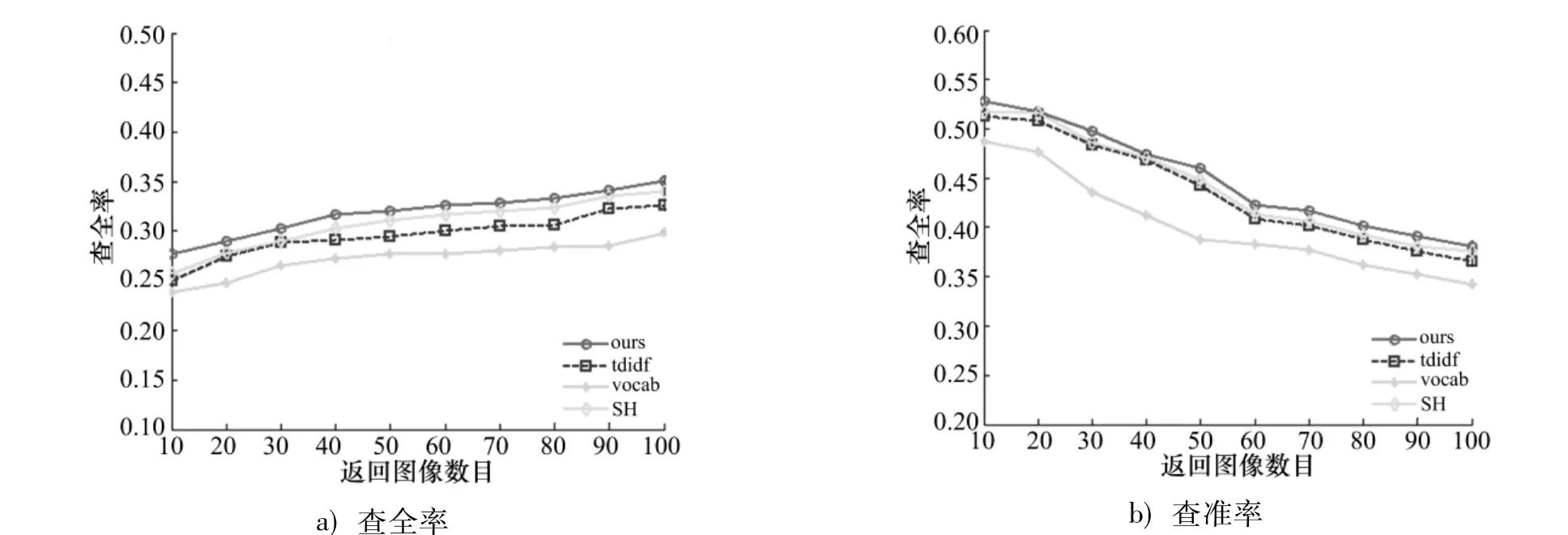
图2 INRIA Holiday图像库查全-查准曲线图Fig.2 Recall and precision picture INRIA Holiday image database
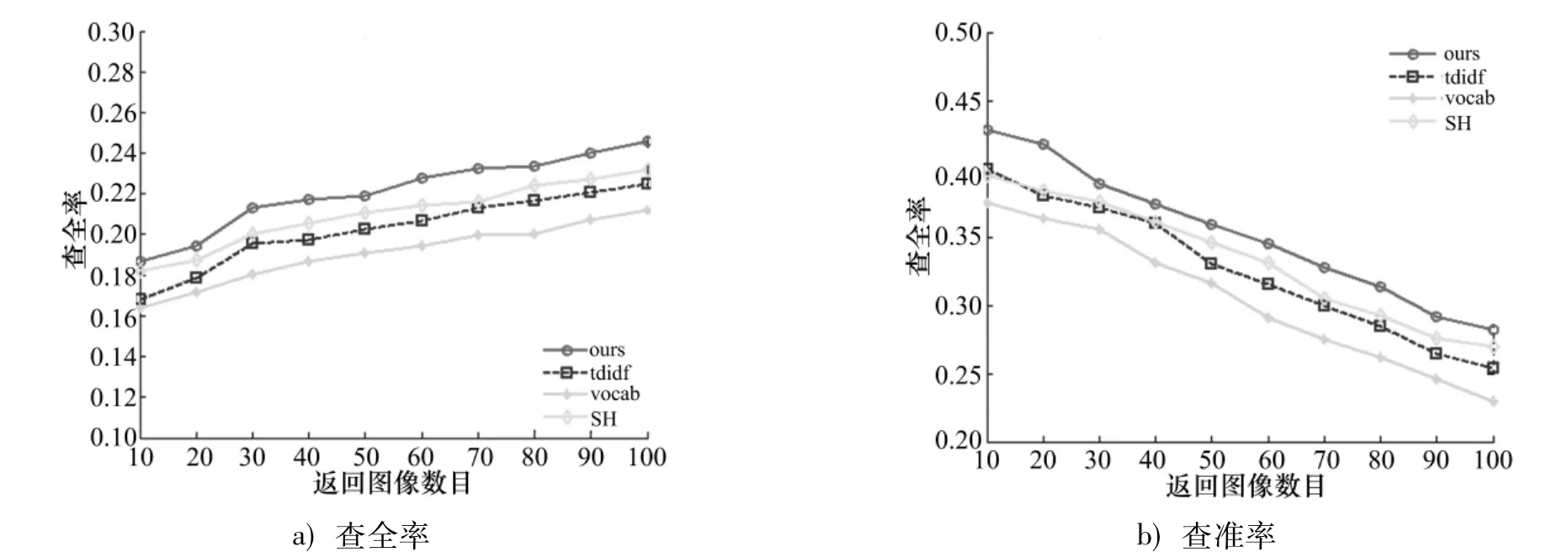
图3 Oxford building图像库查全-查准曲线图Fig.3 Recall and precision picture Oxford building image database
5.2.2 平均精度
文中还采用平均精度来评价图像的检索精度,如下式所示:
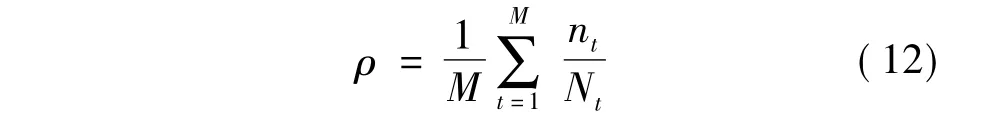
式中:M为图像库中总的图像数目;Nt为图像库中属于同一类图像的数目;nt为被正确检索出的属于同一类图像的数目.
由图4可以看出字典尺寸对平均精度的影响.从图中各组实验的检索结果中发现,随着字典尺寸的增加,平均准确率的结果均越来越好.可以看出,字典经PCA[22]降维后,基于方向学习的LDA平均精度最高.
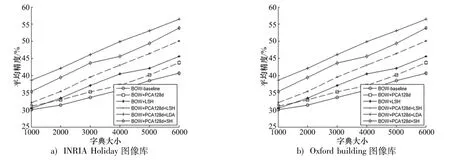
图4 字典生成尺寸对平均准确率的影响Fig.4 Effect of dictionary size on the average precision
由图5可知,编码的长度是影响算法性能非常关键的参数.编码长度的取值越大,算法的随机性越小,算法的平均精度越高,随之检索复杂度也增加.
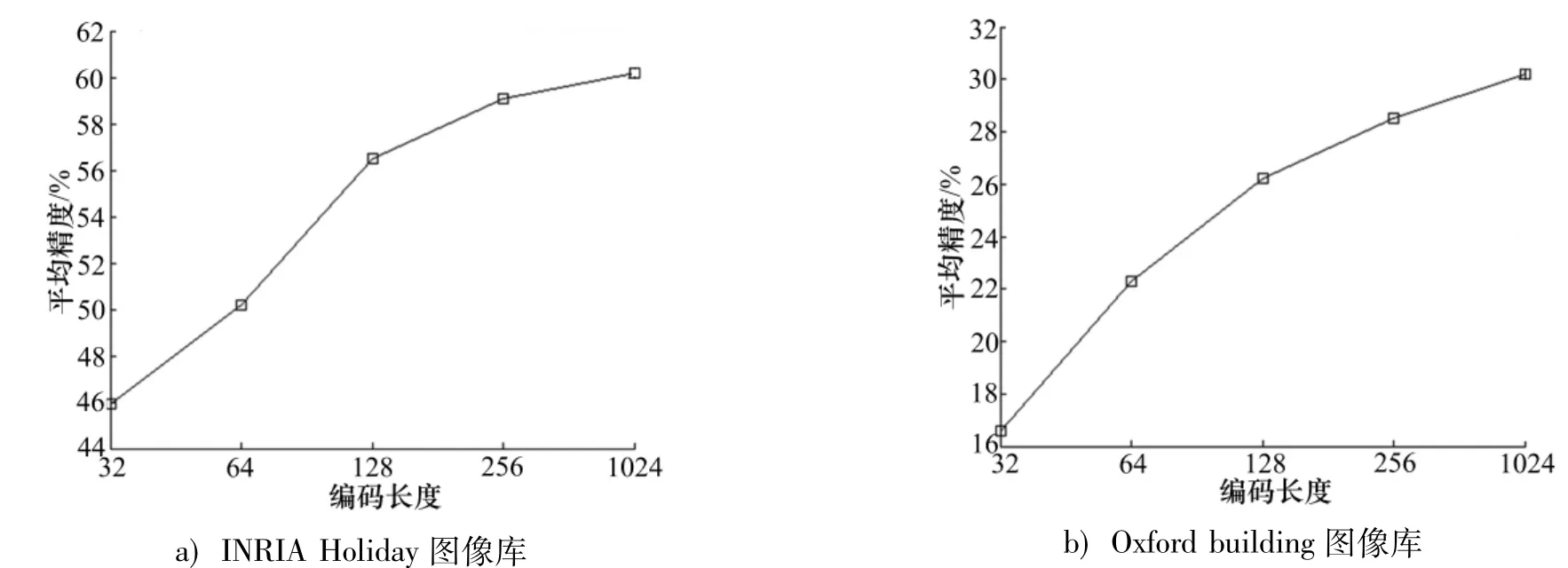
图5 编码长度对平均精度的影响Fig.5 Effect of encodings's length on the average precision
实验以两幅包含相同目标或场景的图像为例,实验结果如图6,7.图中左上带蓝色框的是查询图像,图6a)是从INRIA Holiday图像库检索出来的5幅未经空间验证的相似图像,不难看出,这些候选匹配对中存在错误匹配对,因此影响了检索的质量;图6b)中经过空间几何验证的结果大大减少了误配.图7a)是Oxford库初步查询的结果;图7b)是空间几何验证后的结果.可以看出空间验证可以很好地对查询结果进行重新排序,提高检索的准确率.

图6 INRIA Holiday图像库空间验证Fig.6 Space verification of INRIA Holiday image database

图7 Oxford building图像库空间验证Fig.7 Space verification of Oxford building image database
5.3 讨论
从实验结果可以看出文中方法具有良好的检索性能,验证了算法思路的有效性:首先归功于样本分布信息的判别投影方向学习,该方法利用图像间的相似性,学习最优的判别投影方向,降低了算法的随机性;其次归功于采用了基于正交子空间的分解,提高了编码紧致性;最后采用RANSAC算法对初次检索返回的结果图像加以验证,进一步提高了算法的检索准确率.
6 结论
针对传统的LSH编码低效,以及目前的CBIR算法很少考虑图像像素点的空间信息的问题,文中提出了在一种监督学习框架下基于正交子空间的判别投影哈希函数学习的海明编码方法.该方法首先根据特征值的能量分布进行子空间的分解,其次基于Fisher判别分析准则,利用样本的分布信息学习一组最佳投影的哈希函数,实现原始特征空间向海明空间的紧致嵌入,最终生成一组紧凑且具有判别性的二进制编码用于图像检索.公开数据集上的实验结果表明:与其他经典算法相比,该方法具有较好的稳定性及有效性,大大提高了图像检索的平均准确率.
References)
[1] 何佳蓉,苏赋.基于内容的图像检索发展方向的探索[J].信息通信,2015,1:85.
[2]Yilldizer E,Balci A M,Hassan M,et al.Efficient content-based image retrieval using multiple support vector machines ensemble[J].Expert Systems with Applications,2012,39(3):2385-2396.
[3]Kovashka A,Parikh D,Grauman K.Whittlesearch:interactive image search with relative attribute feedback[J].International Journal on Computer Vision,2015,115(2):185-210.
[4]Zhang H,Zha Z J,Yang Y,et al.Attribute-augmented semantic hierarchy:towards bridging semantic gap and intention gap in image retrieval[C]∥ACM International Conference on Multimedia.Barcelona,Spair: ACM,2013:33-42.
[5]Oquab M,Bottou L,Laptev I,et al.Learning and transferring mid-level image representations using convolutional neural networks[C]∥IEEE Conference on Computer Vision and Pattern Recognition.Columbus,OH,United States:IEEE,2014:1717-1724.
[6]Mansoori N S,Nejati M,Razzaghi P,et al.Bag of visual words approach for image retrieval using color information[C]∥Conference on Electrical Engineering.Mashhad:IEEE,2013,1-6.
[7]Yoo D,Park C,Choi Y,et al.Intra-class key feature weighting method for vocabulary tree based image retrieval[C]∥Proceedings of IEEE Conference on UbiquitousRobotsand AmbientIntelligence.Daejeon: IEEE,2012:517-520.
[8]Xu H,Wang J D,Zeng G,et al.Complementary hashing for approximate nearest neighbor search[C]∥Proceedings of IEEE International Conference on Computer Vision.Barcelona:IEEE,2011:1631-1638.
[9]Zobel J,Moffat A.Inverted files for text search engines[J].ACM Computing Surveys,2006,38(2):6-10.
[10]Wang X Y,Yang M,Zhu S H,et al.Contextual weighting for vocabulary tree based image retrieval[C]∥IEEE International Conference on Computer Vision.Barcelona:IEEE,2011:209-216.
[11]Ji J Q,Yan S C,Li J M,et al.Batch-orthogonal locality-sensitive hashing for angular similarity[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2014,36(10):1963-1974.
[12]Philbin J,Chum O,Isard M,et al.Object retrieval with large vocabularies and fast spatial matching[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition.Minneapolis,MN,USA:IEEE,2007,1-8.
[13]Cao Y D,Zhang H G,Guo J.Weakly supervised locality sensitive hashing for duplicate image retrieval[C]∥Proceedings of the 18th IEEE International Conference on Image Processing.Brussels:IEEE,2011: 2461-2464.
[14]Chafik S,Daoudi I,Ouardi H EI,et al.Locality sensitive hashing for content based image retrieval:a comparative experimental study[C]∥Proceedings of the Fifth International Conference on Next Generation Networks and Services.Casablanca:IEEE,2014:38-43.
[15]Kafai M,Eshghi K,Bhanu B.Discrete cosine transform locality-sensitive hashes for face retrieval[J].IEEE Transactions on Multimedia,2014,16(4): 1090-1103.
[16]Ge T Z,He K M,Ke Q F,et al.Optimized product quantization for approximate nearest neighbor search[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Portland,OR,USA: IEEE,2013:2946-2953.
[17]Gong Y C,Lazebnik S,Gordo A,et al.Iterative quantization:a procrustean approach to learning binary codes for large-scale image retrieval[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2013,35(12):2619-2929.
[18] 邱亚辉,李长青,崔有帧.RANSAC算法在剔除图像配准中误匹配点的应用[J].影像技术,2014(4): 46-47.
[19]Philbin J,Chum O,Isard M,et al.Object retrieval with large vocabularies and fast spatial matching[C]∥Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.Minneapolis,MN,USA: IEEE,2007,1-8.
[20]Jegou H,Douze M,Schmid C.Hamming embedding and weak geometry consistency for large scale image search[C]∥Proceedings of the 10th European conference on Computer vision.Marseille,France:Springer,2008:304-317.
[21]Agrawal S,Khatri P.Facial expression detection techniques:based on Viola and Jones algorithm and principal component analysis[C]∥Proceedings of the Fifth International Conference on Advanced Computing&Communication Technologies.Haryana:IEEE,2015.108-112.
(责任编辑:童天添)
Image retrieval method based on hash code learning
Zuo Xin1,Shen Jifeng2,Yu Hualong1,Gao Shang1,Xu Dan1,Hu ChunLong1
(1.School of Computer Science and Engineering,Jiangsu University of Science and Technology,Zhenjiang Jiangsu 212003,China)
(2.School of Electrical and Information Engineering,Jiangsu University,Zhenjiang Jiangsu 212013,China)
We propose a supervised discriminative hash function learning for hamming coding to deal with the inefficiency of classical locality sensitive hashing(LSH)method.Firstly,the method decomposes the subspace according to the energy distribution based on the eigenvalues.Secondly,it makes use of the distribution of samples based on fisher criterion to embed the original feature space into hamming space in a more compact manner,and finally it generated a compact and discriminative binary code for the image retrieval system.Experimental results based on the public dataset demonstrated that our method is superior to other classical methods,which is more stable with less memory cost and also increases the average precision.
LSH;orthogonal subspace;discriminative projection learning;visual bags of words; spatial pyramid
TP391
A
1673-4807(2015)06-0567-07
10.3969/j.issn.1673-4807.2015.06.011
2015-07-01
国家自然科学基金资助项目(61305058);江苏省青年科学基金资助项目(BK20150470,BK20130471,BK20140566,BK20150471);江苏省高校自然科学基金资助项目(15KJB520008);江苏科技大学博士科研启动资金资助项目;校管课题(633301302)
左欣(1980—),女,博士,讲师,研究方向为图像检索、视觉属性学习.E-mail:13952861739@163.com
左欣,沈继锋,于化龙,等.基于哈希编码学习的图像检索方法[J].江苏科技大学学报(自然科学版),2015,29(6):567-573.
猜你喜欢
数学物理学报(2021年1期)2021-03-29
电脑爱好者(2020年20期)2020-10-22
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
小学阅读指南·低年级版(2019年11期)2019-07-01
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
创新作文(小学版)(2016年19期)2016-08-22
读者(2016年14期)2016-06-29
工业设计(2016年8期)2016-04-16
电脑爱好者(2015年13期)2015-09-10
