
结合上下文多维度声学特征组的汉语重音检测*
2014-12-02 03:01:04赵云雪郑世杰
哈尔滨师范大学自然科学学报 2014年3期
赵云雪,张 珑,郑世杰
(哈尔滨师范大学)
0 引言
在语音信号处理领域,韵律模型的研究已经很好地用于英语、法语的语音识别[1-4].近些年,随着研究的不断深入,技术的不断进步,韵律模型也开始逐步地应用到汉语的语音识别领域.特别是基于朗读语篇语料库,语音的韵律特征成为语音识别技术中的研究焦点.
韵律规则是合成语音中的一个不可或缺的部分.在许多西方语言为母语的人眼里,汉语听起来,有声有色、有板有眼、快慢有致,像歌曲一样优美动听.语流中这种由音高、音长、音强和时长等所体现出来的特征,称为“韵律特征”,也叫“超音段特征”[5],它们反映出语音信号不同特性之间的差异.韵律特征主要包括声调、语调、重音和节奏等.声调属于音节层的韵律;语调属于句子层,乃至语篇层的韵律.韵律对合成语音的自然度和可懂读以及是否连贯的影响极大,甚至还会影响语音识别的可理解度.对于同一个音素,由于语境不同,重音的表现也会不同,并且声学特征会表现出很大的差别.通过修改语音数据的声学参数,如基频、音长和音强,可以进行重音和语调的模拟,实现语速和声调的变化.
众所周知,汉语可以分为字、词、短语、句子、段落和篇章等不同部分.相应地,汉语的重音也有与韵律结构相对应的层级结构,可以分为:音节、音步、韵律词、韵律短语和语调单位.从目前语音识别的研究状况来看,我们常常关心词与词之间的或者句子与句子之间韵律层级.关于汉语韵律层级的划分以及韵律划分同句法和语法之间的关系,很多研究者给出了不同的结论.并且,我们也知道人们在进行语言交流时,其交流的语言不仅仅是各个单元的层级结构,还有各个单元的轻重也同样起着非常重要的作用.一般说汉语的重音,是指说话或朗读时读的比较重的音素或短语,因此常常给人一种幻觉,语音的轻重是由气流的强弱产生的.汉语普通话中,一般可以将汉语重音分为:词重音和句重音.所谓词重音,指词的某个音节可分为重轻等级.汉语的语句重音是指一句话里重读的某个音节或词语.韵律的层级结构和重音构成了韵律研究中的两个基本的问题.
现有的研究中,大部分都是基于大规模语料库的统计方法.为了描述韵律特征的结构信息、轻重音以及基频运动的模式,需要一个统一的框架.目前,已有很多这样的描述框架,如 ToBI[6]、TILT[7]、Fujisaki 等人[8]、IViE[9]、C_ToBI[10]等.在构建这些标有韵律信息的韵律库时,完全依靠人工标注这些韵律结构信息和轻重音是十分耗时的和低效的,并且也不准确;还不利于韵律模型在自然语言理解中的应用.因此,人们越来越倾向于利用计算机技术,通过建立模型对韵律进行自动标注.
该研究中将充分利用来自声学(如基频或音高、能量、音强、时长等方面)的信息以及上下文方面的信息,构建汉语重音检测的特征集,使用Weka中的机器学习的方法训练模型,进而对汉语重音进行检测.
该文在第1部分中将详细阐述本研究的国内外研究概况和发展趋势;在第2部分简单介绍ASCDD朗读语篇语料库;在第3部分详细介绍了本文所使用的上下文多维度声学特征组;在第4部分对实验环境进行描述;并对实验结果进行分析;在第5部分,给出我们的实验结果和本研究领域的发展趋势.
1 国内外研究概况和发展趋势
国内研究状况,对于汉语的重音检测技术,胡伟湘等人[11]利用音长和音高声学相关特征,采用基于分类回归树结构的区分度模型,在韵律标注语料库ASCCD上能够达到78%的重音检测正确率.邵艳秋等人[12]又利用神经网络对声学相关特征进行汉语重音检测,能够达到78.4%的正确率.倪崇嘉等人[13]对汉语重音检测做了进一步的研究,利用声学相关特征以及词典语法相关特征对汉语重音进行检测,采用Boosting集成分类回归树对当前音节的声学相关特征以及词典和语法相关特征进行建模,同时还对词典和语法相关特征采用条件随机场方法建模,最后,将Boosting集成分类回归树模型和条件随机场模型加权组合获得识别率更高的混合模型,在ASCCD语料库上能够获得76.3%重音检测正确率.
国外研究状况,对于英语的重音检测技术,Ananthakrishnan等人[14]构建了韵律识别系统,选用耦合隐马尔可夫模型(CHMM)在音节和词层次上对重音进行检测.在基于BURNC语料库重音检测的实验表明,在音节层次或音素层次上达到74.9%英语重音检测正确率.2008年,Ananthakrishnan等人[15]又在上述研究的基础上,在最大后验概率(Maximum A Prior,MAP)框架下,利用BURNC语料库对英语重音进行检测,能够达到86.75%的重音检测正确率.然后,Ananthakrishnan等人[16]仅利用RFC特征和韵律语言模型对英语重音进行检测,在BURNC语料库上能够达到67.7%检测正确率.Sridhar等人[17]在最大熵框架下,利用声学和语法的特征对韵律进行自动标注,在波士顿大学广播新闻语料库和波士顿Derection语料库(Boston Directions Corpus,BDC)上对单个词的重音检测分别能够达到86.0%和79.8%的正确率.Johnson等人[18]利用神经网络和高斯混合模型在BURNC语料库上实验,结果充分表明,对单个词的重音能够达到84.2%检测正确率.Rosenberg等人[19]试验了在2~20 bark上,仅采用能量相关特征,利用分类回归树的C4.5算法对重音进行检测,在BDC语料库上对重音的检测正确率能够达到81.9%.Sun[20]利用 Pitch Target特征,同时结合时长、能量以及一些文本特征构造特征集,采用集成机器学习的Boosting和Bagging方法训练分类器,分别能够达到87.17%和84.26%的重音检测正确率.Hun等人[21]利用声学相关特征和词典语法特征方面的信息,采用神经网络和支持向量机方法建立声学-重音模型和语法-重音模型,并通过加权的方法对声学-重音模型和语法-重音模型进行组合,能够达到89.84%的重音检测正确率.Margolis等人[22]利用 Boosting方法、决策树以及高斯线性分类器对重音进行检测,分别达到 88.0%、86.3%、87.1%的检测正确率.
2 ASCCD朗读语篇语料库
ASCCD朗读语篇语料库(Annotated Speech Corpus of Chinese Discourse)由语篇语料、语音数据和语音学标注信息组成,适用于语言语音研究、语音工程开发和基础汉语普通话教学等领域.语料文本是18篇叙事体、议论体语篇,每篇3~5个自然段,每个自然段500~600个音节,总计9000个音节,共10个发音人,5男5女,分别记为 M001、M002、M003、M004、M005、F001、F002、F003、F004、F005,使用标准普通话,以自然的方式,标准的语速,流畅地朗读语篇.所有语音都经过标注,音段采用SAMPA-C标准标注[23],韵律采用C-ToBI韵律标注系统标注,其标注了音节拼音、声韵母、声调、韵律边界等级以及语句重音信息[24].标记每个韵律单位的重音,共分0、1、2、3级.汉语的重音也是与韵律结构对应的层级结构.韵律词中最重音节重音标为1,次要韵律短语中最重音节重音标为2,主要韵律短语中最重音节重音标为3,0则表示不重读,即正常读音.在本研究中,我们将音节分为轻音、正常读音和重音,不细分它们之间的差别,将韵律词重音和次要韵律短语(MIP)重音看做正常读音,只把主要韵律短语(MAP)重音看作是重读.ASCCD语料库中重音的分布如表1所示.
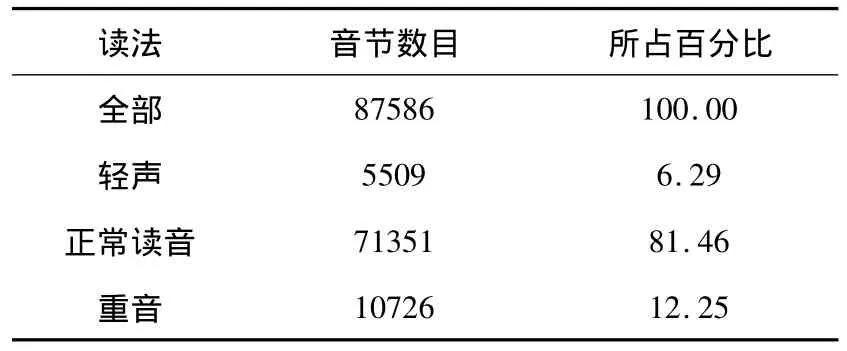
表1 ASCCD语料库中重音的分布
3 基于声学特征相关特征的重音检测
文献[25]和文献[26]表明,时长、强度和基频等声学特征,与重音有很强的相关性.因此,在本文采用时长、基频、音强和能量等相关声学特征对汉语重音进行预测.重音是语音信号的一部分区域,那么,重音的表现也会受到周围环境影响.因此,我们假设基于上下文的声学特征能够提高汉语重音的检测正确率.为了验证我们的假设,我们提取了基频、音强、能量和时长的上下文特征.汉语中单音节词和双音节词所占的比重较高,故本文选取了八个上下文窗口:(1)当前音节前一个音节;(2)当前音节后一个音节;(3)当前音节前两个音节;(4)当前音节后两个音节;(5)当前音节前一个音节和当前音节后一个音节;(6)当前音节前一个音节和当前音节后两个音节;(7)当前音节前两个音节和当前音节后一个音节;(8)当前音节前两个音节和当前音节后两个音节.本文是采用Z-SCORE算法对某些特征进行标准化的.
3.1 对于基频特征,为每一音节计算下列特征
f0_min:当前音节的基频最小值
f0_max:当前音节的基频最大值
f0_mean:当前音节的基频平均值
f0_stdev:当前音节的基频标准差
f0_zMax:当前音节归一化后的基频最大值
norm_f0_min:说话者标准化后当前音节的基频最小值
norm_f0_max:说话者标准化后当前音节的基频最大值
norm_f0_mean:说话者标准化后当前音节的基频平均值
norm_f0_stdev:说话者标准化后当前音节的基频标准差
norm_f0_zMax:说话者标准化后当前音节归一化的基频最大值
delta_f0_min:当前音节基频曲线倾斜度的最小值
delta_f0_max:当前音节基频曲线倾斜度的最大值
delta_f0_mean:当前音节基频曲线倾斜度的平均值
delta_f0_stdev:当前音节基频曲线倾斜度的标准差
delta_f0_zMax:当前音节基频曲线倾斜度归一化的最大值
delta_norm_f0_min:说话者标准化后当前音节基频曲线倾斜度的最小值
delta_norm_f0_max:说话者标准化后当前音节基频曲线倾斜度的最大值
delta_norm_f0_mean:说话者标准化后当前音节基频曲线倾斜度的平均值
delta_norm_f0_stdev:说话者标准化后当前音节基频曲线倾斜度的标准差
delta_norm_f0_zMax:说话者标准化后当前音节基频曲线倾斜度归一化后的最大值
f0_f2b0__zMax:当前音节前的两个音节的归一化的基频最大值
f0_f2b0__zMean:当前音节前的两个音节的归一化的基频平均值
norm_f0_f2b0__zMean:说话者标准化后当前音节前的两个音节的归一化基频平均值
norm_f0_f2b0__zMax:说话者标准化后当前音节前的两个音节的归一化基频最大值
delta_f0_f2b0__zMean:当前音节前的两个音节的基频曲线倾斜度的归一化平均值
delta_f0_f2b0__zMax:当前音节前的两个音节的基频曲线倾斜度的归一化最大值
delta_norm_f0_f2b0__zMax:说话者标准化后当前音节前的两个音节的基频曲线倾斜度的归一化最大值
delta_norm_f0_f2b0__zMean:说话者标准化后当前音节前的两个音节的基频曲线倾斜度的归一化平均值
汉语中单音节和双音节词所占的比重较高,所以本文选取当前音节前两个音节、一个音节、零个音节和当前音节后两个音节、一个音节、零个音节这样八个上下文窗口,同计算当前音节前的两个音节的上下文相关特征一样,也计算了其他7个上下文窗口的基频类似特征.
3.2 对于音强特征,为每一音节计算下列特征
I_min:当前音节的音强最小值
I_max:当前音节的音强最大值
I_mean:当前音节的音强平均值
I_stdev:当前音节的音强标准差
I_zMax:当前音节归一化后的音强最大值
norm_I_min:说话者标准化后当前音节的音强最小值
norm_I_max:说话者标准化后当前音节的音强最大值
norm_I_mean:说话者标准化后当前音节的音强平均值
norm_I_stdev:说话者标准化后当前音节的音强标准差
norm_I_zMax:说话者标准化后当前音节的音强最大值
delta_I_min:当前音节音强曲线倾斜度的最小值
delta_I_max:当前音节音强曲线倾斜度的最大值
delta_I_mean:当前音节音强曲线倾斜度的平均值
delta_I_stdev:当前音节音强曲线倾斜度的标准差
delta_I_zMax:当前音节音强曲线倾斜度归一化的最大值
delta_norm_I_min:说话者标准化后当前音节音强曲线倾斜度的最小值
delta_norm_I_max:说话者标准化后当前音节音强曲线倾斜度的最大值
delta_norm_I_mean:说话者标准化后当前音节音强曲线倾斜度的平均值
delta_norm_I_stdev:说话者标准化后当前音节基频曲线倾斜度的标准差
delta_norm_I_zMax:说话者标准化后当前音节音强曲线倾斜度归一化的最大值
I_f2b0__zMax:当前音节前的两个音节的归一化的音强最大值
I_f2b0__zMean:当前音节前的两个音节的归一化的音强平均值
norm_I_f2b0__zMean:说话者标准化后当前音节前的两个音节的归一化音强平均值
norm_I_f2b0__zMax:说话者标准化后当前音节前的两个音节的归一化音强最大值
delta_I_f2b0__zMean:当前音节前的两个音节的音强曲线倾斜度的归一化平均值
delta_I_f2b0__zMax:当前音节前的两个音节的音强曲线倾斜度的归一化最大值
delta_norm_I_f2b0__zMax:说话者标准化后当前音节前的两个音节的音强曲线倾斜度的归一化最大值
delta_norm_I_f2b0__zMean:说话者标准化后当前音节前的两个音节的音强曲线倾斜度的归一化平均值
同计算当前音节前的两个音节的上下文相关特征一样,也计算了其他7个上下文窗口的音强类似特征.
3.3 对于能量特征,为每一音节计算下列特征
bark__mean:当前音节500~2000 Hz频率范围内能量的平均值
bark__zMax:当前音节500~2000 Hz频率范围内能量归一化的最大值
bark__max:当前音节500~2000 Hz频率范围内能量的最大值
bark__stdev:当前音节500~2000 Hz频率范围内能量的标准值
bark__min:当前音节500~2000 Hz频率范围内能量的最小值
bark_tilt__stdev:当前音节500~2000 Hz频率范围内的能量与总能量的比值的标准差
bark_tilt__min:当前音节500~2000 Hz频率范围内的能量与总能量的比值的最小值
bark_tilt__mean:当前音节500~2000 Hz频率范围内的能量与总能量的比值的平均值
bark_tilt__zMax:当前音节500~2000 Hz频率范围内的能量与总能量的比值归一化的最大值
bark_tilt__max最大值:当前音节500~2000 Hz频率范围内的能量与总能量的比值的最大值
bark_f2b0__zMean:当前音节前的两个音节的500~2000 Hz频率范围内能量归一化的平均值
bark_f2b0__zMax:当前音节前的两个音节的500~2000 Hz频率范围内能量归一化的最大值
bark_tilt_f2b0__zMax:当前音节前的两个音节的500~2000 Hz频率范围内能量与总能量的比值归一化的最大值
bark_tilt_f2b0__zMean:当前音节前的两个音节的500~2000 Hz频率范围内能量与总能量的比值归一化的平均值
英语重音和荷兰语重音的研究表明:在500 Hz到2000 Hz频带上的能量与重音有密切的联系[13].同计算当前音节前的两个音节的上下文相关特征一样,也计算了其他7个上下文窗口的能量类似特征.
3.4 对于时长特征,为每一音节计算下列特征
duration_duration:当前音节的时长
duration_follpause:当前音节之后的停顿时间
duration_duration_f2b0_zNorm:当前音节前两个音节的时长标准化
同计算当前音节前的两个音节的上下文相关特征一样,也计算了其他7个上下文窗口的时长类似特征.
4 试验及实验结果分析
4.1 实验环境
在汉语语料库ASCCD上,选择F001、F002、F003和F005四个人作为训练集,选择F004一个人作为测试集,在句子层次上训练集与测试集的大小是4∶1,在音节层次上训练集共包含了35060个音节,测试集上共包含了8761个音节,其中重音音节有964个.对于机器学习方法,我们采用WEKA的NaiveBayes分类器,并且使用WEKA的默认设置训练得到.
贝叶斯分类器的分类原理是通过某对象的先验概率,利用贝叶斯公式计算出其后验概率,即该对象属于某一类的概率,选择具有最大后验概率的类作为该对象所属的类.
4.2 实验结果及分析
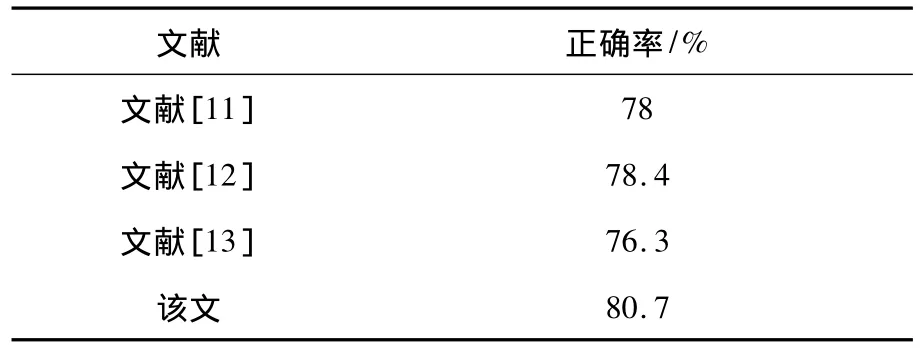
表2 基于声学特征的汉语重音检测正确率
该文和文献[13]最大的不同是选取的上下文窗口.文献[13]认为,汉语在重读时,当前音节之前的音节对重音的影响程度要大于当前音节之后的影响,所以,只选择了当前音节之前的两个音节以及之后的一个音节作为当前音节的上下文窗口.该文实验表明,不同上下文窗口的优化组合能更好检测汉语重音,其结果见表2.

表3 各个声学特征的检测正确率
重音感知中不仅仅有声学特征,还有词典、语法特征.在众多特征中,哪种特征是影响重音感知最重要的因素,不同人有不同的解释.赵元任先生认为,汉语重音特征表现为音域加宽、音程加大,其次才是气流加强[27].林茂灿等人认为,汉语重音最重要的特征是音长增加,而音强的作用不是想象中那么大[28].沈烔等人则认为,在听辨重音时,时长的作用并不明显,而音高的作用很重要[29].在该实验中,基频、音强、时长和能量四种声学特征之间进行比较可得出,基频是重音感知最重要的因素(见表3).
5 总结与展望
该文基于ASCCD朗读语篇语料库,结合上下文多维度声学相关特征进行汉语重音检测,采用NaiveBayes算法对当前音节及前后音节的声学特征组进行建模,该方法充分利用了当前音节及前后音节的相关特性.实验的结果表明Naive-Bayes分类器具有良好的分类效果.将来,我们要对所用的特征进行简化,尝试使用其他的特征组合,比如语言学特征,并还要探索其他的建模方法和技术以刻画重音的属性.
[1] Gallwitz F,Batliner A,Buckow J,et al.Integrated recognition of words and phrase boundaries[J].Proceedings of the International Conference on Spoken Language Processing,1998(7):2883-2886.
[2] Hirschberg Julia,Swerts Marc.Prosodic cues to recognition errors[J].Proceedings of the Automatic Speech Recognition and Understanding Workshop,1999:345-352.
[3] Hirschberg Julia,Litman Diane,Swerts Marc.Generalizing prosodic prediction of speech recognition errors[J].Proceedings of the International Conference on Spoken Language Processing,2000:615-618.
[4] Hirschberg Julia.Communication and prosody:Functional aspects of prosody[J].Speech Communication,2002,36(1):31-43.
[5] 韩纪庆,张磊,郑铁然.语音信号处理[M].北京:清华大学出版社,2004.
[6] Silverman K,Beckman M,Pitrelli J,et al.ToBI:A standard for labeling English prosody[C].//Proceedings of the 1992 international conference on spoken language processing,1992(2):867-870.
[7] Taylor P.The TILT intonation model[J].Proceedings of the International Conference on Spoken Language Processing Sydney.Australia,1998(4):1383-1386.
[8] Fujisaki H,Hirose K.Modeling the dynamic characteristics of voice fundamental frequency with application to analysis and synthesis of intonation[J]Proceedings of the International Congress of Linguistic.Tokyo,Japan,1982:57-70.
[9] Grabe E,Nolan F,Farrar K.IViE-A comparative transcription system for international variation in English//Proceedings of the International Conference on Spoken Language Processing.Sydney,Australia,1998:1259-1262.
[10] Li Aijun.Chinese prosody and prosodic labeling of spontaneous speech//Proceedings of the Speech Prosody 2002.Aixen-Provence,France,2002:39-46.
[11]胡伟湘,董宏辉,陶建华.等.汉语朗读话语重音自动分类研究[J].中文信息学报,2005,19(6):78-83.
[12]邵艳秋,韩纪庆,刘挺.等.自然风格言语的汉语句重音自动判别研究[J].声学学报,2006,31(3):203-210.
[13]倪崇嘉,张爱英,刘文举.基于声学相关特征与词典语法相关特征的汉语重音检测[J].计算机学报,2011,34(9):1638-1647.
[14] Ananthakrishnan S,Narayanan S.An automatic prosody recognizer using a coupled multi-stream acoustic model and a syntactic-prosodic language model//Proceedings of the International Conference on Acoustics,Speech,and Signal Processing.Philadephia,PA,USA,2005.1-269-1-272.
[15] Ananthakrishnan S,Narayanan S.Automatic prosodic event detection using acoustic,lexical,and syntactic evidence.IEEE Transactions on Audio,Speech,and Language Process,2008,16(1):216-228.
[16] Ananthakrishnan S,Narayanan S.Fine-grained pitch accent and boundary tone labeling with parametric F0 features//Proceedings ofthe InternationalConference on Acoustics,Speech,and Signal Processing.Las Vegas,Nevada,USA,2008.4545-4548.
[19] Sridhar V K R,et al.Exploiting acoustic and syntactic features for automatic prosody labeling in a maximum entropy framework.IEEE Transactions on Audio,Speech,and Language Process,2008,16(4):797-811.
[20] Johnson M H,et al.Simultaneous recognition of words and prosody in Boston University radio speech corpus.Speech Communications,2005,46(3-4):418-438.
[21] Rosenberg A,Hirschberg J.Detecting pitch accent using pitch-corrected energy-based predictors//Proceedings of the Interspeech.Antwerp,Belgium,2007.2777-2780.
[22] Sun Xuejing.Pitch accent prediction using ensemble machine learning//Proceedings of the International Conference on Spoken Language Processing.Denver,Colorado,USA,2002.953-956.
[23] Hun J,Liu Y.Automatic prosodic events detection using syllable-based acoustic and syntactic features//Proceedings of the International Conference on Acoustics,Speech,and Signal Processing.Taipei,Taiwan,China,2009:4565-4568.
[24] Margolis A,Ostendorf M.Acoustic-based pitch-accent detection in speech:Dependence on word identity and insensitivity to variations in word usage//Proceedings of the International Conference on Acoustics,Speech,and Signal Processing.Taipei,Taiwan,Chhina,2009.4513-4516.
[25] Chen Xiaoxia,Li Aijun,Sun Guohua,et al.An application of SAMPA-C for standard Chinese//Proceedings of the International Conference on Spoken Language Processing.Beijing,China,2000.652-655.
[26] Li Aijun.Chinese prosody and prosodic labeling of spontaneous speech//Proceedings of the Speech Prosody 200.Aix-en-Provence,France,2002.39-46.
[27] Pitrelli J F.ToBI prosodic analysis of a professional speaker of American English//Proceedings of the Speech Prosody.Nara,Japan,2004.557-560.
[28] Nenkova A,Brenier J,Kothari A,et al.To memorize or to Predict:Prominence labeling in conversational speech//Proceedings of the HLT-NAACL.Rochester,NY,USA,2007.9-16.
[29]赵元任.语言问题.北京:商务印书馆,1980.
[30]林茂灿.颜景助.孙国华.北京话两字组正常重音的初步试验.方言,1984(1):57-73.
[31]沈炯,Hoek J H.汉语语势重音的音理:简要报告.语文研究,1994(3):10-15.
猜你喜欢
中国人民公安大学学报(自然科学版)(2022年1期)2022-07-20 02:51:14
新疆大学学报(自然科学版)(中英文)(2022年2期)2022-03-27 02:08:08
口腔颌面修复学杂志(2020年5期)2021-01-06 08:18:46
艺术家(2020年5期)2020-12-07 07:49:32
山东交通科技(2020年2期)2020-08-13 09:24:06
电子制作(2017年20期)2017-04-26 06:57:35
语言与翻译(2015年4期)2015-07-18 11:07:45
大众文艺(2015年5期)2015-01-27 11:12:44
湖北科技学院学报(2014年6期)2014-07-12 15:29:55
中国石油和化工标准与质量(2013年7期)2013-04-29 23:13:53
