
语音同一认定中音段长度对基频分析的影响
2022-07-20 02:51刘贻杰李江春陈维娜黄颀涵
中国人民公安大学学报(自然科学版) 2022年1期
刘贻杰, 李江春, 陈维娜, 黄颀涵
(1.中国人民公安大学侦查学院, 北京 100038; 2.法庭科学湖北省重点实验室(湖北警官学院), 湖北武汉 430034)
0 引言
从1962年Kersta[1]首次提出“声纹鉴定”这一概念之后,语音同一认定技术已成功服务于法庭科学[2]。基频是语音同一认定中的一个重要的声学参数[3-5]。说话人通过控制其声带的振动速率,产生不同的音高,振动速率通过声学参数“基频”(通常标记为F0)来表征[6]。基频的生理基础是声带的解剖学特征,而每个人的声带长短、薄厚等均存在一定的差异;同时,后天的发音习惯也存在差异,故可利用基频来对说话人进行鉴别。
LaRiviere[7]对8名志愿者所发元音的基频值和共振峰频率进行测量,并对数据进行分析,认为基频和共振峰频率均能应用于语音同一认定,且两者的价值相当。Jessen[8]等人进行了一项针对说话人在正常朗读、正常对话、大声朗读和大声对话4个条件下基频值变化的研究,发现平均基频会随着音量的提高而升高,另外在朗读模式下,大声朗读的基频个体稳定性明显弱于正常朗读,但在对话模式下未发现明显差异。Nolan[9]通过实验发现了选择音段的长短对个体识别有一定的影响。Labutin[10]等人尝试将基频应用于说话人自动识别系统的训练当中,使用了包括平均值、最大值、最小值、最大值-3%、F0平均下降速度等十几项参数,并对参数的权重作调整,结果发现,随着测量音段的时长增加,相等错误率(EER)下降。上述研究主要针对的是英语、德语等非声调语言,而汉语属于声调语言[11],国内外尚缺乏对汉语普通话基频用于语音同一认定的相关研究。
当前,我国电信网络诈骗案件呈高发态势,嫌疑人往往“只闻其声、不见其人”,需要通过声纹自动识别、语音同一认定来提供关键信息以及证据。研究能够用于语音同一认定的汉语普通话语音声学参数、丰富语音特征指标的评价体系是亟待解决的问题。因此,将汉语普通话基频作为研究对象,在结合国外学者对非声调类语言基频的研究成果基础上,针对汉语普通话的声调语言特性,分别对单音节字、多音节词、句子及语段的基频进行测量及统计分析,研究音段选取长度对汉语普通话基频分析的影响,进而确定基频特征在同一人发音中的稳定性和不同人间的差异性,以期为语音同一认定的检案实践提供参考。
1 实验设计
1.1 录音对象及语料
本实验邀请20名男性志愿者进行录音,分别编号为1~20,相关信息见表1。20名志愿者均能流利地讲出标准的普通话,在录音时健康状况良好,发音正常,无明显沙哑、囊鼻等状况。实验选择的语料是《他和我们四个人一起去无锡市旅游》,该语料基本包含了汉语普通话所有韵母类型。
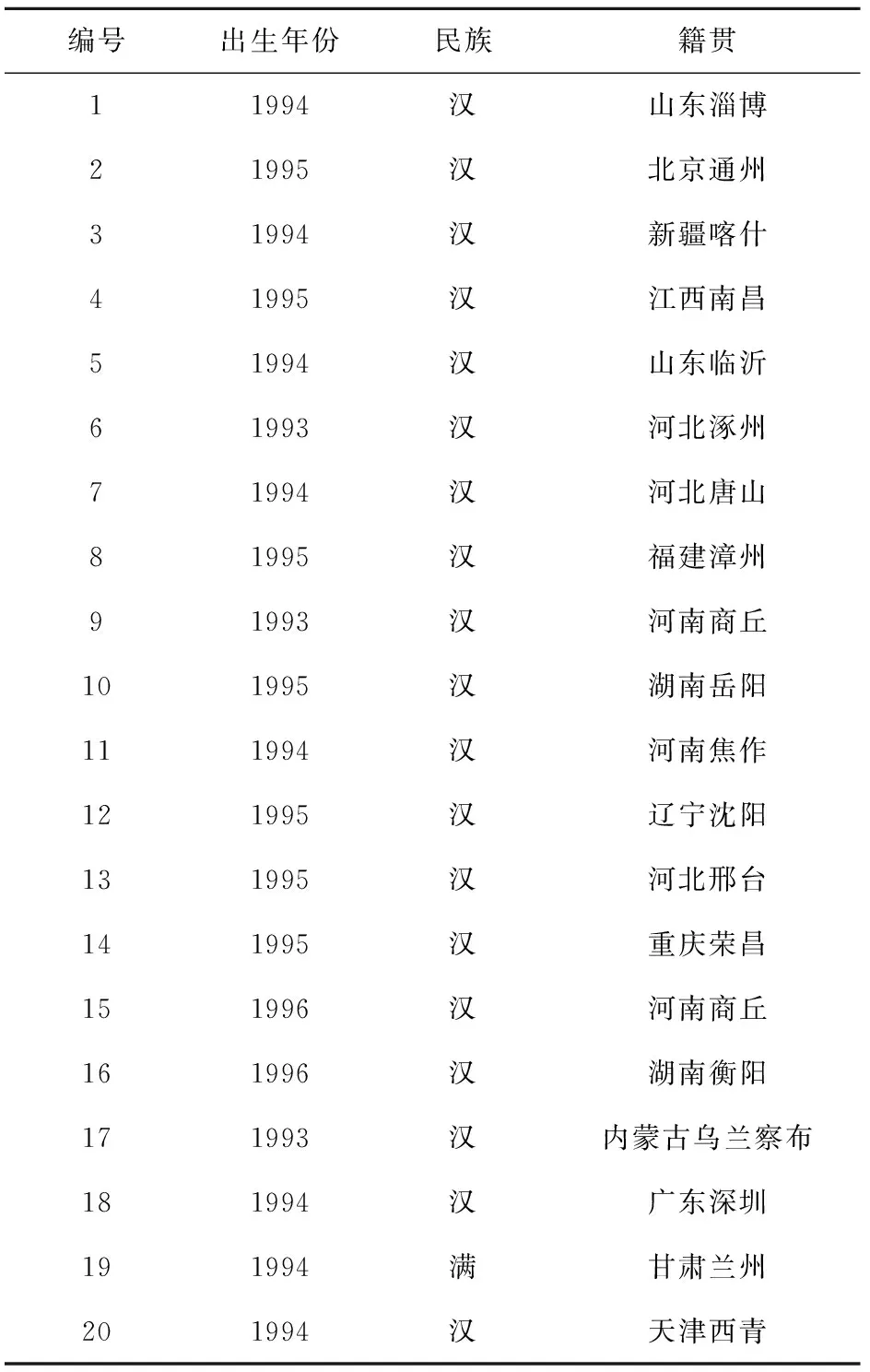
表1 20名志愿者简要信息
1.2 实验设备及软件
1.2.1 录音设备及软件
冠牌iD- 330MU型USB接口麦克风、联想ThinkPad S230u Twist计算机、Adobe Audition 2.0。
1.2.2 分析设备及软件
戴尔G3 3590计算机、Praat v.6.1.09、IBM SPSS Statistics R26.0.0.0 32位版。
1.3 语音样本采集过程
录音环境为专业的语音实验室,门窗关闭,未开空调;录音距离控制在约10 cm。在录音前志愿者先熟悉语料内容,然后正式开始录音。录音参数设置16 000 Hz的采样率和16 bit的采样精度,单声道,wav格式。志愿者按照自己平时的言语习惯进行自然状态下的发声,每人就同一语料录制3遍。录音文件以志愿者的编号来命名。
1.4 基频测量及统计分析
1.4.1 基频值测量
单音节字基频。分别测量20位志愿者在3次录制中的“今”“他”“家”“三”“八”5个单音节字的基频值,记录每次测量的基频数值及发音时长。
多音节词基频。分别测量20位志愿者在3次录制中的“旅游”“毕业于”“四川大学”3个多音节词语的基频值,记录每次测量的基频数值及其发音时长。
句子基频。分别测量20位志愿者在3次录制中的“今天……旅游”“他的……九零”共两个句子的基频均值、最小值和最大值,分别标记为“句一mean”“句一min”“句一max”“句二mean”“句二min”“句二max”,同时记录每次所截取句子的发音时长。
语段基频。分别测量20位志愿者3次录制的完整语料的基频均值、最小值、最大值,分别标记为“语段mean”“语段min”“语段max”,同时记录每次所截取的语段时长。
1.4.2 统计分析
使用方差均值比统计分析个体相对稳定性。计算出同一人3次发音中各单音节字、多音节词的平均时长、基频均值、方差、标准差和方差均值比;以及句子、语段的平均时长、基频均值、最小值、最大值的方差、标准差和方差均值比等。当方差均值比大于10%时表示数据并不稳定、波动性较强,而当方差均值比小于10%时则表明数据较稳定。
使用皮尔逊相关性检验初步统计分析发音个体间差异性[12]。皮尔逊相关性检验用于体现两变量之间的相关性,而检验的显著性(即“Sig值”)用于体现个体间差异;显著性小于0.05时,拒绝原假设,个体间存在差异,反之则不存在差异或差异不明显。
使用欧氏距离综合统计分析句子、语段基频的发音个体间差异性[13]。欧氏距离用于直观体现多维向量间的差异,评价相似度时则用距离加1取倒数,得到一个数值,若大于0.8则相似度非常高,大于0.5小于0.8则中等相似,大于0.5小于0.3则相似度较低,小于0.3则基本不相似。
2 实验结果
2.1 截取音段时长统计
经统计,20位志愿者发单音节字的平均时长在0.100~0.126 s之间,发多音节词的平均时长在0.316~0.636 s之间,句子发音的平均时长在3.184~3.492 s之间,念读语段的平均时长为13.010 s,具体发音时长情况如图1所示。由图1可知,同类音段的语料单元发音时长较为接近,而不同类音段的语料单元发音时长有明显差异,这有助于分析发音时长变化对基频值测量的影响。此外,截取音段时长统计表明:单音节字和多音节词发音时长均较短,故此类音段的基频特征仅能考察到均值这一单一指标;而句子和语段的发音时长较长,语音基频信息丰富,可考察基频均值、最大值和最小值等多项指标。
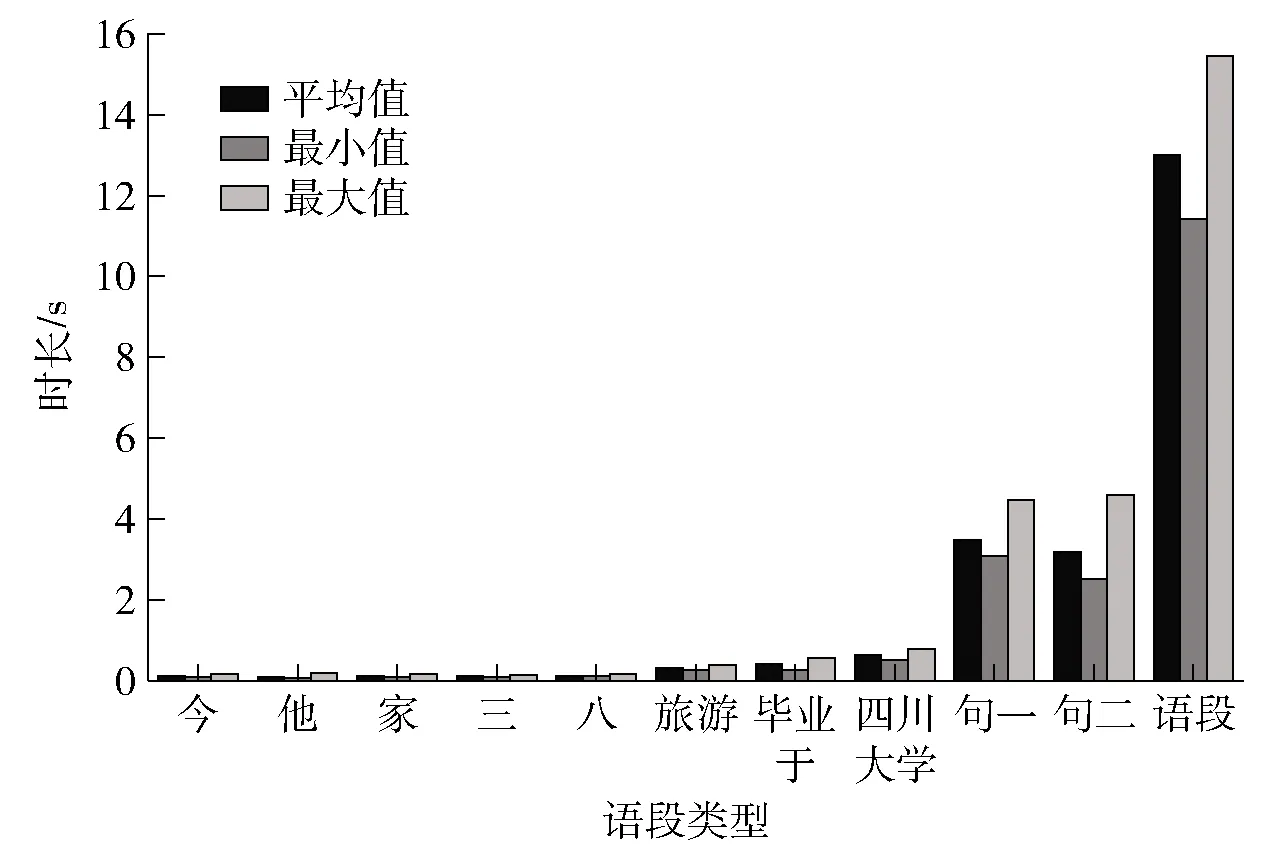
图1 20位志愿者不同音段长度的发音时长
2.2 个体稳定性分析
2.2.1 单音节字基频个体稳定性的统计结果
对于音节“今”,有13个人的基频值方差均值比大于10%,占65%;对于音节“他”,有10个人的基频值方差均值比大于10%,占50%;对于音节“家”,有13个人的基频值方差均值比大于10%,占65%;对于音节“三”,有5个人的基频值方差均值比大于10%,占25%;对于音节“八”,有5个人的基频值方差均值比大于10%,占25%。统计结果如图2所示。
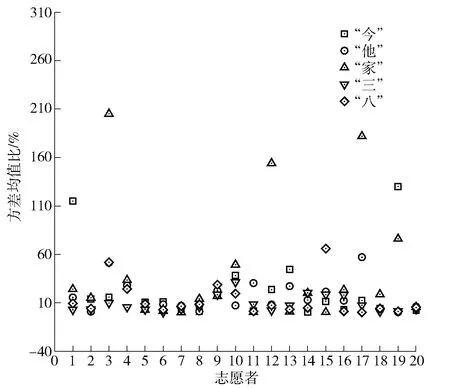
图2 20名志愿者单音节字基频值方差均值比
2.2.2 多音节词基频个体稳定性的统计结果
对于词语“旅游”,有8位志愿者的基频值方差均值比大于10%,占40%;对于词语“毕业于”,有4位志愿者的基频值方差均值比大于10%,占20%;对于词语“四川大学”,有6位志愿者的基频值方差均值比大于10%,占30%。统计结果如图3所示。
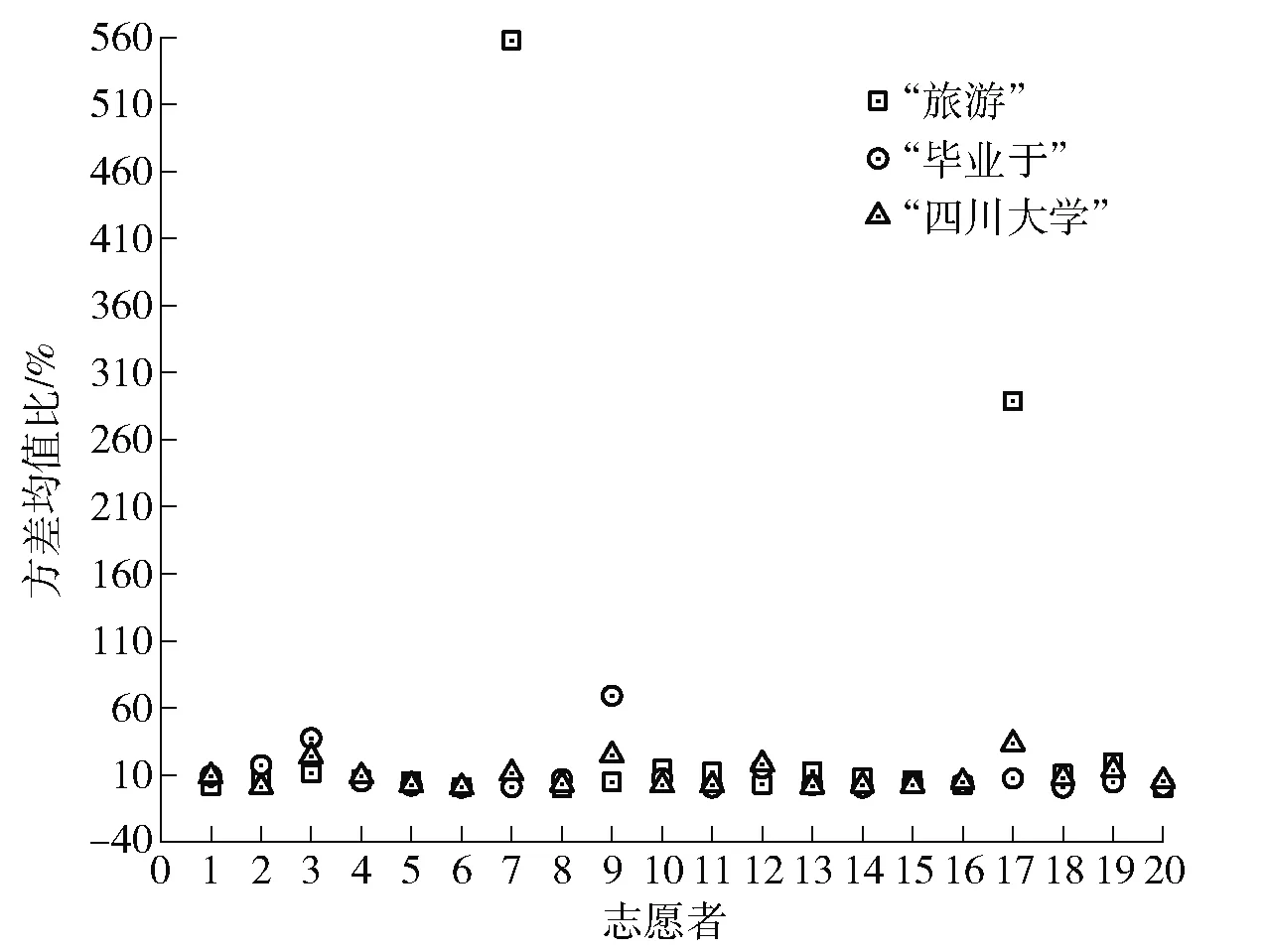
图3 20名志愿者多音节词基频值方差均值比
2.2.3 句子基频个体稳定性的统计结果
对于句一mean,仅有3人基频值的方差均值比大于10%,占15%,而对于句二mean,仅有2人基频值的方差均值比大于10%,占10%。而对于句一min,有10个人的基频值的方差均值比大于10%,占50%,且对于句一max,有16个人的基频值的方差均值比大于10%,占80%;同样,对于句二min,有9个人的基频值的方差均值比大于10%,占45%,且对于句二max,有12个人的基频值的方差均值比大于10%,占60%。统计结果如图4所示。
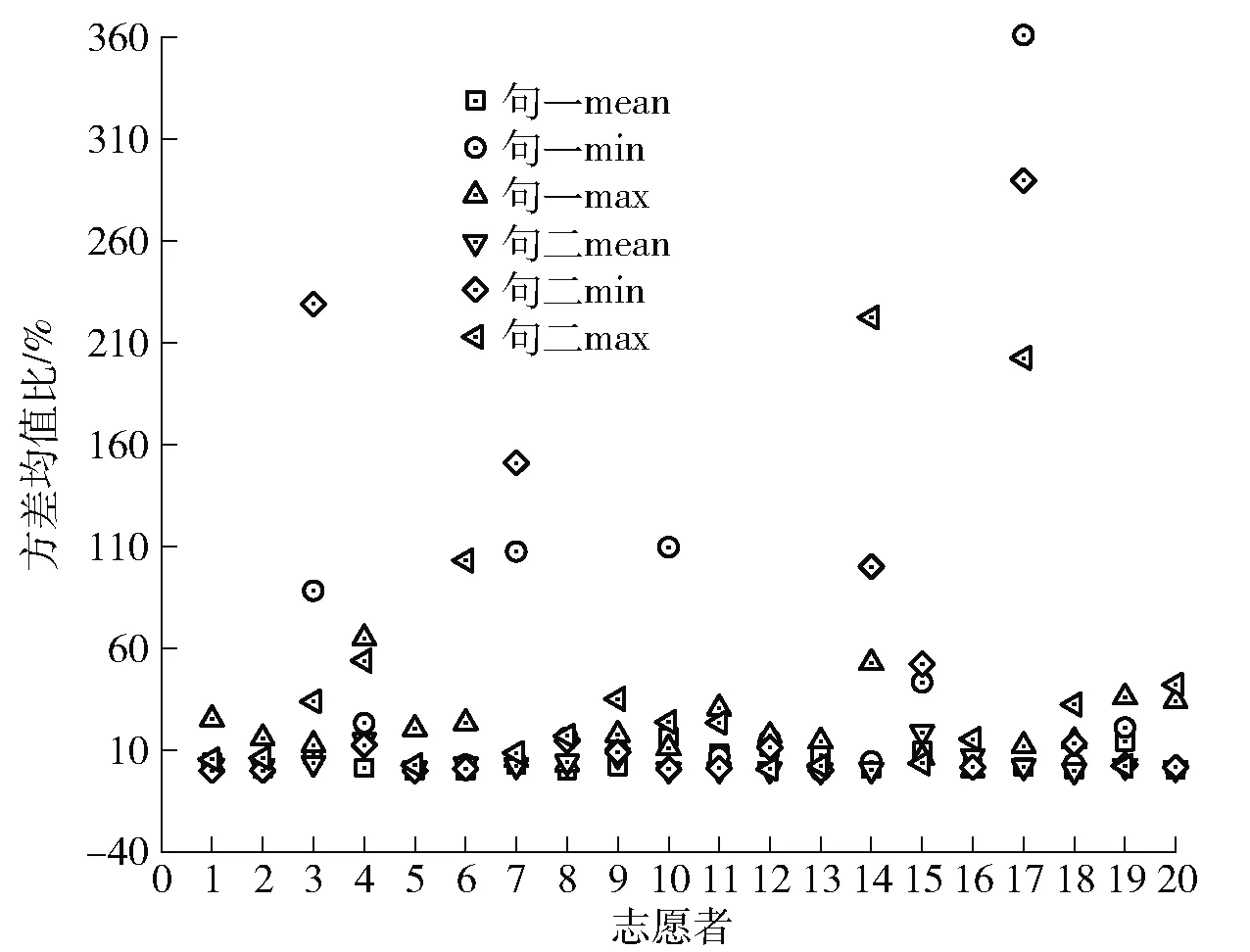
图4 20名志愿者句子基频值方差均值比
2.2.4 语段基频个体稳定性的统计结果
对于语段基频mean,没有志愿者的基频值方差均值比大于10%;对于语段基频min,有7个人的基频值的方差均值比大于10%,占35%;对于语段基频max,有10个人的基频值的方差均值比大于10%,占50%。统计结果如图5所示。
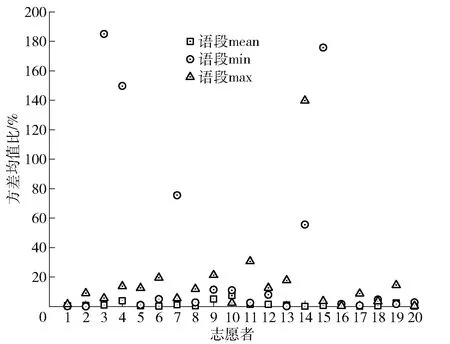
图5 20名志愿者语段基频值方差均值比
通过对不同时长音段的基频个体稳定性进行统计分析发现:单音节字的基频值表现并不稳定,即不具备个体稳定性;多音节词的基频个体稳定性同样较差;而在句子的各项基频参数指标中,仅均值具有较好的个体稳定性,而基频最大值、最小值稳定性均较弱;语段基频均值具有良好的个体稳定性,而语段基频的最大值和最小值稳定性较弱。同时,从图2~图5中可发现随着音段时长的增加,基频均值的稳定性也随之增强,表现为:语段>句子>多音节词>单音节字。
2.3 人间差异性分析
2.3.1 单一基频指标人间差异性统计结果
分别对20位志愿者单音节字、多音节词、句子、语段的单一基频值指标(仅均值、最大值或最小值)进行皮尔逊相关性检验结果如表2~表5所示。

表2 20名志愿者在单音节字基频值间的皮尔逊相关性检验结果

表3 20名志愿者在多音节词基频值间的皮尔逊相关性检验结果

表4 20名志愿者在句子基频值间的皮尔逊相关性检验结果

表5 20名志愿者在语段基频值间的皮尔逊相关性检验结果
由表2的统计分析结果可知:20位志愿者在发音节“今”“他”“家”“三”“八”时的显著性分别为0.233、0.311、0.161、0.255、0.279,均大于0.05,不能拒绝原假设,即单音节字的基频值在发音个体间没有差异性或差异性不大。
由表3的结果可知:20位志愿者在发多音节词“旅游”“毕业于”“四川大学”时的显著性为0.623、0.342、0.418,均大于0.05,不能拒绝原假设,即多音节词基频的个体间没有差异性或差异性不大。
由表4的结果可知:对于句一,志愿者在句一mean、句一min、句一max的显著性分别为0.522、0.228、0.488,均大于0.05;对于句二,志愿者在句二mean、句二min、句二max的显著性分别为0.459、0.894、0.360,均大于0.05,即句子的基频均值、最小值、最大值在单一使用时均不存在个体间差异或存在的差异不明显。
由表5的结果可知:20位志愿者语段mean、语段min、语段max的显著性分别为0.471、0.172、0.507,均大于0.05,不能拒绝原假设,即语段的基频均值、最小值、最大值在单一使用时不存在个体间差异或存在的差异不明显。
上述结果表明,无论选取的音段长或短,仅通过单一基频值指标(包括均值、最小值和最大值)无法区分不同的发音人。
2.3.2 复合基频指标人间差异性统计结果
20位志愿者句子和语段的基频具备均值、最大值和最小值等多项指标,通过计算欧氏距离分别对句子、语段的基频均值、最大值和最小值进行综合分析,统计结果如图6~图8所示。
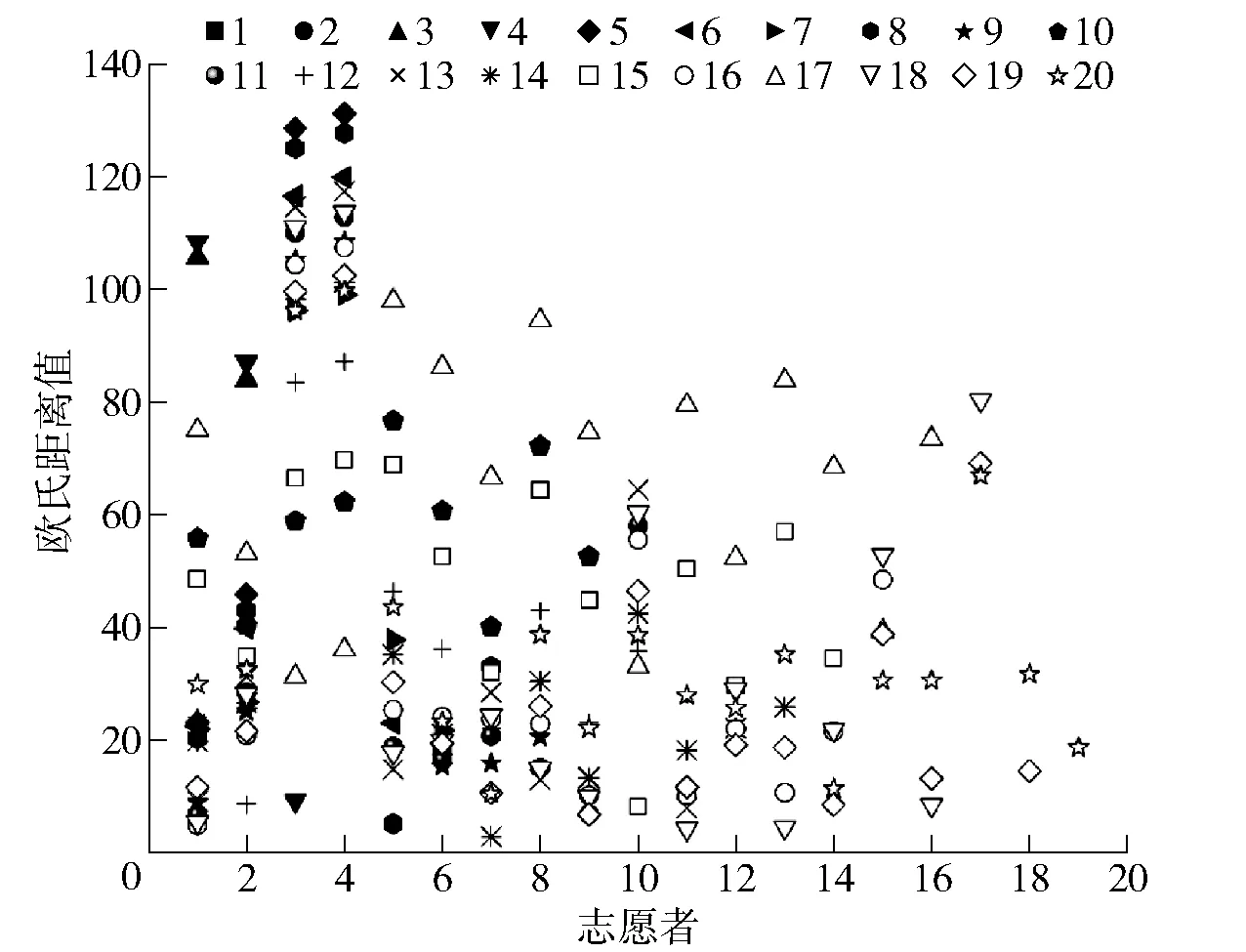
图6 20名志愿者句一基频欧氏距离统计结果
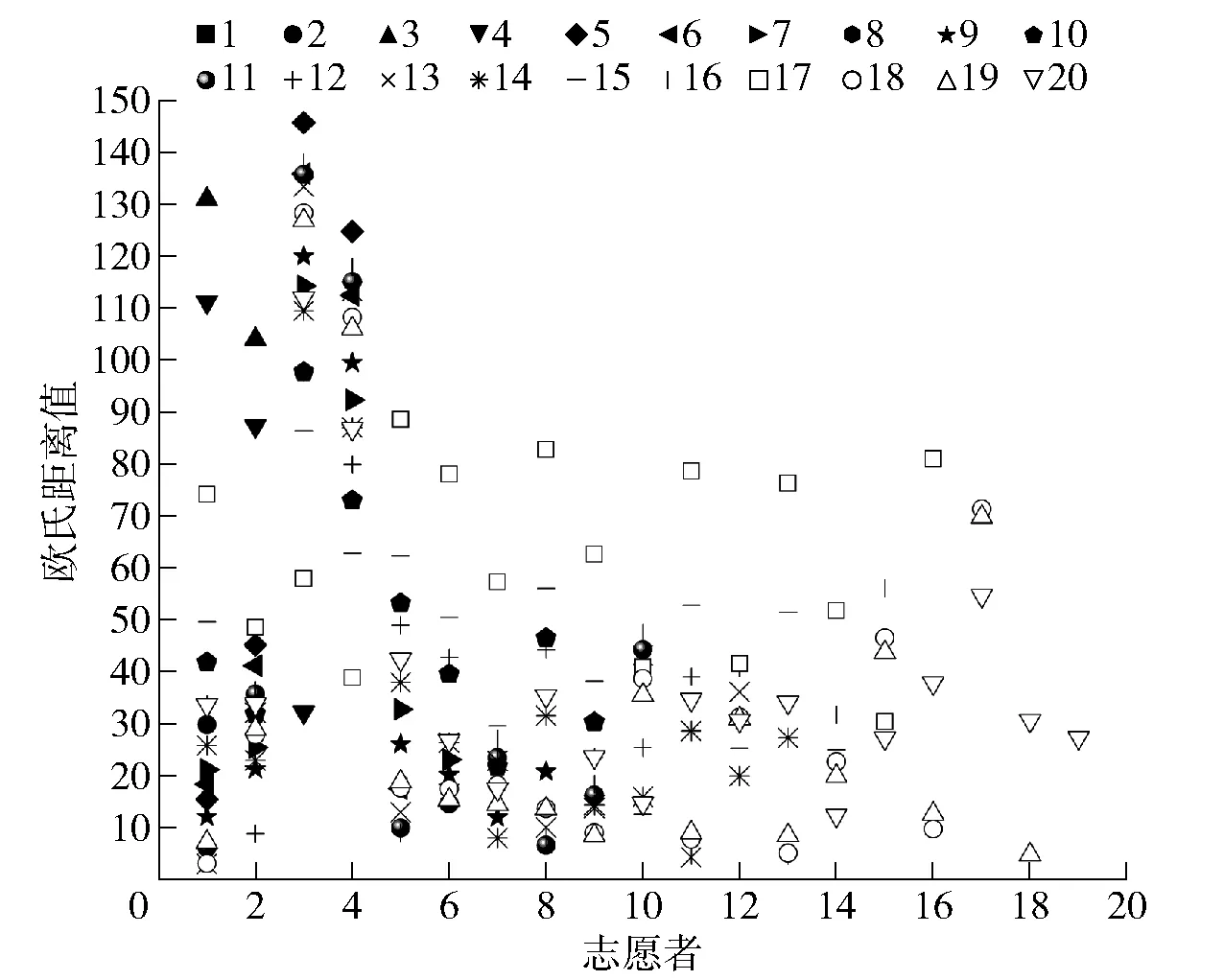
图7 20名志愿者句二基频欧氏距离统计结果
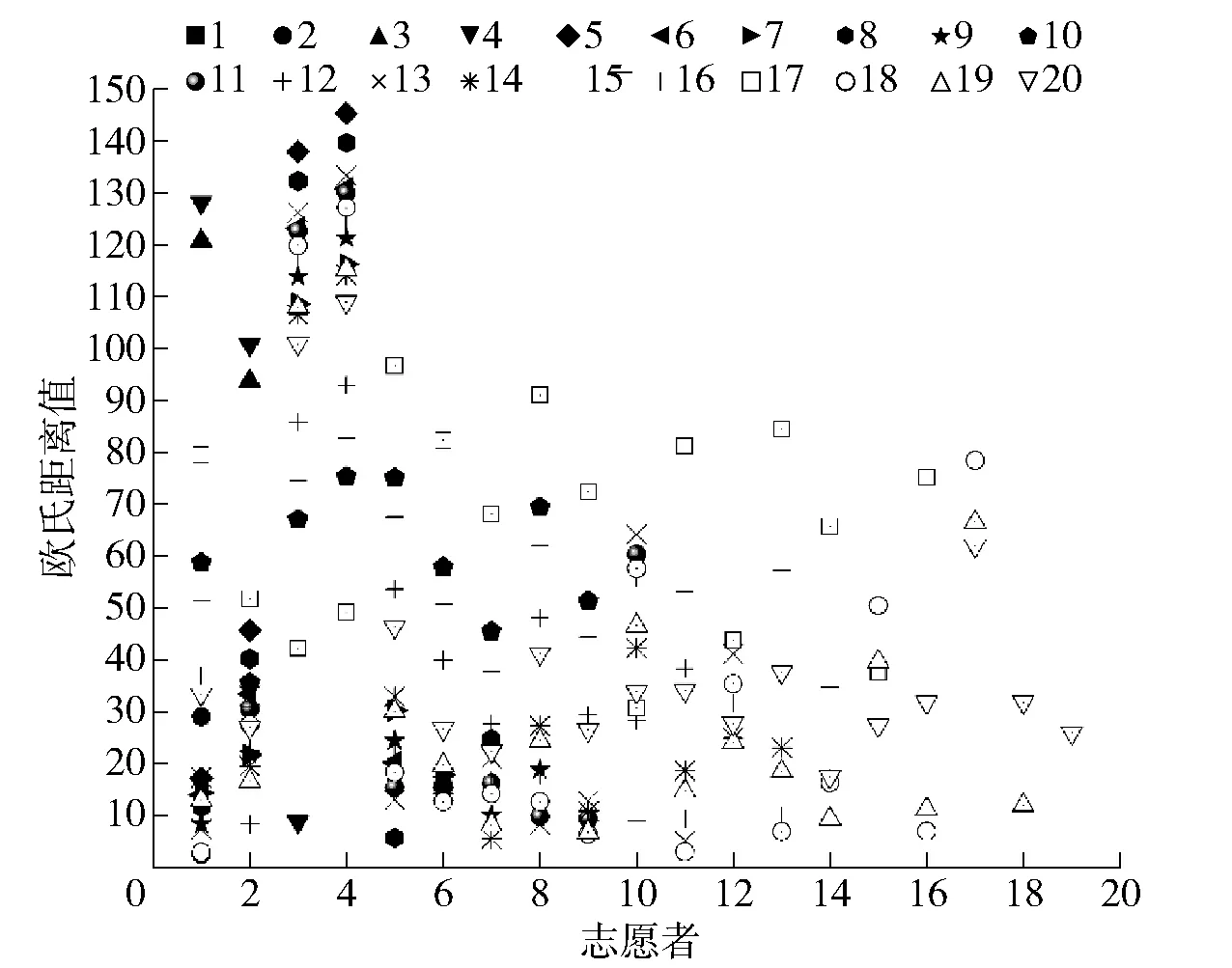
图8 20名志愿者语段基频欧氏距离统计结果
根据图6呈现的统计结果,20名志愿者句一基频的欧氏距离最小为7号志愿者与14号志愿者,其距离值为2.830,相似度换算得0.261,基本无相关性,即20名志愿者两两间均存在较大差异。
根据图7呈现的统计结果,20名志愿者句二基频的欧氏距离最小为1号志愿者与13号志愿者,其距离值为3.111,相似度换算得0.243,基本无相关性,即20名志愿者两两间均存在较大差异。
根据图8呈现的统计结果,20名志愿者语段基频的欧氏距离最小为1号志愿者与11号志愿者,其距离值为2.465,相似度换算得0.289,基本无相关性,即20名志愿者两两间均存在较大差异。
复合基频指标人间差异性统计结果表明,对于句子和语段,综合使用基频的均值、最小值和最大值进行分析,能更好地体现人间差异,实现发音人的个体识别。
3 结论
从20名志愿者的单音节字基频方差均值比结果和皮尔逊相关性检验结果中可以看出:单音节字的基频既不具备个体相对稳定性,也不具备明显的人间差异性,即单音节字的基频不适合应用于语音同一认定中。
从20名志愿者的多音节词基频方差均值比结果和皮尔逊相关性检验结果中可以看出:与单音节字基频相比,多音节词基频的个体稳定性相对有所提高,但人间差异性仍然不明显。因此,多音节词基频同样不适合应用于语音同一认定中。
从20名志愿者的句子、语段基频值方差均值比统计结果和皮尔逊相关性检验结果中可以看出:句子、语段的基频均值个体相对稳定性均较好,可用于语音同一认定中;但仅使用基频均值、最小值或最大值的单一指标,无法区分发音个体,需将基频均值、最小值和最大值结合起来进行综合分析应用于语音同一认定。
综上所述,在语音同一认定实践中,可尝试截取句子、语段或更长的音段来进行基频分析,综合运用基频均值、最大值和最小值能够为检验鉴定提供更为可靠的参数。
猜你喜欢
语文世界(小学版)(2022年4期)2022-05-01
中学生阅读(初中版)(2020年10期)2020-10-28
求知导刊(2019年13期)2019-08-30
考试周刊(2019年9期)2019-01-26
中华活页文选·教师版(2017年12期)2018-01-04
初中生世界·九年级(2017年10期)2017-11-08
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
中学生数理化·八年级数学人教版(2016年5期)2016-08-23
现代语文(学术综合) (2014年10期)2014-11-22
