
基于CCA和数据引力场模型的社交媒体信息置信度评估方法
2014-10-20 08:36张萌李杨沙朝锋
微型电脑应用 2014年9期
张萌,李杨,沙朝锋
0 引言
近些年来,随着互联网的高速发展和社会媒体的快速兴起,社交网络已经成为人们沟通和交流的重要工具[1][2][3]。微博作为社交网络的一种重要形式,在新闻事件的传播过程中发挥着越来越重要的作用。在微博等社交网络中,信息在能够呈病毒式传播。一旦某一条新闻信息进入微博平台,常常能够在短时间内被数以万计的用户转发,从而实现信息的快速传播。但是,由于微博的使用者都是普通用户,他们在新闻的传播过程中,通常缺少辨识真假的能力,这导致了在微博等社交媒体中也常常出现谣言或者是虚假信息被不明真相的用户快速传播的情况。这对于整个社会媒体造成了较大的消极影响。往往一个谣言或者虚假信息本身带有一定的目的性,如果被广泛传播,很容易误导用户,甚至造成比较大的社会影响。进一步,如果社会网络中充斥着虚假信息,则会让用户不再信任社交网络,最终从根本上影响社会媒体和社会网络的健康发展。近几年来,各种社交网络公司都相继提供“辟谣”功能,但是,他们基本上需要通过管理员协助完成,且往往在谣言和虚假信息已经大量传播以后才能发现和阻止,无法避免反应滞后的缺点。因此,如何快速而有效的将谣言和虚假信息止于源头是一个重要而困难的问题[4]。近些年以来更多科研工作者将研究方向关注于信息在互联网上的传播方式等问题[5]。这其中,大部分工作都是基于社交网络平台(例如:twitter、新浪微博[6]等)的数据分析[7][8]。这些工作对于本文的研究起到了重要的借鉴作用。
本文正是在这个背景下,通过分析社交网络的特点,从微博内容信息和微博用户信息两方面进行特征提取的同时,通过利用置信度评估算法,自动实现对于微博信息中谣言以及虚假信息的快速检测。从而实现在不影响社会媒体运转和工作的情况下,准确判断出谣言和虚假信息,并且进一步阻止其传播的目的。具体而言,想要通过计算机自动地判断谣言或者虚假信息,在算法设计方面,我们需要着重考虑信息的特征提取和判别模型选择这两个方面,力求找到更加适合判别真实和虚假信息的方法。相比于其他的信息传播方式,社会媒体的信息传播有着其特殊性。考虑到它具有一定的组织结构,而且我们能够获得传播者的用户相关的更多信息,这都更加有利于对新闻信息的真假做出判断。关于特征提取,本文针对微博具有不同类型的特征,设计了基于 CCA的多视角特征提取方法。同时本文在判别算法设计中受到物理学中引力场的启发,提出了一种新的判别学习模型——数据引力场模型。考虑到社会网络的快速发展导致每天产生海量的微博数据。而其中并非只有新闻信息的传递,更多的内容是无法判断真假的,比如朋友之间的私人聊天对话,本文称之为“闲聊”信息。要完成本文的提出的任务,首先,要把新闻信息从大量的“闲聊”信息中区分出来。因此,如何有效的判别出新闻信息也是本文的重要工作。
1 基于CCA的微博特征提取
微博信息的特征提取是微博置信度检测和评估的第一步工作,也是重要的基础工作。选择合适的特征将有助于提高检测和评判的准确率。在这个过程中,需要从多个视角进行特征的提取(考虑有关微博内容的信息的同时,也需要考虑微博发布者的相关信息),从而保证获取特征的全面性。下面本文将通过以下两部分内容阐述特征提取的过程:1)基于社交网络微博信息的多视角特征选择;2)利用CCA来实现多视角特征的融合。
1.1 基于微博内容及社交网络背景的特征选择
如何选择特征通常取决于要完成的任务和目标。在本文中,我们则需要提取更适合判定虚假信息或是谣言的特征。同时,考虑到社交网络中的信息具有多样化的特点:很多用户也会在社交网络中进行私人聊天等,而这些内容无法简单的进行真实或者虚假的区分。因此,为了实现置信度评估这一目标,首先要将微博信息中关于“新闻”和“闲聊”区分出来。其中,“新闻”表示可以被判定真假的微博信息,“闲聊”表示无法判定真假的微博信息。在社交网络中,每天会有海量的新微博产生,因此,区分微博信息“新闻”和“闲聊”这个任务也不可避免的要借助计算机来自动判别完成。因此,在特征选择的过程中我们不仅要提取那些有利于置信度辨别的特征,也要考虑那些倾向于区分“新闻”和“闲聊”的特征。所以,本文需要从微博内容中提取信息(例如:该微博是否存在超链接等,这种信息有利于本文判断微博内容的置信度),同时,也不能忽略社交网络中的相关信息,因为,用户信息也能够帮助我们对虚假的信息做出更加准确的判定(可以认为一个信用很低或者经常发出虚假消息的人更新的微博信息往往是不被信任的)。考虑到以上因素,本文将从微博内容信息和相关用户信息两个视角来提取相关的特征信息。考虑到特征选择数量较多,部分被选择出来的特征信息如图1所示:
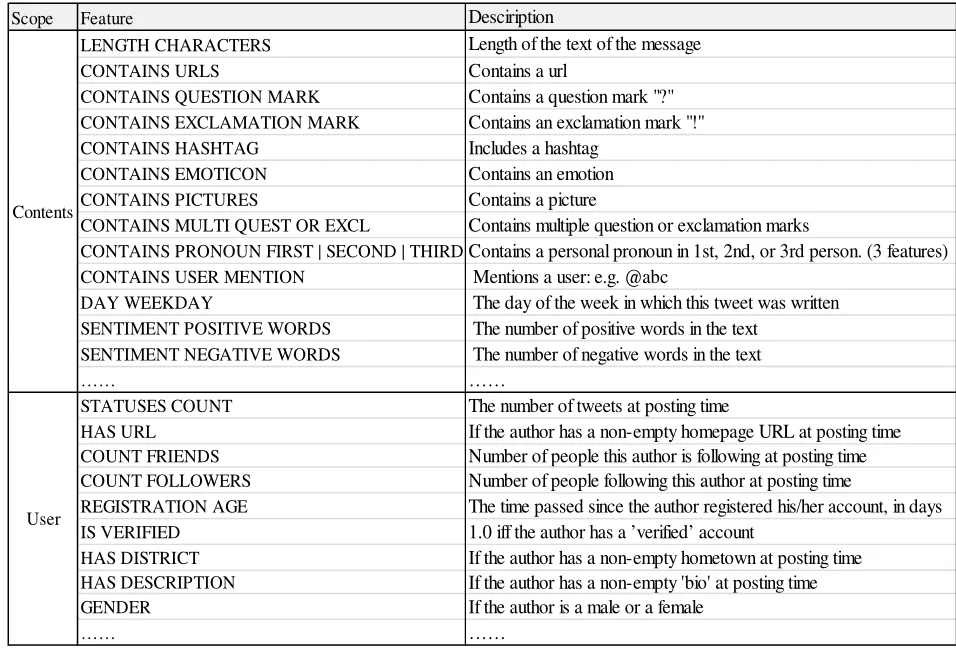
图1 基于微博内容和用户信息的多视角特征信息(部分)
1.2 基于CCA的多视角特征融合
考虑到在判定虚假信息时选择多视角的特征集合,因此,本文面临着特征组合的问题。事实上,简单的加权连接并不是一个好的选择。而CCA[9](典型相关分析)作为一种常用的组合特征维数约减方法,可以将多视角的特征数据映射到同一个特征子空间中并且保证他们之间的相关性最大[10],因此,本文考虑采用 CCA方法来实现多个视角的特征融合。
下面将具体描述基于CCA的多视角特征融合方法。设S为数据样本集,并且S中样本数量为N。令P ∈RDPN, Q ∈RDQN, 为两个不同视角的特征集合,并且通常不同视角特征具有不同的特征维度DP≠DQ,我们做如下定义如公式(1):
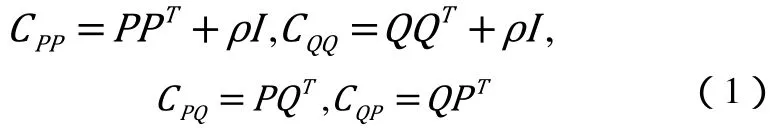
在公式中ρ为正则化因子。本文的目标是为每个视角的特征数据找到一组投影方向,并保证他们之间的相关性最大化。我们用如下公式来表达如公式(2):
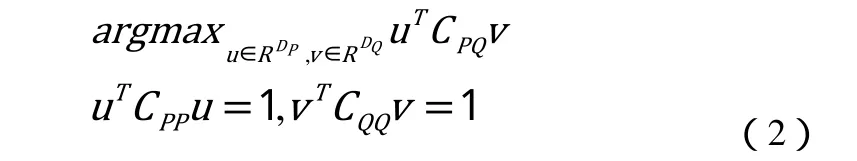
其中u和v表示从各自特征空间投影到同一特征子空间的投影向量。为了获得这组相关性最大的投影向量,我们可以把其转化为特征向量求解问题,通过公式3计算出投影向量{u1, u2…, uD}和{v1, v2…, vD}如公式(3):
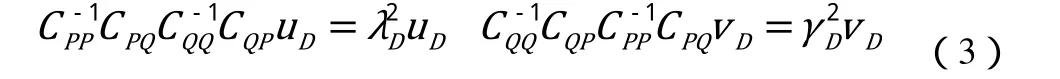
在本文中,我们定义微博内容视角特征为P,用户信息视角的特征为Q,并且通过CCA将这两个视角的数据融合到了同一子空间中。不同视角的数据融合的过程如图 2所示:

图2 基于CCA的多视角特征融合
最终的微博特征FV可以通过下列公式获得公式(4):

2 基于数据引力场的置信度评估算法框架
2.1 数据引力场模型
本文所要实现的置信度判别的目标可以转化为对应的分类学习问题。在我们获得一个有效的数据特征集之后,选择一个合适的学习判别算法也是提高系统性能的关键步骤。本文从物理学中引力重力场模型获得启发,将引力场的思想引入到数据空间中,设计了一种监督学习方法——数据引力场模型。并通过该模型完成信息置信度评估的任务。
为了更好的阐述数据引力场模型,我们首先考虑物理学中的有关万有引力的公式如公式(5)、(6):
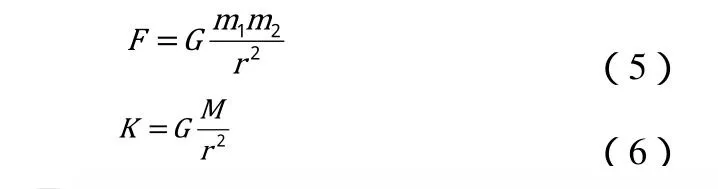
其中,公式5是万有引力公式,m1, m2表示两个物体的质量,r表示两个物体相互之间的距离,而G则是引力常量。公式6则表示质量为M的物体在空间中形成的引力场。事实上,我们也可以把空间中的数据看成一个个不同的物体;不同的样本都拥有自己对应的引力场。假设同类的样本具有相同方向的引力场,而不同的样本具有相反方向的引力场。当需要对一个新的样本进行分类的时候,可以通过计算该样本点在当前位置上所有训练集样本点引力场的叠加,具有较大引力场的类别会把该样本吸引过去,从而最终实现分类的目的。这里给定训练样本S,可以通过以下公式计算样本k的分类结果如公式(7)、(8):
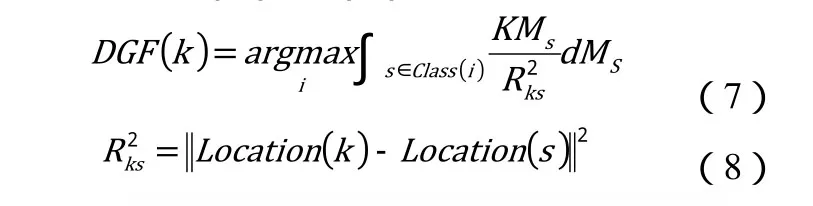
其中,Location(*) 表示样本点的坐标,K是常系数。
与引力场所不同的是,我们需要对每一个训练样本的质量做一个新的定义:数据置信度。如果一个样本的周围空间里都是相同类别的样本,则可以认为这个样本关于这个类别具有较高的置信度。反之,如果它周围都是其他类别的样本,那么就认为其具有较低的置信度,如图3所示:

图3 不同置信度的样本示例
更加清晰解释这个问题,其中,不同类别的样本采用不同形状来区分:左图中展示的是低质量的样本,因为它周围的样本都是其他类别的,所以它具有低置信度;右图展示的是高质量的样本点,因为它周围的样本都是相同类别的,所以它具有高置信度。由此我们通过下列公式定义数据的置信度如公式(9):

这里通过高斯模型来限制周围样本对当前样本的影响权重。
2.2 数据引力场的近似算法
在2.1章节中本文讨论了关于数据引力场分类学习算法的理论模型。然而上述方法需要计算整个数据集,而当数据集规模增大时,该模型的计算开销非常巨大。为此,本文需要为该模型找到快速分类的方法。显然,每个样本的权重与距离的平方成反比,由此我们可以忽略距离较远的一些样本点,只计算离该样本最近的前 N样本的权重,这样就近似的模拟出数据引力场模型并且极大的减小了计算开销。如公式(10)、(11):

其中,TopN(i) 表示与样本最近的N个近邻样本中属于第i类的样本集。这样,我们就基于公式10、公式11为数据引力场算法找到了一个快速计算的近似解法。
2.3 微博信息置信度评估的算法框架
上文中提到,微博平台作为社交网络的重要组成部分,它所承载的功能是十分多样化。虽然微博平台成为了一个重要的新闻和信息的传播途径,但是,实际上,新闻信息在所有微博中所占的比例并不高。大部分的微博信息仍然属于“闲聊”的范畴。而本文要实现微博置信度的评估和预测,首先,就要找到可以评估置信度的新闻类数据。通过 CCA的特征提取算法对微博内容信息和用户信息进行特征提取,然后进入置信度评判系统。通过本文设计的数据引力场的判别模型计算出微博信息属于置信度可评估的信息(“新闻”)还是置信度不可评估信息(“闲聊”)。如果是“新闻”类信息,则通过下一个分类判别机制最终判断出该信息的置信度。在下一章中,本文将通过实验说明基于数据引力场模型和CCA特征提取的算法框架能够获得比较准确的置信度评估结果。因此,本文基于上文中提到的相关算法设计了一个置信度评估的算法框架,如图4所示:
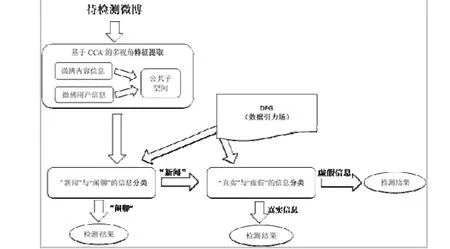
图4 微博信息置信度评估算法框架
3 实验及性能评估
为了验证本文设计的置信度评估方法的性能,我们从新浪微博中提取了233,369条微博以及相关的用户信息。通过过滤如“转发微博”等无内容的信息产生最终的数据集,并进行了相关的标注工作。经过统计,我们发现在这个数据集中,具有传播“新闻”性质的内容占微博总数量的20%-30%。本文依照章节1描述的基于CCA特征融合方法产生了应用于学习模型分类的特征,并且按照图4的流程完成了以下实验过程。
首先,评估本文的算法在区分微博信息是属于“新闻”类别和 “闲聊”的类别的性能,我们在最终提取的特征中选择一部分作为训练集对引力场模型(DFG)进行训练。为了说明本文中算法具有更好的性能,我们选择SVM和KNN算法作为对比。采用相同特征对于微博“新闻”和“闲聊”信息在不同大小的训练集下进行分类判别的实验结果。如图5所示:
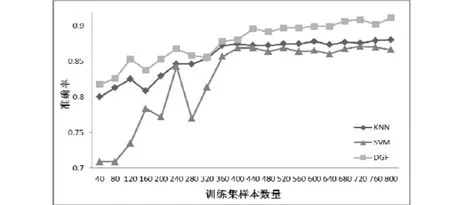
图5 不同算法微博信息进行“新闻”和“闲聊”的分类对比。
从图5中可以看出,随着训练集数量的增高,本文所提出的DGF算法最终能够达到平均91%的准确率,而在同等条件下,KNN算法和SVM算法分别只能达到88%和86%。这证明中本文提出的DFG方法具有更好的分类判别性能。
接下来本文采用同样的方法针对“新闻”类进行置信度评判,判别新闻是“真实”或“虚假”。本文在新闻类的特征集中选择其中部分数据作为训练集。采用3种分类判别算法(KNN算法、SVM算法和DGF算法)进行对比实验得到的结果,如图6所示:
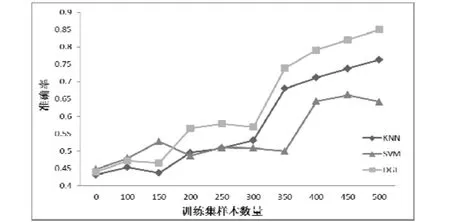
图6 不同算法对“新闻”类信息进行真实和虚假分类对比。
通过该实验可以看出,随着训练样本数量的提升,本文提出的DGF算法仍然取得了较好的结果,平均准确率能够达到85%,明显高于KNN和SVM所获得的判别结果。
如表1所示:
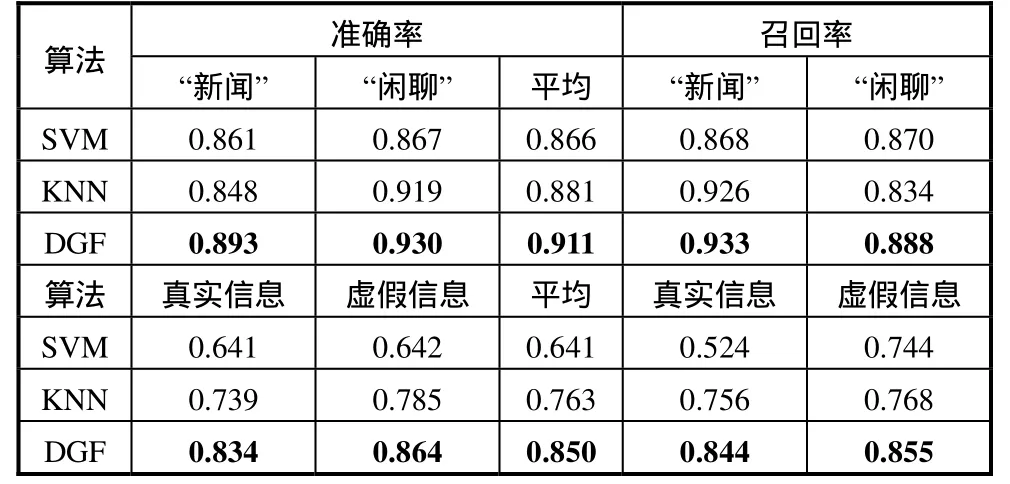
表1.DGF、SVM、KNN分类结果的准确率和召回率。
详细阐释了在这两组分类过程中“新闻”与“闲聊”、“真实”与“虚假”之间采用 DGF、SVM、KNN3种不同算法的实验所获得的准确率和召回率。从表中1可以看到,本文提出的DGF算法相较于其他两种算法有较大的提升,这证明本文的算法能够提供更好的置信度评估。
最后为了说明基于CCA的多维度特征提取的在置信度评判问题上具有更好的效果。我们分别采用仅基于微博内容特征、基于微博用户特征和基于CCA的多视角特征对“新闻”类微博置信度判别做了对比实验,实验均采用DFG作为判别算法。实验结果如图7所示:
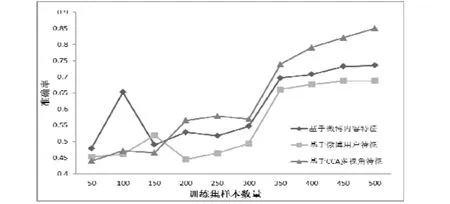
图7 不同的特征提取方法获得的分类判别准确率对比结果。
随着训练样本数量的提升,本文的基于CCA的多维度特征提取方法相较于其他两种方法能够获得更好的平均判别准确率,这表明基于CCA的特征融合方法对本文的置信度评判性能的提升有较大的贡献。
4 总结
本文介绍了一种应用于社会媒体上的信息置信度评估的分析与判别方法。该方法通过基于CCA 特征融合的多视角特征提取算法以及数据引力场DGF判别模型,设计了一个从海量社会媒体信息中检测出谣言和虚假信息的算法框架,并且将该算法应用于新浪微博数据集上的评估实验
取得了较好的实验结果。本文未来的工作主要关注于利用社交媒体中用户之间的关联信息对评估算法进行优化,以期望在检测虚假信息或者谣言的任务中获得更加准确的检测结果。
[1]Carlos Castillo, Marelo Mendoza, Barbara Poblete.Information credibility on twitter [C]// Proceedings of the 20th international conference on World Wide Web, NewYork: ACM, 2011: 675-684.
[2]Vahed Qazvinian, Emily Rosengren, Dragomir R.Radev,et al.Rumor has it: identifying misinformation in microblogs[C]// Proceedings of the Conference on Empirical Methods in Natural Language Processing, Stroudsburg,PA, USA: ACL, 2011: 1589--1599.
[3]Manish Gupta, Peixiang Zhao, and Jiawei Han.Evaluating event credibility on twitter [C]// SIAM International Conference on Data Mining (SDM13), Anaheim, California, USA: SIAM, 2012: 153-164.
[4]Ceren Budak, Divyakant Agrawal, and Amr El Abbadi.Limiting the spread of misinformation in social networks[C]// Proceedings of the 20th international conference on World Wide Web, New York: ACM, 2011: 665-674.
[5]Meredith Ringel Morris, Scott Counts, Asta Roseway, et al.Tweeting is believing? Understanding microblog credibility perceptions [C]// Proceedings of the ACM 2012 conference on Computer Supported Cooperative Work,New York: ACM, 2012: 441-450.http://weibo.com.
[6]K.Lee, B.Eoff, and J.Caverlee.Seven months with the devils: a long-term study of content polluters on twitter[C]// Proceedings of the Fifth International AAAI Conference on Weblogs and Social Media, Barcelona,Spain: AAAI, 2011.
[7]Mohammad Ali Abbasi and Huan Liu.Measuring User credibility in social media [C]// Proceedings of the 6th International Conference on Social Computing, Behavioral-Cultural Modeling, and Prediction, Washington:LNCS, 2013: 441-448.
[8]Asaf Degani, Michael Shafto, Leonard Olson.Canonical correlation analysis: use of composite heliographs for representing multiple patterns [C]// Proceedings of the 4th International Conference, Diagrams 2006, CA, LNCS,2006: 93-97.
[9]Albert Gordoa,b, Jos´e A.Rodr´ıguez-Serrano, Florent Per-ronnin, et al. Leveraging category-level labels for instance-level image retrieval[C].// IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, Rhode Island: IEEE, 2012: 2045-2052.
猜你喜欢
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
商洛学院学报(2020年6期)2020-12-24
新课程·上旬(2020年10期)2020-08-14
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
计算机应用(2018年5期)2018-07-25
中学理科园地(2017年5期)2017-11-09
自动化学报(2017年11期)2017-04-04
决策与信息(2016年35期)2016-02-08
