
基于逻辑强化学习的Deep Web增量信息获取方法
2014-10-20 08:36顾伟傅德胜蔡玮
微型电脑应用 2014年9期
顾伟,傅德胜,蔡玮
0 引言
随着Web的飞速发展,Deep Web中蕴藏着海量高质量数据。使用传统搜索引擎在Internet表面检索到的信息只是其中的一小部,在Internet深处还存在海量信息无法被搜索到,这些信息被称为Deep Web[1]。Deep Web数据量是非常巨大的,大约是可索引的web信息的500倍。目前Deep Web数据集成主要有两种实现方式:一种是基于元搜索的方法,提供一个统一的查询接口,将用户查询通过语义映射转发到相应的Deep Web数据源,返回的结果通过提取,语义标注,去重合并后呈现给用户。该方法不需要维护本地数据库,但查询响应时间由远程数据源的服务质量决定。另一种方案就是将Deep Web中爬取出来的内容存储在本地动态网页拷贝库中,并通过建立索引来缩短用户查询的响应时间[2]。该方案的关键问题是如何让本地数据与远程数据同步。本文在相同更新资源条件下,使本地和远程数据保持最大化同步。
由于Deep Web数据的动态性,其数据往往处于频繁更新的状态,但用户总是希望得到最新的内容[3]。由于不同的Deep Web数据源中数据记录的变化频率是不一样的,根据统一的频率更新所有的本地数据非常耗费资源。由于 Deep Web数据处于快速动态的更新状态,本文提出的方法可以有效地提高Deep Web数据集成服务质量,实现Deep Web数据的自动增量更新,从而使Deep Web数据可以更好地为科研、生产和决策服务。
自Deep Web概念提出以来,国内外学者对如何有效利用Deep Web信息做了广泛研究。针对Deep Web数据提取,Ntoulas Alexandros[4]对Deep Web查询生成制定了有效的生成策略。Capi等[5]将强化学习用于主题相关评估计算中,控制了搜索的正确方向。为了解决典型强化学习存在的“维数灾难”问题[6],近年来出现了分层强化学习法[7]和搜索空间限定法[8]等方法,主要通过对问题抽象来实现。搜索空间限定法通过在受限的策略空间中搜索最优,容易引起局部最优。分层强化学习法借助抽象方法将强化学习任务进行分解,实现降维,从而各层学习任务在低维空间中就可完成,但针对增量数据爬取,很难进行分层处理。为此,本文采用逻辑强化学习方法可以很好地解决这个问题。
近年来,国内研究机构,如苏州大学[9]和中国人民大学[10]对Deep Web信息提取进行了深入的研究。然而,国内其他学者对Deep Web增量数据提取问题研究较少,在Surface Web增量数据提取方面作了一定的研究。
1 Deep Web简介
Internet已经成为当今社会人们获取信息的主要来源,尤其是数据库技术与网络技术的结合,使Internet拥有了最为巨大的信息量,进而衍生出深度网(Deep Web)。最初由Dr.Jill Ellsworth于l994年提出,指那些由普通搜索引擎难以发现其信息内容的web页面。2001年,Christ Sherman等定义Deep Web为:虽然通过互联网可以获取,但普通搜索引擎由于受技术限制而不能或不作索引的那些文本页、文件或其它通常是高质量、权威的信息。
据最近对Deep Web的调查得到了以下有意义的发现:当前Deep Web的规模为307,000个站点,450,000个数据库和1,258,000个查询接口,在2000-2004年间增长了3-7倍;Deep Web广泛分布于几乎所有的学科领域;Deep Web对于主流搜索引擎来说并不是完全不可见,大约有1/3的数据已经被覆盖;Deep Web中的数据大多是结构化的;尽管一些Deep Web的目录服务已经开始索引Web上的数据库,但是他们的覆盖率很小约为0.2%到15.6%;Web数据库往往位于站点的较浅层,94%的Web数据库位于站点Web数据库往往位于站点的较浅层,94%的Web数据库位于站点前3层。
2 基于逻辑强化学习的增量数据提取方法
Deep Web检索系统的数据库复制了远程数据库的对象信息,但当远程数据库的对象信息发生改变时,本地数据库无法知晓,必须周期性检测远程数据库的变化情况,因此需要根据远程数据库的变化规律来确定两者之间的同步频率。
2.1 强化学习的简介
马尔可夫决策程序(MDP)[11]的逻辑组成对应于一个有穷的状态机,由于状态和活动是非结构的,因此这个自动机必须是以命题表示。通过逻辑马尔可夫决策程序可以通过逻辑符号来替代同类状态和活动,最大程度地减少状态和活动的数量。针对强化学习一直被“维数灾难”问题所困扰的问题,在关系强化学习的基础上,将逻辑谓词规则与强化学习相结合,形成一种新的逻辑强化学习方法,采用轮廓表表达的状态和活动[12],可以准确地表达。
2.2 同步频率确定
泊松过程[13]是一个常用于描写随机事件累计发生次数的基本数学模型,表面上看,只要随机事件在不相交时间区间是重复独立发生,而且在充分小的区间上最多只发生一次,它们的累计次数就是一个泊松过程。在很多应用场合都可以近似地归结为泊松过程。文中采用泊松过程来描述对象信息的变化情况,使得本地数据库可以更好地与远程数据库保持同步。
2.3 Deep Web数据更新
根据Deep Web的特性,可根据有两种不同的粒度制定Deep Web数据更新策略[14-15],分别通过数据源的重要性权重和数据源的变化频率、以及数据记录的历史变化频率来确定更新频率。
2.4 Deep Web新数据发现
基于逻辑强化学习算法,在Deep Web数据获取的过程中进行在线学习。根据关键词或关键词的组合所返回结果中新记录数,设置相应的奖赏值。根据学习结果,对可能出现新数据的关键词或关键词的组合分配更多的资源。在相同资源约束前提下,可有效提高新数据的发现效率。
为了避免在数据获取过程中搜索树膨胀,采用将强化学习技术应用到数据获取的可控网络爬虫方法中。该方法通过强化学习技术得到一些控制“经验信息”,根据这些信息来预测较远的回报,按照某一主题进行搜索,以使累积返回的回报值最大。
基于逻辑强化学习的爬虫(LQ-Spider)的训练抓取过程包括下列步骤。
步骤1.提供待查询数据的主题,分别构建站点初始训练队列URL,然后提取队首队列URL,分析其页面结构提取页面中的链接地址 URL,并根据页面关键信息计算链接地址的立即回报,结合经验得出未来回报值,然后结合Value值词库中未来回报来计算该链接地址的综合Q值。
步骤2.权衡立即回报价值和未来回报价值的信任度,即现在是处理利用阶段还是探索阶段,控制信任度。根据URL 地址的深度因子是否大于5,如果深度因子大于5,则抛弃,不放入待提取 URL队列。据调查,91%的深层网页查询接口所在页面的深度都在5层之内,因此当URL链接的深度大于5时,就不处理该链接,可以在保证准确度的前提下,有效减小处理量。
步骤3.当得到深度因子小于5的 URL链接后,然后判断其综合Q值是否大于某个主题值,如果是则更新Value值词库中的原属性值,并用新的Value值词库来计算未来回报,然后根据URL优先权放入待提取URL队列中,如此反复训练直到得到最终的待提取URL队列,然后由爬虫程序有目的的抓取Deep Web中增量信息。如果综合Q值小于某个主题值,则舍去该URL。返回步骤(1)继续下一轮训练。
3 实验验证
在这一节中,通过具体的实验来评估所提出的方法的有效性和可行性。首先,需对其理论基础进行分析验证该新方法的可行性,然后,在此基础上进一步验证采用该方法的性能优劣。
3.1 验证变化规律
研究表明网页的变化频率可以用泊松过程来表达。实验数据集采用加利福尼亚大学一科研小组采集的 Web对象信息。该数据集包括书籍、汽车、论坛和工作4个领域的对象信息。该数据集借助爬虫程序收集了一年半。收集到的Web对象数据集如表1所示:

表1 Web对象数据集
通过 λ= X/ T计算对象的平均变化频率,X表示时间段T内的变化次数。上述数据集的平均变化频率在各时段的对象个数如表2所示:

表2 平均变化频率在各时段内的对象个数
接着,统计不同领域平均变化频率相同的对象,各时间点t附近的对象变化概率如图1所示:
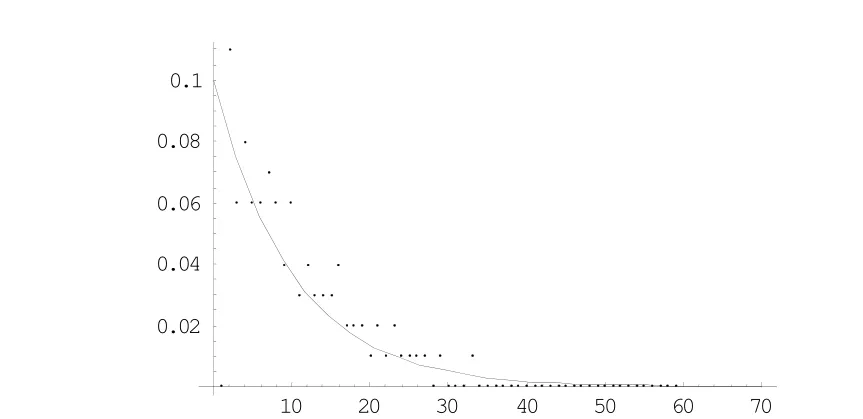
图1 间隔为10天的对象信息变化规律
X轴表示对象相邻变化的时间间隔,Y轴表示对象变化的比例。根据泊松过程曲线可以明显看出对象变化规律符合泊松过程。
3.2 验证新方法的性能
目前评价聚焦爬虫性能指标主要是通过计算抓取的相关页面和不相关页面的比率来衡量爬虫优劣。本文采用收获率方法来进行评估不同爬虫的性能。其中

实验通过采用基于逻辑强化学习的Deep Web聚焦爬虫(LQ-Spider)和常用 Deep Web爬虫(如 Best-first和Breadth-first)对工作和论坛两个领域的数据源进行抓取分析,来比较不同方法的爬虫获取信息的收获率,实验结果如图2所示:
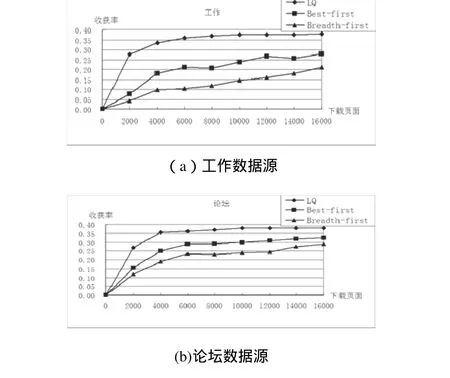
图2 两种数据提取方法比较
为了检验采用不同方法的Deep Web聚焦爬虫的爬行效果,本文选取工作和论坛两个领域,分别采用 Best-first、Breadth-first策略和我们的爬行策略(LQ)进行爬行,图2所示比较了几种爬虫的抓取性能,其中 X轴表示爬虫抓取的结果页数量,y轴表示收获率。另外每个结果页面包括从后台数据库中取到至少十条数据记录。实验结果表明,采用基于逻辑强化学习的爬虫能够获取更多的信息,本文提出的爬行策略取得了较好的应用效果,大大提高了爬虫的收获率。
4 总结
对于Deep Web增量数据提取问题,主要存在数据更新和发现新数据两大难点。而它们的关键是更新频率和新数据的发现。由于在处理此类问题时存在状态爆炸和难以分层处理等问题,这样很难用传统的强化学习方法加以解决。为此,本文在分析了Deep Web数据更新频率基础上,提出了一种强化学习的 Deep Web数据提取方法。结果表明,该新方法能提高数据的时新性和新数据的发现效率,可有效提高Deep Web信息集成服务质量。下一步还需进一步优化爬虫算法和更新频率提高获取的准确度。
[1]Luciano Barbosa, Juliana Freire.Siphoning Hidden-Web Data through Keyword-Based Interfaces[C].Proceedings of Brazilian Symposium on Databases, Brasília, DF, Brasil, 2004: 309-321.
[2]鲜学丰, 崔志明, 赵朋朋, 等.基于循环策略和动态知识的 Deep Web数据获取方法[J].通信学报,2012,33(10):35-43.
[3]He B., Patel M., Zhang Z., et al.Accessing the Deep Web:A Survey[J].Communications of the ACM, 2007,50(5):94-101.
[4]刘全, 高阳, 陈蓄道, 等.一种基于启发式轮廓表的逻辑强化学习方法[J].计算机研究与发展, 2008, 45(11):1824-1830.
[5]孟涛, 王继民, 闫宏飞.网页变化与增量搜集技术[J].软件学报, 2006,17(5):1051-1067.
[6]赵朋朋.Deep Web信息集成若干关键技术研究[D].苏州大学博士论文, 2008.
[7]Cho J., Ntoulas A., Effective Change Detection Using Sampling[C].Proceedings of 28th International Conference on Very Large Data Bases, Hong Kong, China,Springer Berlin, 2002: 514-525.
[8]Wu Ping, Wen Ji-Rong, Liu Huan, et al.Query Selection Techniques for Efficient Crawling of Structured Web Sources[C].Proceedings of the 22th International Conference on Data Engineering.Atlanta,GA,USA.IEEE Computer Society, 2006:47-56.
[9]刘伟, 孟小峰, 孟卫一.Deep Web数据集成研究综述[J].计算机学报, 2007,30(9):1475-1489.
[10]林超.面向Deep Web的对象检索关键技术研究[D].苏州大学硕士论文, 2008.
[11]Jayant Madhavan, David Ko, Lucja Kot, et al.Google's Deep-Web Crawl[C].Proceedings of 34th International Conference on Very Large Data Bases.Auckland, New Zealand, Springer Berlin,2008:1241-1252.
[12]Rodrigo B.Almeida, Barzan Mozafari, Junghoo Cho.On the Evolution of Wikipedia[C].Proceedings of the International Conference on Weblogs and Social Media 2007.Colorado, U.S.A, AAAI Press, March 2007.
[13]Ka Cheung Sia, Junghoo Cho, and Hyun-Kyu Cho.Efficient Monitoring Algorithm for Fast News Alerts[J].IEEE Transactions on Knowledge and Data Engineering,2007,19(7) :950-961.
[14]Olston C., Pandey S..Recrawl Scheduling Based on Information Longevity[C]Proceedings of the 17th International World Wide Web Conference, Beijing, China, ACM Press ,2008:437-446.
[15]Croonenborghs T, Ramon J, Blockeel H, Bruynooghe M.Online Learning and Exploiting Relational Models in Reinforcement Learning[C].Proceedings of 20th International Joint Conference on Artifical Intelligence, Hyderabad, India, AAAI Press, 2007: 726-731.
猜你喜欢
房地产导刊(2022年10期)2022-10-18
数学物理学报(2022年5期)2022-10-09
数学物理学报(2021年6期)2021-12-21
现代信息科技(2021年21期)2021-05-07
数学物理学报(2020年6期)2021-01-14
电子制作(2018年2期)2018-04-18
计算机与生活(2018年3期)2018-03-12
中国科技期刊研究(2017年2期)2017-05-14
电子制作(2017年9期)2017-04-17
浙江大学学报(工学版)(2015年2期)2015-05-30
