
基于覆盖粗糙集的语言动力系统
2014-09-13 13:05:02汤建国汪江桦韩莉英祝峰
智能系统学报 2014年2期
汤建国,汪江桦,韩莉英,祝峰
(1.新疆财经大学 计算机科学与工程学院,新疆 乌鲁木齐 830012; 2. 闽南师范大学 粒计算实验室,福建 漳州 363000)
语言动力系统(linguistic dynamic systems, LDS)的概念是王飞跃教授在20世纪90年代初提出的,它是以词计算为基础来对问题进行动态描述、分析、综合,进而设计、控制和评估的系统[1- 2]。由于语言具有很强的不确定性,其语义会随着语境及语调等因素的不同而发生改变,因而如何处理这种不确定性是LDS研究中的一个关键问题。王飞跃教授在这方面做了大量基础性工作[3-6],他利用模糊数学的方法来解决不确定问题,建立了基于模糊逻辑的LDS模型。
近年来,粗糙集[7-8]作为一种处理不确定问题的有效方法得到了快速发展,其扩展理论覆盖粗糙集[9-16]也引起很多学者的关注和研究兴趣,涌现出许多重要的研究成果[17-24]。本文将利用覆盖粗糙集方法来研究语言动力系统中的不确定问题,建立基于覆盖粗糙集的LDS模型,利用粗糙集中的上下近似思想探讨解决实际问题的推理方法,并通过实例对其具体的应用和计算方法进行阐述。
1 相关定义
为了讨论方便,在本文的后续内容中,令U表示一个非空有限集合,称为论域。
1.1 覆盖粗糙集
设U是一个论域,C是U的一个子集族。如果C中的所有子集都不空,且∪C=U,则称C是U的一个覆盖;称有序对(U,C)为覆盖近似空间。对于任意一个子集X⊆U,定义X关于C的下近似和上近似分别为:

{K∈C|K⊆X}
(1)
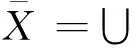
(2)
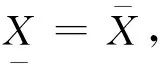
C*(X) = {K∈C|K⊆X}
(3)
C*(X) = {K∈C|K∩X≠}
(4)
在粗糙集中,一个集合的下近似中的元素被认为是确定属于该集合的,而上近似中的元素则被认为是可能属于该集合的。因此,可以根据下近似来获取确定的规则和知识,而依据上近似来获取可能性的规则和知识。由于C*(X) ⊆C*(X),所以在C*(X)中除去C*(X)后剩余的集合都是可能属于集合X的。令C**(X)表示C*(X)与C*(X)的差集,即:
C**(X) =C*(X) -C*(X)
(5)
对于U中的任意一个元素x,其关于C的邻域为
N(x) = ∩{K∈C:x∈K}
(6)
1.2 语言动力系统
语言动力系统是一类特殊的动力学系统,它将问题(过程)、情形(状态)、策略(控制器)、观察(反馈)、目标和评估用文字术语来表达[2]。王飞跃教授结合词计算将LDS建模成一个模糊动力学系统,其状态方程、输出方程和反馈控制分别表示如下:
状态方程:Xk+1=F(Xk,Uk,k),F:In×Im×Z+→In。
输出方程:Yk=H(Xk,k),H:In×Z+→Ip。
反馈控制:Uk=R(Yk,Vk,k),R:Ip×Iq×Z+→Im。
式中:Z+= {0, 1,…,K},Xk∈In是一个表示系统状态的向量,Yk∈Ip是输出,Vk∈Iq是输入,Uk∈Im是控制,k是离散时间实例,F,H,R是模糊逻辑算子,它们各自定义了LDS中的系统、输出和控制映射。系统中变量X、Y、U和V的定义域分别为:
DX= {x1,x2, …,xn}
DY= {y1,y2, …,yp}
DU= {u1,u2, …,um}
DV= {v1,v2, …,vq}
2 问题的提出
语言动力系统是一个非常复杂的动力学系统,它面向的处理对象是自然语言所表达的人类知识,而这种知识具有很强的不确定性。因而,如何有效应对这种不确定性是语言动力系统研究中的一个关键的问题。
王飞跃教授利用基于模糊逻辑的词计算对LDS进行建模,来处理LDS中的不确定问题。词计算是以隶属函数为基础的一种计算理论,它可以在一定程度上很好地反映和处理自然语言中的不确定性。但由于如何确定隶属函数是一件繁琐而困难的工作,因而在面对复杂的大数据问题时,这种方法就显得力不从心。
粗糙集是一种重要的处理不确定问题的理论,与词计算不同的是,粗糙集在解决问题时不依赖给定数据之外的任何先验知识,而是完全根据所给数据来客观地获取知识。因此,利用粗糙集分析和处理数据时不需去确定隶属函数。经典的粗糙集理论是建立在对论域划分的基础上,即不同概念之间不存在交集。而在现实世界中,用自然语言描述的概念往往具有一定的模糊性,如很难对“年轻”这一概念予以确切地描述和区分,这就会将“年轻”中的一些人也分到诸如“较年轻”或“较不年轻”等概念中去,反之亦然。鉴于此,Zakowski[9]将经典粗糙集扩展为了覆盖粗糙集,从而允许不同概念之间可以存在非空交集,增强了粗糙集对实际问题的处理能力。
覆盖的这一特征与自然语言表达知识的特点非常相似,即在对概念的表述上都存在一定的不确定性,这就使得利用覆盖粗糙集来研究语言动力系统具有很强的可行性。目前,覆盖粗糙集研究已取得长足发展,在诸如公理化和模型扩展等理论方面和数据挖掘等应用方面都取得了很多成果,已成为一种重要的研究不确定问题的方法。因此,基于上述分析,本文将利用覆盖粗糙集对语言动力系统中的不确定问题展开探索性的研究。
3 覆盖粗糙集的LDS模型
3.1 模型
自然语言的丰富内涵造成了语言表达知识的不确定性,如何用计算机准确地判断一句话所要表示的意义,对计算机科学来说无疑是一个巨大的挑战。覆盖粗糙集通过上、下近似逼近的方式来近似地刻画目标集合,可以快速地给目标集合的不确定性划定一范围,提高了知识获取的效率。这一思想为处理不确定问题提供了一个很好的方法,借助这种思想建立了基于覆盖粗糙集的LDS模型:
状态方程:
输出方程:
反馈控制:
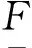
3.2 推理方法
在覆盖粗糙集理论中,认为目标集合的下近似集是确定成立的知识,而上近似集则是可能成立的知识。根据这一特点,设计了基于覆盖粗糙集的LDS分析和解决问题的推理过程,其主要步骤为:
1) 将语言描述的背景知识转换为覆盖形式的知识。粗糙集中认为知识是一种分类能力,并将每类事物都用一个集合来表示。在覆盖粗糙集中,这些类对应的集合被称为覆盖块。于是,为了求解问题需要先将已有的知识转换为反映分类能力的覆盖。具体来说,首先要依据实际问题来获得论域U,其次再根据已有知识得到覆盖C,最后为了实现用自然语言来描述计算结果,需要给予覆盖中的每个覆盖块一个语言标签ω。
①根据实际情况确定论域U;
②根据对问题的已有知识来获得U上的覆盖C= {K1,K2, …,Kn};
③根据问题的具体情况给各覆盖块添加语言标签 →ω(C) = {ω1,ω2, …,ωn},其中,∀Ki∈C,ω(Ki) =ωi。
2) 将要求解的问题转换成目标集合。通过分析问题的特点,将问题转换为目标集合X。
3) 根据得到的覆盖和式(3)、(4)求得目标集合X的C*(X)和C*(X)。
4) 根据C*(X)和C*(X)来得出确定成立和可能成立的知识。在这一过程中,一方面要根据问题给出描述结论的2种语言范式,即描述确定成立知识和描述可能成立知识的语言范式。另一方面,需要结合1)中的ω(C)来实现计算结果的语言表示。
此外,在实际问题中经常会遇到以一个数值区间表示的集合,本文对于这类集合的一些基本运算和相互间的关系做出如下规定:
设a、b、c和d是4个任意实数,其中a≤b,c≤d,A= [a,b]和B= [c,d]是2个数值区间。定义A和B的交运算、并运算以及子集等关系如下:
1)A∩B。
若a≥c且b≤d,则A∩B= [a,b];
若c≤a≤d且b>d,则A∩B= [a,d];
若a≤c且c≤b≤d,则A∩B= [c,b];
若a≤c且b>d,则A∩B= [c,d];
若b
2)A∪B。
若a≥c且b≤d,则A∪B= [c,d];
若c≤a且b>d,则A∪B= [c,b];
若a≤c且b≤d,则A∪B= [a,d];
若a≤c且b>d,则A∪B= [a,b]。
3)A⊆B。
若c≤a且b≤d,则称A是B的子集,记为A⊆B。
4)A∈B。
若a=b且A⊆B,则称A属于B,记为A∈B。
5)A=B
若a=c且b=d,则称A等于B,记为A=B。
4 实例与分析
例1 将学生的成绩分为优、良、中、差4个等级,对应的分值区间分别为(85, 100]、(75, 90)、(65, 80)、[0, 70)。假设学生小明的成绩等级为“中”,分析哪些成绩等级的学生成绩比小明的成绩好。
按照前面给出的推理过程,依次展开如下4个推理步骤:
1)根据已知条件可知学生的成绩分数范围为[0, 100],即:论域U= [0, 100];
其次,将各成绩等级作为不同的类别,从而得到U上的覆盖C= {K1,K2,K3,K4} = {(85, 100], (75, 90), (65, 80), [0, 70)};
最后,对覆盖C中的各覆盖块添加语言标签。从例题中可知,C中的4个覆盖块分别对应成绩等级中的优、良、中、差,于是可得:
ω(C) = {优, 良, 中, 差},其中,ω(K1) = 优,ω(K2) = 良,ω(K3) = 中,ω(K4) = 差。
2)由于小明的成绩等级为“中”,其对应的成绩为(65, 80),也就是说小明的具体成绩可以是这个区间中的任何一个实数。若令小明的成绩为a(65
3)根据得到的C和X可知,在C中只有覆盖块K= (85, 100] ⊆X,其余覆盖块均不是X的子集。根据式(3)可得
C*(X) = {K1}
类似地,K1∩X= (85, 100] ≠ ∅,K2∩X= (80, 90] ≠ ∅。根据式(4)可得
C*(X) = {K1,K2}
进一步地,根据式(5)可得:C**(X) = {K2}。
4)给出描述结论的2种语言范式。
① 确定成立知识的语言范式。
“成绩等级为“ω(K)”的学生成绩“一定”比小明的成绩好。”这里K∈C*(X)。
② 可能成立知识的语言范式。
“成绩等级为“ω(K)”的学生成绩“可能”比小明的成绩好。”这里K∈C**(X)。
其次,结合ω(C)来实现计算结果的语言表示。
由C*(X) = {K1}且ω(K1) =“优”可得
“成绩等级为“优”的学生成绩“一定”比小明的成绩好。”
再由C**(X) = {K2}且ω(K1) =“良”可得
“成绩等级为“良”的学生成绩“可能”比小明的成绩好。”
这说明如果一个学生的成绩等级是“优”,则他她的成绩一定比小明要好。如果一个学生的成绩等级为“良”,则他的实际成绩也有可能比小明好。由此可见,这种方法判断结果与在现实中的理解和分析是一致的。
上例通过对一个用自然语言描述的问题进行推理后得出了用自然语言描述的结果,下面再通过一个例子来从另一个角度展示如何对一个非自然语言问题进行推理。
例2 假设在例1中,小明的期中和期末考试成绩分别是76分和83分。请对小明的这2次成绩进行等级评价。
先对小明的期中成绩进行评价。由于论域U、覆盖C以及ω(C)都与例1相同,只需确定本例中的目标集合X。小明的成绩是76分,可将此成绩看成是区间[76, 76]。由于单个分值不具代表性,以该分值的所在的邻域作为目标集合。根据式(6)可得:
N(76) = ∩{K2,K3} = (75, 80)
即目标集合为X= (75, 80)。从而根据式(3)和(4)可得
C*(X) = ∅,C*(X) = {K2,K3}
由于C*(X)为空,所以在本例的问题中不存在确定成立的结论,而只有可能成立的结论。
可能成立知识的语言范式:
“小明的成绩等级“可能”为“ω(K)””。
结合ω(C)可得
“小明的成绩等级‘可能’为‘中’”。
“小明的成绩等级‘可能’为‘良’”。
同理,在分析小明的期末成绩时,可以得到对应于83分的邻域为区间(75, 90),即目标集合X= (75, 90)。从而根据式(3)和(4)可得
C*(X) = {K2},C*(X) = {K2}
进一步地,根据式(5)可得:C**(X) = ∅。
从而可得小明期末成绩等级评价的结果为:“小明的成绩等级“一定”为“良””。
上例对一个具体成绩的等级进行了推理和描述,其结果大体与在现实中的判断结果一致。之所以说大体上一致是因为在现实中,用“中”或“良”来描述小明的成绩还是显得有些宽泛,通常根据经验或感觉将其更细致地表述为诸如“中上”或“良下”等。在现实生活中,人们的这种“经验”和“感觉”在描述事物和表达信息时往往非常微妙,虽然其传递的是一种模糊的信息,但却并不让人感到费解。相反,人们多数会更愿意接受这种描述。
那么在推理方法中,如何反映和实现自然语言中类似人的这种“经验”和“感觉”呢?其实已有的很多方法都可以用来解决这个问题,比如概率的方法、模糊集中的隶属度方法以及粗糙集中的描述距离的熵等。但由于自然语言本身是灵活多变的,相同的一句话在不同场景或时间背景下意义会存在很大不同,所以在用这些方法解决这个问题是,还需要采取具体问题具体对待的方式来灵活处理。在后续的研究中,将对这一问题展开深入的分析和研究。
5 结束语
本文利用覆盖粗糙集的方法对语言动力系统进行建模,提出了分析和解决问题的推理方法,通过实例对其进行了阐述和验证,结果表明模型计算得出的结论与现实中的实际情况基本一致。在后续研究中,将对人在用自然语言描述事物时的模糊性修饰和表述进行研究,以使模型的计算结果更加准确合理。
参考文献:
[1]WANG Feiyue. Modeling, analysis and synthesis of linguistic dynamic systems: a computational theory[C]//IEEE International Workshop on Architecture for Semiotic Modeling and Situation Control in Large Complex Systems. Monterey, CA, 1995: 173-178.
[2]王飞跃. 词计算和语言动力学系统的计算理论框架[J]. 模式识别与人工智能, 2001, 14(4): 377-384.
WANG Feiyue. Computing with words and a framework for computational linguistic dynamic systems[J]. Pattern Recognition and Artificial Intelligence, 2001, 14(4): 377-384.
[3]WANG F Y. On the abstraction of conventional dynamic systems: from numerical analysis to linguistic analysis[J]. Information Sciences, 2005, 171(1/2/3): 233-259.
[4]WANG F Y, YANG T , MO H. On fixed points of linguistic dynamic systems[J]. Journal of System Simulation, 2002, 14(11): 1479-1485.
[5]王飞跃. 词计算和语言动力学系统的基本问题和研究[J]. 自动化学报, 2005(6): 32-40.
WANG Feiyue. Fundamental issues in research of computing with words and linguistic dynamic systems[J]. Acta Automatica Sinica, 2005(6): 32-40.
[6]莫红,王飞跃. 基于词计算的语言动力系统及其稳定性[J]. 中国科学: F辑, 2009, 39(2): 254-268.
[7]PAWLAK Z. Rough sets[J]. International Journal of Computer and Information Sciences, 1982, 11(5): 341-356.
[8]PAWLAK Z. Rough Sets: Theoretical aspects of reasoning about data[M]. Boston: Kluwer Academic Publishers, 1991: 1-79.
[9]ZAKOWSKI W. Approximations in the space(U,∏)[J]. Demonstratio Mathematica, 1983(16): 761-769.
[10]ZHU W, WANG F. Reduction and axiomization of covering generalized rough sets[J]. Information Sciences, 2003, 152: 217-230.
[11]ZHU W, WANG F. Axiomatic systems of generalized rough sets[C]//Proceedings of the 1st International Conference on Rough Sets and Knowledge Technology. Chongqing, China, 2006: 216-221.
[12]ZHU W, WANG F. Covering based granular computing for conflict analysis[C]//IEEE International Conference on Intelligence and Security Informatics. San Diego, CA, USA: 2006: 566-571.
[13]ZHU W, WANG F. Relationships among three types of covering rough sets[C]//IEEE International Conference on Granular Computing. Atlanta, GA, USA, 2006: 43-48.
[14]ZHU W, WANG F. Topological properties in covering-based rough sets[C]//Proceedings of the 4th International Conference on Fuzzy Systems and Knowledge Discovery. Haikou, China, 2007: 289-293.
[15]ZHU W, WANG F. On three types of covering-based rough sets[J]. IEEE Transactions on Knowledge and Data Engineering, 2007, 19(8): 1131-1143.
[16]ZHU W, WANG F. The fourth type of covering-based rough sets[J]. Information Sciences, 2012, 201: 80-92.
[17]YAO Y Y, YAO B X. Covering based rough set approximations[J]. Information Sciences, 2012, 200: 91-107.
[18]GE X, BAI X L, YUN Z Q. Topological characterizations of covering for special covering-based upper approximation operators[J]. Information Sciences, 2012, 204: 70-81.
[19]WANG L J , YANG X B, YANG J Y, et al. Relationships among generalized rough sets in six coverings and pure reflexive neighborhood system[J]. Information Sciences, 2012, 207(10): 66-78.
[20]TANG J G, SHE K, WANG Y Q. Covering-based soft rough sets[J]. Journal of Electronic Science and Technology, 2011, 9(2): 118-123.
[21]TANG J G, SHE K, ZHU W. The refinement in covering-based rough sets[C]//Proceedings of the International Conference on Granular Computing. Taipei, China, 2011: 641-646.
[22]TANG J G, SHE K, ZHU W. Covering-based rough sets based on the refinement of covering-element[J]. International Journal of Computational and Mathematical Sciences, 2011, 5: 198-208.
[23]WANG S P, ZHU W. Matroidal structure of covering-based rough sets through the upper approximation number[J]. International Journal of Granular Computing, Rough Sets and Intelligent Systems, 2011, 2(2): 141-148.
[24]ZHANG Y, LI J, WU W. On axiomatic characterizations of three pairs of covering based approximation operators[J]. Information Sciences, 2010, 180(2): 274-287.
猜你喜欢
语数外学习·高中版下旬(2023年7期)2023-09-25 00:45:13
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28 11:06:20
科教导刊·电子版(2021年6期)2021-05-06 05:05:10
成都信息工程大学学报(2021年6期)2021-02-12 03:00:52
南京大学学报(数学半年刊)(2020年1期)2020-03-19 02:24:44
测控技术(2018年10期)2018-11-25 09:35:52
厦门理工学院学报(2016年3期)2016-11-10 09:39:14
广东石油化工学院学报(2016年3期)2016-05-17 05:17:10
电源技术(2016年2期)2016-02-27 09:04:56
都市丽人(2015年4期)2015-03-20 13:33:22
