
相似度质心多层过滤策略的动态文摘方法
2014-08-30 09:22于洋范文义刘美玲王慧强
哈尔滨工程大学学报 2014年10期
于洋,范文义,刘美玲,王慧强
(1.东北林业大学林学院,黑龙江哈尔滨150040;2.哈尔滨工程大学计算机科学与技术学院,黑龙江哈尔滨150001)
动态多文档文摘的主要任务是在人们已经了解同一主题相关历史信息的基础上,获得随时间推移的相同主题下的动态变化的新颖性信息。一个新闻话题,通常有它自己的生命周期,包括出现阶段、发展阶段、衰退阶段和消亡阶段。不同的阶段具有不同的侧重点,而不同时刻的话题重心之间具有关联性,动态多文档文摘技术需要在主题相关性的基础上考虑多个文档集之间的时序关系。
动态文摘任务是由document understanding conference(DUC)[1]2007 年提出的,并且成为了 Text Analysis Conference(TAC)2008年的一项子任务,由美国NIST[2]承办。在 IARPA的支持下于2007年举行了第一届评测会议。主要研究的主题是分析出历史信息和当前信息之间的关系,找出它们之间的相同信息和相异信息然后提取新信息,过滤历史信息,实现对文档集信息演化性的建模。因此,人们希望快速高效的识别出重要的新颖的信息,以减少获取信息的代价。
张瑾[3]等提出了高性能的动态多文档文摘方法,利用模糊理论中的隶属度来衡量当前候选文摘句与历史信息的关联性,设定阈值,过滤掉关联性度量值高于阈值的候选文摘句,这属于第1大类动态文摘方法。参加TAC2008 Update task评测的系统中的大部分使用的动态文摘方法都属于第2大类。第3大类动态文摘方法是面向语义的文摘方法,多应用在面向领域的文摘系统和多语言环境中,参加TAC2009 Update task评测的系统绝大部分都是基于语义的建模方法。综上可知,以上3大类动态文摘方法是该领域中的主导方法。
本研究从分析历史文档与当前文档关系的角度,研究动态演化环境下动态文摘求解模型。首先给出了基于文本相似度累加(text similarity cumulative model,TSCM)的动态多文档文摘模型和基于质心整体优选(centroid integer selection model,CISM)的动态多文档文摘模型,应用TSCM来给候选文摘句加权打分,为使文摘具有较低的信息冗余度,使用提出的动态MMR(maximal marginal relevance)算法,然后用CISM进行质心判别和多层过滤。并在TAC2008测试集上进行测试。
1 动态文摘建模方法
1.1 基本概念和思想
1)文本相似度累加思想。
文本相似度累加思想体现在分析历史文档和当前文档间的关系上。文本相似度累加的思路是计算文档中所有句子的相似度并进行累加,对比以往的词级相似度计算,提高了内容过滤的可理解性和准确性。因此在文档内容一层过滤时,首先从动态性的演化性分析的角度对历史文档集合和当前文档集合做句子相似度计算,以时间信息和相似度值为依据过滤掉重复的文本信息,对过滤后的新产生的文档句子集合重新排序,并抽取出相似度值最低最能反映出信息新颖性的句子集合。句子级的相似度累加所产生的文摘比词级计算更能反应当前时序阶段内容的侧重点。
2)质心整体优选。动态多文档文摘生成文摘结构包括如下几个步骤:①预处理相关文档集;②对候选文摘句加权打分;③从候选文摘句集合中提取文摘句想成文摘;④根据相关时间信息对文摘句排序,进而生成连贯合理的文摘。无论动态文摘方法还是静态文摘方法,这4个步骤都缺一不可。文摘句选取阶段是动态多文档文摘方法的关键阶段,该阶段算法的好坏直接影响该动态文摘方法的性能。质心多层过滤优选方法以文本相似度累加模型为参照,涉及了多文档文摘技术的3大类型,改进了相应的解决方案。并在动态多文档文摘的信息显著度、信息新颖度和信息冗余度3项主要标准指标中应用了新的算法提高性能。
1.2 主要评测方法
多文档文摘系统的关键问题是如何识别重要性信息和删去冗余性信息。自动多文档文摘系统在最近几年获得了足够的重视,而对动态多文档文摘的研究工作才刚刚开始。他们共同的问题是,在不同文档中出现的信息不可避免的会互相重叠,即有较高的冗余度。因此,高效的动态多文摘方法,需要仔细分析测试任务,解决当前文摘高冗余度和历史文摘低关联度的问题。
目前在动态多文档文摘领域的评价方法主要包括自动评价 ROUGE[4]、BE(basic elements)[5]方法和人工评价金字塔PYRAMID[6]方法。
1)ROUGE和BE方法。
ROUGE方法是由Lin Chin Yew等于2002年提出并在2004年的DUC会议上正式使用。这个评价方法通过计算系统产生的文摘和人工文摘间所重叠的最长单词数目来评价系统文摘。其评价方法的计算比较复杂。Eduard Hovy等提出了BE方法,它以最小的基本词素作为比较单元,对ROUGE进行了很好的扩展。
2)Pyramid方法。
该方法是由Nenkova和Passonneau于2004年提出的。它采用一致确认的方法来进行评测。该方法以多年累积的权威性参考文摘中提取得到的短语表做为参考(这些短语由短而长排列,形如金字塔),通过比较机器文摘和参考文摘中在短语表中包含相同成分的多少来评测机器文摘的质量。
1.3 文本相似度累加模型
具体实现过程如算法1所示。
算法1:基于TSCM的多文档文摘算法
Input:多文档集合
Output:生成的动态文摘结果
1)设历史信息句子集合为Sh,当前信息句子集合为Sc,统计Sh中句子长度;
2)对Sc中的每个句子Sci(0<i< count(Sc))计算Sci与Shi(0<j< count(Sh))相似度值 Sim(senti,sentj),应用提出的句子级的相似度计算方法进行相似度计算;
3)计算相似度的累加迭代的值:
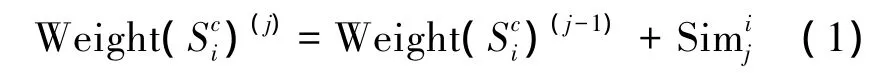
式中:Weight(Sci)(j)表示句子Sci与Sh中前j(0<j<count(Sh))个句子相似度值的累加;
4)根据当前文档句子集合Sc中的句子Sci的Weight(Sci)(j(j=count(Sh))值按照从高到底的顺序排列。设置一个阈值n表示过滤掉的句子的数目,删除当前文档句子集合Sc中的前n个句子。count(Sc)代表当前文档集合中句子的数目。剩下的count(Sc)-n个句子就是当前文档中包含新信息的句子。在利用TSCM分析历史信息和当前信息的一层信息过滤之后,动态演化性特征已经凸显,接下来,使用CISM进行多层的动态信息过滤。
本文提出的CISM涉及了MDS技术的3种类型,改进了相应的解决方案,并应用在动态MDS的信息显著度、信息新颖度和信息冗余度3项主要标准指标中,增强了模型性能。
1)信息显著度指标。
为提高质心整体优选动态模型产生文摘的信息显著度,本章提出应用文本相似度算法来给候选文摘句加权打分。基于句子相似度计算的句子加权方法参见1.5节
2)信息新颖度指标。
信息新颖度是动态MDS的又一重要度量指标,为了动态MDS在信息动态演化过程中保持信息新颖度,本章CISM采用上述提到的第1大类方法过滤与历史信息具有高关联度的句子,即在对文摘句加权之前,对文档集句子集合进行过滤处理,过滤掉当前文档集中的历史信息,对文档集的信息差异性建模,然后从经过滤处理后的句子集合中产生文摘。
3)信息冗余度指标。为了动态文摘能具有较低的信息冗余度,需要选择高性能的去冗余算法。此模型应用提出的动态MMR算法,参见1.4节。首先从候选文摘句集合中选出权值最高的句子作为正式文摘集合的第1个句子,下一步依据候选文摘句与正式文摘句集合中所有句子的相关性度量值,给候选文摘句集合中所有句子一定惩罚值后获得新的权值,然后提取权值最高的后选文摘句加入正文摘句集合当中,这样迭代执行,直到文摘句达到指定的数目。
为提高该动态文摘方法产生文摘的信息显著度,本模型首先应用文本相似度算法来给候选文摘句加权打分。为使文摘具有较低的信息冗余度,需要选择高性能的去冗余算法,现阶段主流的去冗余算法是最大边缘相关算法(MMR)[7]使生成的文摘具有低信息冗余性。MMR是一种有效的去冗余度算法,该算法流程如下:
1)首先从候选文摘句集合中选出权值最高的句子作为正式文摘集合的第1个句子;
2)依据候选文摘句与正式文摘句集合中所有句子的相关性度量值,给候选文摘句集合中所有句子一定惩罚值后获得新的权值;
3)提取权值最高的候选文摘句加入文摘句集合当中,这样迭代执行直到文摘句达到指定的数目。
MMR算法毋庸置疑的使文摘的性能具有较大幅度的提升,但是它也带来了相关的问题,即对首句文摘句选择的成功与否对文摘的性能有较大的影响。如果第1句文摘句选择失败,整个文摘将不会具有好的性能。为了解决此问题,提出了一种基于质心整体选优的动态文摘方法。
1.4 质心整体选优模型
基于质心整体选优的动态文摘方法着重考虑了文摘中第一个句子的选择对文摘的影响,在文摘生成过程中分别以多个高分句子为初始句,利用已有的动态文摘句选择方法生成多个候选文摘,再引入质心概念对多个候选文摘从整体的内容完整性、新颖性进行衡量。即以文档集合的质心作为评价依据,以候选文摘整体作为评价对象,对其表述信息的完整性进行衡量,最终从多个候选文摘中选择内容完整性最好的候选文摘作为该文档集合的文摘。
基于质心整体选优的文摘句选择方法包括以下几个方面:初始句的选择、多候选文摘的生成以及最终文摘的选择。CISM方法包括以下几个方面:初始句的选择、多候选文摘的生成以及最终文摘的选择。过程如图1所示。
1)初始文摘句的选择。
首先运用文摘句过滤算法过滤掉当前候选文摘句集合中信息新颖度低的句子,生成一个信息新颖度高的候选文摘句集合。用句子的长度信息、位置信息和所包含词语的TF*IDF*ISF权值(详见1.5节)对句子进行打分,计算上述处理后的候选文摘句集合中所有句子的信息显著度,根据句子信息显著对句子排序。从排序后的序列中,一次选取分值高的指定书目N个的非重复句子作为多个候选文摘的初始句。

图1 CISM流程Fig.1 CISM process diagram
2)多候选文摘算法描述。
算法2:相似度质心多层过滤文摘算法
Input:文档集合
Output:N个候选文摘
利用句子的位置信息,长度信息以及所包含词语的TF*IDF*ISF权值对句子打分。根据权重值对加权后的句子按照从高到低的顺序排列,形成句子队列A。从队列A选出分值最高的指定数目的N(这里N初值设置给10)个句子作为多候选文摘的初始句。对每一个初始句执行以下操作:
①清空已选文摘句队列S,将初始句加入S中;
②按句子权重依次选取后续句子,选择排名最高的候选句加入已选文摘句集合S;
③重复步骤②,直到已选文摘句集合S达到文摘的目标尺寸(句子数、字数),终止;
④将生成的候选文摘加入到候选文摘队列M;
3)最优文摘的选择。
对队列M中的每一个候选文摘计算权重:

式中:Score(Di)代表候选文摘打分;senti是候选文摘中句子;Di代表候选文摘;C代表当前文档集合的句子集合;sentj代表当前句子集合中的句子;sentk代表历史文摘中的句子;H代表历史文摘句集合;α和β分别代表候选文摘与当前文档句的相似度和与历史文摘句的相似度所占的比例。应用此模型算法,将候选文摘的权重进行重排列,选出打分最高的最优文摘作为最终结果。
1.5 动态多文档文摘句子加权方法
应用本项目前期工作中作者[8]提出的3种改进的句子加权方法:分别是动态短语的信息粒度[9]表示方法,动态TF-IDF-ISF的句子加权方法和动态句子级相似度计算的加权方法。
动态短语信息粒度的表示方法为

式中:Phrase_Weight(j)是句子中短语的权重:
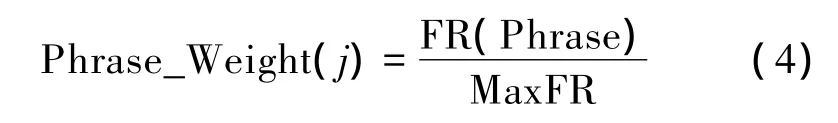
式中:FR(Phrase)是短语的词频,MaxFR是词频最大短语的词频,SentLength_Weight(senti)是句子长度权重。
在实际的计算过程中,如果SentLength<x,舍掉此句,不参与运算;
如SentLength>=x则SentLength_Weight(senti)=0;x是动态的句子长度阈值,根据实际需要进行调整。
动态TF-IDF-ISF的句子加权方法:
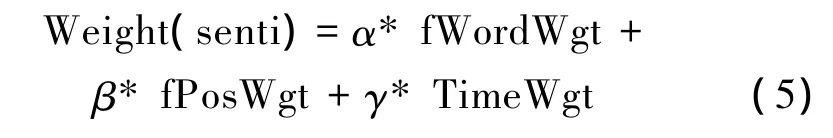
式中 :Weight(senti)表示句子Si的打分,fWordWgt=ISF表示句子 senti的词语权重,其中,TF(w)表示词w在文档中的出现频率,IDF(w)表示词w的反文档频率,ISF(w)表示词w的反句子频率,f(w)是频率统计函数,DF(w)为整个文档集合中包含词w的文档数,SF(w)为整个文档集中包含词w的句子数。
基于句子相似度计算的句子加权方法:

式中:Weight(Si)(0<i<count)表示句子Si的权重;count表示文档集合中句子的总数 Simij=,表示句子Si与Sj相似度值.
2 实验结果与分析
2.1 实验数据及评价
从DUC 2007开始,Update Summarization测试语料从主要任务的45个话题中挑选10个话题,每个话题由3个连续进化的时间片组成。假定读者对先前的文档有一定的了解,Update Summarization任务的目的就是针对每一个时间片给出100字的动态多文档文摘,该文摘反映随着时序的变化和基于同一主题的文档集合内容的动态演化,可见文摘技术向网络动态数据信息处理方向发展。
在TAC 2008中,测试预料假设已有历史多文档集合,按照时间顺序后产生的集合均看做是演化的多文档集合。Update Summarization任务的测试语料由来自AQUAINT-2的48个话题组成,每个话题包含两个时间片,均由10个大小相当的文档组成。
在TAC2008的Update Summarization测试数据上,评价标准采用文摘评测领域著名的ROUGE工具,其中最主要的2个指标ROUGE-2和 ROUGESU4*是评价动态多文档文摘性能的。将动态文摘结果的(R-2)和(R-SU4*)得分与TAC 2008 Update国际标准参赛系统的得分进行了对比,结果表明不同模型在性能上各有所长。
Example
<topic id=“D0801A”>
<title>Airbus A380<title>
<narrative>Describe developments in the production and launch of the Airbus A380.
<narrative>
<docsetA id=“D0801A-A”>
<doc id=“AFP ENG 20050115.0485”>
……
<doc id=“AFP ENG 20050504.0328”><docsetA>
<docsetB id=“D0801A-B”>
<doc id=“AFP ENG 20050601.0580”>
……
<doc id=“APW ENG 20060329.0349”>
<docsetB>
<topic>
2.2 实验结果
在以上模型基础上,以4组实验进行结果的比较。
实验1 是在文本相似度累加动态多文档文摘模型下3种不同加权算法生成的动态文摘的ROUGE评价结果,如表1所示。

表1 TSCM 3种算法的文摘性能对比Table 1 Comparison of three TSCM algorithms
实验2 测试模型中文档过滤过程中的所设置的句子数对动态多文档文摘的影响,对受句子长度影响最大的TSCM_C进行了分析。实验在10到110的取值范围内对句子个数进行测试,实验结果如图2所示。

图2 TSCM_C文摘长度阈值分析Fig.2 TSCM_C digest length threshold analysis
由图2以看出,TSCM_C在句子数为100时达到最优性能。此时,在ROUGE-2和ROUGE-SU4*上的得分分别为0.050 13和0.138 60,在ROUGE-2上进一步缩小了与第一名的差距,同时在ROUGESU4*上更加凸显了TSCM_C模型的动态演化性。
实验3 CISM模型和TSCM模型最好性能性能的比较,如表2所示:

表2 CISM模型和TSCM模型性能对比Table 2 CISM and TSCM performance comparison
实验4 如表3所示,其中CISM模型整体性能接近最好成绩,TSCM_C中短语信息粒度的句子加权方法的R-2比第1名的系统稍差,但是R-SU4*的分数已经超过了第1名。TSCM_B模型中综合打分进入前3名,说明这2种动态文摘模型在不同侧重点上,具有很好的性能和潜力,具有发展的空间,是值得研究的算法。
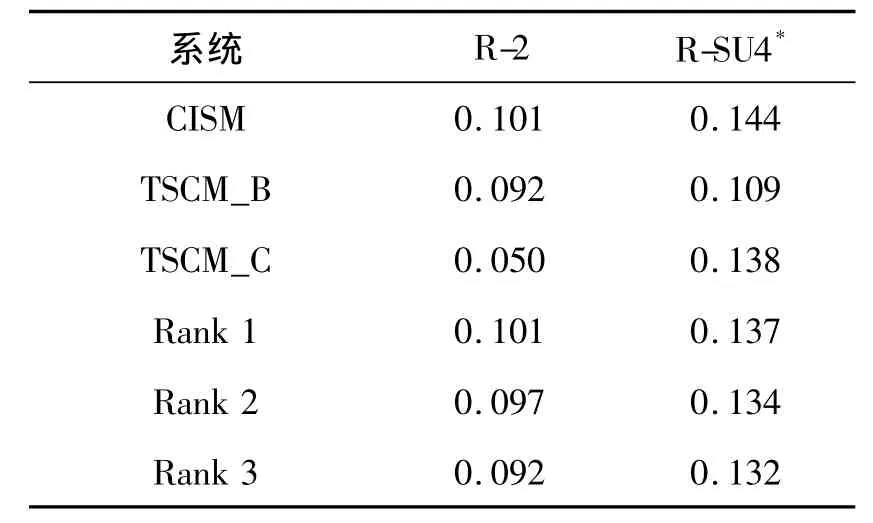
表3 与TAC2008实际系统的性能对比Table 3 Comparison with performance of TAC2008
2.3 实验分析
通过以上实验结果,综合分析提出的2种模型,动态多文档候选集多层过滤模型,基于文本相似度累加模型实验打分位于TAC2008发布的所有系统结果的上游。使用的改进的基于短语的句子加权方法时,它的ROUGE-SU4*打分已高出了TAC2008中第1名的系统,基于文本相似度累加模型实验打分位于TAC2008发布的所有系统结果的上游。可见TSCM是一种动态性能较好的模型。适用于动态性较强的新闻领域及实时社会计算领域。CISM系统的ROUGE-2打分仅次于第2名的系统,ROUGESU4*打分也在前列,表明通过修改去冗余方法也可使该模型生成的文摘具有较强的显著性和代表性。以生成的文摘集合为候选集合的方法,具有更强的灵活性,经算法调整可适用于有不同要求的领域,是一种适应性较强的动态文摘模型。
3 结束语
在动态多文档文摘领域中,动态多文档文摘模型研究是一个全新的课题,前正处于起步阶段。已有研究者提出了多种类型的动态文摘方法,有基于候选文摘句过滤的,有基于信息惩罚加权的,也有基于语义的,并且都获得了良好的性能。本项目提出的2种改进模型改善了原来动态文摘模型的性能,提高了文本抽取和文本理解的效率,与其他的模型比较,具有良好的动态性和生成高质量文摘。但是还存在许多问题需要解决,比如如何提高首句提取的精确率,如何使提取的首句具有动态演化性等问题。下一步工作是解决该改进算法所存在的问题,进一步提高改进算法的性能,应用于多种实际数据介质,增强文摘演化的识别能力。此类研究对于大数据集及数据挖掘的研究具有积极意义。
[1]LIN C Y,HOVY E.Automatic evaluation of summaries using n-gram co-occurrence statistics[C]//Proceedings of the 2003 Conference of the North American Chapter of the Association for Computational Linguistics on Human Language Technology.Morristown,USA,2003:71-78.
[2]WAN Xiaojun.Using bilingual information for cross-language document summarization[C]//Proceedings of the 49th Annual Meeting of the Association for Computational Linguistics:HumanLanguageTechnologies. Portland,USA,2011:1546-1555.
[3]张瑾,许洪波,程学旗.面向网络演化信息的动态文摘方法研究[J].计算机学报,2008,3(4):696-696.ZHANG Jin,XU Hongbo,CHENG Xueqi.Research abstracts method for dynamic information network evolution[J].Journal of Computers,2008,3(4):696-696.
[4]LIN C Y.Rouge:a package for automatic evaluation of summaries[C]//Text Summarization Branches Out:Proceedings of the ACL-04 Workshop.Barcelona,Spain,2004:74-81.
[5]HOVY E,LIN C Y,ZHOU L,et al.Automated summarization evaluation with basic elements[C]//Proceedings of the Fifth Conference on Language Resources and Evaluation(LREC 2006).Genoa,Italy,2006:604-611.
[6]NENKOVA A,PASSONNEAU R,MCKEOWN K.The pyramid method:incorporating human content selection variation in summarization evaluation[J].ACM Transactions on Speech and Language Processing(TSLP),2007,4(2):1-8
[7]GOLDSTEIN J,MITTAL V,CARBONELL J,et al.Creating and evaluating multi-document sentence extract summaries[C]//Proceedings of The Ninth International Conference on Information and Knowledge Management.Washington DC,USA,2000:165-172.
[8]刘美玲,任洪娥,于洋.基于网络的动态多文档文摘系统框架[J].软件学报,2013,24(5):1006-1021.LIU Meiling,REN Honge,YU Yang.Based on dynamic multi-document summarization system network framework[J].J Of Software,2013,24(5):1006-1021.
[9]刘美玲,郑德权,赵铁军,等.动态多文档文摘模型研究[J].软件学报,2012,23(2):289-298 .LIU Meiling,ZHENG Dequan,ZHAO Tiejun,et al.Dynamic multi-document summarization model[J].J of Software,2012,23(2):289-298.
猜你喜欢
汽车实用技术(2022年14期)2022-07-30
客联(2022年3期)2022-05-31
北京航空航天大学学报(2021年4期)2021-11-24
中国新闻周刊(2021年26期)2021-07-27
环境影响评价(2020年2期)2020-12-02
宝藏(2017年2期)2017-03-20
信息安全研究(2016年4期)2016-12-01
航天器工程(2014年5期)2014-03-11
物理与工程(2010年1期)2010-03-25
