
数据源敏感的多源XML 数据相似度量方法*
2014-08-16 07:59:54王继奎李少波
华南理工大学学报(自然科学版) 2014年7期
王继奎 李少波,2†
(1.中国科学院 成都计算机应用研究所,四川 成都 610041;2.贵州大学 现代制造技术教育部重点实验室,贵州 贵阳 550003)
可扩展标记语言(XML)成为当前网络应用中事实的数据表达、数据交换的标准[1].由于XML 数据的自描述、半结构化性质,很难准确地获得XML数据的模式信息.所以,传统的实体识别技术难以有效地应用在XML 数据重复检测上来.在多源异构的情况下,XML 数据的结构信息对相似度计算影响很小,所以不考虑XML 数据的结构信息,可将预处理后的XML 数据当作文本信息进行处理.文本相似度在语言学、心理学和信息理论领域被广泛研究.文本相似度量方法还广泛地应用于文本分类[2]、文本的重复检测[3]等领域.传统的方法利用词频信息将文档建模成一个向量,并利用向量间的余弦相似度计算文档间的相似度.基于语义的方法则是通过同义词、蕴涵和冗余等语义关系进行计算[4].文献[5]基于信息论的原理定义了词与词的相似度.文献[6]基于文本句子聚类的技术提出了判定句子相似性的方法.文献[7]基于WordNet 提出了SSRM 模型来发现文本中的相似词项.文献[8]最早提出了利用编辑距离来度量两棵树的相似度.文献[9]提出,两个XML 文档的距离可以通过计算它们的索引树来测定.文献[10]基于文档的分类提出对词项权重进行修正.文献[11]在预处理的基础上,通过建立属性对象表,提出了Max-merge 算法对XML 重复对象进行检测.文献[12]用树编辑距离的上下限优化基于树编辑距离的相似检测算法,降低了相似检测计算的复杂度,提高了运算效率.文献[13]提出了一种递归相似度计算方法计算XML 数据的相似度.文献[14]提出了一种对有序树计算相似度的方法.这些工作从多方面对文本分类与XML 数据重复检测进行研究.但是在已知数据源的情况下,词项在数据源中的分布如何影响词项的权重,进而影响XML 数据相似度量的研究则很少.与文本信息不同的是,预处理后的XML 数据不仅可以获得词项在数据中的分布情况,还可以获得其在数据源中的分布情况.通过观察,发现很多来源于同一数据源的数据有许多共同的词项,其区分能力显然低于有同样逆向文档频率的IDF 值[15]且在各数据源分布比较均匀的词项.因此,有必要根据词项在数据源中的分布情况修正IDF.利用修正后的逆向文档频率IDF 将数据建模成向量,采用余弦相似度判断两个数据是否相似.这样就排除了其他因素的干扰,得以单独观察已知数据源对XML 数据相似度量的影响.
文中利用含有词项f 的数据xi、xj出现在不同数据源的概率定义词项f 的数据源敏感度ρ 作为词项f 权重的修正系数,并基于修正后的词项权重向量定义了XML 数据xi、xj的相似度函数.最后在模拟数据集与真实数据集上进行了实验.
1 词项的数据源敏感度
1.1 定义
定义1 待检测数据集合D={x1,x2,…,xm},xj表示标号为j 的XML 数据.Q ( xj)表示xj的词项集合,也用Qj表示,可看作是xj各属性的义原词集合的并集.
定义3 数据源集合S={s(xi):xiD},si表示数据xi的数据源.
定义5 ID(f)表示词项f 逆向文档频率,ID(f)=
定义6 词项权重向量w(xi)=〈b1,b2,…,如果fkQ(xj),ak=1;否则ak=0,bk=akID(fk).
定义7 Df={xiD:fQ(xi)};nf=eD(f).ns,f={xiD:fQ(xi)&& si=s}.Df表示数据集D 中包含词项f 的数据子集;nf表示数据集D 中包含词项f的数据个数;ns,f表示数据源s 提供的数据集中包含词项f 的数据个数.
1.2 数据源敏感度
度量词项f 的数据源敏感度的测度ρ 需要满足以下性质:
(2)ρf=0 时满足∀xi,xj,xiDf,xjDf且xi≠xj→s(xi)=s(xj),即词项f 仅来源于同一数据源.
(3)ρf=1 时,满足∀xi,xj,xiDf,xjDf且xi≠xj→s(xi)≠s(xj),即每个数据源最多只存在一个词项f.
(4)当ρf(0,1)时,满足∃xi,xj,xiDf,xjDf,xi≠xj且s(xi)≠s(xj).即至少有两个数据源提供词项f.
令pf为xiDf,xjDf,xi≠xj时s(xi)≠s(xj)的概率.则
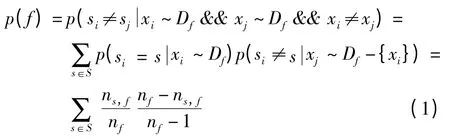
xi~Df&& xj~Df表示先从Df中取出一个元素xi,接着从Df再取出一个元素xj.p(f)表示词项f 出现在XML 数据xi、xj中,而xi、xj不属于同一数据源的概率.一般情况下nf≠1,nf=1 表示词项在所有数据中仅出现一次,对XML 数据重复检测的意义不大,在实现中不考虑.
显然,pf满足词项f 的数据源敏感度测度ρf的4 个性质.定义

当pf=0 时表示词项f 仅仅分布在一个数据源中;当pf=1 表示每个数据源最多仅有一个词项f,分布最分散,因而增大词项f 的权重.β{0,1},作为修正标记,β=0 表示不修正,β=1 表示修正.
2 相似度函数
基于IDF 的相似度函数为
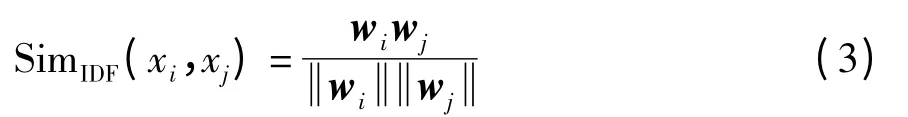
式中,wi=〈b1,b2,…,b|VD|〉.
XML 数据不同于一般的文本数据,词项f 的权重可以使用ID(f)度量.因为处理后XML 数据中,词项f 多次出现在同一XML 数据中的概率很低,就不再考虑词频的影响.
数据源敏感的相似度函数为
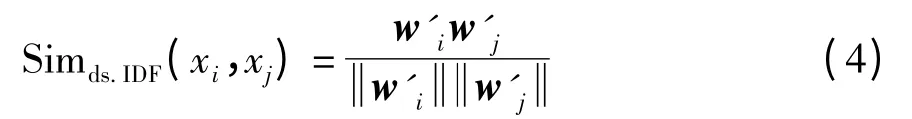
式(4)对式(3)中的词项权重进行了修正,新的相似度函数考虑词项f 的数据源敏感度.
XML 数据的相似度依然采用向量的余弦相似度度量.在具体实现相似度函数时,有多种实现公式.一般情况下,如果两个XML 数据有相同的词项,词项的敏感度大说明其出现在不同数据源的概率就大,其对相似度计算结果的贡献也应该大.直观地讲,有相同词项的两个数据,其来源于不同数据源重复的概率要大于来源于同一数据源的概率.因为,同一数据源的数据有很多相同的词项,而且同一数据源的数据在进行数据集成前一般是进行过数据清洗的,其重复的可能性本来就小.相反,来源于不同数据源的数据从整体上看各数据源可看作真实世界的视图,有着巨大的交集.不同的数据源分别对客观世界的实体做出了独立的描述,极端的情况是每个数据源针对同一客观实体各自独立提供一个描述.所以,修正后的相似度函数增加了实体描述的各数据源共有的个性词项的权重,从而降低了数据源特有词项的权重.理论上,同样相似度阈值的情况下,式(4)应该比式(3)有更高的召回率,也应该有更高的F 测度值.
3 实验结果与分析
与普通的文本不同,XML 数据是半结构化数据,在集成过程中通常文件比较小,且抽取时可完成数据源标识;由于其来源异构的特性,发现其模式信息比较困难.所以针对这些特点,在实验中将XML数据预处理后,将其看作有数据源及唯一标识的普通文本.实验对异构数据模式、内容比较杂乱无章的XML 数据进行验证,不考虑蕴涵、冗余等语义关系,也不考虑词项的层次信息.实验环境为Eclipse3.4、jdk1.6、Win7(64 位),内存为8 G.
3.1 XML 数据预处理
对于来源于不同数据源的XML 数据进行添加数据源标识.改造后的数据模式为
x'i=(oi,s,Qi).
式中,oi表示数据唯一标号,Qi表示XML 数据预先去除XML 标记、空值后的词项集合.所以,在XML数据预处理后,实验数据变成带有数据源信息及唯一标识的文本信息.
3.2 数据相似度实验
通过实验观察词项权重修正系数ρ 对相似度计算的影响,数据集为模拟数据集.经过处理后的XML 数据与表1 中的数据具有一样的模式.部分数据相似度计算结果见表2.
数据〈5,9〉的两种方法相似度计算结果均为1.000,通过查看表得知两组数据完全相同,所以结果合理.数据〈1,5〉通过IDF 方法与ds.IDF 方法的计算结果差距较大.f1={guitar,hero,IIIX,gameboy,from,Toys-R-us},f5={guitar,hero,IIIX,for,gameboy};在阈值为0.5 的情况下,Simds.IDF认为两者是相似的,而SimIDF则认为两者不相似.查看各词项权重计算结果,发现词项IIIX 的权重从IDF 计算的1.18 变成修正后的2.71,而Toys-R-us 的权重(1.87)没有变化.这也意味者词项IIIX 在相似度计算时,词项IIIX 与词项Toys-R-us 的权重对比发生了逆转.其原因是IIIX 在3 个数据源都有分布,且均匀;而Toys-R-us 仅存在于1 个数据源中.所以词项IIIX 的区分能力强于词项Toys-R-us,计算结果符合预期,也更合理.其他词项可类似分析.这解释了为什么对于数据〈1,5〉,Simds.IDF计算的结果大于SimIDF的结果.实际观察也发现,从某种意义上来说标号1 和标号5标识了来源于不同数据源的同一实体,其现实世界的唯一标识很可能是guitar+hero +IIIX.显然,是否为同一实体,与数据的解释密切相关.同样的方法可以解释为什么数据〈2,3〉的计算结果差别大.从以上分析可看到,数据源的确对数据相似度计算有影响.对表1 提供的数据进行重复检测,结果显示ds.IDF 方法在相似度阈值为0.6 时,重复数据检测召回率比IDF方法提高了36.4%.
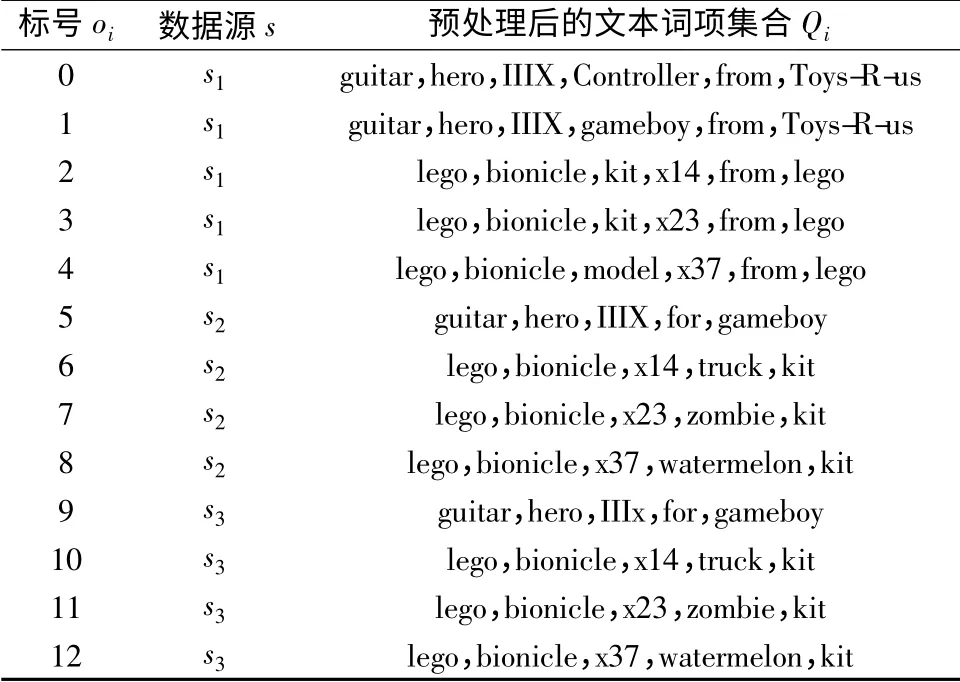
表1 测试数据Table 1 Test dataset
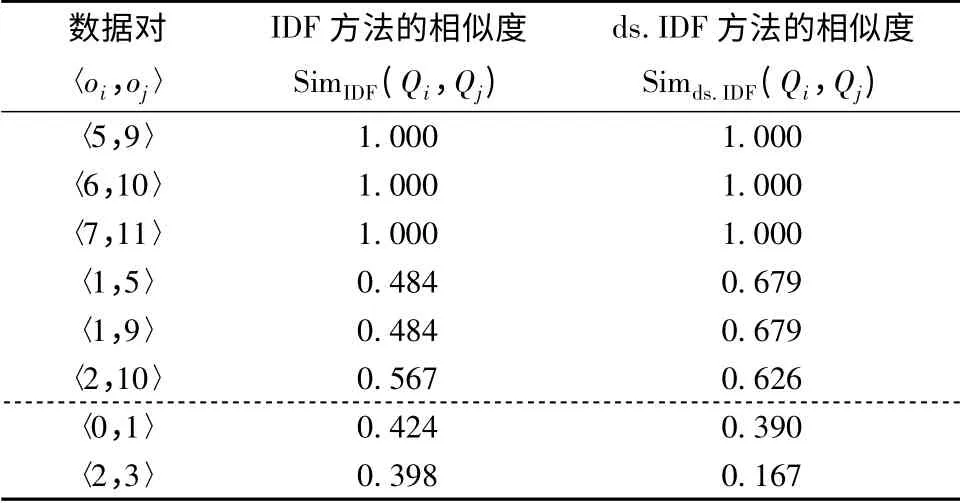
表2 部分数据相似度计算结果Table 2 Results of some similary experiments
3.3 真实数据集实验
实验数据来源于常用的Books-Authors 数据集,抽取了包括A1Books 在内的84 个数据源的9 个不同ISBN 的书籍信息.处理后的数据格式为{o,s,z,q1,q2,…,qn},如{1,A1Books,9780073516677,O'Leary,Timothy J.,O'Leary,Linda I.}.计算F 测度的依据为:如果IDF 方法或ds.IDF 方法计算的相似度大于阈值且其ISBN 相同,就认为检测出一个重复数据;否则认为做了一个错误检测.最后统计正确检测、错误检测以及总数,并计算F 测度值.
实验结果表明在相似度阈值 为0.8、0.5、0.2的情况下,IDF 方法的F 测度值分别为0.26、0.63和0.96,ds.IDF 方法的分别为0.29、0.68 和0.98.在相同相似度阈值的情况下,ds.IDF 方法重复检测的F 测度值均略高于IDF 方法,真实数据上的实验也验证了修正后的词项权重,提高了重复数据检测的F 测度值.实验结果与预期相符.可以得出结论:基于修正后IDF 的相似度函数在XML 重复数据检测中提高了有效性.同时也看到在 较高的情况下,F 测度值很低,原因是不同数据源对于同一实体的描述差别很大,从相似度的角度很难判断其为同一实体.计算结果也表明两种方法的准确率几乎都是100%,原因是Books-Authors 数据集中两个不同的实体之间的相似度很小,基本在0.2 以下.
4 结论
文中在IDF 作为词项权重度量的基础上,进一步考虑了已知数据源对词项权重的影响;将IDF 的思想推广到词项权重的数据源敏感性上,提出利用提供相同词项的待检测数据不在同一数据源中的概率度量词项的数据源敏感度,并作为修正IDF 的依据.模拟及真实数据集上的实验表明,修正后的相似度函数有效性更好,其重复检测的F 测度值也更高,结果符合预期.相似度函数的应用十分广泛,下一步拟将数据源敏感的数据相似度度量方法应用在数据挖掘的分类、聚类领域.
[1]孔令波,唐世渭,杨冬青,等.XML 数据的查询技术[J].软件学报,2007,18(6):1400-1418.Kong Ling-bo,Tang Shi-wei,Yang Dong-qing,et al.Querying techniques for XML data[J].Journal of Software,2007,18(6):1400-1418.
[2]Ko Y,Park J,Seo J.Improving text categorization using the importance of sentences[J].Information Processing &Management,2004,40(1):65-79.
[3]Theobald M,Siddharth J,Paepcke A.Spotsigs:robust and efficient near duplicate detection in large web collections[C]∥Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.Singapore:ACM,2008:563-570.
[4]黄承慧,印鉴,侯昉.一种结合词项语义信息和TF-IDF方法的文本相似度量方法[J].计算机学报,2011,34(5):856-864.Huang Cheng-hui,Yin Jian,Hou Fang.A text similarity measurement combining word semantic information with TF-IDF method[J].Chinese Journal of Computers,2011,34(5):856-864.
[5]Lin D.An information-theoretic definition of similarity[C]∥Proceedings of the Fifteenth International Conference on Machine Learning.San Francisco:Morgan Kaufmann Publishers Inc,1998:296-304.
[6]Aliguliyev R M.A new sentence similarity measure and sentence based extractive technique for automatic text summarization[J].Expert Systems with Applications,2009,36(4):7764-7772.
[7]Hliaoutakis A,Varelas G,Voutsakis E,et al.Information retrieval by semantic similarity[J].International Journal on Semantic Web and Information Systems (IJSWIS),2006,2(3):55-73.
[8]Tai K C.The tree-to-tree correction problem[J].Journal of the ACM(JACM),1979,26(3):422-433.
[9]郑仕辉,周傲英,张龙.XML 文档的相似测度和结构索引研究[J].计算机学报,2003,26(9):1116-1122.Zheng Shi-hui,Zhou Ao-ying,Zhang Long.Similarity measure and structural index of XML documents [J].Chinese Journal of Computers,2003,26(9):1116-1122.
[10]Zhang Yun-tao,Gong Ling,Wang Yong-cheng.An improved TF-IDF approach for text classification [J].Journal of Zhejiang University Science A,2005,6A (1):49-55.
[11]李亚坤,王宏志,高宏,等.基于实体描述属性技术的XML 重复对象检测方法[J].计算机学报,2011,34(11):2131-2141.Li Ya-kun,Wang Hong-zhi,Gao Hong,et al.Efficient entity resolution on XML data based on entity-describeattribute[J].Chinese Journal of Computers,2011,34(11):2131-2141.
[12]陈伟,丁秋林.一种XML 相似重复数据的清理方法研究[J].北京航空航天大学学报,2004,30(9):835-838.Chen Wei,Ding Qiu-lin.Study on an XML approximately duplicated data cleaning method[J].Journal of Bejing University of Aeronautics and Astronautics,2004,30(9):835-838.
[13]张丙奇,白硕,赵章界.XML 数据相似度研究[J].计算机工程,2005,31(11):25-27.Zhang Bing-qi,Bai Shuo,Zhao Zhang-jie.A recursive method to compute similarity of XML documents [J].Computer Engineering,2005,31(11):25-27.
[14]Akutsu T,Fukagawa D,Takasu A.Approximating tree edit distance through string edit distance[J].Algorithmica,2010,57(2):325-348.
[15]Jones K S.A statistical interpretation of term specificity and its application in retrieval[J].Journal of Documentation,1972,28(1):11-21.
猜你喜欢
数学物理学报(2022年3期)2022-05-25 13:33:12
数学物理学报(2022年2期)2022-04-26 14:07:54
数学物理学报(2020年4期)2020-09-07 09:14:00
数学年刊A辑(中文版)(2020年2期)2020-07-25 02:04:44
哲学评论(2018年1期)2018-09-14 02:34:18
计算机与生活(2018年3期)2018-03-12 08:38:11
中国科技期刊研究(2017年2期)2017-05-14 06:16:26
浙江大学学报(工学版)(2015年2期)2015-05-30 07:05:04
土木建筑工程信息技术(2013年4期)2013-10-17 02:27:54
上海理工大学学报(社会科学版)(2011年4期)2011-09-26 11:01:32
