
功能小句自动句法分析结果的错误分析
2014-07-16 08:52:38马建军
黑龙江工业学院学报(综合版) 2014年9期
马建军,宗 敏
(大连理工大学 外国语学院英语系,辽宁 大连 116024)
句法分析是自然语言处理的基本问题,是指通过计算机算法得到自然语言句子的句法结构。[1]自上个世纪50年代以来,句法分析问题一直是自然语言处理领域的重点和难点。[2]提高句法分析的质量不仅要更正算法,选择更合适的语法模板,更要从每次实验的错误中进行总结分析,在具体方面加以改正。实验表明丰富的语言知识对句法分析精度的提高有积极的作用,[3]但是在自然处理领域研究者多从算法和模板上进行错误分析或多个实验进行比较,从语言学角度分析的文章甚至段落少之又少。徐润华将句法错误分为两大类:语法功能不合理和语法缺失,仅举了4个例子。[4]马建军提出由于搭配库知识不全,小句中的小品词和介词很难区分,并明确指出做状语的名词短语容易出现识别错误。[5]盛文凤在其毕业论文中指出两大类介词短语识别错误:边界错误和功能错误,也仅有4个例子。[5]
鉴于此,本文应用韩礼德系统功能语言学中小句的理论,对基于CRF的功能句法自动分析结果进行数据统计,从句法错误的表现形式和句法错误原因两方面进行归纳总结,并结合实例做出形式化描述,对于设立标注规则,降低人工成本、提高句法分析准确度,甚至译后编辑都具有一定的实际价值和理论意义。
一 错误分类统计及讨论
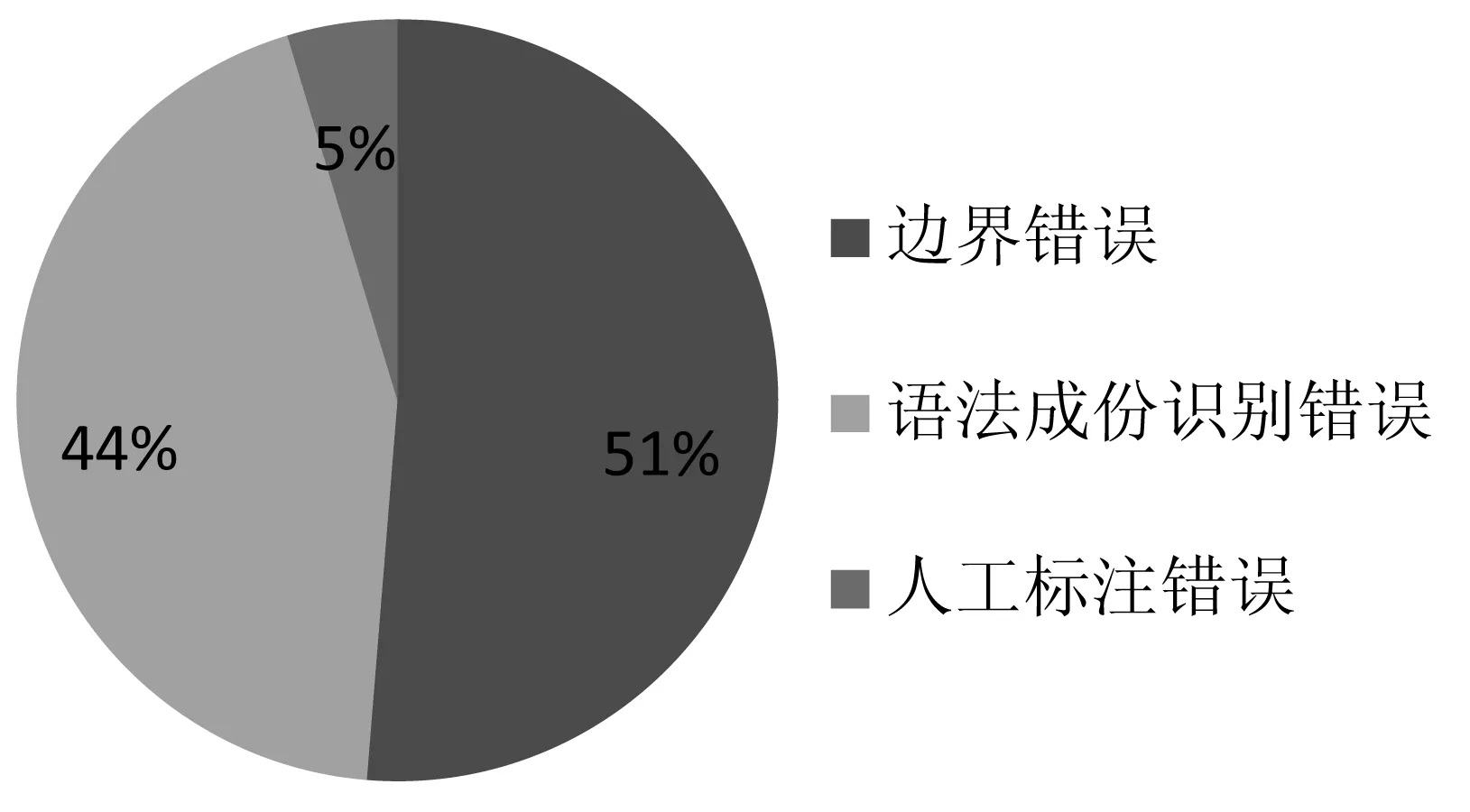
图1 三类一级错误百分比
经统计,5021个句子中,共出现193种错误。本文将其总共分为3类一级错误、7类二级错误和38类三级错误。其中,一级错误包括:机器自动识别的边界错误(99种)、机器欠缺语言知识造成的语法成份识别错误(85种)以及少量的句法分析前期的人工标注语注错误(9种)。三类一级错误所占百分比如图1所示。一级的边界错误可分为两类二级错误:漏编错误(26种)和语法成分边界错误(73种)。两类二级错误里可继续分出11种三级错误。边界错误细致构成如表1所示。
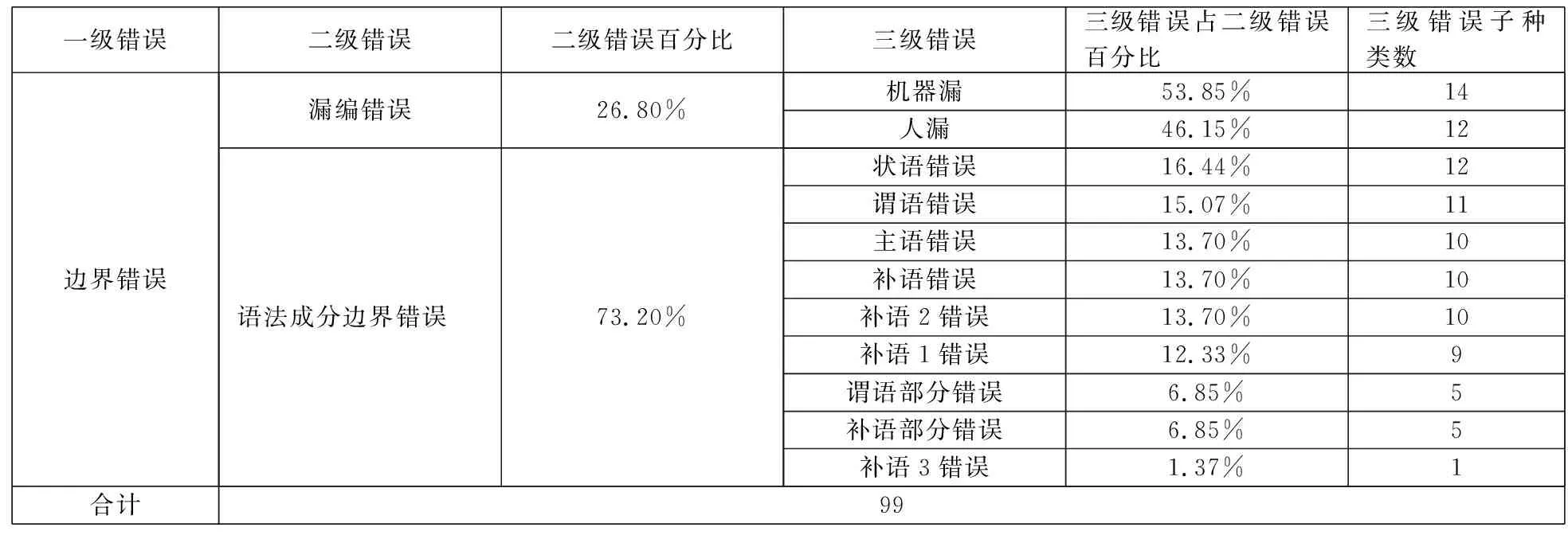
表1 边界错误构成
按照IOB2标注语方法,I表示该标注项目在短语内,B表示短语开始位置。因此,我们把语法成份识别错误分为两类二级错误:短语内成份错误(45种)和短语起始成份错误(40种)。具体例子如表2所示。

表2 短语内成份错误和短语起始成份错误示例
本文中,按照功能语法小句理论,小句成份功能块被分为7大类:主语、谓语、补语、补语1/2/3/4、状语、谓语剩余部分和补语剩余部分,共10部分。但是,所选择的句法分析结果的语料中,没有涉及到有补语4的小句,所以具体的语法成份错误包括9种。语法成分识别错误构成如表3所示。
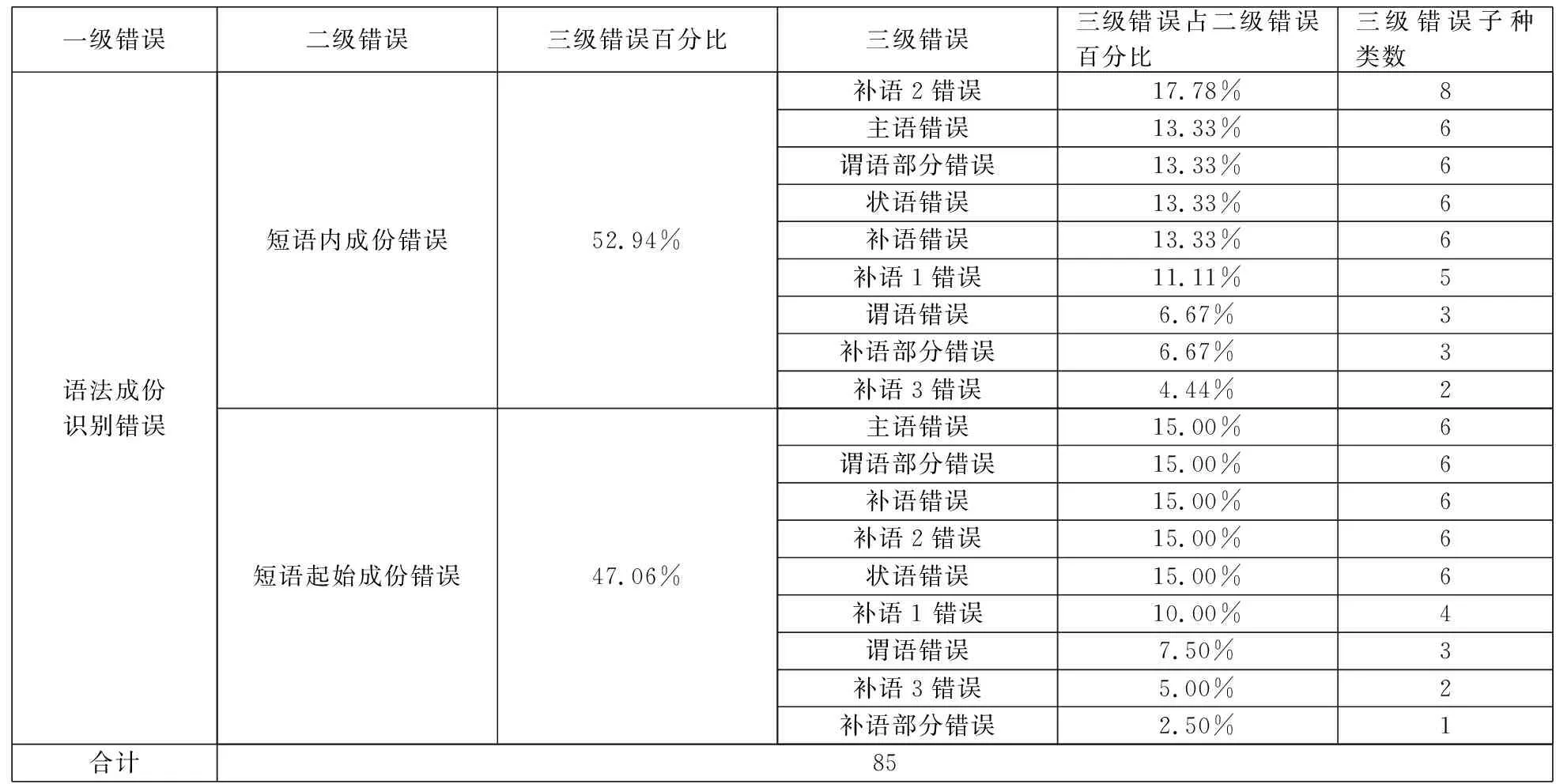
表3 语法成分识别错误构成
第三类一级错误——人工标注错误仅占错误总数的5%,具体的标注错误(三级错误)仅有9种。将这9种错误归为三类二级错误:不小心打错词的手误、原文有缩写导致标注识别错误和成份嵌套错误,每种错误仅错1-4词,大多数只错一词。具体如表4所示。
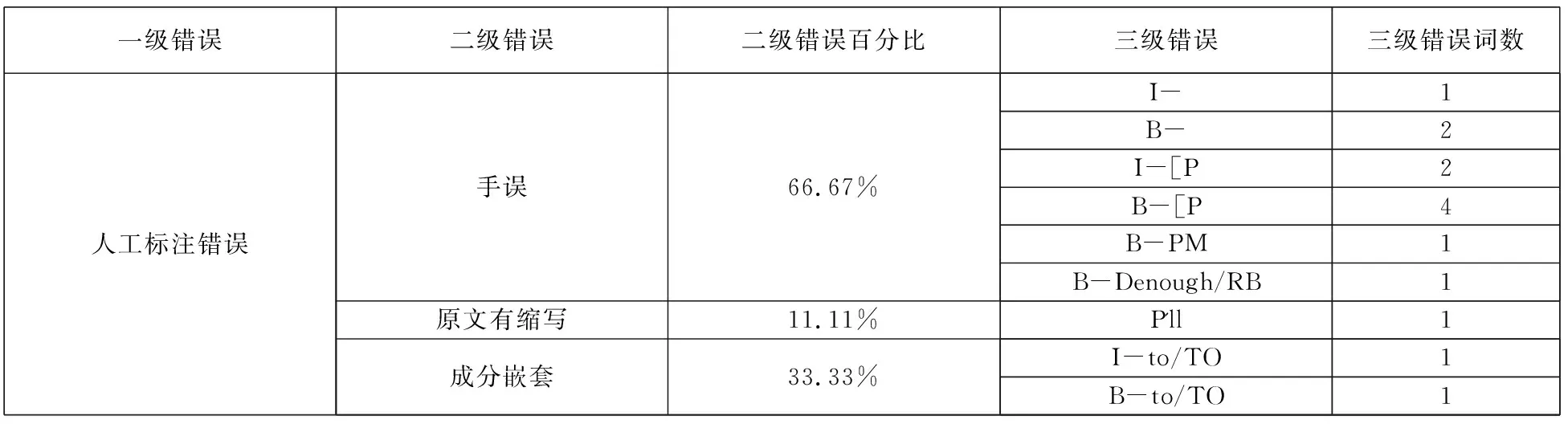
表4 人工标注错误构成
注: 1)I-和B-指该成分被用“[]”扩起来了,但是没有注明功能
2)I-[P和I-[B指该成分在标注时多标了一个“[”,如:“[[P”。
3)B-PM指该成分在标注时,不小心P后多了一个M。
4)B-Denough/RB指功能D与词enough/RB之间缺少了空格。
5)I-to/TO和B-to/TO指用“][”把不该分开的成分分开了。
从图1,表1,表3,表4可以看出:
1.三类一级错误中,人工标注错误比例是最低的,仅占5%。但是,人工标注错误中,除了“原文有缩写”这一项,手误和句子成分识别不清的问题是应该避免的。
2.在二级的漏编错误中,机器漏编而人有标注的情况(53.85%)比人没有标注而机器标注的情况(46.15%)略多一些。这说明我们需要增加或者细化标注规则,以免机器思维混乱,导致错误。
3.不论是在语法成份的边界错误还是在语法成份的识别错误中:状语、补语2和主语的识别错误最多;补语3和补语补充部分因为语料中出现的次数少,所以错误少;谓语部分和谓语错误在不同的情况中时多时少。这意味着,状语和补语2是自动句法分析的难点。要细化状语边界的描述,并将状语常出现的位置考虑到系统设置中,增强系统的排序功能,才能提高对状语和补语2的识别效果。
二 错误原因
需要说明的是,三个级别的错误会同时存在于小句当中,他们不是非此即彼,而是互相关联且共存的。因此,我们要从整个小句入手,究其不能被机器学习,或者影响机器学习的因素。通过对错误小句的样本分析,本文确定了如表5所示的小句句法分析错误原因。
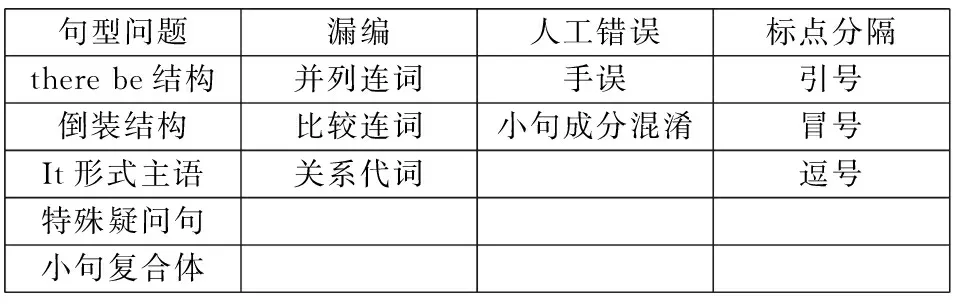
表5 小句句法分析错误原因
自然语言是复杂的,机器仅靠运算,对句型的识别能力有限度。如表5所示,小句句法分析错误共4大类原因:特殊句型、漏编、人工错误和标点分隔。每一类下面有具体的出错项目,现举例说明。
1.句型问题。
(1)there be句型,如例1,
错误标注:[P There/EX are/VBP] [C so/RB many/JJ rich/JJ people/NNS in/INP your/PRP$ area/NN] ,/, and/CC...
在我们的标注规则中,there be被划分到一起,识别为小句谓语P,这一点机器学到了。但是,there be 句型中,be后面的成份才是句子的真正主语S,而不是动词be的补语C。在there be句型的一般现在时、现在完成时、过去完成时的句子中,这种错误均有出现。
(2)倒装结构,如例2,
错误标注:[D Here/RB] [P are/VBP] [C our/PRP$ latest/JJS price/NN sheets/NNS] and/CC…
Here为地点副词,放在句首,小句需要倒装,be后的成份应该是句子的主语S,但是机器判断不出这是倒装句,因此将be后的成份识别为补语C。类似的倒装结构还出现在enclosed is…,attached are…,listed are…等小句中。
(3)It形式主语句型,如例3,
错误标注:Although/INC it/IT [P is/VBZ] [D already/RB] [D very/RB] [P late/JJ for/FOR] [C your/PRP$ L∨C/NNP] to/TO [P arrive/VB] ,/,…
我们知道,在It is … for sb. to do sth.句型中,句子的真正主语是sb. to do sth.,而机器所掌握的只是介词for后面应该接补语C,因此出现主语S识别错误。
(4)特殊疑问句,如例4,
错误标注:Why/WRB [P do/VBP] [C thousands/NNS of/INP people/NNS] who/WP [D normally/RB] [P suffer/VBP from/RP] [C the/DT miseries/NNS of/INP cold/JJ ,/, damp/JJ ,/, changeable/JJ weather/NN] [P wear/VB] [C Thermotex/NNP] ?/.
在上面的疑问句中,do是一个疑问助词,而不是实意动词,因此do后面的成份应该是主语S,而不是补语C。此类问题还出现在how long does...,what will be…等小句中。
(5)小句复合体。
功能语法中的小句复合体实际就是传统语法中的复合句或者并列句。标注错误的语料中,小句复合体错误之一是主从详述关系小句,即定语从句。如例5,
错误标注:… if/INC [S you/PRP] [P would/MD accept/VB] [C our/PRP$ order/NN for/INP coffee/NN] [C whose/WP$ number/NN] [P is/VBZ] [C No./NN 3003/CD] ./.
例5中,whose number 是定语从句的主语S,不能被识别为C。小句复合体中,投射关系小句,即宾语从句,也是常出现错误的小句复合体。如下例6,
错误标注:… ,/, [P have/VBP shown/VBN] that/INC [S of/INP all/DT conventional/JJ underwear/NN fabrics/NNS Thermotex/NNP] [P has/VBZ] [C the/DT highest/JJS warmth/NN insulating/VBG properties/NNS] ./.
介词短语修饰名词,应位于名词后,而不是名词前。因此,例6中,介词短语of all conventional underwear fabrics应该被标注为宾语从句的状语D,Thermotex为后面小句的主语S。
2.漏编。
机器没有学到规则而漏编,可能是因为规则设置模糊,更有可能是前期人工标注时,人为主观漏掉了对一些词的标注,以致不同小句中,对同一个词标注出现冲突,导致错误。语料中体现最多的漏编项目有:并列连词、比较连词和关系代词。
(1)并列连词问题,如例7,
错误标注:[P There/EX is/VBZ] [D also/RB] [S a/DT saving/NN in/INP freight/NN charges/NNS] when/WRB [S separate/JJ consignments/NNS] [P intended/VBN for/RP] [C the/DT same/JJ port/NN of/INP destination/NN] [P are/VBP carried/VBN] [D in/INP one/CD container/NN] and/CC [C an/DT additional/JJ saving/NN on/INP insurance/NN] [D because/INP of/INP the/DT lower/JJR premiums/NNS] [P charged/VBN for/RP] [C containershipped/VBN goods/NNS] ./.
例7的句子主干可以提炼为:There is a saving in freight charges and an additional saving on insurance,这使得an additional saving on insurance成为there be句型中的第二个主语。但是由于and 没有被标注成份,所以机器不能识别出and并列的是两个短语还是两个小句,以至于成份识别出错。类似错误还出现在连词or和either…or…结构中。
(2)比较连词than没有纳入标注范围,见例8,
错误标注:[D Due/JJ to/INP our/PRP$ internal/JJ remittance/NN procedures/NNS] ,/, which/WDT [P took/VBD] [D longer/RBR than/INP anticipated/VBN] ,/, …
例8中,由于than没有标注功能,系统就近选择,将其标入状语D,完全忽视了比较的意义,同时还造成了谓语anticipated的识别错误。
(3)定语从句关系代词没有纳入标注范围。
并不是每一个没有入编的定语从句关联词都有识别错误,但机器对个别关系代词的自动识别会出现错误,尤其是介词+关系代词的情况。常出现错误的有:who,with those who,of which,which。见例9,
错误标注:Since/INC [S the/DT defects/NNS of/INP the/DT goods/NNS] [P are/VBP inherent/JJ][D in/INP the/DT quality/NN of/INP the/DT material/NN of/INP which/WDT] [S the/DT goods/NNS] [P are/VBP made/VBN] ,...
例9中有三个错误:首先,“be +形容词+介词”的结构中,介词应该被标注在谓语中,算作谓语P的一部分,机器没有学习到,反而将in与后面的名词短语放在一起当做状语D。进而,the quality of the material本该是in的补语C,就被括在了状语内。最后,of which由于没有被标注功能,系统自动将其识别为了状语D,造成错误。
3.人工错误。
人工错误中的手误错误在错误分类表格下的注释中已经有详细说明,此处不再举例赘述。关于小句功能成分混淆问题,可能由于标注者疲劳或句子过长或其他原因,功能成分划分有误,而机器自动识别正确,见例10,
错误标注:[S In/INP support/NN of/INP our/PRP$ claim/NN] [S we/PRP] [P are/VBP sending/VBG] [C1 you/PRP] [C2 a/DT survey/NN report/NN] [P issued/VBN] by/BY [C CCIB/NNP] ./.
但是例10中, in support of介词短语表示“为了支持……”,应该被识别为状语D,但是人工标记成了主语S,反而机器标记正确。
4.标点分隔。
标点分隔问题指:本该共同作为同一功能的几个短语,由于其间有标点,机器就近选择标点所代表的功能,以至于标注混乱。常出现错误的标点有:引号、冒号、逗号。以引号错误为例,见表6。

表6 引号分隔错误示例
三 结语
本研究表明功能句法分析的错误中,边界错误最多,其次是功能成分识别错误,人工错误最少。但究其根本,在初期进行语料标注时,功能成分边界的划分、标注项目的确定和少量人为标记错误,对机器识别结果都有一定的影响。基于功能小句的句法分析系统还有很大的改进余地,本研究正是迈向改进的第一步。此后,对小句的研究会进一步深入,为提高句法分析精度贡献绵薄之力。
[1]俞士汾.计算语言学概论[M].北京:商务印书馆,2004.
[2]李业刚,黄河燕.汉语组块分析研究综述[J].中文信息学报,2013,27(3):1-8.
[3]袁里驰.融合语言知识的统计句法分析[J].中南大学学报(自然科学版),2012,43(3):986-991.
[4]徐润华.基于词语搭配知识和语法功能匹配的句法分析器[D].南京师范大学,2013.
[5]马建军.面向机器翻译的英语功能名词短语识别研究[D].大连理工大学,2012.
[6]盛文凤.英语介词短语功能识别及其在翻译中的应用[D].大连理工大学,2013.
[7]闫旭.浅谈SQL Server数据库的特点和基本功能[J].价值工程,2012:229-231.
猜你喜欢
疯狂英语·初中天地(2021年8期)2021-11-20 05:59:44
证券市场红周刊(2018年41期)2018-05-14 18:45:56
证券市场红周刊(2018年22期)2018-05-14 17:40:17
高中生·天天向上(2018年2期)2018-04-14 09:33:14
Transactions of Nanjing University of Aeronautics and Astronautics(2018年1期)2018-03-29 07:35:47
牡丹(2017年18期)2017-07-22 21:46:35
国际汉语学报(2016年1期)2017-01-20 08:21:30
现代语文(2016年27期)2016-03-03 02:58:54
中国洗涤用品工业(2015年9期)2015-02-28 19:03:05
外语教学理论与实践(2014年2期)2014-06-21 08:34:22
