
改进的最大相关最小冗余特征选择方法研究
2014-04-03 01:44姚明海
计算机工程与应用 2014年9期
姚明海,王 娜,齐 妙,李 妍
YAO Minghai1,2,WANG Na3,QI Miao2,LI Yan4
1.渤海大学 信息科学与技术学院,辽宁 锦州 121013
2.东北师范大学 计算机科学与信息技术学院,长春 130117
3.锦州师范高等专科学校 计算机系,辽宁 锦州 121013
4.大连市妇女创就业指导服务中心,辽宁 大连 116001
1.College of Information Science and Technology,Bohai University,Jinzhou,Liaoning 121013,China
2.School of Computer Science and Information Technology,Northeast Normal University,Changchun 130117,China
3.Department of Computer,Jinzhou Teachers Training College,Jinzhou,Liaoning 121013,China
4.Dalian Women and Employment Guidance Service Center,Dalian,Liaoning 116001,China
1 引言
随着科学技术的飞速发展,描述事物的数据维数越来越庞大,这些庞大的数据必然会引起维数灾难(Curse of dimensionality)[1]。特征选择是处理高维数据,实现数据降维的有效方法,从原始特征集合中提取特征子集,去掉冗余信息和干扰信息,实现特征维数的最优缩减,从而提高了后续算法的预测准确率和计算性能[2-3]。近些年,特征选择方法在模式识别[4-5]、生物信息学[6]、医学数据处理[7]等多个领域受到广泛的关注。特征选择不改变特征的原始表达,仅从特征集中筛选最能代表观测数据特点的最优特征子集,因此能很好地保持原始特征的含义,更利于人们的理解和判断。
特征评价和特征搜索策略是构成特征选择方法的两个重要因素。特征评价是判断所选特征优劣的标准,特征搜索策略是生成特征子集的主要手段。特征选择方法按特征子集的评价机制和搜索策略主要分为过滤式和封装式两大类。过滤式方法通过数据的内在属性评价特征的优劣,独立于后续的学习算法,是一种计算效率较高的方法。具有代表性的方法有T检验(T-test)[8]、Fisher score[9]、信息增益(Information Gain,InforGain)[10]等。但是,过滤式特征选择方法往往忽略了关于相关性的分析。封装式方法是依赖于机器学习算法的特征选择方法,通过分类算法的分类性能评价特征子集的优劣。与过滤式方法相比封装式方法计算的精度会好一些,但算法效率较低。考虑到特征之间的相关性和冗余性,人们提出了基于空间搜索的最大相关最小冗余(Minimal Redundancy Maximal Relevance,MRMR)算法[11]。MRMR算法使用互信息衡量特征的相关性与冗余度,并使用信息差和信息熵两个代价函数来寻找特征子集。但是,MRMR算法存在冗余度和相关性评价方法单一,不能根据用户需求设置特征维度等问题。曹静在文献[12]中提出了针对特征相关性和冗余性加权融合的方法,但对于特征选择的评价方法仍然没有改进。因此本文针对MRMR算法中的特征冗余度与相关性计算方法提出了改进方案。在冗余度计算过程中提出了一种新的简单快速的计算方法;在计算特征相关性过程中引入多种经典过滤式特征选择方法对特征重要性进行计算。
2 MRMR算法
最大相关最小冗余算法是最为典型的基于空间搜索的过滤式方法。最大相关就是指特征与类别相关度大,即特征能最大程度反映样本类别信息;最小冗余指特征间相关度小即冗余度小。MRMR方法使用互信息度量特征的相关性与冗余度,使用信息差和信息熵构建特征子集的搜索策略。
MRMR算法中最大相关和最小冗余定义分别如公式(1)和公式(2)所示:

其中,F为特征集合,c为样本类别,I(fr,c)表示特征fr与类别c之间的互信息,I(fr,fo)表示特征 fr与特征fo之间的互信息。
给定两个随机变量x和 y,设它们的概率密度分别为 p(x),p(y)和 p(x,y),则它们之间的互信息定义如公式(3)所示:

MRMR算法利用公式(4)作为评价函数指导特征子集的选择。
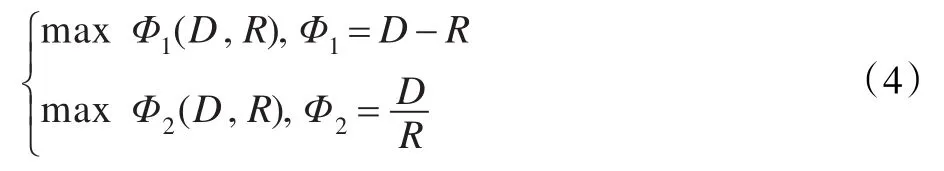
3 MMRMR算法
3.1 算法流程
MRMR算法从空间搜索角度考虑了特征与类别间的相关性和特征冗余度,在性能上普遍优于基于排序的特征选择方法,但其还存在一定的不足。首先,MRMR方法仅使用互信息来度量特征间的相关性,这就降低了该方法的适用范围。众所周知,评价特征重要程度的指标有很多,如基尼系数、Fisher得分、信息增益等等。所以,本文在评价特征重要性时提出了使用多种评价指标对特征重要性进行评价的方法,针对不同的数据选用不同的评价指标,使算法更具有鲁棒性,适用范围更广。同时在冗余度评价上,设计了简单直观的冗余度评价函数。MRMR方法以实现特征的最大相关最小冗余为前提,这就意味着无法避免某些情况下选出的特征维数过低。针对MRMR方法的以上问题,本文提出了MMRMR方法,该算法能够具有更广泛的适用性和更高的预测准确性。算法流程如图1所示。

图1 MMRMR算法流程图
3.2 冗余度评价函数
针对数字图像提出一个新的冗余度评价函数。其核心思想是:对于两个特征,如果其特征值越相近,则这两个特征越相对冗余。针对数字图像数据,如果图像两个不同位置的像素值所构成的两组向量值域越相近,就说明这两个位置越相对冗余。再进一步考虑到数字图像往往存在噪声、模糊等降质情况的存在。这里根据高斯分布 3σ法则(有68.3%的取值存在于 (μ-σ,μ+σ]区间),利用特征的均值和方差来重建值域,克服噪声等降质情况的影响。数学描述如公式(5)所示:

其中,V是一个256维的向量,且V∈{0,1}。
对于特征 f,设其均值为 fˉ,方差为 fv,则V(max(0,fˉ-fv),min(255,fˉ+fv))=1 ,即256 维V仅在[max(0,fˉ-fσ),min(255,fˉ+fσ)]值域范围内为 1,其余为0。该方法即能准确计算不同特征间的冗余性,又能避免噪声的影响。
3.3 相关性评价函数
对于特征重要性的判断有许多经典算法,并且这些算法被广泛地应用到了各个领域。但是目前还没有给出某种方法更适用于哪种数据的推荐。因此,为了更充分地挖掘数据本质,扩大方法的使用范围,本文采用多种评价指标计算特征的重要性。
本文将要进行对比的评价函数分别是:基于T检验(T-test)的评价方法[8]、基于 χ2算法(Chi2 algorithm,ChiSquare)的特征选择方法[13]、基于Relief算法的特征得分方法[14]、Fisher得分方法[9]、基于信息增益(Information Gain,InforGain)的方法[10]、基于基尼系数(Gini index,Gini)的方法[15]和 Kruskal-Wallis方法[16]。其中,T-test是利用t分布理论来比较两个特征的差异是否显著的统计方法;ChiSquare算法利用χ2统计来计算特征与类标签的相关性,实现特征重要性打分;Relief算法通过计算类内和类间样本距离来对特征打分;Fisher得分方法是寻找一组具有最好判别能力的特征子集的有监督方法;InforGain通过计算使用特征前后信息熵的改变来进行特征打分;Gini得分是一种基于统计测量和不纯分割的方法,Gini系数值越小说明这个特征越好;Kruskal-Wallis得分通过计算不同特征的分布是否存在差异进行特征打分。鉴于每种方法都有着自身的特点,因此本文在特征相关性评价上,针对不同数据集采用了不同的评价方法。
3.4 评价函数
MMRMR算法的目标是在所有特征中选出k个具有最大权重且冗余度最小的特征组合。评价函数定义如公式(6)所示:


4 实验结果与分析
使用五个经典的用于生物认证的数据库来验证MMRMR算法的有效性。在实验中,对于相关性评价采用了七种不同的特征权重计算方法,产生了七种不同的MMRMR方法,表1中列出了由此产生的七种方法。为了说明方法的有效性,本文提出的MMRMR方法同这七种经典的过滤式方法以及原始的MRMR方法在特征选择维度最高不超过200维的前提下进行对比实验。众所周知,每种特征选择方法采用的评价标准都不尽相同,所以针对不同的数据类型一些特征选择方法会有着其独特的优势。因此,本文在MMRMR框架下特征权重计算方法的选择上,参考了经典方法在不同数据库的识别效果,针对每一个数据库选择识别率相对较高的评价函数作为MMRMR框架下的特征权重计算方法。

表1 MMRMR框架生成的各种方法
为了体现特征选择的作用,本文选用基于欧氏距离的K-nn分类器进行预测判断。本文将以预测准确率(Predictive Accuracy,PR)作为评估标准,其定义如公式(7)所示:

其中,Num表示测试样本总数,RP表示被正确判断的样本数量。为了使实验结果符合统计规律,在实验过程中进行10次随机采样,将每类样本的一半作为训练样本,剩余样本作为测试样本,随机采样次数满足99%的数据均参与过训练和测试,计算获得的平均PR作为最终结果。
4.1 在FERET数据库上的实验结果
FERET数据库[17]包含1428个用户(60%男性,40%女性)的14051张多姿态人脸灰度图像。从数据库中随机选出72(人)×6(张)图像作为实验数据,并将图像大小调整为32×32。图2列出了部分实验用图像。

图2 FERET数据库中部分人脸图像
由表2可以看出,原始的Fisher得分方法和Relief方法在该数据库上识别率相对较高,因此本文采用了Fisher得分方法和Relief方法作为MRMR框架下的特征权重计算方法。MMRMR(F)在维数仅为200维的前提下就具有最高的准确率78.06%,其次MMRMR(R)也具有较高的预测准确率。

表2 FERET数据库上各种方法的平均预测准确率
为了对实验结果有更直观的认识,将MMRMR框架下的Fisher和Relief方法与传统Fisher和Relief方法的预测准确率随维度变化的情况在图3中显示出来。由图3中可以看出本文提出的MMRMR(F)方法在维数仅为140维时,其准确率就明显超过其他方法,接近采用全体特征的预测准确率。这也充分说明了该算法能够在充分去掉冗余信息的同时具有更高的预测准确率。MMRMR(R)结果次之,但是在较低维度时,它的准确率上升最快,如果再配合更精细的分类器模型,它会具有在较低运算复杂度的情况下就能产生较高的识别率的特性。

图3 部分方法的结果对比图
4.2 在ORL人脸数据库上的实验结果
ORL人脸数据库[18]包含400张图片(40(人)×10(张)),包括了面部表情和姿态的轻微变化。将数据库中图像大小调整为44×36,图4列出了该数据库的部分人脸图像。

图4 ORL数据库中部分人脸图像
由表3可以看出,基于InforGain、ChiSquare和Fisher为评价方法的MMRMR(I)、MMRMR(Chi)和MMRMR(F)在维数为200、180和200时就具有较高的预测准确率,几乎都高于传统的InforGain、ChiSquare和Fisher方法。并且,MMRMR(I)的预测准确率已经超过了90%。在该数据库上获得最高预测准确率的方法与FERET数据库上具有最高准确率的方法不同,这也说明不同的特征选择方法适用范围各不相同。
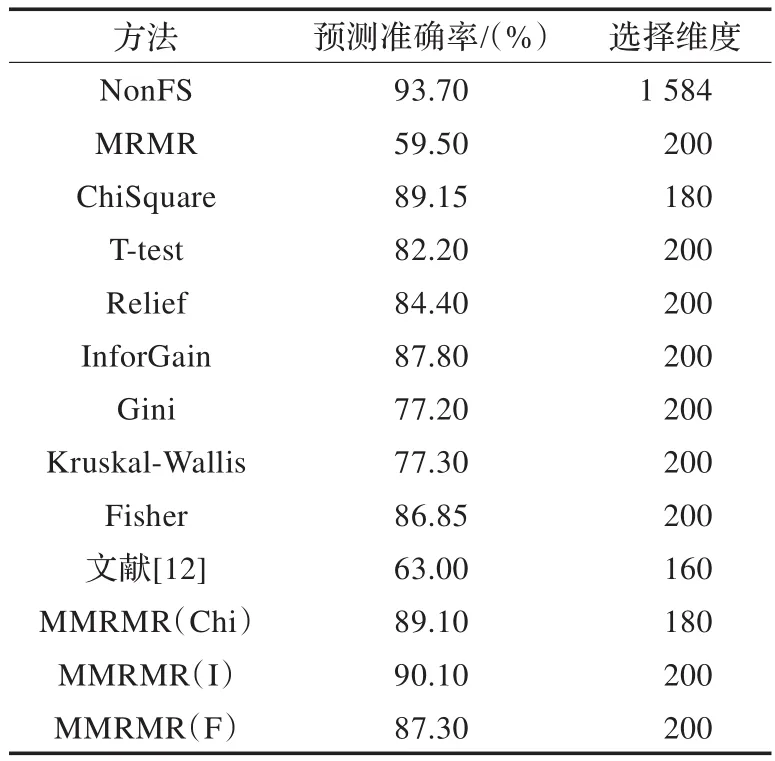
表3 ORL数据库上各种方法的平均预测准确率

图5 部分方法的结果对比图

图6 部分方法的特征选择结果(200维)对比图
图5中显示了本文方法与传统方法的预测准确率随选择特征维度变化的情况。由图中可以看出本文提出的MMRMR(I)方法明显优于其他方法,在160维时就接近90%。所有方法的准确率都没有在较低维的时候超过使用全体特征的准确率。原因在于:(1)本文将特征选择的维度上限设为200维,如果将上限进一步升高,选出更多的特征就可以进一步升高准确率;(2)在经过调整大小的预处理后,冗余信息被减少;(3)数据库过于简单,未能充分体现特征选择的优势。
图6给出了部分方法在200维时的特征选择对比结果图。由图6中可以看出,原始的特征选择方法除了T-test方法,其他方法基本上都认为识别的重要特征是头发,这明显与常识不服。本文方法选出的特征更多集中在面部区域,更能代表图像的特征,并且和实际情况相吻合。
4.3 在CMU PIE人脸数据库上的实验结果
CMU PIE数据库[19]包含了68个人的41368张不同姿态、光照和表情的人脸图片。实验中对每一个人选取同一姿态、同一表情和不同光照的21张图像,并在实验前根据眼睛位置将裁剪出的脸部区域调整大小为32×32的大小,部分图像如图7所示。

图7 CMU PIE数据库中部分人脸图片
由表4可以看出,由于该数据库的原因,所有方法的预测准确率都很高,甚至达到100%。但本文方法的预测准确率仍然高于原始方法,并且展现了在低维数时就具有较高识别率的特性,同时,多个方法都能在低维度时达到100%的准确率。对于传统MRMR算法和文献[12]中的方法在多个数据库上的实验结果都不是很理想,这也表明这两种方法的特征评价标准不适用于生物特征数据库。
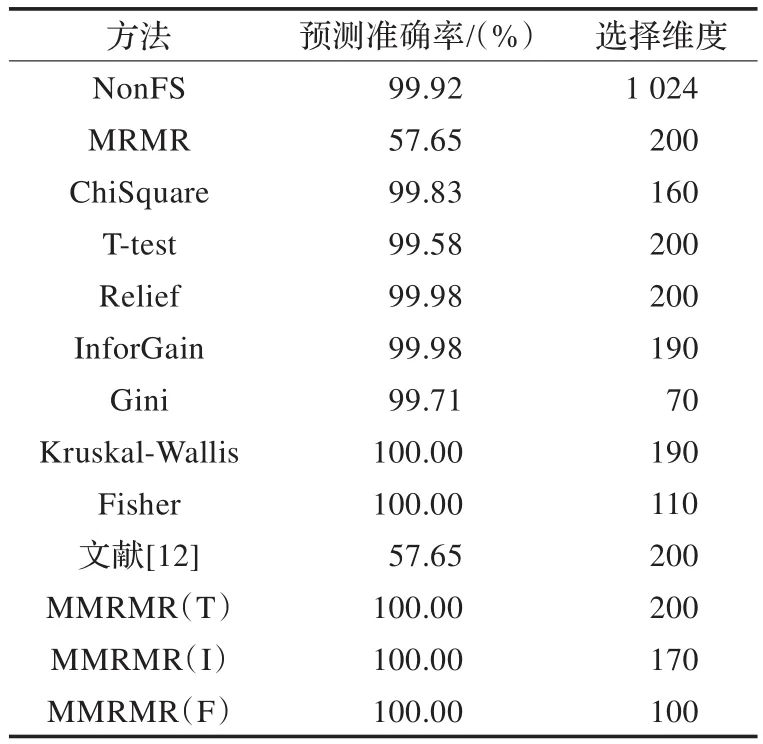
表4 PIE数据库上各种方法的平均预测准确率
由图8中可以看出,虽然这几种方法最后都能达到100%的准确率,但是本文提出的几种方法在20维时就具有较高的准确率,在40维的时候就接近了100%。

图8 部分方法的结果对比图
图9给出了这几种方法在60维时的特征选择结果。虽然在准确率上这几种方法都很接近,但是从选择的图像区域可以发现本文提出的几种方法更优秀。其他方法仅选出了轮廓和少量的眼睛,而本文方法选出了五官区域的重要特征。

图9 部分方法的特征选择结果(60维)对比图
4.4 在扩展的YaleB人脸数据库上的实验结果
扩展的YaleB数据库[20]包含38个人,每个人大约64张图片,包括了面部表情和光照条件的变化。图片在使用前调整为32×32像素的大小。图10中显示了扩展的YaleB数据库中的部分图片。

图10 扩展的YaleB数据库中部分人脸图片
表5列出了不同方法的预测准确率,可以看到本文提出的MMRMR(Chi)方法在维数仅为80维的时候就具有最高的预测准确率。

表5 扩展的YaleB数据库上各种方法的平均预测准确率
图11是识别率较高的四种方法的预测准确率随维度变化曲线图,如图所示,本文提出的MMRMR(Chi)方法随着维度的增大准确率迅速达到最大值。其他几种方法在60维后预测准确率基本无法进一步提高。

图11 部分方法的结果对比图
在图11中看出其他方法在200维时达到的预测准确率本文的方法在80维时就已经达到。在80维之后,随着维数的增加预测准确率有了明显下降,这说明在80维时选出的特征组合最好,当维数进一步增加就无法避免选出了冗余特征,造成准确率的降低。虽然随着后续特征的增加,准确率有了一定的回升,但是冗余特征的存在使得准确率无法回到最优时候的高度。部分方法的特征选择结果对比图如图12所示。

图12 部分方法的特征选择结果对比图
4.5 在CASIA(1.0)虹膜数据库上的实验结果
中国科学院自动化研究所的CASIA虹膜图像数据库[21]包括756张来自108只不同眼睛的图片,每只眼睛有7幅灰度图像,图13显示了CASIA数据库中部分虹膜图像。本文采用文献[22]中的方法对虹膜进行预处理。

图13 CASIA数据库中部分虹膜图片
表6的结果指出,无论是哪种特征选择方法在200维的情况下都没有超过不进行特征选择的准确率。造成这一情况的原因主要是因为在实验之前进行了一系列的预处理操作。这些操作已经将原始图像中大量的冗余信息和噪声去除。即使这样本文提出的MMRMR(I)方法仍然高于原有方法。

表6 CASIA数据库上各种方法取得的最高平均预测准确率
图14是ChiSquare、Relief、InforGain、Fisher和MMRMR(I)几种方法准确率随维度变化的曲线图。从图中可以看出 MMRMR(I)方法的预测准确率在所有维度下都优于其他方法。

图14 部分方法的结果对比图
5 结论
虽然MRMR方法的理念非常先进,但在实际应用中却有很多明显的不足,因此本文在现有特征选择方法的基础上,针对MRMR方法进行了改进,提出了MMRMR算法,避免了传统MRMR算法仅使用互信息判断特征的相关性和冗余度的问题,另外还解决了传统算法中不能根据用户需求设置特征选择数量的问题。通过在多个数据库上实验,验证了算法的有效性。同时,本文的方法可以适用于不同的数据库,能够根据不同数据库的特点具体问题具体分析。本文采用经典的过滤式特征选择方法进行权重计算,在后续研究中会针对具体问题选择特定的重要性评价算法和冗余度计算方法或提出新的算法来提高预测的精准度。
[1]Jain A K,Duin R P W,Mao J.Statistical pattern recognition:a review[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2000,22(1):4-37.
[2]Blum A,Langley P.Selection of relevant features and examples in machine learning[J].Artif Intell,1997,97:245-271.
[3]Dash M,Liu H.Feature selection for classifications[J].Intelligent Data Analysis:An Inter J,1997,1:131-156.
[4]Saeys Y,Inza I,Larrañaga P.A review of feature selection techniques in bioinformatics[J].Bioinformatics,2007,23(19):2507-2517.
[5]Zhang D,Chen S,Zhou Z H.Constraint score:a new filter method for feature selection with pairwise constraints[J].Pattern Recognition,2008,41(5):1440-1451.
[6]Naikal N,Yang A Y,Sastry S S.Informative feature selection for object recognition via sparse PCA[C]//2011 IEEE International Conference on Computer Vision(ICCV),2011:818-825.
[7]Zhang N,Ruan S,Lebonvallet S,et al.Kernel feature selection to fuse multi-spectral MRI images for brain tumor segmentation[J].Computer Vision and Image Understanding,2011,115(2):256-269.
[8]Press W H,Teukolsky S A,Vetterling W T,et al.Numerical recipes in C:the art of scientific computing[M].2nd ed.New York:Cambridge University Press,1992.
[9]Bishop C M.Neural networks for pattern recognition[M].Oxford:Oxford University Press,1995.
[10]Cover T M,ThomasJ A.Elementsofinformation theory[M].[S.l.]:Wiley,1991.
[11]Peng H,Long F,Ding C.Feature selection based on mutual information:criteria of max-dependency,max-relevance,and min-redundancy[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(8):1226-1238.
[12]曹静.基于最大相关最小冗余的特征选择算法研究[D].秦皇岛:燕山大学,2010.
[13]Liu H,Setiono R.Chi2:feature selection and discretization of numeric attributes[C]//Proc 7th Int Conf Tools with Artif Intell,1995:388-391.
[14]Kira K,Rendell L A.A practical approach to feature selection[C]//Proc 9th Int Workshop on Machine Learning,1992.
[15]Breiman L,Friedman J,Olshen R,et al.Classification and regression trees[M].Montery,CA:Wadsworth Int Group,1984.
[16]Wei L J.Asymptotic conservativeness and efficiency of kruskal-wallis test for k dependent samples[J].Journal of the American Statistical Association,1981,76(376):1006-1009.
[17]Phillips P J.The FERET evaluation methodology for face recognition algorithms[J].IEEE Trans on PAMI,2000,22(10):1090-1104.
[18]Samaria F S,Harter A C.Parameterisation of a stochastic model for human face identification[C]//Proceedings of the Second IEEE Workshop on Applications of Computer Vision,1994:138-142.
[19]Sim T,Baker S,Bsat M.The CMU pose,illumination,and expression database[J].IEEE Trans on PAMI,2003,25:1615-1618.
[20]Lee K C,Ho J,Kriegman D J.Acquiring linear subspaces for face recognition under variable lighting[J].IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27(5):684-698.
[21]CASIA-IrisV1[EB/OL].[2013-09-28].http://www.cbsr.ia.ac.cn/IrisDatabase.htm.
[22]Qi M,Lu Y,Li J,et al.User-specific iris authentication based on feature selection[C]//2008 International Conference on Computer Science and Software Engineering,2008:1040-1043.
猜你喜欢
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
中国交通信息化(2018年5期)2018-08-21
山西建筑(2017年29期)2017-11-15
黑龙江交通科技(2017年7期)2017-09-20
黑龙江交通科技(2017年10期)2017-03-01
电子制作(2017年23期)2017-02-02
黑龙江交通科技(2016年11期)2016-03-11
西北工业大学学报(2015年4期)2016-01-19
